
Bluetongue Risk Map for Vaccination and Surveillance Strategies in India

 , ,
, ,
Abstract
1. Introduction
- To identify the variables that discriminate between the presence and absence of BT outbreaks in South India.
- To investigate whether environmental conditions in South India drive variation between the presence and absence of bluetongue outbreaks (more than one presence or absence group).
- To test whether known but sparse absence data, or pseudo-absence data, give better accuracy in BT presence/absence models.
- To develop a BTV risk map for South India to help in surveillance and vaccination strategies.
2. Materials and Methods
2.1. Bluetongue Presence and Absence Data
2.2. Remotely Sensed Variables
2.3. Non-Linear Discriminant Analysis Model (NLDA) Description
2.3.1. NLDA and Clustering
2.3.2. Variable Selection
2.3.3. Variable Selection Criteria
2.3.4. Bootstrapping
2.3.5. Accuracy and Validation Statistics
3. Results
3.1. Single Best Model Results
3.2. Averaged Bootstrap Model Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Roy, P. Bluetongue virus proteins. J. Gen. Virol. 1992, 73, 3051–3064. [Google Scholar] [CrossRef] [PubMed]
- Chanda, M.; Carpenter, S.; Prasad, G.; Sedda, L.; Henrys, P.; Gajendragad, M.; Purse, B. Livestock host composition rather than land use or climate explains spatial patterns in bluetongue disease in South India. Sci. Rep. 2019, 9, 4229. [Google Scholar] [CrossRef] [PubMed]
- Sreenivasulu, D.; Subba Rao, M.; Reddy, Y.; Gard, G. Overview of bluetongue disease, viruses, vectors, surveillance and unique features: The Indian sub-continent and adjacent regions. Vet. Ital. 2004, 40, 73–77. [Google Scholar] [PubMed]
- Palaniyandi, M. The role of remote sensing and GIS for spatial prediction of vector-borne diseases transmission: A systematic review. J. Vector Borne Dis. 2012, 49, 197. [Google Scholar] [CrossRef] [PubMed]
- Calistri, P.; Goffredo, M.; Caporale, V.; Meiswinkel, R. The distribution of Culicoides imicola in Italy: Application and evaluation of current Mediterranean models based on climate. J. Vet. Med. Ser. B 2003, 50, 132–138. [Google Scholar] [CrossRef] [PubMed]
- Conte, A.; Giovannini, A.; Savini, L.; Goffredo, M.; Calistri, P.; Meiswinkel, R. The effect of climate on the presence of Culicoides imicola in Italy. J. Vet. Med. Ser. B 2003, 50, 139–147. [Google Scholar] [CrossRef] [PubMed]
- Wittmann, E.; Mellor, P.; Baylis, M. Using climate data to map the potential distribution of Culicoides imicola (Diptera: Ceratopogonidae) in Europe. Rev. Sci. Tech.-Off. Int. Des Epizoot. 2001, 20, 731–740. [Google Scholar] [CrossRef] [PubMed]
