
Applications of Big Data in Media Organizations

 ,
,  ,
, 
{kind=link}
Abstract
1. Introduction
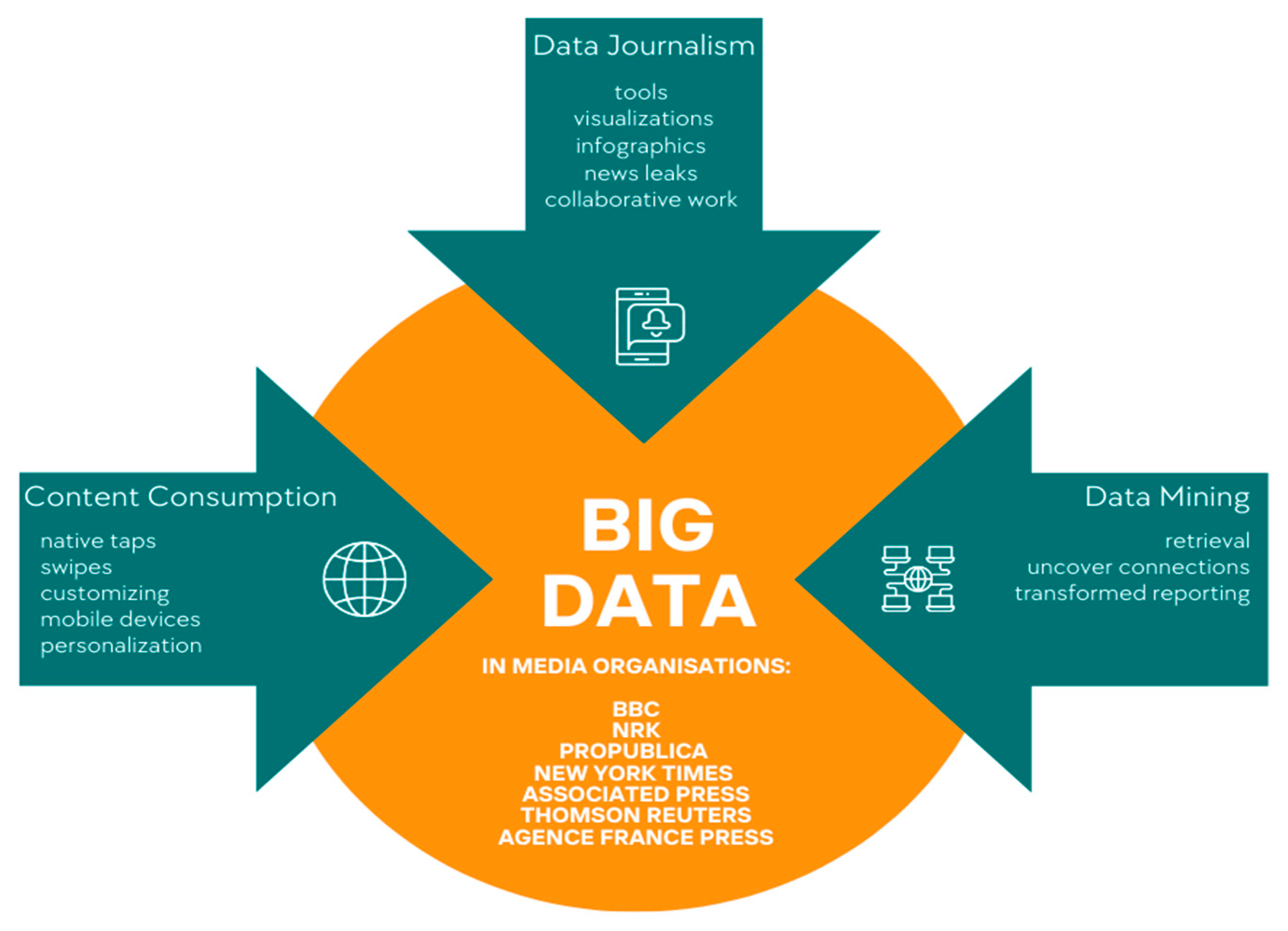
- Identify the importance of big data utilization by media organizations.
