1. Introduction
A morpheme refers to the smallest meaningful word in a phrase. In Korean, morphological analysis (MA) is generally performed in the order of morpheme segmentation and part-of-speech (POS) annotation. Based on a Korean sentence, all possible morphemes and their POS tags are suggested through morpheme segmentation. Subsequently, the most suitable morphemes and their POS tags are determined through POS annotation. A named entity (NE) refers to morpheme sequences with specific meanings, such as person, location, and organization names. Named entity recognition (NER) is a subtask of information extraction that identifies NEs in sentences and classifies them into predefined classes. Most NEs are composed of a combination of specific POSs, such as a proper noun, general noun, and number. Therefore, many NER models generally use the results of morphological analysis as informative clues [
1,
2]. However, this pipeline architecture causes the well-known error propagation problem. In other words, errors of MA directly deteriorate the performances of NER models. MA models for agglutinative languages, such as Korean and Japanese, demonstrate worse performances than those of isolating languages, which significantly affect the performances of the corresponding NER models. Moreover, in languages such as Korean and Japanese that do not use capitalization, detecting NEs without any morphological information such as morpheme boundaries and POS tags is difficult.
Table 1 shows an example of named entities affected by MA results in Korean.
In
Table 1, to increase readability, we have romanized Korean characters (so-called
Hangeul) and hyphenated Korean characters (so-called
eumjeols). The sentence “u-ri-eun-haeng-e ga-da” means “I go to Woori bank.” In an incorrect MA result, “u-ri” and “eun-haeng” are incorrectly analyzed as a pronoun (NP) and a general noun (NNG), respectively. This incorrect result yields an incorrect NER result, i.e., “not existing (N/A)” instead of “organization (ORG).” To reduce these error propagation problems, we present an integrated model, in which MA and NER are performed at once.
The remainder of this paper is organized as follows: in
Section 2, we summarize previous studies on MA and NER; we propose the integrated model in
Section 3; we explain the experimental setup and evaluate the proposed model in
Section 4; finally, we conclude our study in
Section 5.
2. Previous Studies
MA and NER are considered to be sequence-labeling problems, where POS and NE tags are annotated to a word sequence. For sequence labeling, most previous studies have used statistical-based machine learning (ML) methods, such as structural support vector machine (SVM) [
3] and conditional random fields (CRFs) [
4]. A method for unknown morpheme estimation using SVM and CRF has been proposed [
5]. However, ML models depend on the training corpus size and manually designed features. To resolve these problems, studies based on deep learning have been conducted. Many MA and NER studies have used recurrent neural network (RNN) [
6,
7]. NER was performed using bidirectional long short-term memory (Bi-LSTM) and CRFs [
1]. In another study, an attention mechanism and a gated recurrent unit (GRU) were used, which reduced the number of gates and time complexity of LSTM [
8]. An effective method for reflecting external knowledge (i.e., NE dictionary) into Bi-GRU-CRFs was proposed [
9]. Additionally, RNNs and CRFs have been used in MA studies [
10,
11]. To alleviate MA error propagation, an integrated model that simultaneously performs MA and NER has also been studied, which used two layers of Bi-GRU-CRFs [
12]. Güngör et al. [
13] proposed a model which alleviates morphological ambiguity by jointly learning NER and morphological disambiguation taggers using Bi-LSTM-CRFs for Turkish. As mentioned above, many ML models have used CRFs to obtain optimal paths among all possible label sequences. However, these models did not always yield good performances. Bi-LSTM-Softmax [
14] demonstrated better performance than Bi-LSTM-CRFs for POS tagging. To obtain optimal label paths better than those obtained with CRFs, a label attention network (LAN) was proposed, which captured the potential long-term label dependency by providing incrementally refined label distributions with hierarchical attention to each word. Therefore, we adopted this LAN in our integrated model.
3. Integrated Model for MA and NER
For
characters,
, in a sentence
, let
and
denote a morpheme tag sequence and an NE tag sequence in
, respectively.
