
Interaction between Risk Single-Nucleotide Polymorphisms of Developmental Dyslexia and Parental Education on Reading Ability: Evidence for Differential Susceptibility Theory


Highlights
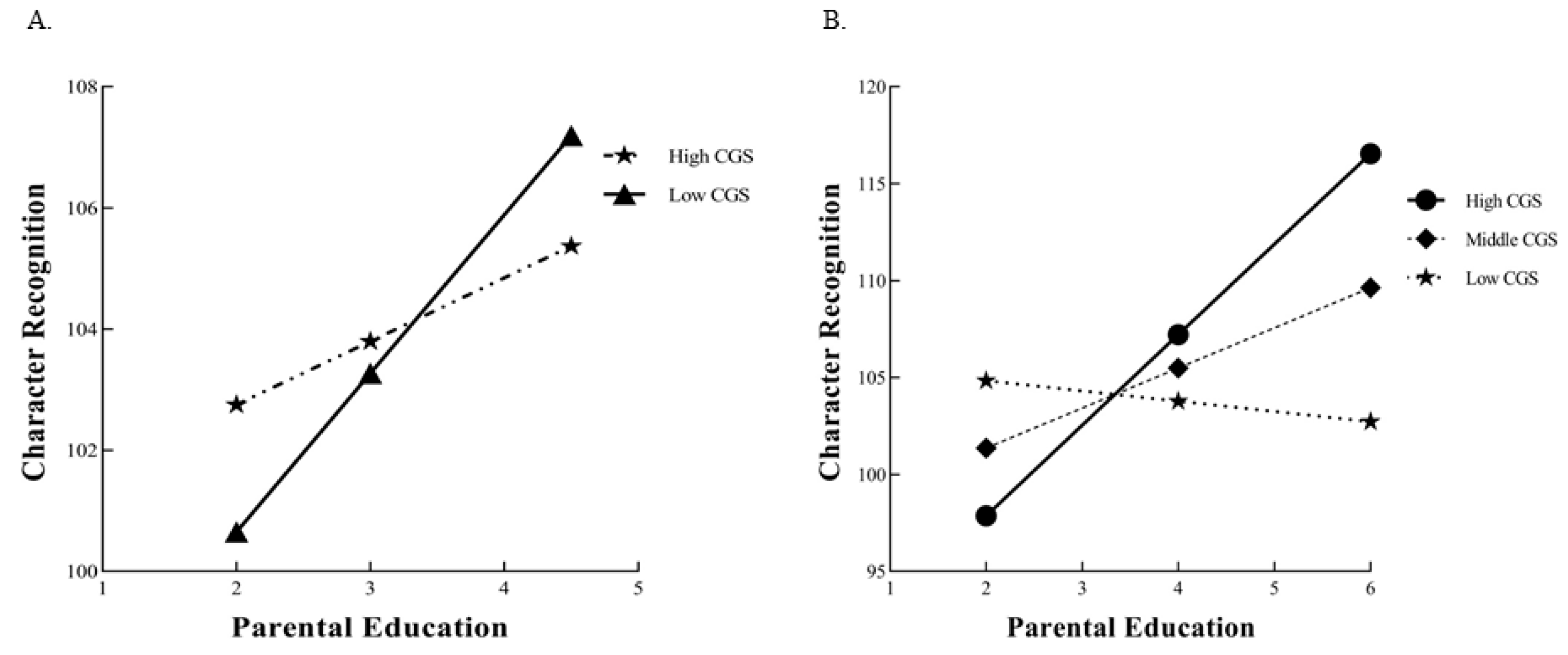
- We calculated the cumulative genetic score (CGS) of nine SNPs related to develop-mental dyslexia and found that the interaction between CGS and parental education had an effect on reading ability. This G×E interaction supported the differential susceptibility model, which states that individuals carrying more plasticity alleles are affected more than those carrying fewer.
