

Feasibility of Automated Black Ice Segmentation in Various Climate Conditions Using Deep Learning




Abstract
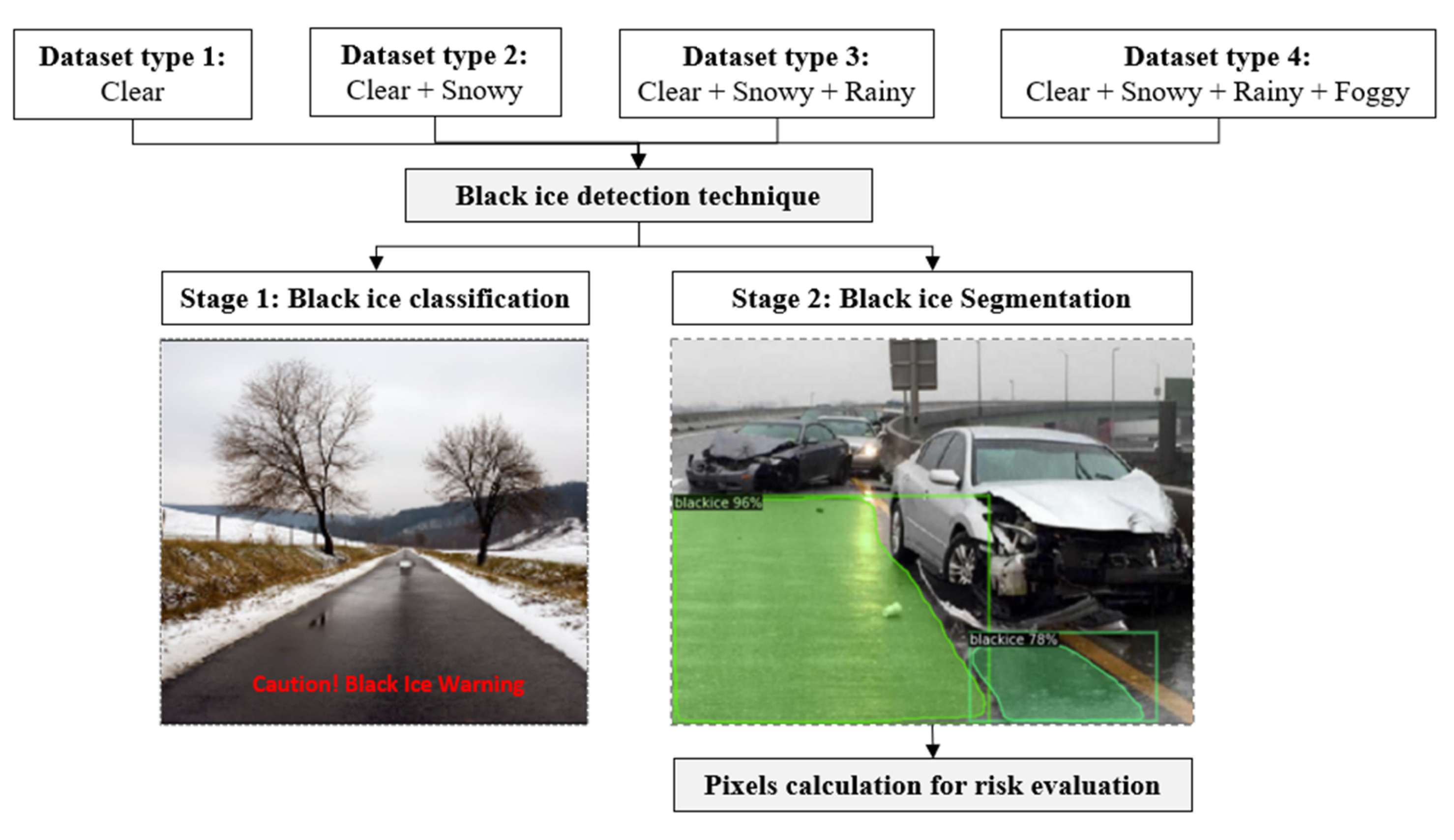
1. Introduction
2. Methodology
2.1. Overview
2.2. Dataset Preparation
2.2.1. Data Collecting and Pre-Processing
2.2.2. Data Labelling
2.2.3. Adjustment of Brightness
2.2.4. Data Augmentation
2.3. Deep Learning-Based Object Detection
2.3.1. Conventional Faster R-CNN
2.3.2. Mask R-CNN
2.3.3. Improved Mask R-CNN
2.3.4. Applications
2.3.5. Hyperparameters
2.4. Comparable Architectures
2.5. Comparative Analysis and Evaluation
Cross-Entropy Loss Function
3. Results and Discussions
3.1. Black Ice Classification
3.2. Black-Ice Segmentations
3.2.1. Overall Results
3.2.2. Effect of Weather on Training Performance
3.2.3. Average Precision Results AP50
3.2.4. Pre-Trained Model Evaluation
3.3. Architecture Comparison
3.4. Risk Assessment
3.5. The Effect of Augmentations
3.6. Potential Applications
4. Conclusions
- Through the image classification and object detection process, the training results suggest that the “Clear Weather” groups achieved the maximum precision, while the “Combined weather” dataset (Clear, Snow, Rainy, Foggy) is considered the most difficult to identify black ice.
