
Energy-Efficient Retrofitting under Incomplete Information: A Data-Driven Approach and Empirical Study of Sweden


Abstract
:1. Introduction
2. Literature Review
2.1. Current Retrofitting Estimation Methods
2.2. Data-Driven Approach and Application for Building Retrofitting
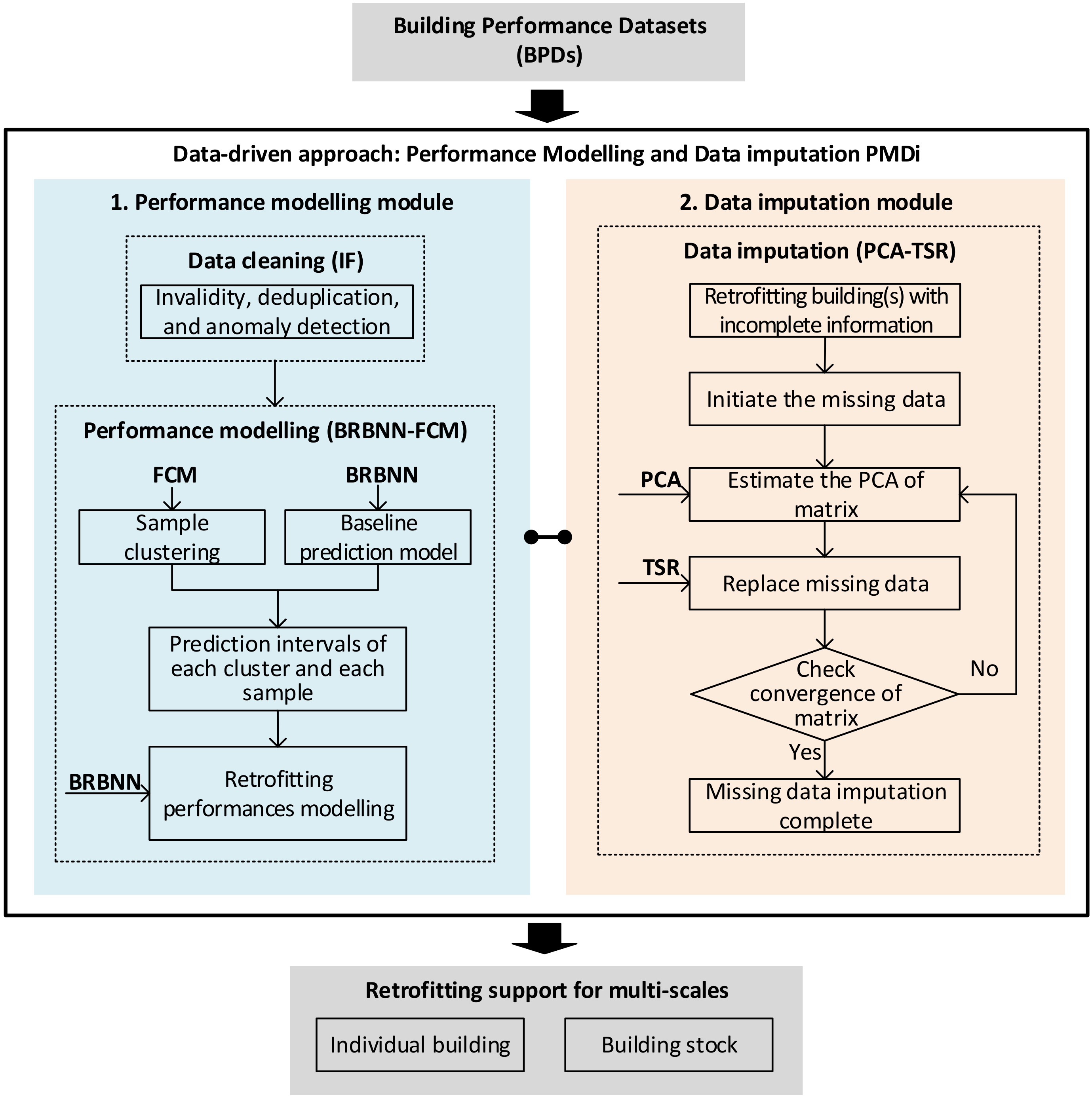
3. Proposed Approach
3.1. Performance Modelling Module
3.1.1. Data Cleaning
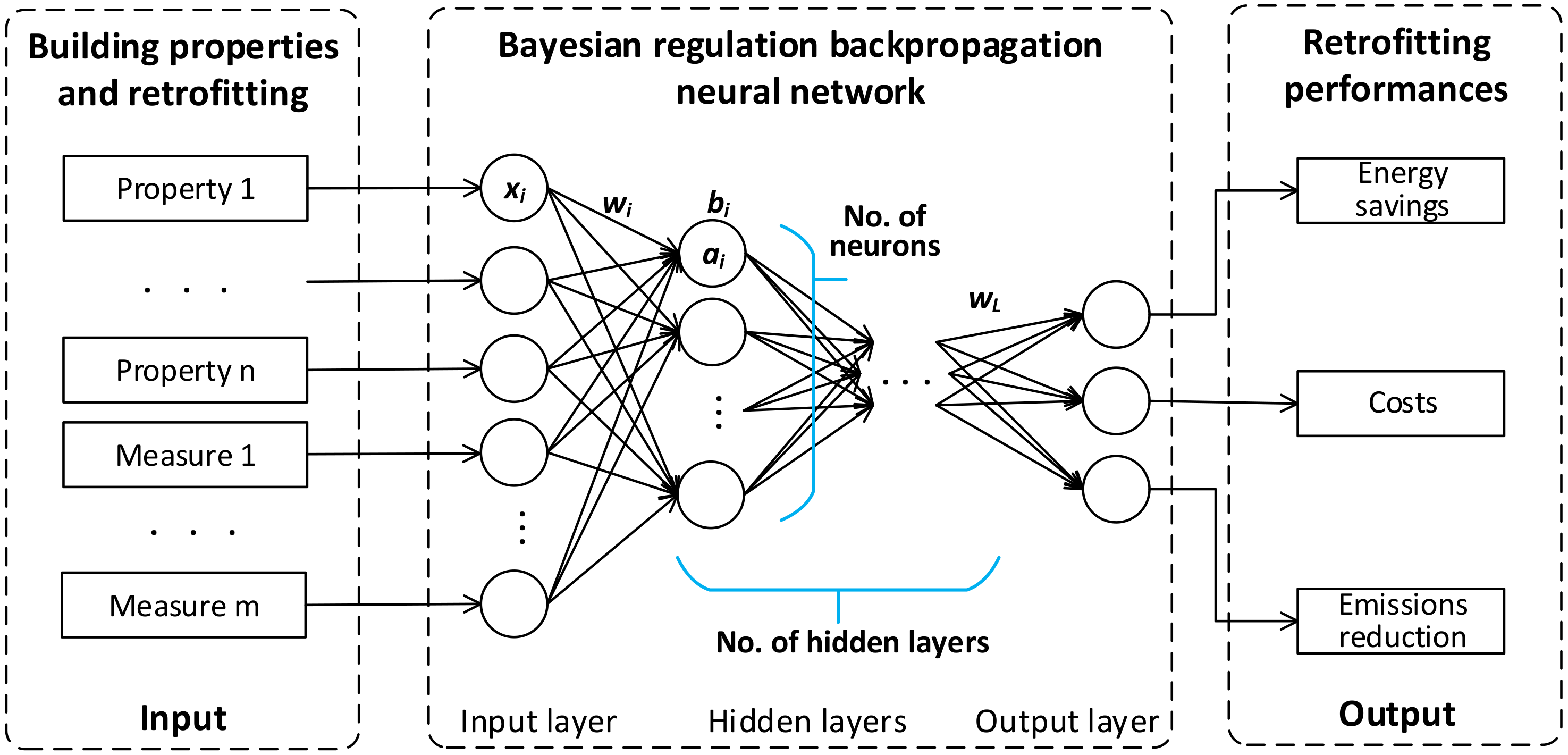
3.1.2. Performance Modelling
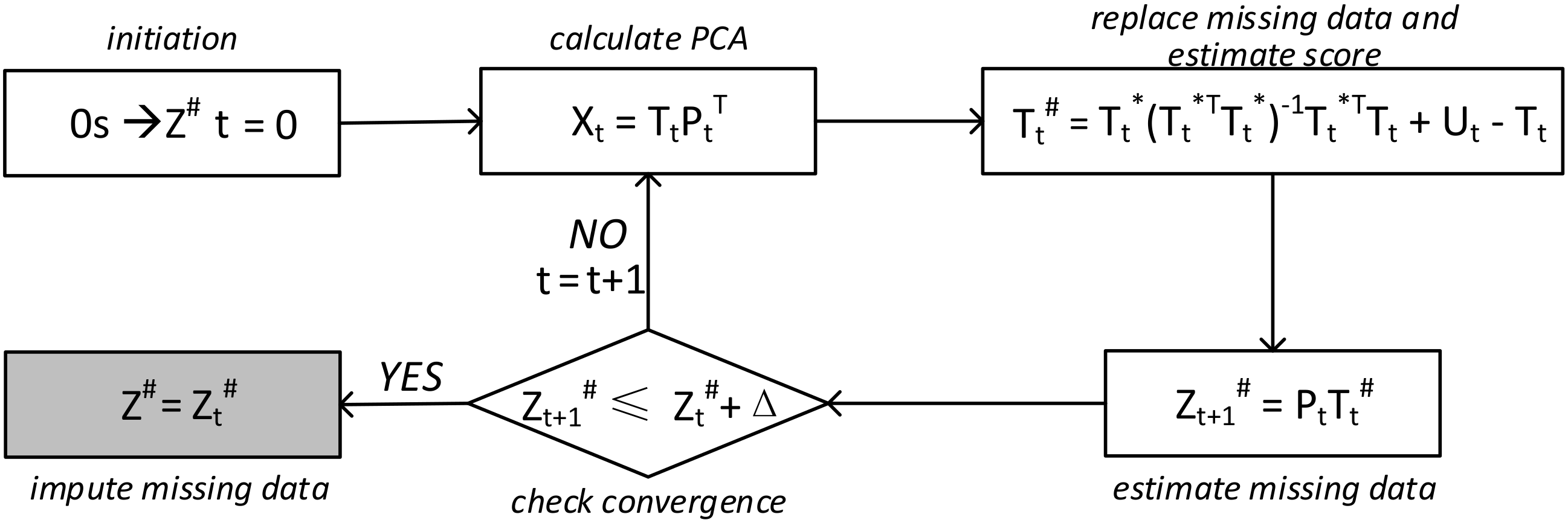
3.2. Data Imputation Module
4. Empirical Study
4.1. Empirical Information
4.2. Method Application and Validation
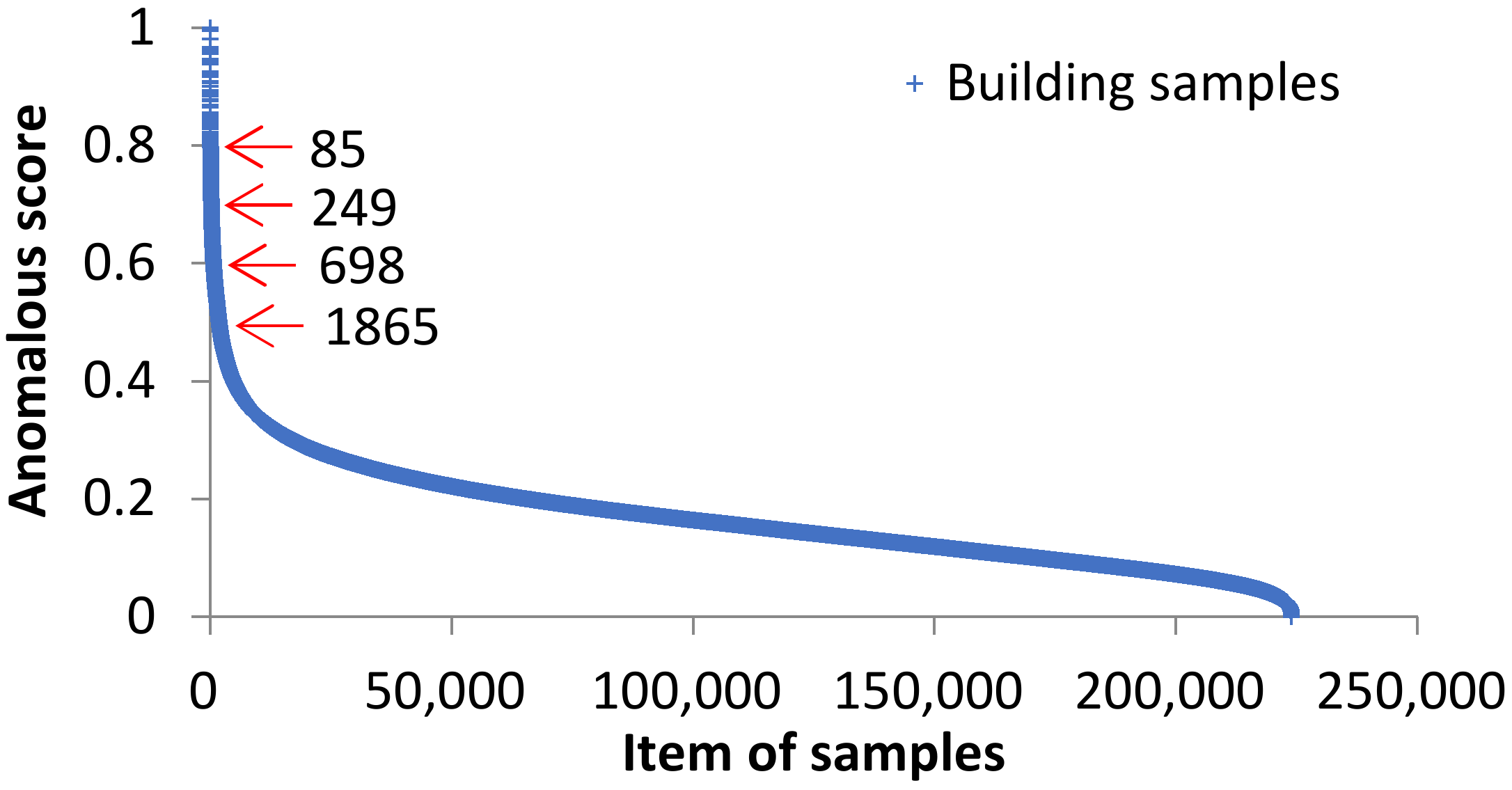
4.2.1. Data-Cleaning Process
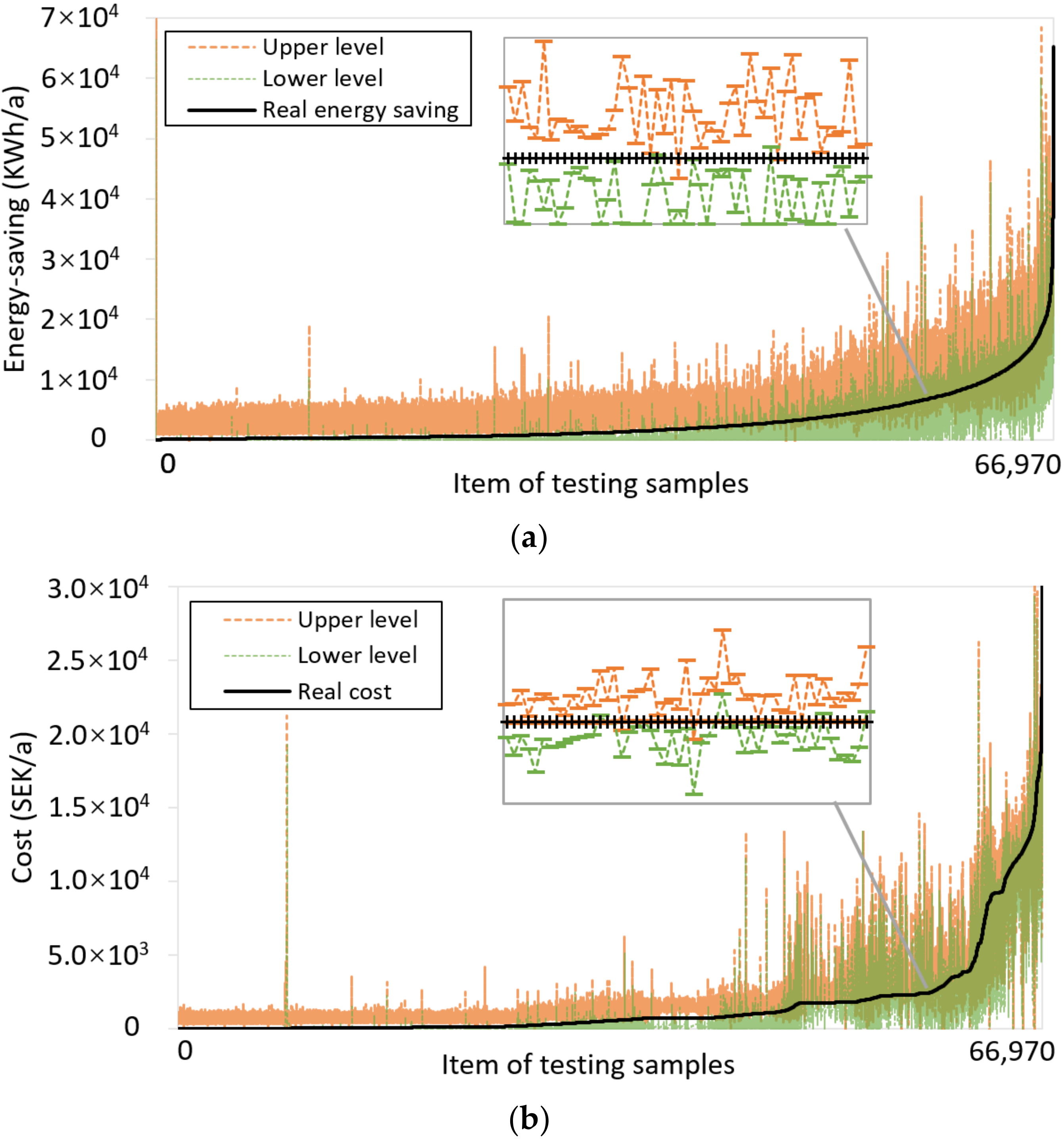
4.2.2. Performance Modelling Process and Validation
4.2.3. Data Imputation Process and Validation
5. Application Results and Method Discussion
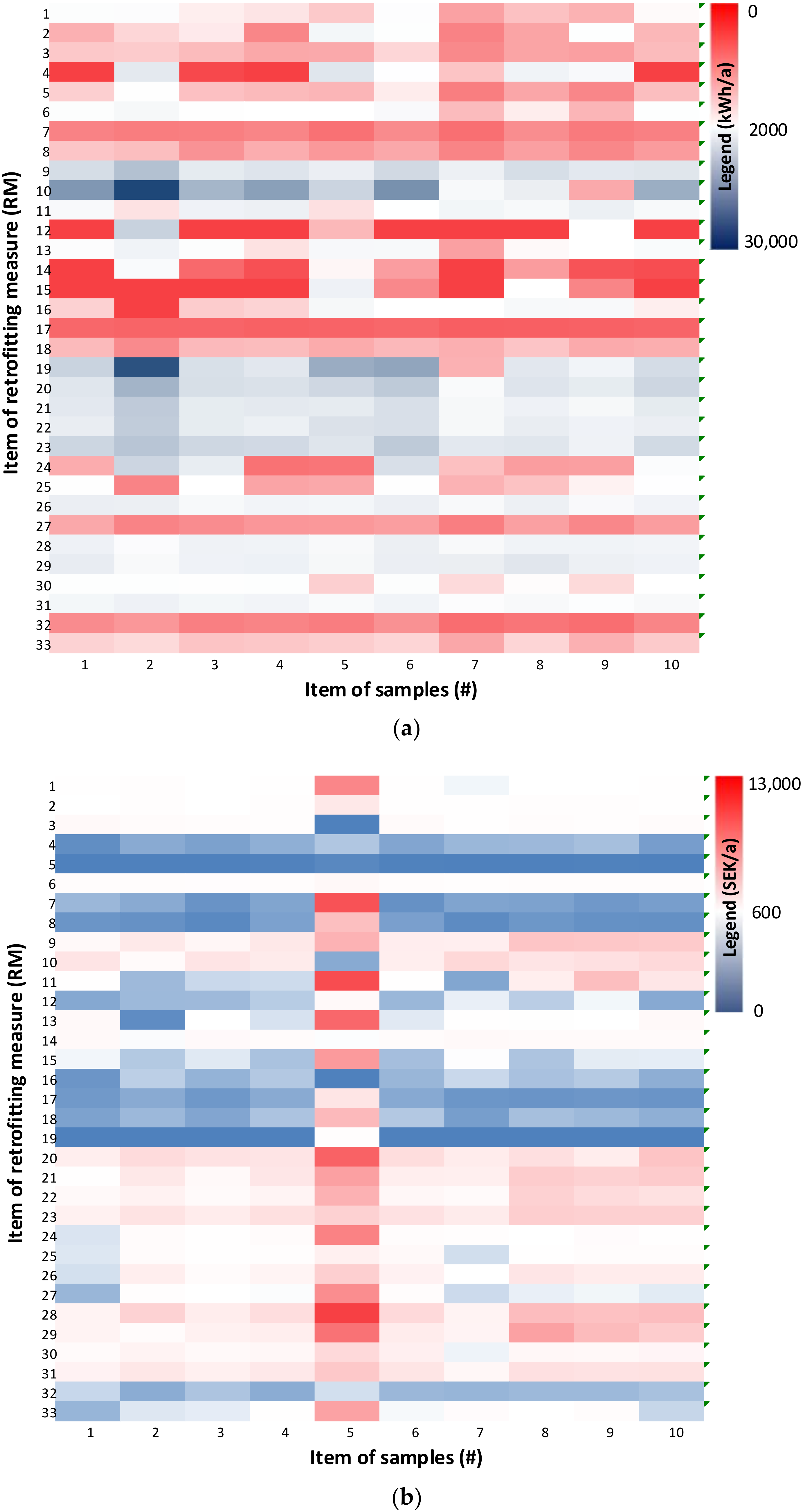
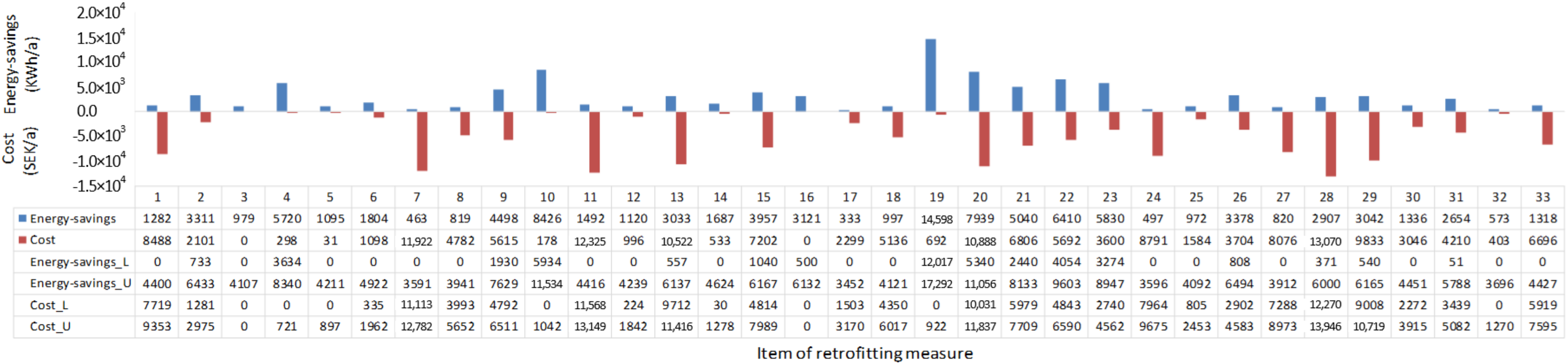
5.1. Multi-Scale Application
5.2. Method Discussion
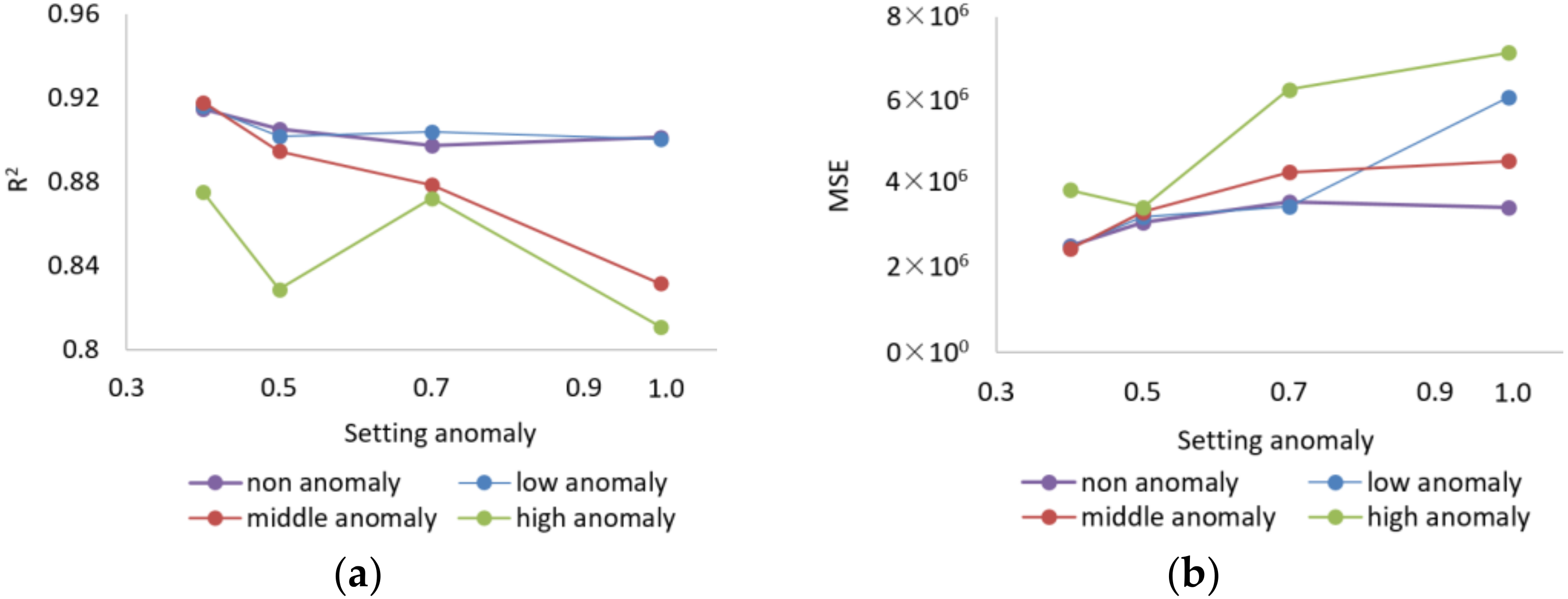
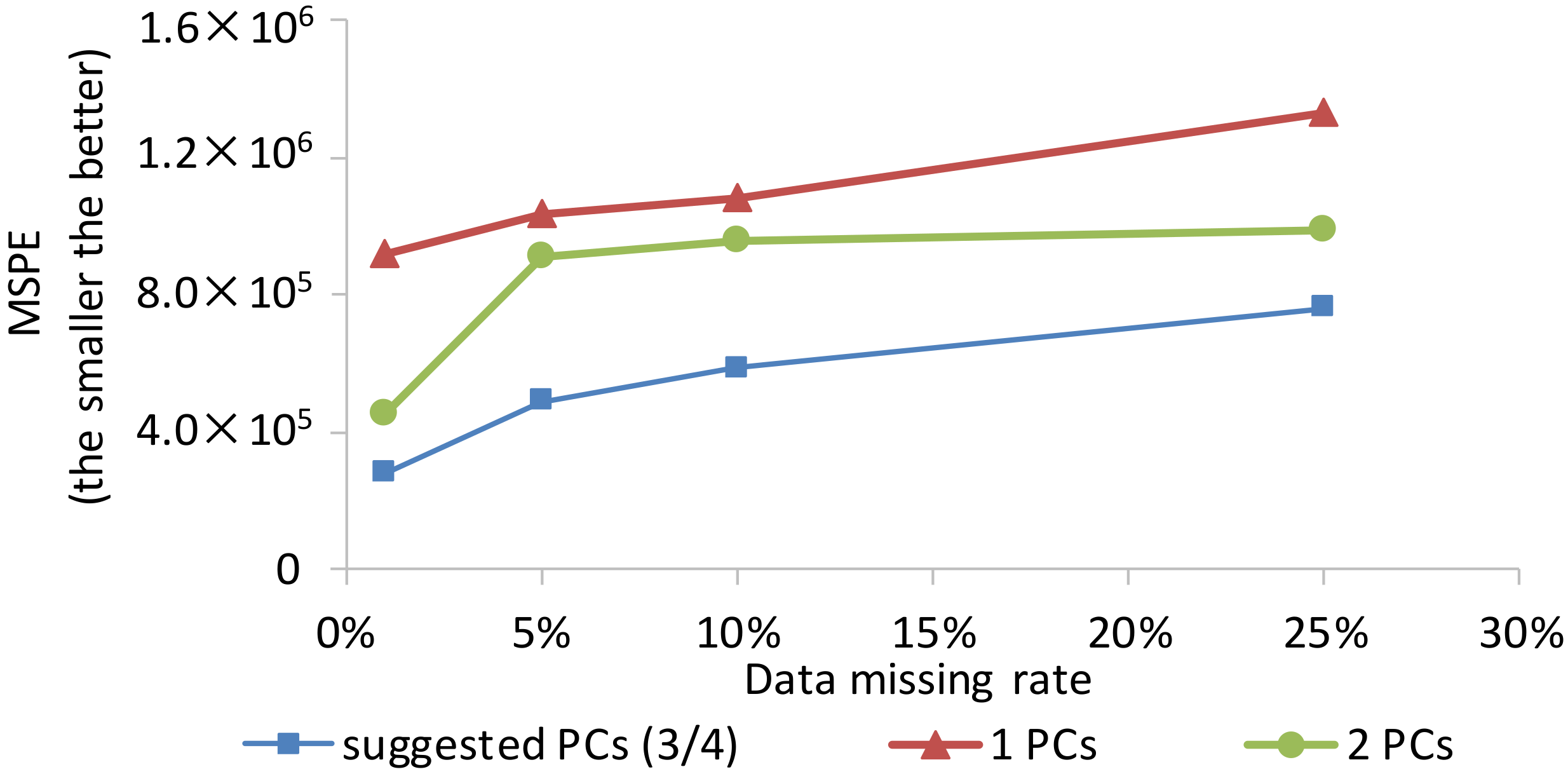
5.2.1. Different Method Setting
5.2.2. Previous Study Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BPDs | Building performance datasets |
| BPS | Building performance simulation |
| BRBNN | Bayesian regularization backpropagation neural network |
| EPC | Energy performance certificate |
| FCM | Fuzzy C-means clustering |
| IF | Isolation forest |
| MI | Mean imputation |
| MPI | Mean prediction interval |
| MSE | Mean square error |
| MSPE | Mean squared prediction error |
| PCA | Principal component analysis |
| PICP | Prediction interval coverage probability |
| PIs | prediction intervals |
| PMDI | Performance modelling with data imputation |
| R2 | Coefficient of determination |
| RM | Retrofitting measure |
| RMSE | Root mean square error |
| SI | Statistics imputation |
| TSR | Trimmed scores regression |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item of Samples (#) | 1 | 2 | 3 | 4 | 5 |
| Province | Norrbottens | Uppsala | Södermanlands | Gävleborgs | Stockholm |
| City | Boden | Uppsala city | Eskilstuna | Sandviken | Stockholm city |
| Own home (Y/N) | Y | Y | Y | Y | Y |
| Building complexity * (Y/N) | N | N | N | N | N |
| Building type (attached/detached) | attached | detached | attached | attached | attached |
| Construction year | 1971 | 1970 | 1965 | 1960 | 1969 |
| Heated area (m2, Atemp > 10 °C, except storage room) | 132 | 190 | 176 | 142 | 154 |
| Number of basement floors (>10 °C, except storage room) m2 | 0 | 1 | 1 | 1 | 0 |
| Number of floors aboveground | 1 | 3 | 1 | 2 | 2 |
| Number of stairs | 0 | 0 (0) | 0 | 0 | 0 (0) |
| Number of residential apartments | 1 (1) | 1 | 1 | 1 (1) | 1 |
| Available electrical power for heating and water (>10 W/m2, Y/N) | N | N | N | N | Y |
