
Irregular Facades: A Dataset for Semantic Segmentation of the Free Facade of Modern Buildings


Abstract
1. Introduction
2. The Dataset of Irregular Facades (IRFs)
2.1. Overview of the IRFs
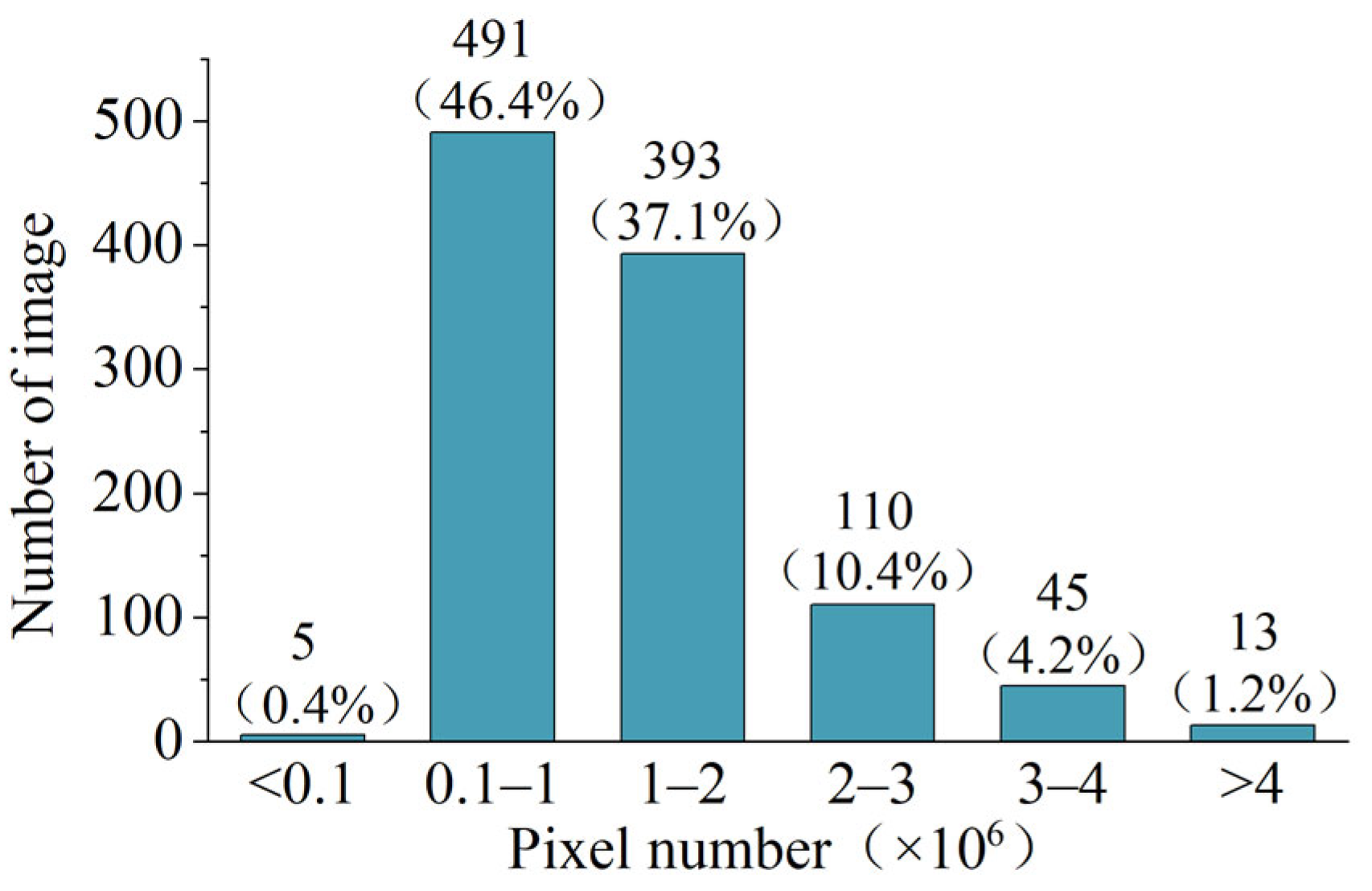
2.1.1. Image Sizes
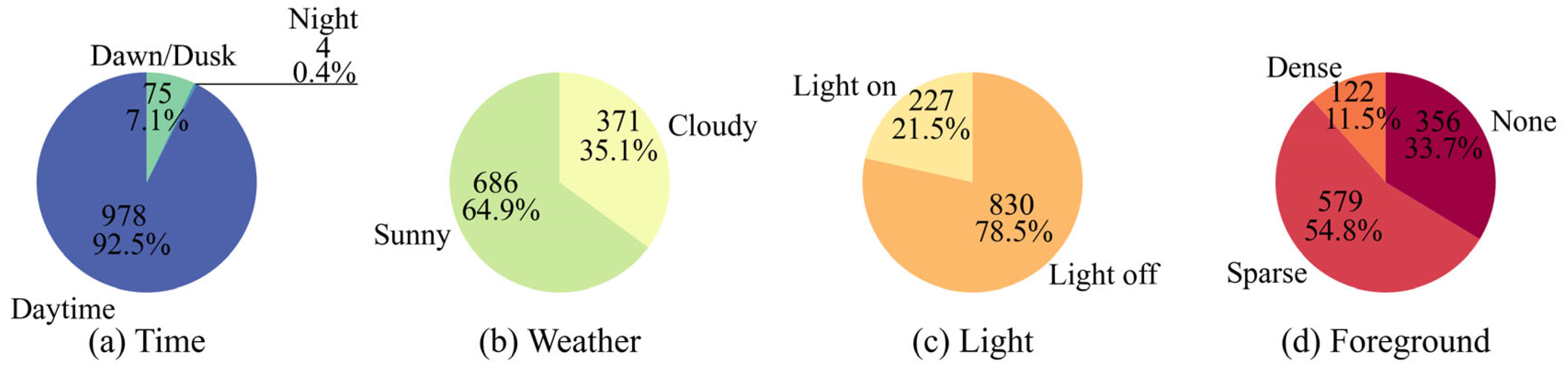
2.1.2. Image Features
2.2. Classes and Annotations
2.2.1. Classes
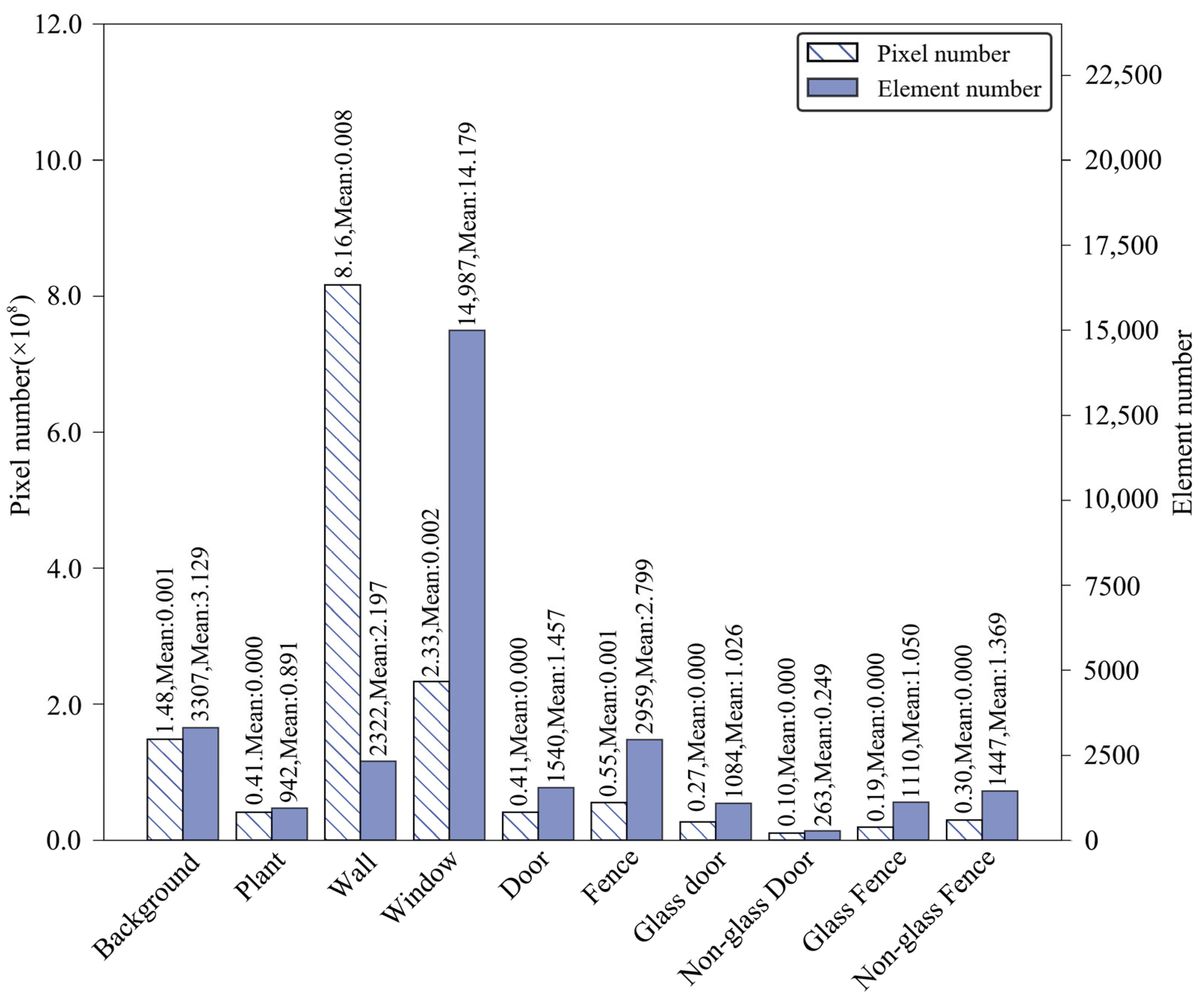
2.2.2. Number of Pixels and Elements
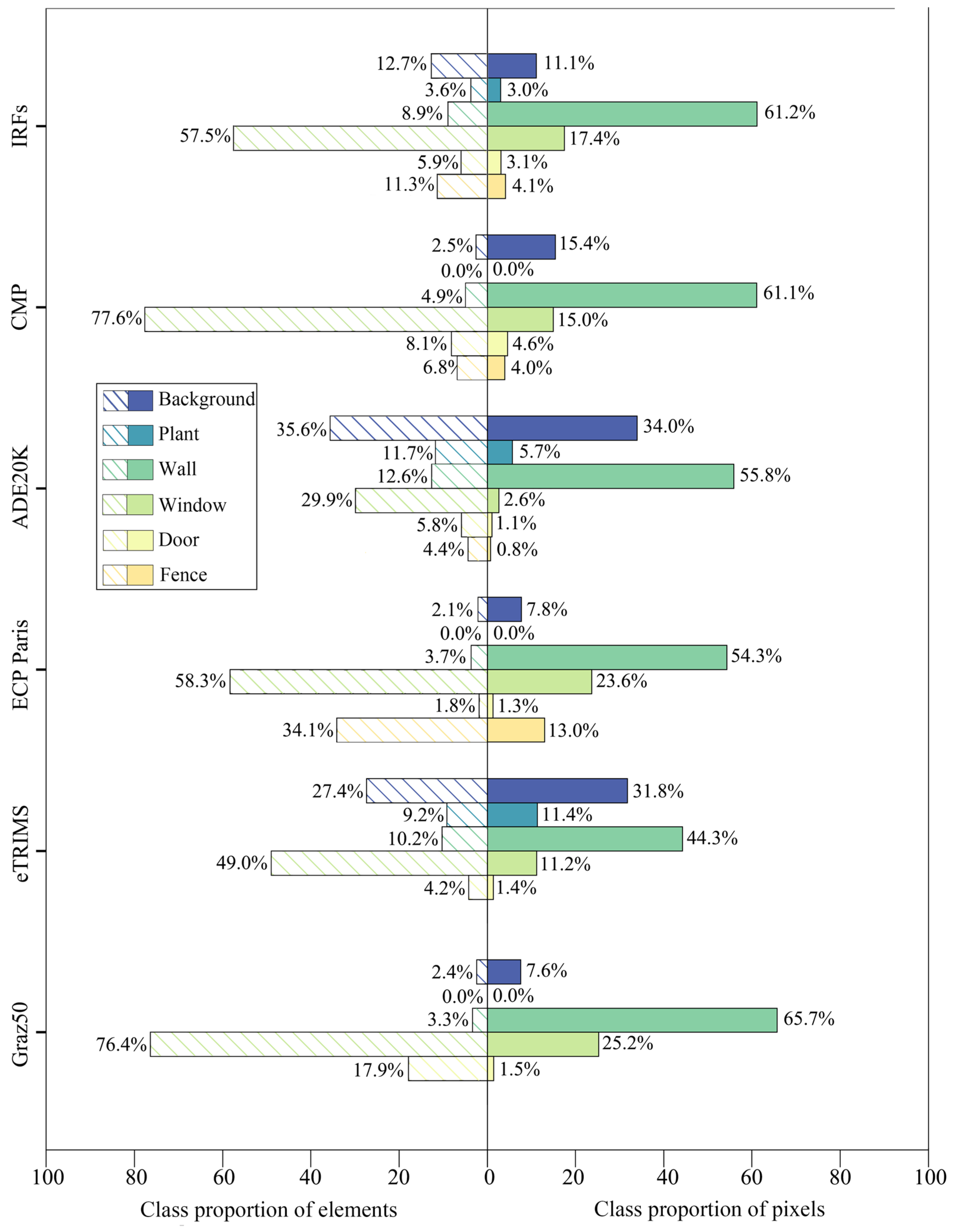
2.3. Comparison to Existing Datasets
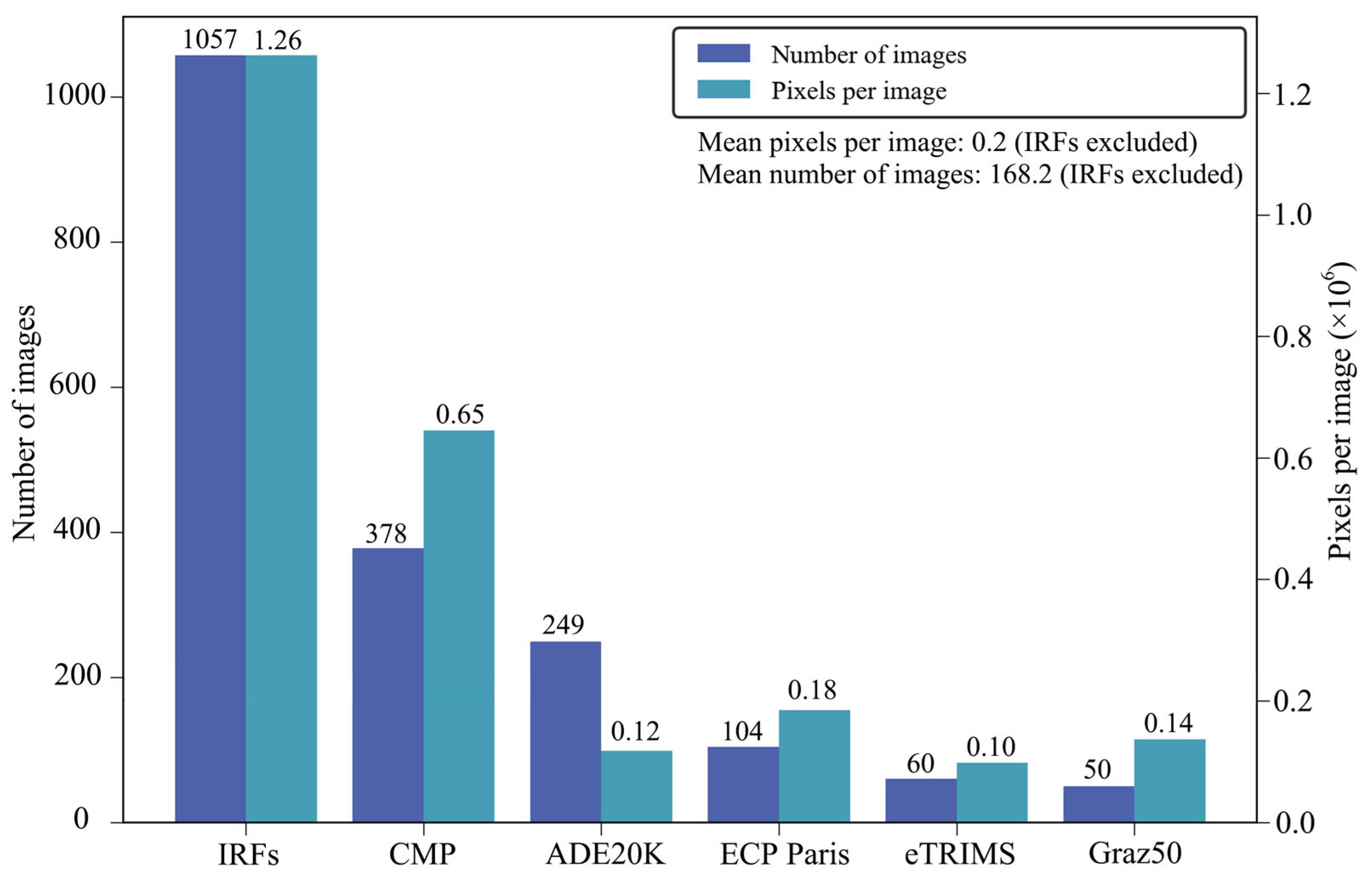
2.3.1. Data Size
2.3.2. Architectural Style
2.3.3. Class Proportion
2.3.4. Complexity
3. Experiment
3.1. Datasets and Networks
3.1.1. Datasets
- Viewed from the front. Facades in the datasets should be viewed from the front orthographically or with only weak perspective distortion;
- Openly available. Only the datasets that can be accessed from open sources were adopted in this experiment;
- Widely used. The wide applications guarantee the dataset’s effectiveness in training classifiers for facade segmentation;
- Highly rated. Good reputation indicates the high quality of the datasets.
3.1.2. Networks
- U-Net only needs very few annotated images to train classifiers. This makes it well adaptable to datasets with a small number of samples, including ECP Paris, eTRIMS, and Graz50;
- DeepLabv3+ shows excellent performance on the images with reduced feature resolution, thus learning from the existing datasets effectively, especially ADE20K;
- SegNeXt achieves efficient multi-scale information interaction at an acceptable computational cost, making it sensitive to objects of different sizes, like the elements on building facades;
- HRNet maintains high-resolution representations through the whole training process so that the details of the boundaries between the facade elements of different classes can be perceived more accurately;
- PSPNet fully uses the scenery context features that are particularly important for the free facade elements with irregular shapes and textures.