- Weather datasets greatly contribute to the training effectiveness of the deep learning model. For example, the precision AP50 values for the first, second, third, and fourth conditions are 92.5%, 83.7%, 75.3%, and 54.6%, respectively. The image segmentation technique for black ice detection may encounter difficulties in various weather conditions due to the identical textures between the black ice pattern (color, brightness, and texture attributes) and frost/wet pavements during rainy and foggy weather. In addition to the climate condition, concrete pavement can cause inaccuracies in detection due to its white color, making it difficult to distinguish from glossy black ice.
- Among all pre-trained models, the best model image segmentation (R101-FPN) was modified to configure hyperparameters, resulting in a maximum precision of 93.7%. All proposed deep learning models encountered overlapped image segmentation issues due to the limitation of the training dataset.
- By retrieving the segmentation zone, the degree of danger area can be determined by calculating the number of pixels, promoting a potential tool for monitoring the risky percentage of traffic users.
- Although the Mask R-CNN may require a longer processing time of 0.83 secs per iteration, this architecture outperforms the other models (Yolov4) in the AP50 scale, which achieved the highest value of 92.5%, suggesting the practical application for black ice warning.
- Overall, this study reveals that black ice detection via deep learning methods is possible and can supplement the safety of driving during winter. The forthcoming study aims to enhance the segmentation measures by incorporating a bigger dataset and hyperspectral photos that offer more details about each pixel. Additionally, visualizations and inputs from LiDAR sensors would be combined to create a completely computerized monitoring process.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Riehm, M.; Gustavsson, T.; Bogren, J.; Jansson, P.E. Ice Formation Detection on Road Surfaces Using Infrared Thermometry. Cold Reg. Sci. Technol. 2012, 83–84, 71–76. [Google Scholar] [CrossRef]
- Abdelaal, A.; Sarayloo, M.; Nims, D.K.; Mohammadian, B.; Heil, J.; Sojoudi, H. A Flexible Surface-Mountable Sensor for Ice Detection and Non-Destructive Measurement of Liquid Water Content in Snow. Cold Reg. Sci. Technol. 2022, 195, 103469. [Google Scholar] [CrossRef]
- Tabatabai, H.; Aljuboori, M. A Novel Concrete-Based Sensor for Detection of Ice and Water on Roads and Bridges. Sensors 2017, 17, 2912. [Google Scholar] [CrossRef]
- Alimasi, N.; Takahashi, S.; Enomoto, H. Development of a Mobile Optical System to Detect Road-Freezing Conditions. Bull. Glaciol. Res. 2012, 30, 41–51. [Google Scholar] [CrossRef]
- Abdalla, Y.E.; Iqbal, M.T.; Shehata, M. Black Ice Detection System Using Kinect. In Proceedings of the 2017 IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE), Windsor, ON, Canada, 30 April–3 May 2017. [Google Scholar] [CrossRef]
