Abstract
Modeling and analyzing human microbiome allows the assessment of the microbial community and its impacts on human health. Microbiome composition can be quantified using 16S rRNA technology into sequencing data, which are usually skewed and heavy-tailed with excess zeros. Clustering methods are useful in personalized medicine by identifying subgroups for patients stratification. However, there is currently a lack of standardized clustering method for the complex microbiome sequencing data. We propose a clustering algorithm with a specific beta diversity measure that can address the presence-absence bias encountered for sparse count data and effectively measure the sample distances for sample stratification. Our distance measure used for clustering is derived from a parametric based mixture model producing sample-specific distributions conditional on the observed operational taxonomic unit (OTU) counts and estimated mixture weights. The method can provide accurate estimates of the true zero proportions and thus construct a precise beta diversity measure. Extensive simulation studies have been conducted and suggest that the proposed method achieves substantial clustering improvement compared with some widely used distance measures when a large proportion of zeros is presented. The proposed algorithm was implemented to a human gut microbiome study on Parkinson’s diseases to identify distinct microbiome states with biological interpretations.
1. Introduction
Human microbiome carries complicated relationships among species yet profoundly connect with human health. Studies to understand of the effects of the microbiome on human diseases have been conducted recently. For example, evidence linking Parkinson’s disease to the gut microbiome is presented in Hill-Burns’ work [1]. The microorganisms in the human body consist of over 1000 species of bacteria [2,3]. Modern technology promotes the scope of microbiome research so that the massive microbiome data can be generated by 16S rRNA sequencing or shotgun metagenomic sequencing.
The microbiome data that is generated by the sequencing technology needs to be classified into taxonomic groups. The abundance of a species is quantified based on their similarity to operational taxonomic units (OTUs) and formed into discrete counts of sequence reads. Typical reads have excessive zeros due to either sampling errors or their unique features that only dominant microorganisms are shared among samples. Positive reads are usually skewed with extreme sparse count measures, which are called overdispersion. Traditional statistical methodologies encounter challenges in microbiome studies and result in potential bias [4,5,6].
An essential research question of microbiome study is to determine whether the microbiota can be stratified into subgroups. If so, how many groups are there, and how to interpret the strata, i.e., does the classification differentiate treatments, diseases, or genetic types. To answer these questions, the measurement of similarity between two microbial communities is desirable. Beta diversity has been proposed to fit diverse purposes, providing various results in assessing the differences between communities. For microbial composition, beta diversity measures the distance among communities based on measurement abundance, either observed counts or relative abundance, calculated based on a dissimilarity or distance measure to quantify the similarity between samples. Many non-parametric statistical methods have been developed to quantify distance measures. For instance, Euclidean and Manhattan distances are most commonly used. Other beta diversity metrics, such as Bray-Curtis Distance (BC) [7], Jensen-Shannon Distance (JS), Jaccard Index, UniFrac distances (unweighted [8], weighted [9], and generalized [10]) are also frequently applied in microbiome studies. Besides the distance metrics, graphical network models have also been introduced in Sparse Inverse Covariance Estimation for Ecological Association Inference (SPIEC-EASI [11,12]). The method applied a centered log-ratio transformation to the OTU data followed by either neighborhood selection or sparse inverse covariance selection to estimate the interaction graph. However, the method encounters difficulty in the underdetermined data regime. For example, the number of OTUs is much larger than the number of samples. In addition, SPIEC-EASI method relies on a single variance-covariance matrix which may not be able to completely recover the underlying OTU network due to the complex structure of the microbial community. In comparison, the mixture models are more flexible from the way of construction, and it may approximate the real distribution of taxa and lead to more accurate estimations of distances that are used in clustering.
The clustering of microbiome samples has been achieved in many studies using a variety of approaches. Clustering algorithms, including distance-based and parametric modeling, have been used to group subjects according to the microbiome samples. Two main types of distance-based approaches are hierarchical clustering [13,14,15] with different linkage options and discrete clusterings such as k-means [16,17,18,19] and Partition Around Medoids (PAM) [20,21,22,23]. Discrete clustering requires a pre-specified number of clusters while different linkages for hierarchical clustering such as Ward linkage, complete linkage, simple linkage, and average linkage provide rules to agglomerate. The Dirichlet-multinomial regression model [24] is the most frequently used on microbial metagenomic data for model-based clustering. Extensions such as the Sparse Dirichlet-multinomial regression technique [25] and finite mixtures of the Dirichlet-multinomial model [26,27] have been proposed to improve on different statistical aspects. These regression models investigate the relation between microbiome composition data and environmental or biological factors. However, currently, only a univariate analysis could be performed. On the other hand, distance-based clustering allows us to take multiple OTUs into account simultaneously.
For the clustering algorithms, it is critical to determine the optimal number of clusters K. Therefore, validation measures for clustering have been explored to identify the ideal number of groups K to represent data [28,29,30,31,32]. Validation indices are used to measure the quality of a clustering result in two ways: internal and external. An internal validation index is to use the information from the data only to decide the optimal number of clusters, such as the Silhouette width index [33], prediction strength [34], Calinski-Harabasz index [35], and Laplace approximation. Validation scores can be computed for different K, respectively, and then they identify the optimal K accordingly. An external validation index, on the other hand, uses prior knowledge to compare the predictive results.
