1. Introduction
Biodiversity is an essential component and a key element in maintaining the stability of ecosystems. In the face of the current sharp decline in global biodiversity, it is urgent to take adequate measures to prevent and protect it. Wildlife monitoring and conservation that determine biodiversity patterns is a cornerstone of ecology, biogeography, and conservation biology. Therefore, monitoring animal habits and activity patterns during the rewilding training process is essential. Driven by advances in cheap sensors and computer-vision technologies for detecting and tracking wildlife, biodiversity research is rapidly transforming into a data-rich discipline. Video data have become indispensable in the retrospective analysis and monitoring of endangered animal species’ presence and behaviors. However, large-scale research is prohibited by the time and resources needed to process large data manually.
Recent technological advances in computer vision have led to wildlife scientists realizing the potential of automated computational methods to monitor wildlife. This ongoing revolution is facilitated by cost-effective mechanical high-throughput wildlife-tracking methods that generate massive high-resolution images across scales relevant to the ecological context in which animals perceive, interact with and respond to their environment. While applying existing tools is tempting, many potential pitfalls must be considered to ensure the responsible use of these approaches. For example, a large amount of data is required to train these deep-learning models accurately. However, because many species rarely occur, only a few shot samples are available; thus, the performance is typically low.
Few-shot learning aims to develop the ability to learn and generalize autonomously from a small number of samples. It can rapidly generalize to new tasks containing only a few samples with supervised information. Multiple recent publications have discussed this approach [
1,
2,
3,
4,
5]. Generally, the research on multiobject tracking mainly focuses on how to improve the real-time performance of multiobject monitoring [
6,
7], how to better model the appearance information of the target [
8,
9,
10,
11], and how to associate targets efficiently [
12,
13,
14,
15]. Multiobject-tracking methods always follow the tracking-by-detection paradigm. In [
7], this method was called separate detection and embedding (SDE). This means that the MOT system was broken down into two steps: (1) locating the target in single video frames; and (2) associating detected targets with existing trajectories. Another multi-object tracking learning paradigm, JDE, was also proposed. JDE jointly learned the detector and embedding model in a single deep network. In other words, the JDE method used a single network to output both the detection result and the corresponding appearance embeddings of the detected boxes. The SDE method used two separate networks to accomplish the above two tasks. JDE was closer to real-time performance, but the tracking accuracy was slightly worse than SDE. The small-sample object-detector performance was not as good as that of YOLO [
