
Action Recognition Using a Spatial-Temporal Network for Wild Felines






Abstract
:Simple Summary
Abstract
1. Introduction
- We propose a novel two-stream architecture that incorporates spatial and temporal networks for wild feline action recognition. The two-stream network architecture combines the advantages of both the outline features for static action detection and the moving features of the leg skeleton for moving action detection.
- We build a Tiny VGG network for classifying the outline features extracted by Mask R-CNN. This method can improve the robustness against complex environments due to Mask R-CNN. The Tiny VGG network can also reduce the number of network parameters and avoid overfitting.
- We present a skeleton-based action recognition model for wild felines. The bending angle fluctuation amplitude of knee joints in a video clip is used as the temporal feature to represent three different upright actions. This model can improve the performance of moving action recognition based on the temporal features, particularly when the animals are occluded by many objects, such as growing plants, fallen trees, and so on.
2. Related Work
3. Methods and Materials
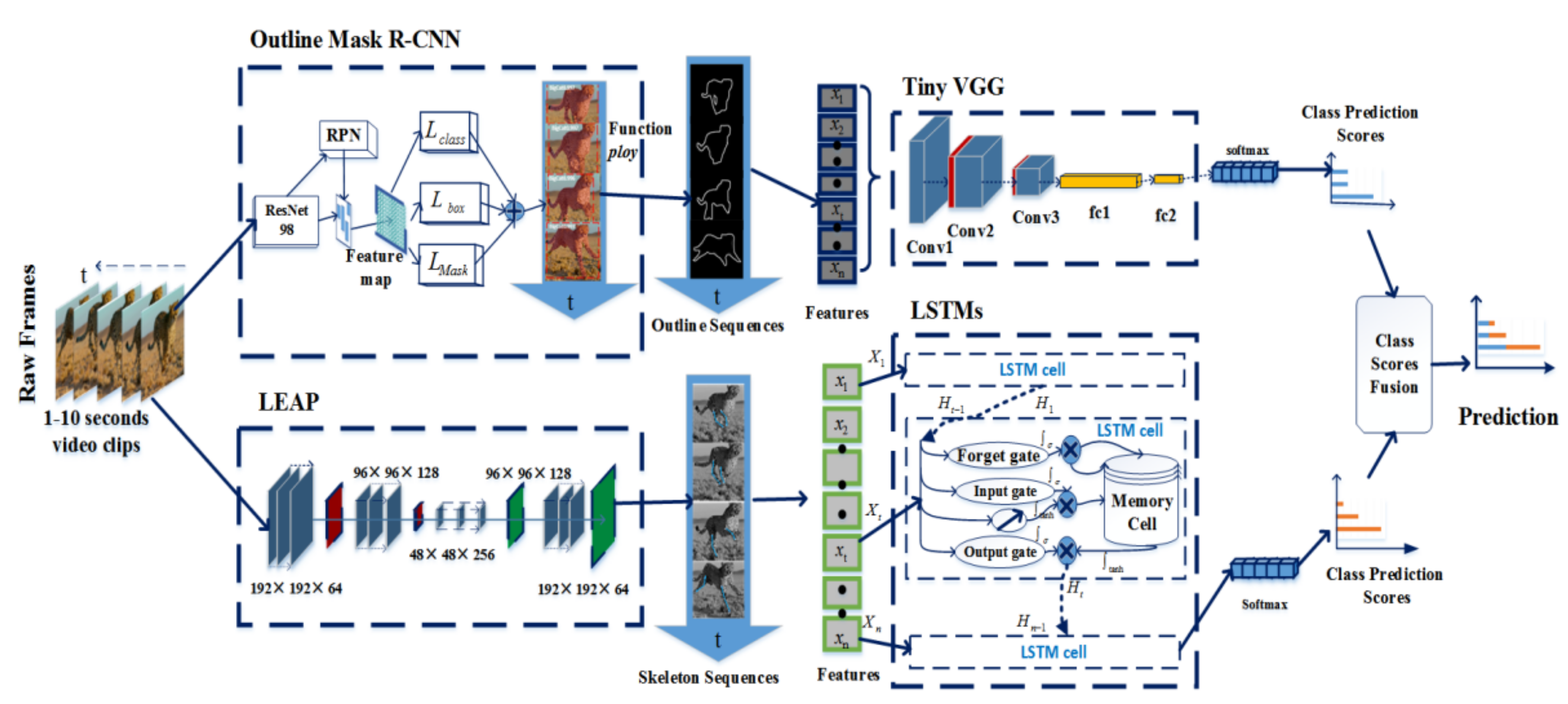
3.1. Pipeline Overview
3.2. Construction of the Outline Model
3.2.1. Outline Mask RCNN
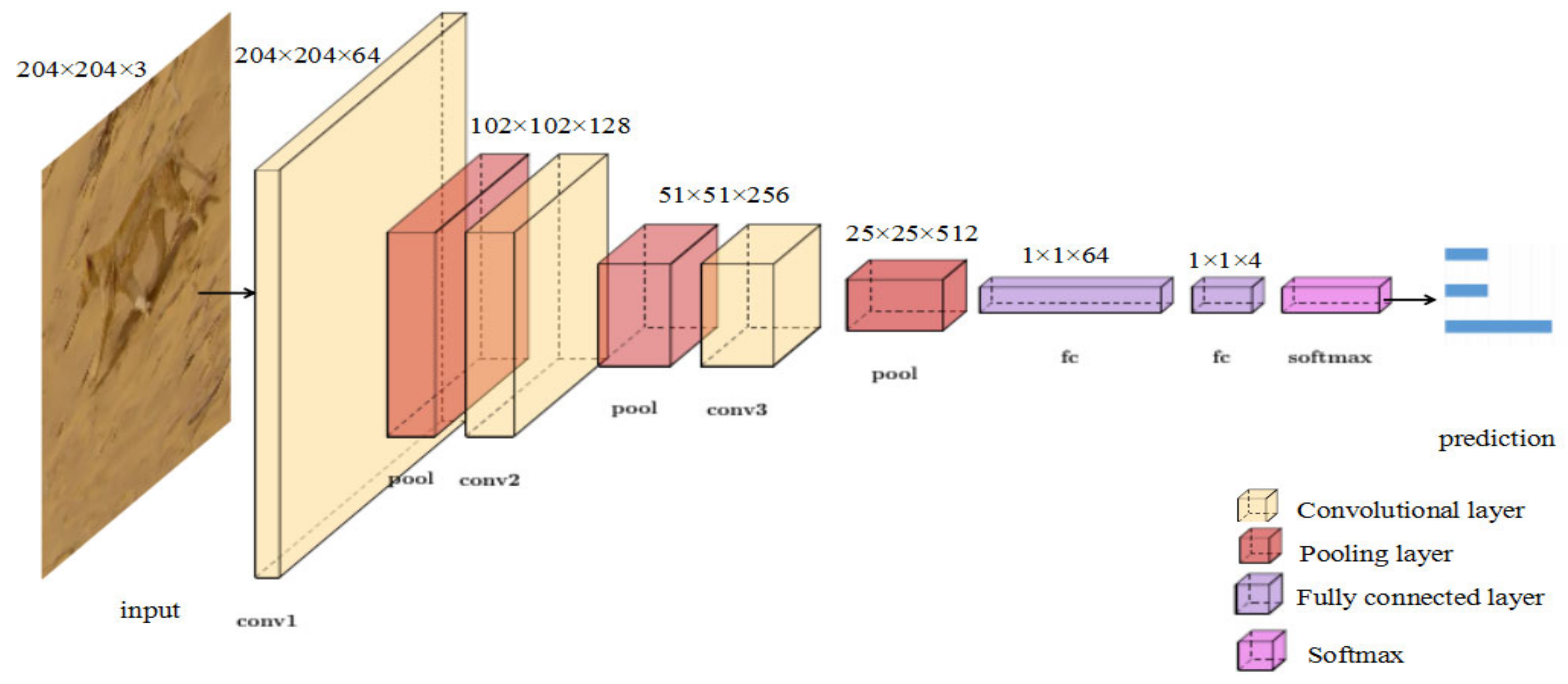
3.2.2. Tiny VGG for Action Classification
3.3. The Construction of the Skeleton Model
3.3.1. Tracking the Position of the Animal’s Leg Joints
3.3.2. Action Identification Based on Skeleton
3.4. Score Fusion
3.5. Materials
3.5.1. Configurations
3.5.2. Data Collection
3.5.3. Data Preprocessing
4. Results and Analysis
4.1. Outline Classification-Based Action Recognition
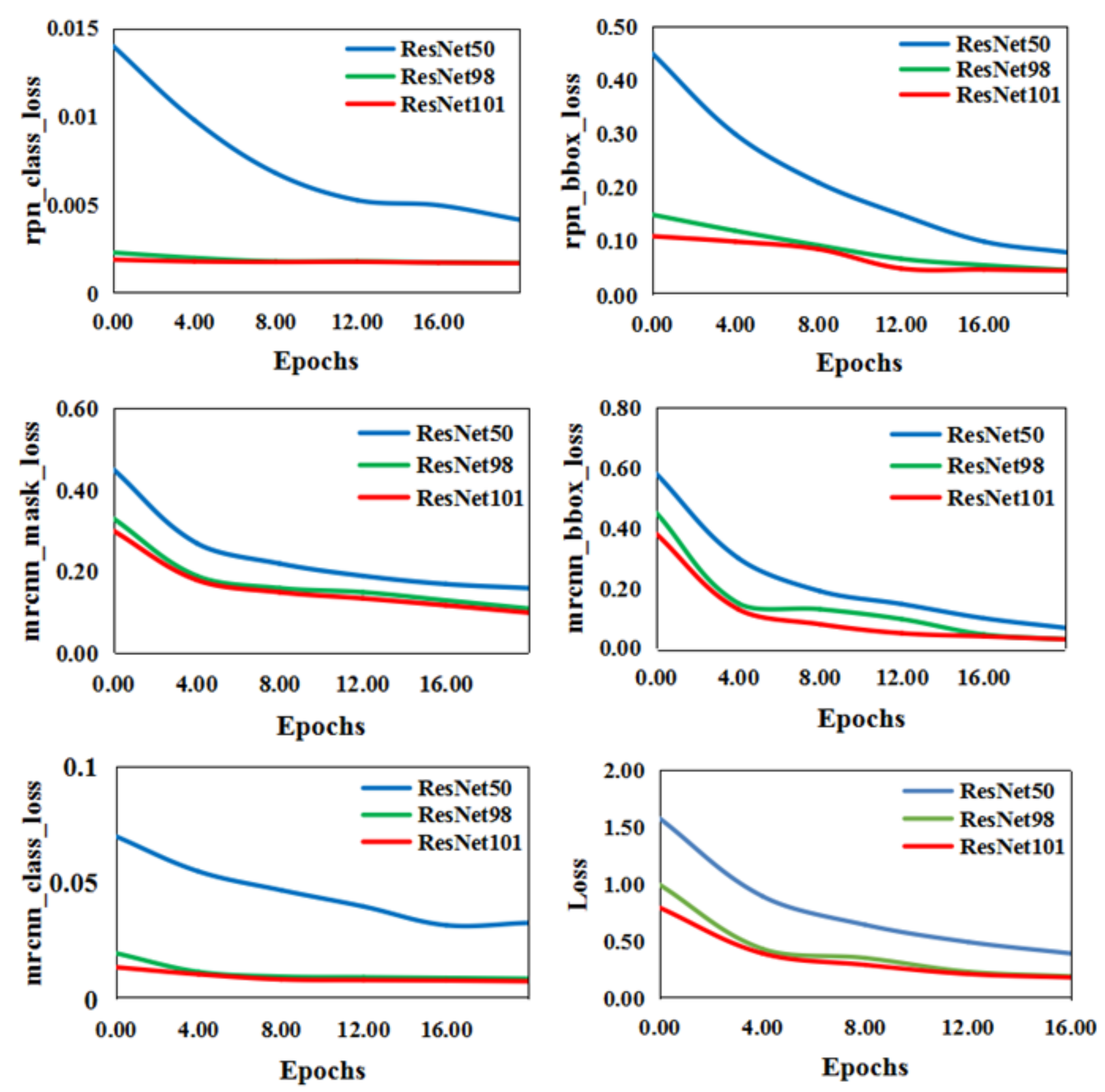
4.1.1. Outline Mask R-CNN