Table 2 shows morpheme tags and NE tags that are defined according to the character-level BIO (beginner–inner–outer) tagging scheme.
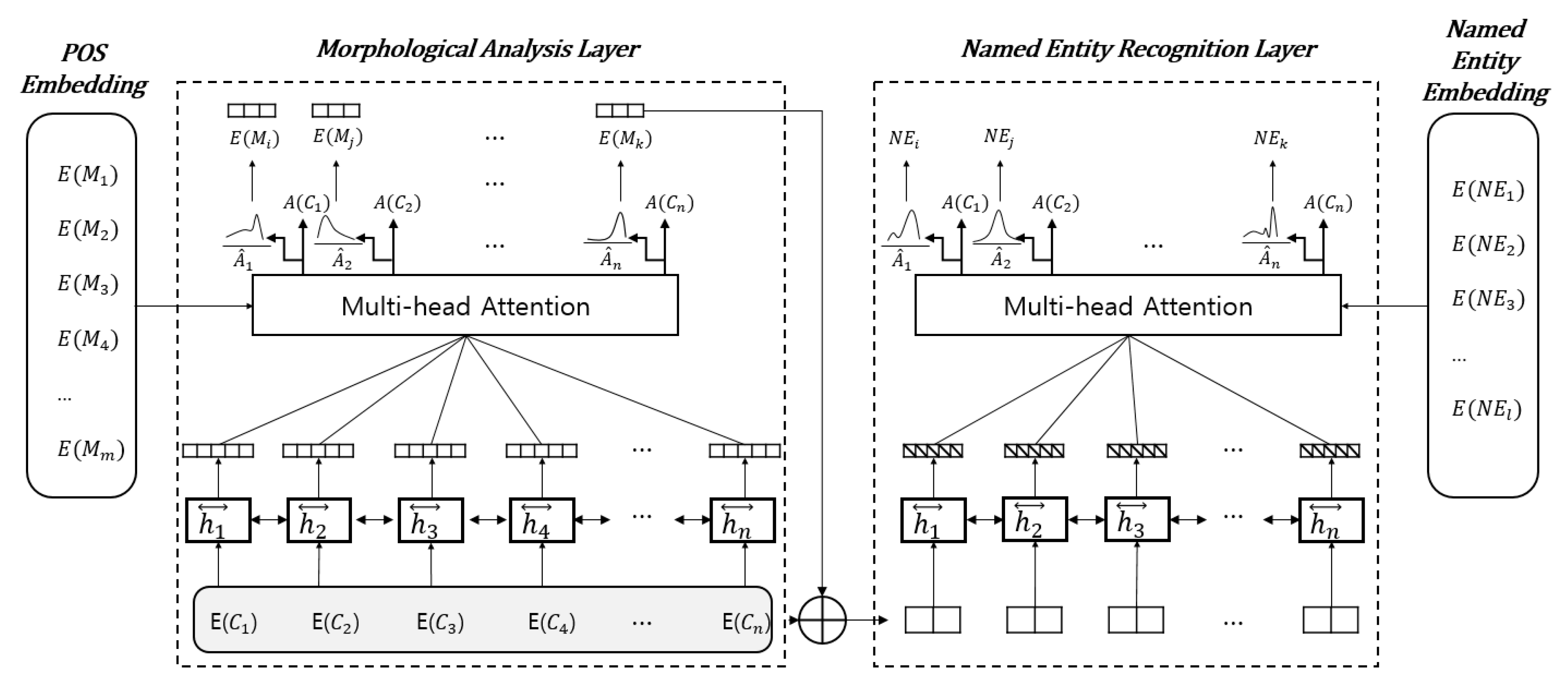
The integrated model, known as (MANE), can then be formally expressed using the following equation:
According to the chain rule, (1) can be rewritten as the following equation:
To obtain the sequence labels
and
that maximize (2), we adopted a bidirectional long short-term memory with a label attention network (Bi-LSTM-LAN), as shown in
Figure 1.