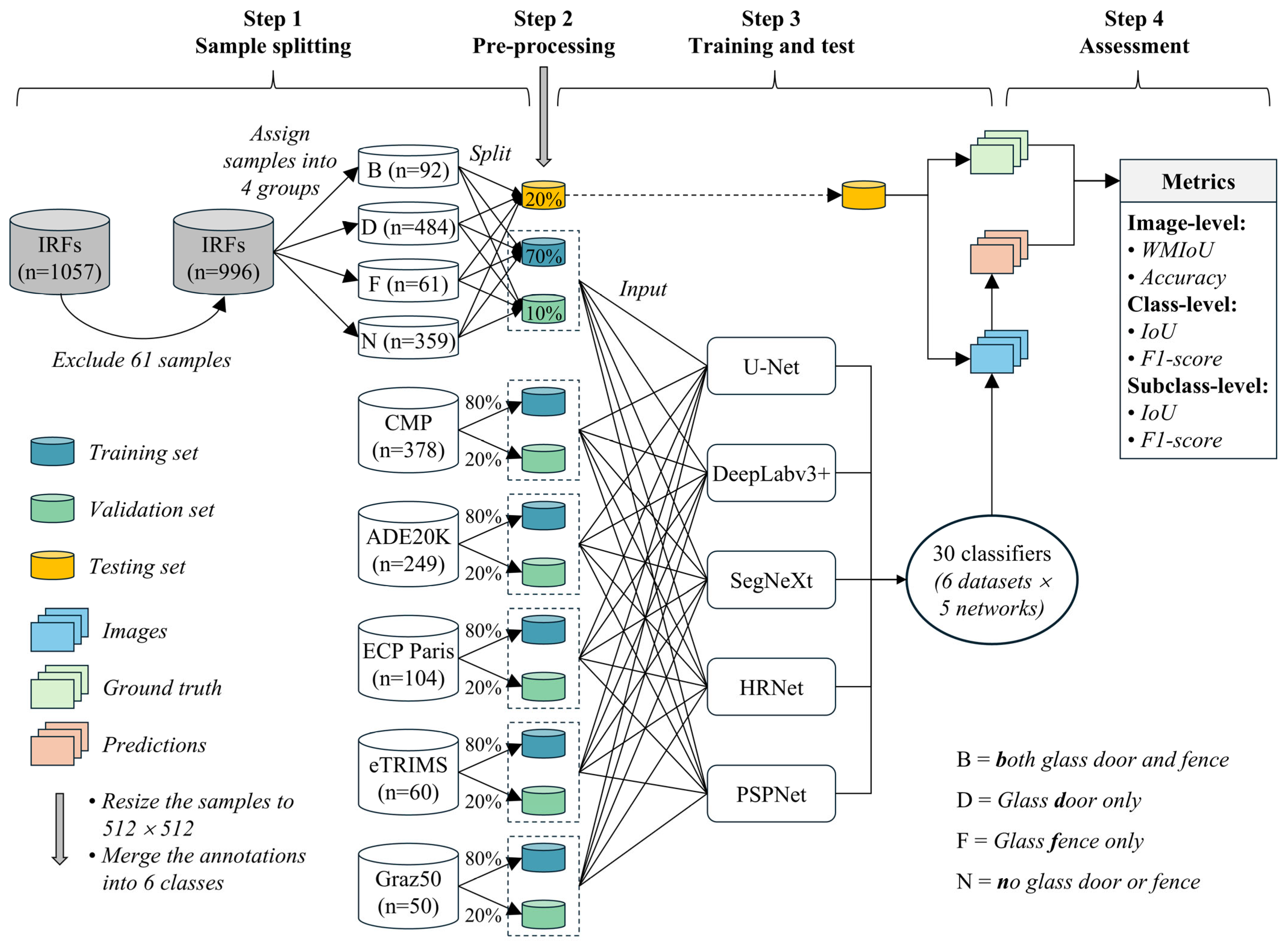
3.2. Process
3.2.1. Sample Splitting
- ①
- In order to calculate the metrics of glass and non-glass elements based on the samples in which the materials were not specifically labeled, 61 samples in which glass door (or fence) and non-glass door (or fence) both appeared were excluded to ensure that each image only contains the door (or fence) of one material;
- ②
- The remaining samples (n = 996) were assigned into four groups according to the distribution of glass elements, as shown in Table 3;
- ③
- The samples of each group were split into training (70%), validation (10%), and testing (20%) sets randomly.
3.2.2. Pre-Processing
3.2.3. Training and Test
3.2.4. Assessment
3.3. Results
3.3.1. Image Level
3.3.2. Class Level
3.3.3. Subclass Level
4. Discussion
- The quality of the training sample is more important than the quantity in classifier training. With the progress of CV technology, the priority of sample quality may continue to increase. Besides resolution, sample quality can also be improved in terms of classes, perspectives, etc.;
- Because of the obvious difference between buildings and environments, the knowledge of building outline is easier to transfer among different architectural styles than that of facade elements. To obtain the composition of single buildings from street or aerial viewed images that include multiple buildings in the visual field, the instance segmentation of buildings is more important than distinguishing buildings from the environment;
- The existence, rather than the quantity, of the facade elements of the same class but different materials in samples is considered the key to improving the classifier’s adaptability. To train classifiers that understand the color, texture, and transparency of various materials, each material must be presented in the samples, but not necessarily in large quantities nor evenly distributed.
