Abstract
As one of the most important and obvious global features for fingerprints, the singular point plays an essential role in fingerprint registration and fingerprint classification. To date, the singular point detection methods in the literature can be generally divided into two categories: methods based on traditional digital image processing and those on deep learning. Generally speaking, the former requires a high-precision fingerprint orientation field for singular point detection, while the latter just needs the original fingerprint image without preprocessing. Unfortunately, detection rates of these existing methods, either of the two categories above, are still unsatisfactory, especially for the low-quality fingerprint. Therefore, regarding singular point detection as a semantic segmentation of the small singular point area completely and directly, we propose a new customized convolutional neural network called SinNet for segmenting the accurate singular point area, followed by a simple and fast post-processing to locate the singular points quickly. The performance evaluation conducted on the publicly Singular Points Detection Competition 2010 (SPD2010) dataset confirms that the proposed method works best from the perspective of overall indexes. Especially, compared with the state-of-art algorithms, our proposal achieves an increase of 10% in the percentage of correctly detected fingerprints and more than 16% in the core detection rate.
1. Introduction
Fingerprint recognition was originally used for criminal investigation and has gradually been extended to other applications such as border control, computer logon, mobile payment, and so on [1]. The singular point is one of the most important and obvious global features for fingerprints, and it plays an essential role in fingerprint registration, fingerprint classification, fingerprint indexing and fingerprint template protection. Image processing and analysis of the fingerprint are typically based on the location and pattern of the singular points in the fingerprint images. The singular point area is defined as a region where the ridge curvature is higher than normal or the direction of the ridge changes rapidly [2]. Generally speaking, the singular points (both cores and deltas) not only represent the characteristics of local ridge patterns but also determine the topological structure (i.e., fingerprint type) and influence the distribution of orientation field largely [3]. Better singular point detection is one of the most important challenges in the field of fingerprint recognition, especially for the low-quality fingerprint image.
Singular points detection has been studied for many years and lots of excellent methods have been proposed based on traditional digital image processing technology, such as the Poincare index [3,4,5,6,7], the filter and model techniques [8,9,10,11,12] and the hybrid schemes [13,14]. These methods have achieved, to some extent, satisfactory detection results for high-quality fingerprint. However, most of them require a high-precision fingerprint orientation field for detection, meaning that the detection result is very dependent on the performance of fingerprint preprocessing algorithm, which is indirect and time-consuming. In recent years, singular point detection based on deep learning has come up [15,16,17], and its advantage over the traditional methods lies in that the original fingerprint images are directly adopted instead of the orientation fields. It is worth mentioning that Geetika et al. [17] firstly adopt the idea of semantic segmentation for extracting fingerprint singular points. However, their semantic segmentation network (i.e., macro-localization network) just segments the big coarse image block containing singular points. For more precise positioning, all the segmented image blocks need to be put into their non-semantic segmentation network (i.e., micro-regression network) for training again. In summary, most methods based on deep learning need too much training data or complicated training process, which are inefficient for practical applications. More importantly, in terms of detection rates, neither methods based on traditional digital image processing technology [3,4,5,6,7,8,9,10,11,12,13,14] nor those on deep learning [15,16,17], are satisfactory, especially for the low-quality fingerprint.
Motivated by these concerns, we try to design a higher performance detection method which has simple and effective network architecture and requires a smaller amount of training data. Semantic segmentation, i.e., making a prediction at every pixel, is the natural next step for whole-image classification, object detection, part and key point prediction as well as local correspondence [18]. As long as the detected singular points are located in the accurate singular point areas, the detection result is determined to be correct. Therefore, in this paper, we treat singular points detection as a problem of semantic segmentation of small singular point area completely and directly and thus propose a new customized network architecture named SinNet, which contains a symmetrical encoder-decoder network with inception modules [19], skip connections [20] and batch normalization. The overall work uses SinNet, a pixel-to-pixel system, to extract the accurate small singular point area directly, and followingly, uses a simple post-processing without training to locate the singular point quickly.
The contributions of this study are mainly two-fold:
- For the first time, we treat singular point detection as a problem of semantic segmentation of small singular point area completely and directly. Different from other methods based on deep learning, our method requires much less fingerprint data and easier training process.
- A new customized network architecture called SinNet is designed for extracting the accurate singular point area. The training data labeling, the mixed loss function, the encoder-decoder architecture, the inception module, skip connections and the batch normalization are used together to ensure the efficient performance of the network. Our method achieves the best performance in terms of comprehensive evaluation on SPD2010 [2], especially in the correctly detection rate (CD) and the detection rate of cores.
2. Related Work
Most researches on singular point detection are based on traditional digital image processing algorithms. Now, with its wide application in the field of computer vision, deep learning has provided new solutions to the singular point detection problem. From this point of view, the existing singular points detection methods can be mainly divided into two categories: (1) the methods with traditional digital image processing [3,4,5,6,7,8,9,10,11,12,13,14], and (2) the ones with deep learning [15,16,17]. In the following, we shall give a thorough overview on detection methods.