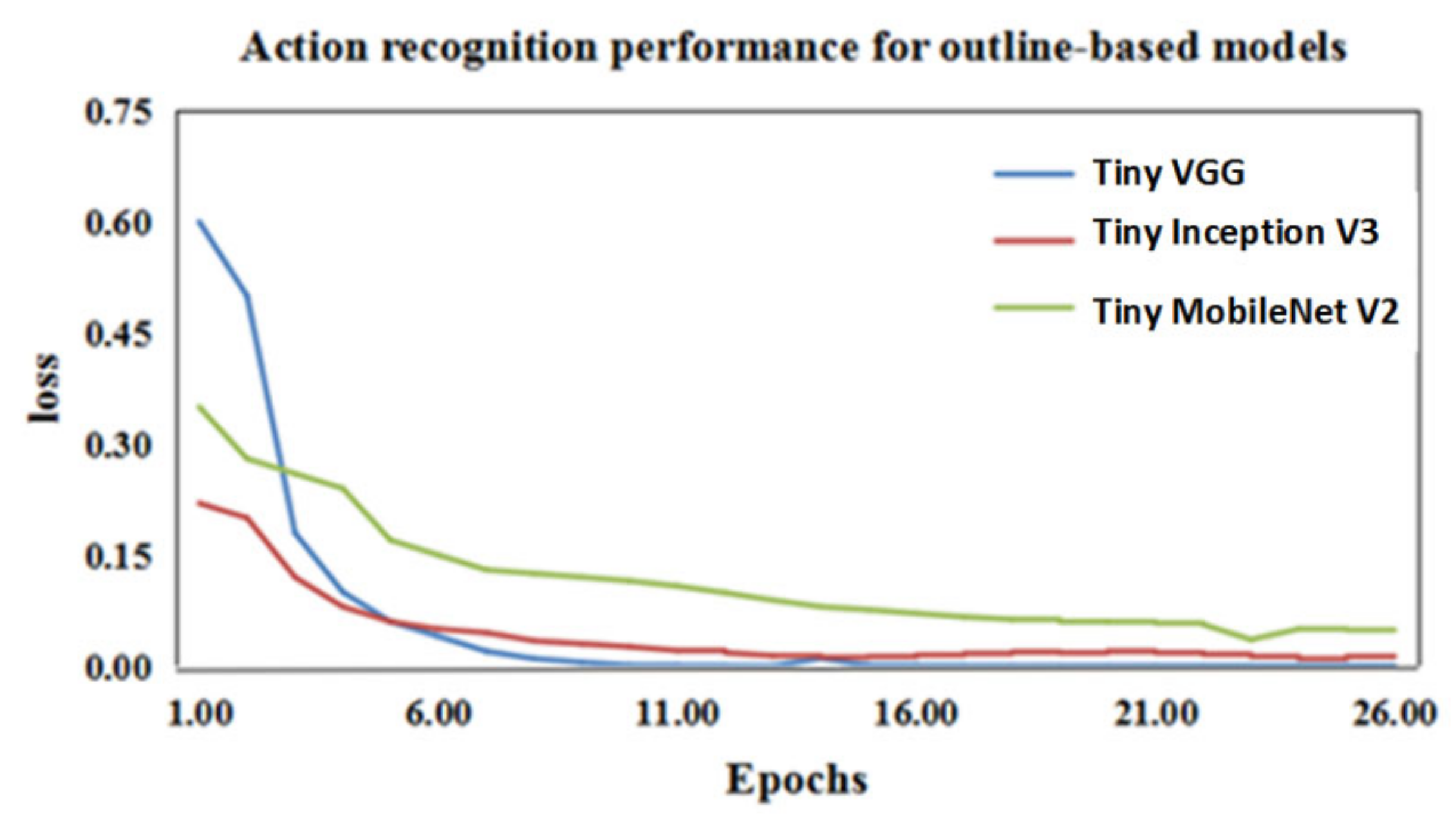
4.1.2. Tiny VGG for Action Classification
4.2. Skeleton Classification-Based Action Recognition
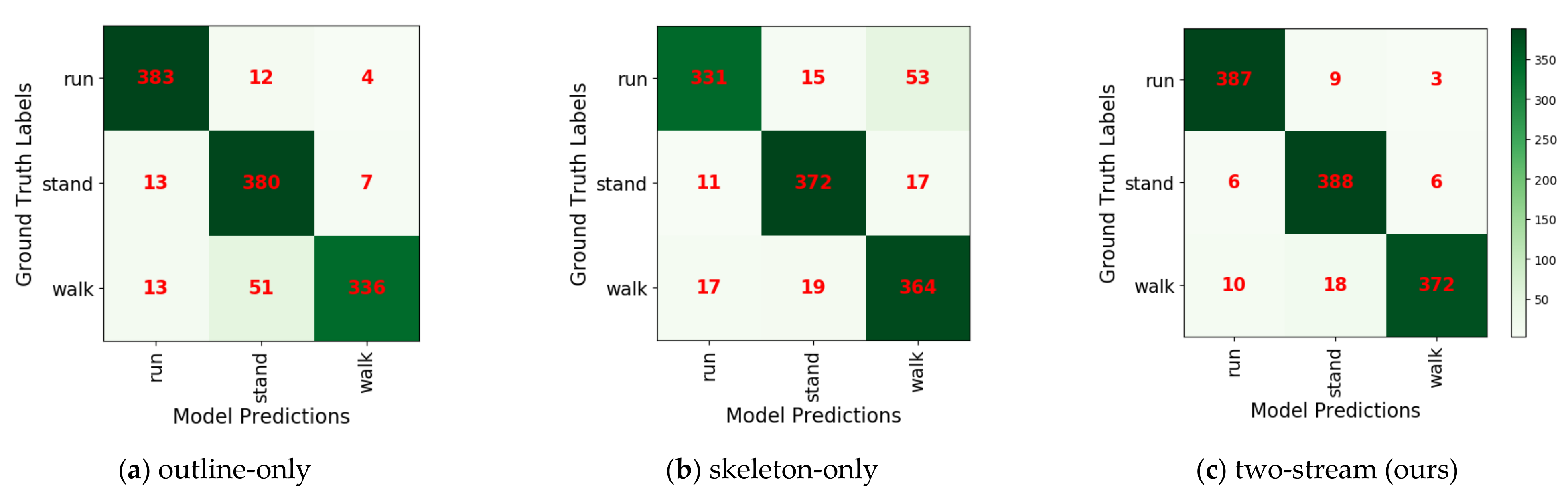
4.3. Our Two-Stream Model
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fraser, A.F. Introduction. In Feline Behaviour and Welfare; Hulbert, S., Lainsbury, A., Head, T., Eds.; CABI: Wallingford, UK, 2012; pp. 1–5. [Google Scholar]
- Atkinson, T. The Origin and Evolution of the Domestic Cat. In Practical Feline Behaviour Understanding Cat Behaviour and Improving Welfare; Makepeace, C., Lainsbury, A., Kapp, T., Eds.; CABI: Wallingford, UK, 2018; pp. 3–11. [Google Scholar]
- Marchant-Forde, J.N. The science of animal behavior and welfare: Challenges, opportunities and global perspective. Front. Vet. Sci. 2015, 2, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Anderson, D.J.; Perona, P. Toward a science of computational ethology. Neuron 2014, 84, 18–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Biolatti, C.; Modesto, P.; Dezzutto, D.; Pera, F.; Tarantola, M.; Gennero, M.S.; Maurella, C.; Acutis, P.L. Behavioural analysis of captive tigers Pantheratigris: A water pool makes the difference. Appl. Anim. Behav. Sci. 2016, 174, 173–180. [Google Scholar] [CrossRef]
- Shepherdson, D.J.; Mellen, J.D. Second Nature Environmental Enrichment for Captive Animals; Smithsonian Institution Press: Washington, DC, USA, 1998; pp. 184–201. [Google Scholar]
- Vaz, J.; Narayan, E.J.; Dileep Kumar, R.; Thenmozhi, K.; Thiyagesan, K.; Baskaran, N. Prevalence and determinants of stereotypic behaviours and physiological stress among tigers and leopards in Indian zoos. PLoS ONE 2017, 12, e0174711. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chakravarty, P.; Maalberg, M.; Cozzi, G.; Ozgul, A.; Aminian, K. Behavioural compass: Animal behaviour recognition using magnetometers. Mov. Ecol. 2019, 7, 28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Williams, H.J.; Holton, M.D.; Shepard, E.L.; Largey, N.; Norman, B.; Ryan, P.G.; Duriez, O.; Scantlebury, M.; Quintana, F.; Magowan, E.A.; et al. Identification of animal movement patterns using tri-axial magnetometry. Mov. Ecol. 2017, 5, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Noda, T.; Kawabata, Y.; Arai, N.; Mitamura, H.; Watanabe, S. Animal-mounted gyroscope/ accelerometer/ magnetometer: In situ measurement of the movement performance of fast-start behaviour in fish. J. Exp. Mar. Biol. Ecol. 2014, 451, 55–68. [Google Scholar] [CrossRef] [Green Version]
- Mench, J.A. Why it is important to understand animal behavior. ILAR J. 1998, 39, 20–26. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Yuan, P.; Liu, X.; Zhou, H. Street tree segmentation from mobile laser scanning data. Int. J. Remote Sens. 2020, 41, 7145–7162. [Google Scholar] [CrossRef]
- Akçay, H.G.; Kabasakal, B.; Aksu, D.; Demir, N.; Öz, M.; Erdoğan, A. Automated Bird Counting with Deep Learning for Regional Bird Distribution Mapping. Animals 2020, 10, 1207. [Google Scholar] [CrossRef]
- Agbele, T.; Ojeme, B.; Jiang, R. Application of local binary patterns and cascade AdaBoost classifier for mice behavioural patterns detection and analysis. Proced. Comput. Sci. 2019, 159, 1375–1386. [Google Scholar] [CrossRef]
- Jiang, Z.; Crookes, D.; Green, B.D.; Zhang, S.; Zhou, H. Behaviour recognition in mouse videos using contextual features encoded by spatial-temporal stacked Fisher vectors. In ICPRAM; Queen‘s University Belfast: Belfast, UK, 2017; pp. 259–269. [Google Scholar]