| The building’s energy use for heating and warm water, kWh | 22,400 | 34,000 | 21,200 | 20,800 | 18,500 |
| The building’s energy use for household, etc., kWh | 7300 | 5000 | 4200 | 2800 | 24,414 (24,900) |
| The building’s total energy use, kWh | 22,400 | 34,000 | 21,200 | 20,800 | 18,500 |
| The electricity that is included in the building’s energy use, kWh | 0 | 0 | 0 | 0 | 18,500 |
| Normal year adjusted value (degree days), kWh | 22,767 | 37,522 | 0 | 21,060 | 0 |
| Normal year adjusted value (Energy Index) | 22,761 | 36,988 | 22,800 | 20,938 | 21,247 |
| Energy consumption per area, kWh/m2, year | 172 | 195 | 130 | 147 | 138 |
| Energy consumption per area of which electricity, kWh/m2, year | 0 | 0 | 0 | 0 | 138 |
| Reference value 1 (according to new building requirements), kWh/m2, year | 130 | 90 | 90 | 110 | 55 |
| Reference value 2, min (statistical range), kWh/m2, year | 180 | 122 | 132 | 143 | 132 |
| Reference value 2, max (statistical range), kWh/m2, year | 220 | 149 | 162 | 175 | 162 |
| Energy version | 2012 | 2012 | 2015 | 2012 | 2015 |
| Energy class | D | F | E | D | G |
| Requirement for regular ventilation control in the building (Y/N) | N | N | N | N | N |
| Ventilation system FTX (Y/N) | N | N | N | N | N |
| Ventilation system F (Y/N) | N | N | N | N | N |
| Ventilation system FT (Y/N) | N | N | N | N | N |
| Ventilation system natural ventilation (Y/N) | N | N | Y | N | Y |
| Ventilation system F with recycling (Y/N) | N | N | N | N | N |
| Available air-conditioning systems with nominal cooling power greater than 12 Kw (Y/N) | N | N | N | N | N |
| Item of samples (#) | 6 | 7 | 8 | 9 | 10 |
| Province | Östergötlands | Norrbottens | Västernorrlands | Skåne | Skåne |
| City | Norrköping | Piteå | Härnösand | Trelleborg | Osby |
| Own home (Y/N) | Y | Y | Y | Y | Y |
| Building complexity * (Y/N) | N | N | N | N | N (N) |
| Building type (attached/detached) | attached | attached | attached | detached | attached |
| Construction year | 1962 | 1934 | 1932 | 1900 | 1958 |
| Heated area (m2, Atemp > 10 °C, except storage room) | 185 | 110 | 190 | 90 | 119 |
| Number of basement floors (> 10 °C, except storage room), m2 | 1 | 0(0) | 1 | 0 | 1 |
| Number of floors aboveground | 1 | 2(2) | 2 | 1 | 1 |
| Number of stairs | 0 | 0 | 0 | 0 | 0 |
| Number of residential apartments | 1 | 1 | 1 | 1 | 1 |
| Available electrical power for heating and water (>10 W/m2, Y/N) | N | Y | Y | Y | N |
| The building’s energy use for heating and warm water, kWh | 27,100 | 10,800 | 16,400 | 11,800 | 19,999 (20,000) |
| The building’s energy use for household, etc., kWh | 5173 (4000) | 14,000 | 21,600 | 17,300 | 4482 (4500) |
| The building’s total energy use, kWh | 27,100 | 11,249 (10,800) | 16,400 | 11,800 | 20,028 (20,000) |
| The electricity that is included in the building’s energy use, kWh | 0 | 10,800 | 16,400 | 11,800 | 0 |
