1. Introduction
The industrial revolution and modernization have led us to a new era of science and technology. On the one hand, it has opened new horizons for transportation, trade, mining, agriculture, and urbanization. On the other hand, it has become a vital factor in polluting air, soil, and water. In the last two decades, many environmental researchers have been monitoring the quality of ambient air. Particulate matter (PM) is found to be the most dangerous kind of air pollution among various other air pollutants. After a study done by the World Health Organization (WHO) and the International Agency of Research center (IARC), PM in ambient air has been categorized as ‘carcinogenic’ [
1,
2]. PM
are the fine particulate matters with size less than 2.5 micrometer which are the major cause of allergies, pulmonary, and cardiovascular diseases, morbidity, and mortality. Various epidemiological tests [
3] have shown a direct relationship between PM pollution with respiratory infections and cardiovascular diseases. WHO declares ambient air pollution, especially fine particulate matter, has the most adverse effect on human health, which is mostly emitted by industries, power plants, households, biomass burning, and vehicles [
4]. WHO has also estimated that increasing levels of PM have played a major role in causing lung cancer, chronic obstructive pulmonary disease (COPD), ischemic heart disease, and stroke, thus leading to premature deaths.
In this era of big data and Artificial Intelligence (AI), it is important to estimate the concentration of fine particles in the air so that people can take precautionary measures to prevent from alarming levels of high air pollution concentrations. Various deterministic models have been used for the prediction of PM
concentration and other air pollutants. Several studies have been done to estimate the air pollutants concentration using numerous modeling techniques [
5] including statistical, Machine Learning (ML), and photo-chemical models [
6].
The objectives of this paper are as follows: (1) Analyze the features that are highly correlated with the PM concentration, such as meteorological parameters (temperature, wind speed, relative humidity, surface roughness, planetary boundary layer, and precipitation) and pollutants’ concentrations (PM, CO, NO, SO, and O). (2) The pollutants’ concentration variables can be measured by monitoring stations at specified locations and also predicted by the CMAQ model. After combining the features predicted by CMAQ model (elemental carbon (EC), ammonium (ANH), nitrate (ANO), and miscellaneous pollutants (OTHR) concentration), the results of ML models have improved (3) Design and optimize six recently used state-of-the-art machine learning models and compare their average performances. We choose two recent and most widely used tree-based models, XGBoost and LightGBM, which fall under the category of machine learning; four popular Deep Learning (DL) neural networks named Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and convolutional-LSTM (CNNLSTM); and a combination of Bidirectional and Unidirectional LSTM (BiULSTM) for the prediction of PM concentration. Among these, LSTM network outperforms other well-known models.
2. Related Work
Time series forecast is the most important part of the ML regression problem; both shallow and DL models have been used for this purpose. Tree-based models such as decision trees, random forests (RF) [
7], and gradient tree boosting models are well known to give good performance and have been widely used in supervised ML methods. These can map non-linear relationships among data unlike linear ML models such as linear regression [
8] and support vector machine (SVM) [
9]. The RF model has been used to study the impact of various factors on pollutants concentrations by utilizing meteorological parameters, pollutants concentration, and traffic flow [
10]. XGBoost [
11], introduced by Chen, T. and Guestrin, C., is an ensemble of boosted decision trees that uses gradient descent for model optimization and has been widely used in regression [
12], classification [
13], and time series forecasting [
14]. XGBoost was implemented to predict PM
concentration in [
15], where the author analyzed the data of one station in China and compared the results with RF, SVM, Multiple Linear Regression (MLR) [
16], and Decision Tree Regression (DTR) algorithms [
17]. The dependent variables used in this research were pollutants’ concentrations such as PM
, CO, NO
, SO
, and O
; among all the models, XGBoost showed the best results. LightGBM [
18] also belongs to the gradient tree boosting models, in which a decision tree is split in leaf-wise with the best fit, thus reducing the loss with better accuracy. Similarly, XGBoost and LightGBM models have been used to predict the thermal power energy development [
19] and later showed less Mean Absolute Percentage Error (MAPE%) on their dataset.
