Evaluation of Light Gradient Boosted Machine Learning Technique in Large Scale Land Use and Land Cover Classification




Abstract
:1. Introduction
Motivation and Objectives
2. Literature Review
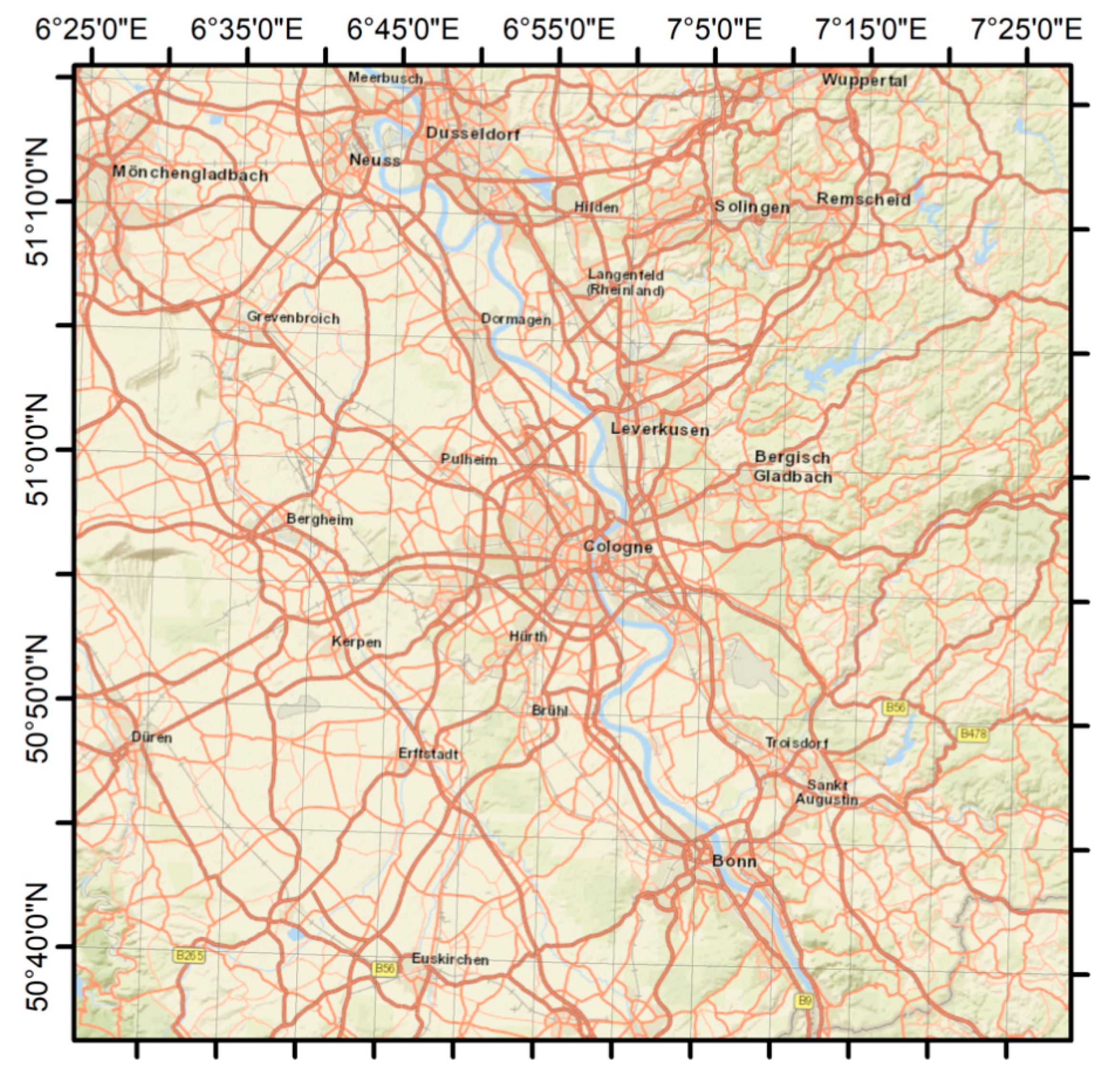
3. Study Area
4. Data
Sentinel-2 Data
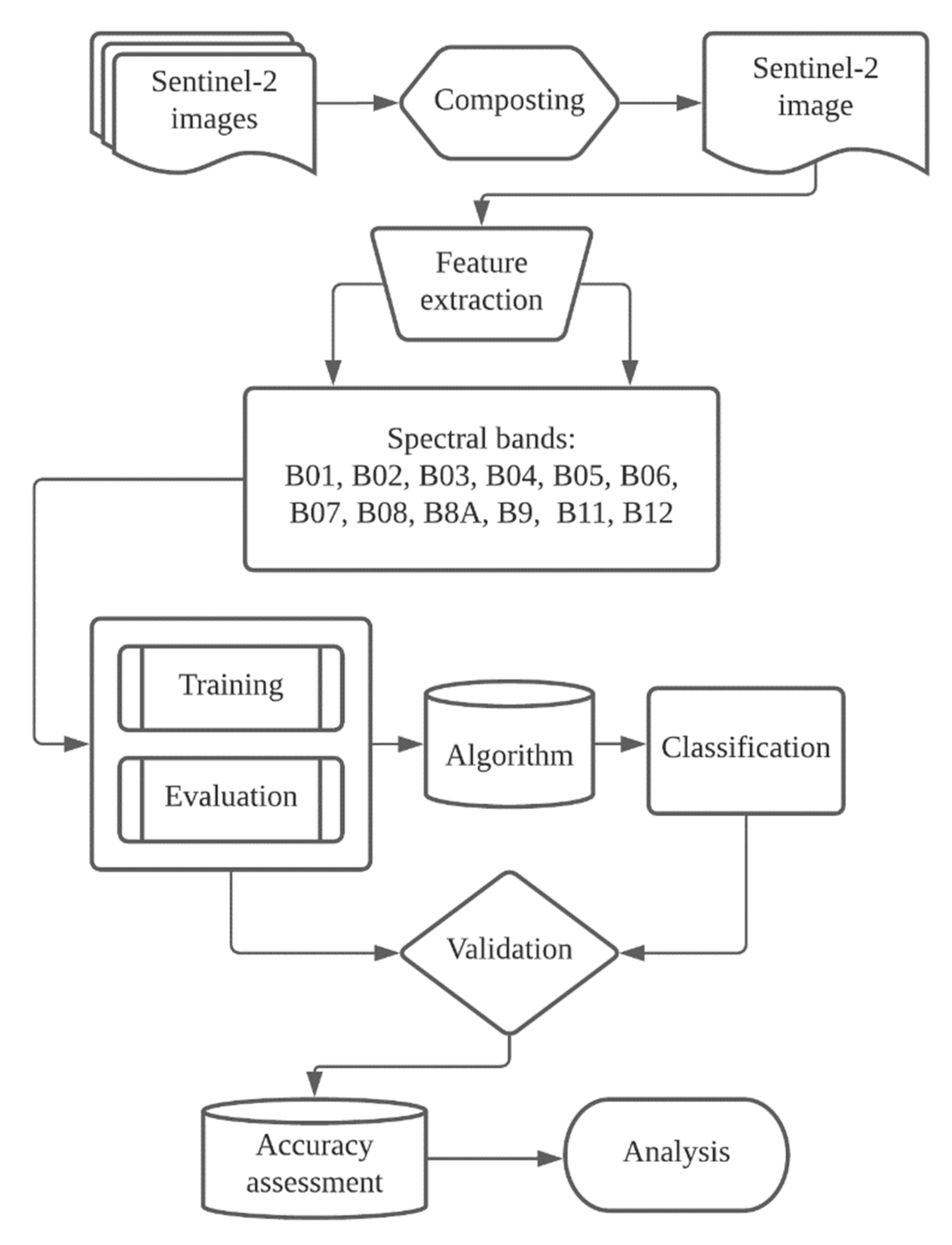
5. Methods
5.1. Study Design and Sample Selection
5.2. Machine Learning Algorithms
5.2.1. Random Forests (RF)
| params: { max_features: 0.5, min_samples_split: 4, min_samples_leaf: 5 } |
5.2.2. Support Vector Machines (SVM)
| params: { C: [10, 100, 1000], gamma: [0.1, 1, 10], kernel: [’rbf’, ’poly’, linear’] } |
5.2.3. Light Gradient Boosting
| params: { num_leaves: 1024, bagging_freq: 3, objective: regression, bagging_fraction: 0.3, learning_rate: 0.005, feature_fraction: 1 }, |
5.3. Model Training and Tuning