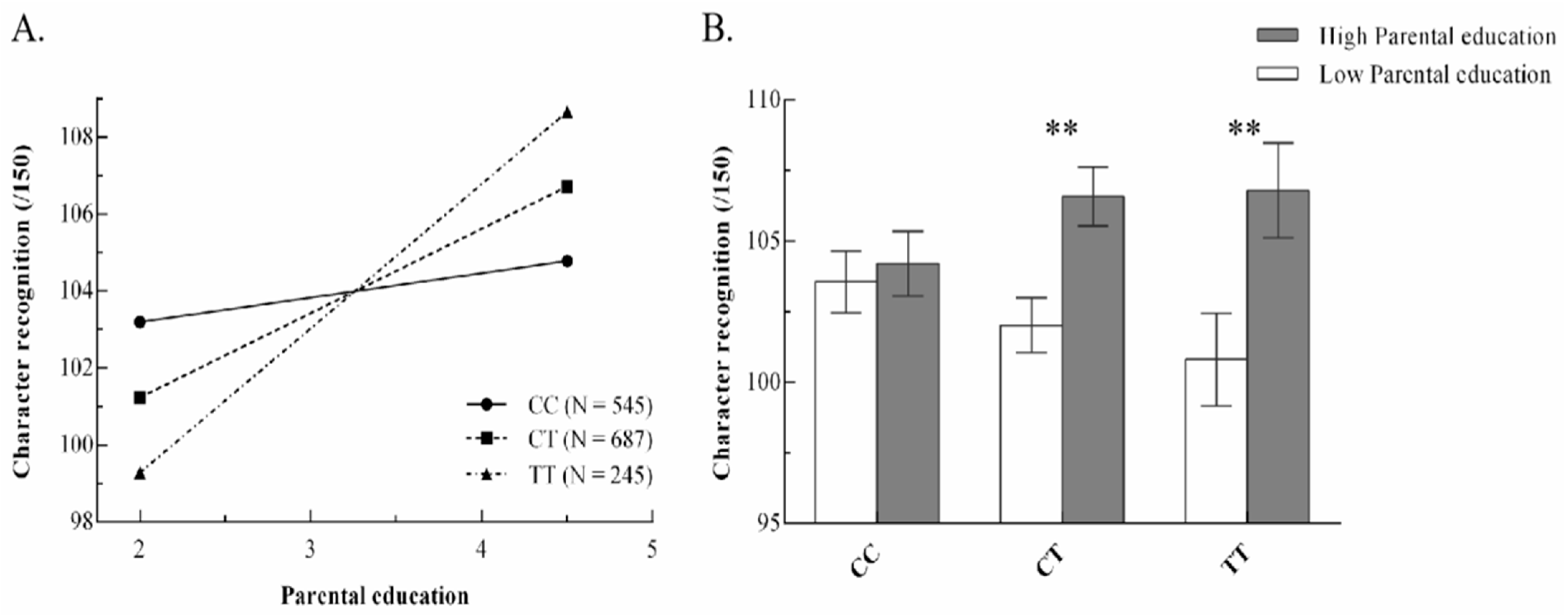
- The interaction between rs281238 and parental education conformed to the strong differential susceptibility model, which states that children with the “T” allele would have the highest reading ability in a positive environment and the lowest reading ability in an adverse environment, whereas children without the “C” allele would not benefit from parental education.
- Our results indicated the validity of the differential susceptibility model in reading ability, suggesting that regardless of whether children are struggling with dyslexia or possess good reading skills, an improved environment can lead to enhance-ments in their performance.
- This model underscores the importance of environmental factors in shaping the reading abilities of all children, emphasizing the potential for growth and devel-opment across the spectrum of reading abilities.
