Matching Consignees/Shippers Recommendation System in Courier Service Using Data Analytics



Abstract
:1. Introduction
2. Literature Review
2.1. Shippers/Consignees Behavior Segmentation
2.2. Association Rule
2.3. Clustering Technique
2.4. Decision Tree
2.5. Monte Carlo Simulation
3. Methodology
3.1. Step 1: Product Association
- (1)
- FP-Growth was used to determine items in the set that have been frequently delivered together in a certain fraction of transactions.
- (2)
- Evaluation of the association rule used Min sup and Min conf thresholds [47] measured by Equations (1) and (2). Thresholds are defined for expected values of minimum revenue.
3.2. Step 2: Shipper/Consignee Clustering
- (1)
- Determining R, F, M, NC, NP, W, and D variables for each shipper and consignee
- (2)
- Correlating variables to investigate relationships
- (3)
- Determining optimal numbers of clusters, with the K-optimal method [62]. The K-means technique was used to cluster a group of Y shippers and X==>Y consignees.
- (4)
- Analyzing different clusters of Y shippers and screening potential X==>Y consignee clusters.
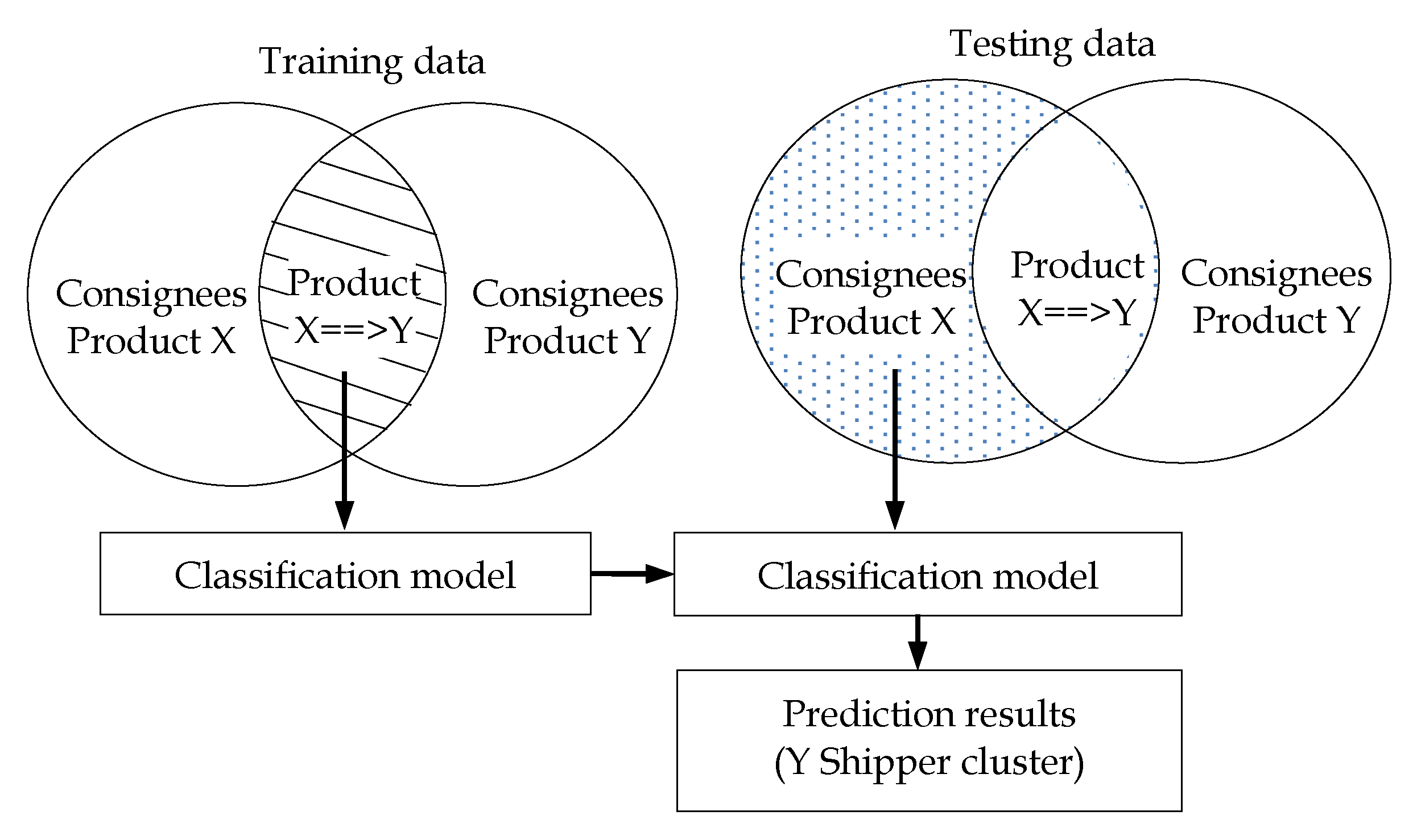
3.3. Step 3: Prediction of Shippers/Consignees Matching
- (1)
- Classification of the delivery behavior of X==>Y consignees and Y shipper clusters through a decision tree algorithm. Predictions of X consignees were used as testing data (Figure 2).
- (2)
- Evaluation of the classification model through 10-fold cross-validation. Accuracy and confidence of rule thresholds were determined for the expected value of minimum revenue in Step 4.