16,
17,
18,
19], Faster R-CNN [
20], and other general object detectors [
21,
22]. In the object detection of each frame, there will be missed detection, which significantly affects the effect of the multiobject-tracking task. Therefore, to ensure the performance effect of a multiobject-tracking model driven by a small amount of data, in addition to selecting the SDE paradigm, we also proposed a trajectory reconstruction module in the data association part to further optimize the tracking accuracy, as shown in
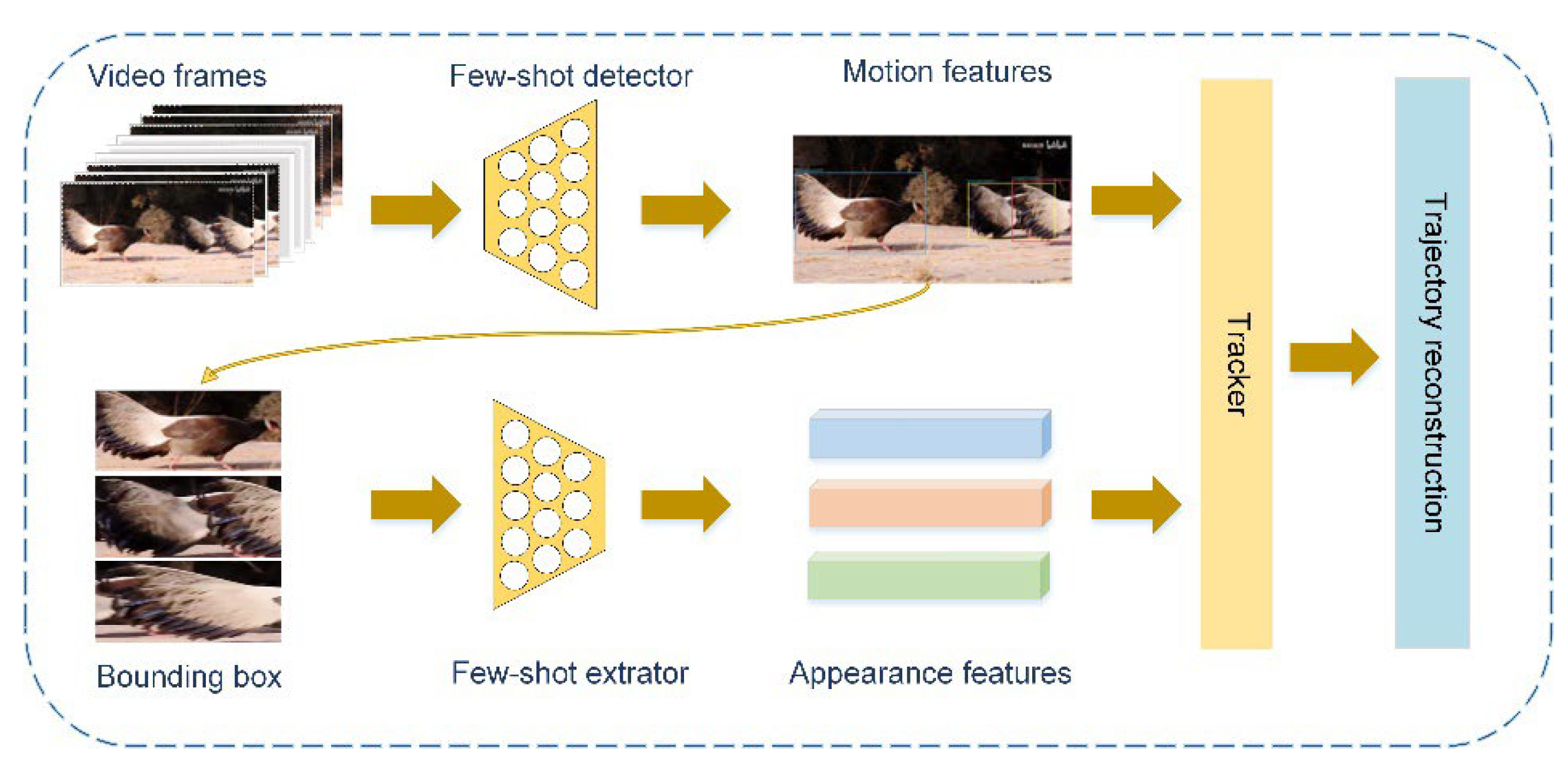
Figure 1.
The research hotspots of multiobject tracking under the tracking-by-detection paradigm always have the following two aspects: (1) a more accurate detection of targets in complex environments; and (2) the ability to deal with long-term occlusion and short-term occlusion problems and to associate targets more accurately. Some previous works [
23,
24,
25] showed that a multiobject-tracking approach could achieve a state-of-the-art performance when used together with a robust object detector. They used Kalman filtering to predict and update trajectories [
23] and proposed an extension [
24]. In addition to considering the motion features above, the apparent features of the target were also considered. Feichtenhofer et al. introduced correlation features representing object cooccurrences across time to aid the ConvNet during tracking. Moreover, they linked the frame-level detections based on across-frame tracks to produce high-accuracy detections at the video level [
25].
The primary purpose of data association is to match multiple targets between frames, including the appearance of new marks, the disappearance of old targets, and the identity matching of targets between consecutive frames. Many approaches formulated the data-association process as various optimization problems [
12,
13]. The former mapped the maximum a posteriori (MAP) data-association problem to cost-flow networks with nonoverlapping constraints on trajectories. A min-cost flow algorithm found the optimal data association in the network. The latter believed that re-identification only by appearance was not enough, and long-distance object reproduction was also worthy of attention. They proposed a graph-based formulation that linked and clustered person hypotheses over time by solving an instance of a minimum cost lifted multicut problem. Some works, such as [
26,
27], emphasized improving the features used in data association. They proposed dual matching attention networks with spatial and temporal attention mechanisms [
26]. The spatial attention network generated dual spatial attention maps based on the cross-similarity between each location of an image pair, making the model more focused on matching common regions between images. The temporal attention module adaptively allocated different levels of attention to separate samples in the tracklet to suppress noisy observations. To obtain a higher precision, they also developed a new training method with ranking loss and regression loss [
27]. The network considered the appearance and the corresponding temporal frames for data association.