According to the principle, singular point detection methods on the traditional digital image processing can be further divided into three sub-categories, including methods on the Poincare index [3,4,5,6,7], ones on filter and model techniques [8,9,10,11,12] and ones on the hybrid schemes [13,14]. The Poincare index of a point is defined as the cumulative orientation differences counterclockwise along a simple closed [3], and it can be used to judge whether there are singular points in an orientation field block or not. The Poincare index method is firstly proposed by Kawagoe et al. [4] and now is considered as the most classical way to detect singular points. Unfortunately, it does not work well for fingerprint local areas with unclear flow direction, which is its main drawback. To further improve detection performance, on the basis of the Poincare index method, some researchers add some global and local features to their methods [3,5,6,7]. The most popular Poincare index method with the feature is presented by Jie et al. [3], who proposed the orientation values along a circle (DORIC) feature for the removal of spurious singular points and then used the classic Poincare index method [4] to detect the singular points initially. As a novel constraint, a core-delta relation is utilized to select singular points finally. Although the Poincare index methods have achieved, to some extent, satisfactory detection results for high-quality fingerprint, there are still limitations. For example, most of these methods require the high-precision fingerprint orientation field before detection, which means that the detection result is very dependent on the quality of the original image and the performance fingerprint preprocessing algorithm.
The filter and model techniques provide another way for detecting fingerprint singular points. Methods based on filter and model techniques detect cores and deltas generally by means of using the designed corresponding filters or analyzing the corresponding models, such as complex filter methods [8,9], multi-scale Gaussian filter method [10] and multi-scale orientation entropy method [11]. The most popular one is presented by Fan et al. [12], and it combined zero-pole model and Hough transform (HT) to detect the core and the delta. The orientation field is estimated by Zero-pole Model. HT is used for coarse detection at the global level and the Poincare index is used for fine detection. Besides Fan et al.’s method, there are a certain number of similar methods, most of which can obtain better performance in some experimental evaluations. However, it is worth noting that most of them need to visit every pixel or block to extract enough information to detect singular points [14], which is very time-consuming. At the same time, they cannot perform very well on low-quality fingerprint either.
The emergence of hybrid schemes makes it possible to achieve higher detection rate and faster detection speed. Jin et al. [13] develop a new hybrid index of singular points based on the definition of angle matching index (AMI) in vector fields. AMI is a specific polynomial model of orientation field, which could be also used in other areas, especially the vector field analysis. The AMI information of candidate singular points is collected and the conventional convergence index filter framework is modified. Among the existing methods, this method has achieved the best result on the database SPD2010. En et al. [14] propose a faster method by walking directly to the singular points, and the method does not need to visit each pixel or each small image block to locate the singular point. In En et al.’s method, walking directional fields (WDFs) should be established at first, and then a walking strategy is easily carried out for fast location with an acceptable accuracy. Compared with methods based on the Poincare index and filter and model techniques, although these hybrid schemes can obtain better performance and higher efficiency in experimental evaluations, to a certain extent, they still depend on the quality of the fingerprint orientation field and does not work very well for low-quality fingerprint like the existing ones.
In recent years, much attention has been given to using deep learning models for fingerprint recognition [21], such as segmentation [22,23], orientation field estimation [24,25], minutiae extraction [26,27], and minutiae descriptor extraction [28]. Jin et al. [15] firstly proposed the singular points detection method based on deep learning. They firstly design two convolutional neural networks in which one is used for classifying the core, the delta and the background and the other is used for estimating the positions of the core and the delta. Following this, a probabilistic method is used to determine the actual positions of singular points. However, the block classification method is somewhat rough, and this method has many processing steps. Its training process is also cumbersome including dividing the training images into many blocks and multi-scales. Hong et al. [29] also used the idea of block classification to automatically detect fingerprint singular points. However, its performance does not surpass Jin et al.’s. Inspired by the successful object detection in natural images, Liu et al. [16] regard the singular point detection as the object detection problem and propose a deep learning detection algorithm via faster-RCNN. Liu et al.’s algorithm has a two-step strategy: some candidate patches, in which it is probable for singular points to exist, are chosen by one network in the first step, and the precise singular points are selected and located from the candidate patches in the second step. Compared to Jin et al.’s method, Liu et al.’s is more precise in detection rate. However, for Liu et al.’s method, the detection accuracy is still affected by anchor size, and low-quality small target detection is still a difficult problem [30]. That is to say, the faster-RCNN does not work very well for the fingerprint singular point detection, especially for the low-quality fingerprint. At the same time, it needs a large number of fingerprint images for training.
In 2019, Geetika et al. [17] presented a macro-localization network and a micro-regression network to detect fingerprint singular points from coarse to fine, where the macro-localization network aims at extracting squares of size pixels around singular points while the micro-regression network at regressing the accurate coordinates of singular points. They firstly adopt the idea of semantic segmentation for extracting fingerprint singular points. However, the semantic segmentation network (i.e., macro-localization network) just segments the big coarse image block containing singular points. For more precise positioning, all the segmented image blocks need to be put into the non-semantic segmentation network (i.e., micro-regression network) for training again. Actually, the idea of semantic segmentation plays a limited role in the whole method. Additionally, their twice training is time-consuming and laborious. What’s more, the detection performance of Geetika et al.’s method, close to that of Liu et al.’s method, is still unsatisfactory. However, compared with methods on traditional digital image processing algorithms, those on deep learning have the advantage that the original fingerprint images are directly adopted instead of the orientation fields after processing the original image.