5.4. Accuracy and Misclass Assessment
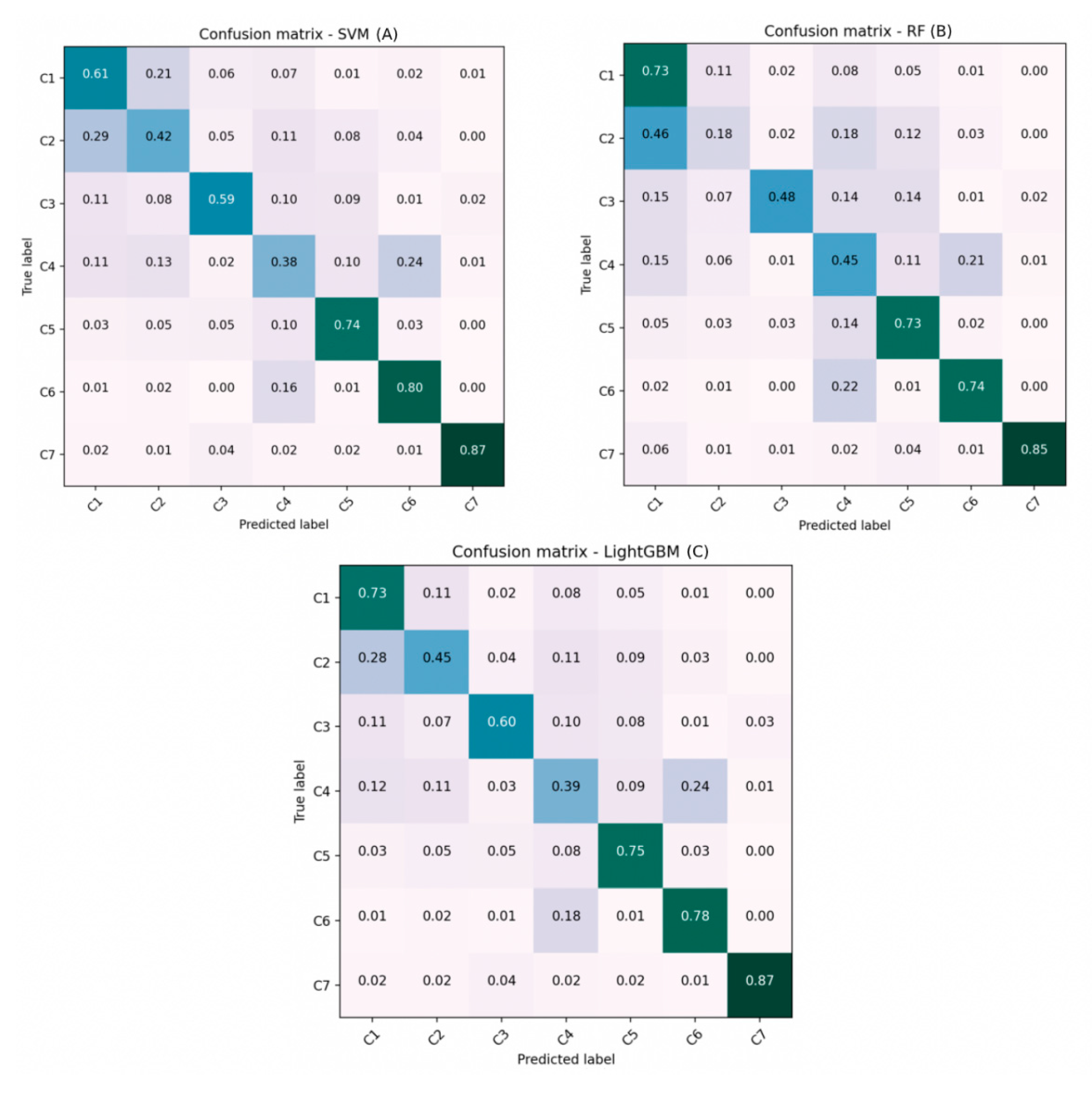
6. Results and Discussion
6.1. Comparing the Alogrithms
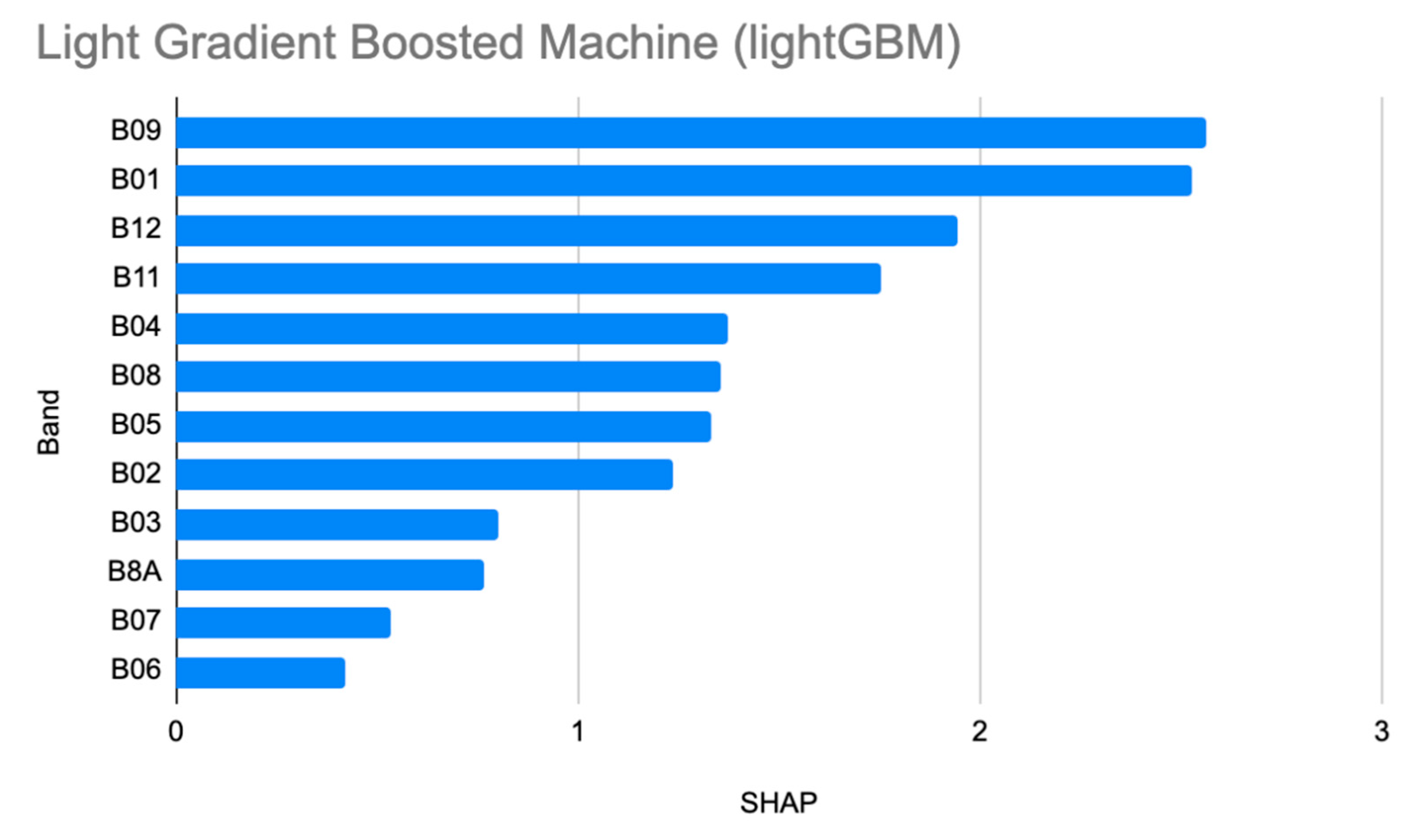
6.2. Variable Importance Metrics
6.3. Calculation Times
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LULC Type | Class ID | Urban Atlas Class | Total Pixels | Pixels (Training/Evaluation) |
|---|---|---|---|---|
| Urban | 1 | 11100: Continuous Urban fabric | 216,422 | 3220/1380 |
| 11210: Discontinuous Dense Urban Fabric | ||||
| 11220: Discontinuous Medium Density Urban Fabric | ||||
| 11230: Discontinuous Low-Density Urban Fabric | ||||
| 11240: Discontinuous very low-density urban fabric | ||||
| 11300: Isolated Structures | ||||
| 12100: Industrial, commercial, public, military and private units | ||||