There are different combinations of distance measures and algorithms. Koren et al. [23] computed the distances with and without the root square of the JS, BC, weighted and unweighted UniFrac distances and selected the number of clusters with the prediction strength and the silhouette index used in the PAM algorithm. Unlike Koren’s approach, Hong et al. [14] applied K-means with Euclidean distance to identify two clusters, in which they believe the number of clusters makes biologically sense in their study. It is noticeable that no standard clustering pipelines are available, and therefore the various approaches to the recognition of subgroups lead to widely different results. This phenomenon is more evident for microbiome datasets due to the features of microbial data—overdispersion and excessive zeros, which will cause more variations in the process of gathering microbiome into groups.
We develop an innovative clustering approach taking a mixture distribution, rather than a beta diversity metric, as the distance measure and applying a clustering algorithm to the microbiome data to characterize sub-populations. The algorithm also involves selecting the optimal number of clusters based on chosen internal indices, and the results are compared between several distance measures and different evaluation methods. The performance of the proposed algorithm is evaluated through comprehensive simulation studies and a real human gut microbiome dataset on Parkinson’s diseases.
2. Materials and Methods
A mixture model is a probabilistic model for representing subpopulations within an overall population, which are frequently used in unsupervised learning [36,37,38,39]. Simple distributions such as Binomial, Poisson, and Gaussian are occasionally unable to model more complex data. For instance, microbiome data may consist not only one mode (zeros and low counts), high probability mass for larger counts, and smaller probability mass for high counts. In this case, the data is better to be modelled in terms of a mixture of several components, where each component is a simple probabilistic distribution.
To deal with the unique characteristics of microbiome data—sparsity with abundant zeros, we incorporate a mixture model proposed by Shestopaloff [40] to attain the beta diversity measures for partition. The mixture model focuses on the distribution of a single OTU across a population which can address the problem of sparsity between samples. It parametrically models the counts’ underlying rate distribution, including low counts OTUs and extremely high counts. For pairwise distances between individual samples, the formulated mixture’s probability is used in norms distances.
By using such a model, the beta diversity measure contains information regarding zero part in the data and distinguishes between the structural and sampling zeros. The proposed mixture models assume the observed counts are from a Poisson distribution with individual-specific rates, and the rates are sampled from some general population distribution, which can be approximated by a set of mixture components. Conditional on the estimated population rate distribution, the subject-specific rate distribution is estimated through individual mixture distribution given the observed sample counts and resolution. After that, beta diversity measure can be calculated by assessing the pairwise differences between samples for a particular OTU using the individual mixture distribution.
2.1. Mixture Model
To introduce some notations for the following section, let be the number of times an OTU was observed from a sample, where i is the subject, and j is the OTU, . Resolution is the sum of the total reads of an individual; thus, it is defined as . To connect the general population distribution to the collected data, the rates can be scaled by the average total reads for OTU j, . Therefore, the relative resolution is defined as .
The mixture model consists of five components to accommodate the complexity of microbiome data. For individuals who are never disclosed to OTU j, the model assigns a zero point mass . For the rates close to zero, a set of adjacent left-skewed distributions with consecutive parameters is used to represent the low rates. For larger rates, the model accommodates a set of Gamma distribution with parameters which are all integers and are derived from the posterior of the Poisson rate given an observed count n, that is . For higher counts that are less dense, the parameters are defined by truncating the interval uniformly after transforming the data range by a log scale. Lastly, for the even higher counts which are too sparse, the model selects a sufficiently large cut-off point and combines all the observations greater than that point into a high point mass .
The parts other than zeros and extreme high point masses consist of several components with fixed parameters from Gamma distributions. Since each OTU’s distribution is estimated independently, we target one OTU per time and drop the subscript j onward. Define the estimated weights for each mixture components described above as where is the weight for zero point mass, where is the weight for the Gamma components, and is the weight for the high point mass. Weights estimation is utilized to compose the final mixture model and can be calculated by minimizing the squared differences between the observed aggregated counts and the expected ones. For a particular OTU, the observed aggregated counts can be expressed as , where k is the number of counts observed in a sample. The expected aggregated counts are the probability of observing k counts from each mixture component in a sample. For the Gamma components, counts are distributed in negative binomial distribution conditioned on the relative resolution . Define the probability of observing a count k from the mth mixture component conditional on is . The expected aggregate counts from all mixture components is
The estimate of weights is obtained by optimizing the objective function
and using bootstrap replicates to find an optimal set of models as mixture components. Details of the bootstrap approach can be found in Appendix A.
For each subject i, the probability density function (PDF) of the mixture model is defined as the product of the individual-specific mixture weights and the count probability from mixture components
where
and
2.2. Distance Measures
2.2.1. Norms Distances
After finalizing the mixture model distribution, distance measures can be calculated through the pairwise distances between samples using probability distribution. Three distance measures based on norms are considered for comparisons: discrete PDF norms (-D PDF), discrete CDF norms (-D CDF), and continuous CDF norms (-C CDF).
Given a mixture distribution’s PDF as and its cumulative density function (CDF) as for subject i, the distance of discrete PDF norms are computed by
for and , where . Similarly, the distance of discrete CDF norms can be calculated analogously using the cumulative density function instead of the PDF.
The continuous CDF norms can be calculated based on the CDF of two individual-specific mixture models. The -C CDF norms can be computed by
where is a matrix such that represents the two components in the mixture model. See details of the derivation in [40].
2.2.2. Other Distances
Other than the distance measures we obtained using the mixture model, some other metrics are selected for comparison, including two standard beta diversity metrics for any ecological distance-based measures, Manhattan and Euclidean distances, and three distance measures specific in microbiome analysis—Bray-Curtis measure, weighted, and generalized UniFrac distances. An unweighted UniFrac distance is not considered in this study since it does not contain taxa abundance information.