- Present the application areas of big data exploitation (media content consumption and management, data journalism investigation and production).
- Highlight the role of data mining in big data applications, social content utilization, and participatory journalism applications.
- Discuss the changes that semantic web technologies will introduce to the exploitation of big data in media organizations.
2. Big Data in Media Organizations
3. Content Consumption
4. Data Journalism
5. Audience Participation
6. Data Mining
7. Future Developments
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adedugbe, Oluwasegun, Elhadj Benkhelifa, Russell Campion, Feras Al-Obeidat, Anoud Bani Hani, and Uchitha Jayawickrama. 2020. Leveraging cloud computing for the semantic web: Review and trends. Soft Computing 24: 5999–6014. [Google Scholar] [CrossRef]
- Ahmed, Jeelani, and Muqeem Ahmed. 2018. Big data and semantic web, challenges and opportunities a survey. International Journal of Engineering & Technology 7: 631–33. [Google Scholar]
- Antoniou, Grigoris, Paul Growth, Frank van Harmelen, and Rinke Hoekstra. 2012. A Semantic Web Primer, 3rd ed. Cambridge: The MIT Press. [Google Scholar]
- Appelgren, Ester, and Gunnar Nygren. 2014. Data Journalism in Sweden: Introducing new methods and genres of journalism into “old” organizations. Digital Journalism 2: 394–405. [Google Scholar] [CrossRef]
- Bartussek, Wolfram, Hermann Bense, Thomas Hoppe, Bernhard G. Humm, Anatol Reibold, Ulrich Schade, Melanie Siegel, and Paul Walsh. 2018. Introduction to Semantic Applications. In Semantic Applications—Methodology, Technology, Corporate Use. Edited by Thomas Hoppe, Bernhard Humm and Anatol Reibold. Berlin: Springer, chp. 1. pp. 1–12. [Google Scholar] [CrossRef]
- Bello-Orgaz, Gema, Jason J. Jung, and David Camacho. 2016. Social big data: Recent achievements and new challenges. Information Fusion 28: 45–59. [Google Scholar] [CrossRef]
- Bentley, Frank, Katie Quehl, Jordan Wirfs-Brock, and Melissa Bica. 2019. Understanding online news behaviors. In CHI Conference on Human Factors in Computing Systems Proceedings. Glasgow and New York: ACM, pp. 1–11. [Google Scholar] [CrossRef]
- Berners-Lee, Tim, James Hendler, and Ora Lassila. 2001. The semantic web. Scientific American 284: 34–43. [Google Scholar] [CrossRef]
- Boberg, Svenja, Tim Schatto-Eckrodt, Lena Frischlich, and Thorsten Quandt. 2018. The moral gatekeeper? Moderation and deletion of user-generated content in a leading news forum. Media and Communication 6: 58–69. [Google Scholar] [CrossRef]
- Bodó, Balázs, Natali Helberger, Sarah Eskens, and Judith Möller. 2019. Interested in diversity. Digital Journalism 7: 206–29. [Google Scholar] [CrossRef]
- Bradshaw, Paul. 2010. How to Be a Data Journalist. The Guardian Data Journalism. Available online: http://www.Guardian.co.uk/news/datablog/2010/oct/01/data-journalism-how-to-guide (accessed on 5 September 2022).
