A Semantic Focused Web Crawler Based on a Knowledge Representation Schema


Abstract
:1. Introduction
- A new SFWC based on a KRS,
- A generic KRS based on SW technologies to model any domain,
- A methodology to build a KRS from an input corpus,
- A similarity measure based on IDF and the statistical measures of arithmetic mean and standard deviation to determine the relevance of a web page for a given topic.
2. Related Work
3. Methodology
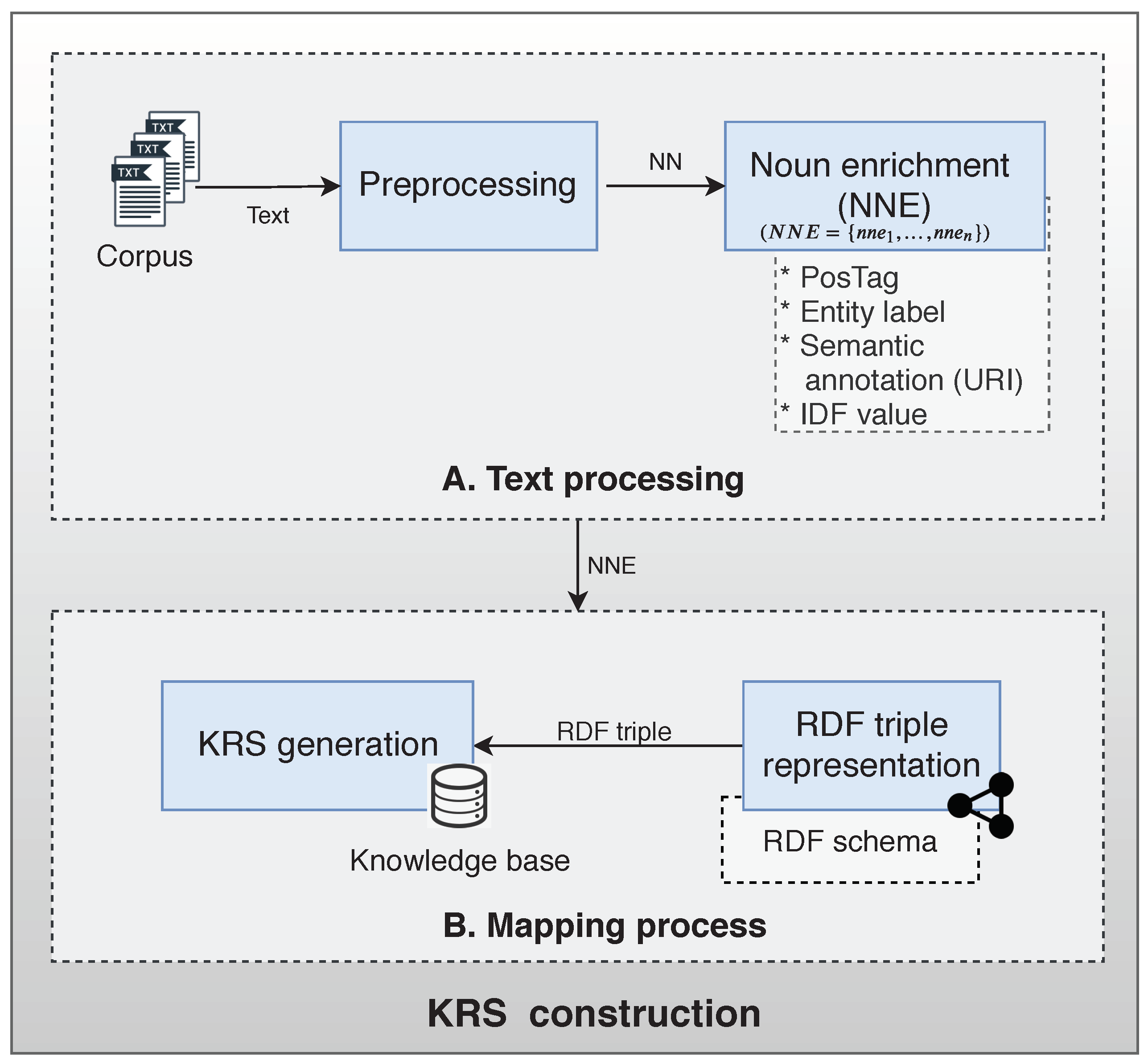
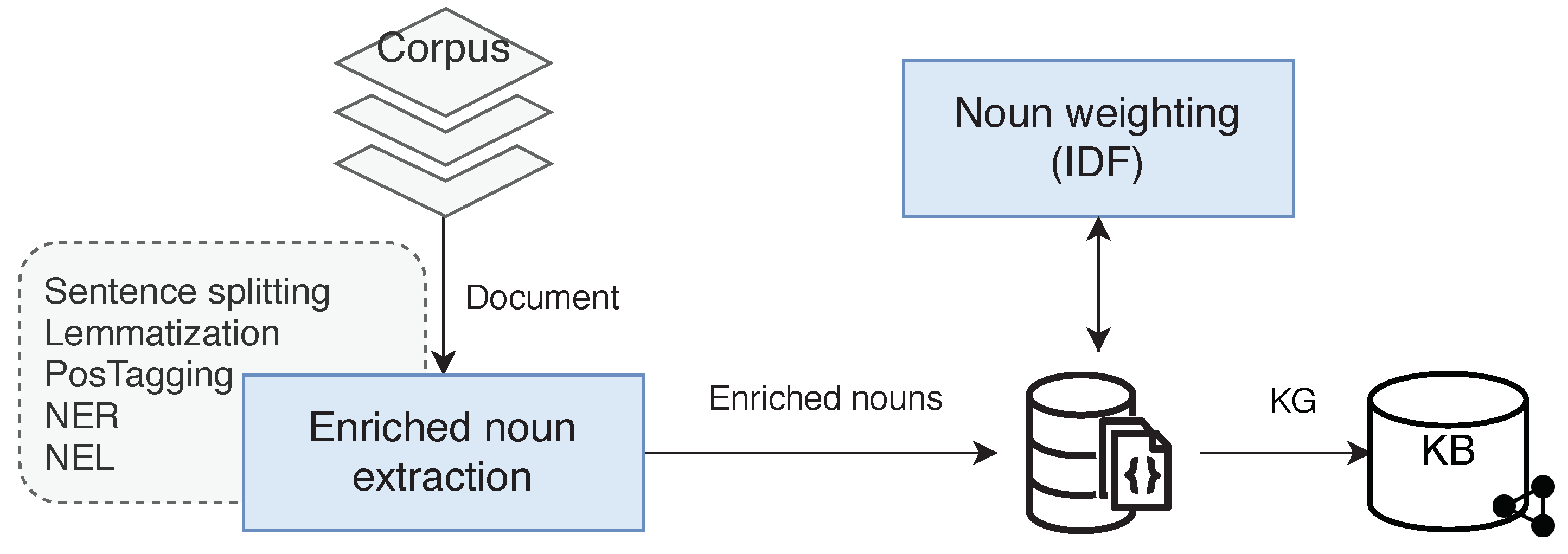
3.1. The KRS Construction
- A. Text processing
- -