Through the analysis above, it can be seen that deep learning is one of the most important trends to improve the performance of fingerprint singular points detection. However, the design of current approaches based on deep learning is somewhat complicated and the training process consumes too much data and time. In addition, for the existing methods based on both traditional digital image processing [4,5,6,7,8,9,10,11,12,13,14] and deep learning [15,16,17], their detection rate of singular points is still unsatisfactory, especially on the low-quality fingerprint. Thus, it is an important and challenging research problem to design a simple and effective network requiring easier training, fewer amounts of training data and yet retaining high singular point detection performance.
3. Proposed Method
As mentioned above, the singular point detection rates of the existing methods are still unsatisfactory, especially for the low-quality fingerprint. Aiming at higher singular point detection rate, we propose a new singular point detection method, which regards singular point detection as a semantic segmentation of the small singular point area completely and directly. In our proposal, the main contribution lies in that we design a new customized convolutional neural network called SinNet which is used to segment the fingerprint singular point area directly and precisely. With the output of SinNet, a simple and fast post-processing called SimpleBlobDetector [31] is used to locate the corresponding singular points quickly.
Therefore, our detection method consists of a main part and an auxiliary part: the former includes the detailed design of SinNet and how to use the newly designed SinNet to extract the small singular area which has dual channel structure, one branch for the core area detection and the other branch for the delta; and the latter is the existing blob detector named SimpleBlobDetector for singular point location. In the following, we shall introduce our proposal in details.
3.1. Algorithm framework
The whole flowchart of the proposed method is shown in Figure 1, with which the functions of the characteristic structures and modules are explained as follows:
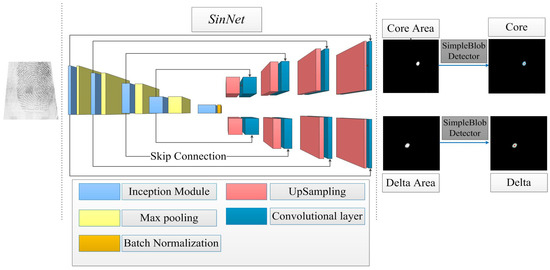
Figure 1.
The flowchart of the proposed method.
- (1)
- SinNet is the encoder-decoder architecture, and it has an encoder part and two corresponding decoder parts, followed by two final pixel-wise convolutional layers. The encoder-decoder architecture is a common architecture of semantic segmentation network, which can be used to segment target areas.
- (2)
- The encoder layers act as feature extractors, which aims at extracting target characteristics. The encoder layers include the convolution operation and the pooling operation. With the deepening of the number of layers, the semantic information extracted is advanced further.
- (3)
- The decoder layers are used to upsample the abstraction back into its original size in details. The decoder layers include the convolution operation and the upsampling operation. The final output image has the same size as the input image.
- (4)
- Five identical customized inception modules are adopted in the encoder part. Here, the inception module can expand the width of the network in structure and extract features on multiple scales in function, and its specific structure is shown in Figure 2. The inception module is to perform multiple convolution on input images in parallel, and stitch all output results into a very deep feature map, which aims to design a network with excellent local topology.
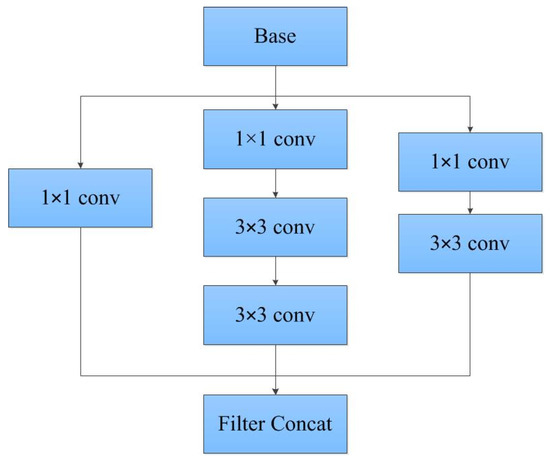 Figure 2. Inception module of SinNet.
Figure 2. Inception module of SinNet. - (5)
- At the end of the encoder part, one batch normalization layer is used to prevent over-fitting, improve the robustness of the model to different hyper-parameters, and keep most activation functions away from its saturation region. It achieves accelerating network convergence speed and improving training stability.
- (6)
- Four skip connections are used for connecting the encoder part and decoder part, and they aim to let the final recovered feature maps fuse low-level features. It is worth noting that each connected feature map dimension should be consistent. The boundary of singular point area is fuzzy and the gradient is complex, so semantic segmentation needs more high resolution information. The skip connection could provide high resolution information for fusion.