- Martins-Bedê, F.T.; Freitas, C.C.; Dutra, L.V.; Sandri, S.A.; Fonseca, F.R.; Drummond, I.N.; Guimarães, R.J.d.P.S.; Amaral, R.S.; Carvalho, O.S. Risk mapping of schistosomiasis in Minas Gerais, Brazil, using MODIS and socioeconomic spatial data. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3899–3908. [Google Scholar] [CrossRef]
- Cao, L.; Cova, T.J.; Dennison, P.E.; Dearing, M.D. Using MODIS satellite imagery to predict hantavirus risk. Glob. Ecol. Biogeogr. 2011, 20, 620–629. [Google Scholar] [CrossRef]
- Kotchi, S.O.; Bouchard, C.; Brazeau, S.; Ogden, N.H. Earth observation-informed risk maps of the Lyme disease vector Ixodes scapularis in Central and Eastern Canada. Remote Sens. 2021, 13, 524. [Google Scholar] [CrossRef]
- Klingseisen, B.; Stevenson, M.; Corner, R. Prediction of Bluetongue virus seropositivity on pastoral properties in northern Australia using remotely sensed bioclimatic variables. Prev. Vet. Med. 2013, 110, 159–168. [Google Scholar] [CrossRef] [PubMed]
- Gahn, M.C.B.; Niakh, F.; Ciss, M.; Seck, I.; Lo, M.M.; Fall, A.G.; Biteye, B.; Fall, M.; Ndiaye, M.; Ba, A. Assessing the risk of occurrence of bluetongue in Senegal. Microorganisms 2020, 8, 1766. [Google Scholar] [CrossRef] [PubMed]
- Purse, B.; Tatem, A.; Caracappa, S.; Rogers, D.; Mellor, P.; Baylis, M.; Torina, A. Modelling the distributions of Culicoides bluetongue virus vectors in Sicily in relation to satellite-derived climate variables. Med. Vet. Entomol. 2004, 18, 90–101. [Google Scholar] [CrossRef]
- Van Doninck, J.; De Baets, B.; Peters, J.; Hendrickx, G.; Ducheyne, E.; Verhoest, N.E. Modelling the spatial distribution of Culicoides imicola: Climatic versus remote sensing data. Remote Sens. 2014, 6, 6604–6619. [Google Scholar] [CrossRef]
- Mellor, P. Replication of arboviruses in insect vectors. J. Comp. Pathol. 2000, 123, 231–247. [Google Scholar] [CrossRef]
- Archana, M.; Sundarraj, R.; Mruthyunjaya, A.G.; Ghosal, T.; Mazumdar, A.; Hemadri, D.; Sengupta, P.; Prasad, M.; Reddy, Y.N.; Yarabolu, K.R. Abundance and Diversity of Culicoides Species (Diptera: Ceratopogonidae) in Different Forest Landscapes of Karnataka, India: Implications for Culicoides Borne Diseases. Transbound. Emerg. Dis. 2023, 2023, 6250963. [Google Scholar] [CrossRef]
- Ciss, M.; Biteye, B.; Fall, A.G.; Fall, M.; Gahn, M.C.B.; Leroux, L.; Apolloni, A. Ecological niche modelling to estimate the distribution of Culicoides, potential vectors of bluetongue virus in Senegal. BMC Ecol. 2019, 19, 45. [Google Scholar] [CrossRef] [PubMed]
- Guichard, S.; Guis, H.; Tran, A.; Garros, C.; Balenghien, T.; Kriticos, D.J. Worldwide niche and future potential distribution of Culicoides imicola, a major vector of bluetongue and African horse sickness viruses. PLoS ONE 2014, 9, e112491. [Google Scholar] [CrossRef]
