1. Introduction
Global climate change is affecting many countries [
1,
2]. Thus, global collaboration has been initiated to support low-carbon sustainable development in response to this grand challenge [
3]. The construction sector, however, cannot be excluded from these mitigation strategies as this industry is responsible for a high portion of global carbon emissions [
4,
5]. Cement is a significant source of carbon dioxide emitted during production and consumption [
6]. Thus, employing some strategies such as using recycled materials could substantially reduce greenhouse gas emissions in this sector [
7,
8]. There are many studies that address how the construction sector can reduce global warming’s impacts, but there are few studies that address the use of recycled materials in this area [
9]. Alternative materials, recycled waste concrete, can be substituted for conventional concrete constituents to alleviate the aforementioned issues and improve sustainability.
Different studies were carried out to discuss and evaluate the technological feasibility of Recycled Construction and Demolition Waste Aggregate Concrete (RCDWAC) [
10,
11,
12,
13,
14]. The mechanical characteristics of RCDWAC may be generally less than those of Ordinary Portland Concrete (OPC), but they are still adequate for some practical construction alternatives [
15]. A recycling station and concrete factory are used to produce RCDWAC, which incorporates natural coarse aggregates [
16]. Two stages were involved in the demolition waste concrete recycling process. Crushing with jaw crushers (first) and crushing with impact crushers (second). Engineering tools (e.g., electromagnets, water cleaners, or air sifters) were used to remove reinforcement and contaminants after crushing [
17].
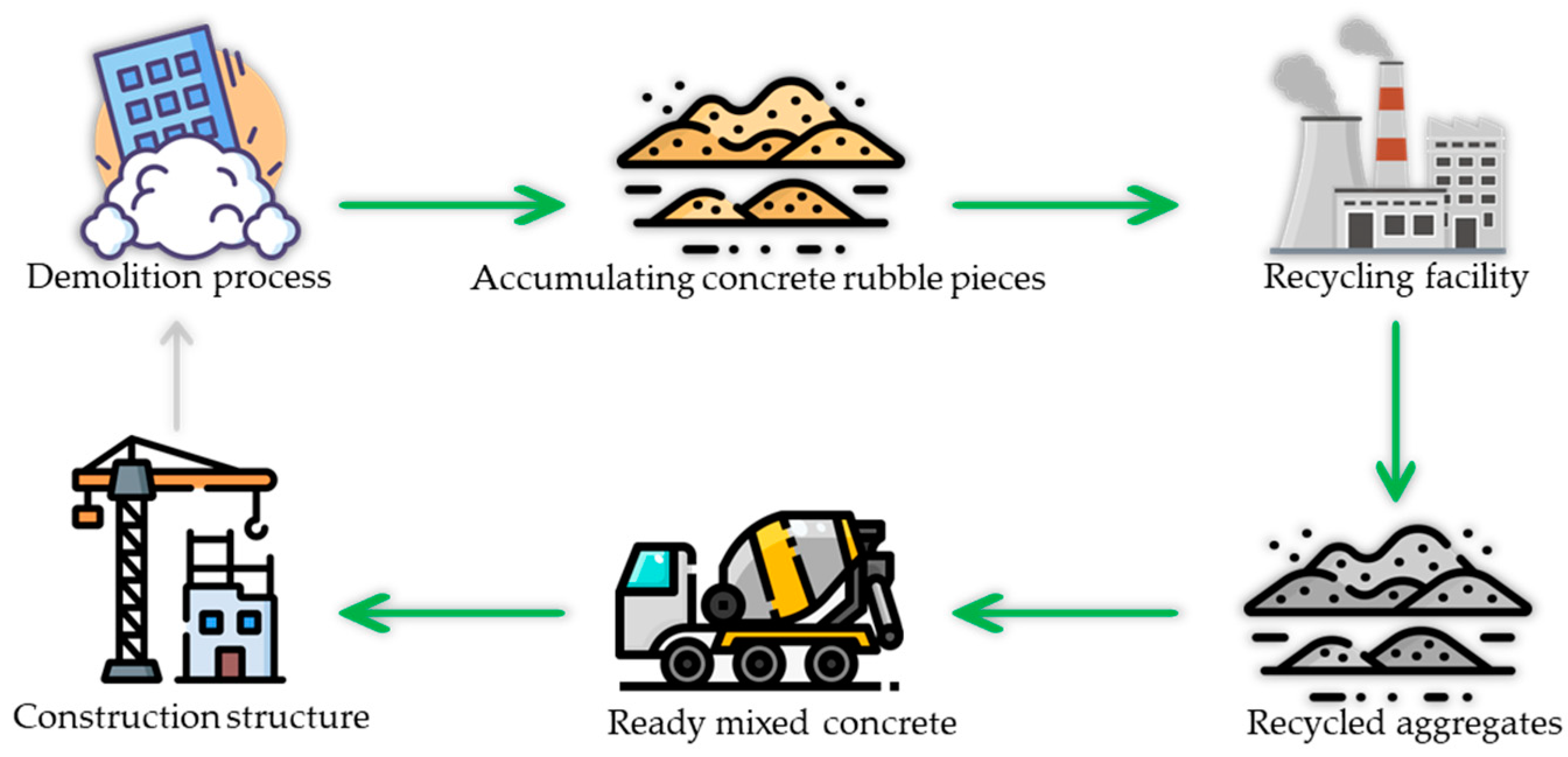
Figure 1 illustrates the reproducing cycle of RCDWAC. Although studies on these concrete types have already begun, their characteristics remain unclear. Characteristics of concrete are input parameters in a number of design codes [
18]. It is, therefore, crucial that these characteristics are accurately estimated so as to save time and effort [
19]. Predicting concrete characteristics has been the focus of the majority of earlier studies [
20]. Models previously published for regular concrete may, however, fail to accurately estimate the characteristics of other types of concrete.
The mechanical behaviour of concrete is dependent on experimental characteristics such as volumetric/weighted mixture proportion values [
21]. Developing cost-effective and eco-friendly cementitious blends with optimal structural performance is a crucial objective for researchers and engineers [
22]. Complex standards necessitate specialised users and time-consuming procedures for experimental investigation. Therefore, civil engineers employed an eco-friendly solution based on the development of
Artificial Intelligence (AI) models to address this issue [
23,
24,
25,
26,
27,
28,
29,
30]. Several linear and nonlinear regression-based AI methods have recently been utilised to model concrete’s mechanical and structural properties. Sadowski et al. [
31] estimated the compressive strength (CS) of low-strength concrete containing mineral dusts using the hybridised model. DeRousseau et al. [
32] tried to compare predictive regression-based artificial intelligence models to simulate the compressive strength of field-placed concrete. Shahmansouri et al. [
33] proposed Artificial Neural Network (ANN) and Gene Expression Programming (GEP) techniques for eco-environmentally concrete properties. The authors of [
34] introduced a novel method for predicting the compressive strength (CS) of foam lightweight concrete based on an optimisation algorithm and Multivariate Adaptive Regression Splines (MARS). Naseri et al. [
35] employed machine learning and evolutionary approaches for designing sustainable mixtures. Dao et al. [
36] investigated Adaptive Neuro-Fuzzy Inference System (ANFIS) and ANN to estimate the behaviour of geopolymer concrete. Asteris and Mokos [
37] employed an ANN system as an alternative application for estimating the CS of concrete using a non-destructive experimental method. Golafshani et al. [
38] estimated the compressive strength (CS) of ordinary and high-performance concretes employing evolutionary methods. Behnood and Golafshani [
39] studied the M5p model tree method to simulate the mechanical properties of mixtures containing waste foundry sand. Asteris and Mokos [
37] presented a surrogate model for the estimation of the compressive strength of masonry. Feng et al. [
40] evaluated an adaptive boosting technique for estimating the compressive strength of concrete containing granulated blast furnace slag. Li et al. [
41] examined the ability of data-driven models known as ANN, ANFIS, and Multiple Linear Regression (MLR) to predict the service life of concrete. Using the GEP concept, Gholampour et al. [
42] formulated the compressive strength of recycled aggregate concrete with non-pozzolanic admixtures. Al-Shamiri et al. [
43] presented the Extreme Learning Method (ELM) and ANN for predicting the CS of cylindrical samples of high-strength concrete.
Although the AI models mentioned above have been successfully applied to a wide variety of civil engineering problems, many rely on crisp input variables to model the target variables, which can be a limitation of the modelling [
44]. In contrast to their crisp counterparts, Fuzzy sets have gradual transitions between defined sets; this enables the uncertainty associated with these concepts to be directly modelled. After defining each model variable with a series of overlapping Fuzzy sets, the mapping of inputs to outputs can be expressed as a set of IF-THEN rules, which can be specified entirely from expert knowledge or from data [
45]. However, unlike NNs, Fuzzy models are prone to a rule explosion; that is, as the number of variables or Fuzzy sets per variable increases, there is an exponential increase in the number of rules [
46].
