Instance Segmentation Method of User Interface Component of Games


Abstract
:1. Introduction
2. Previous Works
2.1. Application Cases of CNN-Based Algorithms in the Game Field
2.2. Segmentation Methods
3. Methods
3.1. Automatic UI Clipping and Paired Synthetic UI Data Generation
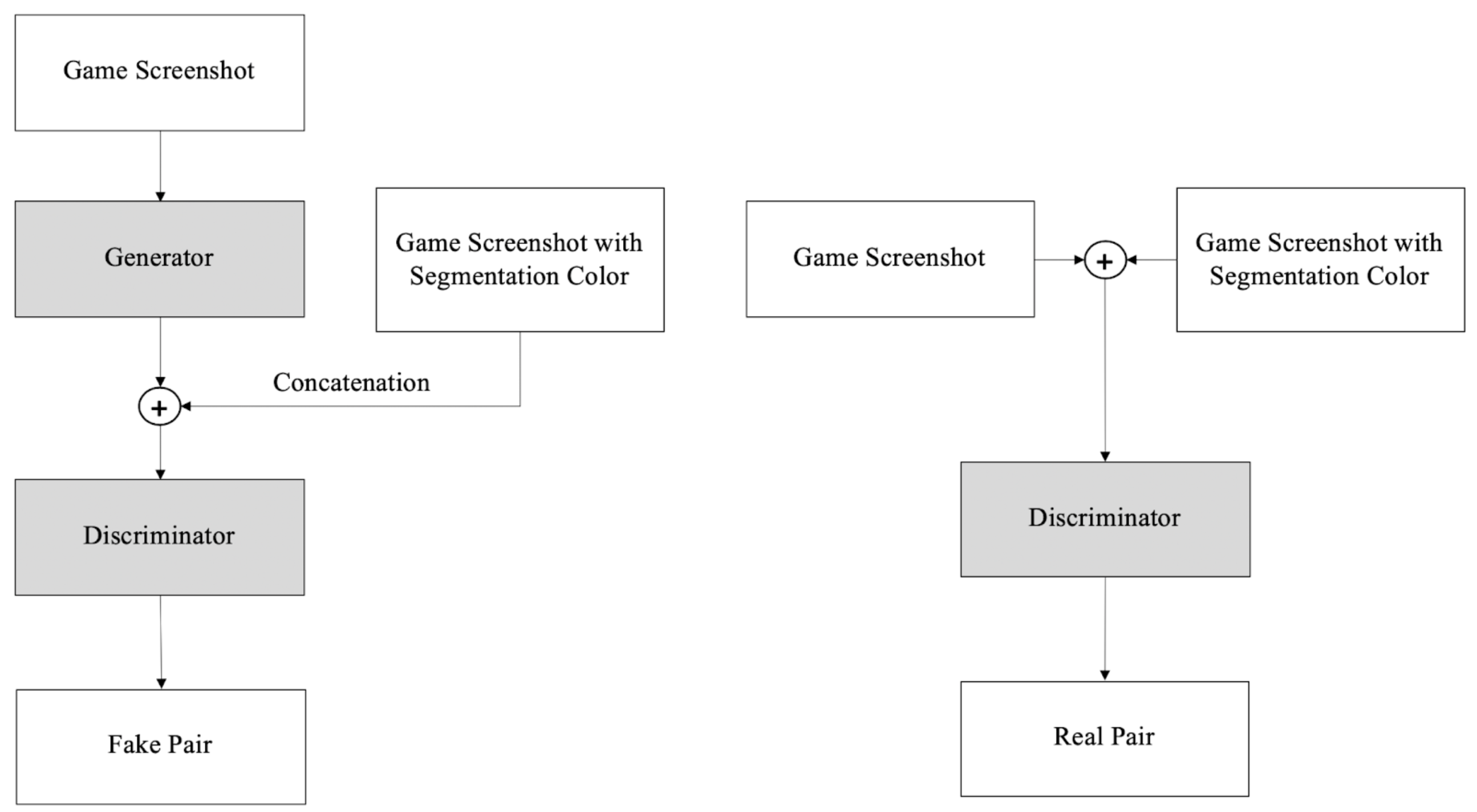
3.2. Network
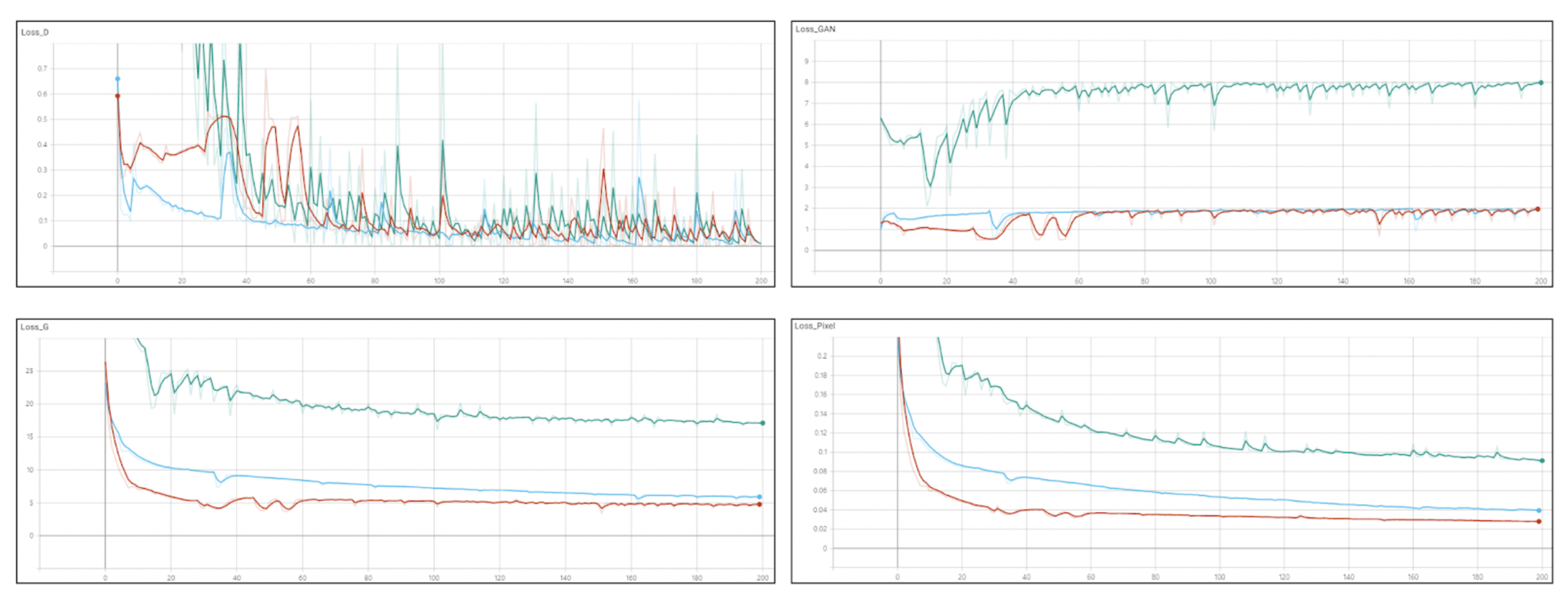
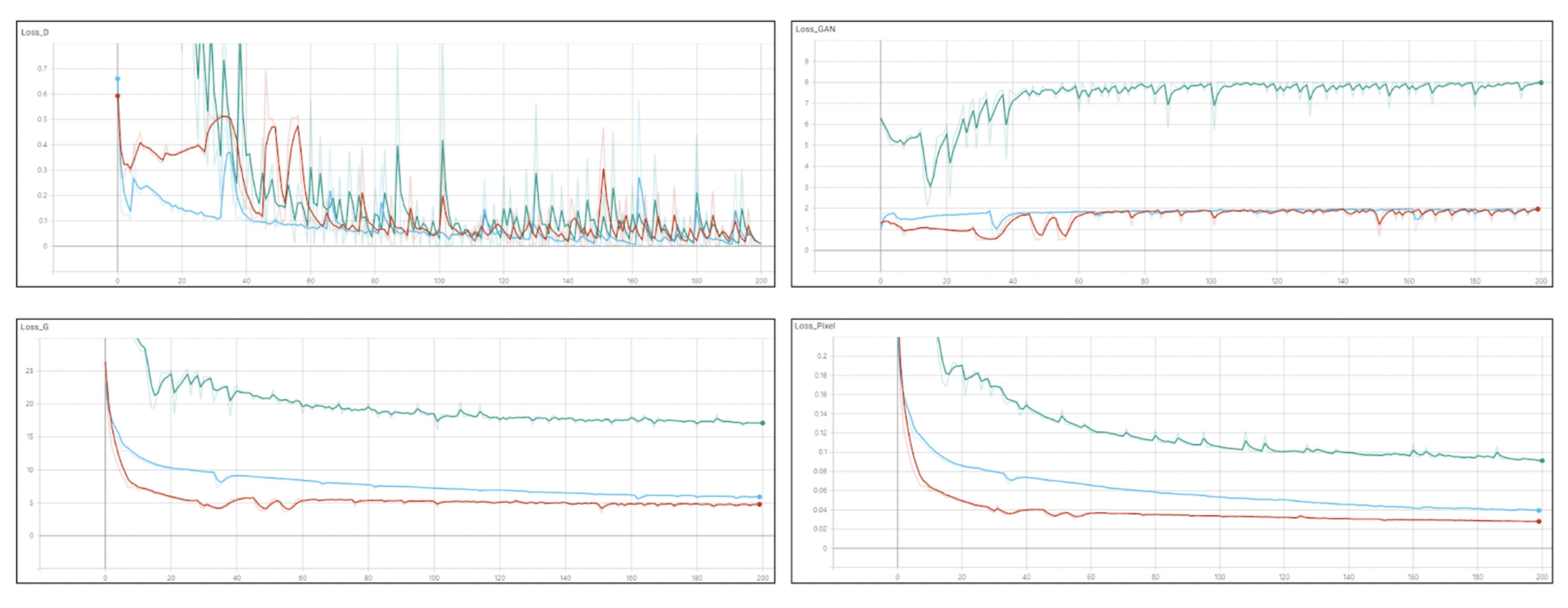
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Giacomello, E.; Lanzi, P.L.; Loiacono, D. DOOM level generation using generative adversarial networks. In Proceedings of the 2018 IEEE Games, Entertainment, Media Conference (GEM), Galway, Ireland, 15–17 August 2018; pp. 316–323. [Google Scholar]
- Volz, V.; Schrum, J.; Liu, J.; Lucas, S.M.; Smith, A.; Risi, S. Evolving mario levels in the latent space of a deep convolutional generative adversarial network. In Proceedings of the Genetic and Evolutionary Computation Conference, Kyoto, Japan, 15–19 July 2018; pp. 221–228. [Google Scholar]
- Awiszus, M.; Schubert, F.; Rosenhahn, B. TOAD-GAN: Coherent Style Level Generation from a Single Example. arXiv 2020, arXiv:2008.01531. [Google Scholar]
- Torrado, R.R.; Bontrager, P.; Togelius, J.; Liu, J.; Perez-Liebana, D. Deep reinforcement learning for general video game ai. In Proceedings of the 2018 IEEE Conference on Computational Intelligence and Games (CIG), Maastricht, The Netherlands, 14–17 August 2018; pp. 1–8. [Google Scholar]
- Nadiger, C.; Kumar, A.; Abdelhak, S. Federated reinforcement learning for fast personalization. In Proceedings of the 2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Sardinia, Italy, 3–5 June 2019; pp. 123–127. [Google Scholar]
- Glavin, F.G.; Madden, M.G. DRE-Bot: A hierarchical First Person Shooter bot using multiple Sarsa (λ) reinforcement learners. In Proceedings of the 2012 17th International Conference on Computer Games (CGAMES), Louisville, KY, USA, 30 July–1 August 2012; pp. 148–152. [Google Scholar]