- Carlson, Matt. 2015. The Robotic Reporter. Digital Journalism 3: 416–31. [Google Scholar] [CrossRef]
- Charbonneaux, Juliette, and Pergia Gkouskou-Giannakou. 2015. “Data journalism”, an investigation practice? A glance at the German and Greek cases. Brazilian Journalism Research 2: 244–67. [Google Scholar] [CrossRef]
- Choudhury, Nupur. 2014. World Wide Web and Its Journey from Web 1.0 to Web 4.0. International Journal of Computer Science and Information Technologies (IJCSIT) 5: 8096–100. [Google Scholar]
- Coronado, Miguel, Carlos A. Iglesias, and Emilio Serrano. 2015. Modelling rules for automating the Evented WEb by semantic technologies. Expert Systems with Applications 42: 7979–90. [Google Scholar] [CrossRef]
- Cubbit, Sean. 2015. Data visualization and the subject of political aesthetics. In Postdigital Aesthetics: Art, Computation and Design. Edited by David Berry and Michael Dieter. London: Palgrave MacMillan, pp. 179–90. [Google Scholar]
- Curry, Edward, Andre Freitas, and Sean O’Riáin. 2010. The Role of Community-Driven Data Curation for Enterprises. In Linking Enterprise Data. Edited by David Wood. Boston: Springer, pp. 25–47. [Google Scholar] [CrossRef]
- de-Lima-Santos, Mathias-Felipe, and Lucia Mesquita. 2021. Data journalism in favela: Made by, for, and about forgotten and marginalized communities. Journalism Practice, 1–19. [Google Scholar] [CrossRef]
- De Maeyer, Juliette, Manon Libert, David Domingo, François Heinderyckx, and Florence Le Cam. 2015. Waiting for Data Journalism. Digital Journalism 3: 432–46. [Google Scholar] [CrossRef]
- Deuze, Μark. 2006. Participation, remediation, bricolage: Considering principal components of a digital culture. The Information Society: An International Journal 22: 63–75. [Google Scholar] [CrossRef]
- Diakopoulos, Nicholas. 2015. Algorithmic Accountability. Digital Journalism 3: 398–415. [Google Scholar] [CrossRef]
- Engels, Robert, ESIS, and Jon Roar Tønnesen. 2007. A Digital Music Archive (DMA) for the Norwegian National Broadcaster (NRK) Using Semantic. Semantic Web Use Cases and Case Studies. Available online: https://www.w3.org/2001/sw/sweo/public/UseCases/NRK/ (accessed on 5 September 2022).
- Evens, Tom, and Kristin Van Damme. 2016. Consumers’ Willingness to Share Personal Data: Implications for Newspapers’ Business Models. International Journal on Media Management 18: 25–41. [Google Scholar] [CrossRef]
- Fairfield, Joshua, and Hannah Shtein. 2014. Big Data, Big Problems: Emerging Issues in the Ethics of Data Science and Journalism. Journal of Mass Media Ethics 29: 38–51. [Google Scholar] [CrossRef]
- Fernàndez, Dèlia, Elisenda Bou Balust, Xavier Giró Nieto, Juan Carlos Riviero, Joan Espadaler, David Rodriguez, Aleix Colom Serra, Joan Marco Rimmerk, David Varas, Issey Massuda, and et al. 2018. Linking Media: Adopting Semantic Technologies for multimodal media connection. Paper presented at ISWC 2018 Posters & Demonstrations, Industry and Blue Sky Ideas Tracks: Proceedings of the ISWC 2018 Posters & Demonstrations, Industry and Blue Sky Ideas Tracks co-located with 17th International Semantic Web Conference (ISWC 2018), Monterey, CA, USA, October 8–12; pp. 1–2. Available online: http://hdl.handle.net/2117/132968 (accessed on 5 September 2022).
- Flew, Terry, Christina Spurgeon, Anna Daniel, and Adam Swift. 2012. The Promise of Computational Journalism. Journalism Practice 6: 157–71. [Google Scholar] [CrossRef]
- França, Reinaldo Padilha, Ana Carolina Borges Monteiro, Rangel Arthur, and Yuzo Iano. 2021. An Overview and Technological Background of Semantic Technologies. In Advanced Concepts, Methods, and Applications in Semantic Computing. Edited by Olawande Daramola and Thomas Moser. Hershey: IGI Global, pp. 1–21. [Google Scholar] [CrossRef]
- Frischlich, Lena, Svenja Boberg, and Thorsten Quandt. 2019. Comment sections as targets of dark participation? Journalists’ evaluation and moderation of deviant user comments. Journalism Studies 20: 2014–33. [Google Scholar] [CrossRef]
- Golf-Papez, Maja, and Ekant Veer. 2017. Don’t feed the trolling: Rethinking how online trolling is being defined and combated. Journal of Marketing Management 33: 1336–54. [Google Scholar] [CrossRef]
- Gross, David. 2014. Big Data and the Semantic Web—What Does It Really Mean? Express. Available online: https://www.express.co.uk/life-style/science-technology/529574/big-data-semantic-web-what-it-means (accessed on 5 September 2022).
