1. Introduction
The monitoring of Respiratory Rate (RR) is a relevant factor in medical applications and day-to-day activities. Contact sensors have been used mostly as a direct solution and they have shown their effectiveness, but with some disadvantages. In general, the main inconveniences are related to the correct and specific use of each contact sensor, the stress, pain, and irritation caused, mainly on some vulnerable skins, like neonates and burns patients [
1]. For a review of contact-based methods and comparisons see [
2]. Contactless breathing monitoring is a recent research interest for clinical and day-to-day applications; a review, and comparison of contactless monitoring techniques can be seen in [
3]. In this paper, the literature review is restricted to respiratory activity and the works concerning the detection of cardiac activity are not included voluntarily.
There are three main categories for contactless RR monitoring methods. The first group includes non-image-based proposals, like radar sensor approaches [
4,
5] and sound-based approaches [
6]. The main disadvantage of radar methods is that the antenna must be in front of the thoracic area, a restriction that cannot always be met [
7], and for sound-based approaches ambient noise remains a difficulty for the extraction of signal [
3]. Other recent approaches include smart textiles for respiratory monitoring with evident restriction in some medical applications [
8]. The second group includes different kinds of image sensing. Thermal images [
9,
10,
11] measure the temperature variations between inhalation and exhalation phases with it not working if the nasal area is not visible. In recent years, several works have used the photoplethysmography technique, employed initially to measure cardiac frequency [
12], to measures skin blood changes to track RR [
13,
14,
15,
16,
17,
18]. Some works such as [
18] train a CNN using respiratory raw signal as reference and a skin reflection model to represent the color variations of the image sequence as input. This technique is robust for extracting signal in both dark and light lighting conditions [
14]; the motion artifacts can be corrected [
17] and can be introduced to a multi-camera system for tracking cardiorespiratory signals for multiple people [
19]. This method is promising; however, the skin must always be visible, a condition that is not met in some positions of the subject. Other methods directly extract the respiratory signal from the motion detected on the RGB video. Different strategies to track motion are proposed. For example, Massaroni et al. [
20] employed frame subtraction and temporal filtering to extract signal, and Chebin et al. detected the motion of the face and the shoulders for a spirometry study [
21]. Several works have used magnification video motion technique to track subtle motions [
22]. This last technique allows revelation of invisible motions due to respiratory rhythm [
23,
24,
25,
26,
27]. The third category uses hybrid techniques applying image-based and non-image-based approaches. For example, in [
28], a sleep monitoring system using infrared cameras and motion sensors is proposed.
Motion magnification methods compute respiratory rate by detecting motions of the thoracic cavity. Their main advantages are that they need only an RGB camera, and the measurement can be taken in different thorax cavity regions, as opposed to thermal and photoplethysmography techniques that require a specific region to extract signal. Motion magnification can be categorized according to the magnification of the amplitude [
23,
24,
29,
30] or the phase of the signal [
25,
26]. It is shown in [
31] that phase amplitude produces a lower noise level in magnified signal compared to amplitude magnification; however, algorithm complexity is higher. Phase magnification also allows discrimination of large motions not related to respiratory activity as shown by Alinovi et al. [
25] or a motion compensation strategy to stabilize RR reported by [
26]. Different decomposition techniques are used to carry out magnification. Al-Najia and Chahl [
30] present a remote respiratory monitoring system to magnify motion using the Wavelet decomposition obtaining smaller errors in RR estimation than with use of traditional Laplacian decomposition. Other works [
27,
32] show that the magnification Hermite approach allows a better reconstruction and a better robustness to the noise than traditional Laplacian decomposition used in [
22]. The camera distance to the subject is an important parameter; in general, systems use short distances but as shown by Al-Najia et al. [
23], magnification techniques allow usage of long ranges for monitoring vital signs. Another important characteristic is the possibility of processing after magnification using other techniques as optical flow [
24].