- Kitron, U. Risk maps: Transmission and burden of vector-borne diseases. Parasitol. Today 2000, 16, 324–325. [Google Scholar] [CrossRef]
- Rogers, D.J.; Packer, M.J. Vector-borne diseases, models, and global change. Lancet 1993, 342, 1282–1284. [Google Scholar] [CrossRef]
- Baylis; Bouayoune; Touti; Hasnaoui, E.H. Use of climatic data and satellite imagery to model the abundance of Culicoides imicola, the vector of African horse sickness virus, in Morocco. Med. Vet. Entomol. 1998, 12, 255–266. [Google Scholar] [CrossRef]
- Tatem, A.; Baylis, M.; Mellor, P.; Purse, B.; Capela, R.; Pena, I.; Rogers, D. Prediction of bluetongue vector distribution in Europe and north Africa using satellite imagery. Vet. Microbiol. 2003, 97, 13–29. [Google Scholar] [CrossRef]
- Purse, B.; Falconer, D.; Sullivan, M.; Carpenter, S.; Mellor, P.; Piertney, S.; Mordue, A.; Albon, S.; Gunn, G.; Blackwell, A. Impacts of climate, host and landscape factors on Culicoides species in Scotland. Med. Vet. Entomol. 2012, 26, 168–177. [Google Scholar] [CrossRef] [PubMed]
- Eastman, J.R.; Fulk, M. Long sequence time series evaluation using standardized principal components. Photogramm. Eng. Remote Sens. 1993, 59, 991–996. [Google Scholar]
- Rogers, D.; Hay, S.; Packer, M. Predicting the distribution of tsetse flies in West Africa using temporal Fourier processed meteorological satellite data. Ann. Trop. Med. Parasitol. 1996, 90, 225–241. [Google Scholar] [CrossRef] [PubMed]
- Scharlemann, J.P.; Benz, D.; Hay, S.I.; Purse, B.V.; Tatem, A.J.; Wint, G.W.; Rogers, D.J. Global data for ecology and epidemiology: A novel algorithm for temporal Fourier processing MODIS data. PLoS ONE 2008, 3, e1408. [Google Scholar] [CrossRef]
- Kumar, H.C.; Hiremath, J.; Yogisharadhya, R.; Balamurugan, V.; Jacob, S.S.; Reddy, G.M.; Suresh, K.; Shome, R.; Nagalingam, M.; Sridevi, R. Animal disease surveillance: Its importance & present status in India. Indian J. Med. Res. 2021, 153, 299–310. [Google Scholar]
- Bonnett, R.; Campbell, J. Introduction to Remote Sensing; The Guilford Press: New York, NY, USA, 2002. [Google Scholar]
- Boyd, D.S.; Curran, P.J. Using remote sensing to reduce uncertainties in the global carbon budget: The potential of radiation acquired in middle infrared wavelengths. Remote Sens. Rev. 1998, 16, 293–327. [Google Scholar] [CrossRef]
- Rogers, D.; Randolph, S. Distribution of tsetse and ticks in Africa: Past, present and future. Parasitol. Today 1993, 9, 266–271. [Google Scholar] [CrossRef]