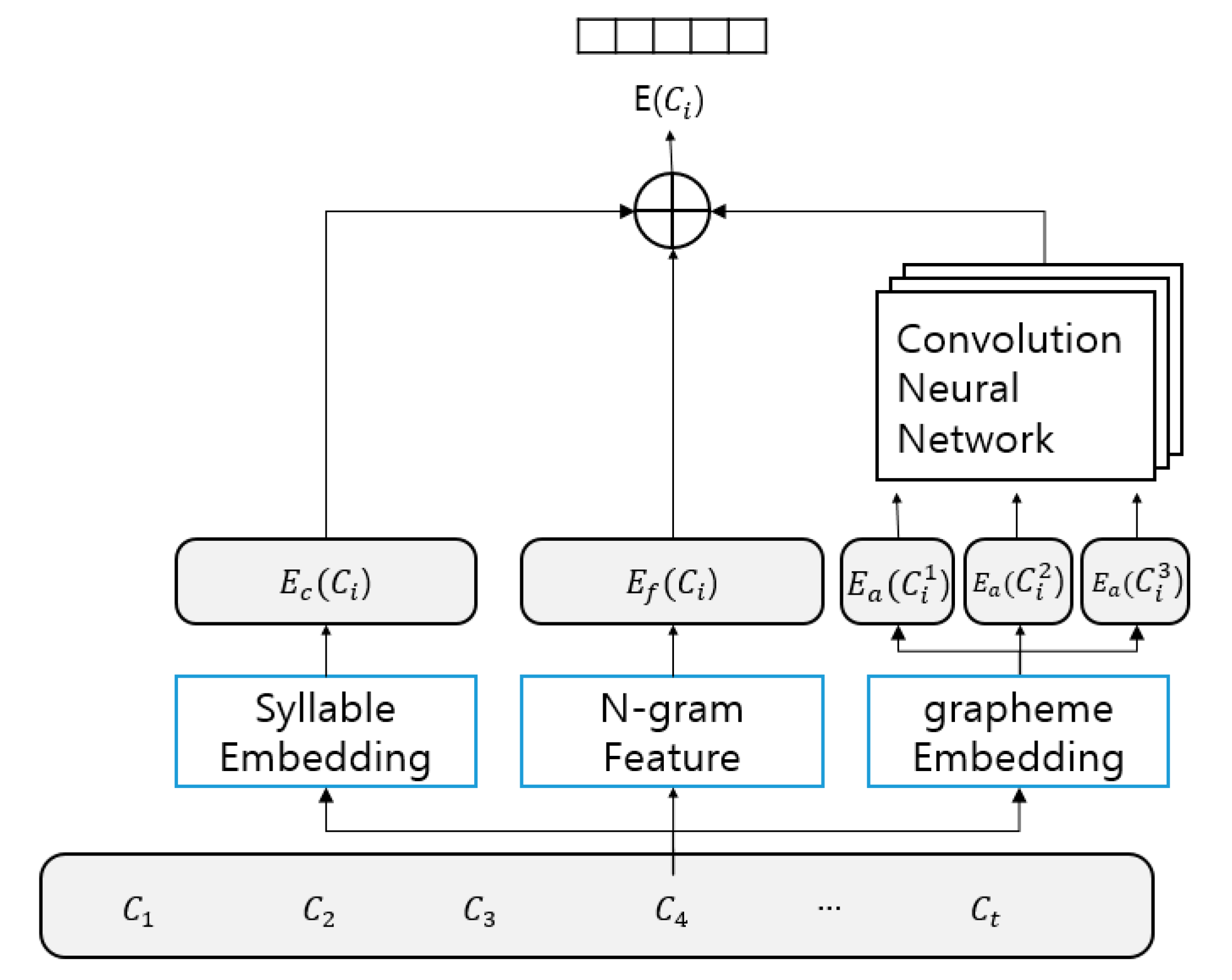
MANE comprises two layers of Bi-LSTM-LAN: an MA layer, shown on the left, and an NER layer, shown on the right. The input unit of the MA layer is a character, and each character is represented by a concatenation of three types of embeddings: character, alphabet, and feature embeddings, as shown in
Figure 2.