- (7)
- At last, a simple and fast blob detection method called SimpleBlobDetector is adopted to locate the singular points.
In order to further clarify our idea, the differences between fingerprint singular points and generic objects are presented in details. For the generic semantic segmentation task, he convolutional neural network, especially the encoder–decoder architecture network, usually needs to segment more than a dozen objects of different subject classes in natural images. Different objects in an image usually contain different features, such as texture, color, shape and size. However, the fingerprint images are simpler, and they are usually gray scale images. Their ridges are represented by dark lines and their valleys together with the background are represented by bright pixels. To some extent, the structures of singular points are simpler than generic objects so that we adopt a shallow encoder-decoder architecture network to achieve the singular point area segmentation. In order to enhance robustness for cores and deltas of different size, we design a wide network using an inception module for extracting multi-scale features. At the same time, we adopt the symmetrical structure and the skip connection to restore the details of fingerprint images.
3.2. Design Details of SinNet
SinNet consists of two parts: the front part achieves the encoder function while the back part achieves the decoder function, which is illustrated in Figure 3. The front part is public and the back part has two branches: one branch is used for the core area segmentation, and the other branch is used for segmenting the delta area. We explain these two parts as follows:
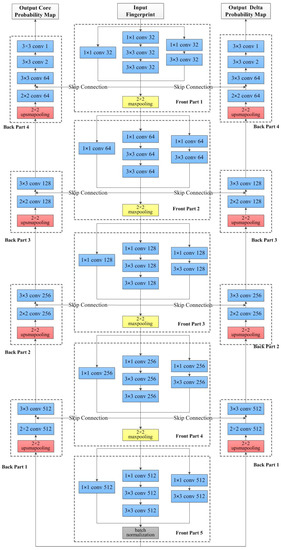
Figure 3.
The detailed SinNet structure.
The front part has five sub-modules. The four sub-modules in front are same in structure. Each of the four sub-modules in front is composed of one inception module and one 2 × 2 max pooling layer. Although they have the same filter sizes, they are different from each other in the number of filters. For these four sub-modules, their numbers of filters are 32, 64, 128 and 256, respectively. The last sub-module consists of one batch normalization layer and one inception module with 512 filters.
In the back part, there are two branches which are identical in structure but different in function. One branch is used for the core area segmentation while the other is for the delta area segmentation. Each of these two branches consists of four sub-modules. The three sub-modules in front are all composed of one 2 × 2 upsampling layer and two convolutional layers. Although they have the same filter sizes, they are different from each other in the number of filters. For these three sub-modules, their numbers of filters are 512, 256 and 128, respectively. The last sub-module consists of one 2 × 2 up-sampling layer and four convolutional layers, whose numbers of filters are 64, 64, 2 and 1, respectively. Actually, the output of the last convolution layer is used as the algorithm output, which is a probability map. Multiplied by 255, the probability map is transformed into the gray scale map where the bright pixels mean that there may be singularities while the dark pixels mean that there may be the background.
3.3. Training
In this section, we shall introduce the configuration and parameter information in our SinNet training, as well as the customized mixed loss function used.
(1) For the configuration and parameter information, in our training process, Adam [32] is chosen as the optimization method. The learning rate and the momentum are set to 0.1 and 0.9, respectively.
(2) For the loss function, we proposed a new mixed loss function based on weighted cross entropy loss function and dice loss function. The formulas of weighted cross entropy loss function, dice loss function, and our new mixed loss function are show as (1), (2) and (3), respectively:
where y is the image of true singular point area, is the image of predicted singular point area, h is the height of the image, w is the width of the image and (i,j) is the coordinates of image pixel. , as shown in (1), is suitable for the binary classification problem. Since positive and negative labels are unbalanced in our training, and are used to balance their loss contributions. , as shown in (2), uses the segmentation effect evaluation index directly as the loss to supervise the network, which is mainly to solve the problem that the proportion of positive and negative samples is seriously unbalanced. Our shown in (3) integrates the characteristics of dice loss with ones of weighted cross entropy loss and works well in training.
3.4. Singular Points Locating and Spurious Points Removing
In this section, we shall show how we use SimpleBlobDetector to locate singular points. With an original fingerprint image as input, SinNet can output a probability map. Multiplied by 255, it is transformed into a gray scale map. The response area of the gray image is the predicted singular point area. Then, the blob detection method called SimpleBlobDetector [31] is adopted to process the response area and the centers of the detected blob are regarded as the singular points, which is what we want finally. The example of blob detection result is shown in Figure 4, where (a) and (d) are the same original fingerprint, (b) is the corresponding detected core area, (c) is the corresponding detected core, (e) is the corresponding detected delta area, and (f) is the corresponding detected delta.

Figure 4.
The example of blob detection results: (a) the original fingerprint; (b) the detected core area; (c) the detected core; (d) the original fingerprint; (e) the detected delta area; and (f) the detected delta.