| Infrastructure | 2 | 12210: Fast transit roads and associated land | 54,568 | |
| 12220: Other roads and associated land | 3220/1380 | |||
| 12230: Railways and associated land | ||||
| 12300: Port areas | ||||
| Mines, dump and construction sites | 3 | 13100: Mineral extraction and dump sites | 49,441 | 3220/1380 |
| 13300: Construction sites | ||||
| 13400: Land without current use | ||||
| Low density vegetation | 4 | 14100: Green urban areas | 53,722 | 3220/1380 |
| 14200: Sports and leisure facilities | ||||
| 32000: Herbaceous vegetation associations | ||||
| 40000: Wetlands | ||||
| Crops | 5 | 21000: Arable land | 474,464 | 3220/1380 |
| 23000: Pastures | ||||
| Dense vegetation | 6 | 31000: Forests | 149,775 | 3220/1380 |
| Water | 7 | 50000: Water | 28,908 | 3220/1380 |
Appendix B



References
- Remote Sensing Imagery. Wiley. Available online: https://www.wiley.com/en-us/Remote+Sensing+Imagery-p-9781848215085 (accessed on 17 August 2020).
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef] [Green Version]
- Ng, E.; Chen, L.; Wang, Y.; Yuan, C. A study on the cooling effects of greening in a high-density city: An experience from Hong Kong. Build. Environ. 2012, 47, 256–271. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Woznicki, S.A.; Baynes, J.; Panlasigui, S.; Mehaffey, M.; Neale, A. Development of a spatially complete floodplain map of the conterminous United States using random forest. Sci. Total Environ. 2019, 647, 942–953. [Google Scholar] [CrossRef] [PubMed]
- Betts, M.G.; Wolf, C.; Ripple, W.J.; Phalan, B.; Millers, K.A.; Duarte, A.; Butchart, S.H.M.; Levi, T. Global forest loss disproportionately erodes biodiversity in intact landscapes. Nature 2017, 547, 441–444. [Google Scholar] [CrossRef]
- Kavzoglu, T. Object-Oriented Random Forest for High Resolution Land Cover Mapping Using Quickbird-2 Imagery. In Handbook of Neural Computation; Elsevier Inc.: Amsterdam, The Netherlands, 2017; pp. 607–619. ISBN 9780128113196. [Google Scholar]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Ustuner, M.; Sanli, F.B. Polarimetric target decompositions and light gradient boosting machine for crop classification: A comparative evaluation. ISPRS Int. J. Geo-Inf. 2019, 8, 97. [Google Scholar] [CrossRef] [Green Version]
- mljar/mljar-supervised: Automates Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning. Available online: https://github.com/mljar/mljar-supervised (accessed on 17 August 2020).
