
Dynamics Learning Rate Bias in Pigeons: Insights from Reinforcement Learning and Neural Correlates

 , and
, and
Abstract
Simple Summary
Abstract
1. Introduction
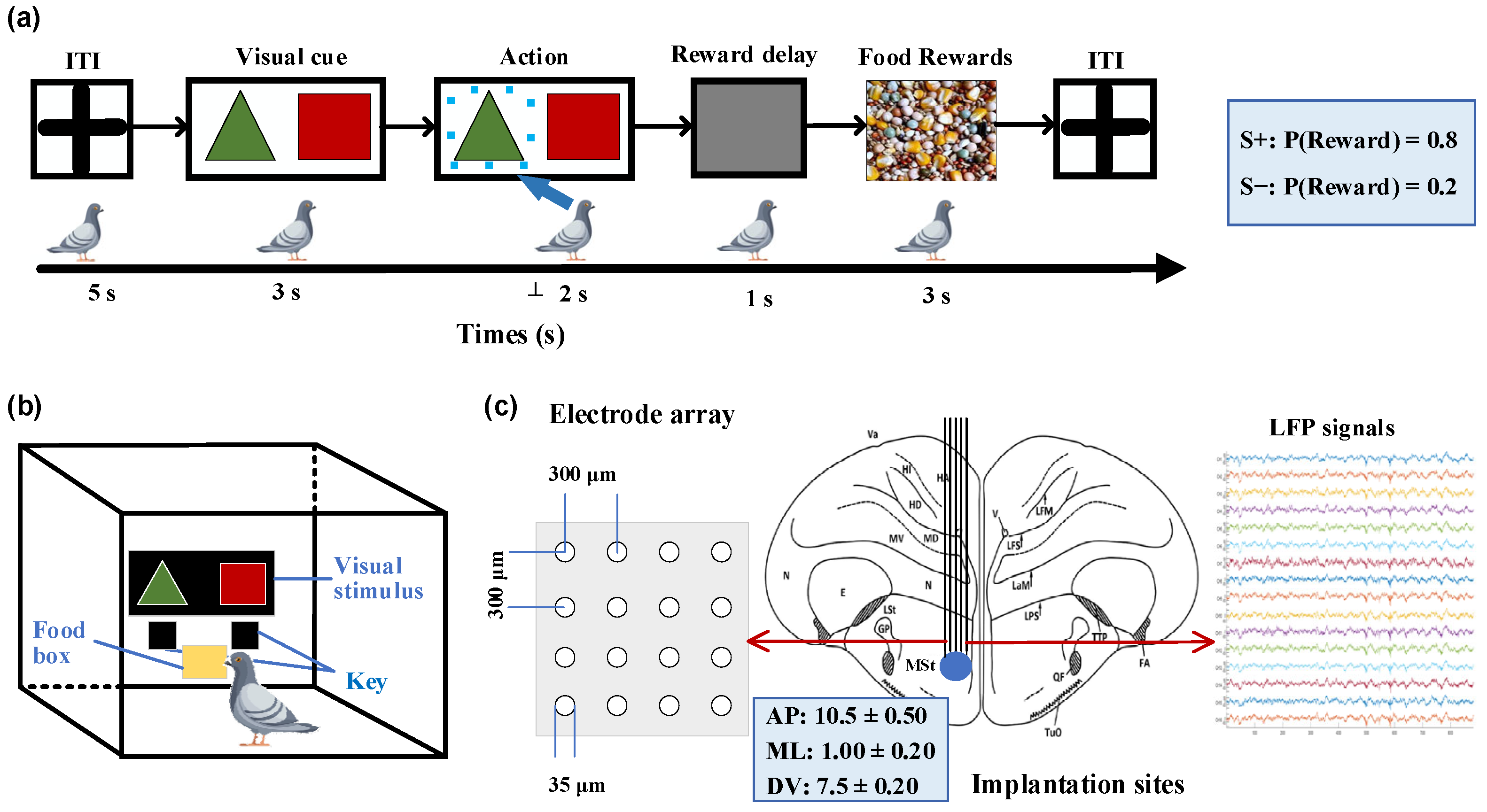
2. Materials and Methods
2.1. Animals, Experimental Procedure and Surgery
2.2. Data Acquisition
2.3. Behavioral Learning Model
2.4. LFP Data Analysis
2.5. Statistical Analysis
3. Results
3.1. Behavioral Results
3.2. Choice Modulates Gamma LFP Power of Outcome Phase
3.3. Gamma-Band LFP Correlates of Values Modulated by the Dynamic Learning Rate Bias
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rangel, A.; Camerer, C.; Montague, P.R. A Framework for Studying the Neurobiology of Value-Based Decision Making. Nat. Rev. Neurosci. 2008, 9, 545–556. [Google Scholar] [CrossRef] [PubMed]
- Verharen, J.P.H.; Den Ouden, H.E.M.; Adan, R.A.H.; Vanderschuren, L.J.M.J. Modulation of Value-Based Decision Making Behavior by Subregions of the Rat Prefrontal Cortex. Psychopharmacology 2020, 237, 1267–1280. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction. IEEE Trans. Neural Netw. 1998, 9, 1054. [Google Scholar] [CrossRef]
- Louie, K. Asymmetric and Adaptive Reward Coding via Normalized Reinforcement Learning. PLoS Comput. Biol. 2022, 18, e1010350. [Google Scholar] [CrossRef] [PubMed]
- Ohta, H.; Satori, K.; Takarada, Y.; Arake, M.; Ishizuka, T.; Morimoto, Y.; Takahashi, T. The Asymmetric Learning Rates of Murine Exploratory Behavior in Sparse Reward Environments. Neural Netw. 2021, 143, 218–229. [Google Scholar] [CrossRef] [PubMed]
- Palminteri, S.; Lebreton, M. The Computational Roots of Positivity and Confirmation Biases in Reinforcement Learning. Trends Cogn. Sci. 2022, 26, 607–621. [Google Scholar] [CrossRef] [PubMed]
- Niv, Y.; Edlund, J.A.; Dayan, P.; O’Doherty, J.P. Neural Prediction Errors Reveal a Risk-Sensitive Reinforcement-Learning Process in the Human Brain. J. Neurosci. 2012, 32, 551–562. [Google Scholar] [CrossRef] [PubMed]
- Sharot, T.; Garrett, N. Forming Beliefs: Why Valence Matters. Trends Cogn. Sci. 2016, 20, 25–33. [Google Scholar] [CrossRef]
- Gershman, S.J. Do Learning Rates Adapt to the Distribution of Rewards? Psychon. B Rev. 2015, 22, 1320–1327. [Google Scholar] [CrossRef]
- den Ouden, H.E.M.; Daw, N.D.; Fernandez, G.; Elshout, J.A.; Rijpkema, M.; Hoogman, M.; Franke, B.; Cools, R. Dissociable Effects of Dopamine and Serotonin on Reversal Learning. Neuron 2013, 80, 1090–1100. [Google Scholar] [CrossRef]
- Lefebvre, G.; Lebreton, M.; Meyniel, F.; Bourgeois-Gironde, S.; Palminteri, S. Behavioural and Neural Characterization of Optimistic Reinforcement Learning. Nat. Hum. Behav. 2017, 1, 0067. [Google Scholar] [CrossRef]
