Bi-LSTM Model to Increase Accuracy in Text Classification: Combining Word2vec CNN and Attention Mechanism



Abstract
1. Introduction
2. Background and Related Research
2.1. Deep Learning Model
2.1.1. Word2vec
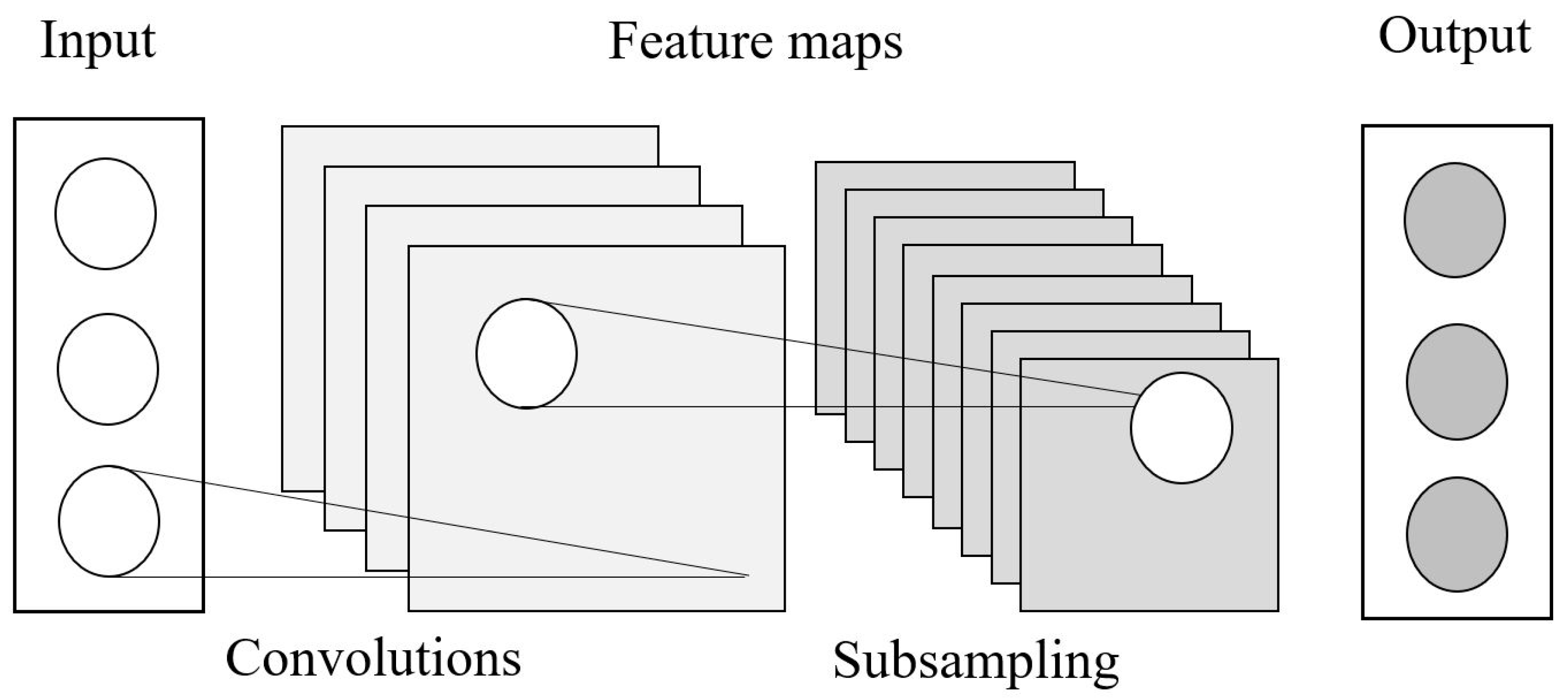
2.1.2. 1D Convolutional Neural Networks
2.1.3. Bi-LSTM
2.1.4. Attention Mechanism
2.2. Related Research
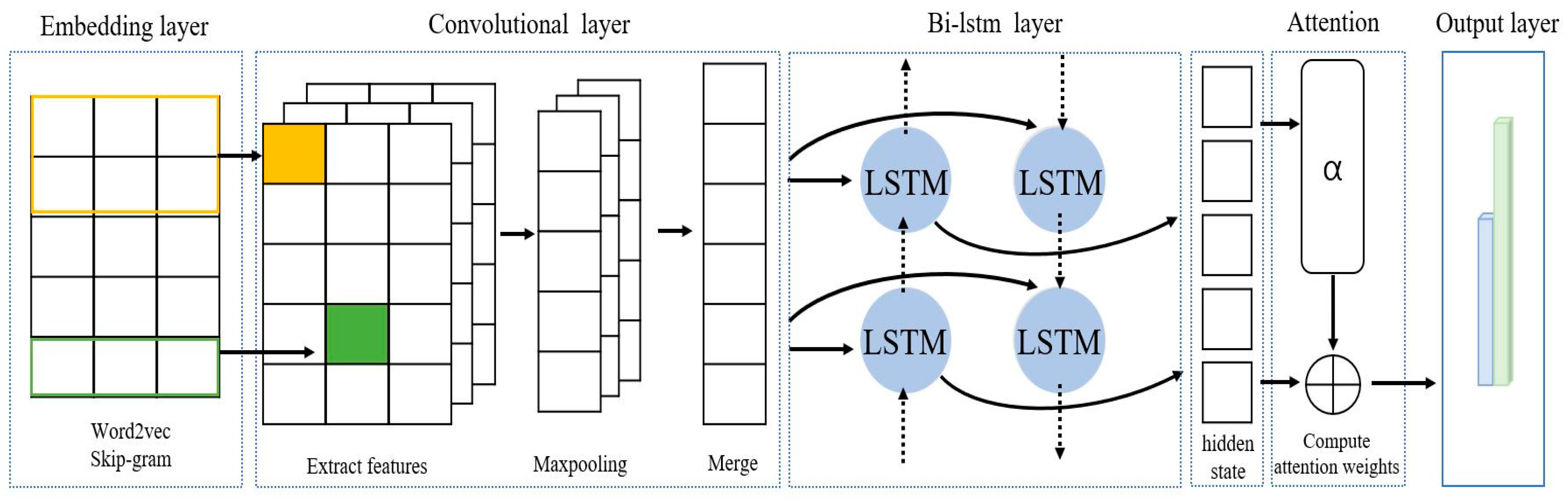
3. The Proposed Model
3.1. Sequence Embedding Layer
3.2. 1D CNN
3.3. Bi-LSTM Attention Layer
4. Experiment
4.1. Dataset
4.2. Parameter Set
4.3. Performance Evaluation Metrics
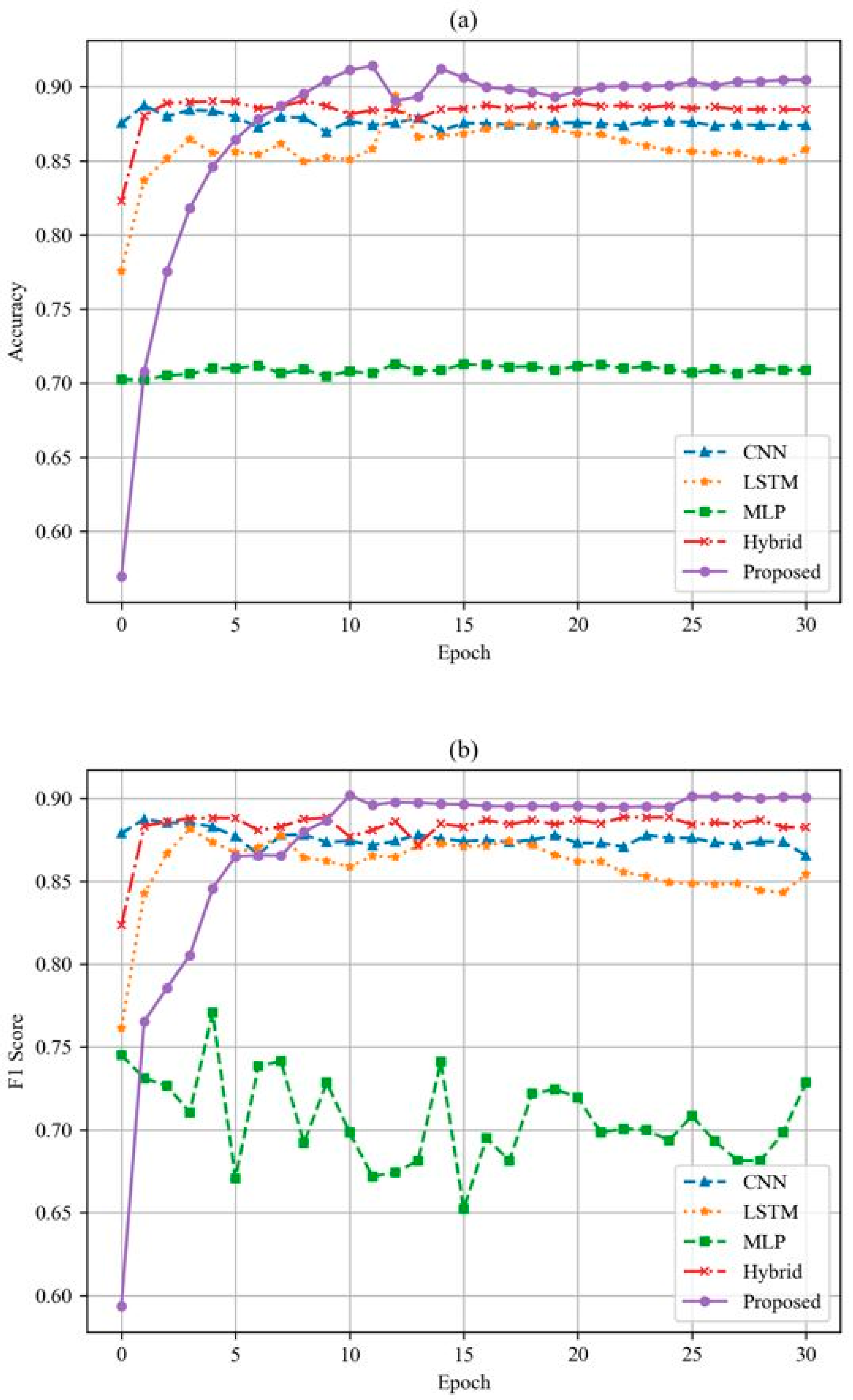
5. Results
6. Analysis
7. Future Works
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.-L.; Chen, S.-C.; Iyengar, S.S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Ikonomakis, M.; Kotsiantis, S.; Tampakas, V. Text Classification Using Machine Learning Techniques. WSEAS Trans. Comput. 2005, 4, 966–974. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Zhang, Y.; Zheng, J.; Jiang, Y.; Huang, G.; Chen, R. A Text Sentiment Classification Modeling Method Based on Coordinated CNN-LSTM-Attention Model. Chin. J. Electron. 2019, 28, 120–126. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Liu, H. Sentiment analysis of citations using word2vec. arXiv 2017, arXiv:1704.00177. [Google Scholar]
- Zhang, D.; Xu, H.; Su, Z.; Xu, Y. Chinese comments sentiment classification based on word2vec and SVMperf. Expert Syst. Appl. 2015, 42, 1857–1863. [Google Scholar] [CrossRef]
- Peng, H.; Song, Y.; Roth, D. Event Detection and Co-reference with Minimal Supervision. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics (ACL), Austin, TX, USA, 1–5 November 2016; pp. 392–402. [Google Scholar]
- Severyn, A.; Moschitti, A. Twitter Sentiment Analysis with Deep Convolutional Neural Networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR ’15, Association for Computing Machinery (ACM), Santiago, Chile, 9–13 August 2015; pp. 959–962. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative study of CNN and RNN for natural language processing. arXiv 2017, arXiv:1702.01923. [Google Scholar]