Let and , for , be the observed counts of OTU i in samples j and k, respectively. Let be the length of the branch i in a phylogenetic tree. The Euclidean distance is defined as
The Manhattan distance is defined as
The Bray-Curtis distance measure is defined as
The weighted UniFrac distance is defined as
And the generalized UniFrac distance is defined as
Note that due to possible zeros in the denominator in Equations (8)–(10), we add a sufficiently small number () in addition to the sum of observed counts. Sensitivity analysis was done and proved that adding a sufficiently small number in the denominator to avoid zeros does not affect the accuracy results.
2.3. Clustering Validation Indices
The clustering assessment utilizes the partition of data by quantifying the results of a clustering algorithm. The indices measure how well the clustering performed regarding both within and between clusters separability. Validation indices can be divided into internal indices and external assessments. When there are no standard labels of the data to evaluate the partition result, internal indices are considered as an assessment of the clustered data itself. Many internal validation indices have been proposed to choose the optimal number of clusters. The number of clusters is data-driven and is usually required to specify in advance by clustering algorithms. Approaches to select the optimal number for partition consider all possible choices that fit the algorithms and then find the best fit of the data after comparing indices. On the other hand, external assessment scores are calculated by directly comparing the partition results with the prior labels, given that the labels are not used in the model-building stage.
2.3.1. Internal Validation Indices
Among the internal indices, similarities are observed in different indices measures. The Dunn index (DI) [41] is a metric for evaluating the separability of within clusters and between clusters. It is the quotient of the minimal distance between points of different clusters and the most substantial within-cluster distance. Let be a cluster of vectors. The diameter of the cluster, which is the largest distance separating two points in cluster is calculated by . Consider as another cluster other than . Let be the inter-cluster distance metric for clusters and . It is measured by the distance between their closest points:
where in cluster and in . The Dunn index is defined as
2.3.2. External Validation Assessment Measures
The results from clustering can be quantified by two measures: accuracy and Jaccard index. Both only consider the results obtained by the optimal number of clusters. Accuracy is how close the clustering results compared to the true cluster index. It is defined as the proportion of correctly clustered subjects. Note that when the clustered number of group c is less than the true number of clusters k, the accuracy of c groups are considered. When c is greater than k, a combination of k out of c groups with the highest accuracy is adopted. Jaccard index measures similarity between the clustered results and the original cluster labels which are defined as the ratio of the number of correctly classified subjects (intersection of predicted and real sets) to the number of the total sample size of the two groups (union of two sets):
2.4. Partitioning Algorithms for Clustering
Partitioning Around Medoids (PAM) algorithm introduced by Kaufman [20], as produced clustering results of this paper, is an adaption of K-means clustering, yet more computational efficient [42] and more robust to the random noises in the data [43]. The aim of clustering for pre-specified K groups is approached in the partitioning algorithm by incorporating two phases: initialization of K medoids and refinement of the initial medoids within clusters. The algorithm takes a greedy search technique in the first step to locate the K medoids in the data with the least computation. Then it uses a swap operation within the neighborhood in the second phase to minimize the objective function
where is the cluster containing object m and is the sum of the distances from object j to the closest medoid m.
PAM follows steepest-ascent hill climber algorithm, which can be summarized as follows:
- Initialize: randomly choose K of the n points in the dataset to be the initial cluster medoids.
- Assign each data point to the closest medoid based on distance.
- Refine: for each medoid m and non-medoid data point j, swap j and m and compute the total cost by the new medoid j. Select the best medoid in terms of minimum cost.
- Repeat steps 2 and 3 until all the medoids are fixed.
A flowchart can be found in Figure 1. PAM selects the points from the original data as medoids, which reduces the difficulty in explaining the cluster. Computation time can be saved by pre-calculating a distance matrix for all the data points. Then in the swap procedure for every iteration, scanning the matrix could be quickly done. In addition, as the refinement phase in step 3 is slow, re-calculation of the distance from only the points that have been moved between clusters to the new medoids in each iteration helps boost efficiency. For all the remaining points, distances can be re-used in objective function calculation.

Figure 1.
A flowchart to illustrate PAM algorithm for two clusters.
The Algorithm 1 shows the detailed steps of the proposed clustering procedure using the mixture distribution.
| Algorithm 1: for clustering based on joint mixture distribution: |
|
2.5. Simulation Studies
We conduct extensive simulation studies to evaluate the performance of the proposed algorithm with selected internal validation indices to finalize the optimal number of clusters for the clustering algorithm. To test how well the method performs in clustering, we derive the accuracy and the Jaccard index.
We simulate the data to mimic the OTU counts and their complex structure with class labels. We consider two scenarios with two sub-classes and three sub-classes, and each sub-class contains 200 subjects for total sample sizes of 400 and 600, respectively. All the results are replicated 100 times.
The simulation procedure for each OTU is as follows:
- Determine the number of rates in each sub-class using
- Generate the rate distribution in each sub-class from a mixture distribution with M components including a zero point mass and Gamma distributions. The number M is randomly chosen between 5 and 15.
- Sample the number of rates from where is the sample size for sub-class c.
- Sample for each subject from a .
- Generate the observed count .
For each scenario, 25 OTUs are simulated. The simulated count data contains three sets of zero proportions (ZP), first set with 13–27% zeros (low ZP) in each sub-class, second set with 39–61% zeros (medium ZP), and third set with 84–93% zeros (high ZP), to examine clustering performance under different ZP scenarios. ZP in every dataset is controlled by varying in Beta distribution from Step 1. The details of the mixture distribution estimation can be found in Appendix B.