- Minullin, R.G.; Mustafin, R.G.; Piskovatskii, Y.V.; Vedernikov, S.G.; Lavrent’Ev, I.S. A Detection Technique for Black Ice and Frost Depositions on Wires of a Power Transmission Line by Location Sounding. Russ. Electr. Eng. 2011, 82, 541–543. [Google Scholar] [CrossRef]
- Gailius, D.; Jacenas, S. Ice Detection on a Road by Analyzing Tire to Road Friction Ultrasonic Noise. Ultragarsas 2007, 62, 17–20. [Google Scholar]
- Ma, X.; Ruan, C. Method for Black Ice Detection on Roads Using Tri-Wavelength Backscattering Measurements. Appl. Opt. 2020, 59, 7242. [Google Scholar] [CrossRef]
- Shen, Y.; Yu, Z.; Li, C.; Zhao, C.; Sun, Z. Automated Detection for Concrete Surface Cracks Based on Deeplabv3+ BDF. Buildings 2023, 13, 118. [Google Scholar] [CrossRef]
- Haruehansapong, K.; Roungprom, W.; Kliangkhlao, M.; Yeranee, K.; Sahoh, B. Deep Learning-Driven Automated Fault Detection and Diagnostics Based on a Contextual Environment: A Case Study of HVAC System. Buildings 2023, 13, 27. [Google Scholar] [CrossRef]
- Dong, C.Z.; Catbas, F.N. A Review of Computer Vision–Based Structural Health Monitoring at Local and Global Levels. Struct. Heal. Monit. 2021, 20, 692–743. [Google Scholar] [CrossRef]
- Spencer, B.F.; Hoskere, V.; Narazaki, Y. Advances in Computer Vision-Based Civil Infrastructure Inspection and Monitoring. Engineering 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Ramanna, S.; Sengoz, C.; Kehler, S.; Pham, D. Near Real-Time Map Building with Multi-Class Image Set Labeling and Classification of Road Conditions Using Convolutional Neural Networks. Appl. Artif. Intell. 2021, 35, 803–833. [Google Scholar] [CrossRef]
- Xie, Q.; Kwon, T.J. Development of a Highly Transferable Urban Winter Road Surface Classification Model: A Deep Learning Approach. Transp. Res. Rec. J. Transp. Res. Board 2022, 2676, 445–459. [Google Scholar] [CrossRef]
- Que, Y.; Dai, Y.; Ji, X.; Kwan Leung, A.; Chen, Z.; Tang, Y.; Jiang, Z. Automatic Classification of Asphalt Pavement Cracks Using a Novel Integrated Generative Adversarial Networks and Improved VGG Model. Eng. Struct. 2023, 277, 115406. [Google Scholar] [CrossRef]
- Tang, Y.; Huang, Z.; Chen, Z.; Chen, M.; Zhou, H.; Zhang, H.; Sun, J. Novel Visual Crack Width Measurement Based on Backbone Double-Scale Features for Improved Detection Automation. Eng. Struct. 2023, 274, 115158. [Google Scholar] [CrossRef]
- Zhang, J.; Qian, S.; Tan, C. Automated Bridge Surface Crack Detection and Segmentation Using Computer Vision-Based Deep Learning Model. Eng. Appl. Artif. Intell. 2022, 115, 105225. [Google Scholar] [CrossRef]
- Pei, L.; Sun, Z.; Xiao, L.; Li, W.; Sun, J.; Zhang, H. Virtual Generation of Pavement Crack Images Based on Improved Deep Convolutional Generative Adversarial Network. Eng. Appl. Artif. Intell. 2021, 104, 104376. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Talip, M.S.A.; Mokhtar, N.; Shoaib, M.A. Crack Segmentation Network Using Additive Attention Gate—CSN-II. Eng. Appl. Artif. Intell. 2022, 114, 105130. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Chaurasia, A.; Qiu, J. YOLO by Ultralytics. Available online: https://docs.ultralytics.com/ (accessed on 5 March 2023).
