Deep Reinforcement Learning with Interactive Feedback in a Human–Robot Environment


 , , and
, , and
Abstract
:1. Introduction
2. Related Works
2.1. Deep Reinforcement Learning and Interactive Feedback
- –
- S is a finite set of system states, ;
- –
- A is a finite set of actions, , and is a finite set of actions available in at time t;
- –
- is the transition function ;
- –
- r is the immediate reward (or reinforcement) function .
2.2. Vision-Based Object Sorting with Robots
2.3. Scientific Contribution
3. Materials and Methods
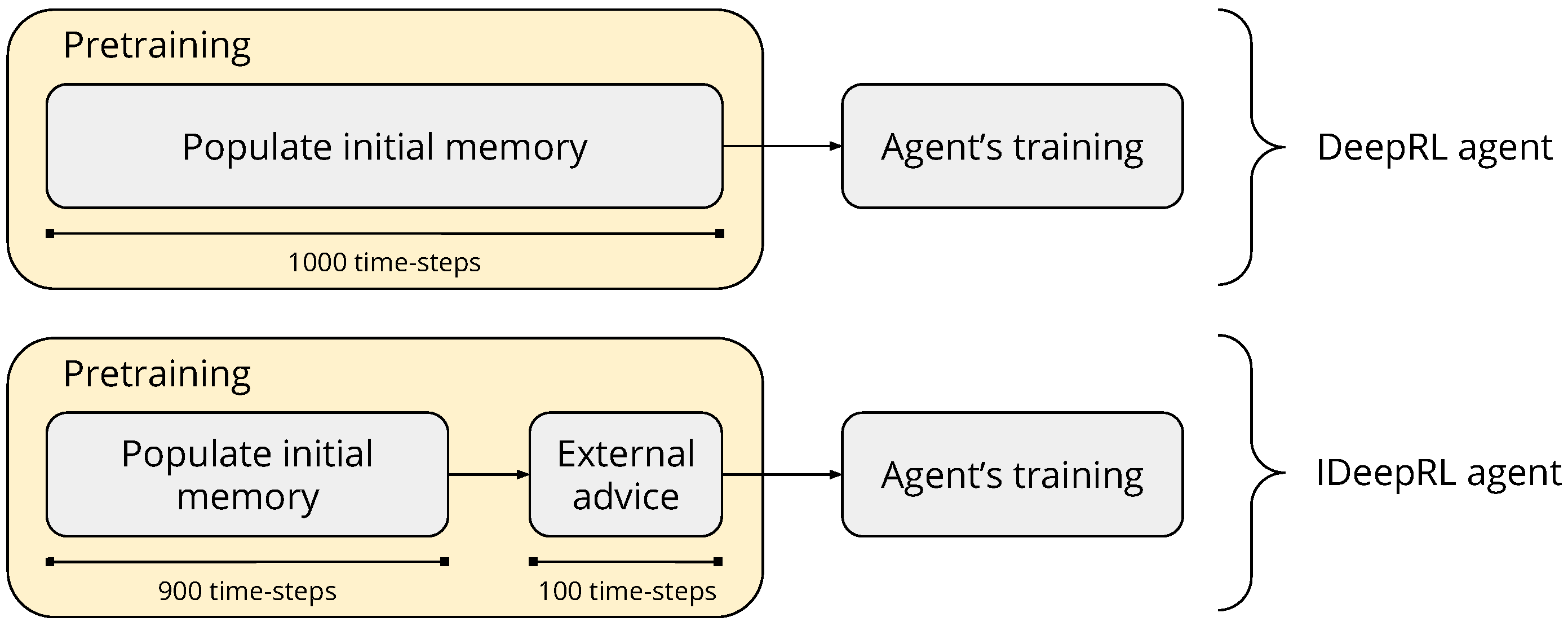