3.4. Step 4: Revenue Simulation
4. Case Study
4.1. The Case and Data Collection
4.2. Implementation
4.2.1. Identifying Potential Products Using Association Rule
4.2.2. Identifying Potential Customers Using Clustering Technique
Variable Analysis
Statistical Correlation Analysis
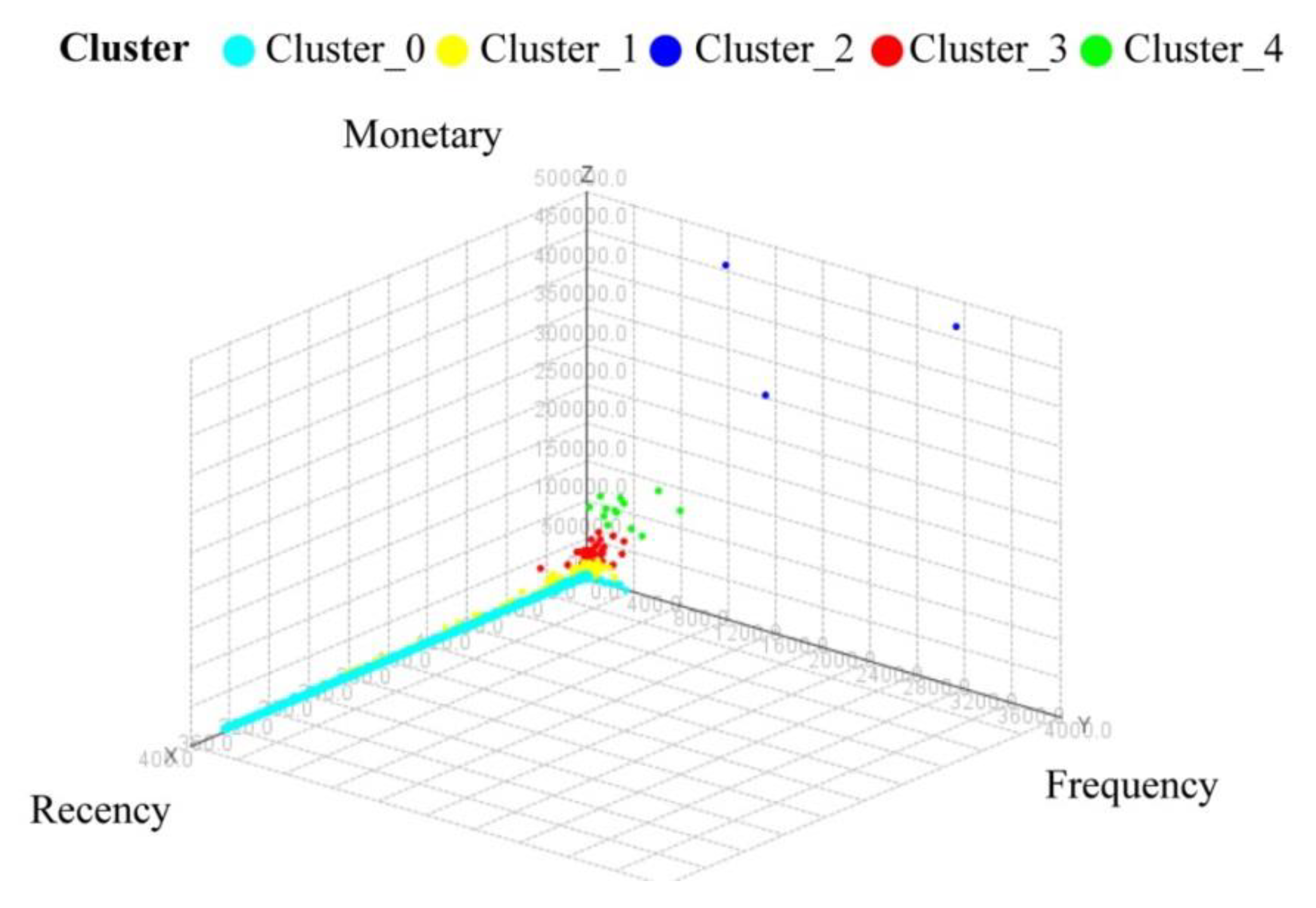
K-means Clustering
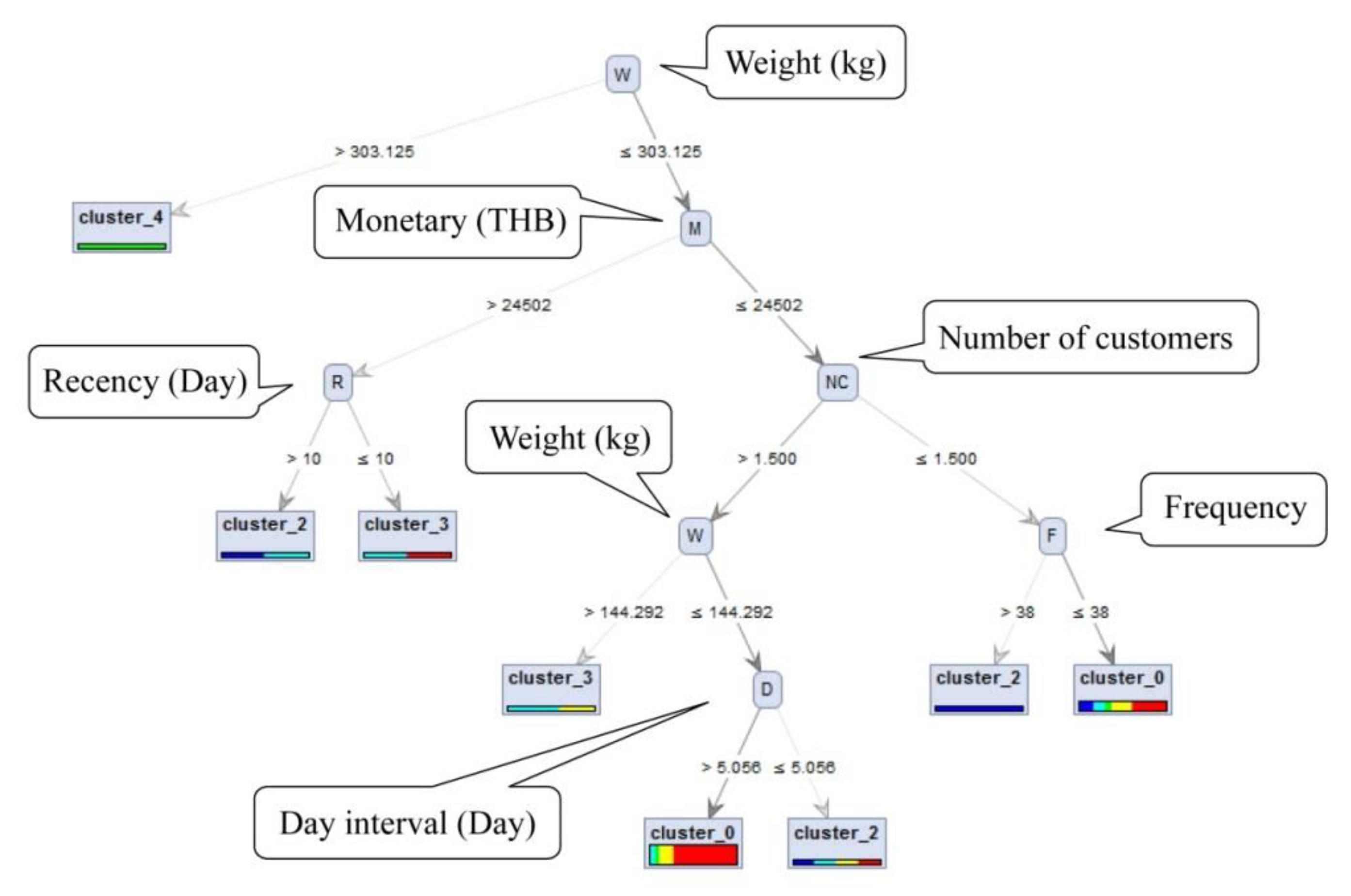
4.2.3. Predicting Possible Matching of Shippers and Consignees Using Decision Tree
- Rule 1: if {Weight > 303.13 kg} then cluster_4
- Rule 7: if {Weight ≤ 303.13 kg} and {Monetary ≤ 24,502 THB} and {Number of customers ≤ 1.5} and {Frequency > 38} then cluster_2
- Rule 4: if {144.30 kg < Weight ≤ 303.13 kg} and {Monetary ≤ 24,502 THB} and {Number of customers > 1.5} then cluster_3
4.2.4. Simulating Expected Revenue Using Monte Carlo Simulation
5. Conclusions and Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Linden, G.; Smith, B.; York, J. Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef] [Green Version]
- Chajri, M.; Fakir, M. Application of Data Mining in e-Commerce. J. Inf. Technol. Res. 2014, 7, 79–91. [Google Scholar] [CrossRef]
- Osadchiy, T.; Poliakov, I.; Olivier, P.; Rowland, M.; Foster, E.; Rowland, M. Recommender system based on pairwise association rules. Expert Syst. Appl. 2019, 115, 535–542. [Google Scholar] [CrossRef]
- Tewari, A.S.; Barman, A.G. Sequencing of items in personalized recommendations using multiple recommendation techniques. Expert Syst. Appl. 2018, 97, 70–82. [Google Scholar] [CrossRef]
- Lu, Q.; Guo, F. Personalized information recommendation model based on context contribution and item correlation. Measurement 2019, 142, 30–39. [Google Scholar] [CrossRef]
- Erevelles, S.; Fukawa, N.; Swayne, L. Big Data consumer analytics and the transformation of marketing. J. Bus. Res. 2016, 69, 897–904. [Google Scholar] [CrossRef]
- Ramamohan, Y.; Vasantharao, K.; Chakravarti, C.K.; Ratnam, A.S.K. A study of data mining tools in knowledge discovery process. Int. J. Soft Comput. Eng. (IJSCE) 2012, 2, 2231–2307. [Google Scholar]
- Sopadang, A.; Cho, B.R.; Leonard, M.S. Development of a Scaling Factor Identification Method Using Design of Experiments for Product-Family-Based Product and Process Design. Qual. Eng. 2002, 14, 319–329. [Google Scholar] [CrossRef]
- Gulc, A. Courier service quality from the clients’ perspective. Eng. Manag. Prod. Serv. 2017, 9, 36–45. [Google Scholar] [CrossRef] [Green Version]
- Ben Ayed, A.; Ben Halima, M.; Alimi, M.A. Big data analytics for logistics and transportation. In Proceedings of the 2015 4th International Conference on Advanced Logistics and Transport (ICALT), Valenciennes, France, 20–22 May 2015; pp. 311–316. [Google Scholar]
- Ansoff, H.I. Strategies for diversification. Harv. Bus. Rev. 1957, 35, 113–124. [Google Scholar]
- Dudin, M.; Lyasnikov, N.V.; Leont’Eva, L.S.; Reshetov, K.; Sidorenko, V.N. Business Model Canvas as a Basis for the Competitive Advantage of Enterprise structures in the Industrial Agriculture. Biosci. Biotechnol. Res. Asia 2015, 12, 887–894. [Google Scholar] [CrossRef]
- Huang, C.-C.; Liang, W.-Y.; Wen, D.-W.; Ting, P.-H.; Shen, M.-Y. Qualitative analysis of big data in the service sectors. Serv. Ind. J. 2018, 1–19. [Google Scholar] [CrossRef]
