1. Introduction
The proportional navigation guidance (PNG) is known as a quasi-optimal of interception guidance law. The simple concept of it can be found in nature. The authors of [
1] show that it is possible to explain predatory flies’ pursuit trajectories with the PNG, in which a rotation rate of a pursuer can be modeled as a multiplication of specific constant and line-of-sight (LOS) rate. In [
2], the authors also describe the terminal attack trajectories of peregrine falcons as PNG. The head of a falcon acts as a gimbal of missile seeker, guiding its body like a modern missile does. That shows centuries of training and evolution possibly brought those creatures to fly with quasi-optimal guidance and gives us an insight to see those natural phenomena with engineered mechanisms on the same boundary. Reinforcement learning (RL)-based training has a similar process. Each generation of an animal and an RL agent act stochastically, have some mutational elements, and follow what has a better reward, and aims for the optimal. Meanwhile, some studies on RL-based missile guidance law have and have carried on. Accordingly, Gaudet [
3] had suspected an RL-based guidance law may help the logic itself to become robust. He proposed an RL framework that has the ability to build the guidance law for the homing phase. He trained Single-Layer Perceptron (SLP) by the stochastic search method to build a guidance law. Reinforcement learning-based missile guidance law surprisingly works well on the noisy stochastic world, possibly because its algorithm is based on probability. He brought PNG and Enhanced PNG as the comparison targets and showed that the RL generated guidance law has better performance in terms of energy consumption and miss distance than the comparison targets concerning the stochastic environment. Additionally, in another paper [
4], he proposed a framework for 3-dimensional RL-based guidance law design for an interceptor trained via the Proximal Policy Optimization (PPO) [
5] algorithm, and showed by comparative analysis that the derived guidance law also has better performance and efficiency than the augmented Zero-Effort Miss policy [
6]. However, previous research on RL-based missile guidance law compared policies that have a state of unidentical input, so the comparison is deemed unfair.
Optimization of RL policy depends on the reward, which is effective when the reward can indicate which policy and single-action is better than the others. Besides, the missile guidance environment we are dealing with makes it harder for RL agents to acquire an appropriate reward. For this kind of environment, called a sparse reward environment, some special techniques were introduced. The simplest way to deal with such a sparse reward environment is by giving an agent a shaped reward. While general rewards are formulated with a binary state, e.g., success or not, shaped reward implies the information of the goal, e.g., formulate reward as a function of the goal. The authors of [
7] proposed an effective reward formulation methodology that is in accordance with the optimization delay due to the sparse reward. A sparse reward can hardly show what is better, so it makes the reward validity weak and training slow. Hindsight Experience Replay (HER) is a replay technique that makes the failed experience an accomplished one. DDPG [
8] combined with this technique shows faster and more stable training convergence than the original DDPG training method. HER has pumped up the learning performance with binary reward by mimicking human learning that we learn not only from accomplishments but even from failures.
This paper presents a novel training framework of missile guidance law and compares trained guidance law with PNG. Additionally, a comparison of the control-system-applied environment will be shown since the overall performance or efficiency of a missile is not only affected by its guidance logic but is affected by the dynamic system as well. The control system which connects guidance command to reality always has a delay. In missile guidance, a system can possibly make the missile miss the target and consume much more energy than expected. There is research on missile guidance to make it robust on uncertainties and diverse parameters. In [
9], Gurfil presents a guidance law that works well even in an environment with missile parametric uncertainties. He focused on building a universal missile guidance law that even covers missiles having different systems. i.e., the purpose is making missiles work well with zero miss distance guidance even if they have various flight conditions. The result he showed was assuring zero miss distance for uncertainties. Additionally, due to the simplicity of the controller that the guidance law needs, proposed guidance law has simplicity in implementation.
The paper will first, in the problem formulation, define environments and engagement scenarios, and overviews of PNG and training methods will be continued therefrom. Finally, simulation results and conclusion will follow.
3. Proportional Navigation Guidance Law
Proportional navigation guidance (PNG) is the most widely used guidance law on homing missiles with an active seeker [
2,
11,
12]. PNG generates an acceleration command by multiplying the LOS rate and velocity with a predesigned gain. The mechanism reduces the look-angle and guides the missile to hit the target.
The acceleration command by PNG in the planar engagement scenario is as follows:
where
is navigation constant (design factor),
is the speed of the missile, and
is the LOS rate.