- Nguyen, N.; Delimayanti, M.; Purnama, B.; Mahmudah, K.; Kubo, M.; Kakikawa, M.; Yamada, Y.; Satou, K. Applying Deep Learning Models to Action Recognition of Swimming Mice with the Scarcity of Training Data. In Bioinformatics; Kanazawa University: Kanazawa, Japan, 2019; pp. 270–275. [Google Scholar] [CrossRef]
- Lorbach, M.; Poppe, R.; Veltkamp, R.C. Interactive rodent behavior annotation in video using active learning. Multimed. Tools Appl. 2019, 78, 19787–19806. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.Q.; Wang, Z.H.; Gao, R.H.; Wu, H.R. Cow behavior recognition based on image analysis and activities. Int. J. Agric. Biol. Eng. 2017, 10, 165–174. [Google Scholar] [CrossRef]
- He, D.J.; Meng, F.C.; Zhao, K.X.; Zhang, Z. Recognition of Calf Basic Behaviors Based on Video Analysis. Trans. CSAM 2016, 47, 294–300. (in Chinese) [Google Scholar] [CrossRef]
- Li, J. Study on Identification of Typical Cow‘s Self-Protective Behavior Based on Machine Vision Technology. Ph.D. Thesis, Inner Mongolia Agricultural University, Hohhot, China, October 2018. (in Chinese). [Google Scholar]
- Lee, J.; Jin, L.; Park, D.; Chung, Y. Automatic Recognition of Aggressive Behavior in Pigs Using a Kinect Depth Sensor. Sensors 2016, 16, 631. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luo, Y.; Wang, L.; Yang, L.; Tan, M.; Wu, Y.; Li, Y.; Li, Z. Puppet resting behavior in the Tibetan antelope (Pantholops hodgsonii). PLoS ONE 2018, 13, e0204379. [Google Scholar] [CrossRef] [Green Version]
- Bod‘ová, K.; Mitchell, G.J.; Harpaz, R.; Schneidman, E.; Tkačik, G. Probabilistic models of individual and collective animal behavior. PLoS ONE 2018, 13, e0193049. [Google Scholar] [CrossRef] [Green Version]
- George, G.; Namdev, A.; Sarma, S. Animal Action Recognition: Analysis of Various Approaches. Int. J. Eng. Sci. Res. Technol. 2018, 7, 548–554. [Google Scholar] [CrossRef]