The main aim of this study is to develop a sustainable and predictive method for assessing the CS of RCDWAC using a hybridised and self-tuned model. To the authors’ knowledge, a hybridised Fuzzy GMDH coupled with HOA has not previously been developed and applied in modelling sustainable technology. During the calibration stage, the trial-and-error procedure for the hyperparameter setting for each model prevented ANFIS and GMDH models from performing satisfactorily for CS prediction. To overcome this shortcoming, HOA, a new metaheuristic method, is applied to explore for appropriate values of the user-defined parameters of the proposed model. HOA is a low-cost algorithm with a high degree of convergence that was first introduced in 2021 [
47]. Then, the hybrid Fuzzy GMDH-HOA results are compared to those extracted from ELM, ANFIS, GMDH, and empirical equations by [
42,
48,
49]. In this research, sensitivity analysis and parametric study were conducted to investigate and determine the most effective input variables (RCDWAC mix properties) and the influence of RCDWA on CS.
The remaining sections of the paper are as follows:
Section 2 proposes a theoretical framework, existing models, an RCDWAC dataset, and a statistical description of used data;
Section 3 describes the AI development and evaluation of proposed approaches for CS of RCDWAC; and
Section 4 concludes with a conclusion, research highlights, and limitations.
3. Methodology
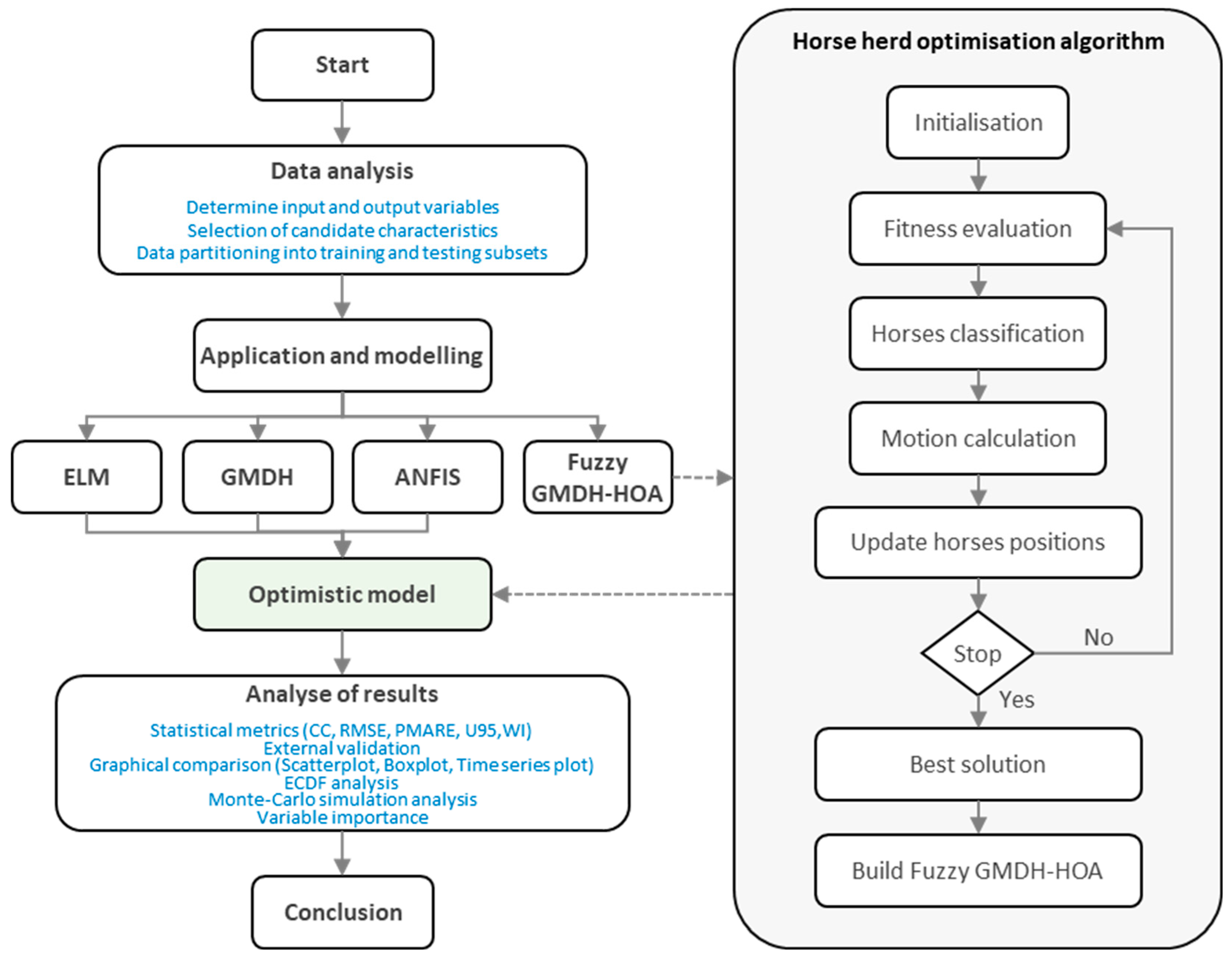
Several AI models, including GMDH, ANFIS, ELM, and hybridised Fuzzy GMDH-HOA, are used in the current study to model the CS of concrete made with recycled wastes from the demolition of structures. In this subsection, the context of the discussed models is presented. In addition,
Figure 3 explains the workflow corresponding to the introduced models in this study.
3.1. Extreme Learning Machine (ELM)
Huang et al. [
68] developed the ELM algorithm for determining the weight of a hidden neuron. It substantially reduces the required calculation time for training and selecting the model structure for large numbers. In addition, its implementation is relatively straightforward [
69,
70,
71]. With a network containing c outputs, hidden neurons and p input units, the
i-th output at time step zero is calculated as follows:
In the above equation
denotes the weight vector and relates the hidden neurons to the
output neuron.
denotes the hidden neuron output of an input pattern
in the data set
. Vector
h(
t) is expressed as:
Here,
bl denotes the bias of the l-th hidden neuron,
denotes the weight vector of the l-th hidden neuron; finally,
represents a sigmoidal activation distribution. The weight vectors (wl) are now randomly derived from a normal or uniform distribution. In addition,
is a
matrix. In this matrix, the t-th column represents the hidden-layer vector
. In a similar way,
denotes a
matrix in which the t-th column is the target or desired vector
which is related to the input pattern
. Ultimately
is a
matrix. The i-th column of this matrix is the weight vector,
. These three matrices are associated with each other through linear mapping.
Based on the available data,
D and
H are known matrices, whereas
M is unknown, but can be calculated using the Moore–Penrose pseudo-inverse method.
If we assume that the number of output neurons equals the number of classes, we can calculate the class index
i* for a new input pattern using the following formula:
where Equation (5) is used for the calculation of
.
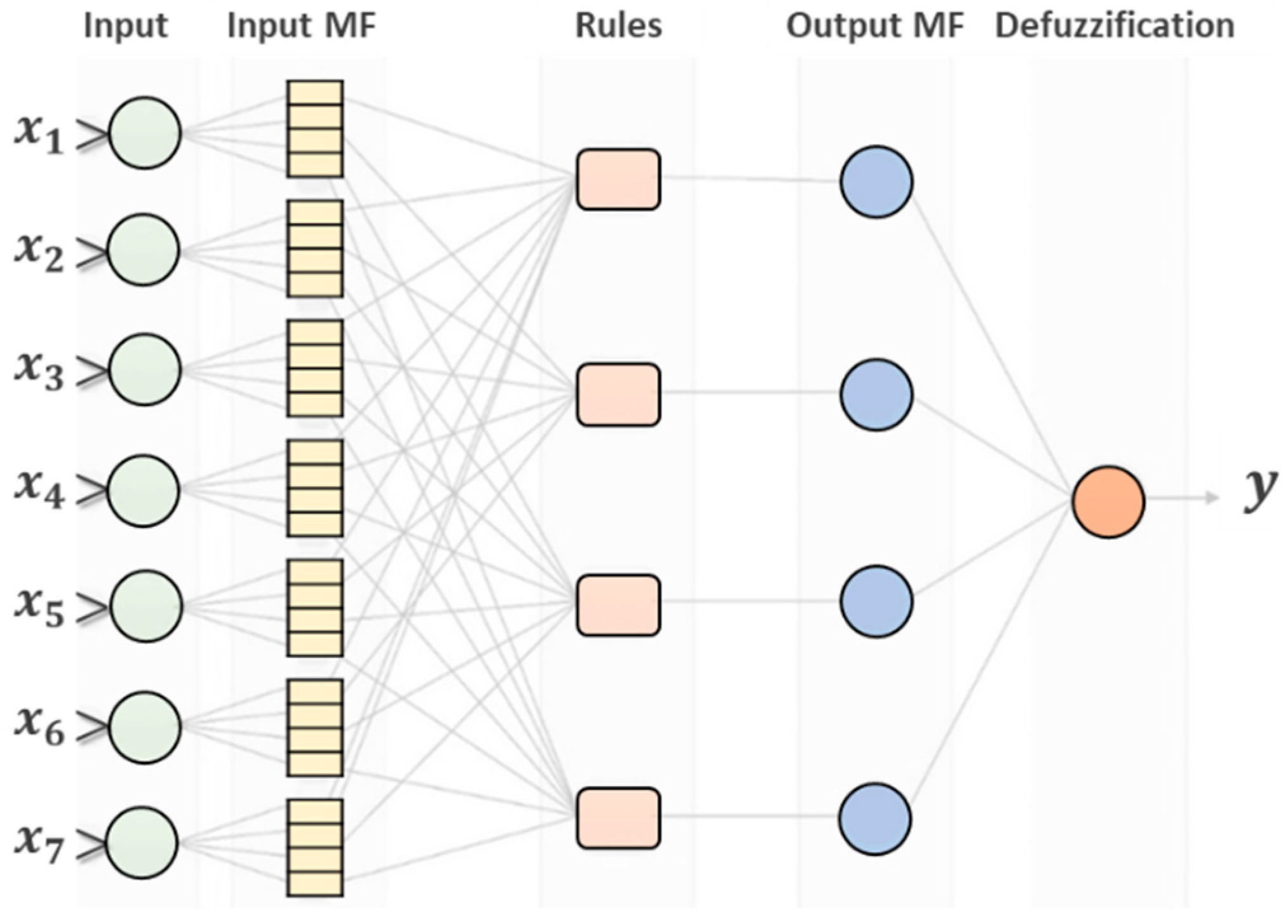
3.2. Adaptive Neuro-Fuzzy Inference System (ANFIS)
ANFIS is a type of ANN that combines neural networks and Fuzzy logic [
72]. Jang [
73] developed ANFIS in 1993 to model nonlinear functions, forecast chaotic time series, and identify nonlinear components. Using the Takagi–Sugeno inference system (expressed as Fuzzy If-Then rules) [
74], ANFIS could be used to construct an input–output mapping. Numerous benefits of ANFIS, including the ability to catch the nonlinear structure of a procedure, accelerated learning, and adaptability, have led to its widespread use among engineers [
75]. The core of ANFIS is the FIS (Fuzzy Inference System). In the initial layer, inputs are received and converted to Fuzzy values using MFs (Membership Functions). The rule base consists of two Fuzzy IF-Then rules of the Takagi and Sugeno varieties:
.
