
Programming and Setting Up the Object Detection Algorithm YOLO to Determine Feeding Activities of Beef Cattle: A Comparison between YOLOv8m and YOLOv10m

 , , and
, , and
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Animals, Diet and Measurements
2.2. Recording System
2.3. Data Set Description and Labelling
- Visiting: Characterized by the animal standing with its head elevated and not engaging in any feeding activity, signifying the absence of feed intake.
- Biting: Defined by the animal lowering its head toward the feeder, suggesting active engagement with the feed and typically indicating the initial action of feed intake.
- Chewing: Marked by the animal raising its head yet displaying clear signs of mastication, evidenced by the presence of feed in the mouth.
2.4. YOLOv8 and v10 Network Structure
2.5. Training
2.6. Evaluation Indicators
- Precision is the ratio of TP predictions to the total number of positive predictions made by the model (both TP and FP). It reflects the accuracy of the positive predictions.
- Recall is the ratio of TP predictions to the total number of actual positive cases (TP and FN). It measures the model’s ability to identify all relevant instances.
- Average Precision (AP) is defined as the area under the precision-recall curve; AP provides a single value that summarizes the model’s precision and recall performance at various threshold levels.
- Mean Average Precision (mAP) is the mean of the average precision values for all classes. It serves as a comprehensive measure that evaluates the overall performance of the model across different object classes.
- F1-Score is the harmonic mean of precision and recall. It balances these two metrics by providing a single score that accounts for both false positives and false negatives.
3. Results
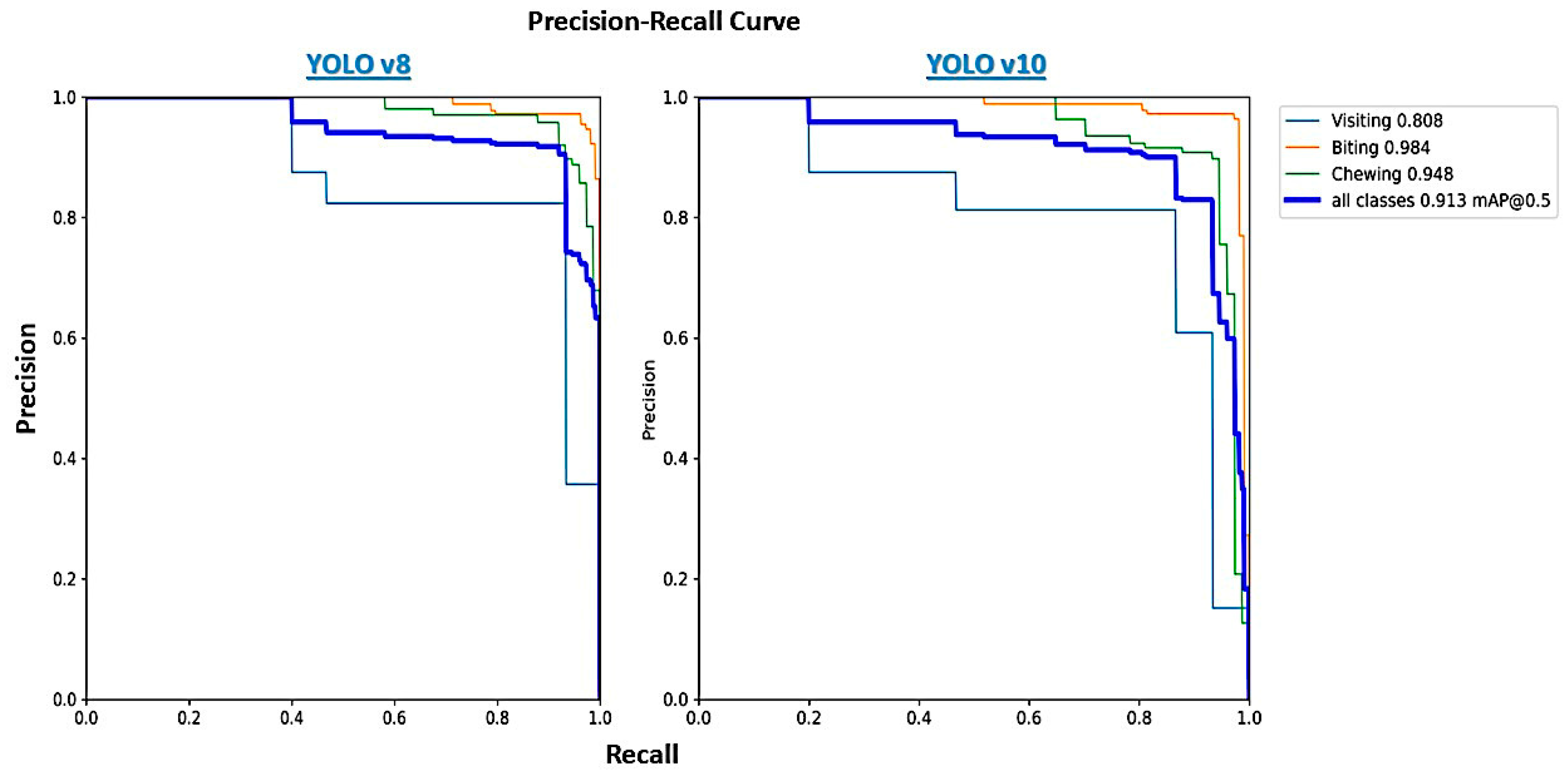
3.1. YOLOv8 and v10 Performance in Feeding Behavior Detection
3.2. Confusion Matrix of Feeding Activities Predicted with YOLOv8 vs. v10
3.3. Learning Rates and Parameters of YOLOv8 and v10
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Difford, G.F.; Plichta, D.R.; Løvendahl, P.; Lassen, J.; Noel, S.J.; Højberg, O.; Wright, A.-D.G.; Zhu, Z.; Kristensen, L.; Nielsen, H.B.; et al. Host genetics and the rumen microbiome jointly associate with methane emissions in dairy cows. PLoS Genet. 2018, 14, e1007580. [Google Scholar] [CrossRef] [PubMed]
- Atkinson, G.A.; Smith, L.N.; Smith, M.L.; Reynolds, C.K.; Humphries, D.J.; Moorby, J.M.; Leemans, D.K.; Kingston-Smith, A.H. A computer vision approach to improving cattle digestive health by the monitoring of faecal samples. Sci. Rep. 2020, 10, 17557. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Zhu, W.; Norton, T. Behaviour recognition of pigs and cattle: Journey from computer vision to deep learning. Comput. Electron. Agric. 2021, 187, 106255. [Google Scholar] [CrossRef]