It is worth noting that in our scheme, blob detection mainly detects the pixel areas whose gray value is larger than the surrounding area in the image. Common blob detection methods are based on differential detector and local extremum, and the reason why we choose SimpleBlobDetector lies in that it is provided by OpenCV, i.e., a computer vision library, and it is a simple and fast blob detection method. Unlike other singular point detection methods, the output of our SinNet is a small and more accurate response area, so more complex post-processing is not needed and the simple SimpleBlobDetector can meet the requirements of singular point location, which also shows the advantage of our algorithm over the existing ones.
In our scheme, several outputs still have spurious points. In order to remove these spurious points and reduce the false alarm rate, a simple rule is defined. If more than two cores or two deltas are detected in a fingerprint image, all of them are determined to be spurious points. That is to say, it is determined that there are no cores or deltas in this fingerprint.
Note that, although the proposed method and Geetika et al.’s method [17] seen intuitively somewhat similar because both our SinNet and their macro-localization network adopt the idea of semantic segmentation, there exist fundamentally differences as follows:
- (1)
- The structures of the two networks are totally different. Especially, our SinNet uses a large amount of inception modules which consist of different convolutional kernels and belong to a successful local multi-path representation strategy [19] for extracting features on multiple scales, while the macro-localization network uses the local single-path representation strategy.
- (2)
- The functions of the two networks are different. According to SPD2010 competition’s instructions, we regard singular point detection as a semantic segmentation of the small singular point area directly. The area is a circle with a center of singular point and a radius of 10 pixels. Our SinNet could segment the small singular area precisely and directly. Therefore, a simple post-processing, a fast blob detector, is enough to find the centers as the singular points. However, the macro-localization network extracts squares of size 43 × 43 pixels around singular points. Actually, it just segments the big coarse image block containing singular points. Therefore, for more precise positioning, all the segmented image blocks need to be put into the regression network for training again.
4. Experimental Results
In this section, we shall evaluate the proposed method on the public fingerprint dataset SPD2010, and compare it with four state-of-the-art methods which consists of two detection methods [13,14] based on the traditional digital image processing and two detection methods [15,16,17] based on deep learning. It is worth noting that as to fingerprint singular point detection evaluation, some researchers use SPD2010 while others use other datasets such as FVC2002 and FVC2004. The reason why we choose SPD2010 lies in that it has clearly marked the exact locations of all singular points for total 500 fingerprint images, while other public fingerprint datasets, such as FVC2002 and FVC2004, fail to do so. At the same time, the fingerprint images in this dataset have a large variety in quality, type, affine transformation and nonlinear distortion [2]. All these make it more convincing than other datasets. In the following, we shall introduce our experiment and analysis: firstly, the training data preparation is given; secondly, the ground truth labels are illustrated; thirdly, the testing fingerprints datasets and evaluation criteria are introduced; fourthly, the experimental results and analysis are presented; fifthly, some properties comparisons between two methods based on deep learning and ours are shown, and at last, the efficiency analysis is given.
4.1. Training Data Preparation
The training set that we use is the training set provided by SPD2010. It has 210 fingerprint images with 355 × 390 pixel resolution captured by an optical scanner (Microsoft Fingerprint Reader-model 1033 and resolution 500dpi) without any restrictions on the poses of fingers. The ground truth of the SPD2010 training set has been given by office according to E. R. Henry’s definition [33] of singular points, and thus we need not do anything. It should be noted that we just use the SPD2010 training set and the data augmentation is not required. All 210 fingerprint images from SPD2010 training dataset are adopted to train our SinNet. Figure 5 shows two examples from the training set of SPD2010, and (a) is a low-quality fingerprint, while (b) is a high-quality fingerprint.

Figure 5.
Two examples of the training set of SPD2010: (a) a low-quality fingerprint; and (b) a high-quality fingerprint.
4.2. Ground Truth Labeling
Here, we shall show ground truth labeling used in our training. According to SPD2010 competition’s instructions, for a ground truth singular point , if a detected singular point satisfies and at the same time, the point is considered to be truly detected, where is the coordinate of detected singular point, t is the type of the singular point including the core and the delta, and is the ground truth. According to the competition’s instructions mentioned above, the detected singular point is considered as a circular area, which is equal to the singular point area. In the process of our labeling, we use the singular point coordinate as the center and let 10 pixels as the radius to draw a circle. The circle area is set to the foreground while the rest is set to the background. Our labels can be classified into two categories, and thus two sets of labels are generated. One set is the label of cores and the other is the label of deltas. The calibrated samples of labeling can be shown in Figure 6, where (a) is the original fingerprint, (b) is the label of core, and (c) is the label of delta.

Figure 6.
The calibrated samples of label: (a) the original fingerprint, (b) the label of core, and (c) the label of delta.