Each node on the first layer is selected as an adaptive node with a function.
In the preceding expression,
represents the membership function of the linguistic label
Ai. Gaussian functions (also known as bell-shaped functions) are frequently used in ANFIS due to their greater capacity in nonlinear data regression [
75]. The following defines a bell-shaped function with a minimum value of zero and a maximum value of one:
In the expression above,
x represents the input and {
} represent the set parameters. The incoming signals are multiplied in the second layer, and the resulting product is transmitted to the third layer. The third layer, the rule layer, computes the ratio of the
i-th node’s firing strength to that of the other nodes. The fourth layer is the defuzzification layer, where each node has a node function. The fifth output layer is responsible for calculating the total output, which is the sum of all incoming signals. The current procedure selects a threshold value between the actual and output values. The subsequent parameters are then calculated using the least-squares method, which produces an error for each calculated value. If the obtained value exceeds the threshold value, a gradient descent algorithm [
76,
77] is used to update the assumed parameters. The procedure is repeated until the error value falls below the threshold value. This method’s parameters are simultaneously calculated and controlled utilising the least-square and gradient descent algorithms.
3.3. Group Method of Data Handling (GMDH)
A self-organising algorithm was initially developed by Ivahnenko. Typically, it is based on self-organising systems [
78]. The model can generate quadratic polynomials in any neuron called Partial Descriptions (PDs) to select neurons with the best fit values, as well as generate error criteria to terminate the training phase and form a tree-like structure to solve highly complex problems [
79,
80]. A function of
can be substituted for the actual function f in order to predict the final output of a complex system,
, for given model input,
, so that it is as close as possible to its actual output, y. Consequently, for given n observations of multi-variable data, the output variable is represented as follows:
In the current status, the model of GMDH can be well-constructed to predict the final values of output,
, in the case of each given input vector
. A relationship between the final output and the inputs can be defined using the following function:
Based on the measured (observed) values and predicted model outputs, the following equation represents the error values:
According to the GMDH model, dependent and independent parameters are related as follows:
In addition, Equation (5) is suggested as the Kolmogorov–Gabor polynomial [
78]. A quadratic polynomial has a lower error rate than other types of polynomials, and its weighting coefficients are calculated by least squares. For each pair of input variables
and
, the error between the actual value and predicted model output y should be minimised. Additionally, this error function can determine the performance of a quadratic polynomial,
, using the least-square method to optimally remove a specified number of neurons (nodes) from each layer, as shown below:
When building the regression quadratic polynomial in GMDH, all possible independent variables (or inputs) are considered out of n input variables [
80]. Weighting coefficients were derived using the least squares method in this case. The number of nodes in each layer can be calculated as follows:
where
stands for the input numbers of the former layer. However, the partial descriptions will be produced in the initial layer from observations
for different pairs of
. In other words,
triples
could be formed as inputs–output systems from n observations using
, expressed as follows [
75,
76,
77]:
Considering coefficients of the weighting of the quadratic polynomial
, a mathematical matrix equation AW = Y, and the vector of output
, the final matrix created by combining two inputs can be determined as follows:
The coefficients vector of can be calculated using the least-squares approach.
3.4. Horse Herd Optimisation Algorithm (HOA)
Metaheuristic algorithms have been developed and used for a wide range of complex engineering problems in recent years [
81,
82,
83,
84,
85,
86]. Developed by [
47], HOA is based on the horses’ observed behaviour patterns in their environment. The six most important behavioural patterns of horses are hierarchy, sociability, grazing, imitation, defence mechanism, and roaming, and the HOA is based on these behaviours. The movement applied to the horses during each iteration (Equation (19)) is as follows:
In the above equation,
denotes the m-th horse position, Iter denotes the current iteration, and AGE represents the range of age for the considered horse and
represents the velocity vector of the considered horse. Each horse has a maximum life of 25–30 years, so it could exhibit various behaviours during its lifetime [
47]. Thus,
represents a life range of 0–5 years,
represents a life range of 5–10 years, and
represents horses that are older than 15 years. A comprehensive and large response matrix is executed per iteration to determine the horses’ ages. In this respect, the matrix is sorted in terms of best responses. From the sorted matrix, the first 10% of horses are selected, representing the
horses. Consequently, the following 20% fall in the
group. Additionally, the remaining 30% and 40% of horses belong to
and
horses, respectively. The motion vectors of horses per different ages and at each cycle of the algorithm could be written as follows based on the above-mentioned horse behaviours (Equation (19))
Using Equations (21) and (22) to explain how the global matrix is derived, positions (
X) are juxtaposed with the cost of each position (
C(
X)).
As shown in the preceding equations, x represents the position and c(x) represents the cost of each position. Moreover, m and d represent the number of horses and the dimensions of the problem. Next, we would store the global matrix according to the last column, which represents costs. The age of the horse is entered here.
In situations where an optimal solution has a high probability, high accuracy and low speed are advantages, and low accuracy and high speed are advantages in situations where an optimal solution has a low probability. The general velocity vector is computed in the following way:
The velocity of
horses in the range of 0–5 years:
The velocity of
horses at the age of 5–10 years:
horses aged 10–15 years have the following velocity:
horses older than 15 years have the following velocity:
3.5. Development of an Adaptive Fuzzy GMDH Using HOA
Ivakhnenko introduced the GMDH neural network, which belongs to the category of self-organising models, in the 19th century. This procedure contains a number of significant operations. The introduction of a combination of input parameters based on the complex theorem of Ivakhnenko to generate partial descriptions (PDs) is one of the operations (i.e., polynomial neurons). The other operation takes into account the error criterion when selecting the seeds (perfectly working polynomial neurons) for each layer’s filtering process. In this study, the optimal structure of a Fuzzy GMDH model was optimised using evolutionary computing techniques and a parallel evaluation mechanism for the target variable. As a benefit, Hwang has utilised the Fuzzy GMDH as a conjunction model by employing various iterative algorithms or evolutionary techniques [
87].