Along with shallow ML models, DL models are also commonly used these days and have been successfully used for pollutants forecasting [
20]. In a recent study [
21,
22], LSTM model has been used for the prediction of PM
and PM
concentrations by utilizing pollutants concentration and meteorological parameters. The authors compared the results with the Community Multi-scale Air Quality (CMAQ) model [
23] and found that DL based model performs better. CNNLSTM is also a variant of LSTM models in which CNN [
24] has been used for extracting the features and then fed to the LSTM model to get the forecast; they are being used in various time series prediction problems [
25,
26]. Huang, C. J. [
27] only used three meteorological parameters (wind speed, wind direction, and precipitation) to predict the PM
concentrations. Their proposed model, which they named “APNet” (a combination of CNN and LSTM), showed good results against SVM, DTR, RF, MLP, CNN, and LSTM. In a recent study [
28], the authors proposed a novel CNNLSTM model with attention mechanism. Along with pollutants concentration and meteorological parameters, they also utilized the information of nearest stations to capture the spatial dependencies. GRU [
29] is also a type of RNN and a variant of LSTM with fewer gates, making the model faster. It also has been adopted in many time series forecasting problems. In [
30], GRU is utilized for estimating primary energy consumption in China and the model results are compared with SVM and MLR, where GRU gives good prediction accuracy. Similarly, a combination of the Bidirectional and Unidirectional LSTM (BiULSTM) model was used for PM
forecasting by Yun, J. [
31], who tested it with SVM and MLR, with BiULSTM providing better prediction results than the other methods used. In this study, input features used are concentrations of pollutants (SO
, CO, NO
, and O
), the meteorological parameters, and PM
concentration of the nearest stations.
The input features play an important role in the prediction of any machine learning model, and, by using background knowledge of the parameters that are vital in the formation of PM particles, the models’ performance can be improved. In our study, we utilized meteorological parameters and pollutants concentrations that are highly effective in the formation of PM concentration collected from ground based monitoring sites as well as predictions of CMAQ model.
3. Methodology
In this section, we discuss how the study was conducted. To get prediction from ML models, data collection, analysis for feature correlation, and data preprocessing were done before inputting the data to ML model. After that, each model was constructed and optimized by setting its best hyperparameters. Then, models were trained and predictions were generated on a test dataset. Finally, to check the efficiency of the models, each model was evaluated using statistical evaluation parameters. The process of this study is shown in
Figure 1.
Section 3.1 contains the description and preprocessing of the data.
Section 3.2 describes the architecture of LSTM network. The experimental process of setting the models is described in
Section 3.3. The evaluation metrics and their formulas are discussed in
Section 3.4.
3.1. Data and Preprocessing
The dataset contains meteorological parameters, measured values of pollutants’ concentration from ground base stations, and predictive values of four pollutants predicted by the CMAQ model in South Korea from 1 January 2016 to 31 December 2016 recorded on hourly basis. Six ground-based pollutants observation are collected: PM
, PM
, sulfur dioxide, ozone, nitrogen dioxide, and carbon monoxide concentrations measured in
g/m
. They are available at Air-Korea website [
32]. Six meteorological parameters (temperature, wind speed, relative humidity, surface roughness, planetary boundary layer, and precipitation) were taken from Korean public data website [
33]. PM
has a strong correlation with the pollutants such as elemental carbon, nitrate, and ammonium, as described in various studies [
34,
35], and ground-based sites do not measure these dependent pollutants, but CMAQ model has the ability to predict these features. CMAQ data have been predicted and provided by Air Lab at Gwangju Institute of Science and Technology [
36] for the same time duration. The CMAQ model predictive features labels are: CMAQ_EC, CMAQ_ANO3, CMAQ_ANH4, and CMAQ_OTHR, measured in
g/m
. To check the models’ performance, we selected data from four sites of Seoul and four locations of Gwangju (a city located south of Seoul). The average evaluation results from all the stations for each model with and without using CMAQ data are given in
Section 4, which show that by including CMAQ features, we can get better prediction results.