- Ellis, J.A.; Fee, C.E.; Thomas, S.E. Proprietary Costs and the Disclosure of Information about Customers. J. Account. Res. 2012, 50, 685–727. [Google Scholar] [CrossRef]
- Boysen, N.; Briskorn, D.; Schwerdfeger, S. Matching supply and demand in a sharing economy: Classification, computational complexity, and application. Eur. J. Oper. Res. 2019, 278, 578–595. [Google Scholar] [CrossRef]
- Dougherty, D. A practice-centered model of organizational renewal through product innovation. Strat. Manag. J. 1992, 13, 77–92. [Google Scholar] [CrossRef]
- Klassen, K.; Rohleder, T. Combining Operations and Marketing to Manage Capacity and Demand in Services. Serv. Ind. J. 2001, 21, 1–30. [Google Scholar] [CrossRef]
- Chen, L.-F.; Chen, S.-C.; Su, C.-T. An innovative service quality evaluation and improvement model. Serv. Ind. J. 2017, 38, 228–249. [Google Scholar] [CrossRef]
- Osterwalder, A.; Pigneur, Y. Business Model Generation: A Handbook for Visionaries, Game Changers, and Challengers; John Wiley and Sons: Hoboken, NJ, USA, 2010; p. 288. [Google Scholar]
- Zolnowski, A.; Weiss, C.; Böhmann, T. Representing Service Business Models with the Service Business Model Canvas—The Case of a Mobile Payment Service in the Retail Industry. In Proceedings of the 2014 47th Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; pp. 718–727. [Google Scholar]
- Hung, J.L.; Zhang, K. Revealing online learning behaviors and activity patterns and making predictions with data mining techniques in online teaching. MERLOT J. Online Learn. Teach. 2008, 4, 425–437. [Google Scholar]
- Birant, D. Data Mining Using RFM Analysis. In Knowledge-Oriented Applications in Data Mining; IntechOpen: London, UK, 2011; pp. 91–108. [Google Scholar]
- Liao, S.-H.; Chu, P.-H.; Chen, Y.-J.; Chang, C.-C. Mining customer knowledge for exploring online group buying behavior. Expert Syst. Appl. 2012, 39, 3708–3716. [Google Scholar] [CrossRef]
- Pitchayadejanant, K.; Nakpathom, P. Data mining approach for arranging and clustering the agro-tourism activities in orchard. Kasetsart J. Soc. Sci. 2018, 39, 407–413. [Google Scholar] [CrossRef]
- Christy, A.J.; Umamakeswari, A.; Priyatharsini, L.; Neyaa, A. RFM ranking—An effective approach to customer segmentation. J. King Saud Univ. Comput. Inf. Sci. 2018. [Google Scholar] [CrossRef]
- Jintana, J.; Mori, T. Customer clustering for a new method of marketing strategy support within the courier business. Acad. Book Chapter 2019, 31, 1–19. [Google Scholar]
- Bult, J.R.; Wansbeek, T. Optimal Selection for Direct Mail. Mark. Sci. 1995, 14, 378–394. [Google Scholar] [CrossRef]
- Aggelis, V.; Christodoulakis, D. Customer clustering using RFM analysis. In Proceedings of the 9th World Scientific and Engineering Academy and Society (WSEAS) International Conference on Computers (ICCOMP’05), Stevens Point, WI, USA, 14 July 2005; pp. 1–5. [Google Scholar]
- Khajvand, M.; Zolfaghar, K.; Ashoori, S.; Alizadeh, S. Estimating customer lifetime value based on RFM analysis of customer purchase behavior: Case study. Procedia Comput. Sci. 2011, 3, 57–63. [Google Scholar] [CrossRef] [Green Version]
- Li, S.-T.; Shue, L.-Y.; Lee, S.-F. Business intelligence approach to supporting strategy-making of ISP service management. Expert Syst. Appl. 2008, 35, 739–754. [Google Scholar] [CrossRef]
