Unsupervised Deep Learning-Based RGB-D Visual Odometry


Abstract
:1. Introduction
2. Relate Works
3. The Proposed Approach
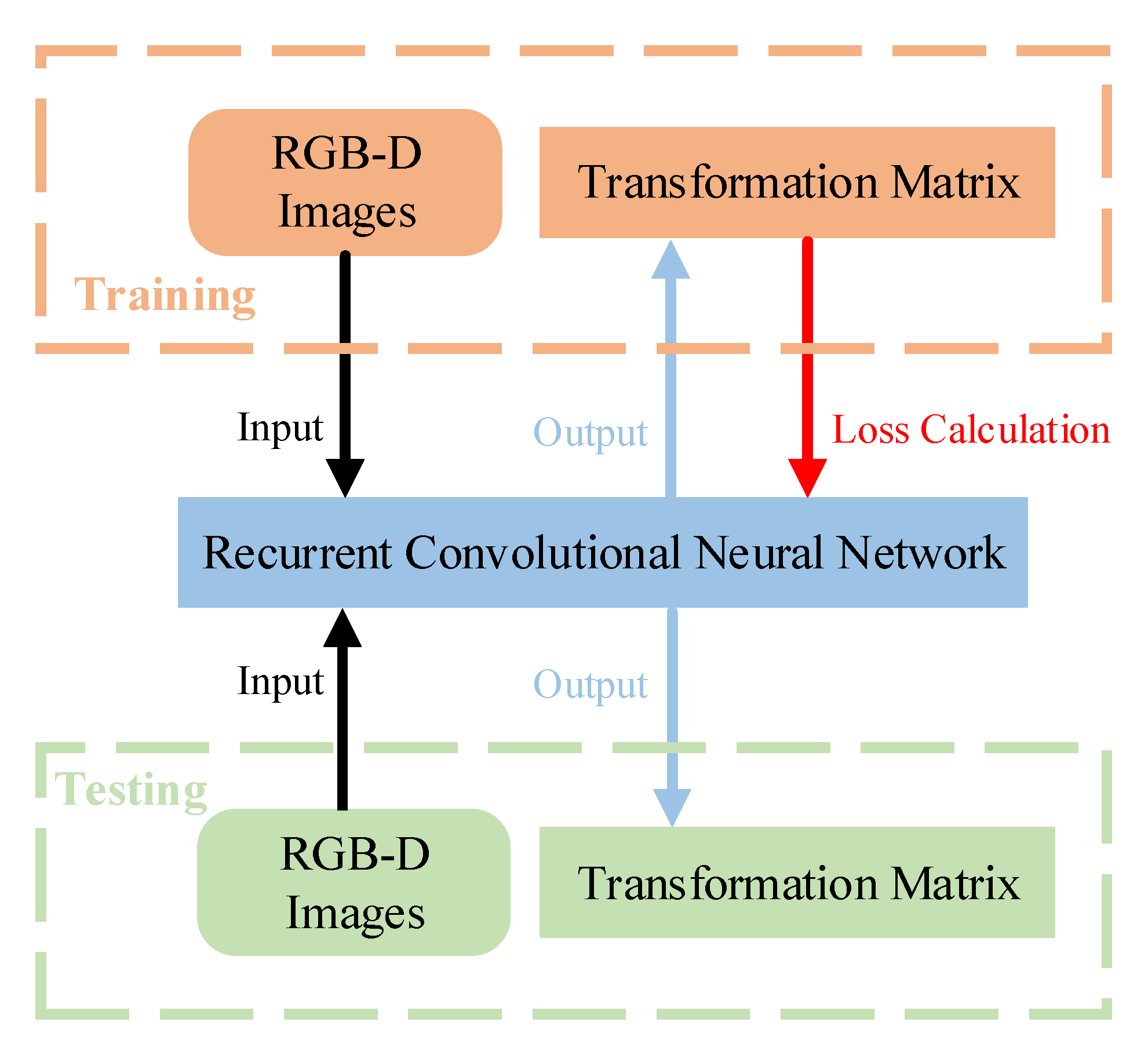
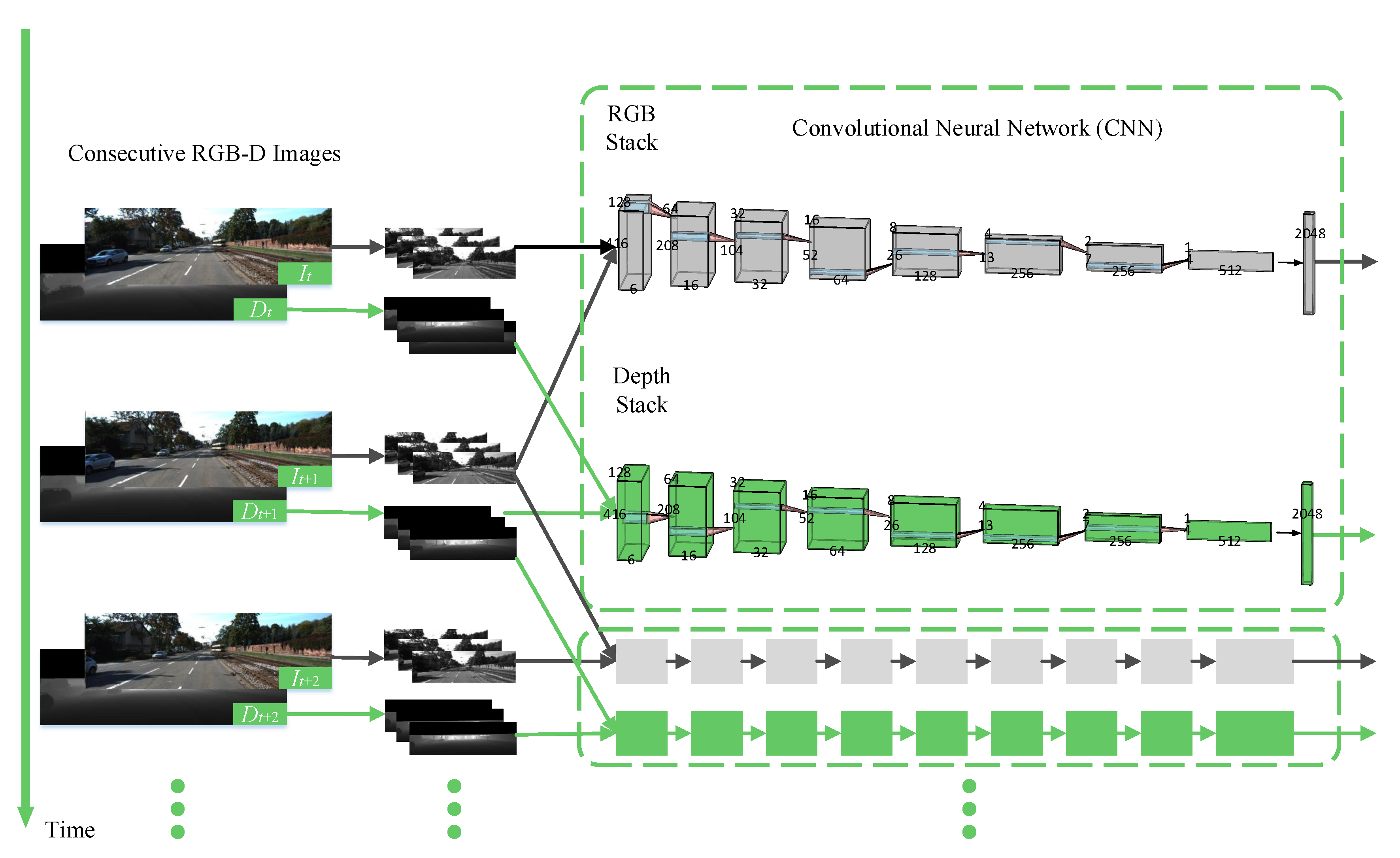
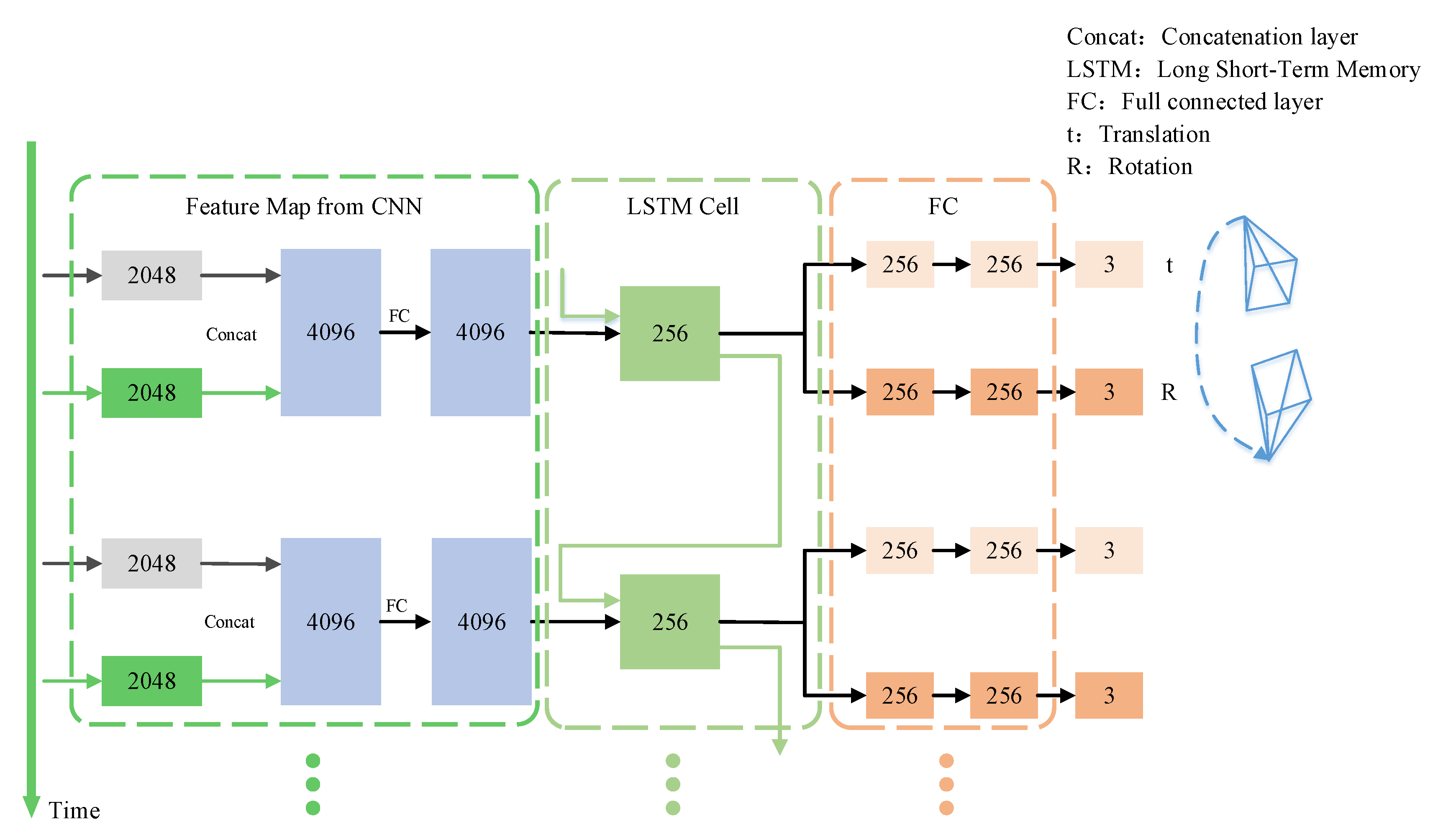
3.1. System Architecture
3.2. Loss Function
| Algorithm 1: Implementation of the RCNN and loss functions. |
 |
3.2.1. 2D Spatial Loss
3.2.2. 3D Spatial Loss
4. Experiments
4.1. Training
- We randomly adjusted the RGB image brightness by gamma adjustment, and the value range of the encoding/decoding gamma value is . Depth images were not processed.
- We randomly adjusted the size of image pairs. The scale factors of the x and y axes are .
- Based on the center of an image, the image pairs were randomly rotated, and the rotation angle degrees.
- Based on the image center, the excess part of image was removed and the missing part was interpolated. Finally the image size were adjusted to .