It is necessary to analyze the relationship between PM
and other features. For this purpose, a heat map is provided in
Figure 2. The variables having the higher correlation with PM
concentrations are shown in dark red color while variables with less correlation are shown in light pink shade. The correlation of PM
with the pollutants from higher to lower is: PM
> ammonium = nitrate ions > carbon monoxide > other-pollutants > nitrogen dioxide > elemental carbon > sulfur dioxide. Ozone and other meteorological parameters are negatively correlated with PM
concentration. The order of negatively correlated features with PM
from highest to lowest are: relative humidity > surface roughness > precipitation > wind speed > ozone > planetary boundary level > temperature. To find data distribution of each feature, we used the histogram shown in
Figure 3. There are 8727 records of data for each station, from which 7680 records were selected for training and 1023 used for testing the models (9:1 ratio for train and test dataset). The missing values were imputed by linear interpolation; data records from 1 January 2016 to 15 November 2016 were used for training and from 16 November to 31 December for testing the models. The inputs of the models are hourly observations of 16 selected features discussed above over the last 24 h and the output or label variable is the PM
concentrations that is the forecast for the next 1 h. The time duration for train and test datasets are separate from each other and do not overlap. For each prediction model, all the training was done on train dataset while validation and evaluation were made on test dataset. We used two gradient tree boosting machine learning models, namely extreme gradient boosting (XGBoost) and Light Gradient Boosting Machine (LightGBM), and reshaped the data to be appropriate for time series forecasting. Four very famous and ubiquitous deep learning models–Long Short-Term Memory (LSTM), a combination of Bidirectional and Unidirectional LSTM (BiULSTM), Gated Recurrent Unit (GRU), and Convolution LSTM (CNNLSTM)—were used. The results were compared after calculating their respective Mean Absolute Error (
MAE), Root Mean Square Error (
RMSE), Correlation Coefficient (
R), and Index of Agreement (
IA), which are given in
Section 3.4.
Before implementing deep learning models, it is recommended to normalize the data. After training the models, we un-normalized or re-scaled the data into their original form to get the prediction results. Thus, all input features were scaled between 0 and 1. The formula for scaling the data is given in Equation (