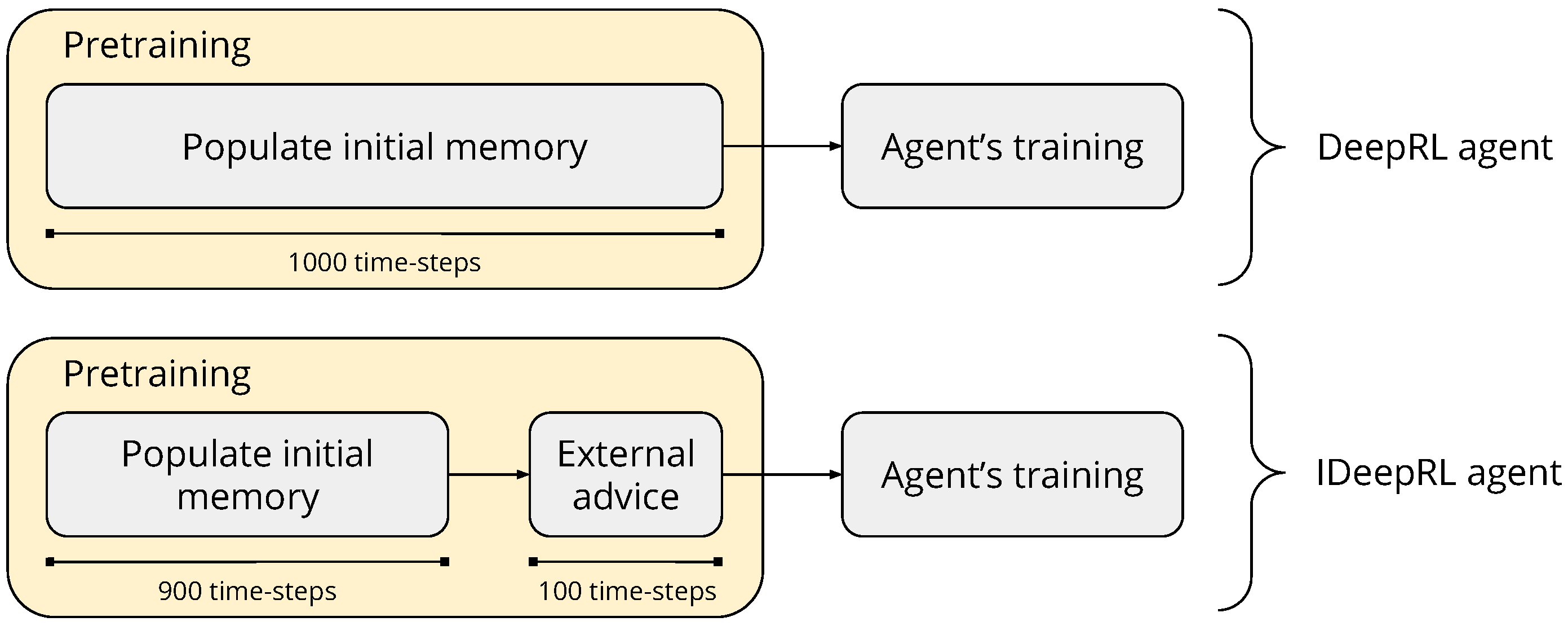
3.1. Methodology and Implementation of the Agents
- i
- DeepRL: where the agent interacts autonomously with the environment;
- ii
- agent–IDeepRL: where the DeepRL approach is complemented with a previously trained artificial agent to give advice; and
- iii
- human–IDeepRL: where the DeepRL approach is complemented with a human trainer.
| Algorithm 1 Pretraining algorithm to populate the batch memory including interactive feedback. |
|
| Algorithm 2 Training algorithm to populate and extract information from the batch memory. |
|