In
Figure 2,
is the
i-th character in a sentence, and
is a character embedding of
. Each character embedding is represented by a randomly initialized
n-dimensional vector and fine-tuned during training. To render MANE robust to typographical errors, we additionally represent each character through an alphabet embedding. A Korean character consists of a first consonant called
chosung, a vowel called
joongsung, and a final consonant called
jongsung that can be omitted. For example, in the word “hak-kyo (school)”, the first character “hak” comprises three alphabets; “h” called
chosung, “a” called
joongsung, and “k” called
jongsung. On the other hand, the second character “kyo” comprises two alphabets; “k” called
chosung and “yo” called
joongsung. In
Figure 2,
is an alphabet embedding of the
j-th alphabet in
that comprises the maximum of three alphabets in Korean, and each alphabet embedding is represented in the same manner as the character embeddings. The maximum three alphabet embeddings are passed into a convolutional neural network (CNN) with 100 filters (filter widths: 1, 2, and 3) [
15]. In NER, dictionary look-up features— which are used to check whether there is an input word in a preconstructed NE dictionary—significantly affect the performance. Based on Kim’s study [
9], in which effective dictionary look-up features have been proposed for Korean NER, we adopted the same dictionary look-up features in MANE. In
Figure 2,
is a feature embedding of
based on looking up a predefined NE dictionary. Subsequently, the character, alphabet, and feature embeddings are concatenated into the input embedding
, as shown in
Figure 1.
In the MA layer, the input embeddings
of the
n characters in a sentence are fed into a Bi-LSTM to yield a sequence of forward-hidden and backward-hidden states, respectively. Subsequently, these two states are concatenated to reflect bidirectional contextual information, as shown in the following equation:
where
is the concatenation of forward hidden state
and backward hidden state
of the
i-th character in a sentence. Next, the degrees of association between the contextualized input embeddings
,
, …
and the morpheme tag embeddings
are calculated based on a multihead attention mechanism [
14], as shown in the following equation:
where
,
, and
are the weighting parameters of the
j-th parameter among
k heads to be learned during training. The morpheme tag embeddings
represent the embedding vectors of the
m morpheme tags that are randomly initialized and fine-tuned during training. The attention score
is calculated using a scaled-dot product, where
is a normalization factor and denotes that the hidden size of Bi-LSTM is the same as the dimension of the morpheme tag embeddings. The attention score vector
represents the degrees of association between the contextualized input embedding
of the
i-th input character and each morpheme tag. In other words, it can be considered as a potential distribution of morpheme tags associated with an input character. In the prediction phase, the MA layer outputs the morpheme tags, as shown in the following equation:
where
denotes the
j-th one among
m attention scores in the trained attention vector
.
In the NER layer, the
i-th input embedding
is concatenated to the embedding of the morpheme tag with a maximum attention score,
. Subsequently, the concatenated vectors are fed into a Bi-LSTM in the same manner that is used for the MA layer, as shown in the following equation:
Next, the attention scores between the contextualized input embeddings ,, … and the NE tag embeddings are calculated using the same multihead attention mechanism as the MA layer. The attention score vector represents the degrees of association between the contextualized input embedding and each NE tag.
Generally, open datasets for training MA models are larger than those for training NER models. Thus, we use a two-phase training scheme in order to optimize the hyperparameters of MANE using different sizes of training data; large POS-tagged data and small NE-tagged data. We first train the MA layer based on the cross-entropy between the correct POS tags,
, and the outputs of the MA layer,
, as shown in the following equation:
In other words, the outputs of the NER layer do not take part in the first training phase. Subsequently, we train all layers based on the cross-entropy between the correct NE tags,
, and the outputs of the NER layer,
, as shown in the following equation:
The outputs of the MA layer do not take part in the second training phase. We expect the hyperparameters in the MA layer to be fine-tuned to the values associated with the correct NE tags in the second training phase.






{kind=link}
{kind=link}