Major research using motion-detection techniques to estimate RR is reviewed and summarized in
Table 1. Most studies listed in
Table 1 were limited to use of motion magnification method from a single subject and for short distances. In this
Table 1, the characteristics of each method to extract RR is summarized: choice of ROI (manually [
20,
29,
30], automatically [
18,
24,
25], or not ROI [
26] ), the kind of signal extracted to estimate RR (raw respiratory signal [
18,
20,
24,
25] or binary signal corresponding to inhalations and exhalations [
26,
29,
30]), the method to obtain motion (amplitude magnification [
24,
29,
30], phase magnification [
25,
26], frame subtraction [
18]), the obtaining of the reference used to validate the method (visually using magnified video directly [
24,
26,
29,
30], using an electronic device [
20,
25,
26]) and the number of subjects used in the work to validate the method. All works in this review use their own database. In the last column in
Table 1 the metric error to measure the assessment of each method is shown. Most methods use Mean Absolute Error (MAE) defined as the absolute value of the difference between the reference value and the estimated value with units of breaths per minute (bpm), or its version in percentage, normalizing the error by reference value. Other works [
25] use Root Mean Squared Error (RMSE) between estimated RR and the reference one. Bland–Altman (BA) analysis [
33] was used to obtain the Mean of the Differences (MOD) between the reference value and the estimated value and the limits of Agreements (LOAs) values that are typically reported in other studies and very useful for comparing our results to relevant scientific literature [
20,
30]. In addition, correlation coefficients as Spearman coefficients (SCC) and Pearson coefficients (PCC) are also reported in some works [
30].
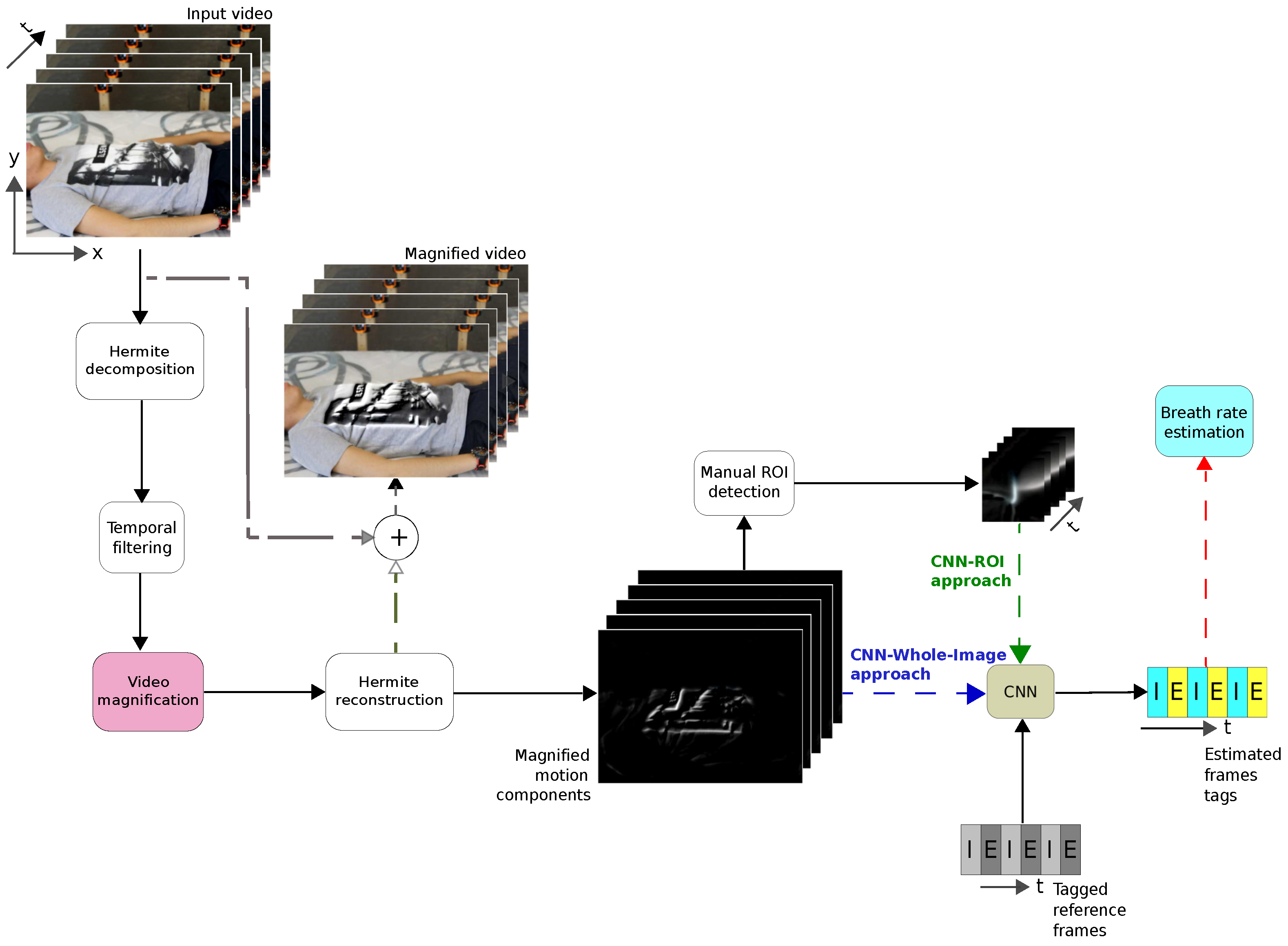
In this paper, we present a combined strategy using motion magnified video and a Convolutional Neural Network (CNN) to classify inhalations and exhalations frames to estimate respiratory rate. First, a Eulerian magnification technique based on Hermite transform is carried out.