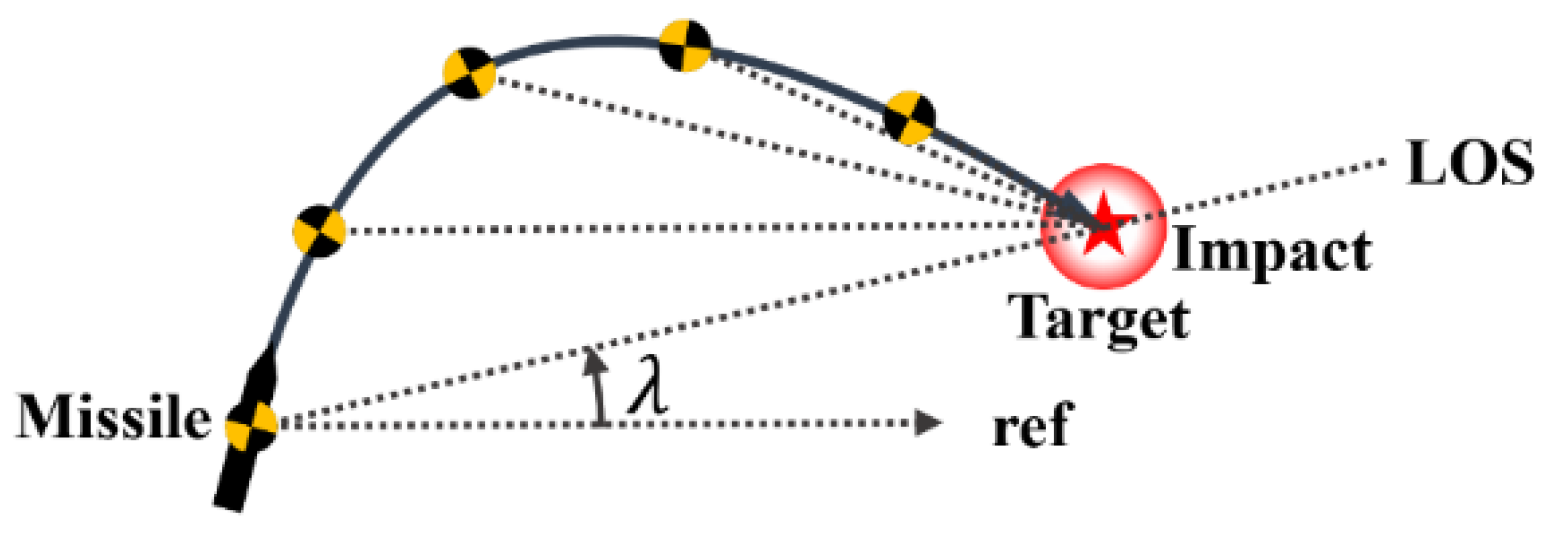
Figure 4 shows the conceptual diagram of PNG.
Meanwhile, Pure PNG, which is one of the branches of PNG, is adopted in this paper. Pure PNG is used for a missile to hit a relatively slow target like a ship. The acceleration axis of the Pure PNG is attached perpendicular to the missile velocity vector as it is shown in
Figure 1. Additionally, the velocity term in Equation (10) of Pure PNG is the inertial velocity of the missile. PNG is very useful, and it basically is even optimal for missile guidance. Technically, creating a missile guidance law that has better performance than PNG, despite sharing the same engagement scenario that PNG is specialized for, is not possible under ideal circumstances. However, PNG is not optimized for practice. Thus, we will figure out whether RL-based is able to exceed the performance of PNG when the simulation environment gets more practical, i.e., applying a controller model. Of course, we did not apply the practical model to training but applied them to the simulation part.
The overall structure of the PNG missile simulation is shown in
Figure 5.
4. Reinforcement Learning
Prior research on RL-based missile guidance was studied under a very limited environment and did not show whether a single network can cover a wide environment and initial conditions which push the seeker to the hardware-limit or not. Additionally, the comparison had been implemented under an unfair condition for the comparison target, which each of them does not take identical states. In this paper, it is demonstrated that the RL-based guidance is able to cover a wide environment under plausible wide initial conditions, and with various system models. In this section, a novel structure and methodology for training will be proposed. We adopted a Deep Deterministic Policy Gradient (DDPG)-based algorithm [
8]. DDPG is a model-free reinforcement learning algorithm that generates deterministic action in continuous space, which makes off-policy training available. The NN we used was optimized via gradient descent optimization. Since the environment we are dealing with is vast and can be described as a sparse reward environment, conventional binary rewards nor even a simple shaped reward do not really help to accelerate training. Thus, the algorithm we used in this paper was slightly modified by making every step of an episode get an equational final score of the episode as a reward. It helps the agent to effectively consider the reward of the far future.