| Normal year adjusted value (degree days), kWh | 31,682 | 12,156 | 19,368 | 8139 (11,611) | 13,751 (21,683) |
| Normal year adjusted value (Energy Index) | 30,905 | 12,632 | 19,451 | 12,687 (12,021) | 21,376 (20,955) |
| Energy consumption per area, kWh/m2, year | 167 | 115 | 102 | 141 (134) | 180 (176) |
| Energy consumption per area of which electricity, kWh/m2, year | 0 | 115 | 102 | 134 | 0 |
| Reference value 1 (according to new building requirements), kWh/m2, year | 90 | 95 | 75 | 55 | 90 |
| Reference value 2, min (statistical range), kWh/m2, year | 132 | 153 | 153 | 112 | 159 |
| Reference value 2, max (statistical range), kWh/m2, year | 162 | 188 | 187 | 137 | 194 |
| Energy version | 2012 | 2012 | 2012 | 2012 | 2012 |
| Energy class | F | D | E (E) | G (G) | F (F) |
| Requirement for regular ventilation control in the building (Y/N) | N | N | N | N | N |
| Ventilation system FTX (Y/N) | N | N | N(N) | N | N |
| Ventilation system F (Y/N) | N | N | N(N) | N | N |
| Ventilation system FT (Y/N) | N | N | N(N) | N | N |
| Ventilation system natural ventilation (Y/N) | Y | N | N(Y) | N | N |
| Ventilation system F with recycling (Y/N) | N | N | N(N) | N | N |
| Available air-conditioning systems with nominal cooling power greater than 12 Kw (Y/N) | N | N | N | N | N |
| Item of Samples | 1 | 2 | 3 | … | … | 40,735 | 40,736 |
|---|---|---|---|---|---|---|---|
| Building Properties | |||||||
| Province | Stockholm | Stockholm | Stockholm | … | … | Stockholm | Stockholm |
| City | Norrtälje | Stockholm city | Sundbyberg | … | … | Södertälje | Södertälje |
| Own home (Y/N) | N | N | N | … | … | N | N |
| Building complexity (Y/N) | N | N | N | … | … | N | N |
| building type (attached/detached) | attached | attached | attached | … | … | attached | attached |
| Construction year | 1971 | 1770 | 1909 | … | … | 1909 | 1968 |
| Heated area (m2, Atemp > 10 °C, except storage room) | 205 | 71 | 193 | … | … | 185 | 305 |
| Number of basement floors heated (>10 °C, except storage room) m2 | 1 | 0 | 1 | … | … | 0 | 1 |
| Number of floors aboveground | 1 | NaN | 2 | … | … | 2 | 1 |
| Number of stairs | 0 | NaN | NaN | … | … | NaN | 2 |
| Number of residential apartments | 1 | NaN | 1 | … | … | NaN | 0 |
| Available electrical power for heating and water (>10 W/m2, Y/N) | N | Y | N | … | … | Y | N |
| The building’s energy use for heating and warm water kWh | 40,000 | 10,000 | 41,582 | … | … | 30,092 | 12,900 |
| The building’s energy use for household, etc., kWh | 0 | 10,450 | 6622 | … | … | 37,402 | 16,900 |
| The building’s total energy use kWh | 40,000 | 10,450 | 41,582 | … | … | 30,484 | 16,900 |
| The electricity that is included in the building’s energy use kWh | 0 | 10,450 | 2162 | … | … | 30,484 | 16,900 |
| Normal year adjusted value (degree days) kWh | 42,740 | 11,838 | 46,680 | … | … | 31,520 | 18,167 |