- Preprocessing: The content of each document is processed for subsequent analysis. At this stage, stop words are removed and words are labeled with its corresponding PoS Tag and lemma.
- -
- Noun enrichment (NNE): The enrichment process assigns to each noun a PoS Tag, lemma, NE label, semantic annotation, and their IDF value. The PoS Tag and lemma were extracted in the previous step. The NE label and the semantic annotation are identified by Named Entity Recognition (NER) and Named Entity Linking (NEL) algorithms over the text. NER identifies NEs from an input text and NEL disambiguates those NEs to a KB to assign a unique identifier (URL). The IDF measure assigns a weight to each noun in accordance with their importance in the corpus.
- B. Mapping process
- -
- RDF triple representation: The enriched nouns information is used to populate the KRS. A document is represented by a set of enriched nouns which are described by a set of RDF triples.
- -
- KRS generation: The KRS is generated from each document and stored in the KB.
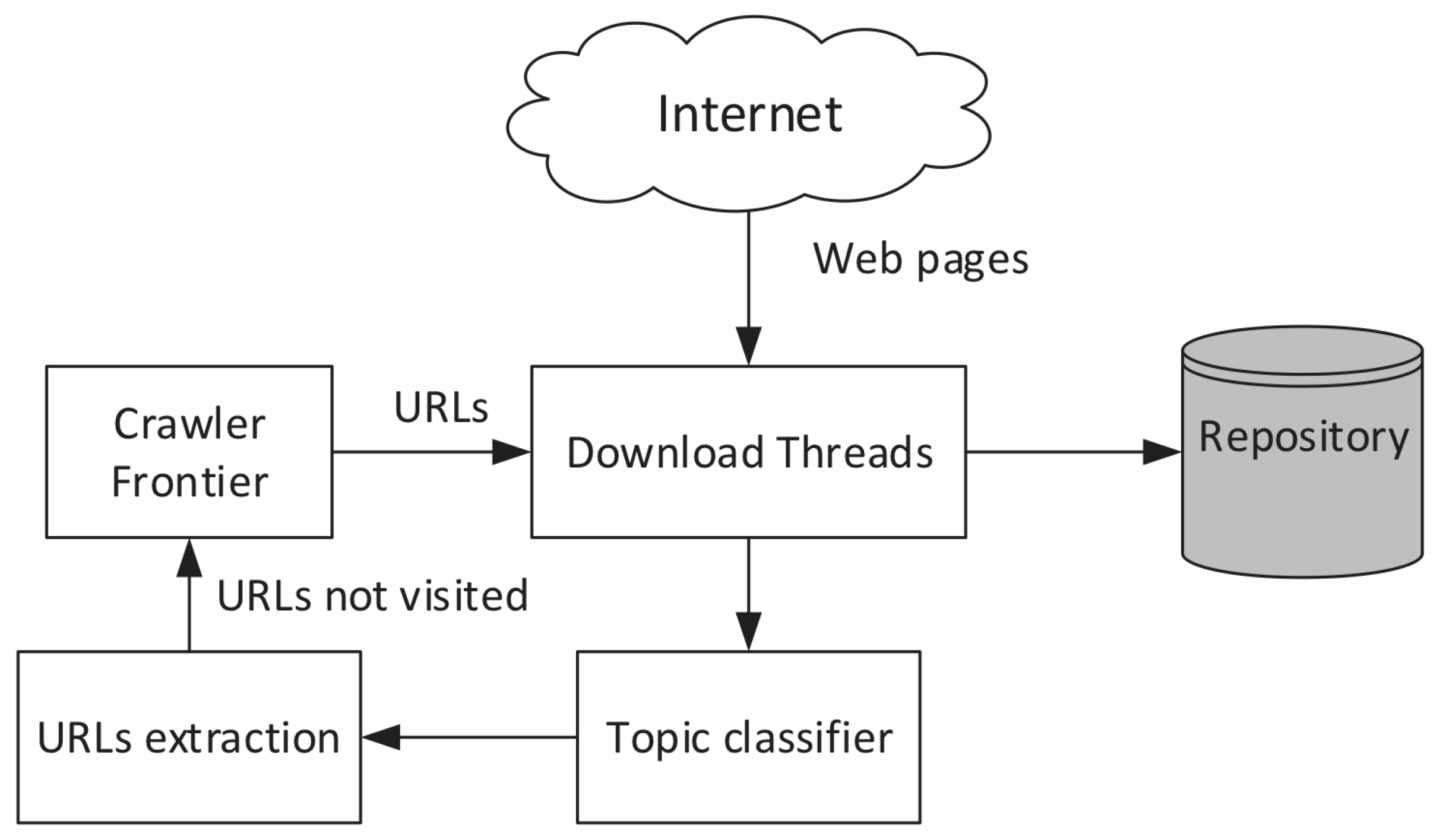
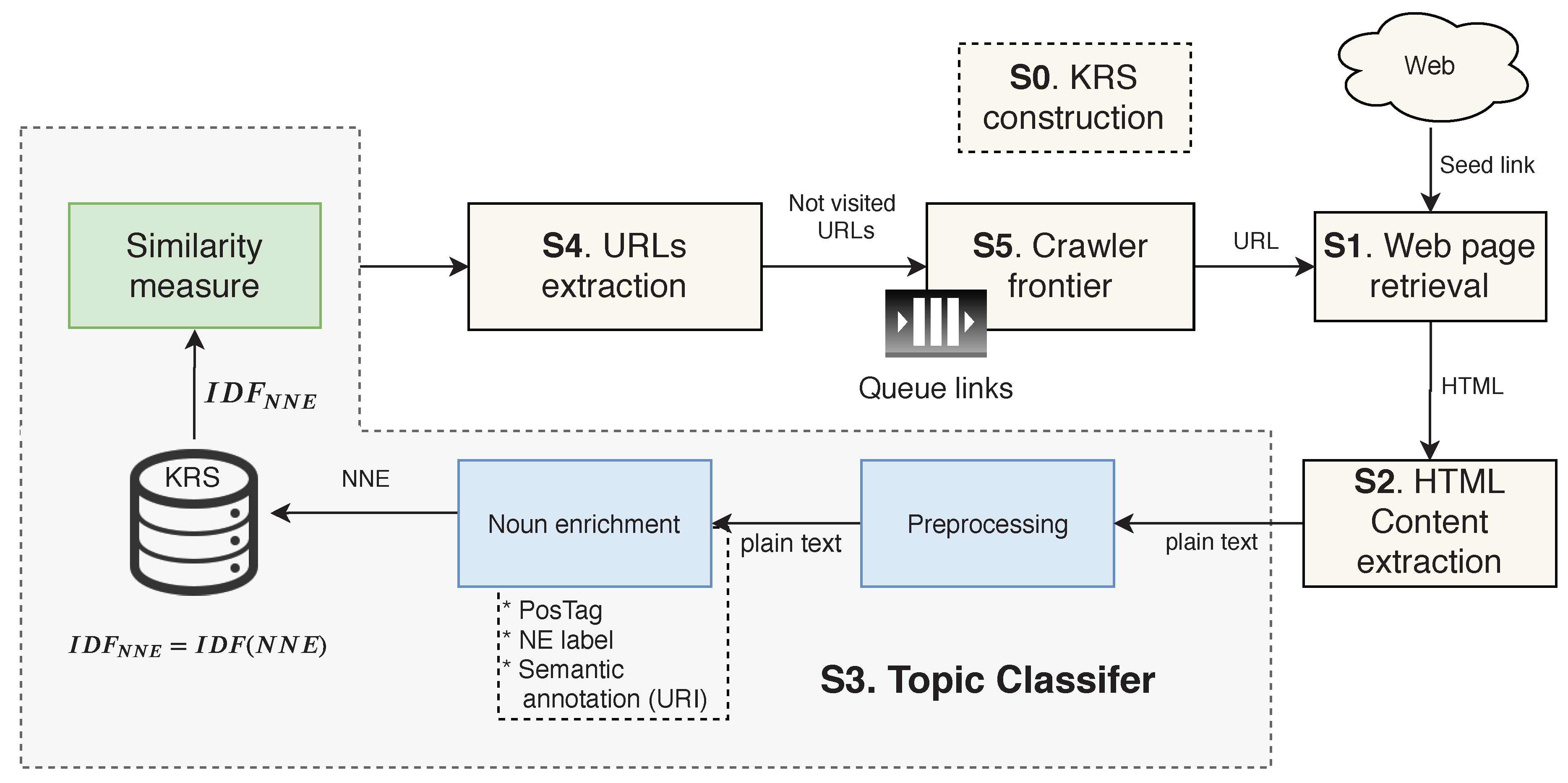
3.2. SFWC Design
- S0. KRS construction: It represents a previous step in the SFWC process.
