
The Use of Multilayer Perceptron Artificial Neural Networks to Detect Dairy Cows at Risk of Ketosis

Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Selection and Sampling of Dairy Herds
2.2. Laboratory Analysis
2.3. Approach
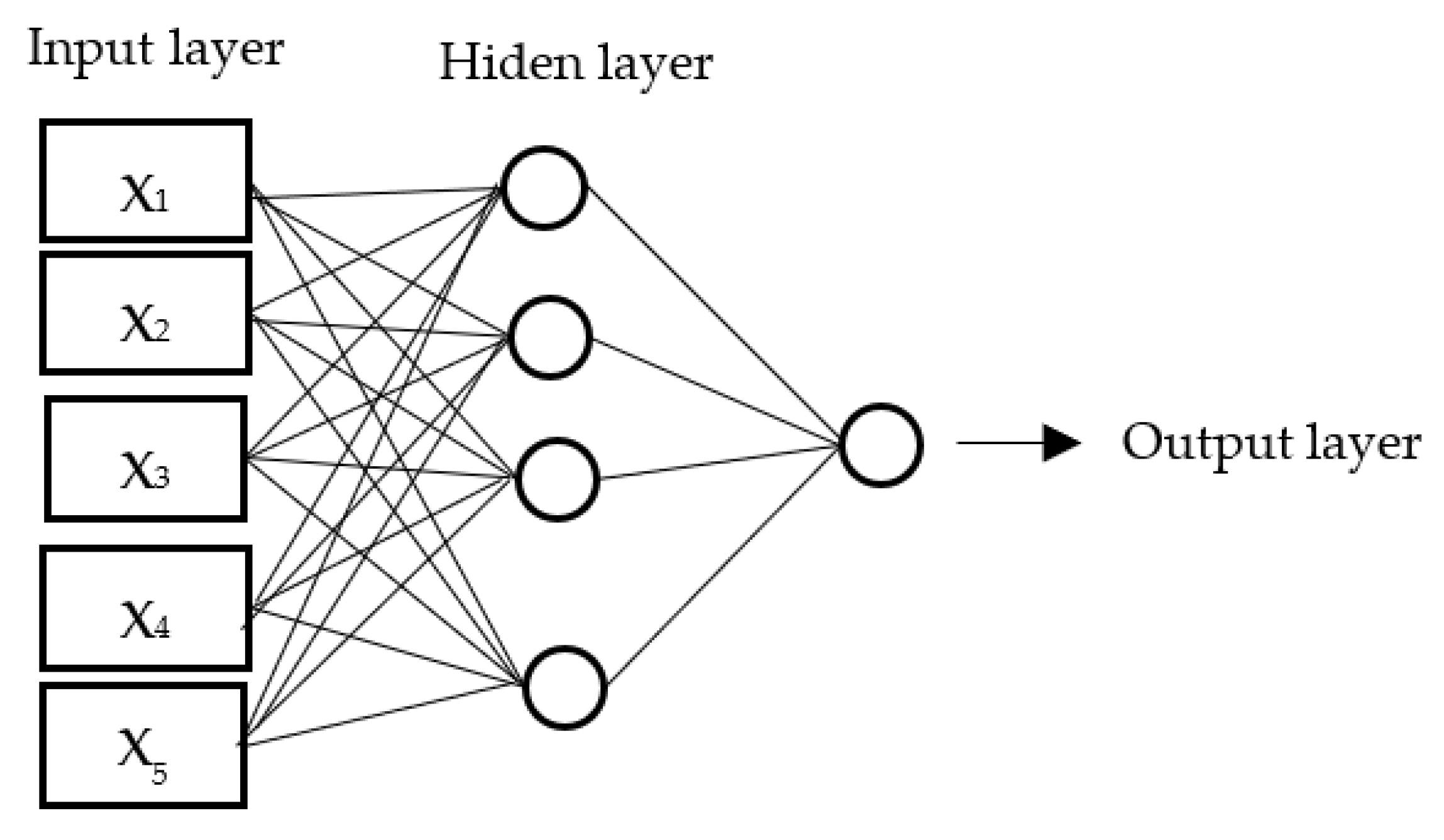
2.3.1. Data Preprocessing for Multi-Layer Perceptron
2.3.2. Feature Selection
2.3.3. Archiving Models
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Suthar, V.S.; Canelas-Raposo, J.; Deniz, A.; Heuwieser, W. Prevalence of subclinical ketosis and relationships with postpartum diseases in European dairy cows. J. Dairy Sci. 2013, 96, 2925–2938. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guliński, P. Ketone bodies—Causes and effects of their increased presence in cows’ body fluids: A review. Vet. World 2021, 14, 1492–1503. [Google Scholar] [CrossRef] [PubMed]
- Mc Art, J.A.A.; Nydam, D.V.; Overton, M.W. Hyperketonemia in early lactation dairy cattle: A deterministic estimate of component and total cost per case. J. Dairy Sci. 2015, 98, 2043–2054. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Horst, E.A.; Kvidera, S.K.; Baumgard, L.H. Invited review: The influence of immune activation on transition cow health and performance—A critical evaluation of traditional dogmas. J. Dairy Sci. 2021, 104, 8380–8410. [Google Scholar] [CrossRef] [PubMed]
- Rachah, A.; Reksen, O.; Tafintseva, V.; Stehr, F.J.M.; Rukke, E.O.; Prestløkken, E.; Martin, A.; Kohler, A.; Afseth, N.K. Exploring dry-film ftir spectroscopy to characterize milk composition and subclinical ketosis throughout a cow’s lactation. Foods 2021, 104, 2033. [Google Scholar] [CrossRef]
- McLaren, C.J.; Lissemore, K.D.; Duffield, T.F.; Leslie, K.E.; Kelton, D.F.; Grexton, B. The relationship between herd level disease incidence and a return over feed index in Ontario dairy herds. Can. Vet. J. 2006, 47, 767–773. [Google Scholar]
- Roberts, T.; Chapinal, N.; Le Blanc, S.J.; Kelton, D.F.; Dubuc, J.; Duffield, T.F. Metabolic parameters in transition cows as indicators for early-lactation culling risk. J. Dairy Sci. 2012, 95, 3057–3063. [Google Scholar] [CrossRef]
- Reynen, J.L.; Kelton, D.F.; LeBlanc, S.J.; Newby, N.C.; Duffield, T.F. Factors associated with survival in the herd for dairy cows following surgery to correct left displaced abomasum. J. Dairy Sci. 2015, 98, 3806–3813. [Google Scholar] [CrossRef] [Green Version]
- Xu, W.; Saccenti, E.; Vervoort, J.; Kemp, B.; Bruckmaier, R.M.; van Knegsel, A.T.M. Short communication: Prediction of hyperketonemia in dairy cows in early lactation using on-farm cow data and net energy intake by partial least square discriminant analysis. J. Dairy Sci. 2020, 103, 6576–6582. [Google Scholar] [CrossRef]