5. Limitation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Image-Level Metric (WMIoU/Accuracy) | Class-Level Metric (IoU/F1-Score) | Subclass-Level Metric (IoU/F1-Score) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset for Training | Network for Training | Background | Plant | Wall | Window | Door | Fence | Glass Door | Non-Glass Door | Glass Fence | Non-Glass Fence | |
| IRFs | U-Net | 0.708 0.828 | 0.561 0.719 | 0.546 0.707 | 0.809 0.895 | 0.618 0.765 | 0.272 0.428 | 0.525 0.689 | 0.309 0.473 | 0.195 0.327 | 0.560 0.718 | 0.593 0.745 |
| DeepLabv3+ | 0.755 0.858 | 0.661 0.797 | 0.538 0.700 | 0.837 0.912 | 0.672 0.804 | 0.406 0.578 | 0.638 0.779 | 0.418 0.590 | 0.412 0.584 | 0.749 0.857 | 0.657 0.793 | |
| SegNeXt | 0.680 0.808 | 0.553 0.713 | 0.515 0.681 | 0.787 0.881 | 0.570 0.727 | 0.229 0.373 | 0.445 0.616 | 0.247 0.396 | 0.205 0.342 | 0.420 0.592 | 0.524 0.688 | |
| HRNet | 0.730 0.845 | 0.661 0.795 | 0.554 0.726 | 0.814 0.893 | 0.634 0.777 | 0.420 0.570 | 0.579 0.713 | 0.420 0.592 | 0.411 0.583 | 0.639 0.780 | 0.614 0.761 | |
| PSPNet | 0.736 0.846 | 0.648 0.787 | 0.547 0.708 | 0.820 0.901 | 0.646 0.785 | 0.406 0.578 | 0.570 0.726 | 0.412 0.584 | 0.440 0.611 | 0.647 0.786 | 0.619 0.765 | |
| On average | 0.722 0.837 | 0.617 0.762 | 0.540 0.704 | 0.813 0.896 | 0.628 0.772 | 0.347 0.505 | 0.551 0.705 | 0.361 0.527 | 0.333 0.489 | 0.603 0.747 | 0.601 0.750 | |
| CMP | U-Net | 0.282 0.390 | 0.129 0.230 | / | 0.363 0.533 | 0.154 0.267 | 0.074 0.139 | 0.154 0.267 | 0.089 0.164 | 0.075 0.140 | 0.093 0.171 | 0.280 0.438 |
| DeepLabv3+ | 0.263 0.367 | 0.067 0.126 | / | 0.347 0.516 | 0.122 0.219 | 0.117 0.210 | 0.227 0.371 | 0.124 0.221 | 0.166 0.285 | 0.085 0.158 | 0.400 0.571 | |
| SegNeXt | 0.233 0.333 | 0.041 0.079 | / | 0.311 0.475 | 0.133 0.235 | 0.077 0.143 | 0.127 0.225 | 0.083 0.153 | 0.095 0.174 | 0.159 0.276 | 0.214 0.353 | |
| HRNet | 0.289 0.387 | 0.194 0.325 | / | 0.369 0.540 | 0.122 0.219 | 0.081 0.151 | 0.151 0.263 | 0.089 0.164 | 0.101 0.183 | 0.129 0.229 | 0.304 0.466 | |
| PSPNet | 0.244 0.342 | 0.102 0.187 | / | 0.315 0.479 | 0.120 0.215 | 0.103 0.187 | 0.188 0.317 | 0.119 0.214 | 0.128 0.228 | 0.121 0.217 | 0.330 0.497 | |
| On average | 0.262 0.364 | 0.107 0.189 | / | 0.341 0.509 | 0.130 0.231 | 0.090 0.166 | 0.169 0.289 | 0.100 0.183 | 0.113 0.202 | 0.117 0.210 | 0.306 0.465 | |
| ADE20K | U-Net | 0.285 0.399 | 0.051 0.042 | 0.208 0.022 | 0.362 0.638 | 0.000 0.000 | 0.038 0.008 | 0.097 0.035 | 0.031 0.008 | 0.034 0.009 | 0.092 0.041 | 0.073 0.057 |
| DeepLabv3+ | 0.345 0.497 | 0.022 0.044 | 0.010 0.020 | 0.568 0.725 | 0.000 0.000 | 0.000 0.001 | 0.013 0.027 | 0.000 0.002 | 0.000 0.000 | 0.025 0.050 | 0.012 0.024 | |
| SegNeXt | 0.276 0.373 | 0.013 0.026 | 0.017 0.035 | 0.454 0.625 | 0.000 0.000 | 0.001 0.003 | 0.013 0.027 | 0.002 0.004 | 0.000 0.001 | 0.004 0.050 | 0.030 0.059 | |
| HRNet | 0.292 0.412 | 0.017 0.034 | 0.008 0.017 | 0.481 0.650 | 0.000 0.000 | 0.002 0.004 | 0.007 0.015 | 0.002 0.005 | 0.001 0.003 | 0.011 0.023 | 0.011 0.015 | |
| PSPNet | 0.357 0.514 | 0.019 0.037 | 0.010 0.020 | 0.589 0.742 | 0.000 0.000 | 0.003 0.007 | 0.003 0.006 | 0.005 0.010 | 0.000 0.000 | 0.003 0.007 | 0.003 0.023 | |
| On average | 0.311 0.439 | 0.024 0.037 | 0.051 0.023 | 0.491 0.676 | 0.000 0.000 | 0.009 0.005 | 0.027 0.022 | 0.008 0.006 | 0.007 0.003 | 0.027 0.034 | 0.026 0.036 | |
| ECP Paris | U-Net | 0.411 0.547 | 0.321 0.487 | / | 0.509 0.675 | 0.243 0.392 | 0.049 0.094 | 0.094 0.172 | 0.039 0.075 | 0.091 0.167 | 0.016 0.032 | 0.161 0.278 |
| DeepLabv3+ | 0.411 0.553 | 0.352 0.521 | / | 0.491 0.659 | 0.284 0.443 | 0.019 0.039 | 0.163 0.281 | 0.011 0.023 | 0.045 0.086 | 0.045 0.087 | 0.305 0.468 | |
| SegNeXt | 0.469 0.601 | 0.297 0.459 | / | 0.594 0.746 | 0.279 0.436 | 0.056 0.107 | 0.116 0.208 | 0.065 0.123 | 0.089 0.165 | 0.059 0.113 | 0.216 0.356 | |
| HRNet | 0.532 0.676 | 0.376 0.547 | / | 0.660 0.796 | 0.327 0.493 | 0.089 0.163 | 0.165 0.284 | 0.096 0.175 | 0.090 0.166 | 0.079 0.147 | 0.282 0.440 | |
| PSPNet | 0.492 0.635 | 0.368 0.538 | / | 0.602 0.752 | 0.315 0.480 | 0.032 0.064 | 0.207 0.343 | 0.029 0.056 | 0.044 0.084 | 0.064 0.121 | 0.341 0.509 | |
| On average | 0.463 0.602 | 0.343 0.510 | / | 0.571 0.726 | 0.290 0.449 | 0.049 0.093 | 0.149 0.258 | 0.048 0.090 | 0.072 0.134 | 0.053 0.100 | 0.261 0.410 | |
| eTRIMS | U-Net | 0.422 0.578 | 0.297 0.459 | 0.211 0.350 | 0.555 0.714 | 0.185 0.313 | 0.036 0.071 | / | 0.037 0.073 | 0.041 0.079 | / | / |
| DeepLabv3+ | 0.518 0.681 | 0.381 0.553 | 0.371 0.542 | 0.650 0.788 | 0.288 0.448 | 0.097 0.178 | / | 0.101 0.184 | 0.106 0.193 | / | / | |
| SegNeXt | 0.375 0.494 | 0.279 0.437 | 0.101 0.185 | 0.487 0.656 | 0.186 0.314 | 0.057 0.108 | / | 0.058 0.111 | 0.081 0.151 | / | / | |
| HRNet | 0.535 0.686 | 0.411 0.583 | 0.287 0.447 | 0.656 0.793 | 0.350 0.519 | 0.148 0.258 | / | 0.134 0.237 | 0.217 0.358 | / | / | |
| PSPNet | 0.499 0.655 | 0.392 0.564 | 0.240 0.388 | 0.620 0.766 | 0.301 0.463 | 0.099 0.182 | / | 0.070 0.132 | 0.189 0.319 | / | / | |
| On average | 0.470 0.619 | 0.352 0.519 | 0.242 0.382 | 0.594 0.743 | 0.262 0.411 | 0.087 0.159 | / | 0.080 0.147 | 0.127 0.220 | / | / | |