1):
We also included the observation values during high fine dust periods that usually occurs in spring and winter seasons [
37] in our training model so we could observe how well our models can predict high dust concentration values.
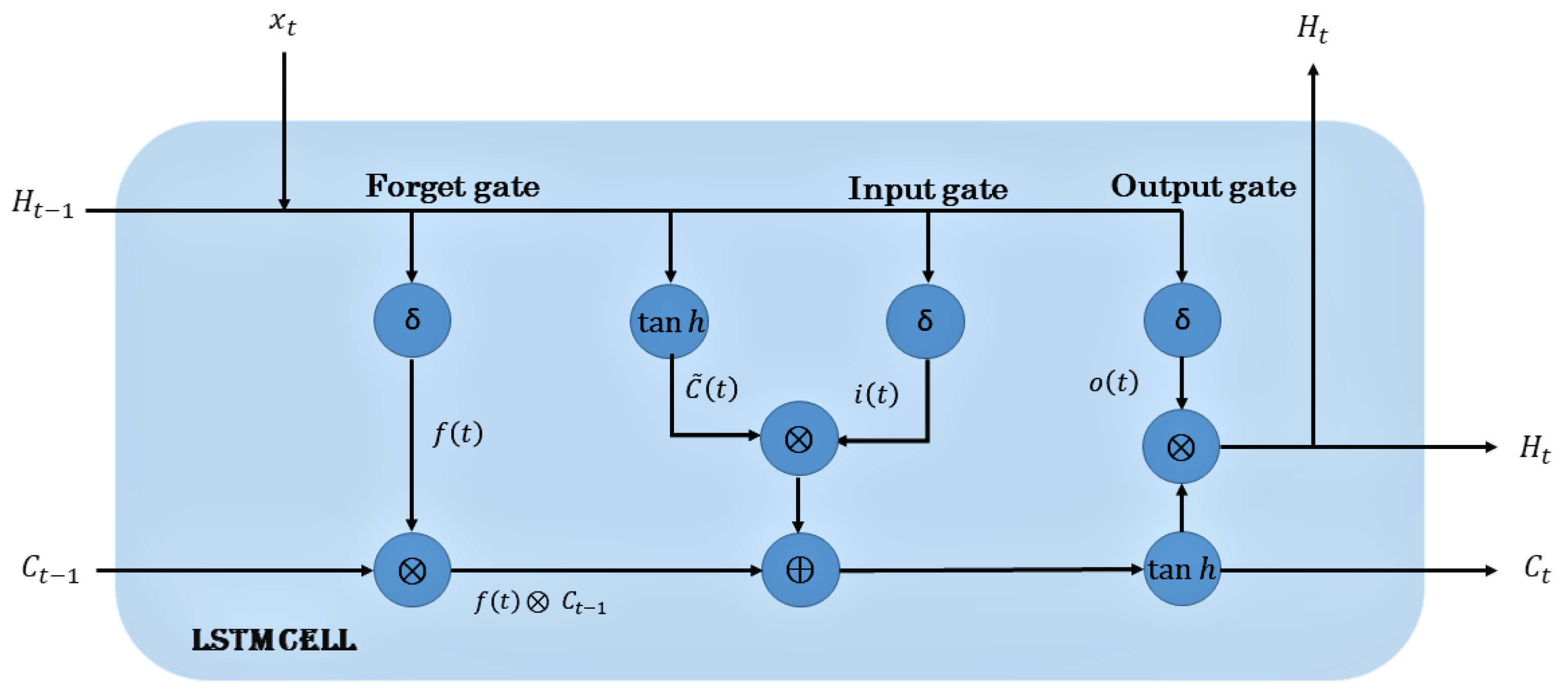
3.2. LSTM Network
An LSTM [
22] network uses cell state, input, output, and forget gates to store long-term dependencies to overcome vanishing gradient problem in typical RNNs and was introduced in 1997 by Hochreiter, S. and Schmidhuber, J. The LSTM processes the data sequentially passing the information as it propagates forward. The operations within LSTM allows it to forget or keep the information. The architecture of LSTM model is shown in
Figure 4.
The cell state which is shown as a horizontal line runs through the entire network and has the ability to add or remove the information with the help of gates. The process of the cell state is to carry the information through the sequence processing and theory information from earlier time steps can be carried all the way through the last time step thus reducing the effect of short term memory. As the process goes on, the information is added or removed from the cell states to gate states. Gates decide which information is allowed on the cell state. The first gate that is the forget gate is responsible for learning what information is necessary to keep or forget as they contain sigmoid function. The sigmoid function generates numbers between zero and one, describing how much of each component should be let through. The tanh function generates a new vector, which is added to the state. The cell state is updated based upon the outputs generated from the gates.
The sigmoid function is given as
Equations (3)–(8) represent the flow of information at each gate and cell state of LSTM network:
f, i, and o represent the outputs generated by forget gate, input gate, and the output gate, respectively. W, W, W, and W are the input weights, respectively. b, b, b, and b are bias terms and H is the output of LSTM network.
3.3. Experimental Set-Up
All models were implemented using Python language version 3.6.7, trained and tested on a computer with an Intel Core i7-8700 CPU processor and the speed of 3.20 GHz using 8192 MB RAM with the graphics card GeForce GTX 1080Ti and the operating system is Linux Ubuntu 18.04.4 LTS. The parameters setting for models is discussed in
Section 3.3.1 and
Section 3.3.2.