| Normal year adjusted value (Energy Index) | 42,598 | 11,518 | 46,989 | … | … | 32,579 | 18,246 |
| Energy consumption per area kWh/m2, year | 208 | 162 | 243 | … | … | 176 | 60 |
| Energy consumption per area of which electricity kWh/m2, year | 0 | 162 | 13 | … | … | 176 | 60 |
| Reference value 1 (according to new building requirements) kWh/m2, year | 110 | 55 | 110 | … | … | 55 | 110 |
| Reference value 2, min (statistical range) kWh/m2, year | 159 | 132 | 157 | … | … | 132 | 79 |
| Reference value 2, max (statistical range) kWh/m2, year | 194 | 162 | 192 | … | … | 162 | 97 |
| Energy version | 2010 | 2010 | 2010 | … | … | 2010 | 2010 |
| Energy class | F | G | F | … | … | G | B |
| Requirement for regular ventilation control in the building (Y/N) | N | N | N | … | … | Y | NaN |
| Ventilation system FTX (Y/N) | N | N | N | … | … | N | NaN |
| Ventilation system F (Y/N) | N | N | N | … | … | N | NaN |
| Ventilation system FT (Y/N) | N | N | N | … | … | N | NaN |
| Ventilation system natural ventilation (Y/N) | Y | N | Y | … | … | Y | NaN |
| Ventilation system F with recycling (Y/N) | N | N | N | … | … | N | NaN |
| Available air-conditioning systems with nominal cooling power greater than 12 Kw (Y/N) | N | N | N | … | … | N | 0 |
| Suggested Retrofitting Strategy and Performances (Y/N) | |||||||
| New radiator valves | N | N | N | … | … | N | N |
| Adjustment of heating system | N | N | N | … | … | N | N |
| Time/need control of heating system | N | N | N | … | … | N | N |
| Cleaning and/or aeration of heating | N | N | N | … | … | N | N |
| Maximum indoor temperature limit | N | N | N | … | … | N | N |
| New indoor sensor | N | N | N | … | … | N | N |
| Replacement/installation of pressure-controlled pumps | N | N | N | … | … | N | N |
| Other action on heating system | N | N | N | … | … | N | N |
| Adjustment of ventilation system * | N | N | N | … | … | N | N |
| Timing of ventilation system | N | N | N | … | … | N | N |
| Need control of ventilation system | N | N | N | … | … | N | N |
| Replacement/installation of speed-controlled fans | N | N | N | … | … | N | N |
| Other action on ventilation | N | N | N | … | … | N | N |
| Time/need control of lighting | N | N | N | … | … | N | N |
| Time/need control of cold | N | N | N | … | … | N | N |
| Other action on lighting, cooling | N | N | N | … | … | N | N |
| Hot-water-saving measures | N | N | N | … | … | N | Y |
| Energy efficient lighting | N | N | N | … | … | N | N |
| Insulation of pipes and ventilation ducts | N | N | N | … | … | N | N |
| Replacement/installation of heat pump | Y | Y | N | … | … | Y | N |
| Replacement/installation of energy efficient heat source | N | N | N | … | … | N | N |
| Replacement/completion of ventilation system | N | N | N | … | … | N | N |
| Recovery of ventilation heat | N | N | N | … | … | N | N |