3. Results
Simulation Results
Figure 2 and Figure 3 show the clustering results of simulated datasets under different scenarios with varying ZPs and number of sub-classes. The distance-based algorithm performance is evaluated through the accuracy and the Jaccard index and presented in boxplots. Specifically, L2.d.pdf, L2.d.cdf, L2.c.cdf, Manhattan, Euclidean, BC, wUniFrac, and gUniFrac represent the clustering results from a distance calculated by the mixture model using norms with discrete variable’s PDF, discrete variable’s CDF, continuous variable’s CDF, Manhattan distance, Euclidean distance, Bray-Curtis distance, weighted UniFrac distance, and generalized UniFrac distance, respectively. All the distances were calculated based on the relative abundance data. We conducted additional simulations to calculate the Manhattan, Euclidean, and Bray-Curtis distances after log-transformation. As we explained in methodology, since unweighted UniFrac distances neglect the abundance information and only consider presence/absence of species of branches in a phylogenetic tree, it is not included in the simulation studies. The top three boxplots in Figure 2 illustrate the accuracy of eight comparative distance metrics for high, medium, and low ZP scenarios when the simulated dataset contains two sub-classes. The bottom three boxplots are the accuracy of the 3-subclass simulation scenario. Our proposed distance measures are marked in green as opposed to the other distance metrics in blue. Jaccard index boxplots (Figure 3) are constructed in the same way as in Figure 2. Mean accuracy (MA) and mean Jaccard index (MJI) are shown in Table 1, calculated by averaging the 100 replicates results in each scenario.
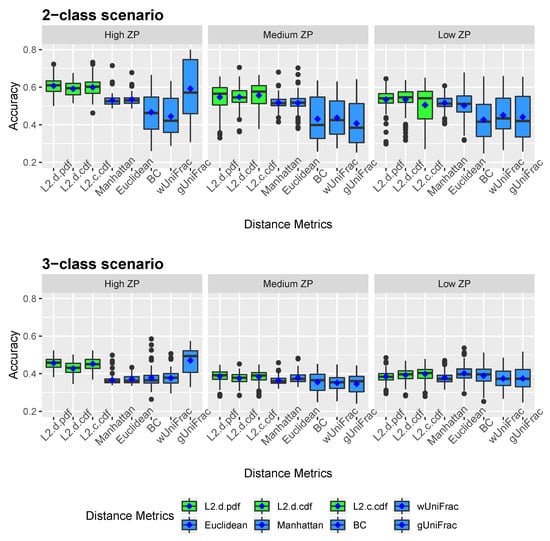
Figure 2.
Accuracy boxplots for simulated data. Two-subclass and three-subclass scenarios are considered. Three different cases of proportion of zeros (ZP) are evaluated - high ZP, medium ZP, and low ZP, are presented in left, middle, and right, respectively. For each box of the boxplots, the center line represents the median, the two vertical lines represent the 25th percentiles to the 75th percentiles. The whiskers of the boxplots show 1.5 interquartile range (IQR) below the 25th percentiles and 1.5 IQR above the 75th percentiles. The mean are shown in blue diamond dots.
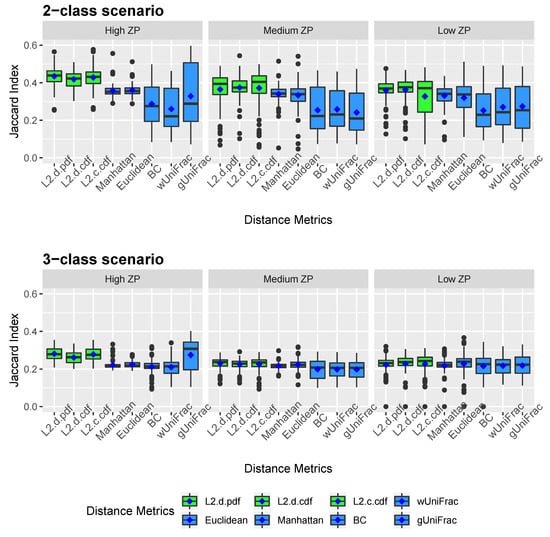
Figure 3.
Jaccard index boxplots for simulated data. Two-subclass and three-subclass scenarios are considered. Three different cases of proportion of zeros (ZP) are evaluated - high ZP, medium ZP, and low ZP, are presented in left, middle, and right, respectively. For each box of the boxplots, the center line represents the median, the two vertical lines represent the 25th percentiles to the 75th percentiles. The whiskers of the boxplots show 1.5 interquartile range (IQR) below the 25th percentiles and 1.5 IQR above the 75th percentiles. The mean are shown in blue diamond dots.

Table 1.
Mean accuracy (MA) and mean Jaccard index (MJI) estimations. A bold value represents the best cases under each scenario. Distances calculation was conducted on the simulated data inputs with and without log-transformation: Manhattan_log, Euclidean_log, Bray-Curtis_log were models using log-transformation, while -D PDF, -D CDF, -C CDF, Manhattan, Euclidean, Bray-Curtis, weighted UniFrac, and generalized UniFrac were without log-transformation.
We observed that by implementing the proposed distance measures in the clustering algorithm, both accuracy and Jaccard index outperform the results by other distance metrics, especially when the datasets contain a substantial amount of zeros. Clustering using the three proposed norms in both 2-subclass and 3-subclass scenarios has considerable improvements with the increase of zero proportions in the datasets. The mean accuracy calculated based on 100 replicates achieves around 0.6 for the proposed norms under high ZP design in 2-subclass scenarios and 0.45 in 3-subclass scenarios. For scenarios with fewer zeros, the -norm distance measures have competitive clustering performance as the competing distance metrics. Among the three norms, the discrete PDF distance has better clustering performance across ZP settings. Out of six settings that we investigated in the 3-subclass scenario, the generalized UniFrac distance and the Manhattan distance with log-transformation provide the best partition with a high and low proportion of zeros, respectively. In contract, the norms show advantages in terms of MA and MJI in the rest of scenarios. Noticeably, the generalized UniFrac distance shows a large variability in the estimation of accuracy. Overall, Manhattan, Euclidean, Bray-Curtis, and weighted UniFrac distance metrics do not distinguish the proportion of zeros in 2-subclass datasets and provide close to the random guess accuracy of 0.5 in 2-subclass scenarios. Jaccard index reveals a similar pattern as accuracy.