4.3. Testing Dataset and the Evaluation Criteria
The proposed algorithm is tested on the testing set of SPD2010, which has 290 fingerprint images. According to SPD2010 competition’s instructions, the evaluation criteria are as follows: (1) the evaluation will consider the quantity and type of the detected singular points as well as their distance to the ground truth. (2) For a ground truth singular point , if a detected singular point satisfies and at the same time, the point is considered to be truly detected. Otherwise, it is called a miss. (3) The detection rate is defined as the ratio of the truly detected singular points to all ground truth singular points. (4) The miss rate is defined as the ratio of the missed singular points to all ground truth singular points. (5) The false alarm rate is defined as the ratio of the falsely detected singular points to all ground truth singular points. (6) If all singular points are truly detected and there are no spurious singular points in a fingerprint, the fingerprint is considered to be ‘correctly’ detected. In our experiment, we evaluated the detection methods strictly according to the evaluation criteria of SPD2010, which is good for evaluating our algorithm and comparing it with the existing ones objectively and conveniently.
4.4. Experiment Analysis
Experiments are conducted and comparison is made between our method and four state-of-the-art methods including Angle Matching Filter (AMF) [13], walking point (WP) [14], singular point block classification method (SPBC) [15], singular point object detection (SPOD) [16] and SP-Net [17]. The experiments are performed under similar conditions and followed all the rules of SPD2010. The experiment results are shown in Table 1.

Table 1.
Detection performance over the SPD2010 test dataset.
From Table 1, it can be seen that: (1) for the corrected detection rate, which is the most important index, the best result of the existing method is 38%, while that of ours is 48%—our proposal achieves about 10% improvement in the corrected detection rate. (2) For the detection rate of cores and deltas, the best results of the existing method are 56% and 60%, respectively, while our method has achieved 68% and 63%. Our approach has achieved the best results on both indexes. (3) For the miss rate of cores and deltas, the lower this rate is, the better the performance is. Our method has also obtained the best result with respect to the miss rate. (4) For the false alarm rate of cores and deltas, the WP works best, which are as low as 10% and 12%, respectively. In comparison, the rates of our proposal are 16% and 15%, respectively. However, WP’s corrected detection rate is only 32%, in the case of low corrected detection rate, it does not perform well in the overall detection performance. Taken together, comprehensively considering various indexes, our method performs best in fingerprint singular point detection accuracy.
In Figure 7, we present three examples of correct detection results by the proposed method. All these three examples are high-quality fingerprint images. In Figure 7, the red star represents the core and the yellow triangle represents the delta. In Figure 8, we present the detection results obtained by different methods on two low-quality fingerprint examples in the test dataset from SPD2010. Figure 8a,c show the core detection results on No.0311 and No.0436 in the testing dataset. The red star is the ground truth, the green star is the result obtained by the proposed method, the yellow star is the result obtained by SPOD, the orange star is the result obtained by SP-Net, the blue star is the result obtained by AMF and the black circle means the corrected detection area. Figure 8b,d show the core detection results obtained by the proposed method. As can be seen from Figure 8, AMF, SPOD and SP-Net detect error singular points, and WP and SPBC cannot even detect any point, while our method can correctly detect the singular points. To some extent, it can be concluded that our method is more effective and robust for detecting the singular points out of low-quality fingerprints. In Figure 9, we present the numbers of correctly detected fingerprint images of our method and other five methods in the test dataset from SPD2010, where A is the total number of the testing set, B is the number of correctly detected fingerprint images by our proposed method, C is the union number of correctly detected fingerprint images by the other five methods, and D is the intersection of B and C.

Figure 7.
Three examples of correct detection results by the proposed method.

Figure 8.
Two examples of core detection results by the five singular points detection methods and the proposed method: (a) the core detection results on No.0311; (b) the core detected by our proposal; (c) the core detection results on No.0436; and (d) the core detected by our proposal.
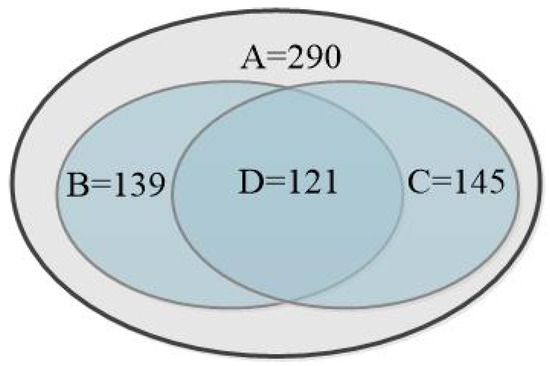
Figure 9.
Numbers of correctly detected fingerprint images of our method and other five methods in the test dataset from SPD2010.
4.5. Properties Comparisons of Three Methods Based on Deep Learning
In order to further compare the differences among the three methods mentioned above based on deep learning with ours, we analyze them from six aspects, including the network number, the network types, the training data scale, the labeling difficulty, the detection accuracy and the loss function. The analysis results are shown in Table 2 and it is explained as follows:
Table 2.
Properties comparisons of four methods based on deep learning.
- (1)
- The network number influences algorithm complexity and training complexity to some extent. SPBC and SP-Net has two networks to be trained, while SPOD and ours have only one.
- (2)
- For the network types, SPBC uses the VGG network and FCN network, SPOD modifies the Faster-RCNN network for detection, and SP-Net used the hourglass network and four layer regression network. In comparison, our SinNet is a customized network, which is newly designed for segmenting the fingerprint singular areas accurately.