- McDonagh, J.; Tzimiropoulos, G.; Slinger, K.R.; Huggett, Z.J.; Down, P.M.; Bell, M.J. Detecting dairy cow behavior using vision technology. Agriculture 2021, 11, 675. [Google Scholar] [CrossRef]
- Islam, N.; Yoder, J.; Nasiri, A.; Burns, R.T.; Gan, H. Analysis of the drinking behavior of beef cattle using computer vision. Animals 2023, 13, 2984. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Han, M.; Song, H.; Song, L.; Duan, Y. Monitoring the respiratory behavior of multiple cows based on computer vision and deep learning. J. Dairy Sci. 2023, 106, 2963–2979. [Google Scholar] [CrossRef] [PubMed]
- Fuentes, A.; Yoon, S.; Park, J.; Park, D.S. Deep learning-based hierarchical cattle behavior recognition with spatio-temporal information. Comput. Electron. Agric. 2020, 177, 105627. [Google Scholar] [CrossRef]
- Jeong, K.; Kim, D.-R.; Ryu, J.-H.; Kim, H.-W.; Cho, J.; Lee, E.; Jeong, J.-H. A Monitoring System for Cattle Behavior Detection using YOLO-v8 in IoT Environments. In Proceedings of the 2024 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 5–8 January 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–4. [Google Scholar]
- Yu, J.; Ye, X.; Tu, Q. Traffic sign detection and recognition in multiimages using a fusion model with YOLO and VGG network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16632–16642. [Google Scholar] [CrossRef]
- Wang, Z.; Hua, Z.; Wen, Y.; Zhang, S.; Xu, X.; Song, H. E-YOLO: Recognition of estrus cow based on improved YOLOv8n model. Expert Syst. Appl. 2024, 238, 122212. [Google Scholar] [CrossRef]
- Fuentes, A.; Han, S.; Nasir, M.F.; Park, J.; Yoon, S.; Park, D.S. Multiview monitoring of individual cattle behavior based on action recognition in closed barns using deep learning. Animals 2023, 13, 2020. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Guo, Y.; Qiao, Y.; Sukkarieh, S.; Chai, L.; He, D. Bigru-attention based cow behavior classification using video data for precision livestock farming. Trans. ASABE 2021, 64, 1823–1833. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.T.; Mark Liao, H.Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; Kwon, Y.; Michael, K.; Thanh Minh, M. ultralytics/yolov5: v6. 0-YOLOv5n ‘Nano’ Models, Roboflow Integration, TensorFlow Export, OpenCV DNN Support; Zenodo: Genève, Switzerland, 2021. [Google Scholar] [CrossRef]
- Balasso, P.; Marchesini, G.; Ughelini, N.; Serva, L.; Andrighetto, I. Machine learning to detect posture and behavior in dairy cows: Information from an accelerometer on the animal’s left flank. Animals 2021, 11, 2972. [Google Scholar] [CrossRef] [PubMed]
- Bezen, R.; Edan, Y.; Halachmi, I. Computer vision system for measuring individual cow feed intake using RGB-D camera and deep learning algorithms. Comput. Electron. Agric. 2020, 172, 105345. [Google Scholar] [CrossRef]