Abstract
:1. Introduction
2. Methods
2.1. Participants
2.2. Measures
2.3. Data Analysis
3. Results
3.1. Correlation Analysis
3.2. Standard Exploratory Analysis
3.3. Confirmatory Re-Parameterized Analysis
3.3.1. Differential Susceptibility vs. Diathesis–Stress Model for rs281238
3.3.2. Differential Susceptibility vs. Diathesis–Stress Model for CGS
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arbanas, G. Diagnostic and statistical manual of mental disorders (DSM-5). Alcohol. Psychiatry Res. 2015, 51, 61–64. [Google Scholar]
- Cécile Di, F.; Ava, G.; Hugo, P.; Franck, R. Epidemiology of developmental dyslexia: A comparison of DSM-5 and ICD-11 criteria. medRxiv 2020, 2020, 998067. [Google Scholar] [CrossRef]
- Bishop, D.V.; Snowling, M.J. Developmental dyslexia and specific language impairment: Same or different? Psychol. Bull. 2004, 130, 858–886. [Google Scholar] [CrossRef]
- Allotey, J.; Zamora, J.; Cheong-See, F.; Kalidindi, M.; Arroyo-Manzano, D.; Asztalos, E.; van der Post, J.; Mol, B.W.; Moore, D.; Birtles, D.; et al. Cognitive, motor, behavioural and academic performances of children born preterm: A meta-analysis and systematic review involving 64,061 children. BJOG 2018, 125, 16–25. [Google Scholar] [CrossRef]
- Aram, D.; Korat, O.; Hassunah-Arafat, S. The contribution of early home literacy activities to first grade reading and writing achievements in Arabic. Read. Writ. 2013, 26, 1517–1536. [Google Scholar] [CrossRef]
- Fernald, A.; Marchman, V.A.; Weisleder, A. SES differences in language processing skill and vocabulary are evident at 18 months. Dev. Sci. 2013, 16, 234–248. [Google Scholar] [CrossRef]
- Friend, A.; DeFries, J.C.; Olson, R.K. Parental education moderates genetic influences on reading disability. Psychol. Sci. 2008, 19, 1124–1130. [Google Scholar] [CrossRef]
- Litt, J.S.; Gerry Taylor, H.; Margevicius, S.; Schluchter, M.; Andreias, L.; Hack, M. Academic achievement of adolescents born with extremely low birth weight. Acta Paediatr. 2012, 101, 1240–1245. [Google Scholar] [CrossRef]
- Hoff, E. The specificity of environmental influence: Socioeconomic status affects early vocabulary development via maternal speech. Child. Dev. 2003, 74, 1368–1378. [Google Scholar] [CrossRef]
- Noble, K.G.; Farah, M.J.; McCandliss, B.D. Socioeconomic background modulates cognition-achievement relationships in reading. Cogn. Dev. 2006, 21, 349–368. [Google Scholar] [CrossRef]
- Rowe, M.L.; Goldin-Meadow, S. Differences in early gesture explain SES disparities in child vocabulary size at school entry. Science 2009, 323, 951–953. [Google Scholar] [CrossRef]
- Turkheimer, E.; Haley, A.; Waldron, M.; D’Onofrio, B.; Gottesman, I.I. Socioeconomic status modifies heritability of IQ in young children. Psychol. Sci. 2003, 14, 623–628. [Google Scholar] [CrossRef]
- Kremen, W.S.; Jacobson, K.C.; Xian, H.; Eisen, S.A.; Waterman, B.; Toomey, R.; Neale, M.C.; Tsuang, M.T.; Lyons, M.J. Heritability of Word Recognition in Middle-Aged Men Varies as a Function of Parental Education. Behav. Genet. 2005, 35, 417–433. [Google Scholar] [CrossRef]
- Manuck, S.B.; McCaffery, J.M. Gene-Environment Interaction. Annu. Rev. Psychol. 2014, 65, 41–70. [Google Scholar] [CrossRef]