- Lee, E.; Jang, Y.; Yoon, D.M.; Jeon, J.; Yang, S.I.; Lee, S.K.; Kim, D.W.; Chen, P.P.; Guitart, A.; Bertens, P.; et al. Game data mining competition on churn prediction and survival analysis using commercial game log data. IEEE Trans. Games 2018, 11, 215–226. [Google Scholar] [CrossRef] [Green Version]
- Yang, W.; Huang, T.; Zeng, J.; Yang, G.; Cai, J.; Chen, L.; Mishra, S.; Liu, Y.E. Mining Player In-game Time Spending Regularity for Churn Prediction in Free Online Games. In Proceedings of the 2019 IEEE Conference on Games (CoG), London, UK, 20–23 August 2019; pp. 1–8. [Google Scholar]
- Lee, J.; Lim, J.; Cho, W.; Kim, H.K. In-game action sequence analysis for game bot detection on the big data analysis platform. In Proceedings of the 18th Asia Pacific Symposium on Intelligent and Evolutionary Systems, Singapore, 10–12 November 2014; Springer: Cham, Switzerland, 2015; Volume 2, pp. 403–414. [Google Scholar]
- Zagal, J.P.; Tomuro, N.; Shepitsen, A. Natural language processing in game studies research: An overview. Simul. Gaming 2012, 43, 356–373. [Google Scholar] [CrossRef] [Green Version]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 102–118. [Google Scholar]
- Clark, C.; Storkey, A. Training deep convolutional neural networks to play go. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1766–1774. [Google Scholar]
- Stanescu, M.; Barriga, N.A.; Hess, A.; Buro, M. Evaluating real-time strategy game states using convolutional neural networks. In Proceedings of the 2016 IEEE Conference on Computational Intelligence and Games (CIG), Santorini Island, Greece, 20–24 September 2016; pp. 1–7. [Google Scholar]
- Yakovenko, N.; Cao, L.; Raffel, C.; Fan, J. Poker-CNN: A pattern learning strategy for making draws and bets in poker games using convolutional networks. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Islam, M.S.; Foysal, F.A.; Neehal, N.; Karim, E.; Hossain, S.A. InceptB: A CNN based classification approach for recognizing traditional bengali games. Procedia Comput. Sci. 2018, 143, 595–602. [Google Scholar] [CrossRef]
- Guzdial, M.; Li, B.; Riedl, M.O. Game Engine Learning from Video. In Proceedings of the IJCAI, Melbourne, Australia, 19 August 2017; pp. 3707–3713. [Google Scholar]