- Pereira, T.D.; Aldarondo, D.E.; Willmore, L.; Kislin, M.; Wang, S.S.H.; Murthy, M.; Shaevitz, J.W. Fast animal pose estimation using deep neural networks. Nat. Methods 2019, 16, 117–125. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. Comput. Sci. 2014, 1556, 23–31. [Google Scholar]
- Jaouedi, N.; Perales, F.J.; Buades, J.M.; Boujnah, N.; Bouhlel, M.S. Prediction of Human Activities Based on a New Structure of Skeleton Features and Deep Learning Model. Sensors 2020, 20, 4944. [Google Scholar] [CrossRef]
- Lin, T.; Zhao, X.; Su, H.; Wang, C.J.; Yang, M. BSN: Boundary Sensitive Network for Temporal Action Proposal Generation. Proceed. Eur. Conf. Comput. Vis. ECCV 2018, 3–19. [Google Scholar]
- Okafor, E.; Pawara, P.; Karaaba, F.; Surinta, O.; Codreanu, V.; Schomaker, L.; Wiering, M. Comparative study between deep learning and bag of visual words for wild animal recognition. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. Proceed. IEEE Conf. Comput. Vis. Pattern Recognit. 2016, 1933–1941. [Google Scholar]
- Gómez, A.; Salazar, A.; Vargas, F. Towards Automatic Wild Animal Monitoring: Identification of Animal Species in Camera-trap Images using Very Deep Convolutional Neural Networks. Ecol. Inform. 2017, 41, 24–32. [Google Scholar] [CrossRef] [Green Version]
- Falzon, G.; Lawson, C.; Cheung, K.-W.; Vernes, K.; Ballard, G.A.; Fleming, P.J.S.; Glen, A.S.; Milne, H.; Mather-Zardain, A.; Meek, P.D. ClassifyMe: A Field-Scouting Software for the Identification of Wildlife in Camera Trap Images. Animals 2020, 10, 58. [Google Scholar] [CrossRef] [Green Version]
- Chen, G.; Han, T.X.; He, Z.; Kays, R.; Forrester, T. Deep convolutional neural network based species recognition for wild animal monitoring. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 858–862. [Google Scholar]