- Daoud, R.A.; Amine, A.; Bouikhalene, B.; Lbibb, R. Combining RFM model and clustering techniques for customer value analysis of a company selling online. In Proceedings of the 2015 IEEE/ACS 12th International Conference of Computer Systems and Applications (AICCSA), Marrakech, Morocco, 17–20 November 2015; pp. 1–6. [Google Scholar]
- Olson, D.L.; Cao, Q.; Gu, C.; Lee, D. Comparison of customer response models. Serv. Bus. 2009, 3, 117–130. [Google Scholar] [CrossRef]
- Cheng, C.-H.; Chen, Y.-S. Classifying the segmentation of customer value via RFM model and RS theory. Expert Syst. Appl. 2009, 36. [Google Scholar] [CrossRef]
- Mccarty, J.A.; Hastak, M. Segmentation approaches in data-mining: A comparison of RFM, CHAID, and logistic regression. J. Bus. Res. 2007, 60, 656–662. [Google Scholar] [CrossRef]
- Chan, C.C.H. Intelligent value-based customer segmentation method for campaign management: A case study of automobile retailer. Expert Syst. Appl. 2008, 34, 2754–2762. [Google Scholar] [CrossRef]
- Chen, Y.-L.; Kuo, M.-H.; Wu, S.-Y.; Tang, K. Discovering recency, frequency, and monetary (RFM) sequential patterns from customers’ purchasing data. Electron. Commer. Res. Appl. 2009, 8, 241–251. [Google Scholar] [CrossRef]
- Liu, D.-R.; Lai, C.-H.; Lee, W.-J. A hybrid of sequential rules and collaborative filtering for product recommendation. Inf. Sci. 2009, 179, 3505–3519. [Google Scholar] [CrossRef]
- Wu, H.-H.; Lin, S.-Y.; Liu, C.-W. Analyzing Patients’ Values by Applying Cluster Analysis and LRFM Model in a Pediatric Dental Clinic in Taiwan. Sci. World J. 2014, 2014, 1–7. [Google Scholar] [CrossRef]
- Hosseini, S.M.S.; Maleki, A.; Gholamian, M.R. Cluster analysis using data mining approach to develop CRM methodology to assess the customer loyalty. Expert Syst. Appl. 2010, 37, 5259–5264. [Google Scholar] [CrossRef]
- Chen, K.; Hu, Y.-H.; Hsieh, Y.-C. Predicting customer churn from valuable B2B customers in the logistics industry: A case study. Inf. Syst. e-Bus. Manag. 2014, 13, 475–494. [Google Scholar] [CrossRef]
- Lee, L.H.L.F.M.; Liu, W.J. The timely product recommendation based on RFM method. In Proceedings of the International Conference on Business and Information, Singapore, 12–14 July 2006. [Google Scholar]
- Sung, C.; Zhang, B.; Higgins, C.Y.; Choe, Y. Data-Driven Sales Leads Prediction for Everything-as-a-Service in the Cloud. In Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 557–563. [Google Scholar]
- Cho, Y.S.; Ryu, K.H.; Ryu, K.S.; Moon, S.C. Personalized u-commerce recommending service using weighted sequential pattern with time-series and FRAT method. In Proceedings of the 2014 IEEE International Conference on Management of Innovation and Technology, Singapore, 23–25 September 2014; pp. 295–300. [Google Scholar]
- Chang, H.-C.; Tsai, H.-P. Group RFM analysis as a novel framework to discover better customer consumption behavior. Expert Syst. Appl. 2011, 38, 14499–14513. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Databases (VLDB), Santiago, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Plasse, M.; Niang, N.; Saporta, G.; Villeminot, A.; Leblond, L. Combined use of association rules mining and clustering methods to find relevant links between binary rare attributes in a large data set. Comput. Stat. Data Anal. 2007, 52, 596–613. [Google Scholar] [CrossRef]