- O’Neill, R.V.; Hunsaker, C.T.; Jones, K.B.; Riitters, K.H.; Wickham, J.D.; Schwartz, P.M.; Goodman, I.A.; Jackson, B.L.; Baillargeon, W.S. Monitoring environmental quality at the landscape scale. Bioscience 1997, 47, 513–520. [Google Scholar] [CrossRef] [Green Version]
- Belmaker, J.; Zarnetske, P.; Tuanmu, M.N.; Zonneveld, S.; Record, S.; Strecker, A.; Beaudrot, L. Empirical evidence for the scale dependence of biotic interactions. Glob. Ecol. Biogeogr. 2015, 24, 750–761. [Google Scholar] [CrossRef] [Green Version]
- Hastings, A.; Byers, J.E.; Crooks, J.A.; Cuddington, K.; Jones, C.G.; Lambrinos, J.G.; Talley, T.S.; Wilson, W.G. Ecosystem engineering in space and time. Ecol. Lett. 2007, 10, 153–164. [Google Scholar] [CrossRef] [PubMed]
- Dudek, G. Short-Term Load Forecasting Using Random Forests. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2015; Volume 323, pp. 821–828. [Google Scholar]
- Dimopoulos, T.; Tyralis, H.; Bakas, N.P.; Hadjimitsis, D. Accuracy measurement of Random Forests and Linear Regression for mass appraisal models that estimate the prices of residential apartments in Nicosia, Cyprus. Adv. Geosci. 2018, 45, 377–382. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D.; Fernández-Delgado, A. Do we Need Hundreds of Classifiers to Solve Real World Classification Problems? J. Mach. Learn. Resear. 2014, 15, 3133–3181. [Google Scholar]
- Wainberg, M.; Alipanahi, B.; Frey, B.J. Are Random Forests Truly the Best Classifiers? J. Mach. Learn. Resear. 2016, 17, 1–5. [Google Scholar]
- Lin, L.; Wang, F.; Xie, X.; Zhong, S. Random forests-based extreme learning machine ensemble for multi-regime time series prediction. Expert Syst. Appl. 2017, 83, 164–176. [Google Scholar] [CrossRef]
- Melkonyan, A.; Koch, J.; Lohmar, F.; Kamath, V.; Munteanu, V.; Alexander Schmidt, J.; Bleischwitz, R. Integrated urban mobility policies in metropolitan areas: A system dynamics approach for the Rhine-Ruhr metropolitan region in Germany. Sustain. Cities Soc. 2020, 61, 102358. [Google Scholar] [CrossRef]
- Esri, HERE, Garmin, USGS, Intermap, INCREMENT P, NRCan, Esri Japan, METI, Esri China (Hong Kong), Esri Korea, Esri (Thailand), NGCC, (c) OpenStreetMap Contributors, and the GIS User Community. Available online: https://www.aacounty.org/departments/public-works/ourwaater/images/ProposedEligibleAreas_Basemap.pdf (accessed on 16 August 2020).
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- LandViewer. EARTH OBSERVING SYSTEM. Available online: https://eos.com/lv/ (accessed on 16 August 2020).
- Spatial-Resolutions-Sentinel-2 MSI-User Guidez-Sentinel Online. Available online: https://sentinel.esa.int/web/sentinel/user-guides/sentinel-2-msi/resolutions/spatial (accessed on 16 August 2020).