- Liang, D.; Zhang, Y. AC-BLSTM: Asymmetric convolutional bidirectional LSTM networks for text classification. arXiv 2016, arXiv:1611.01884. [Google Scholar]
- Zhou, P.; Qi, Z.; Zheng, S.; Xu, J.; Bao, H.; Xu, B. Text classification improved by integrating bidirectional LSTM with two-dimensional max pooling. arXiv 2016, arXiv:1611.06639. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Wang, S.; Huang, M.; Deng, Z. Densely Connected CNN with Multi-scale Feature Attention for Text Classification. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence {IJCAI-18}, International Joint Conferences on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 4468–4474. [Google Scholar]
- Du, C.; Huang, L. Text Classification Research with Attention-based Recurrent Neural Networks. Int. J. Comput. Commun. Control. 2018, 13, 50–61. [Google Scholar] [CrossRef]
- Gao, S.; Ramanathan, A.; Tourassi, G. Hierarchical Convolutional Attention Networks for Text Classification. In Proceedings of the Third Workshop on Representation Learning for NLP, Association for Computational Linguistics (ACL), Melbourne, Australia, 20 July 2018; pp. 11–23. [Google Scholar]
- Melamud, O.; Goldberger, J.; Dagan, I.; Riezler, S.; Goldberg, Y. context2vec: Learning Generic Context Embedding with Bidirectional LSTM. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Association for Computational Linguistics (ACL), Berlin, Germany, 11–12 August 2016; pp. 51–61. [Google Scholar]
- Ceraj, T.; Kliman, I.; Kutnjak, M. Redefining Cancer Treatment: Comparison of Word2vec Embeddings Using Deep BiLSTM Classification Model; Text Analysis and Retrieval 2019 Course Project Reports; Faculty of Electrical Engineering and Computing, University of Zagreb: Zagreb, Croatia, July 2019. [Google Scholar]
- Xiao, L.; Wang, G.; Zuo, Y. Research on Patent Text Classification Based on Word2Vec and LSTM. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; Volume 1, pp. 71–74. [Google Scholar] [CrossRef]
- Rehman, A.U.; Malik, A.K.; Raza, B.; Ali, W. A Hybrid CNN-LSTM Model for Improving Accuracy of Movie Reviews Sentiment Analysis. Multimed. Tools Appl. 2019, 78, 26597–26613. [Google Scholar] [CrossRef]