| Graz50 | U-Net | 0.479 0.638 | 0.278 0.436 | / | 0.614 0.761 | 0.245 0.394 | 0.028 0.054 | / | 0.023 0.046 | 0.043 0.084 | / | / |
| DeepLabv3+ | 0.540 0.701 | 0.305 0.468 | / | 0.681 0.811 | 0.317 0.482 | 0.081 0.151 | / | 0.075 0.141 | 0.111 0.200 | / | / | |
| SegNeXt | 0.471 0.626 | 0.269 0.424 | / | 0.595 0.746 | 0.279 0.436 | 0.028 0.056 | / | 0.016 0.030 | 0.064 0.121 | / | / | |
| HRNet | 0.508 0.662 | 0.311 0.475 | / | 0.626 0.770 | 0.332 0.499 | 0.069 0.130 | / | 0.075 0.118 | 0.100 0.183 | / | / | |
| PSPNet | 0.525 0.682 | 0.308 0.472 | / | 0.652 0.790 | 0.340 0.508 | 0.062 0.117 | / | 0.051 0.098 | 0.097 0.178 | / | / | |
| On average | 0.505 0.662 | 0.294 0.455 | / | 0.634 0.776 | 0.303 0.464 | 0.054 0.102 | / | 0.048 0.087 | 0.083 0.153 | / | / | |
References
- Li, Z.; Guo, R.; Li, M.; Chen, Y.; Li, G. A review of computer vision technologies for plant phenotyping. Comput. Electron. Agric. 2020, 176, 105672. [Google Scholar] [CrossRef]
- Petrova, E.; Pauwels, P.; Svidt, K.; Jensen, R.L. Towards data-driven sustainable design: Decision support based on knowledge discovery in disparate building data. Archit. Eng. Des. Manag. 2019, 15, 334–356. [Google Scholar] [CrossRef]
- Li, Q.; Yang, G.; Gao, C.; Huang, Y.; Zhang, J.; Huang, D.; Zhao, B.; Chen, X.; Chen, B.M. Single drone-based 3D reconstruction approach to improve public engagement in conservation of heritage buildings: A case of Hakka Tulou. J. Build. Eng. 2024, 87, 108954. [Google Scholar] [CrossRef]
- Boulaassal, H.; Landes, T.; Grussenmeyer, P.; Tarsha-Kurdi, F. Automatic segmentation of building facades using Terrestrial Laser Data. In Proceedings of the Paper Presented at the ISPRS Workshop on Laser Scanning 2007 and SilviLaser 2007, Espoo, Finland, 12–14 September 2007; pp. 65–70. Available online: https://shs.hal.science/halshs-00264839 (accessed on 22 August 2024).
- Zhang, G.; Pan, Y.; Zhang, L. Deep learning for detecting building facade elements from images considering prior knowledge. Autom. Constr. 2022, 133, 104016. [Google Scholar] [CrossRef]
- Martinović, A.; Mathias, M.; Weissenberg, J.; Van Gool, L. A Three-Layered Approach to Facade Parsing. In Proceedings of the Computer Vision—ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Proceedings, Part VII. Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 416–429. [Google Scholar] [CrossRef]
- Lotte, R.G.; Haala, N.; Karpina, M.; Aragão, L.E.O.E.C.D.; Shimabukuro, Y.E. 3D Facade Labeling over Complex Scenarios: A Case Study Using Convolutional Neural Network and Structure-From-Motion. Remote Sens. 2018, 10, 1435. [Google Scholar] [CrossRef]
- Neuhausen, M.; König, M. Automatic window detection in facade images. Autom. Constr. 2018, 96, 527–539. [Google Scholar] [CrossRef]
- Sun, Y.; Malihi, S.; Li, H.; Maboudi, M. DeepWindows: Windows Instance Segmentation through an Improved Mask R-CNN Using Spatial Attention and Relation Modules. ISPRS Int. J. Geo-Inf. 2022, 11, 162. [Google Scholar] [CrossRef]
- Mao, Z.; Huang, X.; Xiang, H.; Gong, Y.; Zhang, F.; Tang, J. Glass facade segmentation and repair for aerial photogrammetric 3D building models with multiple constraints. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103242. [Google Scholar] [CrossRef]
- Oskouie, P.; Becerik-Gerber, B.; Soibelman, L. Automated Recognition of Building Facades for Creation of As-Is Mock-Up 3D Models. J. Comput. Civ. Eng. 2017, 31, 04017059. [Google Scholar] [CrossRef]
- Andrade, D.; Harada, M.; Shimada, K. Framework for automatic generation of facades on free-form surfaces. Front. Archit. Res. 2017, 6, 273–289. [Google Scholar] [CrossRef]
- Qi, F.; Tan, X.; Zhang, Z.; Chen, M.; Xie, Y.; Ma, L. Glass Makes Blurs: Learning the Visual Blurriness for Glass Surface Detection. IEEE Trans. Ind. Inform. 2024, 20, 6631–6641. [Google Scholar] [CrossRef]
- Shan, Q.; Curless, B.; Kohno, T. Seeing through Obscure Glass. In Proceedings of the Computer Vision—ECCV 2010: 11th Eu-ropean Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Proceedings, Part VI. Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 364–378. [Google Scholar] [CrossRef]
- Tyleček, R.; Šára, R. Spatial Pattern Templates for Recognition of Objects with Regular Structure. In Proceedings of the Pattern Recognition: 35th German Conference, GCPR 2013, Saarbrucken, Germany, 3–6 September 2013; Proceedings. Weickert, J., Hein, M., Schiele, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 364–374. [Google Scholar] [CrossRef]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Publishing: New York, NY, USA, 2017; pp. 5122–5130. [Google Scholar] [CrossRef]
- Teboul, O.; Simon, L.; Koutsourakis, P.; Paragios, N. Segmentation of building facades using procedural shape priors. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; IEEE Publishing: New York, NY, USA, 2010; pp. 3105–3112. [Google Scholar] [CrossRef]
- Korc, F.; Förstner, W. eTRIMS Image Database for Interpreting Images of Man-Made Scenes; Technical Report TR-IGG-P-2009-01; Department of Photogrammetry, Institute of Geodesy and Geoinformation, University of Bonn: Bonn, Germany, 2009; Available online: http://www.ipb.uni-bonn.de/projects/etrims_db/ (accessed on 22 August 2024).