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sens. 2017, 9, 95. [Google Scholar] [CrossRef] [Green Version]
- Tran, H.; Tran, T.; Kervyn, M. Dynamics of land cover/land use changes in the Mekong Delta, 1973–2011: A Remote sensing analysis of the Tran Van Thoi District, Ca Mau Province, Vietnam. Remote Sens. 2015, 7, 2899–2925. [Google Scholar] [CrossRef] [Green Version]
- Wessels, K.; van den Bergh, F.; Roy, D.; Salmon, B.; Steenkamp, K.; MacAlister, B.; Swanepoel, D.; Jewitt, D. Rapid Land Cover Map Updates Using Change Detection and Robust Random Forest Classifiers. Remote Sens. 2016, 8, 888. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.K.; Roy, D.P. Using the 500 m MODIS land cover product to derive a consistent continental scale 30 m Landsat land cover classification. Remote Sens. Environ. 2017, 197, 15–34. [Google Scholar] [CrossRef]
- Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W. Disturbance-Informed Annual Land Cover Classification Maps of Canada’s Forested Ecosystems for a 29-Year Landsat Time Series. Can. J. Remote Sens. 2018, 44, 67–87. [Google Scholar] [CrossRef]
- Urban Atlas 2018—Copernicus Land Monitoring Service. Available online: https://land.copernicus.eu/local/urban-atlas/urban-atlas-2018?tab=metadata (accessed on 16 August 2020).
- Brink, H.; Richards, J.; Fetherolf, M.; Cronin, B. Real-World Machine Learning; Manning: New York, NY, USA, 2017. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. Random Forests; Springer: New York, NY, USA, 2009; pp. 587–604. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Wolff, E. Very High Resolution Object-Based Land Use-Land Cover Urban Classification Using Extreme Gradient Boosting. IEEE Geosci. Remote Sens. Lett. 2018, 15, 607–611. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; Association for Computing Machinery: New York, NY, USA, 2016; Volume 13–17, pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- MLJAR: Platform for Building Machine Learning Models. Available online: https://cloud.mljar.com/app/#/p/PVd39X0qkODn/datasources (accessed on 16 August 2020).
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.H. Estimating classification error rate: Repeated cross-validation, repeated hold-out and bootstrap. Comput. Stat. Data Anal. 2009, 53, 3735–3745. [Google Scholar] [CrossRef]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef]
- Lachin, J.M. Introduction to sample size determination and power analysis for clinical trials. Control. Clin. Trials 1981, 2, 93–113. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Abdi, A. Decadal Land-use/land-cover and Land Surface Temperature Change in Dubai and Implications on the Urban Heat Island Effect: A Preliminary Assessment; Center for Open Science: Charlottesville, VA, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- Eklundh, L.; Harrie, L.; Kuusk, A. Investigating relationships between landsat ETM+ sensor data and leaf area index in a boreal conifer forest. Remote Sens. Environ. 2001, 78, 239–251. [Google Scholar] [CrossRef]
- Lukeš, P.; Stenberg, P.; Rautiainen, M.; Mõttus, M.; Vanhatalo, K.M. Optical properties of leaves and needles for boreal tree species in Europe. Remote Sens. Lett. 2013, 4, 667–676. [Google Scholar] [CrossRef]