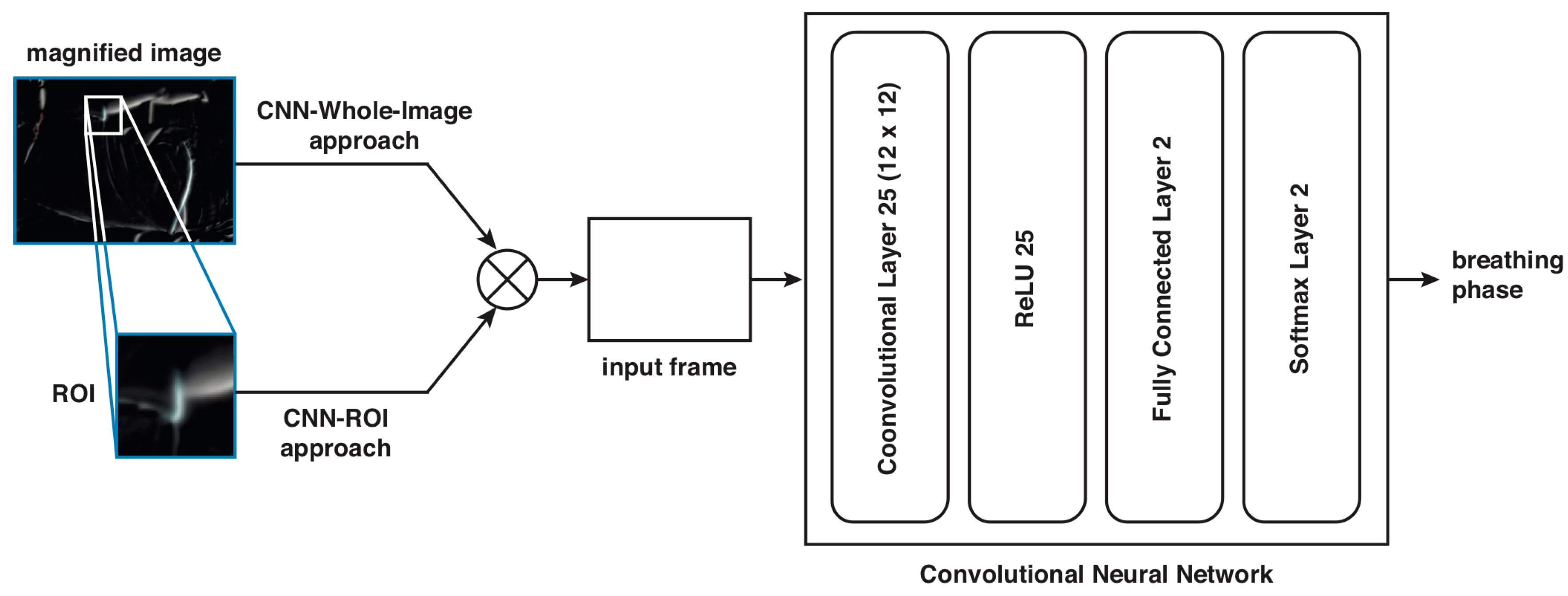
Then, the CNN is trained using tagged frames of reconstructed magnified motion component images. Two strategies are used as input to the CNN. In the first case, a region of interest (ROI) is selected manually on the image frame (CNN-ROI approach) and in the second case, the whole image frame is selected (CNN-Whole-Image proposal). The CNN-Whole-Image proposal includes three approaches: using as input the original video, the magnified video, and the magnified components of the sequence.
Finally, RR is estimated from the classified tagged frames. The CNN-ROI proposal is tested on five subjects lying face down and it is compared to a procedure using different image processing methods (IPM) presented in [
29,
30] to tag the frames as inhalation or exhalation, while the final CNN-Whole-Image proposal is tested on ten subjects in four different positions (lying face down, lying face up, seat and lying fetal). We compared the different approaches computing a percentage error regarding a visual reference of the RR.