3.3.1. XGBoost and LightGBM
To perform extreme gradient tree boosting algorithm, we used standard XGBRegressor from Python package called xgboost version 0.90 and LGBRegressor from lightgbm Python package version 2.1.1 for the implementation of LightGBM model. To get better results from tree-based models, we needed to find best parameters for each model by using customized search approach. The best parameters for XGBoost model are: n_estimators = 70, max_depth = 2, min_child_weight = 1, learning_rate = 0.2, gamma = 0, colsample_bytree = 1, alpha = 10, and objective = reg:squarederror, with all other parameters set to default. For LightGBM, the parameter setting is: learning_rate = 0.1, max_depth = −1, metric = {‘l1’, ‘l2’}, num_leaves = 255, colsample_bytree = 1.0, objective = regression, subsample = 0.6, and seed = 10. Training the model for the best number of iterations while using early stopping patience until 5 epochs to prevent the model from overfitting gives best results at 28 epochs.
3.3.2. Deep Learning Models
To implement recurrent neural networks (RNNs), a high level neural network API called Keras with Tensorflow back end was used. We tried different parameter settings to design each DL model by changing various parameters, such as number of neurons, number of layers, optimizing function, and learning rate, to obtain the best DL model which not only performs well on the train data but also gives good prediction results on the unseen test data. We used 2–4 layers for constructing each RNN model and ran the model by selecting the number of neuron in each layer ranging as 50, 70, 100, or 150 and found that, by using two layers and keeping the number of neurons in each layer as 70, our RNN models give the best performance by minimizing the problem of overfitting and reducing model complexity. To compare RNNs, we used the same number of epochs, batch size, dropout, and loss function. Hyperparameter settings for GRU, LSTM, and BiULSTM were kept the same for comparison. During model construction process, we used dropout [
38], which is a common way to prevent overfitting in neural networks. The number of neurons or units in RNN, dropout rate, and other parameters in each layer from top to bottoms are given as:
No. of cells in each layer: [70, 70]
dropout rate of 20% has been used in the second layer of these three models.
Activation Function: ReLU
Dense layer unit:1
For CNNLSTM model, the parameter settings for each layer from top to bottom are as follows:
No. of filters in CONV1D layer: 32, Kernel size: 3, stride:1
Maxpooling layer: Pool size:3
LSTM layer cells: 32, dropout rate: 30%
Activation Function: ReLU
Dense layer unit:1
Each DL model was trained using mini batch size of 32; early stopping [
39] technique was also utilized to prevent the model from overfitting. Call backs were used to save best weights for each model. To optimize the models, we used Rmsprop [
40], which is an unpublished optimization algorithm introduced by Hinton, G. and designed for neural networks.
Customized search method was adopted to find the best learning rate for DL models, and 0.0001 were observed to be appropriate, while ’mean absolute error’ was used as the loss function to monitor the loss during training process.
3.4. Performance Evaluation for Models
To evaluate the performance of our models, we compared the observed and predicted concentrations of PM
by using four statistical evaluation metrics:
(MAE),
(RMSE),
(R), and
(IA). They are given in Equations (9)–(12). In these equations,
is the actual PM
concentration,
represents the predicted PM
concentration,
is the average of observed values, and
n is the predicted length of the test set.
5. Conclusions and Future Work
In this study, ground base measurements of pollutants, meteorological, and predictive data from CMAQ models are concatenated after analyzing the dependent features that affect the concentration of PM. We estimate the hourly values of PM concentration by applying various well-known machine learning models. In our network training process, we input these features to ML models in order to get next 1 h prediction, while the past 24 h data are provided. Due to spatial and temporal constraints, each station gives different prediction results, therefore, average evaluation values are calculated for all sites. The results show that a well-optimized LSTM network performs better than any other models used in the study. Although ML models and specifically RNNs have the ability to map temporal features, it is very important to analyze the data first, which is then followed by optimizing the model. The advantages of pollutants forecasting using ML models include:
The time, effort, and cost to collect and measure the data from ground based stations or from any other sensors are reduced.
In the case of any defect or failure of measuring equipment or sensors, there would be missing data that can be generated by ML models in limited resources and time using past data.
As other pollutants such as NO, ozone, and PM are also correlated with the concentration of PM, ML models can predict their values as well.
In a nutshell, ML models can be applied in the development of forecasting systems, especially in weather and pollutants concentration predictions. In the future, we will try to overcome the limitations discussed in
Section 4 to get better forecasting results.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}