- Caspi, A.; McClay, J.; Moffitt, T.E.; Mill, J.; Martin, J.; Craig, I.W.; Taylor, A.; Poulton, R. Role of genotype in the cycle of violence in maltreated children. Science 2002, 297, 851–854. [Google Scholar] [CrossRef]
- Caspi, A.; Sugden, K.; Moffitt, T.E.; Taylor, A.; Craig, I.W.; Harrington, H.; McClay, J.; Mill, J.; Martin, J.; Braithwaite, A.; et al. Influence of life stress on depression: Moderation by a polymorphism in the 5-HTT gene. Science 2003, 301, 386–389. [Google Scholar] [CrossRef]
- Mascheretti, S.; Bureau, A.; Battaglia, M.; Simone, D.; Quadrelli, E.; Croteau, J.; Cellino, M.R.; Giorda, R.; Beri, S.; Maziade, M.; et al. An assessment of gene-by-environment interactions in developmental dyslexia-related phenotypes. Genes Brain Behav. 2013, 12, 47–55. [Google Scholar] [CrossRef]
- Brem, S.; Bucher, K.; Halder, P.; Summers, P.; Dietrich, T.; Martin, E.; Brandeis, D. Evidence for developmental changes in the visual word processing network beyond adolescence. NeuroImage 2006, 29, 822–837. [Google Scholar] [CrossRef]
- Su, M.; Wang, J.; Maurer, U.; Zhang, Y.; Li, J.; McBride, C.; Tardif, T.; Liu, Y.; Shu, H. Gene–environment interaction on neural mechanisms of orthographic processing in Chinese children. J. Neurolinguistics 2015, 33, 172–186. [Google Scholar] [CrossRef]
- Belsky, J.; Pluess, M. Beyond diathesis stress: Differential susceptibility to environmental influences. Psychol. Bull. 2009, 135, 885–908. [Google Scholar] [CrossRef]
- Widaman, K.F.; Helm, J.L.; Castro-Schilo, L.; Pluess, M.; Stallings, M.C.; Belsky, J. Distinguishing ordinal and disordinal interactions. Psychol. Methods 2012, 17, 615–622. [Google Scholar] [CrossRef]
- Kegel, C.A.T.; Bus, A.G.; van Ijzendoorn, M.H. Differential Susceptibility in Early Literacy Instruction Through Computer Games: The Role of the Dopamine D4 Receptor Gene (DRD4). Mind Brain Educ. 2011, 5, 71–78. [Google Scholar] [CrossRef]
- Green, C.G.; Babineau, V.; Jolicoeur-Martineau, A.; Bouvette-Turcot, A.A.; Minde, K.; Sassi, R.; St-André, M.; Carrey, N.; Atkinson, L.; Kennedy, J.L.; et al. Prenatal maternal depression and child serotonin transporter linked polymorphic region (5-HTTLPR) and dopamine receptor D4 (DRD4) genotype predict negative emotionality from 3 to 36 months. Dev. Psychopathol. 2017, 29, 901–917. [Google Scholar] [CrossRef]
- Wang, M.; Tian, X.; Zhang, W. Interactions between the combined genotypes of 5-HTTLPR and BDNF Val66Met polymorphisms and parenting on adolescent depressive symptoms: A three-year longitudinal study. J. Affect. Disord. 2020, 265, 104–111. [Google Scholar] [CrossRef]
- Eicher, J.D.; Powers, N.R.; Miller, L.L.; Akshoomoff, N.; Amaral, D.G.; Bloss, C.S.; Libiger, O.; Schork, N.J.; Darst, B.F.; Casey, B.J.; et al. Genome-wide association study of shared components of reading disability and language impairment. Genes Brain Behav. 2013, 12, 792–801. [Google Scholar] [CrossRef]
- Field, L.L.; Shumansky, K.; Ryan, J.; Truong, D.; Swiergala, E.; Kaplan, B.J. Dense-map genome scan for dyslexia supports loci at 4q13, 16p12, 17q22; suggests novel locus at 7q36. Genes Brain Behav. 2013, 12, 56–69. [Google Scholar] [CrossRef]
- Gialluisi, A.; Andlauer, T.F.M.; Mirza-Schreiber, N.; Moll, K.; Becker, J.; Hoffmann, P.; Ludwig, K.U.; Czamara, D.; Pourcain, B.S.; Honbolygó, F.; et al. Genome-wide association study reveals new insights into the heritability and genetic correlates of developmental dyslexia. Mol. Psychiatry 2021, 26, 3004–3017. [Google Scholar] [CrossRef]