Conceptually, tracking technologies using computer vision permit high-resolution snapshots of the movement of multiple animals and can track nontagged individuals, but they are less cost-effective, are usually limited to specific scenarios, and make individual identification challenging. In contrast, here we provide a fully automated computational approach to tracking tasks for wildlife by combining few-shot learning with multiobject tracking to detect, track, and recognize nature. It could represent a step-change in our use of extensive video data from the wild to speed up the procedure for ethologists to analyze biodiversity for research and conservation in the wildlife sciences. This approach represents an automated pipeline for recognizing and tracking species in the wild. Our main contributions can be summarized as follows:
We combined few-shot learning with a multiobject-tracking task. To the best of our knowledge, the multiple automated object-tracking frameworks based on few-shot learning are being proposed for the first time.
Our approach effectively merged the richness of deep neural network representations with few-shot learning that paves the way for robust detection and tracking of wildlife, which can be adaptive for unknown scenarios by data augmentation.
A trajectory reconstruction module was proposed to compensate for the shortcomings of the few-shot object-detection algorithm in the multiobject-tracking tasks, especially in monitoring wildlife.
2. Materials and Methods
2.1. Architecture Overview
While camera traps have become essential for wildlife monitoring, they generate enormous amount of data. The fundamental goal of using intelligent frameworks in wildlife monitoring is automated analyses of behaviors, interactions, and dynamics, both individual and group. For example, sampling the quantity of species’ complex interactions for network analysis is a significant methodological challenge. Early approaches require capturing subjects and are labor-intensive. Their application may be location-specific, and the recorded data typically lacks contextual visual information. In this work, we instead sought to learn the unstrained dynamics and be sensitive to the presence of various locations and groups. The aim was to propose a cost-effective wildlife-tracking approach that generated massive high-resolution video records across scales relevant to the ecological context in which animals perceive, interact with and respond to their environment.
Figure 2 shows the overall design of the proposed MOT framework, called Few-MOT, which followed the tracking-by-detection paradigm, but without requiring large amounts of training data. An input video frame first underwent a forward pass through a few-shot object detector and a few-shot feature extractor to obtain motion and appearance information. Finally, we followed [
24] and made improvements to solve the association problem for a few-shot setting. The upgrades included two parts: (1) a three-stage matching process including cascade matching, central-point matching, and IoU matching; and (2) a trajectory-reconstruction module to compensate for few-shot object detection.
2.2. Few-Shot Detection Module
Most object-detection approaches rely on extensive training samples. These requirements substantially limit their scalability to open-ended accommodation of novel classes with limited labeled training data. In general, the detection branch of multiobject tracking is the state-of-the-art of the object-detection field. Given the extreme scarcity of endangered animal scenes, we had very few samples available. This paper addresses these problems by offering a few-shot object detection with spatial constraints to localize objects in our multiobject-tracking framework. Few-shot object detection only requires a k-shot training sample, and its performance is better than that of the general detector under the same premise.
First, a note that in few-shot learning, we defined a large number of samples as the base, with their counterparts as the novel. In this paper, the novel class refers to the endangered animal class. Our proposed few-shot object-detection method allowed for few-shot learning in different scenarios with spatial dependencies while adapting to a dynamically changing environment during the detection process. It exploited a set of objects and environments that were processed, composed, and affected by each other simultaneously, instead of being recognized individually. Considering the geographical correlation between species and environmental factors, we thus proposed spatial constraints during the data augmentation. The images were first separated from the front and back views using the pretrained saliency network U2-Net [
28]. Then, the pretrained image-inpainting network CR-Fill [
29] repaired the missing parts. Finally, the foreground and background, which were separated, were blended and combined into a new sample. We used a perceptual hashing algorithm for spatial constraints during the combinations that did not correspond to the actual situation. For example, an event with a zero probability, such as a giant panda in the sky, would be misleading for training the object-detection model. After the above-constrained data expansion, the samples were learned from each other. The training of the few-shot object-detection task was performed based on a feature-reweighting method [
30].