Studies available show that a typical Gaussian membership function
can be used to construct neural-Fuzzy systems, as this type of MF can produce more precise results for Fuzzy GMDH systems. It could be used as the number (
k) of Fuzzy rules that are applied to the boundary of the jth input vector (
) as follows:
In the above equation,
and
denote constant coefficients that are applied in the Gaussian membership function known as the Fuzzy rule. Furthermore, y, which denotes the output vector, is derived as the output of a neural-Fuzzy system using the following equation:
In the above equation
.
denotes the real value of the kth Fuzzy rules [
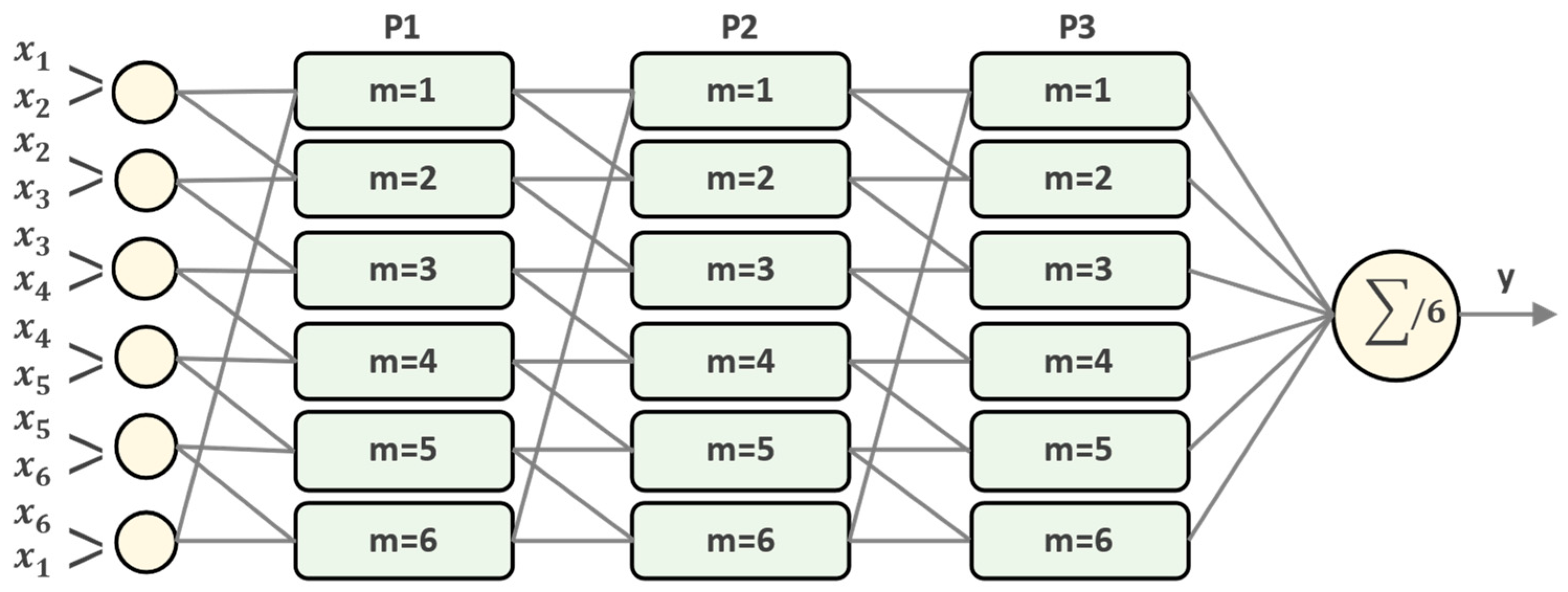
87]. According to the Fuzzy GMDH model, each neuron (partial description) possesses two inputs but one output. As shown in
Figure 4, the output vector of each PD in the current layer is the input vector of the following layer. The ultimate output of the Fuzzy GMDH method is determined by averaging the outputs corresponding to the last layer. Therefore, the inputs from the
neuron and
th layer are taken as the output variables or vectors corresponding to the
th and
th PDs (or neurons) in the
layer. Thus, these output vectors are used to generate the input vector (or neuron) in the
th PD (or neuron) and
th layer. The relationship in mathematical form between
,
, and
is demonstrated by:
in the above equation is a mathematical description used for calculating the kth Gaussian function. The following equation ultimately determines the Fuzzy GMDH network output:
It should be noted that all the Gaussian functions and weighted coefficients are determined by the trial-and-error method.
Regarding the Fuzzy hybrid GMDH, the backpropagation algorithm must be used to tune all the involved parameters in the PDs and Fuzzy MFs. The problem with this algorithm is that it is unable to determine which PD or link should be eliminated, meaning that the network may contain unnecessary PDs or links. The complex topology of the Fuzzy GMDH model necessitates an efficient algorithm for optimising and tuning Fuzzy MF parameters as well as determining optimal weighting coefficients for PDs in the GMDH algorithm. In this regard, our study employs the HOA algorithm, which has several benefits in exploring and locating the best available solution for highly complex problems [
47]. The mentioned algorithm could be used concurrently for network parameter training and structural identification. The HOA algorithm has a number of variables that can be altered to achieve the optimal objective function solution with minimal error. The following function is assumed as the objective function of the optimisation operation in the Fuzzy GMDH based on HOA:
The percentage of the best and worst horses, denoted by pN and qN, respectively. RF (reduction factor), behaviour coefficients for each horse’s age range (
), number of agents, and maximum number of iterations. Once the process of optimisation is complete, the weighting coefficients are determined. Using the HOA-based Fuzzy GMDH, the Gaussian functions are then derived. In this study, the number of variables and maximum iteration number in the HOA were set to 6 and 150, respectively. In addition, other parameters of the HOA were set similar to [
88].
3.6. Statistical Performance
Several performance measures (Equations (32)–(36)) were used in this study, including Wilmot’s Index of Agreement (
WI), Root Mean Square Error (
RMSE), Correlation Coefficient (
CC), Percent Mean Absolute Relative Error (
PMARE), and 95% uncertainty (
U95).
In the equations mentioned above and , respectively, denote the values of experimental and predicted target variables (for example, CS). Additionally, and represent the mean of experimental and determined target values, respectively. n denotes the total number of the used data. In this study, the RMSE value with the range of (0, +∞) and the optimal value of zero were selected to assess performance. CC measure with the range of (−1 to 1) exhibits the appropriateness of the chosen input variable for determining the target value (with CC ≥ 0.8 being the accepted value), and the PMARE (0, +∞) determines the relative error of measured descriptive and logical behaviours and is based on the relative error. U95 is calculated as the 95% uncertainty band to verify the validity of a model.
4. Application Results and Discussion
The ANFIS, ELM, GMDH, and Fuzzy GMDH-HOA models’ implementation and performance capabilities are examined in this section.
4.1. Implementation of Proposed Models
For the development of the ELM approach, a two-layer architecture was employed. On the basis of prior research [
89], the transfer function values, including the sigmoid function, were used to determine the ELM characteristics. To develop the best model’s architecture, 10–120 hidden neuron nodes were proposed. In addition, the RMSE criterion is applied to 500 iterations of the initialisation process for random parameters of hidden layers for each hidden node.
Table 2 displays the results of the trial-and-error method for determining the optimal number. The 90-neuron ELM model performs best in the learning and validation phases, with less than 6 and 8 % errors, respectively.
In terms of RCDWAC’s standalone ANFIS for CS, the R2019a version of MATLAB software is implemented. In order to create an ANFIS model, an initial Fuzzy inference system must be developed and then trained. The Takagi–Sugeno type’s membership functions (Gaussian MFs) were used for this purpose because they typically produce more robust results [
38]. Second, the default hybrid algorithm of ANFIS was used during the training phase, and the least square algorithm was used to set the member function parameters. The optimal architecture of ANFIS for simulation of CS of RCDWAC was determined through a trial-and-error procedure, as shown in
Table 3 and
Figure 5. The ANFIS predictive model was developed using six predictors and four MFs for each input variable with 100 iterations to estimate the compressive strength of RCDWAC based on this structure.
In this study, based on MATLAB open-source code for GMDH evaluation, randomised data information is separated into a calibration subset and a validation subset in order to present new predictive models of CS of RCDWAC. The calibrating subset is utilised in the method’s learning process. The validating phase is used to determine the predictive technique’s performance capacity. Consequently, the GMDH model was implemented using six quadratic polynomials neurons based on a trial-and-error approach to reduce the measurement of each neuron [
87].
The developed Fuzzy GMDH-HOA is implemented by the metaheuristic optimisation algorithm. The proposed model was included in partial description which is based on Gaussian variables and the Fuzzy rule and weights. The HOA algorithm was performed for optimising crucial parameters in PDs. Operation of the coupling and optimising process of the neuro-Fuzzy approach and HOA is a parallel interaction in each PD (neurons). As mentioned before, the proposed Fuzzy GMDH-HOA model for CS of RCDWAC has six independent predictors. Developed Fuzzy GMDH-HOA was implemented in the architecture of two Fuzzy rules and six weighting coefficients.
4.2. A Comparison of Models
The applicability of the regression-based AI method (e.g., GMDH, ANFIS, ELM, and novel proposed Fuzzy GMDH-HOA) was studied to evaluate the compressive strength of RCDWAC. The performance capability metrics of the developed AI method for the evaluation of concrete behaviour strength are presented in
Table 4.
In this research, based on a 75–25% data dividing feature, the proposed hybridised and self-adaptive Fuzzy GMDH-HOA model (CC = 0.944, RMSE = 4.311 MPa and U95 = 27.103) and (CC = 0.941. RMSE = 4.525 MPa and U95 = 27.189), outperformed the other regression-based AI techniques and experimental equations in both calibrating (train) and validating (test) phases, respectively. For further investigation of the Fuzzy GMDH-HOA model, predictive equations extracted from the aforementioned method attained the lowest value of PMARE (9.551%) and highest value of WI (0.969); it indicated that hybridising of the AI method enhanced the accuracy of calibrating and validating the subset in terms of WI of the GMDH, ANFIS, and ELM by 8.5%, 4.1%, and 5.1%, respectively.