The average number of clusters over all the iterations are presented in Table 2. The -D CDF norm predicts the number of clusters the most accurate in 2-subclass scenarios. On the other hand, generalized UniFrac distance and Manhattan distance with log transformation have closer prediction to the actual cluster numbers in the 3-subclass scenarios. However, Bray-Curtis, weighted UniFrac, and generalized UniFrac distances overestimate number of clusters dramatically in the two-subclass situations. Thus, the results in three-subclass scenarios are doubtful to some extent.
Table 2.
Average number of clusters for all simulation scenarios. Optimal number of clusters in each replicate is calculated by Dunn internal indices. A bold value represents the closest estimation of number of clusters to the ground truth.
4. Real Data Implementation
To demonstrate how well our proposed method works, we analyze the data from Hill-Burns et al. [1] that relates the gut microbiome to Parkinson’s disease (PD). The dataset contains stool samples of 197 PD cases and 130 controls. 16S rRNA amplicon sequencing of DNA was extracted for microbial composition performed by Illumina MiSeq. OTUs were picked using a reference of Greengenes 16S rRNA gene sequence database [44] at 97% similarity released in August 2013. The study has shown the association between the dysbiosis of gut microbiome and PD. Besides, the case-only analysis identifies a significant interaction effect between the microbiome and PD medications, including catechol-O-methyl transferase (COMT) inhibitors, anticholinergics, and carbidopa/levodopa.
We apply our algorithm to the PD cases to explore the sub-populations of the PD using gut mirobiome data. The pre-processing step is done by including OTUs on the genus level and excluding ones with the probability of zero relative abundances higher than 80%, resulting in a total of 280 OTUs used for all the samples in our analysis. We compare the proposed norms with the other three distance metrics with and without log-transformation on the relative abundance data. Various internal indices are applied to distance measures for sensitivity analysis. Selection results of the number of clusters are illustrated in Table 3. The maximum number of clusters is set to ten, meaning that the optimal number is between 2 and 10. Different combinations of distances and internal indices provide moderate variations. For Dunn and Xie-Beni [45] indices, norms tend to cluster the data into two or three subgroups while in both with and without log-transformation situations, Manhattan, Euclidean, and Bray-Curtis metrics prefer more clusters except for non-transformed Euclidean distance. Wemmert-Gancarski index provides fewer subgroups than the others across the distance measures. No profound trend is found for the Silhouette index.
Table 3.
Mean with standard deviation and median for OTUs that are significantly different ( 0.001) between two clusters using Dunn internal indices and -D PDF distance.
To illustrate the clustering algorithm, the -D PDF norm is selected as an example for further analysis. We explore OTUs between two clusters for the dataset, and the top 5 significantly different OTUs between clusters are Akkermansia, Anaerotruncus, Bacteroides, Anaerococcus, and Akkermansia. Among these OTUs, Akkermansia [1,46] has previous reported associations. The characteristics of the five OTUs are summarized in Table 4.
Table 4.
Optimal number of clusters for distance metrics by various internal indices.
5. Discussion
We simulate six different scenarios to evaluate the performance of the proposed method thoroughly, using the accuracy and the Jaccard index to reflect clustering results, considering different zero proportions under 2-subclass and 3-subclass settings. Both the accuracy and the Jaccard index are improved or competitive compared to other distance metrics, suggesting better separation among subgroups. Our method performs the best in high and medium zero proportion scenarios, therefore, it is recommended to use our clustering algorithm when a large number of zeros presenting in the data. Under the PAM framework, all distance matrices (Manhattan, Euclidean, Bray-Curtis, and UniFrac) can be used as inputs for clustering. However, as shown in our simulation studies, the pairwise distances calculated by the mixture model perform better than the other distance matrices under a variety of scenarios.
The clustering algorithm involves multiple options, such as the choice of distance measures, the internal indices to specify the number of clusters, and the approach to clustering. Due to a lack of widely accepted standardization, making different choices at each step may lead to various outcomes. Many choices are available regarding the selection of the number of clusters. The decision to make about the optimal number of clusters each time highly relies on data structure, thus case-specific. As we choose to use the Dunn index as internal validation indices for simulation studies, sensitivity analysis is performed using other internal indices. All the considered indices are also compared in real data. Our algorithm classifies subgroups among the PD cases and presented the ability to identify statistically significant distinct OTUs which have association with PD.
The proposed method focuses on distance-based clustering. The next step is to perform partition based on models such as Dirichlet-multinomial and compare with our method. We will also explore the possibility of extending the proposed method to adopt longitudinal trajectories of subjects for deep insights into the dynamic biological mechanisms. The proposed method could be easily extended to high dimensional data with overdispersion. Besides that, we are working on the extension of this proposed method on other microbiome and disease correlation data.
As all clustering methods, one limitation of this algorithm is that suitable internal indices are hard to select for every new data. Thus an optimal and robust number of clusters is difficult to obtain. Besides, for the -norm distances, variable selection is not possible to be developed in clustering. Nevertheless, the proposed algorithm incorporates ad-hoc distance for microbial sequencing data, which provides effective clustering and broader vision to investigate the connection between the microbiome and human health. The introduced clustering algorithm can be seen as a good additional tool for the analysis of microbial data besides the currently used methods.