- Vanholder, T.; Papen, J.; Bemes, R.; Vertenten, G.; Berge, A.C.B. Risk factors for subclinical and clinical ketosis and association with production parameters in dairy cows in the Netherlands. J. Dairy Sci. 2015, 98, 880–888. [Google Scholar] [CrossRef] [Green Version]
- Eom, J.S.; Kim, E.T.; Kim, H.S.; Choi, Y.Y.; Lee, S.J.; Lee, S.S.; Kim, S.H.; Lee, S.S. Metabolomics comparison of serum and urine in dairy cattle using proton nuclear magnetic resonance spectroscopy. Anim. Biosci. 2021, 34, 1930–1939. [Google Scholar] [CrossRef] [PubMed]
- Glatz-Hoppe, J.; Boldt, A.; Spiekers, H.; Mohr, E.; Losand, B. Relationship between milk constituents from milk testing and health, feeding, and metabolic data of dairy cows. J. Dairy Sci. 2020, 103, 10175–10194. [Google Scholar] [CrossRef] [PubMed]
- Mc Art, J.A.A.; Nydam, D.V.; Oetzel, G.R. Epidemiology of subclinical ketosis in early lactation dairy cattle. J. Dairy Sci. 2012, 95, 5056–5066. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benedet, A.; Manuelian, C.L.; Zidi, A.; Penasa, M.; De Marchi, M. Invited review: β–hydroxybutyrate concentration in blood and milk and its association with cow performance. Animal 2019, 13, 1676–1689. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Walsh, R.B.; Walton, J.S.; Kelton, D.F.; LeBlance, S.J.; Leslie, K.E.; Duffield, T.F. The effect of subclinical ketosis in early lactation on reproductive performance of postpartum dairy cows. J. Dairy Sci. 2007, 90, 2788–2796. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goldhawk, C.; Chapinal, N.; Viera, D.M.; Weary, D.M.; von Keyserlingk, M.A.G. Prepartum feeding behavior is an early indicator of subclinical ketosis. J. Dairy Sci. 2009, 92, 4971–4977. [Google Scholar] [CrossRef] [PubMed]
- Satoła, A.; Bauer, E.A. Predicting subclinical ketosis in dairy cows using machine learning techniques. Animals 2021, 11, 2131. [Google Scholar] [CrossRef] [PubMed]
- Grzesiak, W.; Błaszczyk, P.; Lacroix, R. Methods of predicting milk yield in dairy cows–Predictive capabilities of Wood’s lactation curve and artificial neural networks (ANNs). Comput. Electron. Agric. 2006, 54, 69–83. [Google Scholar] [CrossRef]
- Jędruś, A.; Niżewski, P.; Lipiński, M.; Boniecki, P. Neuronowa analiza wpływu sposobu doju i wybranych cech zootechnicznych krów na liczbę komórek somatycznych w mleku. Tech. Rol. Ogrod. Leśna 2008, 4, 22–24. [Google Scholar]
- Grzesiak, W.; Zaborski, D.; Sablik, P.; Żukiewska, A.; Dybus, A.; Szatkowska, I. Detection of cows with insemination problems using selected classification models. Comput. Electron. Agric. 2010, 74, 265–273. [Google Scholar] [CrossRef]