The perceptual hash algorithm pHash reduced the image frequency by the discrete cosine transform (DCT) and then matched similar images by calculating the Hamming distance. The algorithm proceeded as follows: (1) reduce the image to 32
32; (2) convert the image to a grey-scale image; (3) calculate the DCT and DCT mean; (4) perform image pairing to calculate the Hamming distance. The equations to calculate the DCT and Hamming distance are shown in Equations (1)–(3) below:
This analysis can be extended toward a graphical representation (
Figure 3).
2.3. Learning More Robust Appearance Embedding Based on Few-Shot Learning
There is an appearance metric-learning problem in a multiobject-tracking task, and the aim is to learn an embedding space where instances of the same identity are close while instances of different identities are far apart. The metric-learning problem is often defined as a re-identification task in multiobject tracking, mainly aimed at a single category; i.e., pedestrians or vehicles. For example, person re-identification aims at searching for persons across multiple nonoverlapping cameras. The task of Re-ID in this approach shares similar insights with the Re-ID for persons. When presented with an animal-of-interest (query) in video records, an animal Re-ID tells whether this animal has been observed in another place (time). In particular, we tracked nonsingle classes, and each class had very little training data. Thus, we trained the embedding learning process on the few-shot classification task.
Typically, few-shot classification approaches include optimization-based, model-based, and metric-based methods. Since our goal was not to classify but to train a feature learner based on the classification task and its feature map to the target, we performed descriptions of categories and changes in behavior. Thus, directly using a few-shot classification network for training was not applicable. We used elastic-distortion data augmentation to ensure the features had single information. Elastic distortion changed the posture of the target, allowing changes in behavior to be focused and adapted to our eventual tracking task. Because the target was moving and the pose of the same target was constantly changing in the video stream, this variation affected the recognition rate of the target identity during the tracking process.
Firstly, the affine transformation of the image was performed to obtain a random displacement field generated by each pixel of the image. Then, we convolved the random displacement field with
which obeyed the Gaussian distribution, and multiplied the random displacement field by the control factor α, where δ controlled the smoothness of the image and α controlled the strength of the image deformation. We set δ to 0.07 and α to 5. The experimental results suggested that these parameter values enriched the target pose without distorting the image.
Figure 4 shows a partial example of the processed image.
We imitated the approach used in [
31] in our training process, using self-supervision and regularization techniques to learn generic representations suitable for few-shot tasks. Firstly, we used a pretext task called rotation to construct the self-supervised task on the base classes. In the self-supervised task, the input image was rotated by r degrees and
. The secondary purpose of the model was to predict the amount of rotation applied to the image. An auxiliary loss was added to the standard classification loss in the image classification setting to learn the generic representation. Secondly, fine-tuning with a manifold mixup was conducted on the base classes and endangered classes for a few more epochs. The manifold mixup provided a practical way to flatten a given class of data representations into a compact region. The loss function of the first stage is given by:
where
denotes the self-supervision loss, and
denotes the classification loss. The loss function of the fine-tuning stage is given by:
In addition, we used the input data and with corresponding feature representations at layer given by and , respectively.
2.4. Association Module
Considering that the current association modules were all associated with the conventional multiobject-tracking task and were not applied to the multiobject-tracking task with a few-shot setting, it was inevitable that there were some shortcomings. To fit the Few-MOT module to the MOT-EA dataset, we made some improvements with the DeepSORT association algorithm.
2.4.1. Three-Stage Matching
In addition to cascade matching and IoU matching, we added a central-point matching, which helped to alleviate the mismatched detection boxes and tracks due to an excessive intersection ratio. The IoU matrix
was calculated as the intersection-over-union (IoU) distance between every detection and object pair.
where
is the area of
, and
represents the area of
.
The central-point matrix
was calculated as the central-point distance between every detection and track pair.
Figure 5 illustrates the difference between center-point matching and IoU matching.
where
and
are the central-point of the track and detection, respectively.
During the experiment, we found that if we only used cascade matching and central-point matching in the matching stage, it did help to reduce ID switching, but at the same time, it was accompanied by an increase in missed targets. Thus, we worked together on IoU matching and central-point matching and designed the following trajectory-reconstruction module to alleviate this problem. In the MOT-EA dataset, we measured the above two matching strategies using the two indicators for FN and FP, and found that three-stage matching was the best matching strategy. A further discussion of the ablation experiment reveals more details.