6. Conclusions
In this article, we propose a distance-based unsupervised machine learning method to cluster subjects based on their microbial structure. We show that our method provide funtional partitions among subjects under various scenarios in simulation studies, and we apply it to a gut microbiome dataset for Parkinson’s disease. The distance measures we adopted in the clustering algorithm are capable of capturing the underlying rate distributions of microbial counts, through mixture distributions which take account to zero inflation and overdispersed values. norms are calculated based on the mixture distributions’ PDF and CDF, respectively, and further used in partition around mediod for clustering.
Author Contributions
Conceptualization, D.Y. and W.X.; methodology, data collection and analysis, D.Y.; experimental design and supervision, W.X.; writing-original draft preparation, D.Y.; writing-review and editing, D.Y. and W.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Canadian Institutes of Health Research (CIHR Grant 145546) Natural Sciences and Engineering Research Council of Canada (NSERC Grant RGPIN201706672), Crohns and Colitis Canada (CCC Grant CCCGEMIII), CANSSI Ontario Strategic Training for Advanced Genetic Epidemiology (STAGE) Program, and Edwin S.H. Leong Scholarship.
Acknowledgments
We would like to thank Konstantin Shestopaloff and Mei Dong for discussion in this work.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| OTU | operational taxonomic unit |
| BC | Bray-Curtis distance |
| JS | Jenson-Shannon distance |
| PAM | partition around medoids |
| DI | Dunn index |
| MA | mean accuracy |
| MJI | mean Jaccard index |
| PD | Parkinson’s disease |
Appendix A. Mixture Model
Appendix A.1. Individual Mixture Distribution Estimation
A non-parametric bootstrap is adopted to estimate a mixture model with a practical consideration to avoid overspecified and overfitted bootstrap data. The selection of the best model among all bootstrap datasets is unnecessary since the final model will be a set of weighted optimal models from all the datasets so that every component can be incorporated in the estimation. Define a set of models with different mixture components combination. Sample B subsets from the original data and estimate weights for each model l and subset b. In each bootstrap dataset, the estimated aggregated counts for model l are compared with the observed aggregated counts through the distance for and the best model with minimum distance is chosen in subset b. The selected optimal model has weight , and the weight for each component in the mixture distribution is .
Once we have an estimate of the mixture component weights for the final set of mixture components , the individual-specific mixture probabilities condition on can be obtained for each component. Specifically, the probability of observing counts k from subject i being from each mixture component can be written as
Denote the individual-specific mixture weights as , and weights are calculated as . Since the model components remains the same for all the samples, the individual-specific mixture weights become the only variation to compute pairwise distances among samples. Hence distances are calculated based on two parts, individual weights and the probability of an observed count through Poisson-Gamma mixture probabilities from mixture component . The probability of observing count k from mixture component , is
Note that the distribution can estimate structural and non-structural zeros separately, where is for structure zeros and is for non-structure zeros.
Appendix B. Simulation
Appendix B.1. Mixture Distribution Estimation
The underlying mixture distributionis modeled with pre-set four parts to estimate the simulated data.
- Low rate part: set five Gamma distribution , and five models, with the first model including all the distributions, the second model including the last 4 distributions, until the fifth model including only the last Gamma distribution;
- Medium rate part: one model with four Gamma distribution ;
- Higher rate part: one model with three Gamma distribution ; each value in Gamma distribution is chosen by uniformly binned the OTUs on a log-transformed scale from 8% to the 85% quantile;
- High count part: a point mass which combines all the counts greater than the 85% quantile.
The estimation of the joint model is replicated through 300 bootstraps. The estimates of weights in the model are obtained by minimizing the least squares objective function using the Broyden- Fletcher-Goldfarb-Shanno algorithm [47]. We used R packages NLoptr [48] for the model estimation, and cluster [49] and clustCrit [50] for comparison of clustering performance between distance measures.
The appendix is an optional section that can contain details and data supplemental to the main text. For example, explanations of experimental details that would disrupt the flow of the main text, but nonetheless remain crucial to understanding and reproducing the research shown; figures of replicates for experiments of which representative data is shown in the main text can be added here if brief, or as Supplementary data. Mathematical proofs of results not central to the paper can be added as an appendix.