- Luan, Y.; Lin, S. Research on Text Classification Based on CNN and LSTM. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Institute of Electrical and Electronics Engineers (IEEE), Dalian, China, 29–31 March 2019; pp. 352–355. [Google Scholar]
- Wang, J.; Yu, L.-C.; Lai, K.R.; Zhang, X. Tree-Structured Regional CNN-LSTM Model for Dimensional Sentiment Analysis. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 28, 581–591. [Google Scholar] [CrossRef]
- She, X.; Zhang, D. Text Classification Based on Hybrid CNN-LSTM Hybrid Model. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; Volume 2, pp. 185–189. [Google Scholar] [CrossRef]
- Salur, M.U.; Aydin, I. A Novel Hybrid Deep Learning Model for Sentiment Classification. IEEE Access 2020, 8, 58080–58093. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Y.; Tian, J.; Li, T. LSTM-CNN Hybrid Model for Text Classification. In Proceedings of the 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Institute of Electrical and Electronics Engineers (IEEE), Chongqing, China, 12–14 October 2018; pp. 1675–1680. [Google Scholar]
- Dong, Y.; Liu, P.; Zhu, Z.; Wang, Q.; Zhang, Q. A Fusion Model-Based Label Embedding and Self-Interaction Attention for Text Classification. IEEE Access 2020, 8, 30548–30559. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T.; Lapata, M.; Blunsom, P.; Koller, A. Bag of Tricks for Efficient Text Classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Jasmir, J.; Nurmaini, S.; Malik, R.F.; Abidin, D.Z. Text Classification of Cancer Clinical Trials Documents Using Deep Neural Network and Fine Grained Document Clustering. In Proceedings of the Sriwijaya International Conference on Information Technology and Its Applications (SICONIAN 2019), Palembang, Indonesia, 16 November 2019; Atlantis Press: Paris, France, 2020; pp. 396–404. [Google Scholar]
- Schmaltz, A.; Beam, A. Exemplar Auditing for Multi-Label Biomedical Text Classification. arXiv 2020, arXiv:2004.03093. [Google Scholar]
- Wang, Y.-B.; You, Z.-H.; Yang, S.; Li, X.; Jiang, T.; Zhou, X. A High Efficient Biological Language Model for Predicting Protein–Protein Interactions. Cells 2019, 8, 122. [Google Scholar] [CrossRef] [PubMed]