- Gialluisi, A.; Andlauer, T.F.M.; Mirza-Schreiber, N.; Moll, K.; Becker, J.; Hoffmann, P.; Ludwig, K.U.; Czamara, D.; St Pourcain, B.; Brandler, W.; et al. Genome-wide association scan identifies new variants associated with a cognitive predictor of dyslexia. Transl. Psychiatry 2019, 9, 77. [Google Scholar] [CrossRef]
- Luciano, M.; Evans, D.M.; Hansell, N.K.; Medland, S.E.; Montgomery, G.W.; Martin, N.G.; Wright, M.J.; Bates, T.C. A genome-wide association study for reading and language abilities in two population cohorts. Genes Brain Behav. 2013, 12, 645–652. [Google Scholar] [CrossRef]
- Meaburn EL, Harlaar N, Craig IW, Schalkwyk LC, Plomin R: Quantitative trait locus association scan of early reading disability and ability using pooled DNA and 100K SNP microarrays in a sample of 5760 children. Mol. Psychiatry 2008, 13, 729–740. [CrossRef]
- Truong, D.T.; Adams, A.K.; Paniagua, S.; Frijters, J.C.; Boada, R.; Hill, D.E.; Lovett, M.W.; Mahone, E.M.; Willcutt, E.G.; Wolf, M.; et al. Multivariate genome-wide association study of rapid automatised naming and rapid alternating stimulus in Hispanic American and African-American youth. J. Med. Genet. 2019, 56, 557–566. [Google Scholar] [CrossRef]
- Price, K.M.; Wigg, K.G.; Feng, Y.; Blokland, K.; Wilkinson, M.; He, G.; Kerr, E.N.; Carter, T.C.; Guger, S.L.; Lovett, M.W.; et al. Genome-wide association study of word reading: Overlap with risk genes for neurodevelopmental disorders. Genes Brain Behav. 2020, 19, e12648. [Google Scholar] [CrossRef]
- Doust, C.; Fontanillas, P.; Eising, E.; Gordon, S.D.; Wang, Z.; Alagöz, G.; Molz, B.; Pourcain, B.S.; Francks, C.; Marioni, R.E.; et al. Discovery of 42 genome-wide significant loci associated with dyslexia. Nat. Genet. 2022, 54, 1621–1629. [Google Scholar] [CrossRef]
- Eising, E.; Mirza-Schreiber, N.; de Zeeuw, E.L.; Wang, C.A.; Truong, D.T.; Allegrini, A.G.; Shapland, C.Y.; Zhu, G.; Wigg, K.G.; Gerritse, M.L.; et al. Genome-wide analyses of individual differences in quantitatively assessed reading- and language-related skills in up to 34,000 people. Proc. Natl. Acad. Sci. USA 2022, 119, e2202764119. [Google Scholar] [CrossRef]
- Thomas, D. Gene--environment-wide association studies: Emerging approaches. Nat. Rev. Genet. 2010, 11, 259–272. [Google Scholar] [CrossRef]
- Bradley, R.H.; Corwyn, R.F. Socioeconomic status and child development. Annu. Rev. Psychol. 2002, 53, 371–399. [Google Scholar] [CrossRef]
- Craig, L. Parental education, time in paid work and time with children: An Australian time-diary analysis. Br. J. Sociol. 2006, 57, 553–575. [Google Scholar] [CrossRef]
- Anderson, C.A.; Pettersson, F.H.; Clarke, G.M.; Cardon, L.R.; Morris, A.P.; Zondervan, K.T. Data quality control in genetic case-control association studies. Nat. Protoc. 2010, 5, 1564–1573. [Google Scholar] [CrossRef]
- Chang, C.C.; Chow, C.C.; Tellier, L.C.; Vattikuti, S.; Purcell, S.M.; Lee, J.J. Second-generation PLINK: Rising to the challenge of larger and richer datasets. Gigascience 2015, 4, 7. [Google Scholar] [CrossRef]