| Other action on installation | N | N | Y | … | … | N | N |
| Additional insulation of attic ceiling/roof | N | N | N | … | … | N | N |
| Additional insulation walls | N | N | N | … | … | N | N |
| Additional insulation basement/ground | N | N | N | … | … | N | N |
| Installation of solar cells | N | N | N | … | … | N | N |
| Installation of solar heating | N | N | N | … | … | N | N |
| Change to energy efficient windows/window doors with inner window | N | N | N | … | … | N | N |
| Complement window/window doors with inner window | N | N | N | … | … | N | N |
| Sealing windows/window doors/exterior doors | N | N | N | … | … | N | N |
| Other measure (construction) | N | N | N | … | … | N | N |
| Energy-savings (kWh/a) | 16,000 | 4000 | 3659 | … | … | 16,900 | 385 |
| Cost (SEK/a) | 14,400 | 1840 | 1353.83 | … | … | 13,520 | 65.45 |
References
- D’Oca, S.; Ferrante, A.; Ferrer, C.; Pernetti, R.; Gralka, A.; Sebastian, R.; Op‘t Veld, P. Technical, financial, and social barriers and challenges in deep building renovation: Integration of lessons learned from the H2020 cluster projects. Buildings 2018, 8, 174. [Google Scholar] [CrossRef]
- Hall, T.; Vidén, S. The Million Homes Programme: A review of the great Swedish planning project. Plan. Perspect. 2005, 20, 301–328. [Google Scholar] [CrossRef]
- Chen, Y.; Xiao, Z.Q. Research on the Eco-Renovation Strategy on Old Industrial Buildings. Appl. Mech. Mater. 2013, 253, 853–856. [Google Scholar] [CrossRef]
- Heo, Y.; Choudhary, R.; Augenbroe, G. Calibration of building energy models for retrofit analysis under uncertainty. Energy Build. 2012, 47, 550–560. [Google Scholar] [CrossRef]
- Amasyali, K.; El-Gohary, N.M. A review of data-driven building energy consumption prediction studies. Renew. Sustain. Energy Rev. 2018, 81, 1192–1205. [Google Scholar] [CrossRef]
- Mathew, P.A.; Dunn, L.N.; Sohn, M.D.; Mercado, A.; Custudio, C.; Walter, T. Big-data for building energy performance: Lessons from assembling a very large national database of building energy use. Appl. Energy 2015, 140, 85–93. [Google Scholar] [CrossRef]
- Collinge, W.O.; DeBlois, J.C.; Landis, A.E.; Schaefer, L.A.; Bilec, M.M. Hybrid dynamic-empirical building energy modeling approach for an existing campus building. J. Archit. Eng. 2016, 22, 04015010. [Google Scholar] [CrossRef]
- Tian, W.; Yang, S.; Li, Z.; Wei, S.; Pan, W.; Liu, Y. Identifying informative energy data in Bayesian calibration of building energy models. Energy Build. 2016, 119, 363–376. [Google Scholar] [CrossRef]
- Nagpal, S.; Mueller, C.; Aijazi, A.; Reinhart, C.F. A methodology for auto-calibrating urban building energy models using surrogate modeling techniques. J. Build. Perform. Simul. 2019, 12, 1–16. [Google Scholar] [CrossRef]