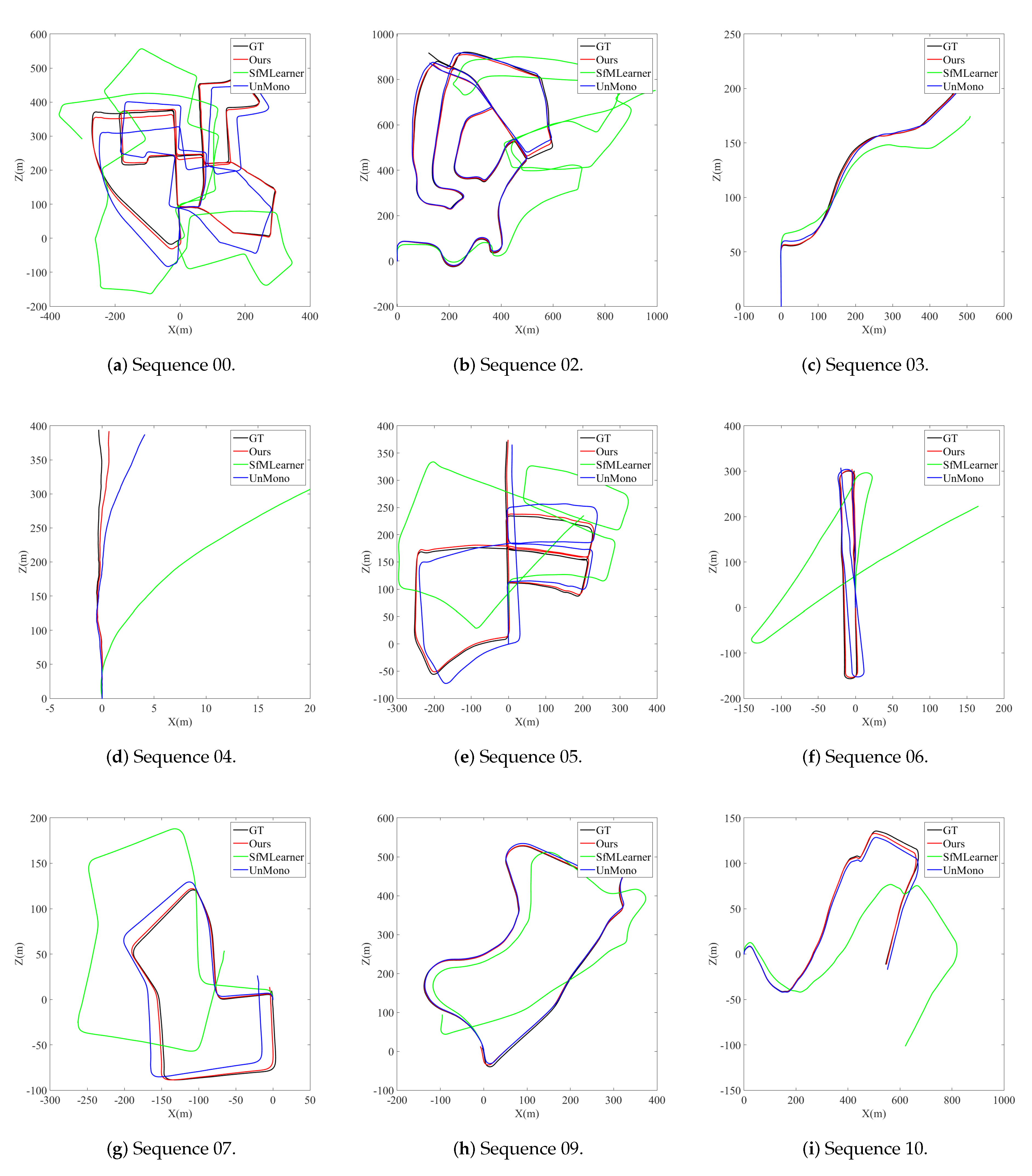
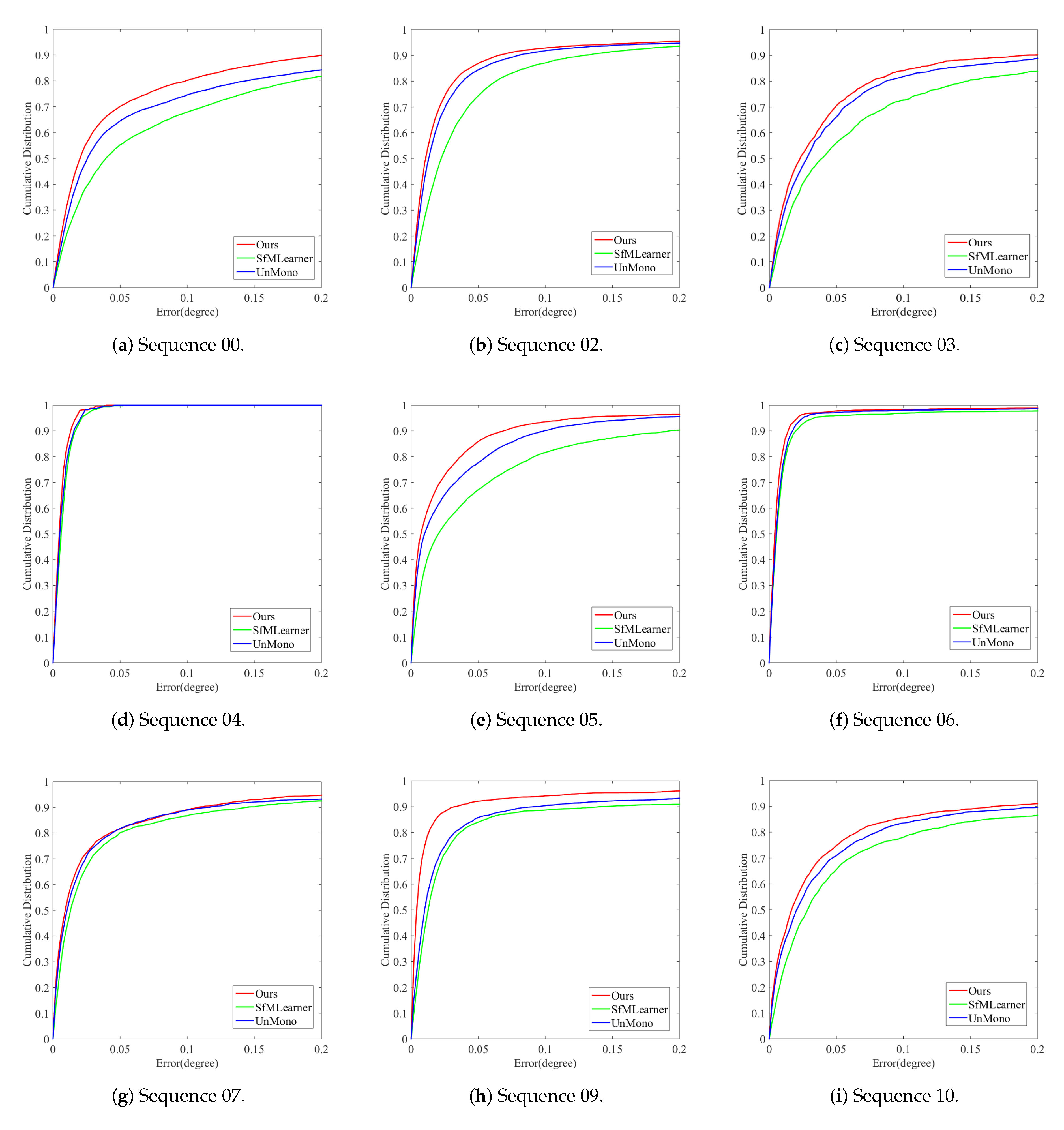
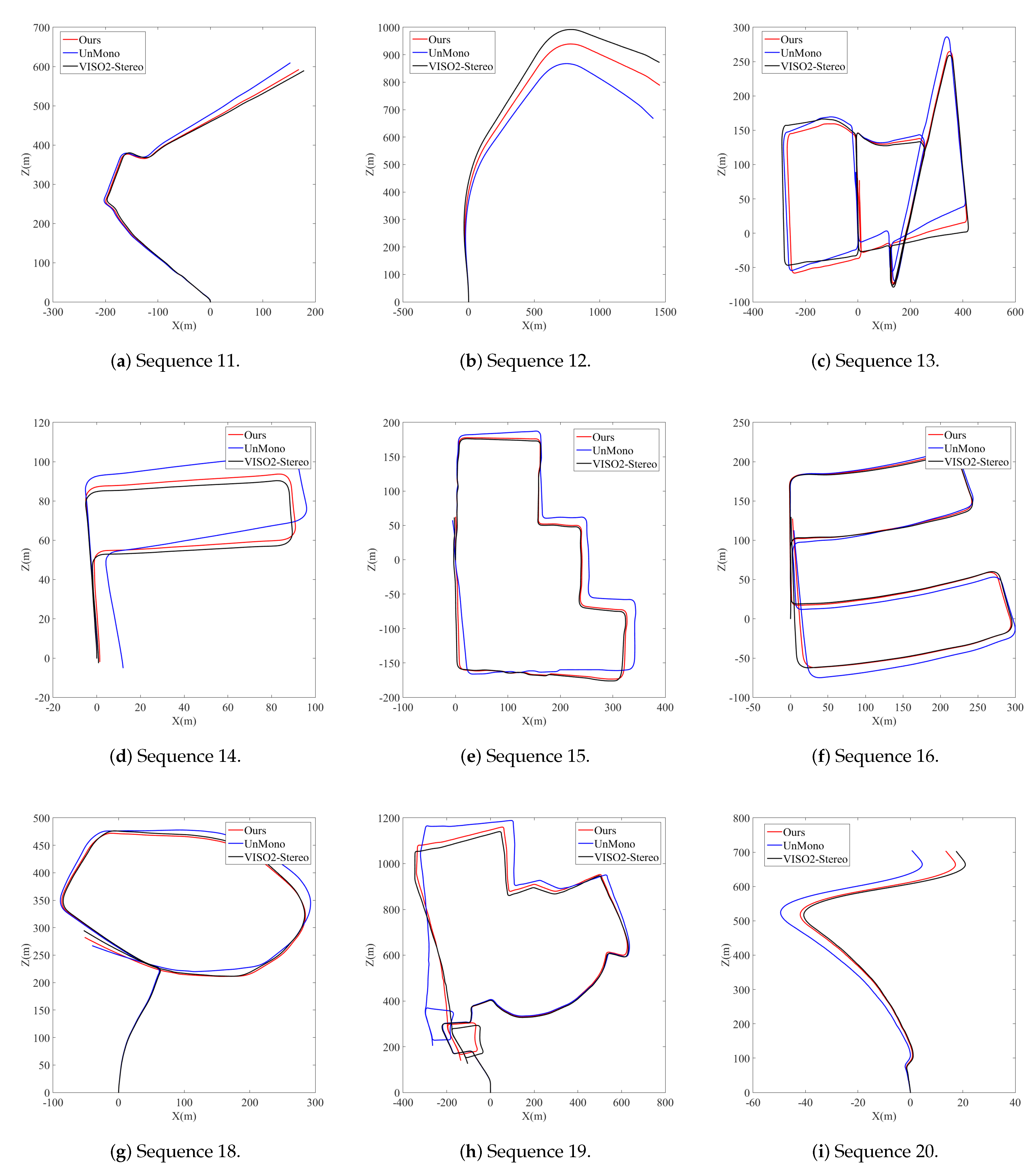
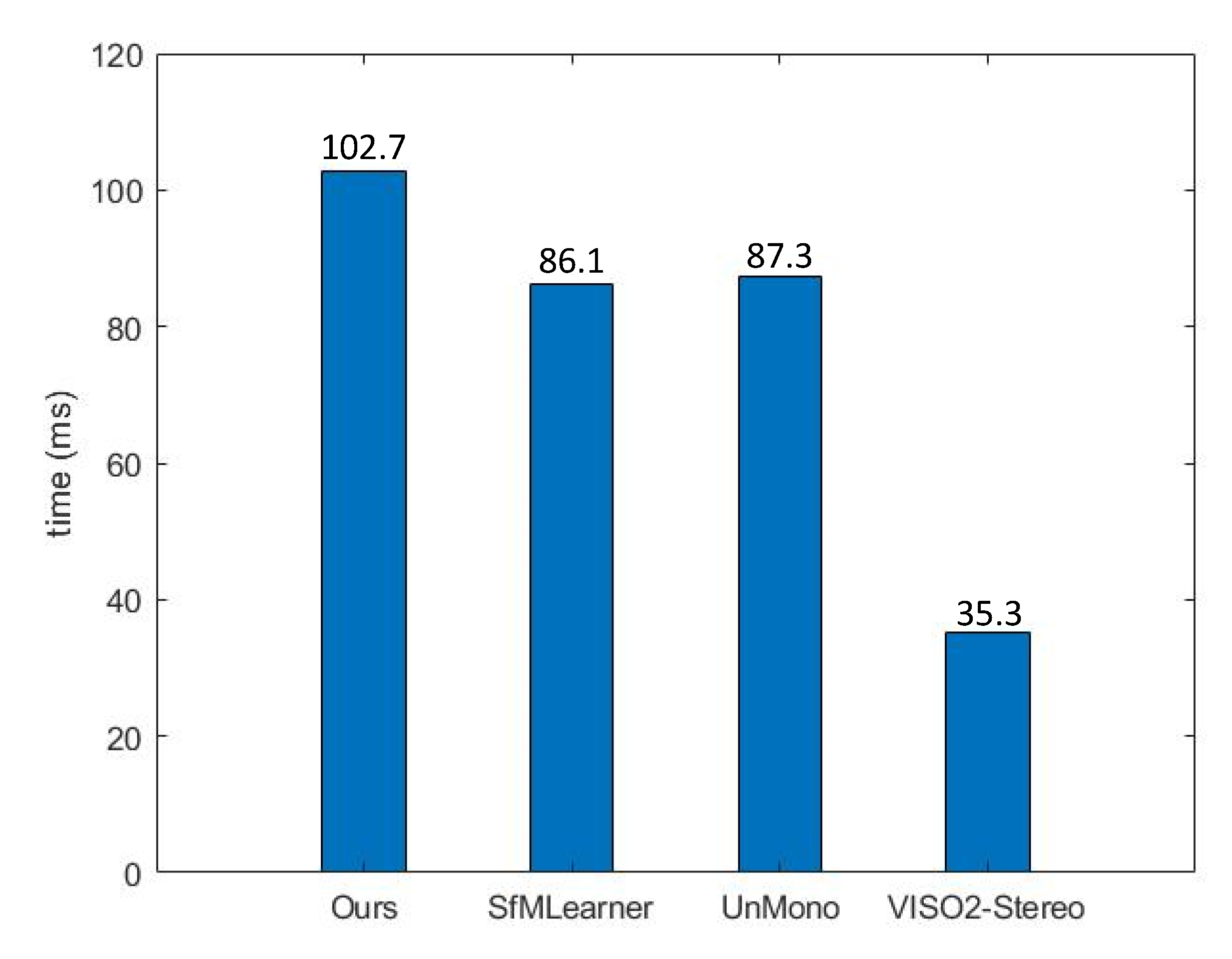
4.2. Performance Evaluation
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nister, D.; Naroditsky, O.; Bergen, J. Visual odometry. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Mukhopadhyay, S.C. Wearable Sensors for Human Activity Monitoring: A Review. IEEE Sens. J. 2015, 15, 1321–1330. [Google Scholar] [CrossRef]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. End-to-end, sequence-tosequence probabilistic visual odometry through deep neural networks. Int. J. Robot. Res. 2017, 37, 513–542. [Google Scholar] [CrossRef]
- Kendall, A.; Cipolla, R. Modelling uncertainty in deep learning for camera relocalization. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 4762–4769. [Google Scholar]
- Kendall, A.; Cipolla, R. Geometric Loss Functions for Camera Pose Regression with Deep Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017; pp. 6555–6564. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6612–6619. [Google Scholar]
- Li, R.; Wang, S.; Long, Z.; Gu, D. UnDeepVO: Monocular Visual Odometry Through Unsupervised Deep Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7286–7291. [Google Scholar]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5667–5675. [Google Scholar]
- Liu, Q.; Li, R.; Hu, H.; Gu, D. Using Unsupervised Deep Learning Technique for Monocular Visual Odometry. IEEE Access 2019, 7, 18076–18088. [Google Scholar] [CrossRef]