The validation measures through the regression slope (external validation) [
90] for estimation of CS of RCDWAC using the presented models are reported in
Table 5. Based on the table, Fuzzy GMDH-HOA with K
prim of 0.983, n of −0.124, and
of 0.587 satisfies the required conditions with the best validation compared to those yielded by other methods such as GMDH (K
prim = 1.005, n = −0.477), ANFIS (K
prim = 0.958, n = −0.272), and ELM (K
prim = 0.942, n = −0.345) models. Moreover, the values of
for GMDH (
= 0.306), ANFIS (
= 0.407), and ELM (
= 0.382) were lower than the recommended condition (
0.5). Therefore, Fuzzy GMDH-HOA was based on an optimistic CS estimation model, and computational correlations were not randomly determined.
Moreover, in this study,
Table 6 is provided in order to discuss the outcomes of the present study with other ones in terms of four aforementioned factors. It is found that the accuracy of the current model seems to provide accurate and precise results in comparison to the previous studies while the number of sample sizes of the current model is much larger than those in the past, except Yuan et al. [
91] that used 638 datasets for model development. However, it can be seen from the results of Yuan, Tian, Ahmad, Ahmad, Usanova, Mohamed, and Khallaf [
91] that the accuracy of the models compared to the present research decreased significantly by about 15 and 32% in terms of CC and RMSE, respectively. Results from Ahmad et al. [
92] are similar and slightly more accurate than the present study because of two important factors: (1) number of input parameters; and (2) number of datasets. It is proven that in many cases having more input variables can improve the accuracy of the models and increase the complexity of the models. The comparison indicated that the current model with fewer input variables and comprehensive datasets is sufficient for predicting the recycled concrete strength.
In addition, regarding to comparison of the model prediction with empirical dataset, it should be noted that in the first step of model development, the network of each model is trained and constructed, and the network then evaluated using unseen datasets called the testing step as the second step. Therefore, assessing the proposed models in the identified range of the dataset will lead to similar prediction results.
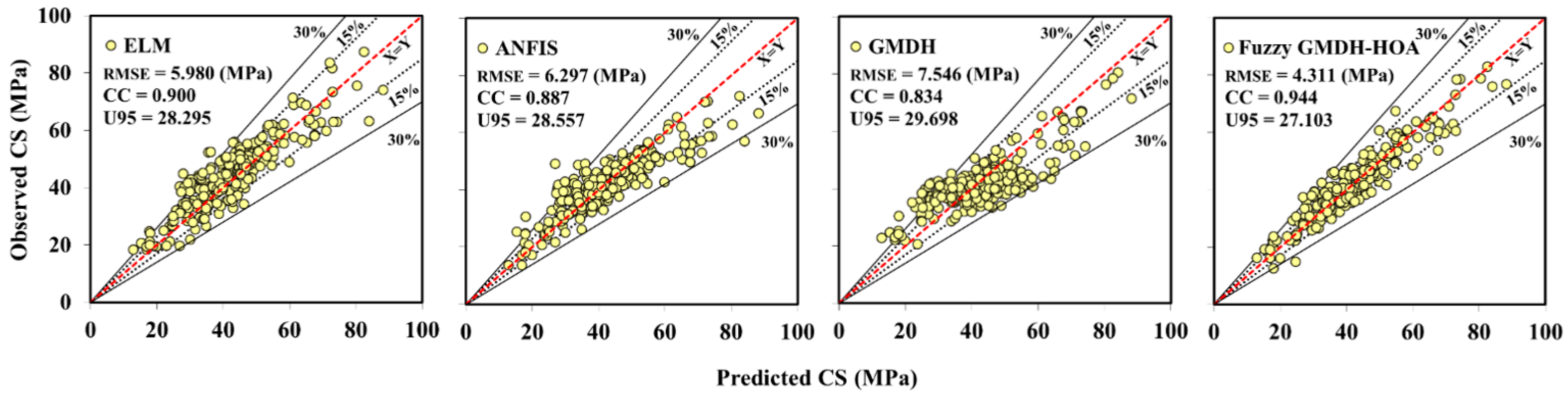
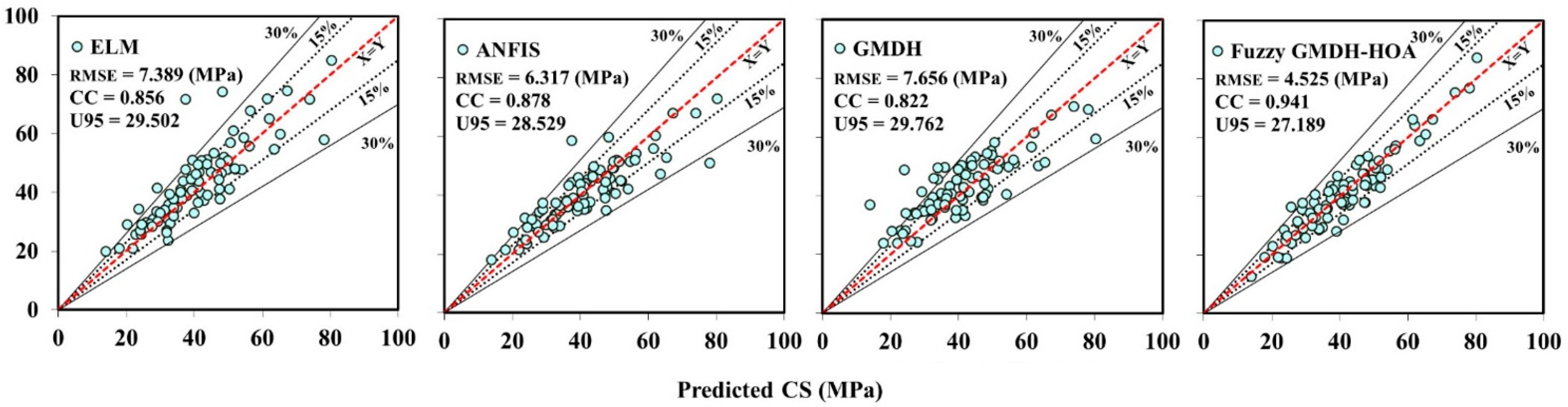
Figure 6 and
Figure 7 display scatterplots for a graphical comparison of AI models based on regression. Fuzzy GMDH-HOA has the highest correlation around the X = Y ideal line during the calibrating and validating phases. In light of these numbers, the CS values calculated using the proposed Fuzzy GMDH and HOA are approximately closest to the perfect line.