- S1. Web page retrieval: It downloads the web page to be locally analyzed.
- S2. HTML content extraction: It extracts the web page content.
- S3. Topic classifier: It processes the web page content and analyzed it to determine if it is similar or not with the KRS.
- S4. URLs extraction: It extracts the URLs (enclosed in <a> tags) from the original web page content.
- S5.Crawler frontier: It collects and stores the extracted URLs in a queue of links. The crawler frontier sends the next URL to the web page retrieval step.
3.3. Similarity Measure
4. Implementation and Experiments
4.1. Implementation
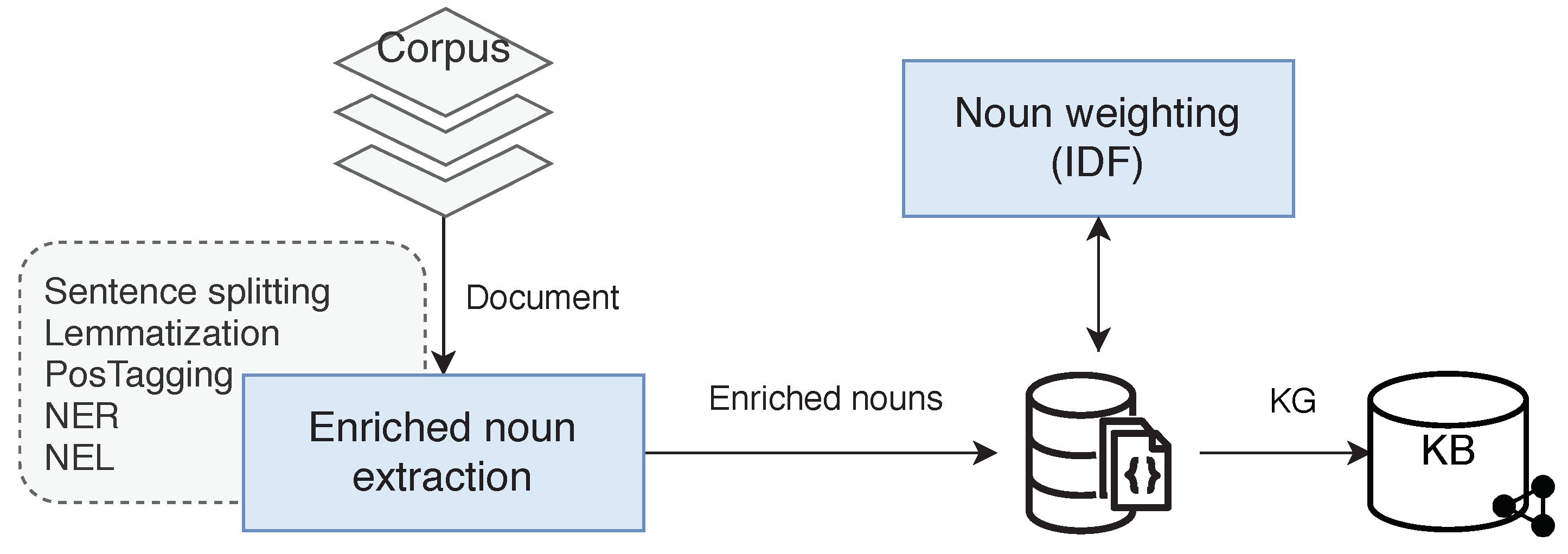
4.1.1. KRS Implementation
Text Processing
- Sentence splitting: The content of a document is divided into sentences, applying splitting rules and pattern recognition to identify the end of a sentence.
- Lemmatization: The root of each word is identified, e.g., the lemma of the verb producing is produce.
- PoS Tagging: A label is assigned to each token in a sentence, indicating their part of speech in the sentence, e.g., NN (noun), advj (adjective), PRP (personal pronoun), etc. PoS Tag are labels from the Penn treebank (a popular set of part of speech tags used in the literature).
- NER: NEs identification. The result is a single-token tagged with the corresponding NE (person, location, organization, etc.).