- Gruszynski Sanseverino, Gabriela, and Mathias Felipe De Lima Santos. 2021. Experimenting with user-generated content in journalistic practices: Adopting a user-centric storytelling approach during the covid-19 pandemic coverage in Latin America. Brazilian Journalism Research 17: 244–79. [Google Scholar] [CrossRef]
- Hahn, Oliver, and Florian Stalph. 2016. Data Journalism in International Reporting. An Exploratory Study on Data-Driven Investigation of Foreign News Stories. Paper presented at the 2016 WJEC, 4th World Journalism Education Congress, Auckland, New Zealand, July 14–16. [Google Scholar]
- Hammond, Philip. 2017. From computer-assisted to data-driven: Journalism and Big Data. Journalism 18: 408–24. [Google Scholar] [CrossRef]
- Hermida, Alfred, Fred Fletcher, Darryl Korell, and Donna Logan. 2012. Share, like, recommend. Journalism Studies 13: 815–24. [Google Scholar] [CrossRef]
- Hilbert, Martin. 2016. Big data for development: A review of promises and challenges. Development Policy Review 34: 135–74. [Google Scholar] [CrossRef]
- Hille, Sanne, and Piet Bakker. 2014. Engaging the social news user. Journalism Practice 8: 563–72. [Google Scholar] [CrossRef]
- Horrocks, Ian, Martin Giese, Evgeny Kharlamov, and Arild Waaler. 2016. Using semantic technology to tame the data variety challenge. IEEE Internet Computing 20: 62–66. [Google Scholar] [CrossRef]
- Ildor, Astrid. 2020. Semantic Web Applications for Danish News Media. In WEBIST. pp. 269–76. [Google Scholar]
- Kalatzi, Olga, Charalampos Bratsas, and Andreas Veglis. 2018. The principles, features and techniques of data journalism. Studies in Media Communication 6: 36–44. [Google Scholar] [CrossRef]
- Karypidou, Christina, Charalampos Bratsas, and Andreas Veglis. 2019. Visualization and interactivity in data journalism projects. Paper presented at 5th Annual International Conference on Communication and Management (ICCM2019), Athens, Greece, April 15–18; Athens: Communication Institute of Greece. [Google Scholar]
- Katsaounidou, Anastasia, Charalampos Dimoulas, and Andreas Veglis. 2018. Cross-Media Authentication and Verification: Emerging Research and Opportunities. Pennsylvania: IGI-Global. [Google Scholar]
- Kelly, John. 2019. Television by the numbers: The challenges of audience measurement in the age of Big Data. Convergence 25: 113–32. [Google Scholar] [CrossRef]
- Kitchin, Rob. 2014. Big data, new epistemologies and paradigm shifts. Big Data & Society 1: 1–12. [Google Scholar] [CrossRef]
- Kitchin, Rob, and Gavin McArdle. 2016. What makes Big Data, Big Data? Exploring the ontological characteristics of 26 datasets. Big Data & Society 3: 1–10. [Google Scholar] [CrossRef]
- Knight, Megan. 2015. Data journalism in the UK: A preliminary analysis of form and content. Journal of Media Practice 16: 55–72. [Google Scholar] [CrossRef]
- Kotenidis, Efthimios, and Andreas Veglis. 2021. Algorithmic Journalism—Current Applications and Future Perspectives. Journalism and Media 2: 244–57. [Google Scholar] [CrossRef]
- Ksiazek, Thomas B., Limor Peer, and Andrew Zivic. 2015. Discussing the news. Digital Journalism 3: 850–70. [Google Scholar] [CrossRef]
- Latar, Noam Lemelshtrich. 2015. The Robot Journalist in the Age of Social Physics: The End of Human Journalism? In The New World of Transitioned Media: Digital Realignment and Industry Transformation. Edited by G. Einav. Berlin: Springer International Publishing, pp. 65–80. [Google Scholar]