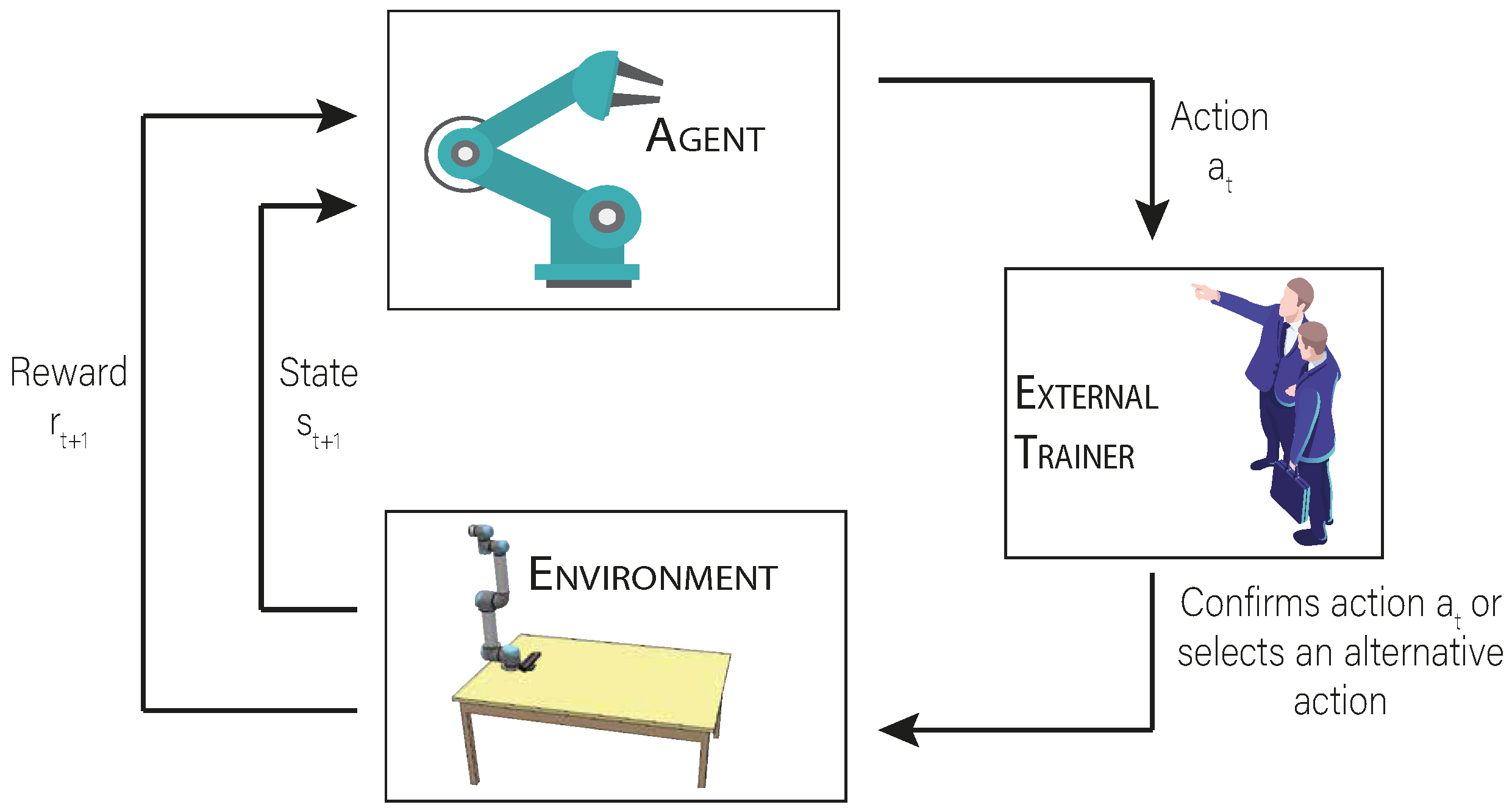
3.1.1. Interactive Approach
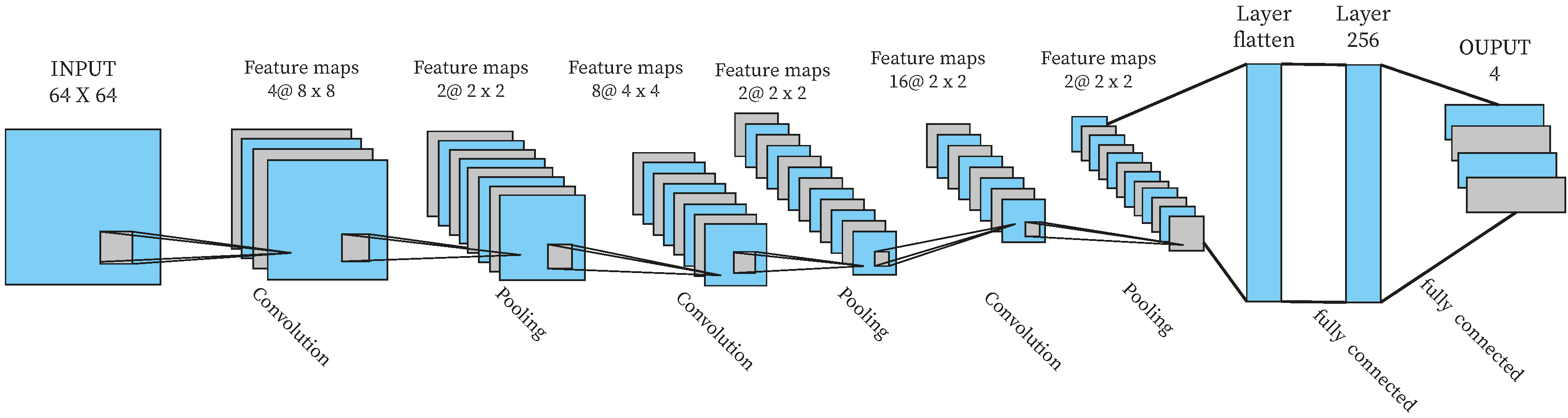
3.1.2. Visual Representation
3.1.3. Continuous Representation
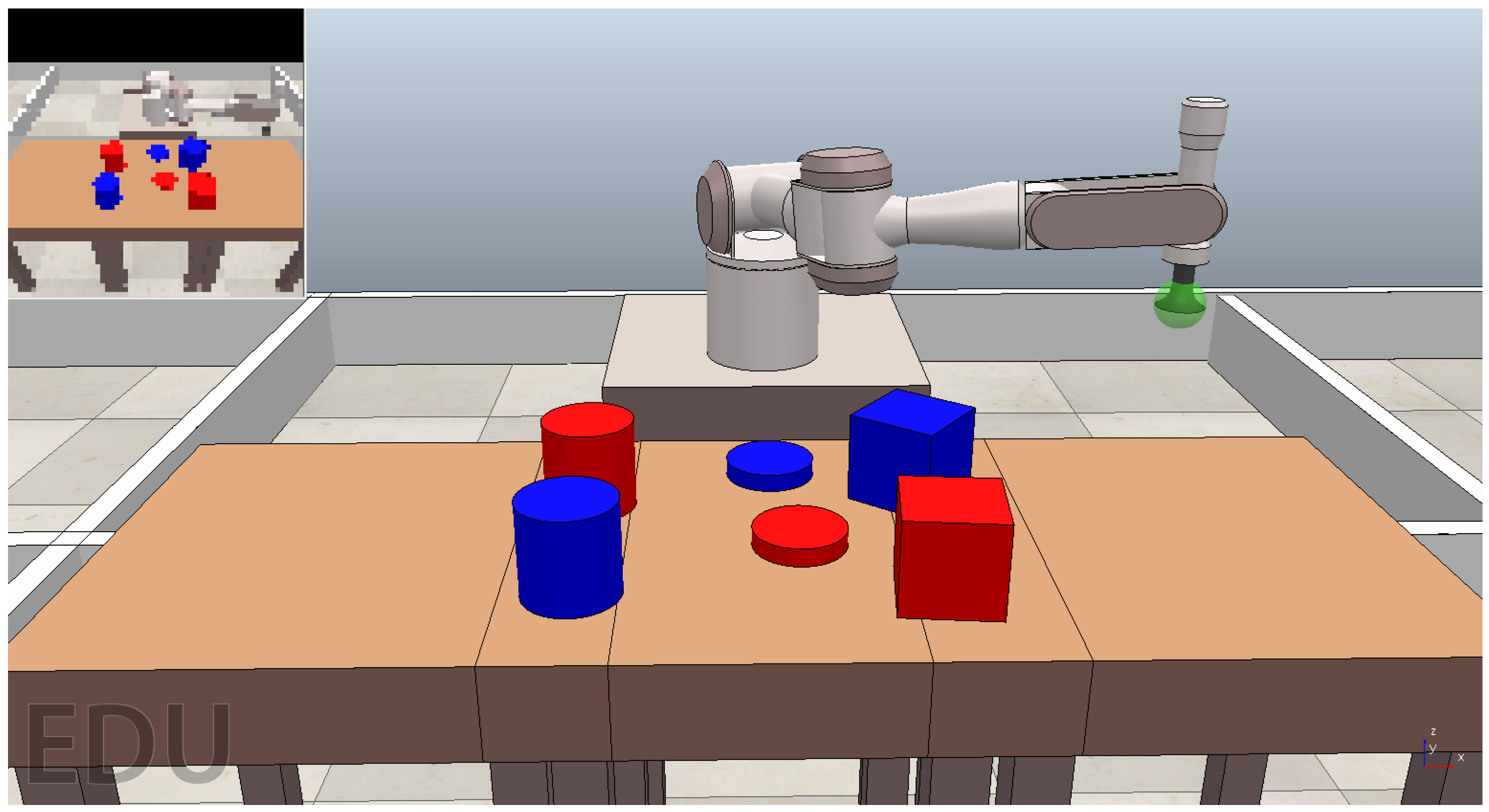
3.2. Experimental Setup
3.2.1. Actions and State Representation
- i
- Grab object: the agent grabs randomly one of the objects with the suction cup grip.
- ii
- Move right: the robotic arm is moved to the table on the right side of the scenario; if the arm is already there, do nothing.
- iii
- Move left: the robotic arm is moved to the table on the left side of the scenario; if the arm is already there, do nothing.
- iv
- Drop: if the robotic arm has an object in the grip and is located in one of the side tables, the arm goes down and releases the object; in case the arm is positioned in the center, the arm keeps the position.
3.2.2. Reward
3.2.3. Human Interaction
- i
- The user reads an introduction to the scenario and the experiment, as well as the expected results.
- ii
- The user is given an explanation about the problem and how it can be solved.
- iii
- The user is taught how to use the computer interface to advise actions to the learner agent.