- Kitt, B.; Geiger, A.; Lategahn, H. Visual odometry based on stereo image sequences with RANSAC-based outlier rejection scheme. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010; pp. 486–492. [Google Scholar]
- Oskiper, T.; Zhu, Z.; Samarasekera, S.; Kumar, R. Visual Odometry System Using Multiple Stereo Cameras and Inertial Measurement Unit. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Gamallo, C.; Mucientes, M.; Regueiro, C.V. Omnidirectional visual SLAM under severe occlusions. Robot. Auton. Syst. 2015, 65, 76–87. [Google Scholar] [CrossRef]
- Wang, R.; Schwörer, M.; Cremers, D. Stereo DSO: Large-Scale Direct Sparse Visual Odometry with Stereo Cameras. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3923–3931. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2100–2106. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Whelan, T.; Kaess, M.; Johannsson, H.; Fallon, M.; Leonard, J.J.; McDonald, J. Real-time large-scale dense RGB-D SLAM with volumetric fusion. Int. J. Robot. Res. 2015, 34, 598–626. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Engel, J.; Sturm, J.; Cremers, D. Semi-dense Visual Odometry for a Monocular Camera. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1449–1456. [Google Scholar]
- Howard, A. Real-time stereo visual odometry for autonomous ground vehicles. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3946–3952. [Google Scholar]
- Tardif, J.; Pavlidis, Y.; Daniilidis, K. Monocular visual odometry in urban environments using an omnidirectional camera. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 2531–2538. [Google Scholar]