- Ciaglia, F.; Zuppichini, F.S.; Guerrie, P.; McQuade, M.; Solawetz, J. Roboflow 100: A rich, multi-domain object detection benchmark. arXiv 2022, arXiv:2211.13523. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Shao, Y.; Zhang, R.; Lv, C.; Luo, Z.; Che, M. TL-YOLO: Foreign-Object Detection on Power Transmission Line Based on Improved Yolov8. Electronics 2024, 13, 1543. [Google Scholar] [CrossRef]
- Xu, X.; Feng, Z.; Cao, C.; Yu, C.; Li, M.; Wu, Z.; Ye, S.; Shang, Y. STN-Track: Multiobject tracking of unmanned aerial vehicles by swin transformer neck and new data association method. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8734–8743. [Google Scholar] [CrossRef]
- Sohan, M.; Sai Ram, T.; Rami Reddy, C.V. A Review on YOLOv8 and Its Advancements. In Data Intelligence and Cognitive Informatics: ICDICI 2023; Jacob, I.J., Piramuthu, S., Falkowski-Gilski, P., Eds.; Algorithms for Intelligent Systems; Springer: Singapore, 2024. [Google Scholar]
- Alif, M.A.R.; Hussain, M. YOLOv1 to YOLOv10: A comprehensive review of YOLO variants and their application in the agricultural domain. arXiv 2024, arXiv:2406.10139. [Google Scholar]
- Andriamandroso, A.; Bindelle, J.; Mercatoris, B.; Lebeau, F. A review on the use of sensors to monitor cattle jaw movements and behavior when grazing. Biotechnol. Agron. Soc. Environ. 2016, 20, 273–286. [Google Scholar] [CrossRef]
- Tani, Y.; Yokota, Y.; Yayota, M.; Ohtani, S. Automatic recognition and classification of cattle chewing activity by an acoustic monitoring method with a single-axis acceleration sensor. Comput. Electron. Agric. 2013, 92, 54–65. [Google Scholar] [CrossRef]
- Alvarenga, F.; Borges, I.; Oddy, V.; Dobos, R. Discrimination of biting and chewing behaviour in sheep using a tri-axial accelerometer. Comput. Electron. Agric. 2020, 168, 105051. [Google Scholar] [CrossRef]
- Galli, J.; Cangiano, C.; Pece, M.; Larripa, M.; Milone, D.; Utsumi, S.; Laca, E. Monitoring and assessment of ingestive chewing sounds for prediction of herbage intake rate in grazing cattle. Animal 2018, 12, 973–982. [Google Scholar] [CrossRef] [PubMed]
- Rau, L.M.; Chelotti, J.O.; Vanrell, S.R.; Giovanini, L.L. Developments on real-time monitoring of grazing cattle feeding behavior using sound. In Proceedings of the 2020 IEEE International Conference on Industrial Technology (ICIT), Buenos Aires, Argentina, 26–28 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 771–776. [Google Scholar]
- Chelotti, J.O.; Vanrell, S.R.; Milone, D.H.; Utsumi, S.A.; Galli, J.R.; Rufiner, H.L.; Giovanini, L.L. A real-time algorithm for acoustic monitoring of ingestive behavior of grazing cattle. Comput. Electron. Agric. 2016, 127, 64–75. [Google Scholar] [CrossRef]