- Song, H.S.; Kim, J.K.; Kim, S.H. Mining the change of customer behavior in an internet shopping mall. Expert Syst. Appl. 2001, 21, 157–168. [Google Scholar] [CrossRef]
- Chen, M.; Chiu, A.; Chang, H.-H. Mining changes in customer behavior in retail marketing. Expert Syst. Appl. 2005, 28, 773–781. [Google Scholar] [CrossRef]
- Yoshimura, Y.; Sobolevsky, S.; Hobin, J.N.B.; Ratti, C.; Blat, J. Urban association rules: Uncovering linked trips for shopping behavior. Environ. Plan. B Urban Anal. City Sci. 2016, 45, 367–385. [Google Scholar] [CrossRef]
- Agrawal, R.; Imielinski, T.; Swami, A. Mining association rules between sets of items in large databases. ACM SIGMOD Rec. 1993, 22, 207–216. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. ACM SIGMOD Rec. 2000, 29, 1–12. [Google Scholar] [CrossRef]
- Zhang, W.; Liao, H.; Zhao, N. Research on the FP Growth Algorithm about Association Rule Mining. In Proceedings of the 2008 International Seminar on Business and Information Management, Wuhan, China, 19 December 2008; pp. 315–318. [Google Scholar]
- Kumar, B.S.; Rukmani, K.V. Implementation of web usage mining using Apriori and FP growth algorithms. Int. J. Adv. Netw. Appl. 2010, 1, 400–404. [Google Scholar]
- Hunyadi, D. Performance comparison of Apriori and FP-Growth algorithms in generating association rules. In Proceedings of the 5th European Computing Conference (ECC’11), Paris, France, 28–30 April 2011; pp. 376–381. [Google Scholar]
- Lin, K.-C.; Liao, I.-E.; Chen, Z.-S. An improved frequent pattern growth method for mining association rules. Expert Syst. Appl. 2011, 38, 5154–5161. [Google Scholar] [CrossRef]
- Yang, W.; Hui, L.; Zhang, N.; Fu, Y. An Improved Incremental Queue Association Rules for Mining Mass Text. In Proceedings of the 2016 International Symposium on Computer, Consumer and Control (IS3C), Xi’an, China, 4–6 July 2016; pp. 447–450. [Google Scholar]
- Wang, B.; Chen, D.; Shi, B.; Zhang, J.; Duan, Y.; Chen, J.; Hu, R. Comprehensive Association Rules Mining of Health Examination Data with an Extended FP-Growth Method. Mob. Netw. Appl. 2017, 22, 267–274. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M. Data Mining Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2001. [Google Scholar]
- Kaushik, M.; Mathur, B. Comparative study of K-means and hierarchical clustering techniques. Int. J. Softw. Hardw. Res. Eng. 2014, 2, 93–98. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium On Mathematical Statistics And Probability, Berkeley, CA, USA, 21 June–18 July 1965 and 27 December 1965–7 January 1966; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Abbas, O.A. Comparisons between Data Clustering Algorithms. Int. Arab J. Inf. Technol. 2008, 5, 320–325. [Google Scholar]
- Liu, C.C.; Chu, S.W.; Chan, Y.K.; Yu, S.S. A Modified K-Means Algorithm—Two-Layer K-Means Algorithm. In Proceedings of the 2014 Tenth International Conference on Intelligent Information Hiding and Multimedia Signal Proceedings, Kitakyushu, Japan, 27–29 August 2014; pp. 447–450. [Google Scholar]
- Shah, S.; Singh, M. Comparison of a Time Efficient Modified K-mean Algorithm with K-Mean and K-Medoid Algorithm. In Proceedings of the 2012 International Conference on Communication Systems and Network Technologies, Rajkot, India, 11–13 May 2012; pp. 435–437. [Google Scholar]