- Huang, J.; Yang, W. A multi-size convolution neural network for RTS games winner prediction. In Proceedings of the MATEC Web of Conferences, Phuket, Thailand, 4–7 July 2018; EDP Sciences: Les Ulis, France, 2018; Volume 232, p. 01054. [Google Scholar]
- Reno, V.; Mosca, N.; Marani, R.; Nitti, M.; D’Orazio, T.; Stella, E. Convolutional neural networks based ball detection in tennis games. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1758–1764. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Liao, N.; Guzdial, M.; Riedl, M. Deep convolutional player modeling on log and level data. In Proceedings of the 12th International Conference on the Foundations of Digital Games, Raleigh, NC, USA, 29 May–1 June 2017; pp. 1–4. [Google Scholar]
- Lample, G.; Chaplot, D.S. Playing FPS games with deep reinforcement learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 23 June 2017. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2359–2367. [Google Scholar]
- Bai, M.; Urtasun, R. Deep watershed transform for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 5221–5229. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Peng, C.; Xiao, T.; Li, Z.; Jiang, Y.; Zhang, X.; Jia, K.; Yu, G.; Sun, J. Megdet: A large mini-batch object detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6181–6189. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Kirillov, A.; Levinkov, E.; Andres, B.; Savchynskyy, B.; Rother, C. Instancecut: From edges to instances with multicut. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 5008–5017. [Google Scholar]
- Arnab, A.; Torr, P.H. Pixelwise instance segmentation with a dynamically instantiated network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 441–450. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Pinheiro, P.O.; Collobert, R.; Dollár, P. Learning to segment object candidates. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1990–1998. [Google Scholar]
- Pinheiro, P.O.; Lin, T.Y.; Collobert, R.; Dollár, P. Learning to refine object segments. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 75–91. [Google Scholar]