- Tan, L.; Dong, X.; Ma, Y.; Yu, C. A multiple object tracking algorithm based on YOLO detection. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Megalingam, R.K.; Babu, D.H.T.A.; Sriram, G.; YashwanthAvvari, V.S. Concurrent detection and identification of multiple objects using YOLO algorithm. In Proceedings of the 2021 XXIII Symposium on Image, Signal Processing and Artificial Vision (STSIVA), Popayan, Colombia, 15–17 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Sapkota, R.; Qureshi, R.; Calero, M.F.; Hussain, M.; Badjugar, C.; Nepal, U.; Poulose, A.; Zeno, P.; Vaddevolu, U.B.; Yan, H.; et al. YOLOv10 to Its Genesis: A Decadal and Comprehensive Review of the You Only Look Once Series. arXiv 2024, arXiv:2406.19407. [Google Scholar]
- Zhou, Y. A YOLO-NL object detector for real-time detection. Expert Syst. Appl. 2024, 238, 122256. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Class | Instances µ | Precision * | Recall * | F1-Score * | mAP * |
|---|---|---|---|---|---|---|
| YOLOv8 | All | 2040 | - | - | - | 0.92 |
| Biting | 1128 | 0.99 | 0.98 | 0.99 | - | |
| Chewing | 762 | 0.84 | 0.98 | 0.91 | - | |
| Visiting | 150 | 1.00 | 0.15 | 0.26 | - | |
| YOLOv10 | All | 1953 | - | - | - | 0.94 |
| Biting | 1081 | 0.99 | 0.98 | 0.99 | - | |
| Chewing | 737 | 0.87 | 0.99 | 0.93 | - | |
| Visiting | 135 | 0.98 | 0.37 | 0.54 | - |
| Feature * | YOLOv8 | YOLOv10 |
|---|---|---|
| Layers | 295 | 498 |
| GFLOPs | 79.1 | 64.0 |
| Optimizer | AdamW | AdamW |
| Learning Rate | 0.01 | 0.01 |
| Momentum | 0.937 | 0.937 |
| Weight Decay | 0.0005 | 0.0005 |
| Warmup Epochs | 3.0 | 3.0 |
| Training Epochs | 1000 | 1000 |
| Batch Size | 8 | 8 |
| Image Size | 640 | 640 |
| Freeze Layers | model.22.dfl.conv.weight | model.23.dfl.conv.weight |
| Augmentations | Blur, MedianBlur, ToGray, CLAHE | Blur, MedianBlur, ToGray, CLAHE |
| Mixed Precision | Yes | Yes |
| Max Detections | 300 | 300 |
| Classes | 3 | 3 |
| Patience | 50 | 50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guarnido-Lopez, P.; Ramirez-Agudelo, J.-F.; Denimal, E.; Benaouda, M. Programming and Setting Up the Object Detection Algorithm YOLO to Determine Feeding Activities of Beef Cattle: A Comparison between YOLOv8m and YOLOv10m. Animals 2024, 14, 2821. https://doi.org/10.3390/ani14192821
Guarnido-Lopez P, Ramirez-Agudelo J-F, Denimal E, Benaouda M. Programming and Setting Up the Object Detection Algorithm YOLO to Determine Feeding Activities of Beef Cattle: A Comparison between YOLOv8m and YOLOv10m. Animals. 2024; 14(19):2821. https://doi.org/10.3390/ani14192821
Chicago/Turabian StyleGuarnido-Lopez, Pablo, John-Fredy Ramirez-Agudelo, Emmanuel Denimal, and Mohammed Benaouda. 2024. "Programming and Setting Up the Object Detection Algorithm YOLO to Determine Feeding Activities of Beef Cattle: A Comparison between YOLOv8m and YOLOv10m" Animals 14, no. 19: 2821. https://doi.org/10.3390/ani14192821