- Chen, D.; Sain, S.L.; Guo, K. Data mining for the online retail industry: A case study of RFM model-based customer segmentation using data mining. J. Database Mark. Cust. Strat. Manag. 2012, 19, 197–208. [Google Scholar] [CrossRef]
- Parvaneh, A.; Tarokh, M.; Abbasimehr, H. Combining data mining and group decision making in retailer segmentation based on LRFMP variables. Int. J. Ind. Eng. Prod. Res. 2014, 25, 197–206. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.; Gupta, P. Comparative study ID3, cart and C4. 5 decision tree algorithm: A survey. Int. J. Adv. Inf. Sci. Technol. 2014, 27, 97–103. [Google Scholar]
- Song, Y.-Y.; Lu, Y. Decision tree methods: Applications for classification and prediction. Shanghai Arch Psychiatry 2015, 27, 130–135. [Google Scholar] [PubMed]
- Skrbinjek, V.; Dermol, V. Predicting students’ satisfaction using a decision tree. Tert. Educ. Manag. 2019, 25, 101–113. [Google Scholar] [CrossRef]
- Gonoodi, K.; Tayefi, M.; Saberi-Karimian, M.; Amirabadizadeh, A.; Darroudi, S.; Farahmand, S.K.; Abasalti, Z.; Moslem, A.; Nematy, M.; Ferns, G.A.; et al. An assessment of the risk factors for vitamin D deficiency using a decision tree model. Diabetes Metab. Syndr. Clin. Res. Rev. 2019, 13, 1773–1777. [Google Scholar] [CrossRef] [PubMed]
- Sheu, J.-J.; Chu, K.-T.; Wang, S.-M. The associate impact of individual internal experiences and reference groups on buying behavior: A case study of animations, comics, and games consumers. Telemat. Inform. 2017, 34, 314–325. [Google Scholar] [CrossRef]
- Hsu, C.-H.; Wang, M.-J.J. Using decision tree-based data mining to establish a sizing system for the manufacture of garments. Int. J. Adv. Manuf. Technol. 2004, 26, 669–674. [Google Scholar] [CrossRef]
- Mitik, M.; Korkmaz, O.; Karagoz, P.; Toroslu, I.H.; Yucel, F. Data Mining Approach for Direct Marketing of Banking Products with Profit/Cost Analysis. Rev. Socionetwork Strat. 2017, 11, 17–31. [Google Scholar] [CrossRef]
- Tayefi, M.; Esmaeili, H.; Karimian, M.S.; Zadeh, A.A.; Ebrahimi, M.; Safarian, M.; Nematy, M.; Parizadeh, S.M.R.; Ferns, G.A.; Ghayour-Mobarhan, M. The application of a decision tree to establish the parameters associated with hypertension. Comput. Methods Programs Biomed. 2017, 139, 83–91. [Google Scholar] [CrossRef]
- Tseng, W.-T.; Chiang, W.-F.; Liu, S.-Y.; Roan, J.; Lin, C.-N. The Application of Data Mining Techniques to Oral Cancer Prognosis. J. Med Syst. 2015, 39, 59. [Google Scholar] [CrossRef]
- Dongming, L.; Yan, L.; Chao, Y.; Chaoran, L.; Huan, L.; Lijuan, Z. The application of decision tree C4.5 algorithm to soil quality grade forecasting model. In Proceedings of the 2016 First IEEE International Conference on Computer Communication and the Internet (ICCCI), Wuhan, China, 13–15 October 2016; pp. 552–555. [Google Scholar]
- Bunnak, P.; Thammaboosadee, S.; Kiattisin, S. Applying Data Mining Techniques and Extended RFM Model in Customer Loyalty Measurement. J. Adv. Inf. Technol. 2015, 238–242. [Google Scholar] [CrossRef]
- Moedjiono, S.; Fransisca, F.; Kusdaryono, A. Segmentation and Classification Customer Payment Behavior at Multimedia Service Provider Company with K-Means and C4. 5 Algorithm. Int. J. Comput. Netw. Commun. Secur. 2016, 4, 265. [Google Scholar]
- US EPA Technical Panel. Guiding Principles for Monte Carlo Analysis; US EPA: Washington, DC, USA, 1997; pp. 1–35.