- Khan, F.; Salahuddin, S.; Javidnia, H. Deep Learning-Based Monocular Depth Estimation Methods—A State-of-the-Art Review. Sensors 2020, 20, 2272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kneip, L.; Chli, M.; Siegwart, R.Y. Robust real-time visual odometry with a single camera and an IMU. In Proceedings of the Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011. [Google Scholar]
- Zhang, J.; Singh, S. Visual-lidar odometry and mapping: Low-drift, robust, and fast. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 2174–2181. [Google Scholar]
- Debeunne, C.; Vivet, D. A Review of Visual-LiDAR Fusion based Simultaneous Localization and Mapping. Sensors 2020, 20, 2068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ottonelli, S.; Spagnolo, P.; Mazzeo, P.L.; Leo, M. Improved video segmentation with color and depth using a stereo camera. In Proceedings of the 2013 IEEE International Conference on Industrial Technology (ICIT), Cape Town, South Africa, 25–28 February 2013; pp. 1134–1139. [Google Scholar] [CrossRef]
- Carfagni, M.; Furferi, R.; Governi, L.; Servi, M.; Uccheddu, F.; Volpe, Y. On the Performance of the Intel SR300 Depth Camera: Metrological and Critical Characterization. IEEE Sens. J. 2017, 17, 4508–4519. [Google Scholar] [CrossRef] [Green Version]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGB-D mapping: Using Kinect-style depth cameras for dense 3D modeling of indoor environments. Int. J. Robot. Res. 2012, 31, 647–663. [Google Scholar] [CrossRef] [Green Version]
- Huang, A.S.; Bachrach, A.; Henry, P.; Krainin, M.; Maturana, D.; Fox, D.; Roy, N. Visual odometry and mapping for autonomous flight using an RGB-D camera. In Robotics Research; Springer: Berlin/Heidelberg, Germany, 2017; pp. 235–252. [Google Scholar]