- Dai, J.; He, K.; Li, Y.; Ren, S.; Sun, J. Instance-sensitive fully convolutional networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 534–549. [Google Scholar]
- Chen, X.; Girshick, R.; He, K.; Dollár, P. Tensormask: A foundation for dense object segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 2061–2069. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Salt Lake City, UT, USA, 18–22 June 2018; pp. 801–818. [Google Scholar]
- Farfade, S.S.; Saberian, M.J.; Li, L.J. Multi-view face detection using deep convolutional neural networks. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 643–650. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. From facial parts responses to face detection: A deep learning approach. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3676–3684. [Google Scholar]
- Li, H.; Lin, Z.; Shen, X.; Br, T.J.; Hua, G. A convolutional neural network cascade for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 5325–5334. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 7263–7271. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. Deepdriving: Learning affordance for direct perception in autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2722–2730. [Google Scholar]
- Taylor, G.R.; Chosak, A.J.; Brewer, P.C. Ovvv: Using virtual worlds to design and evaluate surveillance systems. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Marin, J.; Vázquez, D.; Gerónimo, D.; López, A.M. Learning appearance in virtual scenarios for pedestrian detection. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 137–144. [Google Scholar]
- Vazquez, D.; Lopez, A.M.; Marin, J.; Ponsa, D.; Geronimo, D. Virtual and real world adaptation for pedestrian detection. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 797–809. [Google Scholar] [CrossRef] [PubMed]
- Kingdom Rush, Ironhide Game Studio. Available online: https://android.kingdomrush&hl=en (accessed on 22 August 2020).
- Blade and Soul, NCsoft. Available online: https://www.bladeandsoul.com/en/ (accessed on 22 August 2020).