- Bergman, P.; Berman, S.J. Represent Yourself in Court: How to Prepare & Try a Winning Case; Nolo: Berkley, CA, USA, 2016. [Google Scholar]
- Li, P.; Zhao, F.; Li, Y.; Zhu, Z. Law text classification using semi-supervised convolutional neural networks. In Proceedings of the 2018 Chinese Control and Decision Conference (CCDC), Institute of Electrical and Electronics Engineers (IEEE), Shenyang, China, 9–11 June 2018; pp. 309–313. [Google Scholar]
- Zhang, J.; Kowsari, K.; Harrison, J.H.; Lobo, J.M.; Barnes, L.E. Patient2Vec: A Personalized Interpretable Deep Representation of the Longitudinal Electronic Health Record. IEEE Access 2018, 6, 65333–65346. [Google Scholar] [CrossRef]
- Srivastava, S.K.; Singh, S.K.; Suri, J.S. A healthcare text classification system and its performance evaluation: A source of better intelligence by characterizing healthcare text. In Cognitive Informatics, Computer Modelling, and Cognitive Science; Elsevier BV: Amsterdam, The Netherlands, 2020; pp. 319–369. [Google Scholar]
- Seguí, F.L.; Aguilar, R.A.E.; De Maeztu, G.; García-Altés, A.; Garcia-Cuyàs, F.; Walsh, S.; Castro, M.S.; Vidal-Alaball, J. Teleconsultations between Patients and Healthcare Professionals in Primary Care in Catalonia: The Evaluation of Text Classification Algorithms Using Supervised Machine Learning. Int. J. Environ. Res. Public Health 2020, 17, 1093. [Google Scholar] [CrossRef] [PubMed]
- Kang, M.; Ahn, J.; Lee, K. Opinion mining using ensemble text hidden Markov models for text classification. Expert Syst. Appl. 2018, 94, 218–227. [Google Scholar] [CrossRef]
- Loureiro, S.M.; Guerreiro, J.; Eloy, S.; Langaro, D.; Panchapakesan, P. Understanding the use of Virtual Reality in Marketing: A text mining-based review. J. Bus. Res. 2019, 100, 514–530. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total | Training | Test | Category | Length (Max) | Words (Avg) | Vocabulary_Size |
|---|---|---|---|---|---|---|
| 50,000 | 25,000 | 25,000 | 2 | 500 | 237.71 | 10,000 |
| Word Embedding | Embedding Size | Dropout | Batch Size | Optimizer | Regularizer |
|---|---|---|---|---|---|