References
- Hill-Burns, E.M.; Debelius, J.W.; Morton, J.T.; Wissemann, W.T.; Lewis, M.R.; Wallen, Z.D.; Peddada, S.D.; Factor, S.A.; Molho, E.; Zabetian, C.P.; et al. Parkinson’s disease and Parkinson’s disease medications have distinct signatures of the gut microbiome. Mov. Disord. 2017, 32, 739–749. [Google Scholar] [CrossRef] [PubMed]
- Falony, G.; Joossens, M.; Vieira-Silva, S.; Wang, J.; Darzi, Y.; Faust, K.; Kurilshikov, A.; Bonder, M.J.; Valles-Colomer, M.; Vandeputte, D. Population-level analysis of gut microbiome variation. Science 2016, 352, 560–564. [Google Scholar] [CrossRef] [PubMed]
- Zhernakova, A.; Kurilshikov, A.; Bonder, M.J.; Tigchelaar, E.F.; Schirmer, M.; Vatanen, T.; Mujagic, Z.; Vila, A.V.; Falony, G.; Vieira-Silva, S.; et al. Population-based metagenomics analysis reveals markers for gut microbiome composition and diversity. Science 2016, 352, 565–569. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Paterson, A.D.; Turpin, W.; Xu, W. Assessment and selection of competing models for zero-inflated microbiome data. PLoS ONE 2015, 10, e0129606. [Google Scholar] [CrossRef]
- Zhang, X.; Mallick, H.; Tang, Z.; Zhang, L.; Cui, X.; Benson, A.K.; Yi, N. Negative binomial mixed models for analyzing microbiome count data. BMC Bioinform. 2017, 18, 4. [Google Scholar] [CrossRef]
- Fisher, C.K.; Mehta, P. Identifying keystone species in the human gut microbiome from metagenomic timeseries using sparse linear regression. PLoS ONE 2014, 9, e102451. [Google Scholar] [CrossRef]
- Bray, J.R.; Curtis, J.T. An ordination of the upland forest communities of southern Wisconsin. Ecol. Monogr. 1957, 27, 326–349. [Google Scholar] [CrossRef]
- Lozupone, C.; Knight, R. UniFrac: A new phylogenetic method for comparing microbial communities. Appl. Environ. Microbiol. 2005, 71, 8228–8235. [Google Scholar] [CrossRef]
- Lozupone, C.A.; Hamady, M.; Kelley, S.T.; Knight, R. Quantitative and qualitative β diversity measures lead to different insights into factors that structure microbial communities. Appl. Environ. Microbiol. 2007, 73, 1576–1585. [Google Scholar] [CrossRef]
- Chen, J.; Kyle, B.; Emily, S.; Charlson, C.; Hoffmann, J. Associating microbiome composition with environmental covariates using generalized UniFrac distances. Bioinformatics 2012, 28, 2106–2113. [Google Scholar] [CrossRef]
- Zachary, D.; Christian, L.; Emily, R.; Dan, R.; Martin, J. Sparse and compositionally robust inference of microbial ecological networks. PLoS Comput. Biol. 2015, 11, e1004226. [Google Scholar]
- Tsilimigras, M.C.B.; Fodor, A.A. Compositional data analysis of the microbiome: Fundamentals, tools, and challenges. Ann. Epidemiol. 2016, 26, 330–335. [Google Scholar] [CrossRef]
- Forney, L.J.; Gajer, P.; Williams, C.J.; Schneider, G.M.; Koenig, S.S.; McCulle, S.L.; Karlebach, S.; Brotman, R.M.; Davis, C.C.; Ault, K.; et al. Comparison of self-collected and physician-collected vaginal swabs for microbiome analysis. J. Clin. Microbiol. 2010, 48, 1741–1748. [Google Scholar] [CrossRef] [PubMed]
- Hong, B.Y.; Araujo, M.V.F.; Strausbaugh, L.D.; Terzi, E.; Ioannidou, E.; Diaz, P.I. Microbiome profiles in periodontitis in relation to host and disease characteristics. PLoS ONE 2015, 10, e0127077. [Google Scholar] [CrossRef]
- Leake, S.L.; Pagni, M.; Falquet, L.; Taroni, F.; Greub, G. The salivary microbiome for differentiating individuals: Proof of principle. Microbes Infect. 2016, 18, 399–405. [Google Scholar] [CrossRef] [PubMed]
- Neyman, J. Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability: Held at the Statistical Laboratory, University of California, 21 June–18 July 1970, 9–12 April, 16–21 June, 19–22 July 1971; University of California Press: Berkeley, CA, USA, 1972. [Google Scholar]
- Gury-BenAri, M.; Thaiss, C.A.; Serafini, N.; Winter, D.R.; Giladi, A.; Lara-Astiaso, D.; Levy, M.; Salame, T.M.; Weiner, A.; David, E.; et al. The spectrum and regulatory landscape of intestinal innate lymphoid cells are shaped by the microbiome. Cell 2016, 166, 1231–1246. [Google Scholar] [CrossRef] [PubMed]
- Poole, A.C.; Goodrich, J.K.; Youngblut, N.D.; Luque, G.G.; Ruaud, A.; Sutter, J.L.; Waters, J.L.; Shi, Q.; El-Hadidi, M.; Johnson, L.M.; et al. Human salivary amylase gene copy number impacts oral and gut microbiomes. Cell Host Microbe 2019, 25, 553–564. [Google Scholar] [CrossRef] [PubMed]
- Maia, M.C.; Poroyko, V.; Won, H.; Almeida, L.; Bergerot, P.G.; Dizman, N.; Hsu, J.; Jones, J.; Salgia, R.; Pal, S.K. Association of Microbiome and Plasma Cytokine Dynamics to Nivolumab Response in Metastatic Renal Cell Carcinoma (mRCC). J. Clin. Oncol. 2018, 36, 656. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Partitioning around medoids (program pam). Find. Groups Data Introd. Clust. Anal. 1990, 344, 68–125. [Google Scholar]
- Arumugam, M.; Raes, J.; Pelletier, E.; Le Paslier, D.; Yamada, T.; Mende, D.R.; Fernandes, G.R.; Tap, J.; Bruls, T.; Batto, J.M.; et al. Enterotypes of the human gut microbiome. Nature 2011, 473, 174–180. [Google Scholar] [CrossRef]
- McMurdie, P.J.; Holmes, S. Waste not, want not: Why rarefying microbiome data is inadmissible. PLoS Comput. Biol. 2014, 10, e1003531. [Google Scholar] [CrossRef] [PubMed]