- Zborowski, D.; Grzesiak, W. Detection of heifers with dystocia using artificial neural networks with regards to ERα–BGLI, ERα–SNABI and CYP19–PVUII genotypes. Acta Sci. Pol. Zootech. 2011, 10, 105–116. [Google Scholar]
- Adamczyk, K.; Zaborski, D.; Grzesiak, W.; Makulska, J.; Jagusiak, W. Recognition of culling reasons in Polish dairy cows using data mining methods. Comput. Electron. Agric. 2016, 127, 26–37. [Google Scholar] [CrossRef]
- Kosiński, R. Sztuczne Sieci Neuronowe—Dynamika Nieliniowa i Chaos; Państwowe Wydawnictwo Naukowe: Warszawa, Poland, 2014. [Google Scholar]
- Tadeusiewicz, R. Sieci Neuronowe; Akademicka Oficyna Wydawnicza: Krakow, Poland, 1993. [Google Scholar]
- Osowski, S. Sieci Neuronowe do Przetwarzania Informacji; Oficyna Wydawnicza Politechniki Warszawskiej: Warsaw, Poland, 2000. [Google Scholar]
- Tadeusiewicz, R.; Szaleniec, M. Leksykon Sieci Neuronowych; Wydawnictwo Fundacji “Projekt Nauka”: Warszawa, Poland, 2015. [Google Scholar]
- Boniecki, P.; Weres, J. Wykorzystanie technik neuronowych do predykcji wielkości zbiorów wybranych płodów rolnych. J. Res. App. Agric. Eng. 2003, 48, 56–59. [Google Scholar]
- Korbicz, J.; Obuchowski, A.; Uciński, D. Sztuczne Sieci Neuronowe. Podstawy i Zastosowania; Akademicka Oficyna Wydawnicza PLJ: Warszawa, Poland, 1994. [Google Scholar]
- Rutkowska, D.; Piliński, M.; Rutkowski, L. Sieci Neuronowe, Algorytmy Genetyczne i Systemy Rozmyte; Wydawnictwo Naukowe PWN: Warszawa, Poland, 1997. [Google Scholar]
- Chandler, T.L.; Pralle, R.S.; Dorea, J.R.R.; Poock, S.E.; Oetzel, G.R.; Fourdra, R.H.; White, H.M. Prediction hyperketonemia by logistic and linear regression using test–day milk and performance variables in early–lactation Holstein and Jersey cows. J. Dairy Sci. 2018, 101, 2476–2491. [Google Scholar] [CrossRef]
- Zweig, M.H.; Campbell, G. Receiver operating characteristic (ROC) plots: A fundamental evaluation tool in clinical medicine. Clin. Chem. 1993, 39, 561–577. [Google Scholar] [CrossRef]
- Grossman, R.; Bailey, S.; Ramu, A.; Malhi, B.; Hallstrom, P.; Pulleyn, I.; Qin, X. The management and mining of multiple prediction models using the predictive modeling markup language. Inf. Softw. Technol. 1999, 41, 589–595. [Google Scholar] [CrossRef]
- Carrier, J.; Stewart, S.; Godden, S.; Fetrow, J.; Rapnicki, P. Evaluation and use of three cowside tests for detection of subclinical ketosis in early postpartum cows. J. Dairy Sci. 2004, 87, 3725–3735. [Google Scholar] [CrossRef] [Green Version]