- Khan, M.N.; Ahmed, M.M. Weather and Surface Condition Detection Based on Road-Side Webcams: Application of Pre-Trained Convolutional Neural Network. Int. J. Transp. Sci. Technol. 2022, 11, 468–483. [Google Scholar] [CrossRef]
- Pham, V.; Pham, C.; Dang, T. Road Damage Detection and Classification with Detectron2 and Faster R-CNN. In Proceedings of the 2020 IEEE International Conference on Big Data, Atlanta, GA, USA, 10–13 December 2020; pp. 5592–5601. [Google Scholar] [CrossRef]
- Singh, J.; Shekhar, S. Road Damage Detection and Classification in Smartphone Captured Images Using Mask R-CNN. arXiv 2018, arXiv:1811.04535. [Google Scholar]
- Chen, J.; Li, A.; Bao, C.; Dai, Y.; Liu, M.; Lin, Z.; Niu, F.; Zhou, T. A Deep Learning Forecasting Method for Frost Heave Deformation of High-Speed Railway Subgrade. Cold Reg. Sci. Technol. 2021, 185, 103265. [Google Scholar] [CrossRef]
- Chen, W.; Luo, Q.; Liu, J.; Wang, T.; Wang, L. Modeling of Frozen Soil-Structure Interface Shear Behavior by Supervised Deep Learning. Cold Reg. Sci. Technol. 2022, 200, 103589. [Google Scholar] [CrossRef]
- Ansari, S.; Rennie, C.D.; Clark, S.P.; Seidou, O. IceMaskNet: River Ice Detection and Characterization Using Deep Learning Algorithms Applied to Aerial Photography. Cold Reg. Sci. Technol. 2021, 189, 103324. [Google Scholar] [CrossRef]
- Patel, T.; Guo, B.H.W.; van der Walt, J.D.; Zou, Y. Effective Motion Sensors and Deep Learning Techniques for Unmanned Ground Vehicle (UGV)-Based Automated Pavement Layer Change Detection in Road Construction. Buildings 2023, 13, 5. [Google Scholar] [CrossRef]
- Chen, C.; Gu, H.; Lian, S.; Zhao, Y.; Xiao, B. Investigation of Edge Computing in Computer Vision-Based Construction Resource Detection. Buildings 2022, 12, 2167. [Google Scholar] [CrossRef]
- Kim, J.; Kim, E.; Kim, D. A Black Ice Detection Method Based on 1-Dimensional CNN Using MmWave Sensor Backscattering. Remote Sens. 2022, 14, 5252. [Google Scholar] [CrossRef]
- Lee, H.; Kang, M.; Song, J.; Hwang, K. The Detection of Black Ice Accidents for Preventative Automated Vehicles Using Convolutional Neural Networks. Electronics 2020, 9, 2178. [Google Scholar] [CrossRef]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lee, S.Y.; Le, T.H.M.; Kim, Y.M. Prediction and Detection of Potholes in Urban Roads: Machine Learning and Deep Learning Based Image Segmentation Approaches. Dev. Built Environ. 2023, 13, 100109. [Google Scholar] [CrossRef]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.-Y.R.G. Detectron2. Available online: https://github.com/facebookresearch/detectron2 (accessed on 5 March 2023).
- Keras, F.C. 2015. Available online: https://Keras.Io. (accessed on 5 March 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-Generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. YOLOv6 v3.0: A Full-Scale Reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In European Conference on Computer Vision; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2014; Volume 8691, pp. 346–361. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-Yolov4: Scaling Cross Stage Partial Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13024–13033. [Google Scholar] [CrossRef]
- Nar, K.; Ocal, O.; Sastry, S.S.; Ramchandran, K. Cross-Entropy Loss and Low-Rank Features Have Responsibility for Adversarial Examples. arXiv 2019, arXiv:1901.08360. [Google Scholar]
- Zhang, Z.; Sabuncu, M.R. Generalized Cross Entropy Loss for Noisy Labels. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Alfarrarjeh, A.; Trivedi, D.; Kim, S.H.; Shahabi, C. A Deep Learning Approach for Road Damage Detection from Smartphone Images. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5201–5204. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pavement Types | Weather Types | Train Data | Validation Data | Test Data | Total |
|---|---|---|---|---|---|
| Asphalt pavement | Clear | 128 | 16 | 16 | 160 |
| Snow | 128 | 16 | 16 | 160 | |
| Rainy | 128 | 16 | 16 | 160 | |