- NEL: Entities are defined in an SW KB. From a set of candidates’ words, each word is a query against the target KB to retrieve a list of possible matching entities. After a ranking process, the most relevant entity is selected and their URL is returned and associated with the corresponding word.
Mapping Process
4.1.2. The SFWC Implementation
Web Page Retrieval
HTML Content Extraction
Topic Classifier
URL Extraction
Crawler Frontier
4.2. Results and Evaluation
4.2.1. Qualitative Results
Evaluation
Similarity Measure
- The arithmetic mean () and standard deviation () for the KB is computed over all enriched nouns whose URL value is not empty.
- For every new web page content, enriched nouns are extracted.
- The IDF value for the new web page is calculated over all enriched nouns whose URL value is not empty.
- If the arithmetic mean of the web page content is between , the web page is accepted. Table 8 defines the threshold range for each topic.
| Listing 1: SPARQL query to retrieve the number of documents containing the word “algol” from the KRS. |
@PREFIX sfwc: <http://sfwcrawler.com/core#>
@PREFIX nif: <http://persistence.uni-leipzig.org/nlp2rdf/ontologies/nif-core#>
SELECT COUNT (DISTINCT ?doc) as ?total WHERE {
?s a sfwc:Entity .
?s nif:anchorOf “algol” .
?s sfwc:inDocument ?doc .
;}
|
| Listing 2: The SPARQL query to the KRS to retrieve the number of documents. |
@PREFIX sfwc: <http://sfwcrawler.com/core#>
SELECT COUNT (DISTINCT ?doc) as ?total WHERE {
?doc a sfwc:Document .
;}
|
4.2.2. Qualitative Results
Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Internet Live Stats—Internet Usage and Social Media Statistics. 2016. Available online: https://www.internetlivestats.com/ (accessed on 19 April 2020).
- Lu, H.; Zhan, D.; Zhou, L.; He, D. An Improved Focused Crawler: Using Web Page Classification and Link Priority Evaluation. Math. Prob. Eng. 2016, 2016, 6406901. [Google Scholar] [CrossRef]
- Udapure, T.V.; Kale, R.D.; Dharmik, R.C. Study of Web Crawler and its Different Types. IOSR J. Comput. Eng. 2014, 16, 1–5. [Google Scholar] [CrossRef]
- Kumar, M.; Vig, R. Learnable Focused Meta Crawling Through Web. Procedia Technol. 2012, 6, 606–611. [Google Scholar] [CrossRef] [Green Version]
- Gaur, R.K.; Sharma, D. Focused crawling with ontology using semi-automatic tagging for relevancy. In Proceedings of the 2014 Seventh International Conference on Contemporary Computing (IC3), Noida, India, 7–9 August 2014; pp. 501–506. [Google Scholar]
- Du, Y.; Liu, W.; Lv, X.; Peng, G. An Improved Focused Crawler Based on Semantic Similarity Vector Space Model. Appl. Soft Comput. 2015, 36, 392–407. [Google Scholar] [CrossRef]
- Kumar, J. Apache Solr Search Patterns; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Salah, T.; Tiun, S. Focused crawling of online business Web pages using latent semantic indexing approach. ARPN J. Eng. Appl. Sci. 2016, 11, 9229–9234. [Google Scholar]
- Kumar, M.; Bhatia, R.K.; Rattan, D. A survey of Web crawlers for information retrieval. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7. [Google Scholar] [CrossRef]
- Priyatam, P.N.; Vaddepally, S.R.; Varma, V. Domain specific search in indian languages. In Proceedings of the first ACM Workshop on Information and Knowledge Management for Developing Regions, Maui, HI, USA, 2 November 2012; pp. 23–29. [Google Scholar]
- Altingovde, I.S.; Ozcan, R.; Cetintas, S.; Yilmaz, H.; Ulusoy, O. An Automatic Approach to Construct Domain-Specific Web Portals. In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management, Lisbon, Portugal, 6–7 November 2007; Association for Computing Machinery: New York, NY, USA, 2007; pp. 849–852. [Google Scholar] [CrossRef]
- Bedi, P.; Thukral, A.; Banati, H.; Behl, A.; Mendiratta, V. A Multi-Threaded Semantic Focused Crawler. J. Comput. Sci. Technol. 2012, 27, 1233–1242. [Google Scholar] [CrossRef]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–221. [Google Scholar] [CrossRef]
- Batzios, A.; Dimou, C.; Symeonidis, A.L.; Mitkas, P.A. BioCrawler: An Intelligent Crawler for the Semantic Web. Expert Syst. Appl. 2008, 35, 524–530. [Google Scholar] [CrossRef]