| skip-gram | 500 | 0.2 | 128 | Adam | L2 |
| MODEL | CNN | LSTM | MLP | Hybrid | Proposed |
|---|---|---|---|---|---|
| Accuracy(max) | 0.8874 | 0.8940 | 0.7129 | 0.8906 | 0.9141 |
| Accuracy(avg) | 0.8839 | 0.8579 | 0.7078 | 0.8763 | 0.9026 |
| Data volume | 20 k | 20 k | 20 k | 20 k | 20 k |
| Epoch | 2 | 13 | 13 | 8 | 12 |
| F1 Score | 0.8875 | 0.8816 | 0.7708 | 0.8887 | 0.9018 |
| Recall | 0.8947 | 0.9504 | 0.8562 | 0.8919 | 0.9057 |
| Precision | 0.8818 | 0.8281 | 0.7081 | 0.8872 | 0.8975 |
| Data volume | 20 k | 20 k | 20 k | 20 k | 20 k |
| Epoch | 2 | 4 | 5 | 23 | 10 |
| MODEL | CNN | LSTM | MLP | Hybrid | Proposed |
|---|---|---|---|---|---|
| Accuracy(max) | 0.871 | 0.825 | 0.726 | 0.879 | 0.902 |
| Accuracy(avg) | 0.862 | 0.805 | 0.711 | 0.855 | 0.874 |
| Data volume | 9.5 k | 6.5 k | 14 k | 12.5 k | 13 k |
| Epoch | 10 | 10 | 10 | 10 | 10 |
| F1 Score | 0.875 | 0.813 | 0.694 | 0.877 | 0.901 |
| Recall | 0.887 | 0.799 | 0.890 | 0.886 | 0.905 |
| Precision | 0.868 | 0.830 | 0.696 | 0.874 | 0.901 |
| Data volume | 11 k | 7 k | 7.5 k | 12.5 k | 13 k |
| Epoch | 10 | 10 | 10 | 10 | 10 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, B.; Kim, M.; Harerimana, G.; Kang, S.-u.; Kim, J.W. Bi-LSTM Model to Increase Accuracy in Text Classification: Combining Word2vec CNN and Attention Mechanism. Appl. Sci. 2020, 10, 5841. https://doi.org/10.3390/app10175841
Jang B, Kim M, Harerimana G, Kang S-u, Kim JW. Bi-LSTM Model to Increase Accuracy in Text Classification: Combining Word2vec CNN and Attention Mechanism. Applied Sciences. 2020; 10(17):5841. https://doi.org/10.3390/app10175841
Chicago/Turabian StyleJang, Beakcheol, Myeonghwi Kim, Gaspard Harerimana, Sang-ug Kang, and Jong Wook Kim. 2020. "Bi-LSTM Model to Increase Accuracy in Text Classification: Combining Word2vec CNN and Attention Mechanism" Applied Sciences 10, no. 17: 5841. https://doi.org/10.3390/app10175841
APA StyleJang, B., Kim, M., Harerimana, G., Kang, S.-u., & Kim, J. W. (2020). Bi-LSTM Model to Increase Accuracy in Text Classification: Combining Word2vec CNN and Attention Mechanism. Applied Sciences, 10(17), 5841. https://doi.org/10.3390/app10175841