- Black Desert, Perl Abyss. Available online: https://www.blackdesertonline.com/hashashin (accessed on 22 August 2020).
- Iron Marine, Ironhide Game Studio. Available online: https://android.ironmarines (accessed on 22 August 2020).
- World of Warcraft, Blizzard. Available online: https://worldofwarcraft.com/ (accessed on 22 August 2020).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| no. | Color (R, G, B) | No. | Color (R, G, B) | No. | Color (R, G, B) |
|---|---|---|---|---|---|
| 1 | (0.0, 0.0, 0.0) | 6 | (0.0, 1.0, 1.0) | 11 | (0.0, 0.5, 0.0) |
| 2 | (1.0, 1.0, 1.0) | 7 | (1.0, 0.0, 1.0) | 12 | (0.0, 0.0, 0.5) |
| 3 | (1.0, 0.0, 0.0) | 8 | (1.0, 1.0, 0.0) | 13 | (0.0, 0.5, 0.5) |
| 4 | (0.0, 1.0, 0.0) | 9 | (0.5, 0.5, 0.5) | 14 | (0.5, 0.0, 0.5) |
| 5 | (0.0, 0.0, 1.0) | 10 | (0.5, 0.0, 0.0) | 15 | (0.5, 0.5, 0.0) |
| Kingdom Rush | Blade and Soul | Black Desert | |
|---|---|---|---|
| Number of Segmented UI Components | 7 | 30 | 37 |
| Size of a Single Button (Approx.Pixel) | Large (25 × 25) | Small (5 × 5) | Small (5 × 5) |
| Spacing between UI Components (Approx.Pixel) | Long (5 pixel) | Short (1–2 pixel) | Short (1–2 pixel) |
| Overall Complexity | Low | High | High |
| Pixel Accuracy | 0.882 | 0.851 | 0.842 |
| Mean Accuracy | 0.820 | 0.797 | 0.777 |
| Mean IU | 0.707 | 0.665 | 0.671 |
| Frequency Weighted IU | 0.793 | 0.734 | 0.791 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, S.; Choi, J.-i. Instance Segmentation Method of User Interface Component of Games. Appl. Sci. 2020, 10, 6502. https://doi.org/10.3390/app10186502
Kang S, Choi J-i. Instance Segmentation Method of User Interface Component of Games. Applied Sciences. 2020; 10(18):6502. https://doi.org/10.3390/app10186502
Chicago/Turabian StyleKang, Shinjin, and Jong-in Choi. 2020. "Instance Segmentation Method of User Interface Component of Games" Applied Sciences 10, no. 18: 6502. https://doi.org/10.3390/app10186502
APA StyleKang, S., & Choi, J.-i. (2020). Instance Segmentation Method of User Interface Component of Games. Applied Sciences, 10(18), 6502. https://doi.org/10.3390/app10186502