| Sentinel-2 Bands | Central Wavelength (μm) | Resolution (m) |
|---|---|---|
| B1—Coastal aerosol | 0.443 | 60 1 |
| B2—Blue | 0.490 | 10 |
| B3—Green | 0.560 | 10 |
| B4—Red | 0.665 | 10 |
| B5—Vegetation red edge | 0.705 | 20 1 |
| B6—Vegetation red edge | 0.740 | 20 1 |
| B7—Vegetation red edge | 0.783 | 20 1 |
| B8—NIR | 0.842 | 10 |
| B8A—Vegetation red edge | 0.865 | 20 1 |
| B9—Water vapor | 0.945 | 60 1 |
| B11—SWIR | 1.610 | 20 1 |
| B12—SWIR | 2.190 | 20 1 |
| Class | Producer’s Accuracy | User’s Accuracy | |
|---|---|---|---|
| SVM OA = 0.642, Kappa = 0.583 | Urban | 0.61 | 0.56 |
| Infrastructure | 0.42 | 0.45 | |
| Mines, dump and construction sites | 0.59 | 0.72 | |
| Low density vegetation | 0.42 | 0.40 | |
| Crops | 0.74 | 0.70 | |
| Dense vegetation | 0.80 | 0.69 | |
| Water | 0.87 | 0.95 | |
| RF OA = 0.594, Kappa = 0.527 | Urban | 0.73 | 0.45 |
| Infrastructure | 0.18 | 0.38 | |
| Mines, dump and construction sites | 0.47 | 0.84 | |
| Low density vegetation | 0.45 | 0.36 | |
| Crops | 0.73 | 0.60 | |
| Dense vegetation | 0.74 | 0.71 | |
| Water | 0.85 | 0.96 | |
| LightGBM OA = 0.653, Kappa = 0.596 | Urban | 0.73 | 0.56 |
| Infrastructure | 0.45 | 0.54 | |
| Mines, dump and construction sites | 0.60 | 0.75 | |
| Low density vegetation | 0.39 | 0.40 | |
| Crops | 0.75 | 0.68 | |
| Dense vegetation | 0.77 | 0.70 | |
| Water | 0.87 | 0.95 |
| Result | C1 | C2 | C3 | C4 | C5 | C6 | C7 | |
|---|---|---|---|---|---|---|---|---|
| LightGBM vs. RF | χ2 | 46.745 | 100.947 | 55.125 | 8.256 | 1.76 | 6.282 | 5.263 |
| p | *** | *** | *** | *** | NS | *** | ** | |
| LightGBM vs. SVM | χ2 | 2.481 | 1.215 | 1.306 | 0.125 | 1.161 | 3.361 | 0.1 |
| p | * | NS | NS | NS | NS | * | NS | |
| RF vs. SVM | χ2 | 30.862 | 88.506 | 43.5224 | 10.803 | 0.093 | 20.023 | 5.882 |
| p | *** | *** | *** | *** | NS | *** | ** |
| Z-Test Results | ||
|---|---|---|
| LightGBM vs. RF | χ2 | 0.123 |
| p | 0.45 | |
| LightGBM vs. SVM | χ2 | 3.19 |
| p | 0.00 | |
| RF vs. SVM | χ2 | 3.06 |
| p | 0.00 | |
| Model | Process Time (s) | Machine Size |
|---|---|---|
| LightGBM | 287 s | 8 CPU and 15GB RAM |
| SVM | 367 s | 8 CPU and 15GB RAM |
| RF | 410 s | 8 CPU and 15GB RAM |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
McCarty, D.A.; Kim, H.W.; Lee, H.K. Evaluation of Light Gradient Boosted Machine Learning Technique in Large Scale Land Use and Land Cover Classification. Environments 2020, 7, 84. https://doi.org/10.3390/environments7100084
McCarty DA, Kim HW, Lee HK. Evaluation of Light Gradient Boosted Machine Learning Technique in Large Scale Land Use and Land Cover Classification. Environments. 2020; 7(10):84. https://doi.org/10.3390/environments7100084
Chicago/Turabian StyleMcCarty, Dakota Aaron, Hyun Woo Kim, and Hye Kyung Lee. 2020. "Evaluation of Light Gradient Boosted Machine Learning Technique in Large Scale Land Use and Land Cover Classification" Environments 7, no. 10: 84. https://doi.org/10.3390/environments7100084
APA StyleMcCarty, D. A., Kim, H. W., & Lee, H. K. (2020). Evaluation of Light Gradient Boosted Machine Learning Technique in Large Scale Land Use and Land Cover Classification. Environments, 7(10), 84. https://doi.org/10.3390/environments7100084