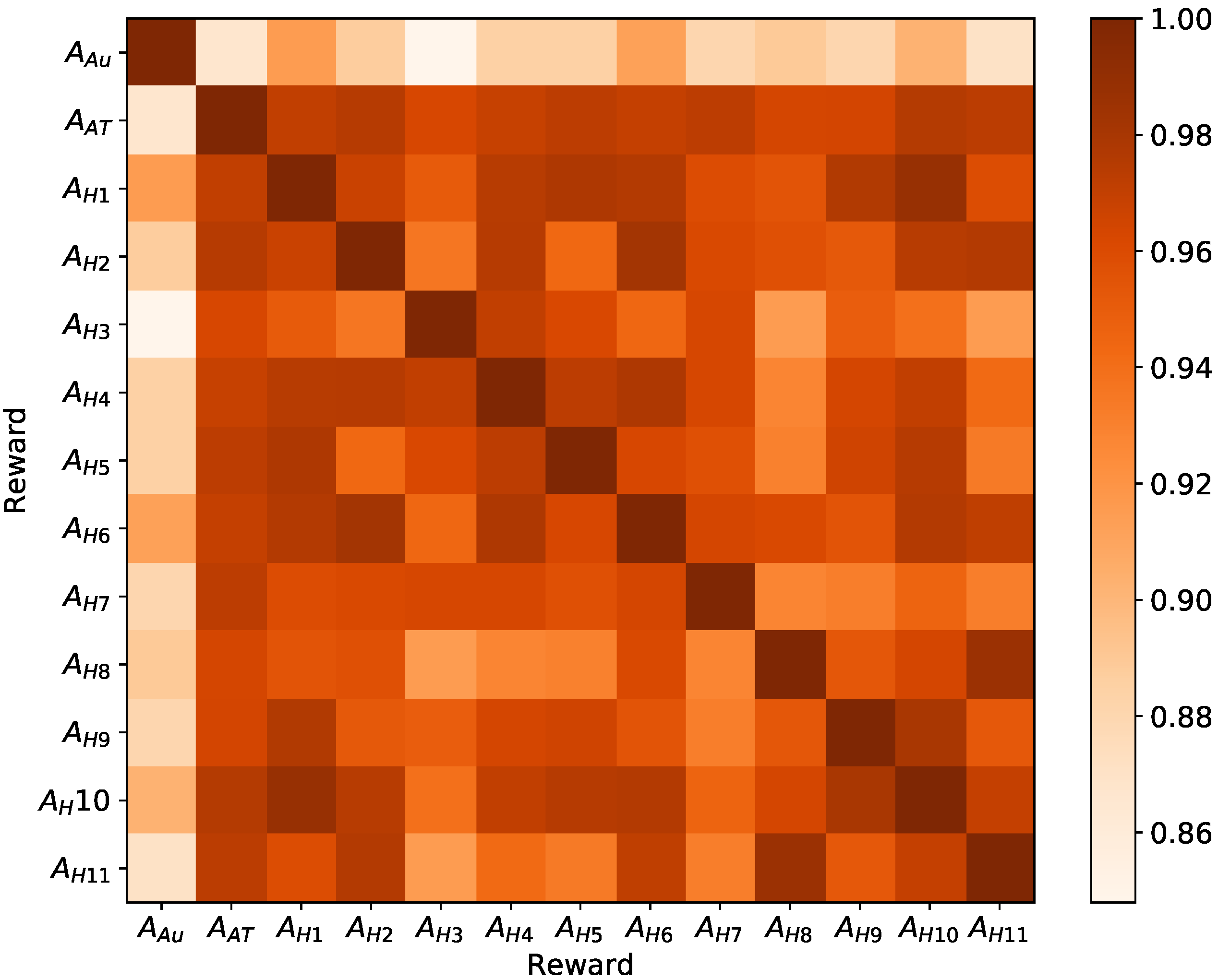
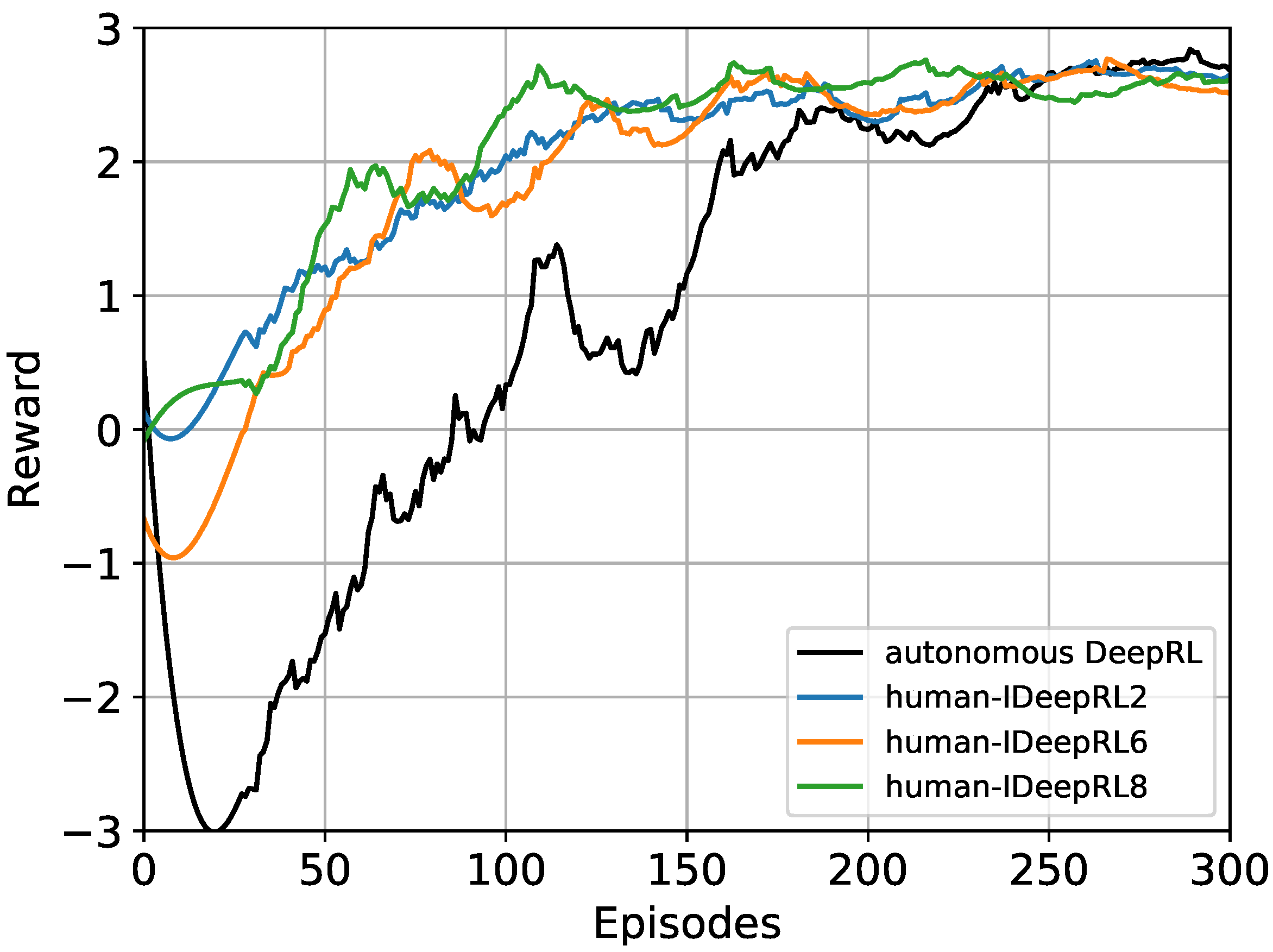
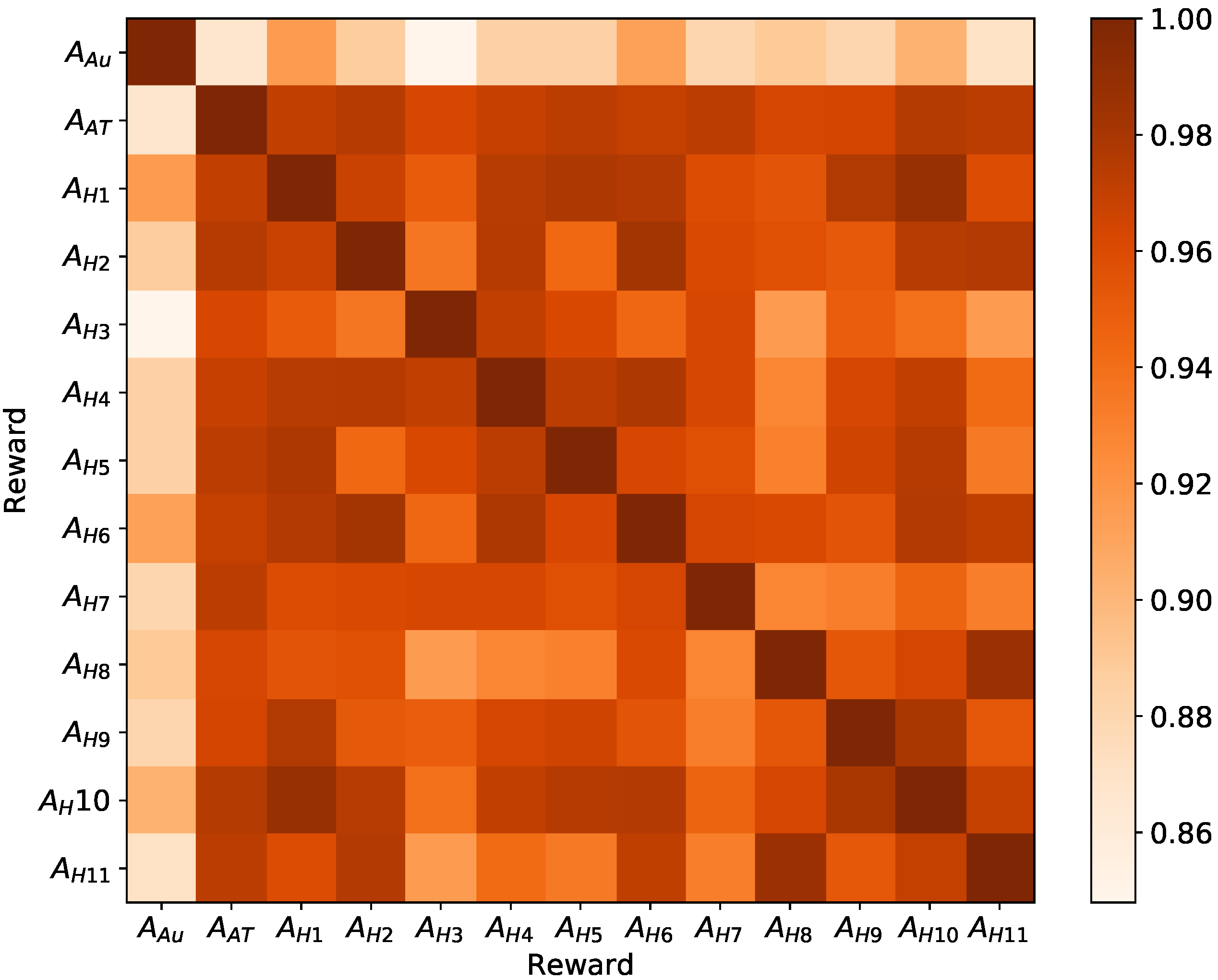
4. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shepherd, S.; Buchstab, A. Kuka robots on-site. In Robotic Fabrication in Architecture, Art and Design 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 373–380. [Google Scholar]
- Cruz, F.; Wüppen, P.; Fazrie, A.; Weber, C.; Wermter, S. Action selection methods in a robotic reinforcement learning scenario. In Proceedings of the 2018 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Gudalajara, Mexico, 7–9 November 2018; pp. 13–18. [Google Scholar]
- Goodrich, M.A.; Schultz, A.C. Human–robot interaction: A survey. Found. Trends® Hum.-Interact. 2008, 1, 203–275. [Google Scholar] [CrossRef]
- Churamani, N.; Cruz, F.; Griffiths, S.; Barros, P. iCub: Learning emotion expressions using human reward. arXiv 2020, arXiv:2003.13483. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Niv, Y. Reinforcement learning in the brain. J. Math. Psychol. 2009, 53, 139–154. [Google Scholar] [CrossRef] [Green Version]
- Cruz, F.; Parisi, G.I.; Wermter, S. Multi-modal feedback for Affordance-driven interactive reinforcement learning. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Bignold, A.; Cruz, F.; Taylor, M.E.; Brys, T.; Dazeley, R.; Vamplew, P.; Foale, C. A conceptual framework for externally-influenced agents: An assisted reinforcement learning review. arXiv 2020, arXiv:2007.01544. [Google Scholar]
- Ayala, A.; Henríquez, C.; Cruz, F. Reinforcement learning using continuous states and interactive feedback. In Proceedings of the International Conference on Applications of Intelligent Systems, Las Palmas de Gran Canaria, Spain, 7–12 January 2019; pp. 1–5. [Google Scholar]
- Millán, C.; Fernandes, B.; Cruz, F. Human feedback in continuous actor-critic reinforcement learning. In Proceedings of the 27th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning ESANN, Bruges, Belgium, 24–26 April 2019; pp. 661–666. [Google Scholar]
- Barros, P.; Tanevska, A.; Cruz, F.; Sciutti, A. Moody Learners—Explaining Competitive Behaviour of Reinforcement Learning Agents. arXiv 2020, arXiv:2007.16045. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Twenty-sixth Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; Wiley: Hoboken, NJ, USA, 1994. [Google Scholar]