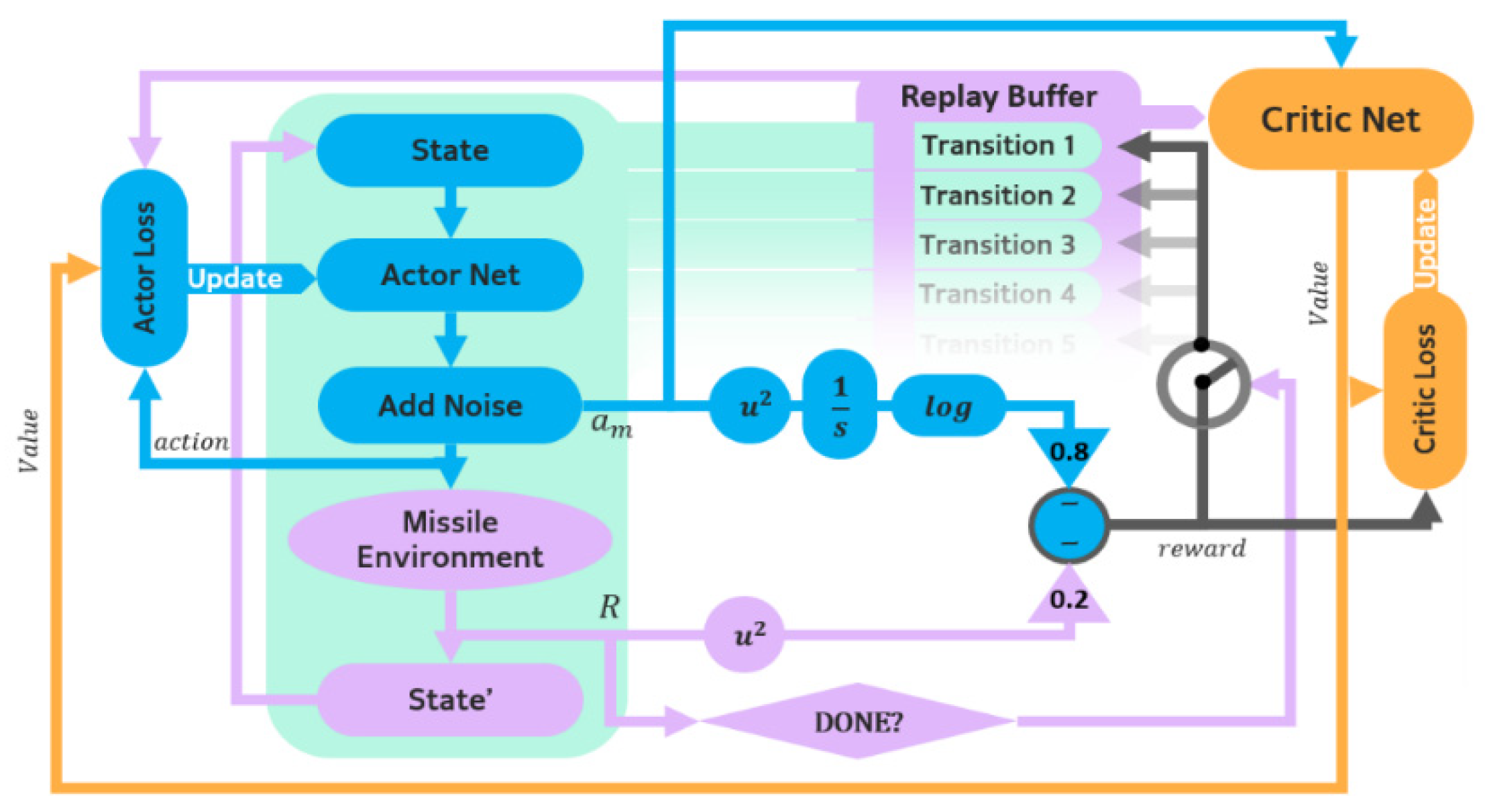
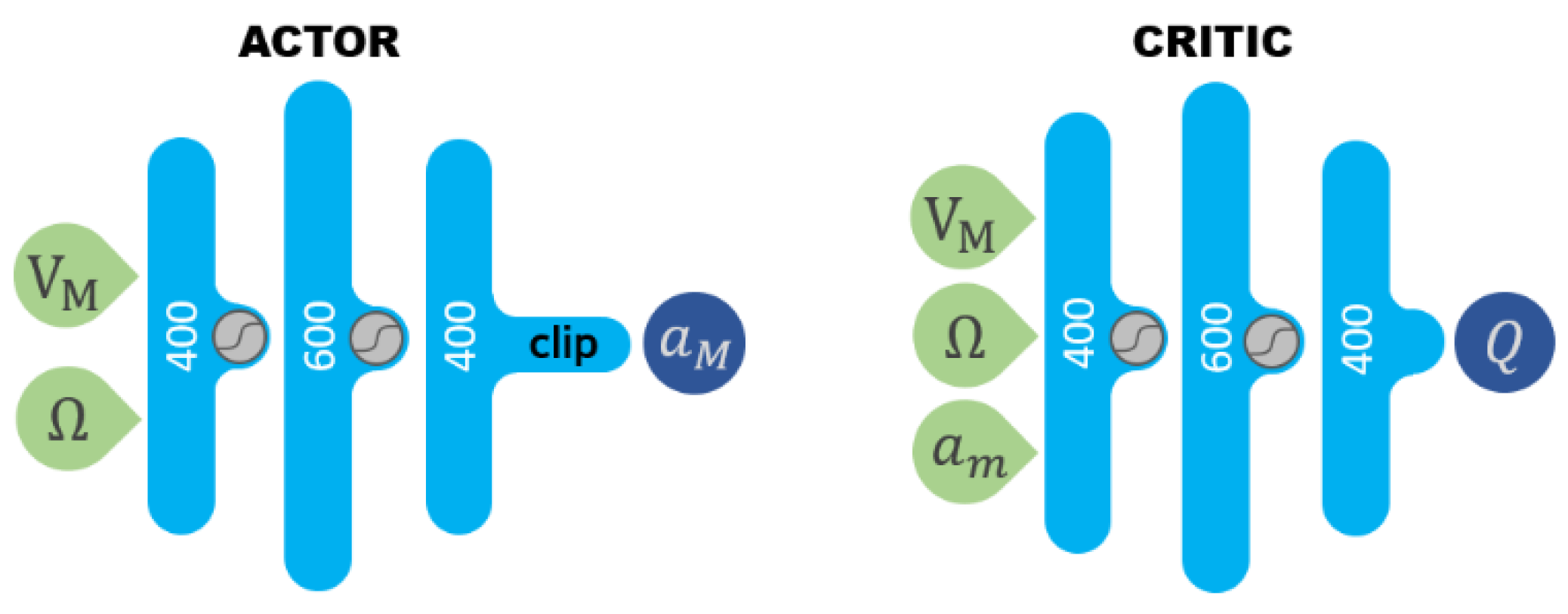
Figure 6 is an overview of the structure we designed. The agent feeds Ω and
as input and stores a transition dataset, which consists of state, action, reward, and next state into a replay buffer.
Developed policy gradient algorithm using an artificial neural network (ANN) needs two separated ANNs which are the actor that estimates the action and the critic that estimates the value.
Figure 7 shows each structure. DDPG, generally, calculates its critic loss from the output of the critic network and the reward of a randomly sampled minibatch, and updates the critic and the actor every single step. Q is the action value, and
![Applsci 10 06567 i001]()
is the hyperbolic tangent activation function.
Both consist of three steps of hidden layers, and actor-network has ±10 g of clipping step as we set. We used the Huber function [
13] as a loss function that shows high robustness to outlier and excellent optimization performance. The equation is as follows:
The training proceeds with a designed missile environment. The environment terminates the episode if it encounters one or more termination conditions as follows—Out of Range condition: target information unavailable since the target is outside of the available field of view of the missile seeker; Time Out condition: time exceeds the maximum timestep which is 400 s; there is also a Hit condition (
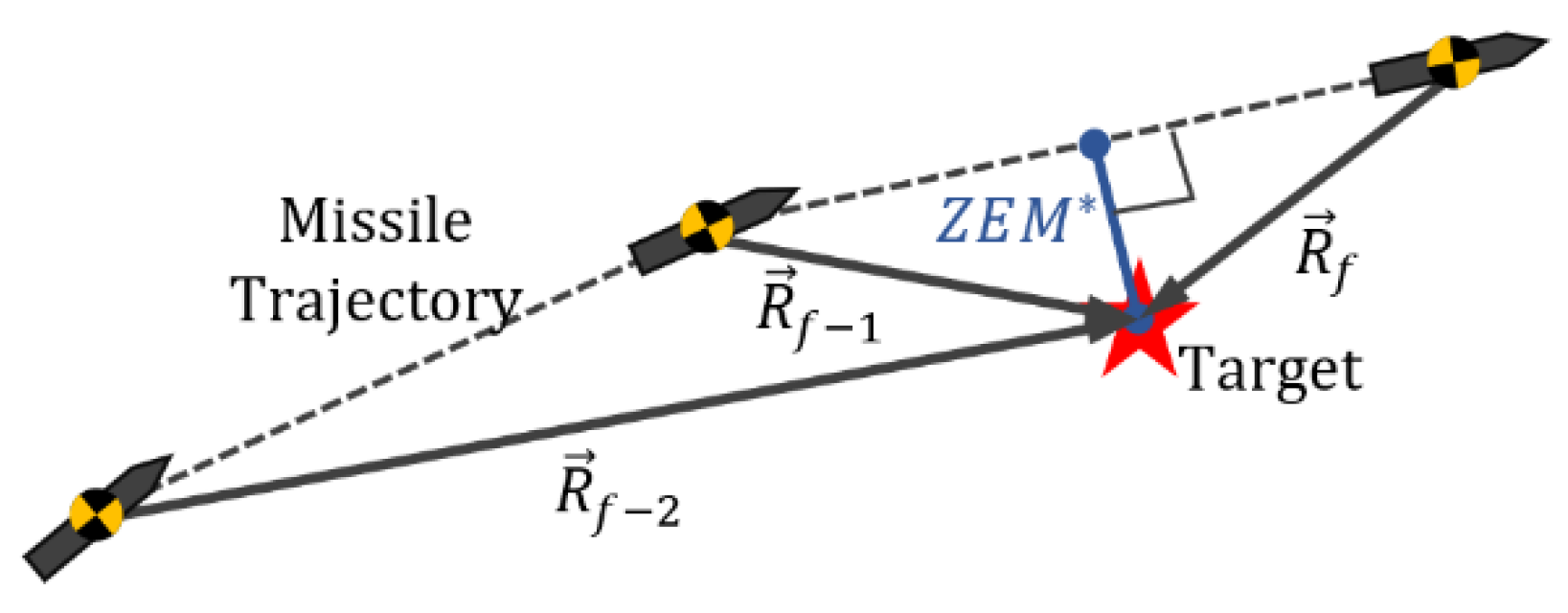
): judged that the missile hits the target. However, the last condition is not for termination, but exists as an observable data that decides whether the policy is proper for the mission or not. As an episode ends, each of the transition datasets gets the corresponding reward which is the final integrated reward of the episode. We estimated the closest distance between a missile and a target to interpolate the closest approach in a discrete environment as follows:
where
is when Hit condition is true,
is
at the final state,
is defined in Equation (8).
The reward is designed with the concept that its maximization minimizes the closest distance between the missile and the target and aims for saving energy as much as possible. To achieve that, two branches of reward term should be considered. One of them is a range reward term. The range reward term should get value from how the missile approaches close to the target. We used negative log-scaled
(the impact distance error of an episode) as a reward to make the reward overcome the following problem. A simple linear scale reward may cause inconsistency and high variance of reward. While an early training is proceeding in the environment, the expected bounds of
is from 0 to
. This colossal scale disturbs the missile not to approach extremely close to the target since the reward of the terminal stage only seemingly slightly varies the variance of reward even if there are distinguishable good and bad actions. Besides, the log-scaled
helps the missile get extremely close to the target by amplifying the small value of
at impact stages. We express the range reward as
and is as follows:
where
(tolerance term for log definition) is set to
. The second branch is an energy reward term. It represents the energy consumption in an episode. The energy term should be distinguishable from what is better or not regardless of the initial condition. Therefore, it must contain influences from the flight range and the initial look-angle. The energy reward term also has a high variance between the early stage and the terminal stage. For the earlier stage, the missile is prone to terminate its episode earlier because the Out of Range termination condition can be satisfied early when the policy is not that well established. In other words, the magnitude of the energy reward term can be too small. Thus, the log-scaled reward was also applied in the energy reward term as follows:
where
is acceleration,
is the termination time.
Therefore, the total reward is a weighted sum of both (13) and (14) as follows
where
and
are weights for each reward that satisfy
,
and
are the means and standard deviations for normalization, respectively, and subscripts represent the properties of each reward.
Table 2 shows the termination conditions and corresponding rewards.
An aspect of the case that satisfies the Time Out condition while Out of Range condition is not satisfied is the maneuver in which the missile is approaching infinitely in spiral trajectory, which made us aware that the magnitude of the cost was becoming too big. Thus, we considered the maneuvers as outliers and gave them the lowest score and stored them to the replay buffer. The overall structure of the RL missile simulation is shown in
Figure 8.
Our rewarding method makes the agent trained faster than the general DDPG algorithm and makes the training stable. Clearly, our rewarding method works better for the sparse reward and vast environment of our missile, and the learning curves for them are shown in
Figure 9.
The full lines represent the reward trend and color-filled areas represent local mins and maxes. Additionally, all data was plotted by applying a low pass filter for the intuitive plot.