- Norouzzadeha, M.S.; Nguyenb, A.; Kosmalac, M.; Swansond, A.; Palmer, M.S.; Packer, C.; Clune, J. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proc. Nat. Acad. Sci. USA 2018, 115, 5716–5725. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, T.; Liu, L.; Zhao, K.; Wiliem, A.; Hemson, G.; Lovell, B. Omni-supervised joint detection and pose estimation for wild animals. Pattern Recognit. Lett. 2018, 132, 84–90. [Google Scholar] [CrossRef]
- Wark, J.D.; Cronin, K.A.; Niemann, T.; Shender, M.A.; Horrigan, A.; Kao, A.; Ross, M.R. Monitoring the behavior and habitat use of animals to enhance welfare using the ZooMonitor app. Anim. Behav. Cognit. 2019, 6, 158–167. [Google Scholar] [CrossRef]
- Zuffi, S.; Kanazawa, A.; Jacobs, D.; Black, M.J. 3D Menagerie. Modeling the3D Shape and Pose of Animals. Comput. Vis. Pattern Recognit. Int. Conf. 2017, 5524–5532. [Google Scholar]
- Romero-Ferrero, F.; Bergomi, M.G.; Hinz, R.C.; Heras, F.J.; De Polavieja, G.G. Idtracker. ai: Tracking all individuals in small or large collectives of unmarked animals. Nat. Methods 2019, 16, 179–182. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. Proceed. IEEE Int. Conf. Comput. Vis. 2017, 2980–2988. [Google Scholar]
- Girshick, R. Fast r-cnn. Proceed. IEEE Int. Conf. Comput. Vis. 2015, 1440–1448. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. Proceed. IEEE Conf. Comput. Vis. Pattern Recognit. 2015, 3431–3440. [Google Scholar]
- Zhang, Y.; Tian, Z.; Lei, Y.; Wang, T.; Patel, P.; Jani, A.B.; Curran, W.J.; Liu, T.; Yang, X. Automatic multi-needle localization in ultrasound images using large margin mask RCNN for ultrasound-guided prostate brachytherapy. Phys. Med. Biol. 2020, 65, 205003. [Google Scholar] [CrossRef] [PubMed]