- (3)
- The training data scale greatly affects the training complexity. Generally speaking, a good network can achieve excellent performance when the amount of data is limited. SPBC, SPOD use more than 10,000 fingerprint images and SP-Net use more than 1000 fingerprint images for training to achieve the effect described in their article, while our proposal just needs 290 fingerprint images. This proves the superiority of our proposed SinNet.
- (4)
- The labeling difficulty is affected by the training data scale and the way of labeling. For SPBC, its training data scale is large, and its way of labeling is a little complex. For SPOD, its training data scale is large, while its way of labeling is easy. For SP-Net, its training data scale is medium, while its way of labeling is hard. In comparison, our method has a smaller training data scale, and easier labeling. That is to say, the labeling difficulty in our method is the lowest, and it is convenient to apply.
- (5)
- The loss function plays an important role in the network training. Both SPBC and SP-Net have double loss functions for two networks and SPOD has double loss functions for anchor classification and coordinates regression. In comparison, our method needs only one mixed loss function for pixel classification.
- (6)
- The detailed detection results and analysis are shown on Section 4.4. Our method has indisputably achieved the best performance in terms of comprehensive indexes among the methods based on deep learning.
From the above analysis, we can draw a conclusion that the properties of four methods based on deep learning are different and our proposed method has advantages in most aspects.
4.6. Efficiency Analysis
To investigate the time efficiency of our proposed method, we record the detection time on a PC computer with Intel(R) Xeon (R) CPU E5-2630 (2.2 GHz), 128 GB of RAM, and GPU Tesla K40C. Results show that it takes about 3.2 milliseconds for our algorithm to detect one fingerprint image, which is fast enough to be favored in real-time applications.
5. Conclusions
The singular point detection accuracy of current methods in the literature is still unsatisfactory, especially on low-quality fingerprint images. We propose a new customized convolutional neural network called SinNet for segmenting the accurate singular point area directly, followed by a simple and fast post-processing to locate the singular points quickly. The training data labeling, the mixed loss function, the encoder-decoder architecture, the inception module, skip connections and the batch normalization are used together to ensure the efficient performance of the network. Advantages over other detection methods lie in three aspects: (1) the customized network is simpler and works better for extracting the accurate singular point area; (2) compared to other methods based on deep learning, our method requires much less fingerprint data and easier training processing; (3) our method achieves the best accuracy of SPD2010 in terms of comprehensive assessment indicators. In specific, the performance of our method is much better than the other methods in most aspects, especially the correctly detection rate (CD) and the detection rate of cores.
Author Contributions
Conceptualization, L.P. and J.C.; methodology, L.P., J.C. and H.Z.; software, J.C. and F.G.; investigation, H.Z. and Z.C.; writing—original draft, J.C. and L.P.; writing—review and editing, L.P. and H.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Key Technologies Research and Development Program of China under Grant 2018YFB1105303, the National Natural Science Foundation of China under Grant 61876139 and 61906149, the National Cryptography Development Fund under Grant MMJJ20170208, and the Natural Science Basic Research Plan in Shaanxi Province of China under Grant 2019JM-129.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gu, S.; Feng, J.J.; Lu, J.W.; Zhou, J. Efficient Rectification of Distorted Fingerprints. IEEE Trans. Inf. Forensics Secur. 2018, 13, 156–169. [Google Scholar] [CrossRef]
- Magalhaes, F.; Oliveira, H.P.; Campilho, A. Spd 2010 Fingerprint Singular Points Detection Competition Introduction. Available online: http://paginas.fe.up.pt/~spd2010/ (accessed on 10 February 2010).