- Yu, Y.B.; Huang, S.L.; Tashi, N.; Zhang, H.; Lei, F.; Wu, L.Y. A Survey about Algorithms Utilized by Focused Web Crawler. J. Electron. Sci. Technol. 2018, 16, 129. [Google Scholar] [CrossRef]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank citation ranking: Bringing order to the Web. In Proceedings of the 7th International World Wide Web Conference, Brisbane, Australia, 14–18 April 1998; pp. 161–172. [Google Scholar]
- Wu, J.; Aberer, K. Using SiteRank for Decentralized Computation of Web Document Ranking. In Adaptive Hypermedia and Adaptive Web-Based Systems; De Bra, P.M.E., Nejdl, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 265–274. [Google Scholar]
- Cai, D.; Yu, S.; Wen, J.R.; Ma, W.Y. VIPS: A Vision-based Page Segmentation Algorithm; Technical Report MSR-TR-2003-79; Microsoft: Redmond, WA, USA, 2003. [Google Scholar]
- Kohlschütter, C.; Nejdl, W. A Densitometric Approach to Web Page Segmentation. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 1173–1182. [Google Scholar] [CrossRef]
- Khalilian, M.; Abolhassani, H.; Alijamaat, A.; Boroujeni, F.Z. PCI: Plants Classification Identification Classification of Web Pages for Constructing Plants Web Directory. In Proceedings of the 2009 Sixth International Conference on Information Technology: New Generations, Las Vegas, NV, USA, 27–29 April 2009; pp. 1373–1377. [Google Scholar] [CrossRef]
- Patel, R.; Bhatt, P. A Survey on Semantic Focused Web Crawler for Information Discovery Using Data Mining Technique. Int. J. Innov. Res. Sci. Technol. 2014, 1, 168–170. [Google Scholar]
- Hassan, T.; Cruz, C.; Bertaux, A. Ontology-based Approach for Unsupervised and Adaptive Focused Crawling. In Proceedings of the International Workshop on Semantic Big Data, Chicago, IL, USA, 19 May 2017; ACM: New York, NY, USA, 2017; pp. 2:1–2:6. [Google Scholar]
- Krótkiewicz, M.; Wojtkiewicz, K.; Jodłowiec, M. Towards Semantic Knowledge Base Definition. In Biomedical Engineering and Neuroscience; Hunek, W.P., Paszkiel, S., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 218–239. [Google Scholar]
- Khalilian, M.; Zamani Boroujeni, F. Improving Performance in Constructing specific Web Directory using Focused Crawler: An Experiment on Botany Domain. In Advanced Techniques in Computing Sciences and Software Engineering; Springer: Dordrecht, The Netherlands, 2010; pp. 461–466. [Google Scholar] [CrossRef]
- Boukadi, K.; Rekik, M.; Rekik, M.; Ben-Abdallah, H. FC4CD: A new SOA-based Focused Crawler for Cloud service Discovery. Computing 2018, 100, 1081–1107. [Google Scholar] [CrossRef]
- Ben Djemaa, R.; Nabli, H.; Amous Ben Amor, I. Enhanced semantic similarity measure based on two-level retrieval model. Concurr. Comput. Pract. Exp. 2019, 31, e5135. [Google Scholar] [CrossRef]
- Du, Y.; Hai, Y.; Xie, C.; Wang, X. An approach for selecting seed URLs of focused crawler based on user-interest ontology. Appl. Soft Comput. 2014, 14, 663–676. [Google Scholar] [CrossRef]
- Hosseinkhani, J.; Taherdoost, H.; Keikhaee, S. ANTON Framework Based on Semantic Focused Crawler to Support Web Crime Mining Using SVM. Ann. Data Sci. 2019, 1–14. [Google Scholar] [CrossRef]
- Yang, S.Y. A Focused Crawler with Ontology-Supported Website Models for Information Agents. In International Conference on Grid and Pervasive Computing; Springer: Berlin/Heidelberg, Germany, 2010; pp. 522–532. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Chen, X.; Zou, Y.; Wang, H.; Dai, Z. A Focused Crawler Based on Naive Bayes Classifier. In Proceedings of the Third International Symposium on Intelligent Information Technology and Security Informatics, IITSI 2010, Jinggangshan, China, 2–4 April 2010; pp. 517–521. [Google Scholar] [CrossRef]
- Pesaranghader, A.; Pesaranghader, A.; Mustapha, N.; Sharef, N.M. Improving multi-term topics focused crawling by introducing term Frequency-Information Content (TF-IC) measure. In Proceedings of the 2013 International Conference on Research and Innovation in Information Systems (ICRIIS), Kuala Lumpur, Malaysia, 27–28 November 2013; pp. 102–106. [Google Scholar] [CrossRef]
- Peng, T.; Zhang, C.; Zuo, W. Tunneling enhanced by web page content block partition for focused crawling. Concurr. Comput. Pract. Exp. 2008, 20, 61–74. [Google Scholar] [CrossRef]