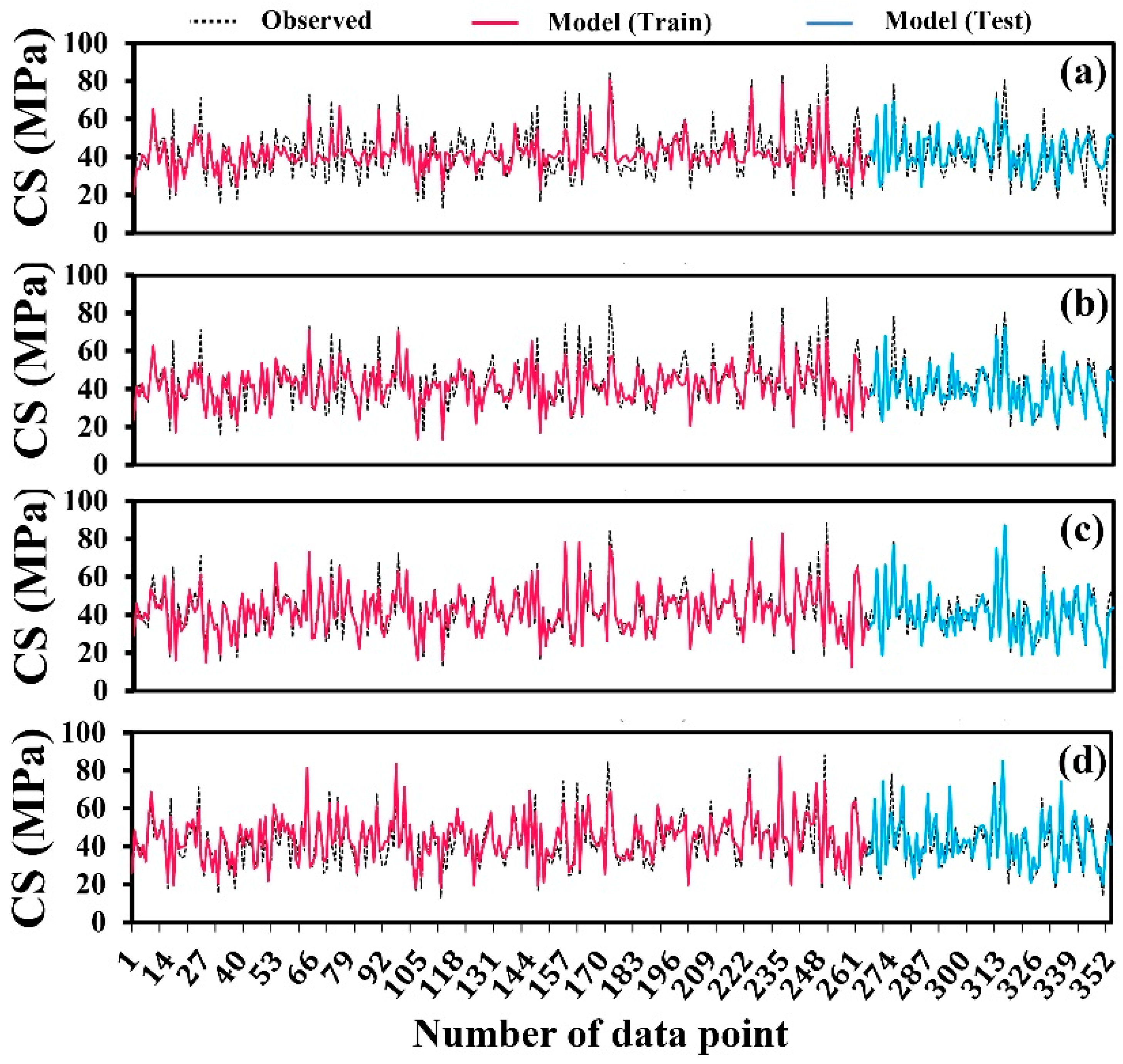
Figure 8 depicts the time series plot for evaluating CS experimental data records (black and dashed line) and proposed data-driven models (coloured and solid line). The Fuzzy GMDH-HOA improved the estimation accuracy of the local maximum (in the range of 50–80 MPa) and minimum values of RCDWAC strengths over other AI tools. A boxplot of the absolute error with quartile values was created for AI analysis (
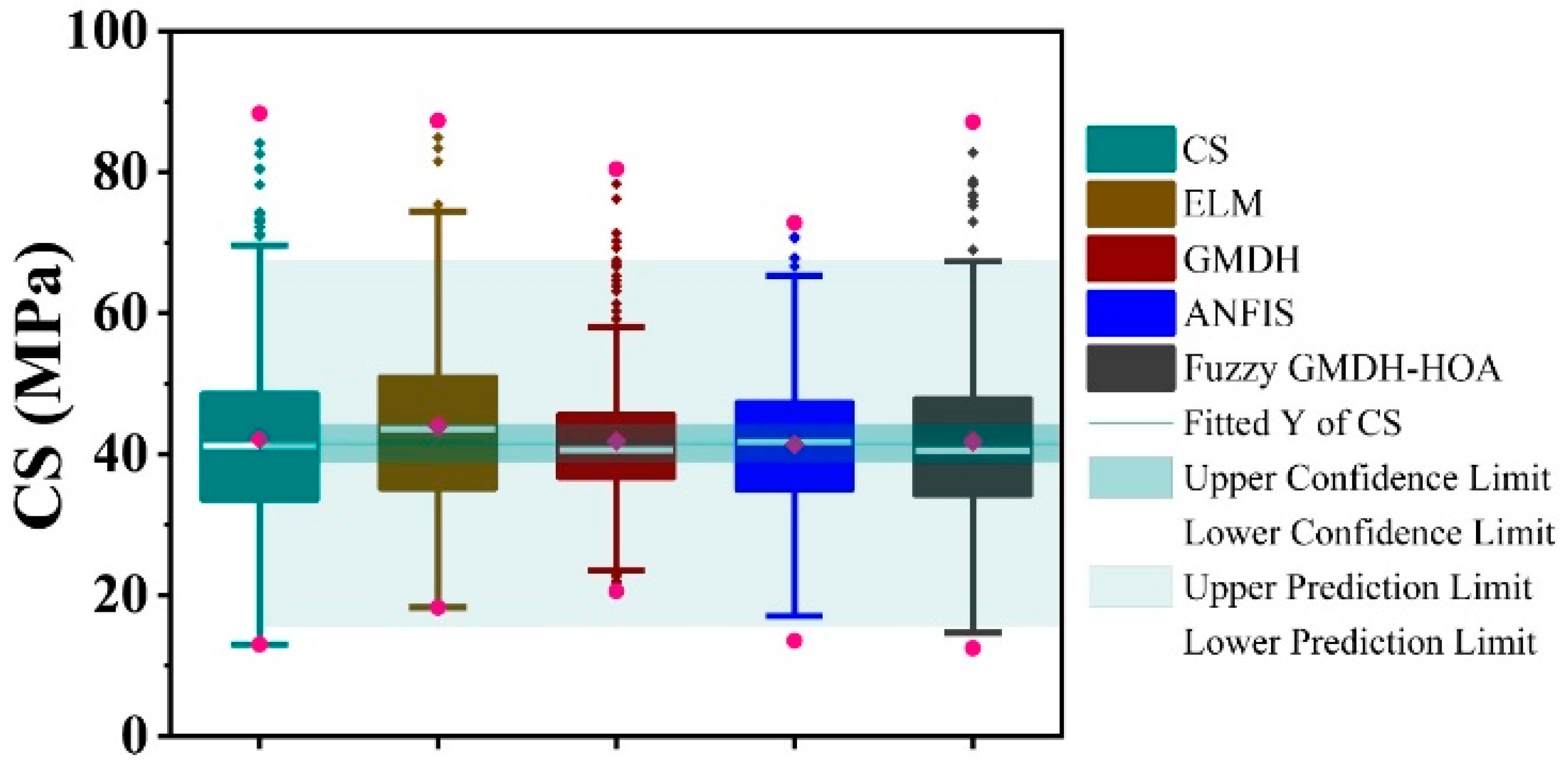
Figure 9). The boxplot’s lower, upper, and middle lines represent the first quartile, third quartile, and median values, respectively. The Fuzzy GMDH-HOA model median and whiskers for simulated and actual CS were nearly identical. The Fuzzy GMDH-HOA model achieved significantly greater statistical precision than the other AI tools.
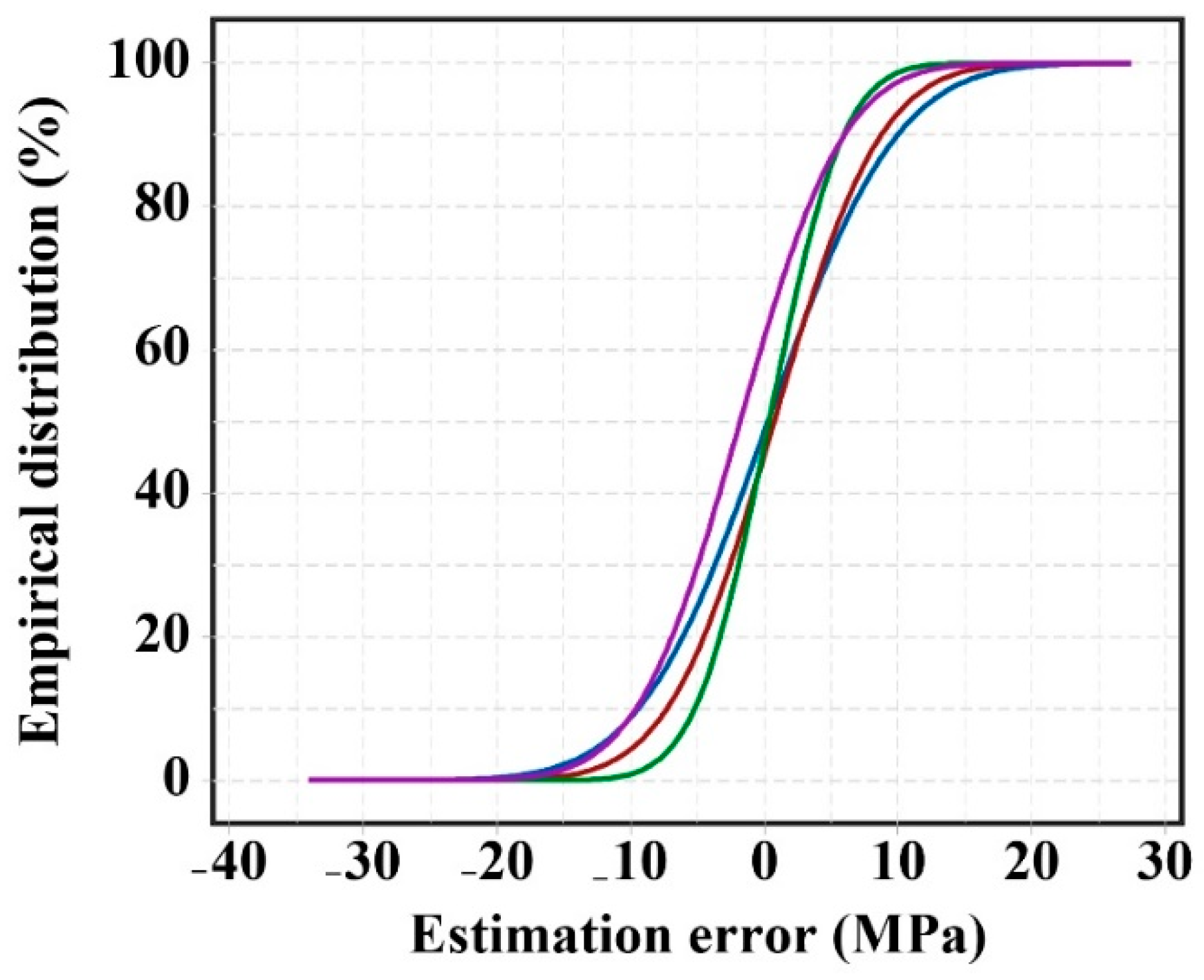
In addition, the Empirical Cumulative Distribution Function (ECDF) analysis was used to measure and investigate the percentage form of the estimated statistical error (|CS|) for the proposed regression-based AI approaches (
Figure 10). Concerning the percentage of errors presented within the estimation error range (i.e., from −34.102 to 27.402 MPa), the ECDF reported the capability of Fuzzy GMDH-HOA for estimating the CS of RCDWAC.