- Lewis, Seth C., and Oscar Westlund. 2015. Big data and journalism: Epistemology, expertise, economics, and ethics. Digital Journalism 3: 447–66. [Google Scholar] [CrossRef]
- Lippell, Helen. 2016. Big Data in the Media and Entertainment Sectors. In New Horizons for a Data-Driven Economy. Cham: Springer, pp. 245–59. [Google Scholar]
- Manosevitch, Idit. 2011. User generated content in the Israeli online journalism landscape. Israel Affairs 17: 422–44. [Google Scholar] [CrossRef]
- Mujawar, Sofiya, and Soha Kulkarni. 2015. Big data: Tools and applications. International Journal of Computer Applications 115: 7–11. [Google Scholar] [CrossRef]
- Murray, Scott. 2017. Interactive Data Visualization for the Web: An Introduction to Designing with D3. Sebastopol: O’Reilly Media, Inc. [Google Scholar]
- Necula, Sabina-Cristiana. 2020. Semantic Web Applications: Current Trends in Datasets, Tools and Technologies’ Development for Linked Open Data. Informatica Economica 24: 72–84. [Google Scholar] [CrossRef]
- Necula, Sabina-Cristiana, Vasile-Daniel Păvăloaia, Cătălin Strîmbei, and Octavian Dospinescu. 2018. Enhancement of e-commerce websites with semantic web technologies. Sustainability 10: 1955. [Google Scholar] [CrossRef]
- Nelson, Jacob L., and James G. Webster. 2016. Audience Currencies in the Age of Big Data. International Journal on Media Management 18: 9–24. [Google Scholar] [CrossRef]
- Newman, Nic, Richard Fletcher, Antonis Kalogeropoulos, David Levy, and Rasmus Kleis Nielsen. 2018. Reuters Institute Digital News Report 2018. Oxford: Reuters Institute for the Study of Journalism. [Google Scholar]
- Newman, Nic, Richard Fletcher, Anne Schulz, Simge Andi, Craig Robertson, and Rasmus Kleis Nielsen. 2021. Reuters Institute Digital News Report, 10th ed. Oxford: Reuters Institute for the Study of Journalism. [Google Scholar]
- Palomo, Bella, Laura Teruel, and Elena Blanco-Castilla. 2019. Data journalism projects based on user-generated content. How La Nacion data transforms active audience into staff. Digital Journalism 7: 1270–88. [Google Scholar] [CrossRef]
- Parasie, Sylvain. 2015. Data-driven revelation? Epistemological tensions in investigative journalism in the age of ‘big data’. Digital Journalism 3: 364–80. [Google Scholar] [CrossRef]
- Qiu, Junfei, Qihui Wu, Guoru Ding, Yuhua Xu, and Shuo Feng. 2016. A survey of machine learning for big data processing. EURASIP Journal on Advances in Signal Processing 2016: 67. [Google Scholar] [CrossRef]
- Quandt, Thorsten. 2018. Dark participation. Media and Communication 6: 36–48. [Google Scholar] [CrossRef]
- Raimond, Yves, Tom Scott, Silver Oliver, Patrick Sinclair, and Michael Smethurst. 2010. Use of Semantic Web technologies on the BBC Web Sites. In Linking Enterprise Data. Edited by Wood David. Boston: Springer, pp. 263–83. [Google Scholar] [CrossRef]
- Ramageri, Bharati. 2010. Data mining techniques and applications. Indian Journal of Computer Science and Engineering 1: 301–5. [Google Scholar]
- Rhayem, Ahlem, Mohamed Ben Ahmed Mhiri, and Faiez Gargouri. 2020. Semantic Web Technologies for the Internet of Things: Systematic Literature Review. Internet of Things 11: 100206. [Google Scholar] [CrossRef]
- Rogers, Simon. 2014. Introduction to Data Journalism. Simon Rogers-Data Journalism and Other Curiosities. Available online: http://simonrogers.net/2014/05/25/introduction-to-data-journalism/ (accessed on 5 September 2022).