- van Knegsel, A.T.M.; van der Drift, S.G.A.; Harnomen, M.; de Roos, A.P.W.; Kemp, B. Short communication: Ketone body concentration in milk determined by Fourier transform infrared spectroscopy: Value for the detection of hyperketonemia in dairy cows. J. Dairy Sci. 2010, 93, 3056–3069. [Google Scholar] [CrossRef]
- Nielen, M.; Aarts, M.G.A.; Jonkers, A.G.M.; Wensing, T.; Schukken, Y.H. Evaluation of two cowside tests for the detection of subclinical ketosis in dairy cows. Can. Vet. J. 1994, 35, 229–232. [Google Scholar]
- Ni, H.; Klugkist, I.; van der Drift, S.; Jorritsma, R.; Hooijer, G.; Nielen, M. Expert opinion as priors for random effects in bayesian prediction models: Subclinical ketosis in dairy cows as an example. PLoS ONE 2021, 16, e0244752. [Google Scholar] [CrossRef]
- Kowalski, M.Z.; Płyta, A.; Rybicka, E.; Jagusiak, W.; Słoniewski, K. Novel model of monitoring of subclinical ketosis in dairy herds in Poland based on monthly milk recording and estimation of ketone bodies in milk by FTIR spectroscopy technology. ICAR Tech. Ser. 2015, 19, 25–30. [Google Scholar]
- Jorritsma, R.; Baldee, S.J.C.; Schukken, Y.H.; Wensing, T.; Wentink, G.H. Evaluation of a milk test for detection of subclinical ketosis. Vet. Q. 1998, 20, 108–110. [Google Scholar] [CrossRef] [PubMed]
- Jenkins, N.T.; Peña, G.; Risco, C.; Barbosa, C.C.; Vieire-Neto, A.; Galvão, K.N. Utility of inline milk fat and protein ratio to diagnose subclinical ketosis and assign propylene glycol treatment in lactating dairy cows. Can. Vet. J. 2015, 56, 850–854. [Google Scholar] [PubMed]


{kind=link}
| Item | Lactation 1 | Lactation 2 | Lactation 3 | Lactation ≥ 4 |
|---|---|---|---|---|
| Number of cows | 402 | 426 | 397 | 295 |
| bBHB (mmol/L) | 0.23 ± 0.33 | 0.65 ± 0.45 | 0.56 ± 0.39 | 0.85 ± 0.36 |
| Milk variables | ||||
| Milk (kg) | 26.89 ± 6.38 | 35.0 ± 0.69 | 32.80 ± 9.26 | 34.2 ± 10.1 |
| Fat (%) | 4.54 ± 1.00 | 4.5 ± 1.02 | 4.92 ± 1.03 | 4.68 ± 1.01 |
| Protein (%) | 3.24 ± 0.33 | 3.4 ± 0.38 | 3.30 ± 0.40 | 3.27 ± 0.34 |
| Lactose (%) | 4.85 ± 0.23 | 4.8 ± 0.20 | 4.76 ± 0.27 | 4.70 ± 0.24 |
| Urea (mg/L) | 197.56 ± 70.05 | 207 ± 77.14 | 203.12 ± 74.34 | 179.42 ± 73.66 |
| SCC (1000/mL) | 561.4 ± 1081.9 | 591.1 ± 1252.06 | 725.42 ± 1188.15 | 834.31 ± 1401.07 |
| Acetone (mmol/L) | 0.15 ± 0.18 | 0.1 ± 0.12 | 0.15 ± 0.17 | 0.13 ± 0.13 |
| mBHB (mmol/L) | 0.09 ± 0.13 | 0.1 ± 0.10 | 0.11 ± 0.11 | 0.86 ± 0.61 |
| Type of Network | Type of Function | Function Model |
|---|---|---|
| MLP | Linear | y = ax + b |
| Hyperbolic tangent | ||
| Exponential | ||
| Logistic | ||
| Sinus | f(x) = sin(x) |
| ID MLP | Activation Functions | |
|---|---|---|