- Tao, C.; Jin, Y.; Cao, F.; Zhang, Z.; Li, C.; Gao, H. 3D Semantic VSLAM of Indoor Environment Based on Mask Scoring RCNN. Discrete Dyn. Nat. Soc. 2020, 2020, 1–14. [Google Scholar] [CrossRef]
- Rohit Malhotra, K.; Davoudi, A.; Siegel, S.; Bihorac, A.; Rashidi, P. Autonomous detection of disruptions in the intensive care unit using deep mask RCNN. Proceed. IEEE Conf. Comput. Vis. Pattern Recognit. Workshops 2018, 2018, 1944–1946. [Google Scholar]
- Swanson, A.; Kosmala, M.; Lintott, C.; Simpson, R.; Smith, A.; Packer, C. Snapshot Serengeti, high-frequency annotated camera trap images of 40 mammalian species in an African savanna. Sci. Data 2015, 2, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Germany, 2014; pp. 740–755. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. Proceed. IEEE Conf. Comput. Vis. Pattern Recognit. 2016, 770–778. [Google Scholar]
- Bridle, J.S. Probabilistic interpretation of feedforward classification network outputs, with relationships to statistical pattern recognition. In Neurocomputing; Springer: Berlin/Heidelberg, Germany, 1990; pp. 227–236. [Google Scholar]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef] [PubMed]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Zhao, F.; Hung, D.L.; Wu, S. K-means clustering-driven detection of time-resolved vortex patterns and cyclic variations inside a direct injection engine. Appl. Therm. Eng. 2020, 180. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Networks Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Zhang, J.; Shi, K.; Wang, H. Applying Software Metrics to RNN for Early Reliability Evaluation. J. Control Sci. Eng. 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Python: An All-in-One Web Crawler, Web Parser and Web Scrapping Library! Available online: https://psgithub.com/hardikvasa/webb (accessed on 11 February 2020).