- Ochoa, C.E.; Capeluto, I.G. Advice tool for early design stages of intelligent facades based on energy and visual comfort approach. Energy Build. 2009, 41, 480–488. [Google Scholar] [CrossRef]
- Hiyama, K.; Kato, S.; Kubota, M.; Zhang, J. A new method for reusing building information models of past projects to optimize the default configuration for performance simulations. Energy Build. 2014, 73, 83–91. [Google Scholar] [CrossRef]
- Nik, V.M.; Mata, E.; Kalagasidis, A.S.; Scartezzini, J.-L. Effective and robust energy retrofitting measures for future climatic conditions—Reduced heating demand of Swedish households. Energy Build. 2016, 121, 176–187. [Google Scholar] [CrossRef]
- Rezaee, R.; Brown, J.; Augenbroe, G.; Kim, J. Assessment of uncertainty and confidence in building design exploration. AI EDAM 2015, 29, 429–441. [Google Scholar] [CrossRef]
- De Wit, S.; Augenbroe, G. Analysis of uncertainty in building design evaluations and its implications. Energy Build. 2002, 34, 951–958. [Google Scholar] [CrossRef]
- Macdonald, I.; Strachan, P. Practical application of uncertainty analysis. Energy Build. 2001, 33, 219–227. [Google Scholar] [CrossRef]
- Booth, A.T.; Choudhary, R.; Spiegelhalter, D.J. Handling uncertainty in housing stock models. Build. Environ. 2012, 48, 35–47. [Google Scholar] [CrossRef]
- Walter, T.; Sohn, M.D. A regression-based approach to estimating retrofit savings using the Building Performance Database. Appl. Energy 2016, 179, 996–1005. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.C.; Jiang, F.; Chen, W.; Wang, M.; Zhai, C. A bi-directional missing data imputation scheme based on LSTM and transfer learning for building energy data. Energy Build. 2020, 216, 109941. [Google Scholar] [CrossRef]
- Nielsen, A.N.; Jensen, R.L.; Larsen, T.S.; Nissen, S.B. Early stage decision support for sustainable building renovation—A review. Build. Environ. 2016, 103, 165–181. [Google Scholar] [CrossRef]
- Niemelä, T.; Kosonen, R.; Jokisalo, J. Cost-effectiveness of energy performance renovation measures in Finnish brick apartment buildings. Energy Build. 2017, 137, 60–75. [Google Scholar] [CrossRef]
- Mata, É.; Wanemark, J.; Nik, V.M.; Kalagasidis, A.S. Economic feasibility of building retrofitting mitigation potentials: Climate change uncertainties for Swedish cities. Appl. Energy 2019, 242, 1022–1035. [Google Scholar] [CrossRef]
- Shadram, F.; Mukkavaara, J. An integrated BIM-based framework for the optimization of the trade-off between embodied and operational energy. Energy Build. 2018, 158, 1189–1205. [Google Scholar] [CrossRef]
- Mata, É.; Kalagasidis, A.S.; Johnsson, F. A modelling strategy for energy, carbon, and cost assessments of building stocks. Energy Build. 2013, 56, 100–108. [Google Scholar] [CrossRef]
- ISO 14040; Environmental Management—Life Cycle Assessment—Principles and Framework. International Organization for Standardization: Geneva, Switzerland, 2006.