- Solver, F. Premium Solver Platform. User Guide, Frontline Systems. 2010. Available online: https://www.solver.com/files/support/PSP-for-MacOS_Manual.pdf (accessed on 20 January 2020).
- Platon, V.; Constantinescu, A. Monte Carlo Method in Risk Analysis for Investment Projects. Procedia Econ. Financ. 2014, 15, 393–400. [Google Scholar] [CrossRef] [Green Version]
- Raychaudhuri, S. Introduction to Monte Carlo simulation. In Proceedings of the 2008 Winter Simulation Conference, Miami, FL, USA, 7–10 December 2008; pp. 91–100. [Google Scholar]
- Rezaie, K.; Amalnik, M.; Gereie, A.; Ostadi, B.; Shakhseniaee, M. Using extended Monte Carlo simulation method for the improvement of risk management: Consideration of relationships between uncertainties. Appl. Math. Comput. 2007, 190, 1492–1501. [Google Scholar]
- Glasserman, P. Monte Carlo Methods in Financial Engineering; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; Volume 5. [Google Scholar]
- Armaghani, D.J.; Mahdiyar, A.; Hasanipanah, M.; Faradonbeh, R.S.; Khandelwal, M.; Amnieh, H.B. Risk Assessment and Prediction of Flyrock Distance by Combined Multiple Regression Analysis and Monte Carlo Simulation of Quarry Blasting. Rock Mech. Rock Eng. 2016, 49, 3631–3641. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Philadelphia, PA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Memariani, A.; Amini, A.; Alinezhad, A. Sensitivity analysis of simple additive weighting method (SAW): The results of change in the weight of one attribute on the final ranking of alternatives. J. Optim. Ind. Eng. 2009, 4, 13–18. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Question (RQ) | DA Techniques | Description |
|---|---|---|
| RQ1 Which products/items do consignees most often receive together? Which items are likely to be recommended? | Association rule
| Discover relationships between product categories that are normally or frequently delivered together. |
| RQ2 Which shippers and consignees are the most/least valuable? What are their distinct characteristics? | Clustering technique
| Group customers according to patterns of behavior and target potential customers to provide recommendations. |
| RQ3 Which shippers and consignees have a greater likelihood of becoming new business partners? | Classification technique
| Learn to predict potential business matches between shippers and consignees. |
| RQ4 Can the matching of consignees and shippers generate revenue? | Simulation
| Estimate revenue that would be generated to support investment decision-making and to simulate new business scenarios. |
| Attributes | Data Type | Description and Data Examples |
|---|---|---|
| Shipper name | Text | Name of shipper e.g., Mr. Emily Brown |
| Consignee name | Text | Name of consignee e.g., Mr. John Meily |
| Date | Numeric | Transaction date e.g., 12/03/2018 |
| Time | Numeric | Transaction time e.g., 10:31:44 AM |
| Products group name | Nominal | Name of product group e.g., food and drink, clothes, garments, and accessories |
| Products category name | Nominal | Name of product category e.g., perishable foods, clothes |
| Start station | Nominal | Name of start station e.g., Chiang Mai |
| Destination station | Nominal | Name of destination station e.g., Chiang Rai |
| Quantity | Numeric | Quantity of cargo per transaction |
| Weight | Numeric | Weight of cargo per transaction (kg) e.g., 15 kg. |
| Freight charges | Numeric | Freight charges per transaction (THB) e.g., 695 THB. |
| Membership application date | Numeric | Date of member registration (first transaction) e.g., 05/12/2017 |
| Employee name | Text | Name of sale officer who recorded the transaction |
| Payment type | Nominal | Payment type e.g., cash, debit, agent |
| No. | Rule | Support | Confidence |
|---|---|---|---|
| 1 | Garment products ==> Clothes | 0.090 | 80.81 |
| 2 | Garments and related products ==> Clothes | 0.019 | 60.79 |
| 3 | Bags and handbags ==> Clothes | 0.018 | 61.93 |
| 4 | Car accessories ==> Spare parts | 0.010 | 56.49 |
| 5 | Garment products ==> Bags and handbags | 0.008 | 87.76 |
| 6 | Meatballs ==> Perishable foods | 0.008 | 64.21 |
| 7 | Underwear ==> Clothes | 0.007 | 52.53 |
| 8 | Computers and spare parts ==> Electronics equipment | 0.007 | 50.00 |