- Chambon, V.; Théro, H.; Vidal, M.; Vandendriessche, H.; Haggard, P.; Palminteri, S. Information about Action Outcomes Differentially Affects Learning from Self-Determined versus Imposed Choices. Nat. Hum. Behav. 2020, 4, 1067–1079. [Google Scholar] [CrossRef]
- Schultz, W. Neuronal Reward and Decision Signals: From Theories to Data. Physiol. Rev. 2015, 95, 853–951. [Google Scholar] [CrossRef]
- Schultz, W. Dopamine Reward Prediction-Error Signalling: A Two-Component Response. Nat. Rev. Neurosci. 2016, 17, 183–195. [Google Scholar] [CrossRef]
- Montague, P.; Dayan, P.; Sejnowski, T. A Framework for Mesencephalic Dopamine Systems Based on Predictive Hebbian Learning. J. Neurosci. 1996, 16, 1936–1947. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.; Kim, H.; Hwang, S.H.; Han, M.; Lee, S.-H.; Kim, H.F. Primate Ventral Striatum Maintains Neural Representations of the Value of Previously Rewarded Objects for Habitual Seeking. Nat. Commun. 2021, 12, 2100. [Google Scholar] [CrossRef] [PubMed]
- Day, J.J.; Roitman, M.F.; Wightman, R.M.; Carelli, R.M. Associative Learning Mediates Dynamic Shifts in Dopamine Signaling in the Nucleus Accumbens. Nat. Neurosci. 2007, 10, 1020–1028. [Google Scholar] [CrossRef] [PubMed]
- Basanisi, R.; Marche, K.; Combrisson, E.; Apicella, P.; Brovelli, A. Beta Oscillations in Monkey Striatum Encode Reward Prediction Error Signals. J. Neurosci. 2023, 43, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Sul, J.H.; Huh, N.; Lee, D.; Jung, M.W. Role of Striatum in Updating Values of Chosen Actions. J. Neurosci. 2009, 29, 14701–14712. [Google Scholar] [CrossRef] [PubMed]
- Atallah, H.E.; McCool, A.D.; Howe, M.W.; Graybiel, A.M. Neurons in the Ventral Striatum Exhibit Cell-Type-Specific Representations of Outcome during Learning. Neuron 2014, 82, 1145–1156. [Google Scholar] [CrossRef] [PubMed]
- Abler, B.; Walter, H.; Erk, S.; Kammerer, H.; Spitzer, M. Prediction Error as a Linear Function of Reward Probability Is Coded in Human Nucleus Accumbens. NeuroImage 2006, 31, 790–795. [Google Scholar] [CrossRef] [PubMed]
- Collins, A.G.E.; Frank, M.J. Opponent Actor Learning (OpAL): Modeling Interactive Effects of Striatal Dopamine on Reinforcement Learning and Choice Incentive. Psychol. Rev. 2014, 121, 337–366. [Google Scholar] [CrossRef] [PubMed]
- Cox, S.M.L.; Frank, M.J.; Larcher, K.; Fellows, L.K.; Clark, C.A.; Leyton, M.; Dagher, A. Striatal D1 and D2 Signaling Differentially Predict Learning from Positive and Negative Outcomes. NeuroImage 2015, 109, 95–101. [Google Scholar] [CrossRef] [PubMed]