- Steinbrücker, F.; Sturm, J.; Cremers, D. Real-time visual odometry from dense RGB-D images. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 719–722. [Google Scholar]
- Sünderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B.; Milford, M. On the performance of ConvNet features for place recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 4297–4304. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Li, R.; Liu, Q.; Gui, J.; Gu, D.; Hu, H. Indoor Relocalization in Challenging Environments With Dual-Stream Convolutional Neural Networks. IEEE Trans. Autom. Sci. Eng. 2018, 15, 651–662. [Google Scholar] [CrossRef]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. DeepVO: Towards end-to-end visual odometry with deep Recurrent Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Marina Bay Sands, Singapore, 29 May–3 June 2017; pp. 2043–2050. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kawakami, K. Supervised Sequence Labelling With Recurrent Neural Networks. Ph.D. Thesis, Technical University of Munich, München, Germany, 2008. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: London, UK, 2015; pp. 2017–2025. [Google Scholar]
- Chen, Y.; Medioni, G. Object modelling by registration of multiple range images. Image Vis. Comput. 1992, 10, 145–155. [Google Scholar] [CrossRef]
- Geiger, A.; Ziegler, J.; Stiller, C. StereoScan: Dense 3d reconstruction in real-time. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 963–968. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Conv1 | Conv2 | Conv3 | Conv4 | Conv5 | Conv6 | Conv7 |
|---|---|---|---|---|---|---|---|
| Filter Size | |||||||