- Sandoval-Martín, María Teresa, and Leonardo La-Rosa. 2018. Big Data as a differentiating sociocultural element of data journalism: The perception of data journalists and experts. Communication and Society 31: 193–209. [Google Scholar] [CrossRef]
- Saridou, Theodora, and Andreas Veglis. 2016. Participatory journalism practices in newspapers’ websites in Greece. Journal of Greek Media & Culture 2: 85–101. [Google Scholar]
- Singer, Jane B., David Domingo, Ari Heinonen, Alfred Hermida, Steve Paulussen, Thorsten Quandt, Zvi Reich, and Marina Vujnovic. 2011. Participatory Journalism. Guarding Open Gates at Online Newspapers. West Sussex: Wiley-Blackwell. [Google Scholar]
- Singh, Priya. 2017. How Big Data Analytics Is Changing—The Media and Entertainment Landscape. Analytics India Magazine. Available online: https://analyticsindiamag.com/big-data-analytics-changing-media-entertainment-landscape/ (accessed on 5 September 2022).
- Snijders, Chris, Uwe Matzat, and Ulf-Dietrich Reips. 2012. Big data: Big gaps of knowledge in the field of internet. International Journal of Internet Science 7: 1–5. [Google Scholar]
- Spayd, Liz. 2017. A ‘Community’ of One: The Times Gets Tailored. New York Times. Available online: https://www.nytimes.com/2017/03/18/public-editor/a-community-of-one-the-times-gets-tailored.html (accessed on 5 September 2022).
- Spyridou, Lia-Paschalia. 2018. Analyzing the active audience: Reluctant, reactive, fearful, or lazy? Forms and motives of participation in mainstream journalism. Journalism 20: 827–47. [Google Scholar] [CrossRef]
- Spyridou, Lia-Paschalia, Maria Matsiola, Andreas Veglis, George Kalliris, and Charalampos Dimoulas. 2013. Journalism in a state of flux: Changing journalistic practices in the Greek newsroom. International Communication Gazette 75: 76–98. [Google Scholar] [CrossRef]
- Stardog. 2019. Graph Identified as Top Technology Trend for 2019. Available online: https://www.businesswire.com/news/home/20190307005668/en/ (accessed on 5 September 2022).
- Stone, Martha. 2014. Big Data for Media. Report. Oxford: Reuters Institute for the Study of Journalism. [Google Scholar]
- Tandoc, Edson C., Jr., and Soo-Kwang Oh. 2017. Small departures, big continuities? Norms, values, and routines in The Guardian’s big data journalism. Journalism Studies 18: 997–1015. [Google Scholar] [CrossRef]
- Thurman, Neil, Judith Moeller, Natali Helberger, and Damian Trilling. 2018. My Friends, Editors, Algorithms, and I. Digital Journalism 7: 447–69. [Google Scholar] [CrossRef]
- Tong, Jingrong. 2015. Chinese journalists’ views of user-generated content producers and journalism: A case study of the boundary work of journalism. Asian Journal of Communication 25: 600–16. [Google Scholar] [CrossRef]
- Turnbull, Sue. 2020. Imagining the Audience. In The Media & Communications in Australia. Edited by Stuart Cunningham and Sue Turnbull. London: Routledge, pp. 59–72. [Google Scholar]
- Underwood, Corinna. 2019. Automated Journalism—AI Applications at New York Times, Reuters, and Other Media Giants. Emerj—The AI Research and Advisory Company. Available online: https://emerj.com/ai-sector-overviews/automated-journalism-applications (accessed on 5 September 2022).
