
Night Lighting Fault Detection Based on Improved YOLOv5


Abstract
1. Introduction
2. Methods
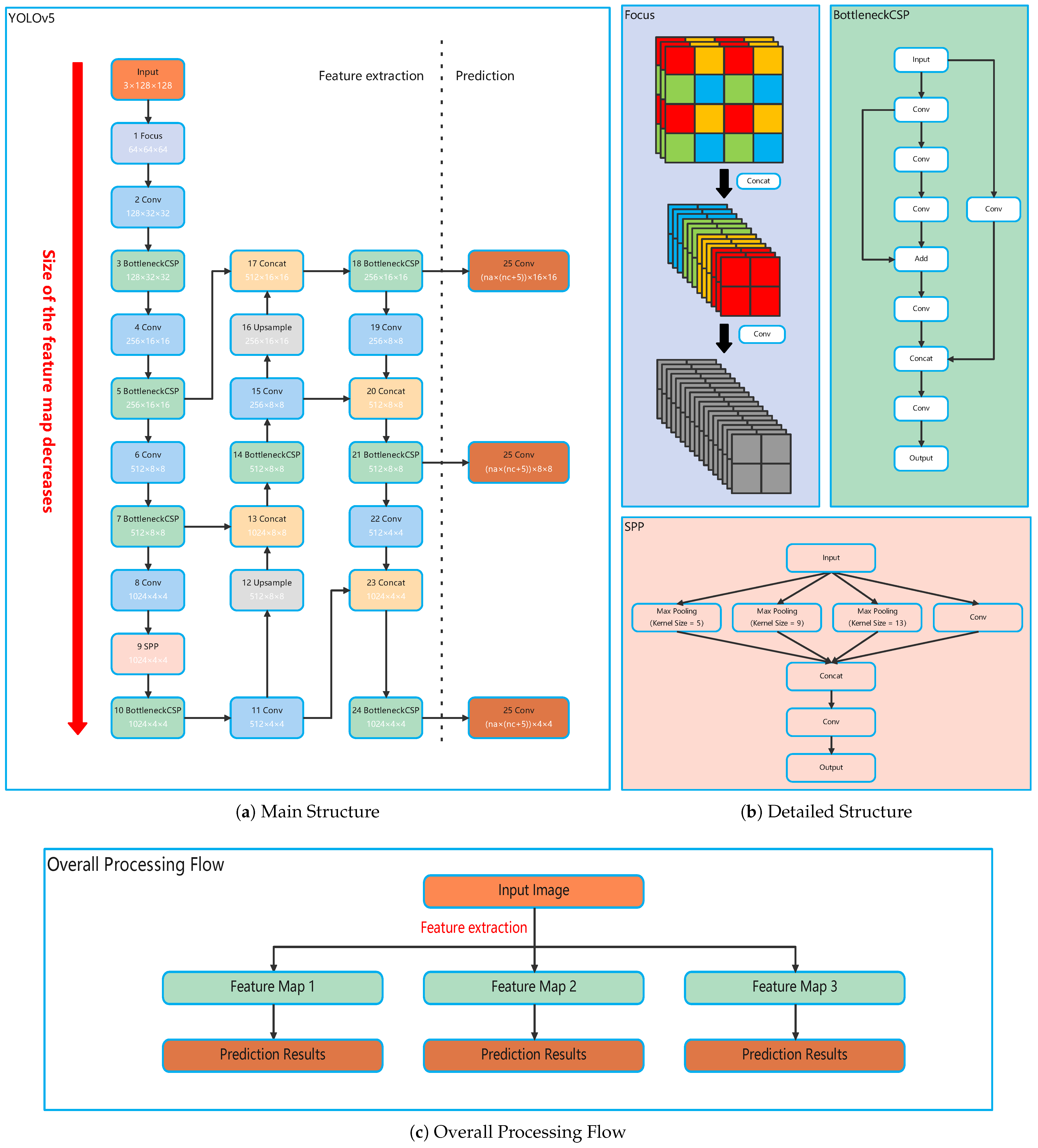
2.1. Network Structure
2.1.1. YOLOv5
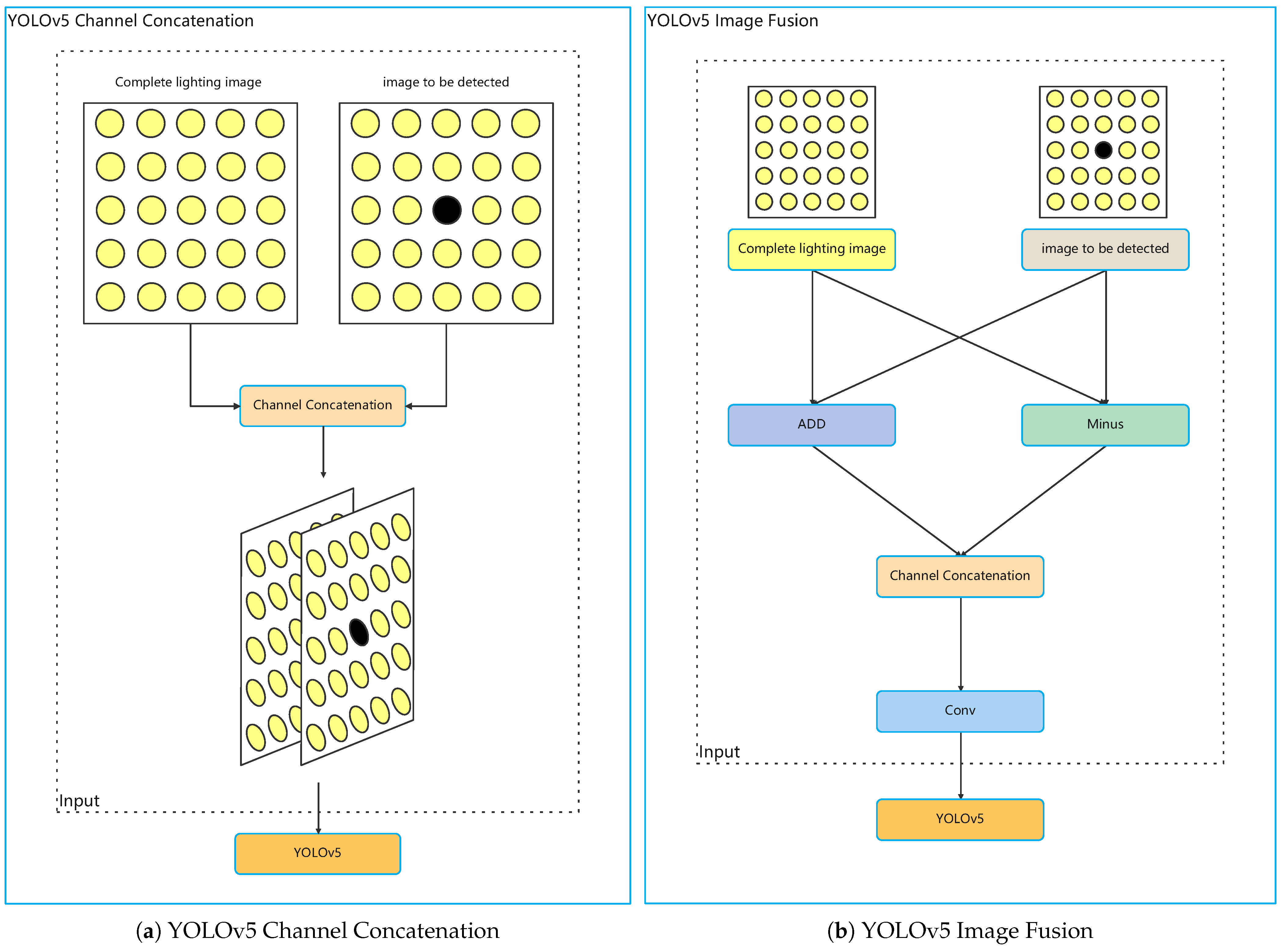
2.1.2. YOLOv5 Channel Concatenation
2.1.3. YOLOv5 Image Fusion
2.2. Automatic Image Collection and Annotation System
- Step 1: The system automatically and randomly generates lighting fault information: the area where the fault occurred.
- Step 2: Based on the lighting fault information, the lighting control system generates actual lighting information, which is output to the lamp panel through the DMX512 protocol. The lamp panel lights up according to the information.