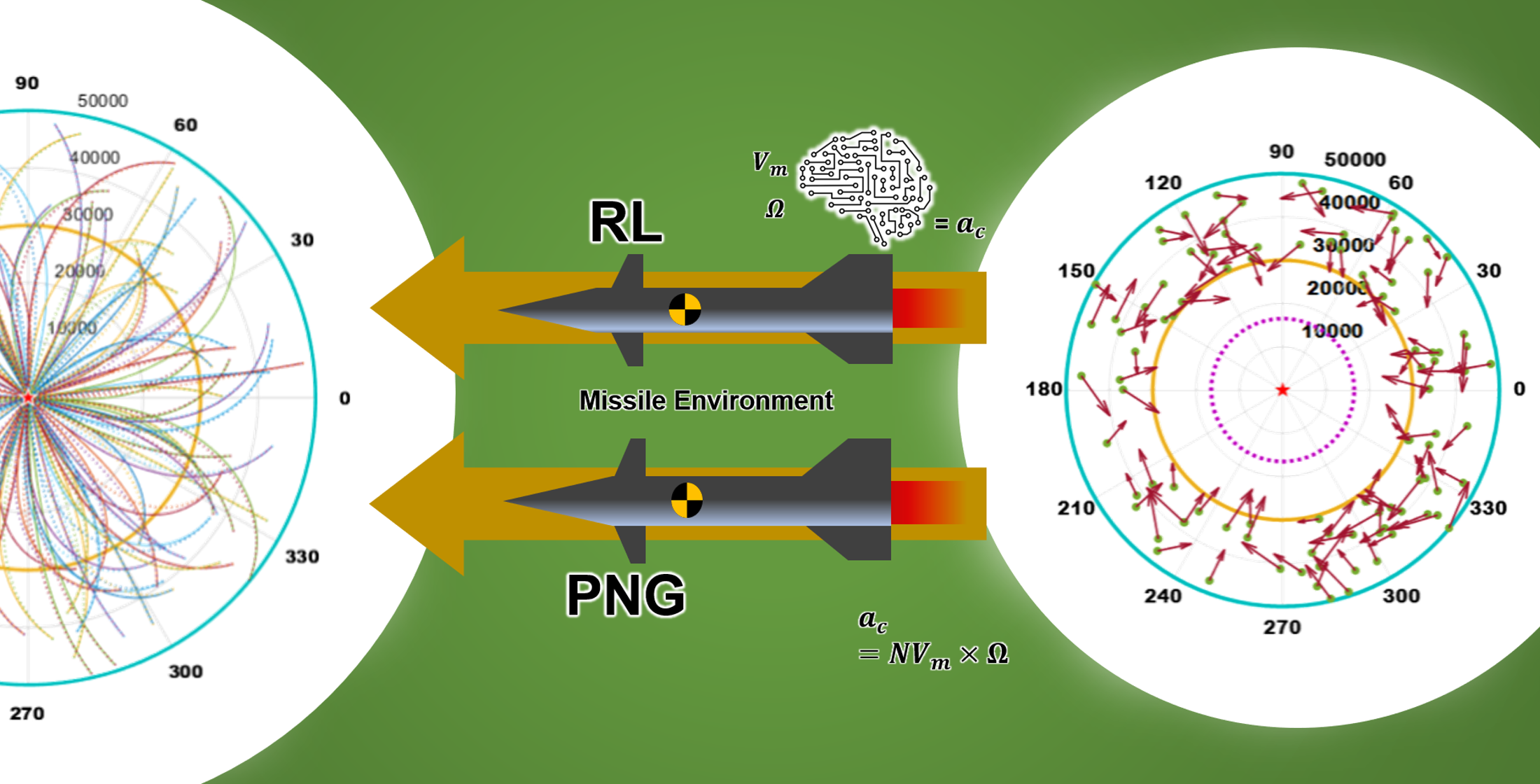
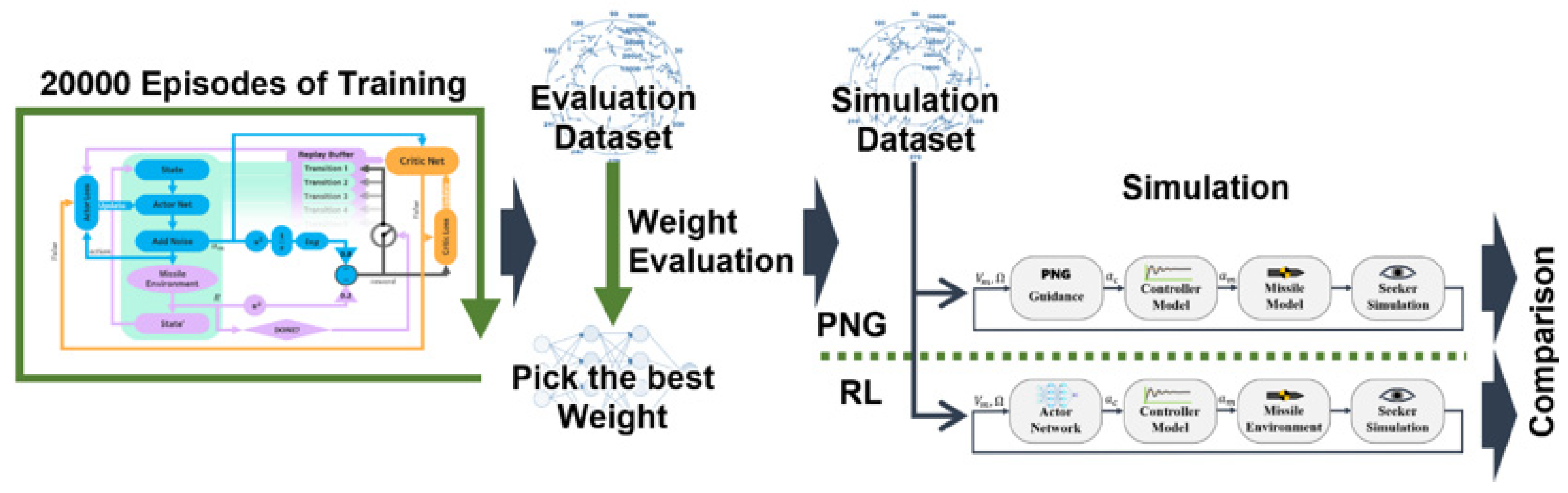
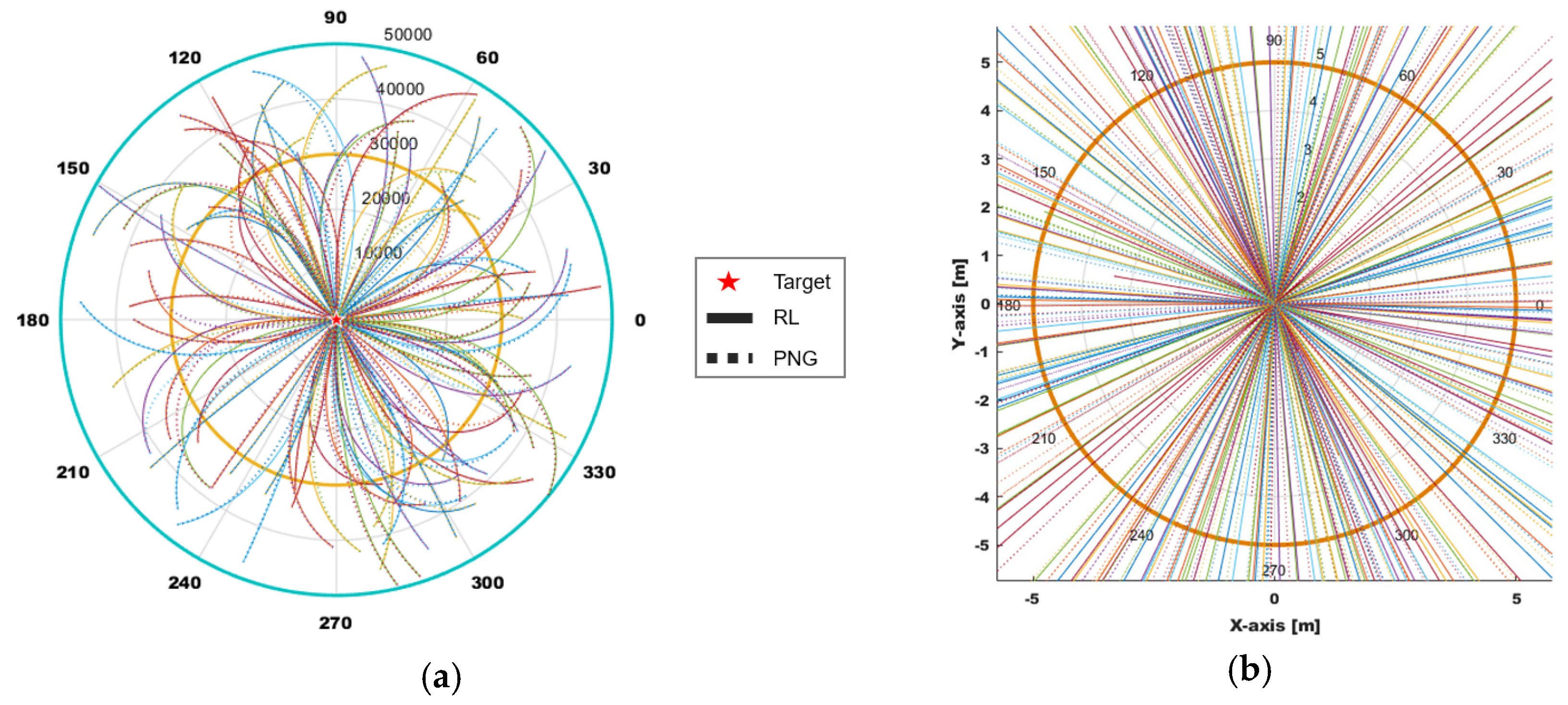
After the training of 20,000 episodes, we implemented the utility evaluation of each trained weight. Specifically, the training started to converge at about the 70th episode via the training structure we designed. Yet, for finding the most optimized weight, we ran the test algorithm with each trained weight by feeding 100 of the uniformly random predefined initial conditions dataset. The dataset was set to range from 30,000 m to 50,000 m as depicted in
Figure 10. It is because we wanted a weight that covers universal conditions. The ZEM* was not considered to decide the utility as long as the ZEM* was less than 5 for all predefined initial conditions. In addition, the weight having the best utility was decided by selecting a weight that has a minimum average