| Hidden | Output | |
| 2-8-1 | linear | linear |
| 2-9-1 | exponential | tangens |
| 2-10-1 | hyperbolic tangent | sinus |
| 2-11-1 | linear | sinus |
| 2-12-1 | hyperbolic tangent | linear |
| 2-13-1 | hyperbolic tangent | linear |
| 5-14-1 | exponential | linear |
| 3-15-1 | sinus | linear |
| ID MLP | Coefficient Correlation | Error Function (SOS) | ||||
|---|---|---|---|---|---|---|
| Training | Testing | Validation | Training Error | Testing Error | Validation Error | |
| 2-8-1 | 0.96 | 0.75 | 0.64 | 0.95 | 0.489 | 0.65 |
| 2-9-1 | 0.96 | 0.73 | 0.64 | 0.96 | 0.49 | 0.63 |
| 2-10-1 | 0.97 | 0.73 | 0.65 | 0.88 | 0.46 | 0.56 |
| 2-11-1 | 0.95 | 0.77 | 0.66 | 0.81 | 0.45 | 0.56 |
| 2-12-1 | 0.96 | 0.74 | 0.64 | 0.89 | 0.46 | 0.59 |
| 2-13-1 | 0.95 | 0.72 | 0.65 | 0.77 | 0.44 | 0.57 |
| 5-14-1 | 0.96 | 0.72 | 0.65 | 0.52 | 0.46 | 0.60 |
| 3-15-1 | 0.96 | 0.72 | 0.64 | 0.50 | 0.45 | 0.59 |
| ID MLP | Input Variable | ||||
|---|---|---|---|---|---|
| BHB | ACE | LAC | FP | PP | |
| 2-8-1 | 7.332 | 2.842 | - | - | - |
| 2-9-1 | 7.520 | 3.616 | - | - | - |
| 2-10-1 | 8.533 | 3.110 | - | - | - |
| 2-11-1 | 5.637 | 2.169 | - | - | - |
| 2-12-1 | 6.216 | 3.289 | - | - | - |
| 2-13-1 | 6.509 | 4.120 | - | - | - |
| 5-14-1 | 2.989 | 2.710 | 1.822 | 1.292 | 1.023 |
| 3-15-1 | 1.568 | 1.122 | - | 1.239 | - |
| ID MLP | AUC ± SE | Cutoff | Sensitivity | Specificity |
|---|---|---|---|---|
| 2-8-1 | 0.87 ± 0.01 | 0.46 | 0.63 | 0.83 |
| 2-9-1 | 0.86 ± 0.01 | 0.52 | 0.84 | 0.61 |
| 2-10-1 | 0.85 ± 0.01 | 0.49 | 0.72 | 0.81 |
| 2-11-1 | 0.84 ± 0.01 | 0.50 | 0.67 | 0.85 |
| 2-12-1 | 0.82 ± 0.01 | 0.52 | 0.75 | 0.82 |
| 2-13-1 | 0.85 ± 0.01 | 0.53 | 0.66 | 0.82 |
| 5-14-1 | 0.89 ± 0.01 | 0.54 | 0.67 | 0.86 |
| 3-15-1 | 0.85 ± 0.01 | 0.51 | 0.65 | 0.85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bauer, E.A.; Jagusiak, W. The Use of Multilayer Perceptron Artificial Neural Networks to Detect Dairy Cows at Risk of Ketosis. Animals 2022, 12, 332. https://doi.org/10.3390/ani12030332
Bauer EA, Jagusiak W. The Use of Multilayer Perceptron Artificial Neural Networks to Detect Dairy Cows at Risk of Ketosis. Animals. 2022; 12(3):332. https://doi.org/10.3390/ani12030332
Chicago/Turabian StyleBauer, Edyta A., and Wojciech Jagusiak. 2022. "The Use of Multilayer Perceptron Artificial Neural Networks to Detect Dairy Cows at Risk of Ketosis" Animals 12, no. 3: 332. https://doi.org/10.3390/ani12030332
APA StyleBauer, E. A., & Jagusiak, W. (2022). The Use of Multilayer Perceptron Artificial Neural Networks to Detect Dairy Cows at Risk of Ketosis. Animals, 12(3), 332. https://doi.org/10.3390/ani12030332