- Dangtongdee, K.D. Plant Identification Using Tensorflow; California Polytechnic State University: Luis San Obispo, CA, USA, 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization; Cornell University: Ithaca, NY, USA, 2014. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. Proceed. IEEE Conf. Comput. Vis. Pattern Recognit. 2018, 4510–4520. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. Proceed. IEEE Conf. Comput. Vis. Pattern Recognit. 2016, 2818–2826. [Google Scholar]
- Nath, T.; Mathis, A.; Chen, A.C.; Patel, A.; Bethge, M.; Mathis, M.W. Using DeepLabCut for 3D markerless pose estimation across species and behaviors. Nat. Protoc. 2019, 14, 2152–2167. [Google Scholar] [CrossRef] [PubMed]
- Graving, J.M.; Chae, D.; Naik, H.; Li, L.; Koger, B.; Costelloe, B.R.; Couzin, I.D. DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning. Elife 2019, 8, e47994. [Google Scholar] [CrossRef]
- Cui, Z. On the Cover: Violin Plot. Educ. Meas. Issues Pract. 2020, 39, 7. [Google Scholar] [CrossRef]
- Ndako, J.A.; Olisa, J.A.; Ifeanyichukwu, I.C.; Ojo, S.K.S.; Okolie, C.E. Evaluation of diagnostic assay of patients with enteric fever by the box-plot distribution method. N. Microbes N. Infect. 2020, 38, 100795. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. Proceed. IEEE Conf. Comput. Vis. Pattern Recognit. 2017, 7291–7299. [Google Scholar]
- Yun, K.; Honorio, J.; Chattopadhyay, D.; Berg, T.L.; Samaras, D. Two-person Interaction Detection Using Body-Pose Features and Multiple Instance Learning. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 28–35. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolution for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence; University of Oulu: Oulu, Finland, 2018; p. 32. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. Proceed. IEEE Conf. Comput. Vis. Pattern Recognit. 2019, 1227–1236. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Size | ResNet50 | ResNet101 | ResNet98 |
|---|---|---|---|---|
| Conv_1 | ||||
| Conv_2 | ||||
| Conv_3 | ||||
| Conv_4 | ||||
| Conv_5 | ||||
| Average Pooling | 1000 dimensions | |||
| Layer | Patch Size | Stride |
|---|---|---|
| Conv1_64 | 3 × 3 | 1 |
| Max Pooling | — | 2 |
| Conv3_128 | 3 × 3 | 1 |
| Max Pooling | 2 × 2 | 2 |
| Conv3_256 | 3 × 3 | 1 |
| Max Pooling | 2 × 2 | 2 |
| Layer | Filter Shape/Stride |
|---|---|
| Conv2d_bn | 1 × 1 × 32/1 |
| Conv2d_bn | 3 × 3 × 32/1 |
| Conv2d_bn | 3 × 3 × 64/2 |
| Max Pooling | Pool 3 × 3/2 |
| Conv2d_bn_1_1 | 1 × 1 × 64/1 |
| Conv2d_bn_1_5 | 1 × 1 × 48/1 |
| Conv2d_bn_1_5 | 5 × 5 × 64/1 |
| Conv2d_bn_1_3 | 1 × 1 × 64/1 |
| Conv2d_bn_1_3 | 3 × 3 × 96/1 |
| Average Pooling | Pool 1 × 1/1 |
| Conv2d_bn_Pool | 1 × 1 × 32/1 |
| Conv2d_bn_2_1 | 1 × 1 × 64/1 |
| Conv2d_bn_2_5 | 1 × 1 × 48/1 |
| Conv2d_bn_2_5 | 5 × 5 × 64/1 |
| Conv2d_bn_2_3 | 1 × 1 × 64/1 |
| Conv2d_bn_2_3 | 3 × 3 × 96/1 |
| Conv2d_bn_2_3 | 3 × 3 × 96/1 |
| Average Pooling | - |
| Conv2d_bn_Pool | 1 × 1 × 64 |
| Max Pooling | - |
| SoftMax | classifier |
| Operator | t | c | n | s |
|---|---|---|---|---|
| Conv2d 3 × 3 | - | 32 | 1 | 2 |
| Bottleneck | 1 | 16 | 1 | 2 |
| Bottleneck | 6 | 24 | 2 | 2 |
| Conv2d 1 × 1 | - | 64 | 1 | 2 |
| MaxPool 7 × 1 | - | - | 1 | - |
| Conv2d 1 × 1 | - | 3 | - | - |
| Tiny MobileNet V2 | Tiny Inception V3 | Tiny VGG | |
|---|---|---|---|
| Galloping | 79% | 77% | 96% |
| Standing | 88% | 89% | 95% |
| Ambling | 82% | 74% | 84% |
| Average accuracy | 83% | 80% | 92% |
| Galloping | Standing | Ambling | Average Accuracy | |
|---|---|---|---|---|
| Outline-only method | 96% | 95% | 84% | 92% |
| Skeleton-only method | 83% | 93% | 91% | 89% |
| Two-stream method | 97% | 97% | 93% | 95% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, L.; Zhao, Y.; Sun, Y.; Zhao, W.; Tang, J. Action Recognition Using a Spatial-Temporal Network for Wild Felines. Animals 2021, 11, 485. https://doi.org/10.3390/ani11020485
Feng L, Zhao Y, Sun Y, Zhao W, Tang J. Action Recognition Using a Spatial-Temporal Network for Wild Felines. Animals. 2021; 11(2):485. https://doi.org/10.3390/ani11020485
Chicago/Turabian StyleFeng, Liqi, Yaqin Zhao, Yichao Sun, Wenxuan Zhao, and Jiaxi Tang. 2021. "Action Recognition Using a Spatial-Temporal Network for Wild Felines" Animals 11, no. 2: 485. https://doi.org/10.3390/ani11020485
APA StyleFeng, L., Zhao, Y., Sun, Y., Zhao, W., & Tang, J. (2021). Action Recognition Using a Spatial-Temporal Network for Wild Felines. Animals, 11(2), 485. https://doi.org/10.3390/ani11020485