- Elith, J.; Graham, C.H. Do they? How do they? WHY do they differ? On finding reasons for differing performances of species distribution models. Ecography 2009, 32, 66–77. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R. Species distribution models: Ecological explanation and prediction across space and time. Annu. Rev. Ecol. Evol. Syst. 2009, 40, 677–697. [Google Scholar] [CrossRef]
- Hao, T.; Elith, J.; Guillera-Arroita, G.; Lahoz-Monfort, J.J. A review of evidence about use and performance of species distribution modelling ensembles like BIOMOD. Divers. Distrib. 2019, 25, 839–852. [Google Scholar] [CrossRef]
- Tatsuoka, M.M.; Lohnes, P.R. Multivariate Analysis: Techniques for Educational and Psychological Research; Macmillan Publishing Co., Inc.: New York, NY, USA, 1988. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Hurvich, C.M.; Tsai, C.-L. Regression and time series model selection in small samples. Biometrika 1989, 76, 297–307. [Google Scholar] [CrossRef]
- Barbet-Massin, M.; Jiguet, F.; Albert, C.H.; Thuiller, W. Selecting pseudo-absences for species distribution models: How, where and how many? Methods Ecol. Evol. 2012, 3, 327–338. [Google Scholar] [CrossRef]
- Congalton, R.G. Remote sensing and geographic information system data integration: Error sources and. Photogramm. Eng. Remote Sens. 1991, 57, 677–687. [Google Scholar]
- Fielding, A.H.; Bell, J.F. A review of methods for the assessment of prediction errors in conservation presence/absence models. Environ. Conserv. 1997, 24, 38–49. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data; International Biometric Society: Washington, DC, USA, 1977; Volume 33, pp. 159–174. [Google Scholar] [CrossRef]
- Robinson, T.P. Spatial statistics and geographical information systems in epidemiology and public health. Adv. Parasitol. 2000, 47, 81–128. [Google Scholar]
- Rogers, D.J. Models for vectors and vector-borne diseases. Adv. Parasitol. 2006, 62, 1–35. [Google Scholar]
- Rupner, R.N.; VinodhKumar, O.; Karthikeyan, R.; Sinha, D.; Singh, K.; Dubal, Z.; Tamta, S.; Gupta, V.; Singh, B.; Malik, Y. Bluetongue in India: A systematic review and meta-analysis with emphasis on diagnosis and seroprevalence. Vet. Q. 2020, 40, 229–242. [Google Scholar] [CrossRef]
- Ahmad, L.; Habib Kanth, R.; Parvaze, S.; Sheraz Mahdi, S.; Ahmad, L.; Habib Kanth, R.; Parvaze, S.; Sheraz Mahdi, S. Agro-Climatic and Agro-Ecological Zones of India; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Baylis, M.; Meiswinkel, R.; Venter, G. A preliminary attempt to use climate data and satellite imagery to model the abundance and distribution of Culicoides imicola (Diptera: Ceratopogonidae) in southern Africa. J. S. Afr. Vet. Assoc. 1999, 70, 80–89. [Google Scholar] [CrossRef] [PubMed]
- Baylis, M.; Mellor, P.; Wittmann, E.; Rogers, D. Prediction of areas around the Mediterranean at risk of bluetongue by modelling the distribution of its vector using satellite imaging. Vet. Rec. 2001, 149, 639–643. [Google Scholar] [CrossRef]