for all predefined initial conditions. In
Figure 10, the vectors and green dots represent the initial headings and the launching position, respectively.
The flow chart for overview of this study is shown in
Figure 11.
6. Conclusions
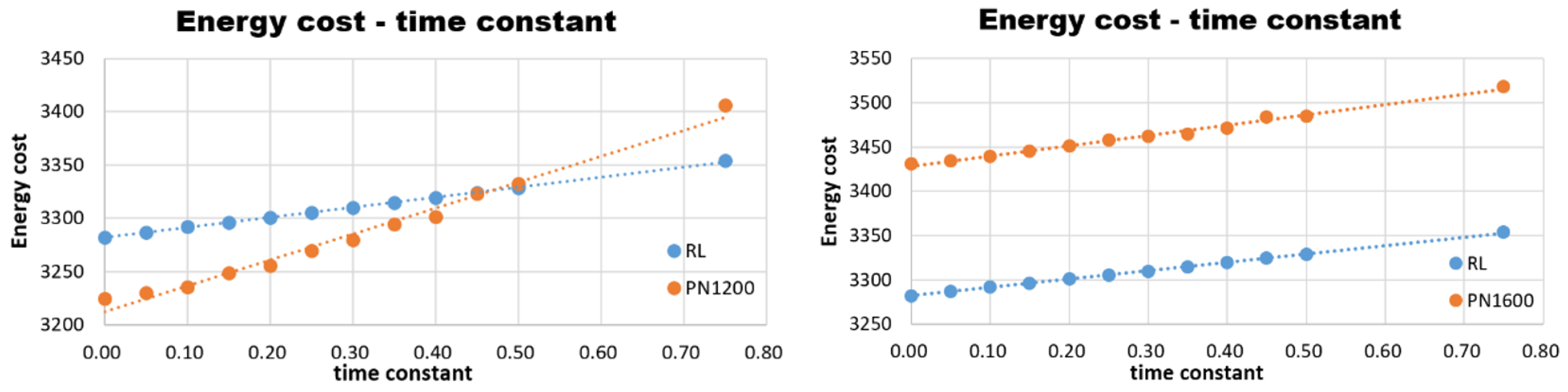
The novel rewarding method, performance, and special features of RL-based missile guidance were presented. We showed that a wide environment of missile training can be trained faster with our rewarding method of Monte-Carlo based shaped reward rather than temporal difference training methodology. Additionally, the performance comparison was presented. This showed that the energy-wise performance of our RL-based guidance law and PNG with navigation constant of 3 to 4 were similar, when using a system that immediately acts. Yet, when it comes to the delayed 1st order system, RL-based shows better energy-wise system robustness than PNG. Moreover, we showed that the RL-based missile guidance algorithm could be formulated without the input state of V. Additionally, this algorithm has better robustness to the controller models than PNG without V. Its significant expandability is that it can replace PNG and has good robustness to the controller model without designing a specific guidance law for the controller model of a missile itself.
This paper showed that RL-based not only can easily replace the existing missile guidance law but is also able to work more efficiently in various circumstances. These special features give insights into the RL based guidance algorithm which can be expanded for future work.




 is the hyperbolic tangent activation function.
is the hyperbolic tangent activation function.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}