- Pan, J.; Shu, H. Rapid Automatized Naming and Its Unique Contribution to Reading: Evidence from Chinese Dyslexia. In Reading Development and Difficulties in Monolingual and Bilingual Chinese Children; Chen, X., Wang, Q., Luo, Y.C., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 125–138. [Google Scholar]
- Belsky, J.; Widaman, K. Editorial Perspective: Integrating exploratory and competitive-confirmatory approaches to testing person × environment interactions. J. Child. Psychol. Psychiatry 2018, 59, 296–298. [Google Scholar] [CrossRef]
- Belsky, J.; van Ijzendoorn, M.H. Genetic differential susceptibility to the effects of parenting. Curr. Opin. Psychol. 2017, 15, 125–130. [Google Scholar] [CrossRef]
- He, Z.; Wang, K.C.; Koprivica, V.; Ming, G.; Song, H.J. Knowing how to navigate: Mechanisms of semaphorin signaling in the nervous system. Sci. STKE 2002, 2002, re1. [Google Scholar] [CrossRef]
- Kichaev, G.; Bhatia, G.; Loh, P.R.; Gazal, S.; Burch, K.; Freund, M.K.; Schoech, A.; Pasaniuc, B.; Price, A.L. Leveraging Polygenic Functional Enrichment to Improve GWAS Power. Am. J. Hum. Genet. 2019, 104, 65–75. [Google Scholar] [CrossRef]
- Klein, M.; Walters, R.K.; Demontis, D.; Stein, J.L.; Hibar, D.P.; Adams, H.H.; Bralten, J.; Roth Mota, N.; Schachar, R.; Sonuga-Barke, E.; et al. Genetic Markers of ADHD-Related Variations in Intracranial Volume. Am. J. Psychiatry 2019, 176, 228–238. [Google Scholar] [CrossRef]
- Lam, M.; Trampush, J.W.; Yu, J.; Knowles, E.; Davies, G.; Liewald, D.C.; Starr, J.M.; Djurovic, S.; Melle, I.; Sundet, K.; et al. Large-Scale Cognitive GWAS Meta-Analysis Reveals Tissue-Specific Neural Expression and Potential Nootropic Drug Targets. Cell Rep. 2017, 21, 2597–2613. [Google Scholar] [CrossRef]
- Lee, J.J.; Wedow, R.; Okbay, A.; Kong, E.; Maghzian, O.; Zacher, M.; Nguyen-Viet, T.A.; Bowers, P.; Sidorenko, J.; Karlsson Linnér, R.; et al. Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. Nat. Genet. 2018, 50, 1112–1121. [Google Scholar] [CrossRef]
- Davies, G.; Lam, M.; Harris, S.E.; Trampush, J.W.; Luciano, M.; Hill, W.D.; Hagenaars, S.P.; Ritchie, S.J.; Marioni, R.E.; Fawns-Ritchie, C.; et al. Study of 300,486 individuals identifies 148 independent genetic loci influencing general cognitive function. Nat. Commun. 2018, 9, 2098. [Google Scholar] [CrossRef]
- Plomin, R.; Haworth, C.M.A.; Davis, O.S.P. Common disorders are quantitative traits. Nat. Rev. Genet. 2009, 10, 872–878. [Google Scholar] [CrossRef]
- Steiger, H.; Thaler, L.; Gauvin, L.; Joober, R.; Labbe, A.; Israel, M.; Kucer, A. Epistatic interactions involving DRD2, DRD4, and COMT polymorphisms and risk of substance abuse in women with binge-purge eating disturbances. J. Psychiatr. Res. 2016, 77, 8–14. [Google Scholar] [CrossRef]
- Tyler, A.L.; Asselbergs, F.W.; Williams, S.M.; Moore, J.H. Shadows of complexity: What biological networks reveal about epistasis and pleiotropy. Bioessays 2009, 31, 220–227. [Google Scholar] [CrossRef]
- Belsky, J.; Pluess, M.; Widaman, K.F. Confirmatory and competitive evaluation of alternative gene-environment interaction hypotheses. J. Child. Psychol. Psychiatry 2013, 54, 1135–1143. [Google Scholar] [CrossRef]
- Bakermans-Kranenburg, M.J.; van IJzendoorn, M.H. Gene-environment interaction of the dopamine D4 receptor (DRD4) and observed maternal insensitivity predicting externalizing behavior in preschoolers. Dev. Psychobiol. 2006, 48, 406–409. [Google Scholar] [CrossRef]