- Pappas, N.; Katsimpras, G.; Stamatatos, E. An Agent-Based Focused Crawling Framework for Topic- and Genre-Related Web Document Discovery. In Proceedings of the 2012 IEEE 24th International Conference on Tools with Artificial Intelligence, Athens, Greece, 7–9 November 2012; Volume 1, pp. 508–515. [Google Scholar] [CrossRef] [Green Version]
- Kumar, M.; Vig, R. Term-Frequency Inverse-Document Frequency Definition Semantic (TIDS) Based Focused Web Crawler. In Global Trends in Information Systems and Software Applications; Krishna, P.V., Babu, M.R., Ariwa, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 31–36. [Google Scholar]
- Hao, H.; Mu, C.; Yin, X.; Li, S.; Wang, Z. An improved topic relevance algorithm for focused crawling. In Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics, Anchorage, AK, USA, 9–12 October 2011; pp. 850–855. [Google Scholar] [CrossRef]
- Hellmann, S.; Lehmann, J.; Auer, S.; Brümmer, M. Integrating NLP Using Linked Data. In The Semantic Web—ISWC 2013; Alani, H., Kagal, L., Fokoue, A., Groth, P., Biemann, C., Parreira, J.X., Aroyo, L., Noy, N., Welty, C., Janowicz, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 98–113. [Google Scholar]
- Lerner, J.; Lomi, A. The Third Man: Hierarchy formation in Wikipedia. Appl. Netw. Sci. 2017, 2, 24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schrage, F.; Heist, N.; Paulheim, H. Extracting Literal Assertions for DBpedia from Wikipedia Abstracts. In Semantic Systems. The Power of AI and Knowledge Graphs; Acosta, M., Cudré-Mauroux, P., Maleshkova, M., Pellegrini, T., Sack, H., Sure-Vetter, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 288–294. [Google Scholar]
- Wu, I.C.; Lin, Y.S.; Liu, C.H. An Exploratory Study of Navigating Wikipedia Semantically: Model and Application. In Online Communities and Social Computing; Ozok, A.A., Zaphiris, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 140–149. [Google Scholar]
- Yano, T.; Kang, M. Taking advantage of Wikipedia in Natural Language Processing; Carnegie Mellon University: Pittsburgh, PA, USA, 2016. [Google Scholar]
- Altingovde, I.S.; Ulusoy, O. Exploiting interclass rules for focused crawling. IEEE Intell. Syst. 2004, 19, 66–73. [Google Scholar] [CrossRef]
- Samarawickrama, S.; Jayaratne, L. Automatic text classification and focused crawling. In Proceedings of the 2011 Sixth International Conference on Digital Information Management, Melbourn, Australia, 26–28 September 2011; pp. 143–148. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Description | Measure |
|---|---|---|
| Cloud service recommendation system [25,26] | A concept ontology-based recommendation system for retrieving cloud services. | Semantic relevance |
| Website models [29] | An ontology-supported website model to improve search engine results. | Cosine similarity |
| Web directory construction [20] | Based on a handmade ontology from WordNet to automatically construct a web directory. | Cosine similarity |
| User-based recommendation system [27] | A knowledge representation model built from a user interest database to select seeds URLs. | Concept similarity |
| Concept labeling [5,22] | An ontology-based classification model to label new concepts during the crawling process, integrating new concepts and relations to the ontology. | Cosine similarity, semantic relevance |
| Cybercrime [28] | Enhanced crime ontology using ant-miner focused crawler. | Significance |
| Category | URLs | Depth | Restriction |
|---|---|---|---|
| Computer science | 1151 | 1 | Pages describing persons are not considered |
| Diabetes | 202 | 1 | |
| Politics | 1717 | 1 | |
| Total | 3070 |
| Category | Number of Pages | Total Enriched Nouns (Average per Document) | Total Enriched Nouns Associated with a KB (Average per Document) |
|---|---|---|---|
| Computer science | 1151 | 289,950 (251.91) | 24,993 (21.71) |
| Diabetes | 202 | 83,723 (414.47) | 14,470 (71.63) |
| Politics | 1717 | 793,137 (461.66) | 80,024 (46.58) |
| TOTAL | 3070 | 1,166,810 (380.07) | 119,487 (38.92) |
| Topic | Seed URLs (Google) | Seed URLs Crawled | Seed URLs Not Crawled | Seed URLs Not Processed |
|---|---|---|---|---|
| Computer science | 50 | 11 (22%) | 32 (64%) | 7 (14%) |