- Step 3: Images are collected and the fault information is saved.
- Step 4: Steps 1 to 3 are repeated until enough images are collected.
3. Experiment Configurations and Results
3.1. Experiment Configurations
3.2. Experiment Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rankel, S. Future lighting and the appearance of cities at night: A case study. Urbani Izziv 2014, 25, 126–141. [Google Scholar] [CrossRef]
- Arora, A.; Goel, V. Real Time Fault Analysis and Acknowledgement System for LED String. In Proceedings of the 2018 International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 28–29 September 2018; pp. 457–461. [Google Scholar] [CrossRef]
- von Staudt, H.M.; Elnawawy, L.T.; Wang, S.; Ping, L.; Choi, J.W. Probeless DfT Scheme for Testing 20k I/Os of an Automotive Micro-LED Headlamp Driver IC. In Proceedings of the 2022 IEEE International Test Conference (ITC), Anaheim, CA, USA, 23–30 September 2022; pp. 365–371. [Google Scholar] [CrossRef]
- Martínez-Pérez, J.R.; Carvajal, M.A.; Santaella, J.J.; López-Ruiz, N.; Escobedo, P.; Martínez-Olmos, A. Advanced Detection of Failed LEDs in a Short Circuit for Automotive Lighting Applications. Sensors 2024, 24, 2802. [Google Scholar] [CrossRef] [PubMed]
- Marzuki, M.Z.A.; Ahmad, A.; Buyamin, S.; Abas, K.H.; Said, S.H.M. Fault monitoring system for traffic light. J. Teknol. 2015, 73, 59–64. [Google Scholar] [CrossRef]
- Nanduri, A.K.; Kotamraju, S.K.; Sravanthi, G.; Sadhu, R.B.; Kumar, K.P. IoT based Automatic Damaged Street Light Fault Detection Management System. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 110853. [Google Scholar] [CrossRef]
- Patel, K.K.; Kar, A.; Jha, S.; Khan, M. Machine vision system: A tool for quality inspection of food and agricultural products. J. Food Sci. Technol. 2012, 49, 123–141. [Google Scholar] [CrossRef]
- Ren, Z.; Fang, F.; Yan, N.; Wu, Y. State of the art in defect detection based on machine vision. Int. J. Precis. Eng. Manuf.-Green Technol. 2022, 9, 661–691. [Google Scholar] [CrossRef]
- Intelligent Defect Inspection Powered by Computer Vision and Deep Learning. 2022. Available online: https://www.infopulse.com/blog/intelligent-defect-inspection-powered-by-computer-vision-and-deep-learning/ (accessed on 30 August 2024).
- Ameliasari, M.; Putrada, A.G.; Pahlevi, R.R. An evaluation of svm in hand gesture detection using imu-based smartwatches for smart lighting control. J. Infotel 2021, 13, 47–53. [Google Scholar] [CrossRef]
- Manakitsa, N.; Maraslidis, G.S.; Moysis, L.; Fragulis, G.F. A Review of Machine Learning and Deep Learning for Object Detection, Semantic Segmentation, and Human Action Recognition in Machine and Robotic Vision. Technologies 2024, 12, 15. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Feng, X.; Jiang, Y.; Yang, X.; Du, M.; Li, X. Computer vision algorithms and hardware implementations: A survey. Integration 2019, 69, 309–320. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Soleimanitaleb, Z.; Keyvanrad, M.A.; Jafari, A. Object Tracking Methods:A Review. In Proceedings of the 2019 9th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 24–25 October 2019; pp. 282–288. [Google Scholar] [CrossRef]
- Hao, S.; Zhou, Y.; Guo, Y. A Brief Survey on Semantic Segmentation with Deep Learning. Neurocomputing 2020, 406, 302–321. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. YOLOv5 by Ultralytics; Zenodo: Geneva, Switzerland, 2022. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Mahaur, B.; Mishra, K.K. Small-object detection based on YOLOv5 in autonomous driving systems. Pattern Recognit. Lett. 2023, 168, 115–122. [Google Scholar] [CrossRef]