2.4.2. Trajectory-Reconstruction Module
We found an excessive amount of missed detection cases in the tracking process given in the previous section, which damaged the tracking effect. In addition, the performance of the few-shot detector was not as good as YOLO, Faster R-CNN, and other general object detectors. The target was then lost in the video stream. However, according to [
32], the tracking accuracy of multiple objects can be written as:
where
is false negatives (the sum of missing amounts in the entire video),
is false positives (the sum of the number of false positives in the entire video),
is the ID switch (the total number of ID switches), and
is the number of the ground truth objects. The object-detection accuracy significantly affected the tracking accuracy, so we designed a trajectory-reconstruction module to deal with the above problems. This module compensated for the lack of a few-shot detector.
First, we specified the central region, as shown in
Figure 6 below. Then, if there was no trajectory and the detection box was successfully matched in frame T, we judged the central-point position of the track in frame T-1. If the central point of the bounding box in frame T-1 was located in the central area, we reconstructed the track of frame T-1 to frame T under the present conditions. We allowed the reconstruction of five consecutive frames because the object’s position usually changed slightly in five consecutive frames. The box of frame T-1 could still locate the object’s position in the subsequent four frames.
4. Discussion
So-called “big data” approaches are not limited to technical fields because the combination of large-scale data collection and processing techniques can be applied to various scientific questions. Meanwhile, it has never been more critical to keep track of biodiversity than over the past decade, as losses and declines have accelerated with ongoing development. However, multiobject tracking is complicated, with experts relying on human interactions and specialized equipment. While cheap camera sensors have become essential for capturing wildlife and their movements, they generate enormous amounts of data, and have become a prominent research tool for studying nature. Machine- and deep-learning methods hold promise as efficient tools to scale local studies to a global understanding of the animal world [
38]. However, the detection and tracking of the target animals are challenging, essentially because the data obtained from wild species are too sparse.
Our deep-learning approach detected and tracked the target animals and produced spatiotemporal tracks that following multiple objects through few-shot learning to alleviate instance imbalance and insufficient sample challenges. This study demonstrated how incorporating track methods, deep learning, and few-shot learning can be a research tool for studying wild animals. Turning now to its limitations, we note that our approach heavily relied on the prominent parts’ detection performance, and easily failed to track infant animals.
5. Conclusions
In this work, we introduced Few-MOT for wildlife to embed uncertainty into designing a multiobject-tracking model by combining the richness of deep neural networks with few-shot learning, leading to correctable and robust models. The approach systematically provided a fully automated pipeline framework to integrate the few-shot learning method with deep neural networks. Instead of a discriminative model, a spatial-constraints model was created. Furthermore, a trajectory-reconstruction module was also proposed to compensate for the shortcomings of the few-shot object detection. Our model demonstrated the efficacy of using few-shot architectures for biological application: the automated recognition and tracking of wildlife. Unlike older, data-rich automation methods, our method was entirely based on deep learning with few shots. It also improved previous deep-learning methods by combining few-shot learning with a multiobject-tracking task. It also provided a rich set of examples by incorporating contextual details of the environment, which can be valuable for few-shot learning efficiency, especially in wildlife detection and tracking.
The data explosion that has come with the widespread use of camera traps poses challenges while simultaneously providing opportunities for wildlife monitoring and conservation [
39]. Tracking animals is essential in animal-welfare research, especially when combined with physical and physiological parameters [
40,
41,
42]. It is also challenging to curate datasets large enough to train tracking models. We proposed a deep-learning framework named Few-MOT to track endangered animals based on a few-shot-learning and tracking-by-detection paradigm. It could record the daily movements of the target being tracked, marking areas of frequent activity and other information that could be used for further analysis. This framework offered a few-shot object detection with spatial constraints to localize objects and a trajectory-reconstruction module for a better association. The experimental results showed that our method performed better on the few-shot multiobject-tracking task. Our new datasets open up many opportunities for further research on multiobject tracking. There were some limitations to our study, notably that the detector could detect a nonexistent target in the wrong place when the surroundings were extremely similar to the target. Future work should investigate how multiple variables, such as the features of the training dataset and different network architectures, affect performance. Furthermore, a key driver in the advancement of intelligent video systems for wildlife conservation will be the increasing availability of datasets for sufficient species, and open-source datasets should also be proposed in the future.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}