- Favi, C.; Di Giuseppe, E.; D’Orazio, M.; Rossi, M.; Germani, M. Building retrofit measures and design: A probabilistic approach for LCA. Sustainability 2018, 10, 3655. [Google Scholar] [CrossRef]
- Gustafsson, M.; Dipasquale, C.; Poppi, S.; Bellini, A.; Fedrizzi, R.; Bales, C.; Ochs, F.; Sié, M.; Holmberg, S. Economic and environmental analysis of energy renovation packages for European office buildings. Energy Build. 2017, 148, 155–165. [Google Scholar] [CrossRef]
- Feng, K.; Lu, W.; Wang, Y. Assessing environmental performance in early building design stage: An integrated parametric design and machine learning method. Sustain. Cities Soc. 2019, 50, 101596. [Google Scholar] [CrossRef]
- Gustafsson, M.; Dermentzis, G.; Myhren, J.A.; Bales, C.; Ochs, F.; Holmberg, S.; Feist, W. Energy performance comparison of three innovative HVAC systems for renovation through dynamic simulation. Energy Build. 2014, 82, 512–519. [Google Scholar] [CrossRef]
- Santangelo, A.; Tondelli, S. Occupant behaviour and building renovation of the social housing stock: Current and future challenges. Energy Build. 2017, 145, 276–283. [Google Scholar] [CrossRef]
- Serrano-Jimenez, A.; Barrios-Padura, A.; Molina-Huelva, M. Towards a feasible strategy in Mediterranean building renovation through a multidisciplinary approach. Sustain. Cities Soc. 2017, 32, 532–546. [Google Scholar] [CrossRef]
- Pasichnyi, O.; Levihn, F.; Shahrokni, H.; Wallin, J.; Kordas, O. Data-driven strategic planning of building energy retrofitting: The case of Stockholm. J. Clean. Prod. 2019, 233, 546–560. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, X.; Shi, Y.; Xia, L.; Pan, S.; Wu, J.; Han, M.; Zhao, X. A review of data-driven approaches for prediction and classification of building energy consumption. Renew. Sustain. Energy Rev. 2018, 82, 1027–1047. [Google Scholar] [CrossRef]
- Yildiz, B.; Bilbao, J.I.; Sproul, A.B. A review and analysis of regression and machine learning models on commercial building electricity load forecasting. Renew. Sustain. Energy Rev. 2017, 73, 1104–1122. [Google Scholar] [CrossRef]
- Feng, K.; Chen, S.; Lu, W.; Wang, S.; Yang, B.; Sun, C.; Wang, Y. Embedding ensemble learning into simulation-based optimisation: A learning-based optimisation approach for construction planning. Eng. Constr. Archit. Manag. 2021, 228, 1439–1453. [Google Scholar] [CrossRef]
- Geyer, P.; Singaravel, S. Component-based machine learning for performance prediction in building design. Appl. Energy 2018, 228, 1439–1453. [Google Scholar] [CrossRef]
- Lu, W.; Feng, K. Big-data driven building retrofitting: An integrated Support Vector Machines and Fuzzy C-means clustering method. Proc. IOP Conf. Ser. Earth Environ. Sci. 2020, 588, 042013. [Google Scholar] [CrossRef]
- Sharif, S.A.; Hammad, A. Developing surrogate ANN for selecting near-optimal building energy renovation methods considering energy consumption, LCC and LCA. J. Build. Eng. 2019, 25, 100790. [Google Scholar] [CrossRef]
- Geyer, P.; Schlüter, A.; Cisar, S. Application of clustering for the development of retrofit strategies for large building stocks. Adv. Eng. Inform. 2017, 31, 32–47. [Google Scholar] [CrossRef]
- Martinez, A.; Choi, J.-H. Analysis of energy impacts of facade-inclusive retrofit strategies, compared to system-only retrofits using regression models. Energy Build. 2018, 158, 261–267. [Google Scholar] [CrossRef]
- Kim, J.; Cho, K.; Kim, T.; Yoon, Y. Predicting the monetary value of office property post renovation work. J. Urban Plan. Dev. 2018, 144, 04018007. [Google Scholar] [CrossRef]
- Sassine, E.; Younsi, Z.; Cherif, Y.; Antczak, E. Frequency domain regression method to predict thermal behavior of brick wall of existing buildings. Appl. Therm. Eng. 2017, 114, 24–35. [Google Scholar] [CrossRef]
- Gudivada, V.; Apon, A.; Ding, J. Data quality considerations for big data and machine learning: Going beyond data cleaning and transformations. Int. J. Adv. Softw. 2017, 10, 1–20. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. CSUR 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data TKDD 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Kim, J.; Naganathan, H.; Moon, S.-Y.; Chong, W.K.; Ariaratnam, S.T. Applications of clustering and isolation forest techniques in real-time building energy-consumption data: Application to LEED certified buildings. J. Energy Eng. 2017, 143, 04017052. [Google Scholar] [CrossRef]
- Yan, Z.; Wang, J. Robust model predictive control of nonlinear systems with unmodeled dynamics and bounded uncertainties based on neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 457–469. [Google Scholar] [CrossRef] [PubMed]
- Foresee, F.D.; Hagan, M.T. Gauss-Newton approximation to Bayesian learning. In Proceedings of the International Conference on Neural Networks (ICNN’97), Houston, TX, USA, 12 June 1997; pp. 1930–1935. [Google Scholar]
- Shrestha, D.L.; Solomatine, D.P. Machine learning approaches for estimation of prediction interval for the model output. Neural Netw. 2006, 19, 225–235. [Google Scholar] [CrossRef] [PubMed]
- Dunn, J.C. A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters. J. Cybern. 1973, 3, 32–57. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Folch-Fortuny, A.; Villaverde, A.F.; Ferrer, A.; Banga, J.R. Enabling network inference methods to handle missing data and outliers. BMC Bioinform. 2015, 16, 283. [Google Scholar] [CrossRef] [PubMed]
- Arteaga, F.; Ferrer, A. Dealing with missing data in MSPC: Several methods, different interpretations, some examples. J. Chemom. J. Chemom. Soc. 2002, 16, 408–418. [Google Scholar] [CrossRef]
- Folch-Fortuny, A.; Arteaga, F.; Ferrer, A. PCA model building with missing data: New proposals and a comparative study. Chemom. Intell. Lab. Syst. 2015, 146, 77–88. [Google Scholar] [CrossRef]
- Groot, A.D.D.; Spiekerman, J.A.A. Methodology: Foundations of inference and research in the behavioral sciences. In 1. The Empirical Cycle in Science; De Gruyter Mouton: Berlin, Germany, 2020; pp. 1–32. [Google Scholar]
- EU. Directive 2002/91/EC Energy Performance of Buildings. 2002. Available online: https://eur-lex.europa.eu/legal-content/EN/ALL/?uri=celex%3A32002L0091 (accessed on 2 July 2022).