- Riemenschneider, H.; Krispel, U.; Thaller, W.; Donoser, M.; Havemann, S.; Fellner, D.; Bischof, H. Irregular lattices for complex shape grammar facade parsing. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; IEEE Publishing: New York, NY, USA, 2012; pp. 1640–1647. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, J.; Zhang, R.; Li, Y.; Li, L.; Nakashima, Y. Improving facade parsing with vision transformers and line integration. Adv. Eng. Inform. 2024, 60, 102463. [Google Scholar] [CrossRef]
- Mao, Z.; Huang, X.; Gong, Y.; Xiang, H.; Zhang, F. A Dataset and Ensemble Model for Glass Facade Segmentation in Oblique Aerial Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6513305. [Google Scholar] [CrossRef]
- Xi, R.; Ma, T.; Chen, X.; Lyu, J.; Yang, J.; Sun, K.; Zhang, Y. Image Enhancement Using Adaptive Region-Guided Multi-Step Exposure Fusion Based on Reinforcement Learning. IEEE Access 2023, 11, 31686–31698. [Google Scholar] [CrossRef]
- Cotogni, M.; Cusano, C. Select & Enhance: Masked-based image enhancement through tree-search theory and deep reinforcement learning. Pattern Recognit. Lett. 2024, 183, 172–178. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, W.; Bai, L.; Ren, P. Metalantis: A Comprehensive Underwater Image Enhancement Framework. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5618319. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, W.; Ren, P. Self-organized underwater image enhancement. ISPRS J. Photogramm. Remote Sens. 2024, 215, 1–14. [Google Scholar] [CrossRef]
- Xi, R.; Lyu, J.; Ma, T.; Sun, K.; Zhang, Y.; Chen, X. Learning filter selection policies for interpretable image denoising in parametrised action space. IET Image Process. 2024, 18, 951–960. [Google Scholar] [CrossRef]
- Yu, K.; Wang, X.; Dong, C.; Tang, X.; Loy, C.C. Path-Restore: Learning Network Path Selection for Image Restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7078–7092. [Google Scholar] [CrossRef]
- Xu, Y.; Hou, J.; Zhu, X.; Wang, C.; Shi, H.; Wang, J.; Li, Y.; Ren, P. Hyperspectral Image Super-Resolution with ConvLSTM Skip-Connections. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5519016. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III. Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part VII. Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar] [CrossRef]
- Guo, M.H.; Lu, C.Z.; Hou, Q.; Liu, Z.; Cheng, M.M.; Hu, S.M. SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation. In Proceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; Curran Associates: Red Hook, NY, USA, 2022. Available online: https://proceedings.neurips.cc/paper_files/paper/2022/hash/08050f40fff41616ccfc3080e60a301a-Abstract-Conference.html (accessed on 22 August 2024).
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html (accessed on 22 August 2024).
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]
- Rahman, M.A.; Wang, Y. Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation. In Proceedings of the Advances in Visual Computing: 12th International Symposium, ISVC 2016, Las Vegas, NV, USA, 12–14 December 2016; Proceedings, Part I. Bebis, G., Boyle, R., Parvin, B., Koracin, D., Porikli, F., Skaff, S., Entezari, A., Min, J., Iwai, D., Sadagic, A., et al., Eds.; Springer: Cham, Switzerland, 2016; pp. 234–244. [Google Scholar] [CrossRef]
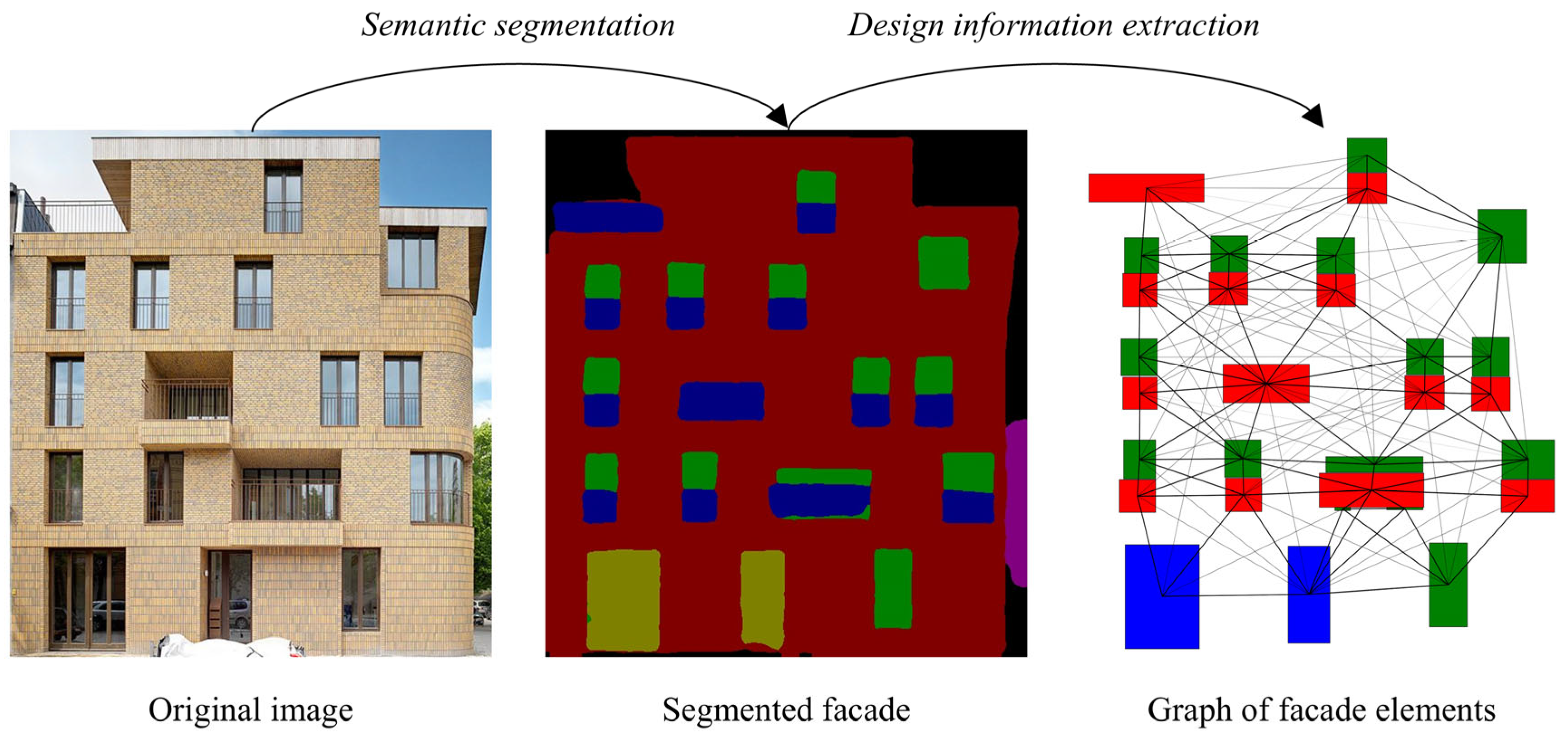
- Hu, Y.; Wei, J.; Zhang, S.; Liu, S. FDIE: A graph-based framework for extracting design information from annotated building facade images. J. Asian Archit. Build. Eng. 2024. Advance online publication. [Google Scholar] [CrossRef]