- Suay, H.B.; Chernova, S. Effect of human guidance and state space size on interactive reinforcement learning. In Proceedings of the International Symposium on Robot and Human Interaction Communication (Ro-Man), Atlanta, GA, USA, 31 July–3 August 2011; pp. 1–6. [Google Scholar]
- Najar, A.; Chetouani, M. Reinforcement learning with human advice. A survey. arXiv 2020, arXiv:2005.11016. [Google Scholar]
- Ng, A.Y.; Harada, D.; Russell, S. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the Sixteenth International Conference on Machine Learning (ICML), Bled, Slovenia, 27–30 June 1999; Volume 99, pp. 278–287. [Google Scholar]
- Brys, T.; Nowé, A.; Kudenko, D.; Taylor, M.E. Combining multiple correlated reward and shaping signals by measuring confidence. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 1687–1693. [Google Scholar]
- Griffith, S.; Subramanian, K.; Scholz, J.; Isbell, C.; Thomaz, A.L. Policy shaping: Integrating human feedback with reinforcement learning. In Proceedings of the Twenty-seventh Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2625–2633. [Google Scholar]
- Li, G.; Gomez, R.; Nakamura, K.; He, B. Human-centered reinforcement learning: A survey. IEEE Trans. Hum.-Mach. Syst. 2019, 49, 337–349. [Google Scholar] [CrossRef]
- Grizou, J.; Lopes, M.; Oudeyer, P.Y. Robot learning simultaneously a task and how to interpret human instructions. In Proceedings of the 2013 IEEE Third Joint International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Osaka, Japan, 18–22 August 2013; pp. 1–8. [Google Scholar]
- Navidi, N. Human AI interaction loop training: New approach for interactive reinforcement learning. arXiv 2020, arXiv:2003.04203. [Google Scholar]
- Bignold, A. Rule-Based Interactive Assisted Reinforcement Learning. Ph.D. Thesis, Federation University, Ballarat, Australia, 2019. [Google Scholar]
- Taylor, M.E.; Carboni, N.; Fachantidis, A.; Vlahavas, I.; Torrey, L. Reinforcement learning agents providing advice in complex video games. Connect. Sci. 2014, 26, 45–63. [Google Scholar] [CrossRef]