- Cox, J.; Witten, I.B. Striatal Circuits for Reward Learning and Decision-Making. Nat. Rev. Neurosci. 2019, 20, 482–494. [Google Scholar] [CrossRef] [PubMed]
- Halpern, B.P.; Karten, H.J.; Hodos, W. A Stereotaxic Atlas of the Brain of the Pigeon (Columbia Livia). Am. J. Psychol. 1968, 81, 289. [Google Scholar] [CrossRef]
- Gao, M.; Pusch, R.; Güntürkün, O. Blocking NMDA-Receptors in the Pigeon’s Medial Striatum Impairs Extinction Acquisition and Induces a Motoric Disinhibition in an Appetitive Classical Conditioning Paradigm. Front. Behav. Neurosci. 2019, 13, 153. [Google Scholar] [CrossRef]
- Schultz, W. Behavioral Theories and the Neurophysiology of Reward. Annu. Rev. Psychol. 2006, 57, 87–115. [Google Scholar] [CrossRef]
- Kahnt, T.; Park, S.Q.; Cohen, M.X.; Beck, A.; Heinz, A.; Wrase, J. Dorsal Striatal–Midbrain Connectivity in Humans Predicts How Reinforcements Are Used to Guide Decisions. J. Cogn. Neurosci. 2009, 21, 1332–1345. [Google Scholar] [CrossRef]
- Carl Aberg, K.; Doell, K.C.; Schwartz, S. Linking Individual Learning Styles to Approach-Avoidance Motivational Traits and Computational Aspects of Reinforcement Learning. PLoS ONE 2016, 11, e0166675. [Google Scholar] [CrossRef]
- Chase, H.W.; Frank, M.J.; Michael, A.; Bullmore, E.T.; Sahakian, B.J.; Robbins, T.W. Approach and Avoidance Learning in Patients with Major Depression and Healthy Controls: Relation to Anhedonia. Psychol. Med. 2010, 40, 433–440. [Google Scholar] [CrossRef]
- Daw, N.D.; Gershman, S.J.; Seymour, B.; Dayan, P.; Dolan, R.J. Model-Based Influences on Humans’ Choices and Striatal Prediction Errors. Neuron 2011, 69, 1204–1215. [Google Scholar] [CrossRef]
- Daw, N.D.; O’Doherty, J.P.; Dayan, P.; Seymour, B.; Dolan, R.J. Cortical Substrates for Exploratory Decisions in Humans. Nature 2006, 441, 876–879. [Google Scholar] [CrossRef]
- Yoshida, M.; Chinzorig, C.; Matsumoto, J.; Nishimaru, H.; Ono, T.; Yamazaki, M.; Nishijo, H. Configural Cues Associated with Reward Elicit Theta Oscillations of Rat Retrosplenial Cortical Neurons Phase-Locked to LFP Theta Cycles. Cereb. Cortex 2021, 31, 2729–2741. [Google Scholar] [CrossRef] [PubMed]
- Wise, T.; Dolan, R.J. Associations between Aversive Learning Processes and Transdiagnostic Psychiatric Symptoms in a General Population Sample. Nat. Commun. 2020, 11, 4179. [Google Scholar] [CrossRef] [PubMed]
- Wise, T.; Michely, J.; Dayan, P.; Dolan, R.J. A Computational Account of Threat-Related Attentional Bias. PLoS Comput. Biol. 2019, 15, e1007341. [Google Scholar] [CrossRef] [PubMed]