- Jing, L.; Chen, Y.; Tian, Y. Coarse-to-Fine Semantic Segmentation From Image-Level Labels. IEEE Trans. Image Process. 2020, 29, 225–236. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.-H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2017, 5, 44–53. [Google Scholar] [CrossRef]








| IRFs | CMP | ADE20K | ECP Paris | eTRIMS | Graz50 |
|---|---|---|---|---|---|
| Background | Background | Background | Sky | Sky, Pavement, Road, Car | Sky |
| Plant | / | Plant, Plant Life, Flora, Tree | / | Vegetation | / |
| Wall | Facade, Cornice, Molding, Pillar, Deco | Building, Edifice | Wall, Roof, Chimney, Outlier | Building | Wall |
| Window | Window, Sill, Blind, Shop | Window | Window, Shop | Window | Window |
| Door | Door | Door | Door | Door | Door |
| Fence | Balcony | Balcony | Balcony | / | / |
| Glass Door | Glass Fence | Plant | ||||
|---|---|---|---|---|---|---|
| Dataset | Pixels n (%) | Images n (%) | Pixels n (%) | Images n (%) | Pixels n (%) | Images n (%) |
| IRFs | 2.7 × 107 (2.0%) | 576 (54.5%) | 1.9 × 107 (1.4%) | 153 (14.5%) | 4.1 × 107 (3.1%) | 417 (39.5%) |
| CMP | 1.7 × 106 (0.7%) | 86 (22.8%) | / | / | 1.1 × 106 (0.5%) | 34 (9.0%) |
| ADE20K | 1.7 × 105 (0.6%) | 52 (20.9%) | 2.4 × 104 (0.1%) | 1 (0.4%) | 1.7 × 106 (5.7%) | 108 (43.4%) |
| ECP Paris | 1.8 × 105 (0.9%) | 69 (66.3%) | / | / | / | / |
| eTRIMS | 3.9 × 105 (6.7%) | 4 (6.7%) | / | / | 6.7 × 105 (11.4%) | 56 (93.3%) |
| Graz50 | 3.0 × 104 (0.4%) | 11 (22.0%) | / | / | 7.6 × 103 (0.1%) | 1 (2.0%) |
| Samples | B | D | F | N | Sum |
|---|---|---|---|---|---|
| Training | 64 | 338 | 42 | 251 | 695 |
| Validation | 10 | 49 | 7 | 36 | 102 |
| Testing | 18 | 97 | 12 | 72 | 199 |
| Sum | 92 | 484 | 61 | 359 | 996 |
| Level | Metrics | Description |
|---|---|---|
| Subclass level | IoU and F1-score of subclasses Glass Door, Non-Glass Door, Glass Fence, and Non-Glass Fence. | For single images, if a pixel of Glass Door (Glass Fence) or Non-Glass Door (Non-Glass Fence) was predicted as Door (Fence), the prediction was regarded as true at the subclass level. |
| Class level | IoU and F1-score of classes Background, Plant, Wall, Window, Door, and Fence. | The class-level metrics were computed based on the predictions and ground truth directly. |
| Image level | Weighted mean IoU (WMIoU) and accuracy. | The pixel number of each class was used as the weight of the class for the calculation of WMIoU. |
| Training and Validation Sets | ||||
|---|---|---|---|---|
| Testing Set | CMP | ECP Paris | eTRIMS | Graz50 |
| SJC [7] | 0.36 | 0.25 | 0.45 | 0.37 |
| IRFs (ours) | 0.333–0.390 | 0.547–0.676 | 0.494–0.686 | 0.626–0.701 |
| Image-Level Metric | Class-Level Metric | |||||
|---|---|---|---|---|---|---|
| Dataset | Accuracy | mIoU | WMIoU | IoU (Wall) | IoU (Window) | IoU (Door) |
| CFP [20] | 0.888 | 0.620 | / | 0.855 | 0.653 | 0.547 |
| IRFs (ours) | 0.858 | / | 0.755 | 0.837 | 0.672 | 0.420 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, J.; Hu, Y.; Zhang, S.; Liu, S. Irregular Facades: A Dataset for Semantic Segmentation of the Free Facade of Modern Buildings. Buildings 2024, 14, 2602. https://doi.org/10.3390/buildings14092602
Wei J, Hu Y, Zhang S, Liu S. Irregular Facades: A Dataset for Semantic Segmentation of the Free Facade of Modern Buildings. Buildings. 2024; 14(9):2602. https://doi.org/10.3390/buildings14092602
Chicago/Turabian StyleWei, Junjie, Yuexia Hu, Si Zhang, and Shuyu Liu. 2024. "Irregular Facades: A Dataset for Semantic Segmentation of the Free Facade of Modern Buildings" Buildings 14, no. 9: 2602. https://doi.org/10.3390/buildings14092602
APA StyleWei, J., Hu, Y., Zhang, S., & Liu, S. (2024). Irregular Facades: A Dataset for Semantic Segmentation of the Free Facade of Modern Buildings. Buildings, 14(9), 2602. https://doi.org/10.3390/buildings14092602