The Monte-Carlo Simulation (MCS) method is used to model uncertainty and specify randomness in a model. Based on probabilistic events, the military was the first to implement MCS [
95,
96,
97]. Predicting the CS involves numerous uncertainties and difficulties, such as the uncertainties associated with input predictors, the uncertainties related to model parameters, etc. The MCS is utilised with forecasting models GMDH, ANFIS, ELM, and GMDH HOA that utilise CS values.
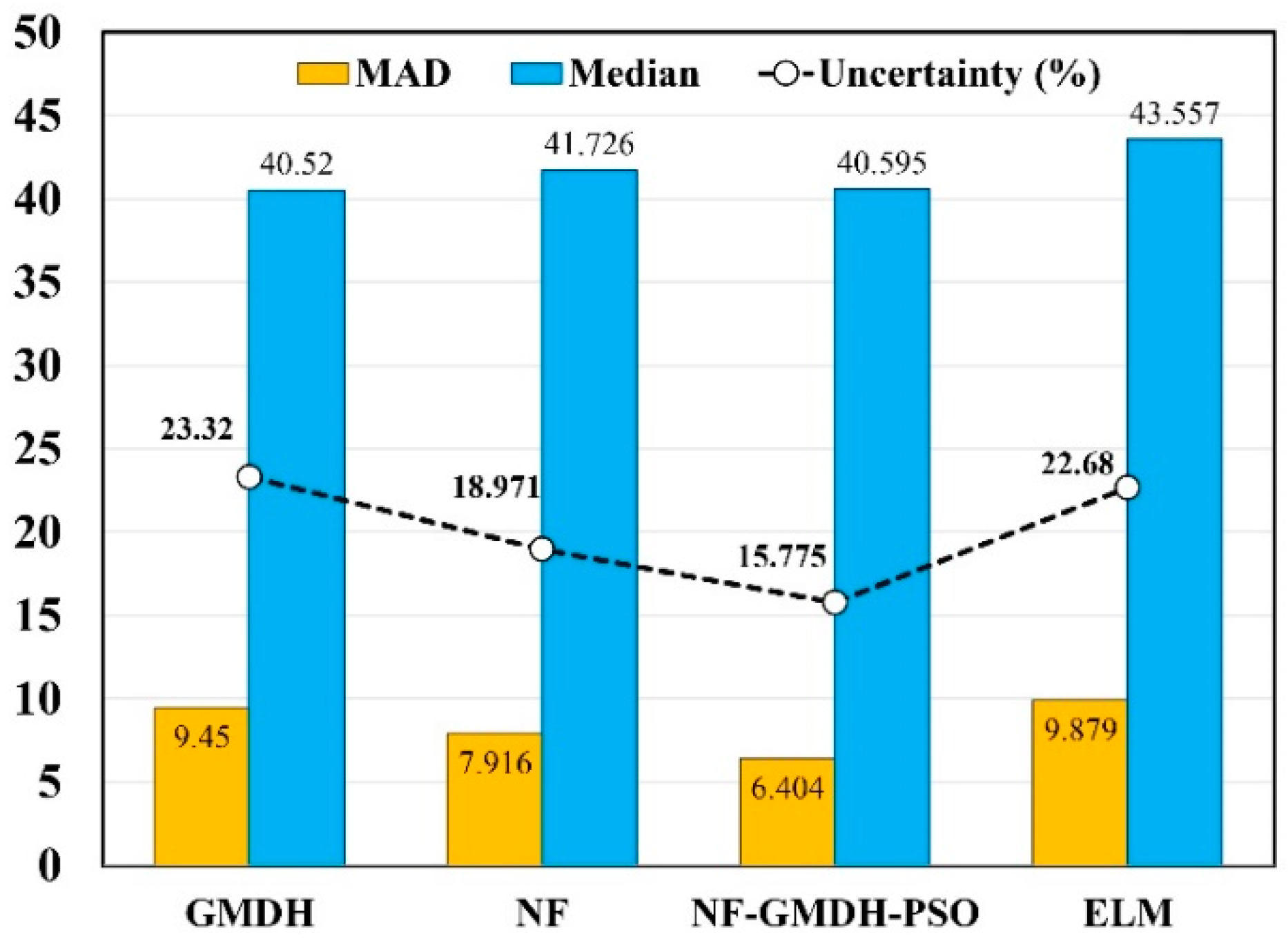
Figure 11 displays the results of this study, including the Mean Absolute Deviation (MAD), median of predicted CS, and uncertainty bandwidth. According to the figure, the positive values obtained for the mean of the estimation error indicating that the estimated CS through the application of the predictive models is greater than those obtained through experimentation. In addition, the lower (15.775 percent) and higher (23.320 percent) uncertainty bands were produced by the Fuzzy GMDH-HOA and GMDH, respectively.
4.3. Variable Importance Analysis
Variable Importance (VA) analysis determines how differences in the values of independent variables affect the dependent variable. The VA percentage is denoted as follows for each model’s inputs [
88]:
where
and
are the maximum and minimum values of the simulated CS over the ith input domain and other predictor values are equal to their mean values. Using the Fuzzy GMDH-HOA model,
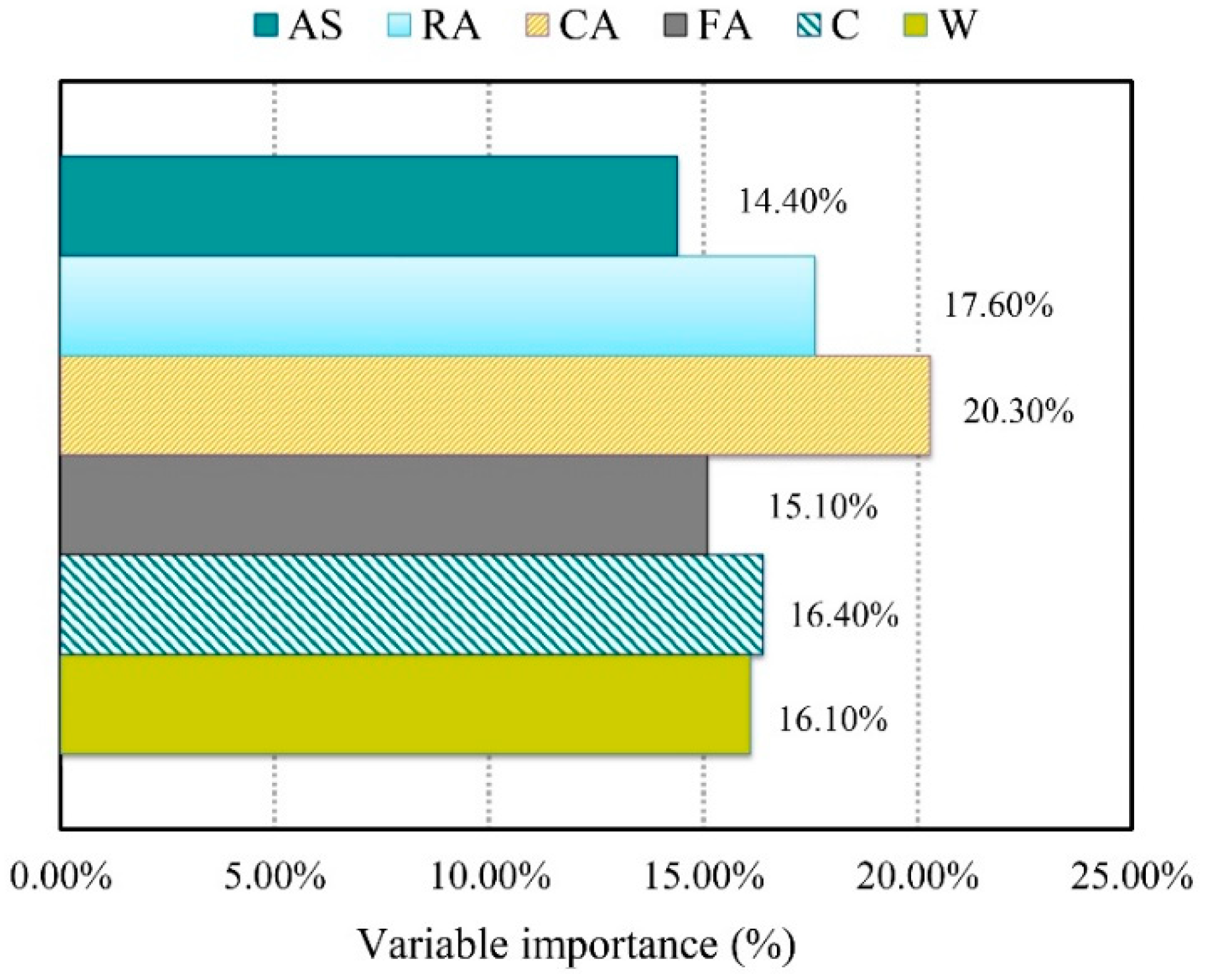
Figure 12 depicts the outcome of VA analysis for RCDWAC CS evaluation based on the Fuzzy GMDH-HOA model (optimistic developed model). This figure indicated that the coarse aggregate (20.03% importance) content is the most influential independent predictor in CS of RCDWAC.