- Keers, R.; Coleman, J.R.; Lester, K.J.; Roberts, S.; Breen, G.; Thastum, M.; Bögels, S.; Schneider, S.; Heiervang, E.; Meiser-Stedman, R.; et al. A Genome-Wide Test of the Differential Susceptibility Hypothesis Reveals a Genetic Predictor of Differential Response to Psychological Treatments for Child Anxiety Disorders. Psychother. Psychosom. 2016, 85, 146–158. [Google Scholar] [CrossRef]
- Knafo, A.; Jaffee, S.R. Gene-environment correlation in developmental psychopathology. Dev. Psychopathol. 2013, 25, 1–6. [Google Scholar] [CrossRef]
- Van Ijzendoorn, M.H.; Bakermans-Kranenburg, M.J.; Belsky, J.; Beach, S.; Brody, G.; Dodge, K.A.; Greenberg, M.; Posner, M.; Scott, S. Gene-by-environment experiments: A new approach to finding the missing heritability. Nat. Rev. Genet. 2011, 12, 881. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| SNP | Traits a | Reference | Year | p Value a | Base Pair | Risk Allele a | Beta a | Gene | χ2 (1) b | pb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | rs1541518 | Non-word reading | Genome-wide association scan identifies new variants associated with a cognitive predictor of dyslexia [28] | 2019 | 6 × 10−8 | 31,108,665 | G | 0.177 | ADCYAP1R1 | 0.02 | 0.99 |
| 2 | rs281238 | Phoneme awareness | 1 × 10−7 | 47,432,075 | T | 0.156 | SEMA6D | 1.29 | 0.52 | ||
| 3 | rs4571421 | Rapid automatized naming of pictures | 3 × 10−7 | 188,588,642 | C | 0.168 | LINC02118 | 0.32 | 0.85 | ||
| 4 | rs7301219 | Rapid automatized naming of pictures | 5 × 10−7 | 43,731,097 | C | 0.151 | -- | 2.31 | 0.31 | ||
| 5 | rs9925265 | Phoneme awareness | 4.51 × 10−7 | 126,496,851 | G | 0.148 | SLC12A3 | 0.28 | 0.87 | ||
| 6 | rs7187223 | Non-word reading | A genome-wide association study for reading and language abilities in two population cohorts [29] | 2013 | 1 × 10−7 | 82,424,128 | A | 0.251 | -- | 1.58 | 0.45 |
| 7 | rs764255 | Word reading | 1.8 × 10−7 | 72,271,184 | T | −0.077 | ZFHX3 | 2.62 | 0.27 | ||
| 8 | rs6963842 | Rapid automatized naming of letters | Multivariate genome-wide association study of rapid automatized naming and rapid alternating stimulus in Hispanic American and African-American youth [31] | 2019 | 2 × 10−7 | 107,994,544 | G | 0.02 | LAMB1 | 0.21 | 0.90 |
| 9 | rs9540938 | Latent naming speed | 5 × 10−7 | 66,867,593 | A | -- | PCDH9 | 1.35 | 0.51 |
| Standard Parameterization | Re-Parameterized Regression Equation | ||||||
|---|---|---|---|---|---|---|---|
| Differential Susceptibility | Diathesis–Stress | ||||||
| Parameter | Gene(G) and Environment(E) Main Effects: Model 1 | Main Effects and G×E Interaction: Model 2 | Parameter | Strong: Model 3a | Weak: Model 3b | Strong: Model 3c | Weak: Model 3d |
| A0 | −7.61 (5.67) | −3.71 (5.83) | C | 3.21 (0.36) | 3.21 (0.41) | 6.85 (--) a | 6.84 (--) a |
| A1 | 1.88 (0.43) | 0.63 (0.62) | A0 | −0.90 (4.82) | −1.70 (5.00) | 6.21 (4.60) | 5.08 (4.60) |
| A2 | 0.01 (0.67) | −5.08 (1.94) | A1 | -- | 0.43 (0.67) | -- | 1.77 (0.46) |
| A3 | -- | 1.56 (0.56) | A2 | 2.49 (0.60) | 2.52 (0.60) | 0.48 (0.26) | 1.89 (0.45) |
| A4 | 0.92 (0.04) | 0.92 (0.04) | A3 | 3.27 (0.97) | 3.30 (0.97) | 0.68 (0.36) | 2.09 (0.52) |
| A5 | −2.56 (0.95) | −2.54 (0.95) | A4 | 0.91 (0.04) | 0.92 (0.04) | 0.86 (0.04) | 0.92 (0.04) |