- Romero-Alvarez, D.; Escobar, L.E.; Auguste, A.J.; Del Valle, S.Y.; Manore, C.A. Transmission risk of Oropouche fever across the Americas. Infect. Dis. Poverty 2023, 12, 47. [Google Scholar] [CrossRef] [PubMed]
- Ravishankar, C.; Nair, G.K.; Mini, M.; Jayaprakasan, V. Seroprevalence of bluetongue virus antibodies in sheep and goats in Kerala State, India. Rev. Sci. Tech.-Off. Int. Épizooties 2005, 24, 953. [Google Scholar] [CrossRef]
- Munyua, P.M.; Murithi, R.M.; Ithondeka, P.; Hightower, A.; Thumbi, S.M.; Anyangu, S.A.; Kiplimo, J.; Bett, B.; Vrieling, A.; Breiman, R.F. Predictive factors and risk mapping for Rift Valley fever epidemics in Kenya. PLoS ONE 2016, 11, e0144570. [Google Scholar] [CrossRef]
- Tumusiime, D.; Isingoma, E.; Tashoroora, O.B.; Ndumu, D.B.; Bahati, M.; Nantima, N.; Mugizi, D.R.; Jost, C.; Bett, B. Mapping the risk of Rift Valley fever in Uganda using national seroprevalence data from cattle, sheep and goats. PLoS Neglected Trop. Dis. 2023, 17, e0010482. [Google Scholar] [CrossRef]
- Lu, T.; Cao, J.M.D.; Rahman, A.A.; Islam, S.S.; Sufian, M.A.; Martínez-López, B. Risk mapping and risk factors analysis of rabies in livestock in Bangladesh using national-level passive surveillance data. Prev. Vet. Med. 2023, 219, 106016. [Google Scholar] [CrossRef] [PubMed]
- Kracalik, I.T.; Kenu, E.; Ayamdooh, E.N.; Allegye-Cudjoe, E.; Polkuu, P.N.; Frimpong, J.A.; Nyarko, K.M.; Bower, W.A.; Traxler, R.; Blackburn, J.K. Modeling the environmental suitability of anthrax in Ghana and estimating populations at risk: Implications for vaccination and control. PLoS Neglected Trop. Dis. 2017, 11, e0005885. [Google Scholar] [CrossRef]
- Blackburn, J.K.; Matakarimov, S.; Kozhokeeva, S.; Tagaeva, Z.; Bell, L.K.; Kracalik, I.T.; Zhunushov, A. Modeling the ecological niche of Bacillus anthracis to map anthrax risk in Kyrgyzstan. Am. J. Trop. Med. Hyg. 2017, 96, 550. [Google Scholar] [CrossRef]
- Boender, G.J.; Hagenaars, T.J.; Bouma, A.; Nodelijk, G.; Elbers, A.R.W.; de Jong, M.C.M.; Van Boven, M. Risk maps for the spread of highly pathogenic avian influenza in poultry. PLoS Comput. Biol. 2007, 3, e71. [Google Scholar] [CrossRef] [PubMed]
- Willgert, K.J.; Schroedle, B.; Schwermer, H. Spatial analysis of bluetongue cases and vaccination of Swiss cattle in 2008 and 2009. Geospat. Health 2011, 5, 227–237. [Google Scholar] [CrossRef] [PubMed]
- Racloz, V.; Venter, G.; Griot, C.; Stärk, K. Estimating the temporal and spatial risk of bluetongue related to the incursion of infected vectors into Switzerland. BMC Vet. Res. 2008, 4, 42. [Google Scholar] [CrossRef] [PubMed]