| 9 | Garment products ==> Garments and related products ==> Clothes | 0.006 | 89.81 |
| 10 | Sewing equipment ==> Clothes | 0.006 | 75.61 |
| 11 | Steaks ==> Seasoning ==> Perishable foods | 0.006 | 67.18 |
| Variables | Definition | Calculation |
|---|---|---|
| R (Recency) | Period of time between previous service and set date | Set date—last transaction date |
| F (Frequency) | Total number of service users within a particular period of time | Count of sale transactions |
| M (Monetary) | Total THB generated by customer’s service within a particular period of time | Sum of money for each customer |
| NC (Number of customers) | Number of consignees/shippers | Count of total consignee/shipper customer numbers |
| NP (Number of product items) | Number of product items | Count of consignee/shipper product items |
| W (Weight) | Average weight per transaction (kg) | Average weight per transaction (kg) |
| D (Day) | Interval between transactions (day) | Average number of days between transactions |
| R | F | M | NC | NP | W | D | |
|---|---|---|---|---|---|---|---|
| R | 1 | ||||||
| F | −0.098 | 1 | |||||
| M | −0.097 | 0.895 | 1 | ||||
| NC | −0.113 | 0.693 | 0.686 | 1 | |||
| NP | −0.108 | 0.160 | 0.154 | 0.232 | 1 | ||
| W | −0.067 | 0.056 | 0.127 | 0.054 | 0.009 | 1 | |
| D | 0.317 | −0.145 | −0.142 | −0.180 | −0.203 | −0.125 | 1 |
| R | F | M | NC | NP | W | D | Number in Cluster | Normalized SAW Score | Rank | |
|---|---|---|---|---|---|---|---|---|---|---|
| Cluster_0 | 160.84 | 2.32 | 313.65 | 1.44 | 2.09 | 11.59 | 272.95 | 14,534 | 0.03 | 5 |
| Cluster_1 | 27.21 | 44.01 | 9920.17 | 9.34 | 3.44 | 39.52 | 11.75 | 228 | 0.12 | 4 |
| Cluster_2 | 1.33 | 1960 | 408,641 | 302.00 | 15 | 36.28 | 1.38 | 3 | 0.49 | 1 |
| Cluster_3 | 7.00 | 124.98 | 38,288.36 | 16.23 | 4.38 | 54.68 | 4.96 | 40 | 0.15 | 3 |
| Cluster_4 | 1.69 | 334.15 | 100,562.4 | 64.69 | 9.77 | 48.06 | 2.29 | 13 | 0.22 | 2 |
| Total | 158.20 | 3.98 | 734.59 | 1.72 | 2.12 | 12.17 | 267.92 | 14,818 | 1 |
| No | Classification Rule | Prediction Shipper Cluster | Number of Consignees in Rule | Number of Shippers in a Cluster | Confidence of Rule-Based Classifier | Accuracy | Association Support |
|---|---|---|---|---|---|---|---|
| 1 | W > 303.13 | Cluster_4 | 1 | 13 | 100% | 62.40% | 9% |
| 2 | W ≤ 303.13 M > 24,502 R > 10 | Cluster_2 | 0 | 3 | 50% | ||
| 3 | W ≤ 303.13 M > 24,502 R ≤ 10 | Cluster_3 | 0 | 40 | 50% | ||
| 4 | W ≤ 303.13 M ≤ 24,502 NC > 1.5 W > 144.30 | Cluster_3 | 6 | 40 | 60% | ||
| 5 | W ≤ 303.13 M ≤ 24,502 NC > 1.5 W ≤ 144.30 D > 5.1 | Cluster_0 | 381 | 14,534 | 72% | ||
| 6 | W ≤ 303.13 M ≤ 24,502 NC > 1.5 W ≤ 144.30 D ≤ 5.1 | Cluster_2 | 12 | 3 | 25% | ||
| 7 | W ≤ 303.13 M ≤ 24,502 NC ≤ 1.5 F > 38 | Cluster_2 | 1 | 3 | 100% | ||
| 8 | W ≤ 303.13 M ≤ 24,502 NC ≤ 1.5 F ≤ 38 | Cluster_0 | 1034 | 14,534 | 39% |
| Rule | Consignees: Shippers | Fitness of Association Model | Fitness of Classification Model | Expected Revenue (THB) | ||||
|---|---|---|---|---|---|---|---|---|
| SA | CA | RC | AC | |||||
| 1 | 1:13 | Triang (4.05, 6.5015) (N = 2400) | 3884 | 0.09 | 0.80 | 1 | 0.624 | 1038 |
| 7 | 1:3 | 11,429 | 1 | 3063 | ||||
| 4 | 6:40 | Pareto (0.9681, 1076) (N = 6) | 0.60 | 12,266 | ||||
| Rule | Minimum, Mean, Maximum Expected Revenue (THB) | Continuous Distribution Functions |
|---|---|---|
| 1 | (192, 1038, 2675) |  Lognorm (1082, 939.8) |
| 7 | (558, 3063, 8161) |  Lognorm (3186.2, 2789.7) |
| 4 | (334, 12,266, 22,200) |  Pearson5 (1.095, 1561) |
| Total | (2380, 16,368, 27,500) |  Pearson5 (2.0665, 10556) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jintana, J.; Sopadang, A.; Ramingwong, S. Matching Consignees/Shippers Recommendation System in Courier Service Using Data Analytics. Appl. Sci. 2020, 10, 5585. https://doi.org/10.3390/app10165585
Jintana J, Sopadang A, Ramingwong S. Matching Consignees/Shippers Recommendation System in Courier Service Using Data Analytics. Applied Sciences. 2020; 10(16):5585. https://doi.org/10.3390/app10165585
Chicago/Turabian StyleJintana, Jutamat, Apichat Sopadang, and Sakgasem Ramingwong. 2020. "Matching Consignees/Shippers Recommendation System in Courier Service Using Data Analytics" Applied Sciences 10, no. 16: 5585. https://doi.org/10.3390/app10165585