| Diabetes | 50 | 9 (18%) | 30 (60%) | 11 (22%) |
| Politics | 50 | 22 (44%) | 18 (36%) | 10 (20%) |
| Total | 150 | 42 (28%) | 80 (53.33%) | 28 (18.67%) |
| Topic | Seed URLs (Wikipedia) | Seed URLs Crawled | Seed URLs Not Crawled | Seed URLs Not Processed |
|---|---|---|---|---|
| Computer science | 50 | 26 (52%) | 24 (48%) | 0 (0%) |
| Diabetes | 50 | 31 (62%) | 19 (38%) | 0 (0%) |
| Politics | 50 | 39 (78%) | 10 (22%) | 1 (2%) |
| Total | 150 | 96 (64%) | 53 (36%) | 1 (0.6%) |
| Topic | Seed URLs | Domain Names Crawled | Web Pages Analyzed | Accepted | Rejected | Error |
|---|---|---|---|---|---|---|
| Computer science | 11 | 104 | 874 | 86 (9.84%) | 765 (87.52%) | 23 (2.63%) |
| Diabetes | 9 | 135 | 957 | 265 (27.69%) | 605 (63.22%) | 87 (9.09%) |
| Politics | 22 | 182 | 1893 | 754 (39.83%) | 1113 (58.79%) | 26 (1.37%) |
| Total | 42 | 421 | 3724 | 1105 (29.67%) | 2483 (66.67%) | 136 (3.65%) |
| Topic | Seed URLs | Domain Names Crawled | Web Pages Analyzed | Accepted | Rejected | Error |
|---|---|---|---|---|---|---|
| Computer science | 26 | 51 | 2624 | 1101 (41.96%) | 1488 (56.71%) | 35 (1.33%) |
| Diebetes | 31 | 55 | 3119 | 1413 (45.30%) | 1670 (53.54%) | 36 (1.15%) |
| Politics | 39 | 8 | 3910 | 2781 (71.12%) | 1097 (28.06%) | 32 (0.82%) |
| Total | 96 | 114 | 9653 | 5295 (54.85%) | 4255 (44.08%) | 103 (1.06%) |
| Topic | Arithmetic Mean () | Standard Deviation () | Threshold Range () |
|---|---|---|---|
| Computer science | 5.01 | 1.56 | [3.45,6.57] |
| Diabetes | 3.19 | 1.54 | [1.65,4.73] |
| Politics | 4.84 | 1.54 | [3.30,6.38] |
| Topic | Total Examples | Sample Size (N) | Sample Size for Accepted () | Sample Size for Rejected () | ||||
|---|---|---|---|---|---|---|---|---|
| G | W | G | W | G | W | G | W | |
| Computer science | 879 | 2589 | 303 | 335 | 93 | 142 | 210 | 192 |
| Diabetes | 957 | 3083 | 284 | 342 | 29 | 157 | 255 | 185 |
| Politics | 1893 | 3878 | 374 | 350 | 151 | 251 | 223 | 99 |
| R1 | R2 | R3 | R4 | Average | |
|---|---|---|---|---|---|
| Computer science | 70/93 (75.27%) | 74/93 (79.57%) | 65/93 (69.89%) | 65/93 (69.89%) | 68.5/93 (73.66%) |
| Diabetes | 26/29 (89.66%) | 23/29 (79.31%) | 26/29 (89.66%) | 28/29 (96.55%) | 25.75/29 (88.79%) |
| Politics | 110/151 (72.85%) | 106/151 (70.20%) | 93/151 (61.59%) | 114/151 (75.50%) | 105.75/151 (70.03%) |
| R1 | R2 | R3 | R4 | Average | |
|---|---|---|---|---|---|
| Computer science | 119/142 (83.80%) | 110/142 (77.46%) | 111/142 (78.17%) | 106/142 (74.65%) | 111.5/142 (78.52%) |
| Diabetes | 127/157 (77.71%) | 132/157 (84.08%) | 124/157 (78.98%) | 134/157 (85.35%) | 128/157 (81.53%) |
| Politics | 217/251 (86.45%) | 240/251 (95.62%) | 225/251 (89.64%) | 206/251 (82.07%) | 222/251 (88.45%) |
| Category | Levels | ||||
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | |
| Computer science | 44 | 1151 | 6487 | 26,730 | 79,845 |
| Diabetes | 145 | 202 | 336 | 349 | 357 |
| Politics | 63 | 1717 | 17,346 | 86,260 | 291,615 |
| Corpus | Wikipedia | |
|---|---|---|
| ( value) | ||
| Computer science | 0.68 | 0.53 |
| Diabetes | 0.65 | 0.62 |
| Politics | 0.63 | 0.57 |
| Interpretation | |
|---|---|
| <0 | Poor agreement |
| 0.01–0.20 | Slight agreement |
| 0.21–0.40 | Fair agreement |
| 0.41–0.60 | Moderate agreement |
| 0.61–0.80 | Substantial agreement |
| 0.81–1.00 | Almost perfect agreement |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernandez, J.; Marin-Castro, H.M.; Morales-Sandoval, M. A Semantic Focused Web Crawler Based on a Knowledge Representation Schema. Appl. Sci. 2020, 10, 3837. https://doi.org/10.3390/app10113837
Hernandez J, Marin-Castro HM, Morales-Sandoval M. A Semantic Focused Web Crawler Based on a Knowledge Representation Schema. Applied Sciences. 2020; 10(11):3837. https://doi.org/10.3390/app10113837
Chicago/Turabian StyleHernandez, Julio, Heidy M. Marin-Castro, and Miguel Morales-Sandoval. 2020. "A Semantic Focused Web Crawler Based on a Knowledge Representation Schema" Applied Sciences 10, no. 11: 3837. https://doi.org/10.3390/app10113837
APA StyleHernandez, J., Marin-Castro, H. M., & Morales-Sandoval, M. (2020). A Semantic Focused Web Crawler Based on a Knowledge Representation Schema. Applied Sciences, 10(11), 3837. https://doi.org/10.3390/app10113837