- Li, Z.; Tian, X.; Liu, X.; Liu, Y.; Shi, X. A Two-Stage Industrial Defect Detection Framework Based on Improved-YOLOv5 and Optimized-Inception-ResnetV2 Models. Appl. Sci. 2022, 12, 834. [Google Scholar] [CrossRef]
- Xue, Z.; Lin, H.; Wang, F. A Small Target Forest Fire Detection Model Based on YOLOv5 Improvement. Forests 2022, 13, 1332. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, Z. Road damage detection algorithm for improved YOLOv5. Sci. Rep. 2022, 12, 15523. [Google Scholar] [CrossRef] [PubMed]
- Lei, F.; Tang, F.; Li, S. Underwater Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2022, 10, 310. [Google Scholar] [CrossRef]
- Hanif, M.Z.; Saputra, W.A.; Choo, Y.H.; Yunus, A.P. Rupiah Banknotes Detection Comparison of The Faster R-CNN Algorithm and YOLOv5. J. Infotel 2024, 16, 502–517. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Available online: https://github.com/ultralytics/yolov3/issues/898 (accessed on 30 August 2024).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value | Hyperparameter | Value |
|---|---|---|---|
| Training epochs | 200 | Batch size | 16 |
| Input image resolution | 640 × 640 | Optimizer | SGD |
| Optimizer momentum | 0.973 | Optimizer weight decay | 0.0005 |
| Initial learning rate | 0.01 | Final learning rate | 0.002 |
| Single class | True | Warmup epochs | 3 |
| Warmup initial momentum | 0.8 | Warmup initial bias learning rate | 0.1 |
| Model Name | TP | FP | FN | P | R | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|---|---|
| Original YOLOv5 @ Layout 1–6 | 146 | 39 | 7 | 0.789 | 0.954 | 0.937 | 0.856 |
| YOLOv5 Channel Concatenation @ Layout 1–6 | 150 | 27 | 3 | 0.847 | 0.980 | 0.981 | 0.854 |
| YOLOv5 Image Fusion @ Layout 1–6 | 150 | 27 | 3 | 0.847 | 0.980 | 0.985 | 0.865 |
| Original YOLOv5 @ Layout 1–5 | 121 | 15 | 4 | 0.890 | 0.968 | 0.969 | 0.902 |
| YOLOv5 Channel Concatenation @ Layout 1–5 | 123 | 20 | 2 | 0.860 | 0.984 | 0.980 | 0.871 |
| YOLOv5 Image Fusion @ Layout 1–5 | 122 | 19 | 3 | 0.865 | 0.976 | 0.986 | 0.891 |
| Original YOLOv5 @ Layout 6 | 25 | 24 | 3 | 0.510 | 0.893 | 0.681 | 0.576 |
| YOLOv5 Channel Concatenation @ Layout 6 | 27 | 7 | 1 | 0.794 | 0.964 | 0.963 | 0.764 |
| YOLOv5 Image Fusion @ Layout 6 | 28 | 9 | 0 | 0.757 | 1.000 | 0.984 | 0.803 |
| Model Name | P | R | mAP@0.5 |
|---|---|---|---|
| Original YOLOv5 | 0.510 | 0.893 | 0.681 |
| YOLOv5 Channel Concatenation | 0.794 | 0.964 | 0.963 |
| YOLOv5 Image Fusion | 0.757 | 1.000 | 0.984 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Dai, C.; Zhang, W.; Liu, S.; Guo, R. Night Lighting Fault Detection Based on Improved YOLOv5. Buildings 2024, 14, 3051. https://doi.org/10.3390/buildings14103051
Zhang F, Dai C, Zhang W, Liu S, Guo R. Night Lighting Fault Detection Based on Improved YOLOv5. Buildings. 2024; 14(10):3051. https://doi.org/10.3390/buildings14103051
Chicago/Turabian StyleZhang, Feng, Congqi Dai, Wanlu Zhang, Shu Liu, and Ruiqian Guo. 2024. "Night Lighting Fault Detection Based on Improved YOLOv5" Buildings 14, no. 10: 3051. https://doi.org/10.3390/buildings14103051
APA StyleZhang, F., Dai, C., Zhang, W., Liu, S., & Guo, R. (2024). Night Lighting Fault Detection Based on Improved YOLOv5. Buildings, 14(10), 3051. https://doi.org/10.3390/buildings14103051