- Caligiuri, V.; Giuliano, G.; Vitale, V.; Chiavacci, L.; Travaglio, S.; Manelli, L.; Piscedda, S.; Giardina, M.; Mainolfi, R. Bluetongue surveillance in the Campania region of Italy using a geographic information system to create risk maps. Vet. Ital. 2004, 40, 385–389. [Google Scholar] [PubMed]
- Giovannini, A.; Calistri, P.; Conte, A.; Savini, L.; Nannini, D.; Patta, C.; Santucci, U.; Caporale, V. Bluetongue virus surveillance in a newly infected area. Vet. Ital. 2004, 40, 188–197. [Google Scholar]
- Abdrakhmanov, S.K.; Beisembayev, K.K.; Sultanov, A.A.; Mukhanbetkaliyev, Y.Y.; Kadyrov, A.S.; Ussenbayev, A.Y.; Zhakenova, A.Y.; Torgerson, P.R. Modelling bluetongue risk in Kazakhstan. Parasites Vectors 2021, 14, 491. [Google Scholar] [CrossRef] [PubMed]
- Purse, B.V.; Mellor, P.S.; Rogers, D.J.; Samuel, A.R.; Mertens, P.P.; Baylis, M. Climate change and the recent emergence of bluetongue in Europe. Nat. Rev. Microbiol. 2005, 3, 171–181. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kappa | Sensitivity | Specificity | |
|---|---|---|---|
| Model 1 | |||
| Accuracy statistics | 0.54 ± 0.048 | 0.79 ± 0.033 | 0.74 ± 0.037 |
| Validation accuracy statistics | 0.20 ± 0.039 | 0.69 ± 0.094 | 0.66 ± 0.027 |
| Model 2 | |||
| Accuracy statistics | 0.84 ± 0.036 | 0.93 ± 0.02 | 0.94 ± 0.014 |
| Validation accuracy statistics | 0.67 ± 0.063 | 0.87 ± 0.062 | 0.90 ± 0.011 |
| Model 3 | |||
| Accuracy statistics | 0.84 ± 0.026 | 0.97 ± 0.013 | 0.96 ± 0.013 |
| Validation accuracy statistics | 0.64 ± 0.035 | 0.88 ± 0.069 | 0.91 ± 0.012 |
| nLST Variance | Biannual Amplitude of nLST | Minimum dLST | Biannual Phase of nLST | Mean EVI | Tri-Annual Phase of Nlst | Annual Phase of nLST | Mean NDVI | Variance of Dlst | Mean of dLST | Sample Size | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| P1 | 7.27 | 1.5 | 303.05 | 3.26 | 0.24 | 1.26 | 4.87 | 0.39 | 21.90 | 308.09 | 62 |
| P2 | 11.0 | 1.31 | 303.66 | 3.32 | 0.25 | 1.25 | 5.35 | 0.40 | 33.36 | 310.18 | 103 |
| P3 | 7.2 | 1.03 | 301.08 | 3.21 | 0.30 | 1.23 | 5.52 | 0.47 | 26.97 | 308.42 | 35 |
| A1 | 15.56 | 1.95 | 301.73 | 3.54 | 0.24 | 0.96 | 5.32 | 0.41 | 45.26 | 309.27 | 144 |
| A2 | 7.5 | 1.22 | 298.82 | 3.34 | 0.34 | 1.65 | 5.66 | 0.54 | 20.25 | 304.61 | 32 |
| A3 | 3 | 0.87 | 297.54 | 3.62 | 0.45 | 1.47 | 3.74 | 0.70 | 9.37 | 301.11 | 24 |
| Mean P | 9.18 | 1.32 | 303.02 | 3.28 | 0.26 | 1.25 | 5.23 | 0.41 | 28.69 | 309.22 | 200 |
| Mean A | 12.76 | 1.71 | 300.76 | 3.52 | 0.28 | 1.13 | 5.18 | 0.46 | 36.95 | 307.54 | 200 |
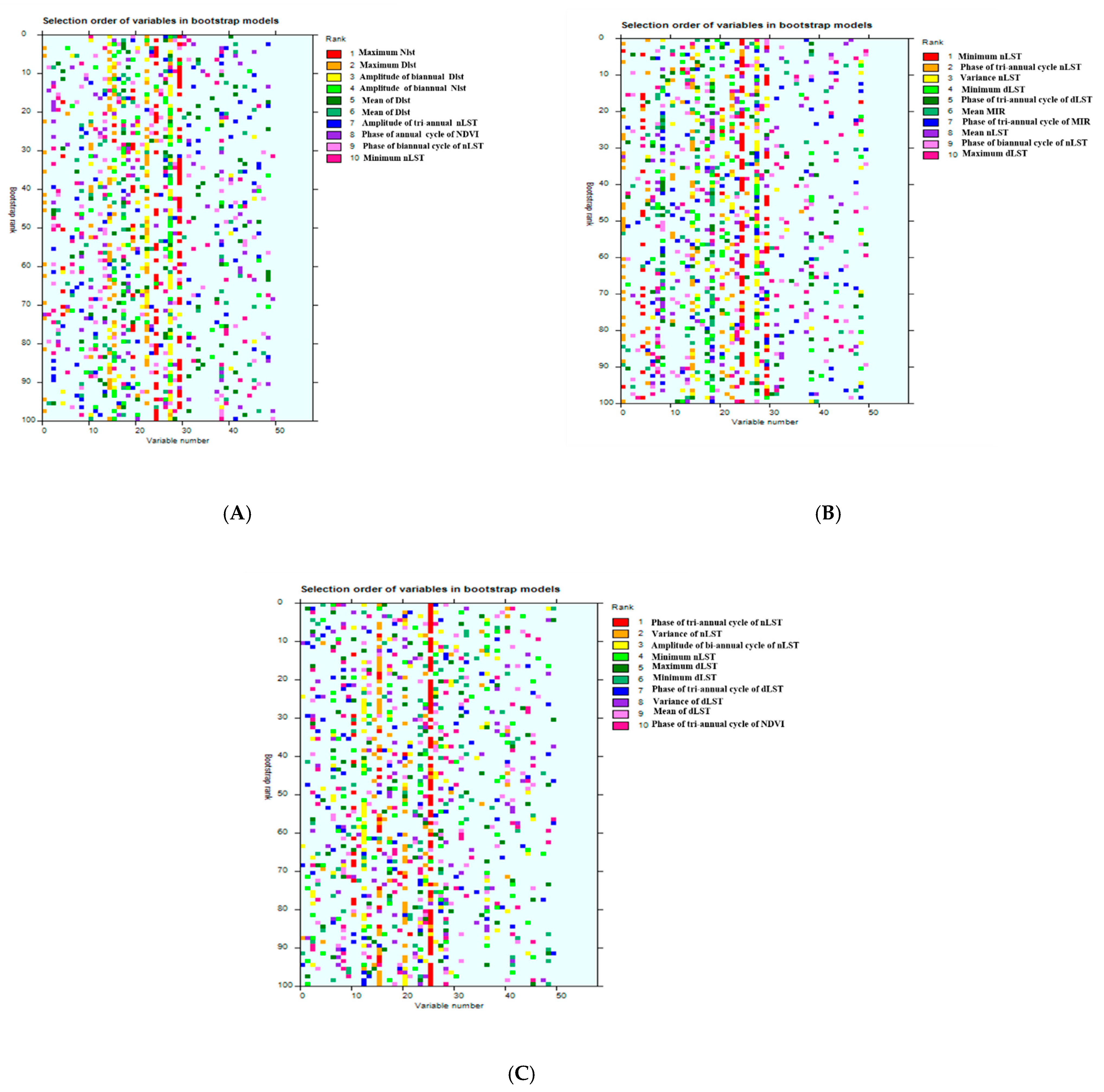
| Top Ten Variables in Model 1 | Top Ten Variables in Model 2 | Top Ten Variables in Model 3 | |
|---|---|---|---|