| R2 | 0.2531 | 0.2566 | A5 | −2.53 (0.95) | −2.54 (0.95) | −2.48 (0.95) | −2.56 (0.95) |
| F | 126.1 | 102.9 | R2 | 0.2567 | 0.2569 | 0.2452 | 0.2530 |
| df | 41,472 | 51,471 | F | 102.90 | 103.00 | 120.90 | 101.00 |
| p | <0.0001 | <0.0001 | df | 51,471 | 61,470 | 41,472 | 51,471 |
| F vs. 1 | -- | 7.81 | p | <0.0001 | <0.0001 | <0.0001 | <0.0001 |
| df | -- | 51,471 | F vs. 3b | 0.41 | -- | 11.175 | 7.66 |
| p | -- | 0.0052 | df | 11,470 | -- | 21,470 | 11,470 |
| p | 0.5202 | -- | <0.0001 | 0.0057 | |||
| F vs. 3c | 21.95 | 11.75 | -- | 14.27 | |||
| df | 11,471 | 21,470 | -- | 11,471 | |||
| p | <0.0001 | <0.0001 | -- | 0.0001 | |||
| AIC | 12,770.55 | 12,764.73 | AIC | 12,764.51 | 12,766.09 | 12,784.38 | 12,771.77 |
| BIC | 12,802.34 | 12,801.81 | BIC | 12,801.59 | 12,808.47 | 12,816.17 | 12,808.85 |
| Standard Parameterization | Re-Parameterized Regression Equation | ||||
|---|---|---|---|---|---|
| Differential Susceptibility | Diathesis–Stress | ||||
| Parameter | Gene(G) and Environment(E) Main Effects: Model 3 | Main Effects and G×E Interaction: Model 4 | Parameter | Model 3e | Model 3f |
| A0 | −7.05 (6.01) | 5.69 (8.41) | C | 3.34 (0.56) | 6.84 (--) a |
| A1 | 1.87 (0.43) | −2.09 (1.88) | A0 | −1.28 (5.02) | 5.06 (4.59) |
| A2 | −0.80 (0.29) | −1.75 (0.82) | A1 | −2.09 (1.88) | 1.33 (0.72) |
| A3 | - | 0.52 (0.24) | A2 | 0.52 (0.24) | 0.07 (0.07) |
| A4 | 0.92 (0.04) | 0.92 (0.04) | A3 | 0.92 (0.04) | 0.92 (0.04) |
| A5 | −2.56 (0.95) | −2.57 (0.95) | A4 | −2.57 (0.95) | −2.573 (0.95) |
| R2 | 0.2552 | 0.2575 | R2 | 0.2555 | 0.2536 |
| F | 126.10 | 102.06 | F | 127.70 | 126.40 |
| df | 41,472 | 51,471 | df | 51,471 | 41,472 |
| p | <0.0001 | <0.0001 | p | <0.0001 | <0.0001 |
| F vs. 4 | -- | 4.68 | F vs. 3f | 3.54 | -- |
| df | -- | 11,471 | df | 11,471 | -- |
| p | -- | 0.0307 | p | 0.0491 | -- |
| AIC | 122,770.47 | 12,767.78 | AIC | 12,767.78 | 12,769.67 |
| BIC | 12,802.26 | 12,804.87 | BIC | 12,804.87 | 12,801.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Q.; Cheng, C.; Wang, Z.; Zhang, X.; Zhao, J. Interaction between Risk Single-Nucleotide Polymorphisms of Developmental Dyslexia and Parental Education on Reading Ability: Evidence for Differential Susceptibility Theory. Behav. Sci. 2024, 14, 507. https://doi.org/10.3390/bs14060507
Yang Q, Cheng C, Wang Z, Zhang X, Zhao J. Interaction between Risk Single-Nucleotide Polymorphisms of Developmental Dyslexia and Parental Education on Reading Ability: Evidence for Differential Susceptibility Theory. Behavioral Sciences. 2024; 14(6):507. https://doi.org/10.3390/bs14060507
Chicago/Turabian StyleYang, Qing, Chen Cheng, Zhengjun Wang, Ximiao Zhang, and Jingjing Zhao. 2024. "Interaction between Risk Single-Nucleotide Polymorphisms of Developmental Dyslexia and Parental Education on Reading Ability: Evidence for Differential Susceptibility Theory" Behavioral Sciences 14, no. 6: 507. https://doi.org/10.3390/bs14060507
APA StyleYang, Q., Cheng, C., Wang, Z., Zhang, X., & Zhao, J. (2024). Interaction between Risk Single-Nucleotide Polymorphisms of Developmental Dyslexia and Parental Education on Reading Ability: Evidence for Differential Susceptibility Theory. Behavioral Sciences, 14(6), 507. https://doi.org/10.3390/bs14060507