- Cruz, F.; Magg, S.; Nagai, Y.; Wermter, S. Improving interactive reinforcement learning: What makes a good teacher? Connect. Sci. 2018, 30, 306–325. [Google Scholar] [CrossRef]
- Dobrovsky, A.; Borghoff, U.M.; Hofmann, M. Improving adaptive gameplay in serious games through interactive deep reinforcement learning. In Cognitive Infocommunications, Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 411–432. [Google Scholar]
- Rajeswaran, A.; Kumar, V.; Gupta, A.; Vezzani, G.; Schulman, J.; Todorov, E.; Levine, S. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. arXiv 2017, arXiv:1709.10087. [Google Scholar]
- Lukka, T.J.; Tossavainen, T.; Kujala, J.V.; Raiko, T. ZenRobotics recycler–Robotic sorting using machine learning. In Proceedings of the International Conference on Sensor-Based Sorting (SBS), Aachen, Germany, 11–13 March 2014. [Google Scholar]
- Zhihong, C.; Hebin, Z.; Yanbo, W.; Binyan, L.; Yu, L. A vision-based robotic grasping system using deep learning for garbage sorting. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 11223–11226. [Google Scholar]
- Sun, L.; Aragon-Camarasa, G.; Rogers, S.; Stolkin, R.; Siebert, J.P. Single-shot clothing category recognition in free-configurations with application to autonomous clothes sorting. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 6699–6706. [Google Scholar]
- Cruz, F.; Magg, S.; Weber, C.; Wermter, S. Improving reinforcement learning with interactive feedback and affordances. In Proceedings of the 4th International Conference on Development and Learning and on Epigenetic Robotics (ICDL-EpiRob), Genoa, Italy, 13–16 October 2014; pp. 165–170. [Google Scholar]
- Cruz, F.; Parisi, G.I.; Wermter, S. Learning contextual affordances with an associative neural architecture. In Proceedings of the 24th European Symposium on Artificial Neural Network, Computational Intelligence and Machine Learning ESANN, Bruges, Belgium, 27–29 April 2016; pp. 665–670. [Google Scholar]
- Zhang, F.; Leitner, J.; Milford, M.; Upcroft, B.; Corke, P. Towards vision-based deep reinforcement learning for robotic motion control. arXiv 2015, arXiv:1511.03791. [Google Scholar]
- Vecerik, M.; Hester, T.; Scholz, J.; Wang, F.; Pietquin, O.; Piot, B.; Heess, N.; Rothörl, T.; Lampe, T.; Riedmiller, M. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards. arXiv 2017, arXiv:1707.08817. [Google Scholar]