- Koren, O.; Knights, D.; Gonzalez, A.; Waldron, L.; Segata, N.; Knight, R.; Huttenhower, C.; Ley, R.E. A guide to enterotypes across the human body: Meta-analysis of microbial community structures in human microbiome datasets. PLoS Comput. Biol. 2013, 9, e1002863. [Google Scholar] [CrossRef] [PubMed]
- Wu, G.D.; Chen, J.; Hoffmann, C.; Bittinger, K.; Chen, Y.Y.; Keilbaugh, S.A.; Bewtra, M.; Knights, D.; Walters, W.A.; Knight, R.; et al. Linking long-term dietary patterns with gut microbial enterotypes. Science 2011, 334, 105–108. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Li, H. Variable selection for sparse Dirichlet-multinomial regression with an application to microbiome data analysis. Ann. Appl. Stat. 2013, 7, 418–442. [Google Scholar] [CrossRef]
- Holmes, I.; Harris, K.; Quince, C. Dirichlet multinomial mixtures: Generative models for microbial metagenomics. PLoS ONE 2012, 7, e30126. [Google Scholar] [CrossRef]
- Feng, Z.; Subedi, S.; Neish, D.; Bak, S. Cluster Analysis of Microbiome Data via Mixtures of Dirichlet-Multinomial Regression Models. J. R. Stat. Soc. Ser. C (Appl. Stat.) 2015, 69, 1163–1187. [Google Scholar]
- Calinski, T.; Harabasz, J. A Dendrite Method for Cluster Analysis. Comm. Stat. Simulat. Comp. 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Strehl, A.; Ghosh, J. Cluster Ensembles—A Knowledge Reuse Framework for Combining Multiple Partitions. J. Mach. Learn. Res. 2003, 3, 583–617. [Google Scholar]
- Zhao, Q.; Franti, P. WB-index: A sum-of-squares based index for cluster validity. Data Knowl. Eng. 2014, 92, 77–89. [Google Scholar] [CrossRef]
- Joonas, H.; Susanne, J.; Tommi, K. Comparison of Internal Clustering Validation Indices for Prototype-Based Clustering. Algorithms 2017, 10, 105. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Tibshirani, R.; Walther, G. Cluster validation by prediction strength. J. Comput. Graph. Stat. 2005, 14, 511–528. [Google Scholar] [CrossRef]
- Hennig, C.; Liao, T.F. Comparing Latent Class and Dissimilarity Based Clustering for Mixed Type Variables with Application to Social Stratification; Research Report No. 308; Department of Statistical Science, University College London: London, UK, 2010. [Google Scholar]
- Figueiredo, M.A.T.; Jain, A.K. Unsupervised learning of finite mixture models. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 381–396. [Google Scholar] [CrossRef]
- Bouguila, N.; Ziou, D.; Vaillancourt, J. Unsupervised learning of a finite mixture model based on the Dirichlet distribution and its application. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2004, 13, 1533–1543. [Google Scholar] [CrossRef]
- Xu, P.; Peng, H.; Huang, T. Unsupervised Learning of Mixture Regression Models for Longitudinal Data. Comput. Stats Data Anal. 2018, 125, 44–56. [Google Scholar] [CrossRef]
- Mohamed, M.B.I.; Frigui, H. Unsupervised clustering and feature weighting based on Generalized Dirichlet mixture modeling. Inf. Sci. 2014, 274, 35–54. [Google Scholar]
- Shestopaloff, K.; Escobar, M.D.; Xu, W. Analyzing differences between microbiome communities using mixture distributions. Stat. Med. 2018, 37, 4036–4053. [Google Scholar] [CrossRef]
- Dunn, J.C. A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters. J. Cybern. 1973, 3, 32–57. [Google Scholar] [CrossRef]
- García-Jiménez, B.; Wilkinson, M.D. Robust and automatic definition of microbiome states. PeerJ 2019, 7, e6657. [Google Scholar] [CrossRef]
- Struyf, A.; Hubert, M.; Rousseeuw, P.J. Integrating robust clustering techniques in S-PLUS. Comput. Stat. Data Anal. 1997, 26, 17–37. [Google Scholar] [CrossRef]
- McDonald, D.; Price, M.N.; Goodrich, J.; Nawrocki, E.P.; DeSantis, T.Z.; Probst, A.; Andersen, G.L.; Knight, R.; Hugenholtz, P. An improved Greengenes taxonomy with explicit ranks for ecological and evolutionary analyses of bacteria and archaea. ISME J. 2012, 6, 610–618. [Google Scholar] [CrossRef] [PubMed]
- Xie, X.L.; Beni, G. A validity measure for fuzzy clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 841–847. [Google Scholar] [CrossRef]
- Keshavarzian, A.; Green, S.J.; Engen, P.A.; Voigt, R.M.; Naqib, A.; Forsyth, C.B.; Mutlu, E.; Shannon, K.M. Colonic bacterial composition in Parkinson’s disease. Mov. Disord. 2015, 30, 1351–1360. [Google Scholar] [CrossRef]
- Nocedal, J. Updating quasi-Newton matrices with limited storage. Math. Comput. 1980, 35, 773–782. [Google Scholar] [CrossRef]
- Ypma, J. Introduction to Nloptr: An R Interface to NLopt. R Package. 2 August 2014. Available online: https://docplayer.net/39407286-Introduction-to-nloptr-an-r-interface-to-nlopt.html (accessed on 20 October 2020).
- Maechler, M.; Rousseeuw, P.; Struyf, A.; Hubert, M.; Hornik, K. Cluster: Cluster Analysis Basics and Extensions. R Package Version 2.0.1. 2015. Available online: https://www.scirp.org/(S(lz5mqp453edsnp55rrgjct55))/reference/ReferencesPapers.aspx?ReferenceID=2062247 (accessed on 20 October 2020).
- Desgraupes, B. Clustering indices. Univ. Paris Ouest-Lab Modal X 2013, 1, 34. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).