- Zhou, J.; Chen, F.L.; Gu, J.W. A Novel Algorithm for Detecting Singular Points from Fingerprint Images. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1239–1250. [Google Scholar] [CrossRef] [PubMed]
- Kawagoe, M.; Tojo, A. Fingerprint pattern classification. Pattern Recognit. 1984, 17, 295–303. [Google Scholar] [CrossRef]
- Weng, D.W.; Yin, Y.L.; Yang, D. Singular points detection based on multi-resolution in fingerprint images. Neurocomputing 2011, 74, 3376–3388. [Google Scholar] [CrossRef]
- Belhadj, F.; Akrouf, S.; Harous, S.; Aoudia, S.A. Efficient fingerprint singular points detection algorithm using orientation-deviation features. J. Electron. Imaging 2015, 24, 033016. [Google Scholar] [CrossRef]
- Bazen, A.M.; Gerez, S.H. Systematic methods for the computation of the directional fields and singular points of fingerprints. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 905–919. [Google Scholar] [CrossRef]
- Nilsson, K.; Bigun, J. Prominent symmetry points as landmarks in fingerprint images for alignment. In Proceedings of the International Conference on Pattern Recognition, Quebec City, QC, Canada, 11–15 August 2002; pp. 395–398. [Google Scholar]
- Nilsson, K.; Bigun, J. Localization of corresponding points in fingerprints by complex filtering. Pattern Recognit. Lett. 2003, 24, 2135–2144. [Google Scholar] [CrossRef]
- Jin, C.; Kim, H. Pixel-level singular point detection from multi-scale Gaussian filtered orientation field. Pattern Recognit. 2010, 43, 3879–3890. [Google Scholar] [CrossRef]
- Chen, H.T.; Pang, L.J.; Liang, J.M.; Liu, E.Y.; Tian, J. Fingerprint Singular Point Detection Based on Multiple-Scale Orientation Entropy. IEEE Signal Process. Lett. 2011, 18, 679–682. [Google Scholar] [CrossRef]
- Fan, L.L.; Wang, S.G.; Wang, H.F.; Guo, T.D. Singular points detection based on zero-pole model in fingerprint images. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 929–940. [Google Scholar] [PubMed]
- Qi, J.; Liu, S.X. A Robust Approach for Singular Point Extraction Based on Complex Polynomial Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 78–83. [Google Scholar]
- Zhu, E.; Guo, X.F.; Yin, J.P. Walking to singular points of fingerprints. Pattern Recognit. 2016, 56, 116–128. [Google Scholar] [CrossRef]
- Qin, J.; Han, C.Y.; Bai, C.; Guo, T.D. Multi-scaling detection of singular points based on fully convolutional networks in fingerprint images. In Proceedings of the Chinese Conference on Biometric Recognition, Shenzhen, China, 28–29 October 2017; pp. 221–230. [Google Scholar]
- Liu, Y.H.; Zhou, B.C.; Han, C.Y.; Guo, T.D.; Qin, J. A Method for Singular Points Detection Based on Faster-RCNN. Appl. Sci. 2018, 8, 1853. [Google Scholar] [CrossRef]
- Geetika, A.; Ranjeet, R.J.; Akash, A.; Kamlesh, T.; Aditya, N. SP-NET: One Shot Fingerprint Singular-Point Detector. arXiv 2019, arXiv:1908.04842. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Mao, X.J.; Shen, C.; Yang, Y.B. Image restoration using convolutional auto-encoders with symmetric skip connections. arXiv 2016, arXiv:1606.08921. [Google Scholar]
- Engelsma, J.J.; Cao, K.; Jain, A.K. Fingerprints: Fixed Length Representation via Deep Networks and Domain Knowledge. arXiv 2019, arXiv:1904.01099. [Google Scholar]
- Zhu, Y.M.; Yin, X.F.; Jia, X.P.; Hu, J.K. Latent Fingerprint Segmentation Based on Convolutional Neural Networks. In Proceedings of the IEEE Workshop on Information Forensics and Security, Rennes, France, 4–7 December 2017; pp. 1–6. [Google Scholar]
- Dai, X.; Liang, J.; Zhao, Q.; Liu, F. Fingerprint segmentation via convolutional neural networks. In Proceedings of the Chinese Conference on Biometric Recognition, Shenzhen, China, 28–29 October 2017; pp. 324–333. [Google Scholar]
- Cao, K.; Jain, A.K. Latent Orientation Field Estimation via Convolutional Neural Network. In Proceedings of the International Conference on Biometrics, Phuket, Thailand, 19–22 May 2015; pp. 349–356. [Google Scholar]
- Qu, Z.; Liu, J.; Liu, Y.; Guan, Q.; Li, R.; Zhang, Y. A novel system for fingerprint orientation estimation. In Proceedings of the Chinese Conference on Image and Graphics Technologies, Beijing, China, 8–10 April 2018; pp. 281–291. [Google Scholar]
- Nguyen, D.L.; Cao, K.; Jain, A.K. Robust Minutiae Extractor: Integrating Deep Networks and Fingerprint Domain Knowledge. In Proceedings of the 2018 International Conference on Biometrics, Gold Coast, Australia, 20–23 February 2018; pp. 9–16. [Google Scholar]
- Tang, Y.; Gao, F.; Feng, J.; Liu, Y.H. FingerNet: An Unified Deep Network for Fingerprint Minutiae Extraction. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics, Denver, CO, USA, 1–4 October 2017; pp. 108–116. [Google Scholar]
- Cao, K.; Jain, A.K. Automated Latent Fingerprint Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 788–800. [Google Scholar] [CrossRef]
- Hong, H.L.; Ngoc, H.N.; TriThanh, N. Automatic Detection of Singular Points in Fingerprint Images Using Convolution Neural Networks. In Proceedings of the 2017 Asian Conference on Intelligent Information and Database Systems, Kanazawa, Japan, 3–5 April 2017; pp. 207–216. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296v1. [Google Scholar]
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2008; Available online: http://shop.oreilly.com/product/0636920044765.do (accessed on 1 June 2020).
- Diederik, P.K.; Jimmy, B.L. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Henry, E.R. Classification and Uses of Finger Prints; HM Stationery Office: London, UK, 1934; Available online: https://www.researchgate.net/publication/243773865_Classification_and_Uses_of_Finger_Prints (accessed on 1 June 2020).









© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).