- Desai, N.; Banerjee, A. Deep Reinforcement Learning to Play Space Invaders; Technical Report; Stanford University: Stanford, CA, USA, 2017. [Google Scholar]
- Adam, S.; Busoniu, L.; Babuska, R. Experience replay for real-time reinforcement learning control. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 201–212. [Google Scholar] [CrossRef]
- Cruz, F.; Wüppen, P.; Magg, S.; Fazrie, A.; Wermter, S. Agent-advising approaches in an interactive reinforcement learning scenario. In Proceedings of the 2017 Joint IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Lisbon, Portugal, 18–21 September 2017; pp. 209–214. [Google Scholar]
- Rohmer, E.; Singh, S.P.; Freese, M. V-REP: A versatile and scalable robot simulation framework. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 1321–1326. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| Optimal action-value function | |
| Expected value following policy | |
| Policy to map states to actions | |
| Discount factor | |
| Reward received at time step t | |
| Agent’s state at time step t | |
| Action taken at time step t |
| DeepRL vs. | DeepRL vs. | Agent–IDeepRL vs. |
|---|---|---|
| Agent–IDeepRL | Human–IDeepRL | Human–IDeepRL |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moreira, I.; Rivas, J.; Cruz, F.; Dazeley, R.; Ayala, A.; Fernandes, B. Deep Reinforcement Learning with Interactive Feedback in a Human–Robot Environment. Appl. Sci. 2020, 10, 5574. https://doi.org/10.3390/app10165574
Moreira I, Rivas J, Cruz F, Dazeley R, Ayala A, Fernandes B. Deep Reinforcement Learning with Interactive Feedback in a Human–Robot Environment. Applied Sciences. 2020; 10(16):5574. https://doi.org/10.3390/app10165574
Chicago/Turabian StyleMoreira, Ithan, Javier Rivas, Francisco Cruz, Richard Dazeley, Angel Ayala, and Bruno Fernandes. 2020. "Deep Reinforcement Learning with Interactive Feedback in a Human–Robot Environment" Applied Sciences 10, no. 16: 5574. https://doi.org/10.3390/app10165574
APA StyleMoreira, I., Rivas, J., Cruz, F., Dazeley, R., Ayala, A., & Fernandes, B. (2020). Deep Reinforcement Learning with Interactive Feedback in a Human–Robot Environment. Applied Sciences, 10(16), 5574. https://doi.org/10.3390/app10165574