| Stride | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Padding | 3 | 2 | 1 | 1 | 1 | 1 | 1 |
| Channel Number | 16 | 32 | 64 | 128 | 256 | 256 | 512 |
| SfMLearner | UnMono | VISO2-Stereo | Ours | |||||
|---|---|---|---|---|---|---|---|---|
| Monocular | Monocular | Stereo | RGB-D | |||||
| Unsupervised | Unsupervised | Feature Based | Unsupervised | |||||
| Seq. | ||||||||
| 00 | 45.89 | 6.23 | 5.14 | 2.13 | 1.86 | 0.58 | 2.97 | 1.53 |
| 02 | 57.59 | 4.09 | 4.88 | 2.26 | 2.01 | 0.40 | 1.83 | 1.71 |
| 03 | 13.08 | 3.79 | 6.03 | 1.83 | 3.21 | 0.73 | 3.21 | 1.15 |
| 04 | 10.86 | 5.13 | 2.15 | 0.89 | 2.12 | 0.24 | 0.94 | 0.57 |
| 05 | 16.76 | 4.06 | 3.84 | 1.29 | 1.53 | 0.53 | 2.31 | 1.03 |
| 06 | 23.53 | 4.80 | 4.64 | 1.21 | 1.48 | 0.30 | 1.25 | 0.80 |
| 07 | 17.52 | 5.38 | 3.80 | 1.71 | 1.85 | 0.78 | 1.47 | 1.31 |
| 08 | 24.02 | 3.06 | 2.95 | 1.58 | 1.92 | 0.55 | 1.91 | 1.20 |
| 09 | 22.27 | 3.62 | 5.59 | 2.57 | 1.99 | 0.53 | 1.86 | 0.50 |
| 10 | 14.36 | 3.98 | 4.76 | 2.95 | 1.17 | 0.43 | 1.15 | 1.17 |
| mean | 24.59 | 4.41 | 4.38 | 1.84 | 1.91 | 0.51 | 1.89 | 1.10 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Zhang, H.; Xu, Y.; Wang, L. Unsupervised Deep Learning-Based RGB-D Visual Odometry. Appl. Sci. 2020, 10, 5426. https://doi.org/10.3390/app10165426
Liu Q, Zhang H, Xu Y, Wang L. Unsupervised Deep Learning-Based RGB-D Visual Odometry. Applied Sciences. 2020; 10(16):5426. https://doi.org/10.3390/app10165426
Chicago/Turabian StyleLiu, Qiang, Haidong Zhang, Yiming Xu, and Li Wang. 2020. "Unsupervised Deep Learning-Based RGB-D Visual Odometry" Applied Sciences 10, no. 16: 5426. https://doi.org/10.3390/app10165426