4.4. Parametric Evaluation of RCDWA on CS
A parametric study was applied to evaluate the presented evolutionary Fuzzy GMDH-HOA model based on experimentally effective constituents (e.g., RA, CA, FA, C, W, and AS). The model’s compatibility between estimated values and RCDWAC mixtures was evaluated to determine the quality and validity of the developed Fuzzy-based design model. In this study, only selected input variables are treated as variables at any given time, while other experimental factors are treated as constants based on the mean values of their entire datasets [
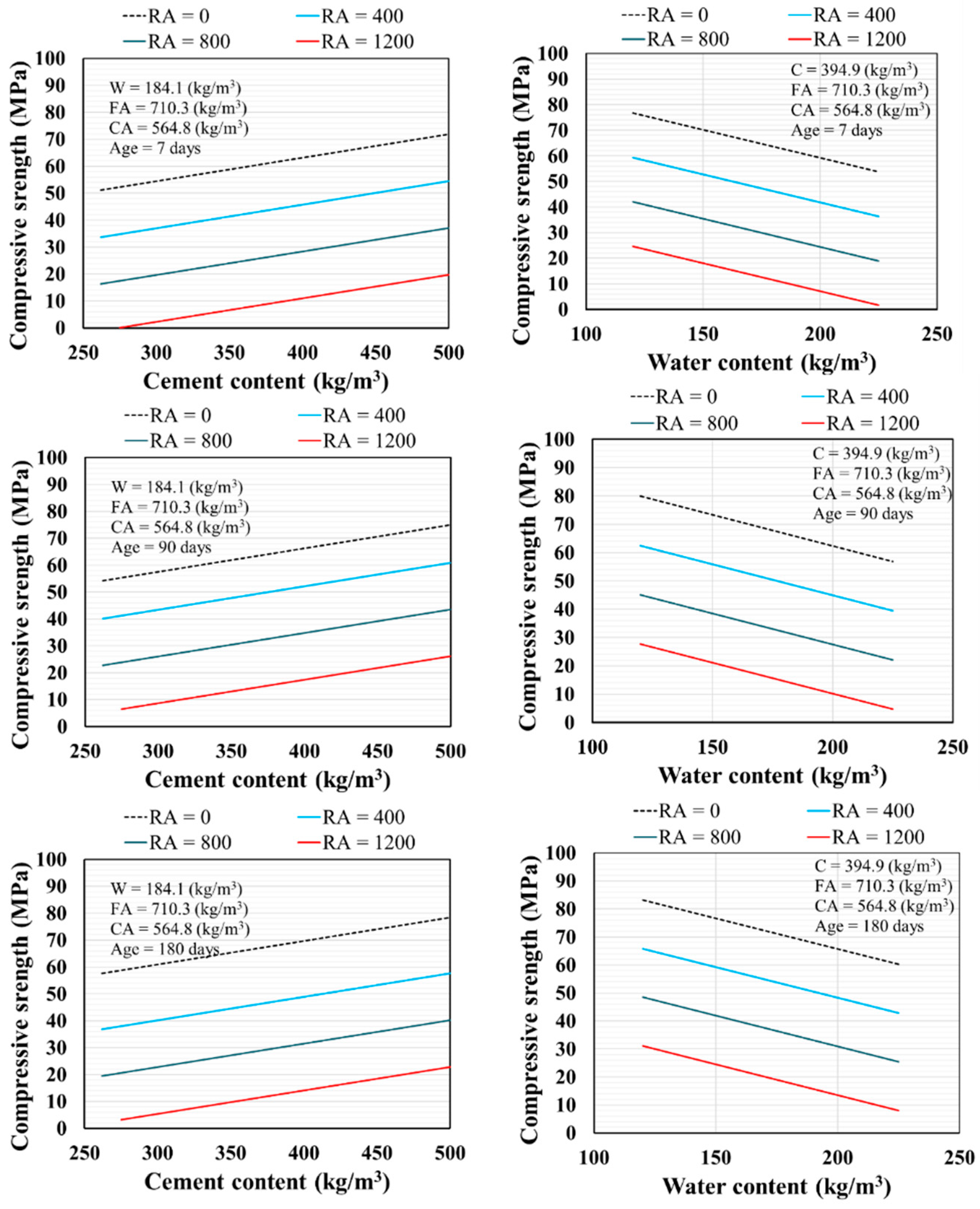
55]. Mechanical properties of RCDWAC mixtures are highly dependent on the mix design and the materials used, and even small changes in the composition of materials can have significant effects. The projects constructed with the optimal content produced a more uniform mixture and, as a result, enhanced mechanical properties. Overall, the model accurately predicts all trends with smooth curves. Specifically,
Figure 13 depicted the expected decrease in CS values with the use of water content in recycled aggregates with long and short curing times (7, 90, and 180 days), as well as the fact that excessive water content in recycled aggregates may cause segregation problems.
5. Summary and Conclusions
Recycled Construction and Demolition Waste Aggregate Concrete (RCDWAC) is an eco-friendly and cost-effective alternative to conventional concrete in the construction industry. This study aimed to implement an eco-friendly solution based on a novel Artificial Intelligence (AI) method in concrete technology for modelling and estimating the Compressive Strength (CS) of RCDWAC using an alternative artificial computing system known as Fuzzy GMDH-HOA. Several AI benchmark methods, such as the supervised learning method (e.g., GMDH), Fuzzy paradigm (e.g., the NeuroFuzzy system), and committee-based model, were compared with the presented model to determine its efficacy and capability (e.g., ELM). In addition, the uncertainty of the presented novel Fuzzy GMDH-HOA model was investigated using the Monte-Carlo simulation framework. For evaluating the predictability of the developed models, statistical indicators including PMARE, CC, U95, RMSE, and WI were utilised. In this regard, the RMSE and PMARE values of the Fuzzy-GMDH-HOA model for CS prediction were decreased to 30.8% and 7.5%, respectively, when compared to the standalone GMDH model. This study’s findings demonstrated the predictive capacity of the proposed Fuzzy GMDH-HOA in developing a reasonable and robust regression-based AI technique for predicting the CS of RCDWAC. On the basis of AI computational operation, modelling error, and visual consideration (e.g., scatterplots, time series plots, boxplot, and ECDF distribution diagram), the proposed model extracted from Fuzzy GMDH can improve accuracy by hybridising the evolutionary HOA algorithm. According to a sensitivity analysis, the coarse aggregate is the most influential independent variable in RCDWAC mix design, accounting for 20.03% of its importance.
Nonetheless, this paper proposed an innovative hybridisation of evolutionary models to evaluate the CS of RCDWAC; future research should address several limitations. As suggested by hybridised computation, Fuzzy GMDH-HOA may be used to simulate the CS of RCDWAC with a high level of estimation capability. One of the disadvantages of the proposed Fuzzy GMDH-HOA is that the technique is time-consuming because tuning parameters are used to achieve optimal conditions. To circumvent these limitations, it was determined that more metaheuristic optimisation algorithms with a high level of convergence should be utilised. More focus should be placed on coupling AI, and the data mining approach (ensemble mechanism, deep learning methods, etc.) could be extended to include the data mining approach. As can be presented from the AI process, the proposed model could predict the CS of RCDWAC in different input types with optimal performance. One of the disadvantages of the proposed hybrid model (e.g., Fuzzy-GMDH-HOA) is that non-equation-based prediction and its implementation is time-consuming because it optimized user manual parameters of the model. Therefore, it was recommended to propose more evolutionary AI approaches for domination of these limitations via high convergence speed algorithms, classifiers, and methods. More focus should be placed on coupling AI, and data mining approaches (ensemble mechanism, deep learning methods, etc.) could be extended to include the data mining approach.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}