- Veglis, Andreas. 2009. Cross media Communication in newspaper organizations. Proceedings of the 4th Mediterranean Conference on Information Systems, Athens, Greece, September 25–27; p. 37. [Google Scholar]
- Veglis, Andreas. 2012. Journalism and Cross Media Publishing: The case of Greece. In Handbook of Online Journalism. Edited by Eugenia Siapera and Andreas Veglis. Hoboken: Blackwell Publishing, pp. 209–23. [Google Scholar]
- Veglis, Andreas. 2014. Moderation Techniques for Social Media Content. Paper presented at HCI International 2014, Crete, Greece, June 22–27; Cham: Springer, pp. 137–48. [Google Scholar]
- Veglis, Andreas, and Andreas Pomportsis. 2014. Journalists in the age of ICTs: Work demands and educational needs. Journalism & Mass Communication Educator 69: 61–75. [Google Scholar]
- Veglis, Andreas, and Charalampos Bratsas. 2017. Journalists in the age of data journalism: The case of Greece. Journal of Applied Journalism & Media Studies 6: 225–44. [Google Scholar]
- Veglis, Andreas, and Theodora Maniou. 2018. The mediated data model of communication flow: Big data and Data Journalism. KOME: An International Journal of Pure Communication Inquiry 6: 32–43. [Google Scholar] [CrossRef]
- Veglis, Andreas, and Theodora Maniou. 2019. Chatbots on the Rise: A new Narrative in Journalism. Studies in Media & Communication 7: 1–6. [Google Scholar] [CrossRef]
- Venturini, Tommaso, Mathieu Jacomy, Liliana Bounegru, and Jonathan Gray. 2018. Visual network exploration for data journalists. In The Routledge Handbook of Developments in Digital Journalism Studies. London: Routledge, pp. 265–83. [Google Scholar]
- Weaver, David H., and Lars Willnat. 2016. Changes in US journalism: How do journalists think about social media? Journalism Practice 10: 844–55. [Google Scholar] [CrossRef]
- Wu, Xindong, Xingquan Zhu, Gong-Quing Wu, and Wei Ding. 2014. Data mining with big data. IEEE Transactions on Knowledge and Data Engineering 26: 97–107. [Google Scholar] [CrossRef]
- Yen, Neil Y., Chengcui Zhang, Agustinus Borgy Waluyo, and James J. Park. 2015. Social Media Services and Technologies Towards Web 3.0. Multimedia Tools Application 74: 5007–13. [Google Scholar] [CrossRef][Green Version]
- Young, Mary Lynn, Alfred Hermida, and Johanna Fulda. 2018. What makes for great data journalism? A content analysis of data journalism awards finalists 2012–15. Journalism Practice 12: 115–35. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Veglis, A.; Saridou, T.; Panagiotidis, K.; Karypidou, C.; Kotenidis, E. Applications of Big Data in Media Organizations. Soc. Sci. 2022, 11, 414. https://doi.org/10.3390/socsci11090414
Veglis A, Saridou T, Panagiotidis K, Karypidou C, Kotenidis E. Applications of Big Data in Media Organizations. Social Sciences. 2022; 11(9):414. https://doi.org/10.3390/socsci11090414
Chicago/Turabian StyleVeglis, Andreas, Theodora Saridou, Kosmas Panagiotidis, Christina Karypidou, and Efthimis Kotenidis. 2022. "Applications of Big Data in Media Organizations" Social Sciences 11, no. 9: 414. https://doi.org/10.3390/socsci11090414
APA StyleVeglis, A., Saridou, T., Panagiotidis, K., Karypidou, C., & Kotenidis, E. (2022). Applications of Big Data in Media Organizations. Social Sciences, 11(9), 414. https://doi.org/10.3390/socsci11090414