| Foggy | 128 | 16 | 16 | 160 | |
| Concrete pavement | Clear | 128 | 16 | 16 | 160 |
| Total | 640 | 80 | 80 | 800 |
| Model Parameter | Value |
|---|---|
| cfg.SOLVER.BASE_LR (Base learning rate) | 0.00025 |
| cfg.SOLVER.IMS_PER_BATCH (Images per batch) | 4 |
| cfg.SOLVER.GAMMA (Decreases learning rate over time) | 0.05 |
| cfg.SOLVER.MAX_ITER (No. of iterations) | 2000 |
| cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE (No. of regions of interest) | 16 |
| cfg.MODEL.ROI_HEADS.NUM_CLASSES (No. of classes) | 2 |
| cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST (Parameter to balance recall/precision) | 0.5 |
| Model | Width × Height | Momentum | Decay | Learning Rate | Activation |
|---|---|---|---|---|---|
| Yolov4 | 300 × 300 | 0.9 | 0.00005 | 0.0013 | Leaky ReLU |
| Yolov4-Tiny | 300 × 300 | 0.85 | 0.0005 | 0.0025 | Leaky ReLU |
| Yolov4-ResNet50 | 300 × 300 | 0.85 | 0.0005 | 0.0002 | Leaky ReLU |
| No. | Machine Learning Methods | Pavement Types | Precision | |||
|---|---|---|---|---|---|---|
| Weather Data Type | ||||||
| 1st Cond. | 2nd Cond. | 3rd Cond. | 4th Cond. | |||
| Clear | Clear, Snowy | Clear, Snowy, Rainy | Clear, Snowy, Rainy, Foggy | |||
| 1 | Image classification | Asphalt pavement | 95.6% | 93.3% | 82.1% | 63.5% |
| 2 | Image classification | Concrete pavement | 94.2% | 85.4% | 78.8% | 58.1% |
| AP50: The Average Precision at IOU = 0.5 | ||||||
|---|---|---|---|---|---|---|
| No. | Machine Learning Methods | Pavement Types | Combined Weather Data | |||
| 1st Cond. | 2nd Cond. | 3rd Cond. | 4th Cond. | |||
| Clear | Clear, Snowy | Clear, Snowy, Rainy | Clear, Snowy, Rainy, Foggy | |||
| 1 | Image segmentation (R101-FPN Model) | Asphalt pavement | 92.5% | 83.7% | 75.3% | 54.6% |
| 2 | Image segmentation (R101-FPN Model) | Asphalt pavement and Concrete pavement | 89.1% | 80.3% | 72.8% | 48.5% |
| Image Segmentation Model | |||
|---|---|---|---|
| FP50 | R101-FPN | X101-FPN | |
| Required time per iteration (second) | 0.87 | 0.83 | 1.43 |
| Iteration to convergence | 2200 | 1800 | 2700 |
| Image Segmentation Model | ||||
|---|---|---|---|---|
| Mask R-CNN | Yolov4 | Yolov4-Tiny | Yolov4-ResNet50 | |
| Required time per iteration (second) | 0.83 | 0.65 | 0.53 | 0.78 |
| AP50 on clear weather (asphalt pavement) | 92.5% | 81.3% | 73.7% | 84.9% |
| Black Ice Zone [Pixel] | Pavement Background [Pixel] | Black Ice Risk (%) | |
|---|---|---|---|
| Figure 14A | 1,634,750 | 2,053,652 | 79.60 |
| Figure 14B | 758,552 | 1,803,374 | 42.06 |
| Figure 14C | 2,412,763 | 2,697,551 | 89.44 |
| No. | Augmentation Methods | Image Classification | Image Segmentation | ||
|---|---|---|---|---|---|
| X101-FPN | FP50 | R101-FPN | |||
| 1 | Cutoff | 15.6% | 21.2% | 18.7% | 22.6% |
| 2 | Random contrast | 5.6% | 11.3% | 5.1% | 7.3% |
| 3 | Cropping | 9.2% | 18.5% | 16.1% | 16.0% |
| 4 | Flipping | 4.7% | 2.7% | 2.1% | 2.9% |
| 5 | Scaling | 3.1% | 6.4% | 6.1% | 5.4% |
| 6 | Rotating | 2.2% | 5.6% | 4.9% | 5.2% |
| 7 | Padding | 12.8% | 17.5% | 22.0% | 19.3% |
| 8 | Resizing | 14.5% | 6.7% | 5.1% | 5.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.-Y.; Jeon, J.-S.; Le, T.H.M. Feasibility of Automated Black Ice Segmentation in Various Climate Conditions Using Deep Learning. Buildings 2023, 13, 767. https://doi.org/10.3390/buildings13030767
Lee S-Y, Jeon J-S, Le THM. Feasibility of Automated Black Ice Segmentation in Various Climate Conditions Using Deep Learning. Buildings. 2023; 13(3):767. https://doi.org/10.3390/buildings13030767
Chicago/Turabian StyleLee, Sang-Yum, Je-Sung Jeon, and Tri Ho Minh Le. 2023. "Feasibility of Automated Black Ice Segmentation in Various Climate Conditions Using Deep Learning" Buildings 13, no. 3: 767. https://doi.org/10.3390/buildings13030767
APA StyleLee, S.-Y., Jeon, J.-S., & Le, T. H. M. (2023). Feasibility of Automated Black Ice Segmentation in Various Climate Conditions Using Deep Learning. Buildings, 13(3), 767. https://doi.org/10.3390/buildings13030767