- Asensio, O.I.; Delmas, M.A. The effectiveness of US energy efficiency building labels. Nat. Energy 2017, 2, 17033. [Google Scholar] [CrossRef]
- Takaguchi, H.; Izutsu, S.; Washiya, S.; Kametani, S.; Hanzawa, H.; Yoshino, H.; Asano, Y.; Okumiya, M.; Shimoda, Y.; Murakawa, S.; et al. Development and analysis of DECC (data-base for energy consumption of commercial building): Part 1 Development on basic database of DECC. J. Environ. Eng. 2012, 77, 699–705. [Google Scholar] [CrossRef]
- Candido, C.; Kim, J.; de Dear, R.; Thomas, L. BOSSA: A multidimensional post-occupancy evaluation tool. Build. Res. Inf. 2016, 44, 214–228. [Google Scholar] [CrossRef]
- Johansson, T.; Vesterlund, M.; Olofsson, T.; Dahl, J. Energy performance certificates and 3-dimensional city models as a means to reach national targets—A case study of the city of Kiruna. Energy Convers. Manag. 2016, 116, 42–57. [Google Scholar] [CrossRef]
- Caceres, A.G. Shortcomings and Suggestions to the EPC Recommendation List of Measures: In-Depth Interviews in Six Countries. Energies 2018, 11, 2516. [Google Scholar] [CrossRef]
- Abela, A.; Hoxley, M.; McGrath, P.; Goodhew, S. An investigation of the appropriateness of current methodologies for energy certification of Mediterranean housing. Energy Build. 2016, 130, 210–218. [Google Scholar] [CrossRef]
- Kavgic, M.; Mavrogianni, A.; Mumovic, D.; Summerfield, A.; Stevanovic, Z.; Djurovic-Petrovic, M. A review of bottom-up building stock models for energy consumption in the residential sector. Build. Environ. 2010, 45, 1683–1697. [Google Scholar] [CrossRef]
- Buratti, C.; Barbanera, M.; Palladino, D. An original tool for checking energy performance and certification of buildings by means of Artificial Neural Networks. Appl. Energy 2014, 120, 125–132. [Google Scholar] [CrossRef]

| No. | Building Property | No. | Building Property |
|---|---|---|---|
| 1. | Location (province) | 18. | Normal year adjusted value (Energy Index) |
| 2. | Location (city) | 19. | Energy consumption per area |
| 3. | Own home (Y/N) | 20. | Energy consumption per area of which electricity |
| 4. | Building complexity* (Y/N) | 21. | Reference value 1 (according to new building requirements) kWh/m2, year |
| 5. | Building type (attached/detached) | 22. | Reference value 2, min (statistical range) kWh/m2, year |
| 6. | Construction year | 23. | Reference value 2, max (statistical range) kWh/m2, year |
| 7. | Heated area (m2, Atemp > 10 °C, except storage room) | 24. | Energy version |
| 8. | Number of basement floors heated (>10 °C, except storage room), m2 | 25. | Energy class * |
| 9. | Number of floors aboveground | 26. | Requirement for regular ventilation control in the building (Y/N) |
| 10. | Number of stairs | 27. | Ventilation system FTX (Y/N) |
| 11. | Number of residential apartments | 28. | Ventilation system F (Y/N) |
| 12. | Available electrical power for heating and water (>10 W/m2) | 29. | Ventilation system FT (Y/N) |
| 13. | The building’s energy use for heating and warm water * kWh | 30. | Ventilation system natural ventilation (Y/N) |
| 14. | The building’s energy use for household, etc. * kWh | 31. | Ventilation system F with recycling (Y/N) |
| 15. | The building’s total energy use * kWh | 32. | Available air-conditioning systems with nominal cooling power greater than 12 kW (Y/N) |
| 16. | The electricity that is included in the building’s energy use kWh | 33. | Date of approval |
| 17. | Normal year adjusted value (degree days) kWh | 34. | EPC version |
| No. | Retrofit Strategy | No. | Retrofit Strategy |
|---|---|---|---|
| 1. | New radiator valves | 18. | Energy efficient lighting |
| 2. | Adjustment of heating system | 19. | Insulation of pipes and ventilation ducts |
| 3. | Time/need control of heating system | 20. | Replacement/installation of heat pump |
| 4. | Cleaning and/or aeration of heating | 21. | Replacement/installation of energy efficient heat source |
| 5. | Maximum indoor temperature limit | 22. | Replacement/completion of ventilation system |
| 6. | New indoor sensor | 23. | Recovery of ventilation heat |
| 7. | Replacement/installation of pressure-controlled pumps | 24. | Other action on installation |
| 8. | Other action on heating system | 25. | Additional insulation of attic ceiling/roof |
| 9. | Adjustment of ventilation system | 26. | Additional insulation walls |
| 10. | Timing of ventilation system | 27. | Additional insulation basement/ground |
| 11. | Need control of ventilation system | 28. | Installation of solar cells |
| 12. | Replacement/installation of speed-controlled fans | 29. | Installation of solar heating |
| 13. | Other action on ventilation | 30. | Change to energy efficient windows/window doors with inner window |
| 14. | Time/need control of lighting | 31. | Complement window/window doors with inner window |
| 15. | Time/need control of cold | 32. | Sealing windows/window doors/exterior doors |
| 16. | Other action on lighting, cooling | 33. | Other measure (construction) |
| 17. | Hot-water-saving measures | -- | -- |
| Structure of Baseline Model | RMSE | R2 | Structure of Endpoints Model | RMSE | R2 |
|---|---|---|---|---|---|
| 67-10-10-10-10-2 | 1.56 × 103 | 0.825 | 67-10-10-10-10-2 | 2.45 × 103 | 0.998 |
| 67-10-10-2 | 1.29 × 103 | 0.875 | 67-10-10-2 | 3.45 × 103 | 0.998 |
| 67-10-2 | 1.70 × 103 | 0.787 | 67-10-2 | 7.09 × 103 | 0.996 |
| 67-3-2 | 1.31 × 103 | 0.871 | 67-3-2 | 1.75 × 104 | 0.991 |
| Data Imputation Method | Mean Squared Prediction Error | Absolute Value Error * |
|---|---|---|
| PCA–TSR | 2.78 × 105 | −1/+28/+4 |
| Mean Imputation (MI) | 1.66 × 106 | −348/−319/+1 |
| Statistics Imputation (SI) | 3.23 × 106 | −421/−394/−37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, K.; Lu, W.; Wang, Y.; Man, Q. Energy-Efficient Retrofitting under Incomplete Information: A Data-Driven Approach and Empirical Study of Sweden. Buildings 2022, 12, 1244. https://doi.org/10.3390/buildings12081244
Feng K, Lu W, Wang Y, Man Q. Energy-Efficient Retrofitting under Incomplete Information: A Data-Driven Approach and Empirical Study of Sweden. Buildings. 2022; 12(8):1244. https://doi.org/10.3390/buildings12081244
Chicago/Turabian StyleFeng, Kailun, Weizhuo Lu, Yaowu Wang, and Qingpeng Man. 2022. "Energy-Efficient Retrofitting under Incomplete Information: A Data-Driven Approach and Empirical Study of Sweden" Buildings 12, no. 8: 1244. https://doi.org/10.3390/buildings12081244
APA StyleFeng, K., Lu, W., Wang, Y., & Man, Q. (2022). Energy-Efficient Retrofitting under Incomplete Information: A Data-Driven Approach and Empirical Study of Sweden. Buildings, 12(8), 1244. https://doi.org/10.3390/buildings12081244