- Mikhael, J.G.; Bogacz, R. Learning Reward Uncertainty in the Basal Ganglia. PLoS Comput. Biol. 2016, 12, e1005062. [Google Scholar] [CrossRef] [PubMed]
- Strait, C.E.; Sleezer, B.J.; Hayden, B.Y. Signatures of Value Comparison in Ventral Striatum Neurons. PLoS Biol. 2015, 13, e1002173. [Google Scholar] [CrossRef] [PubMed]
- Nakhnikian, A.; Rebec, G.V.; Grasse, L.M.; Dwiel, L.L.; Shimono, M.; Beggs, J.M. Behavior Modulates Effective Connectivity between Cortex and Striatum. PLoS ONE 2014, 9, e89443. [Google Scholar] [CrossRef] [PubMed]
- Malhotra, S.; Cross, R.W.; Zhang, A.; van der Meer, M.A.A. Ventral Striatal Gamma Oscillations Are Highly Variable from Trial to Trial, and Are Dominated by Behavioural State, and Only Weakly Influenced by Outcome Value. Eur. J. Neurosci. 2015, 42, 2818–2832. [Google Scholar] [CrossRef] [PubMed]
- Verharen, J.P.H.; Adan, R.A.H.; Vanderschuren, L.J.M.J. Differential Contributions of Striatal Dopamine D1 and D2 Receptors to Component Processes of Value-Based Decision Making. Neuropsychopharmacology 2019, 44, 2195–2204. [Google Scholar] [CrossRef]
- van der Meer, M.A.A.; Kalenscher, T.; Lansink, C.S.; Pennartz, C.M.A.; Berke, J.D.; Redish, A.D. Integrating Early Results on Ventral Striatal Gamma Oscillations in the Rat. Front. Neurosci. 2010, 4, 300. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S+ Value (Model 1) | S− Value (Model 1) | S+ Value (Model 2) | S− Value (Model 2) | RPE (Model 1) | RPE (Model 2) | |
|---|---|---|---|---|---|---|
| Spearman correlation | 0.2303 | 0.1747 | 0.3647 | 0.3309 | 0.0579 | 0.0093 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, F.; Yang, L.; Yang, L.; Li, J.; Li, M.; Shang, Z. Dynamics Learning Rate Bias in Pigeons: Insights from Reinforcement Learning and Neural Correlates. Animals 2024, 14, 489. https://doi.org/10.3390/ani14030489
Jin F, Yang L, Yang L, Li J, Li M, Shang Z. Dynamics Learning Rate Bias in Pigeons: Insights from Reinforcement Learning and Neural Correlates. Animals. 2024; 14(3):489. https://doi.org/10.3390/ani14030489
Chicago/Turabian StyleJin, Fuli, Lifang Yang, Long Yang, Jiajia Li, Mengmeng Li, and Zhigang Shang. 2024. "Dynamics Learning Rate Bias in Pigeons: Insights from Reinforcement Learning and Neural Correlates" Animals 14, no. 3: 489. https://doi.org/10.3390/ani14030489
APA StyleJin, F., Yang, L., Yang, L., Li, J., Li, M., & Shang, Z. (2024). Dynamics Learning Rate Bias in Pigeons: Insights from Reinforcement Learning and Neural Correlates. Animals, 14(3), 489. https://doi.org/10.3390/ani14030489