| 1 | Maximum nLST | Minimum nLST | Phase of tri-annual cycle of nLST |
| 2 | Maximum dLST | Phase of tri-annual cycle nLST | Variance of nLST |
| 3 | amplitude of biannual dLST | Variance nLST | Amplitude of biannual cycle of nLST |
| 4 | Amplitude of biannual nLST | Minimum dLST | Minimum nLST |
| 5 | Mean of Dlst | Phase of tri-annual cycle of dLST | Maximum dLST |
| 6 | Amplitude of tri-annual nLST | Mean MIR | Minimum dLST |
| 7 | Phase of biannual cycle of dLST | Phase of tri-annual cycle of MIR | Phase of tri-annual cycle of dLST |
| 8 | Phase of annual cycle of NDVI | Mean nLST | Variance of dLST |
| 9 | Phase of biannual cycle of nLST | Phase of biannual cycle of nLST | Mean of dLST |
| 10 | Minimum nLST | Maximum dLST | Phase of tri-annual cycle of NDVI |
| Predicted Category | ||||||||
|---|---|---|---|---|---|---|---|---|
| Observed category | P1 | P2 | P3 | A1 | A2 | A3 | Tot. | |
| P1 | 52 | 5 | 3 | 0 | 2 | 0 | 62 | |
| P2 | 9 | 87 | 7 | 0 | 0 | 0 | 103 | |
| P3 | 1 | 4 | 29 | 0 | 1 | 0 | 35 | |
| A1 | 1 | 1 | 0 | 139 | 2 | 1 | 144 | |
| A2 | 0 | 1 | 4 | 0 | 27 | 0 | 32 | |
| A3 | 0 | 0 | 0 | 0 | 1 | 23 | 24 | |
| Tot. | 63 | 98 | 43 | 139 | 33 | 24 | 400 | |
| Category | %Correct | %Producer’s Accuracy | %Consumer’s Accuracy |
|---|---|---|---|
| P1 | 83.87 | 83.87 | 82.54 |
| P2 | 84.47 | 84.47 | 88.78 |
| P3 | 82.86 | 82.86 | 67.44 |
| A1 | 96.53 | 96.53 | 100 |
| A2 | 84.38 | 84.38 | 81.82 |
| A3 | 95.83 | 95.83 | 95.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chanda, M.M.; Purse, B.V.; Sedda, L.; Benz, D.; Prasad, M.; Reddy, Y.N.; Yarabolu, K.R.; Byregowda, S.M.; Carpenter, S.; Prasad, G.; et al. Bluetongue Risk Map for Vaccination and Surveillance Strategies in India. Pathogens 2024, 13, 590. https://doi.org/10.3390/pathogens13070590
Chanda MM, Purse BV, Sedda L, Benz D, Prasad M, Reddy YN, Yarabolu KR, Byregowda SM, Carpenter S, Prasad G, et al. Bluetongue Risk Map for Vaccination and Surveillance Strategies in India. Pathogens. 2024; 13(7):590. https://doi.org/10.3390/pathogens13070590
Chicago/Turabian StyleChanda, Mohammed Mudassar, Bethan V. Purse, Luigi Sedda, David Benz, Minakshi Prasad, Yella Narasimha Reddy, Krishnamohan Reddy Yarabolu, S. M. Byregowda, Simon Carpenter, Gaya Prasad, and et al. 2024. "Bluetongue Risk Map for Vaccination and Surveillance Strategies in India" Pathogens 13, no. 7: 590. https://doi.org/10.3390/pathogens13070590
APA StyleChanda, M. M., Purse, B. V., Sedda, L., Benz, D., Prasad, M., Reddy, Y. N., Yarabolu, K. R., Byregowda, S. M., Carpenter, S., Prasad, G., & Rogers, D. J. (2024). Bluetongue Risk Map for Vaccination and Surveillance Strategies in India. Pathogens, 13(7), 590. https://doi.org/10.3390/pathogens13070590