The contribution of this work is that the final proposed system does not require the selection of a ROI as others methods have reported in the literature [
18,
20,
23,
24,
25,
26,
34]. In addition, to the best of our knowledge, this is the first time that a CNN is trained using tagged frames as inhalation and exhalation, instead of a raw respiratory rate signal used to train other CNN strategies [
18]. Our tagging strategy for training the CNN uses only two classes and is simple to implement.
Table 1 puts into context our proposal with respect to the other important works in the literature.
The paper is organized as follows.
Section 2 presents the methodology of the proposed system including the description of the motion magnification technique, the two training strategies, and the respiratory rate measuring method.
Section 3 presents the experimental protocol and the results obtained from the trained CNN. Finally, conclusions are given in the last section.
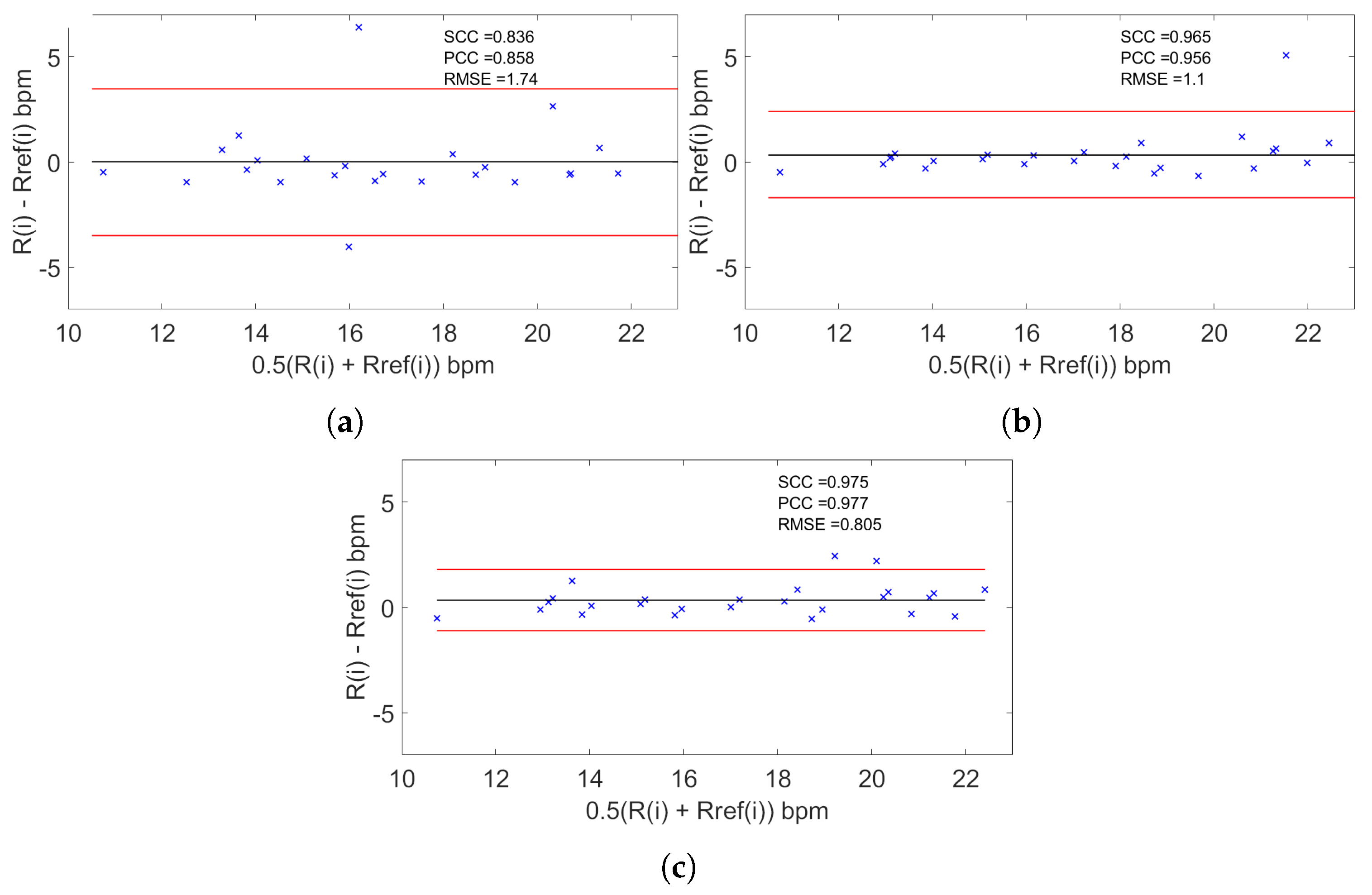
4. Discussion
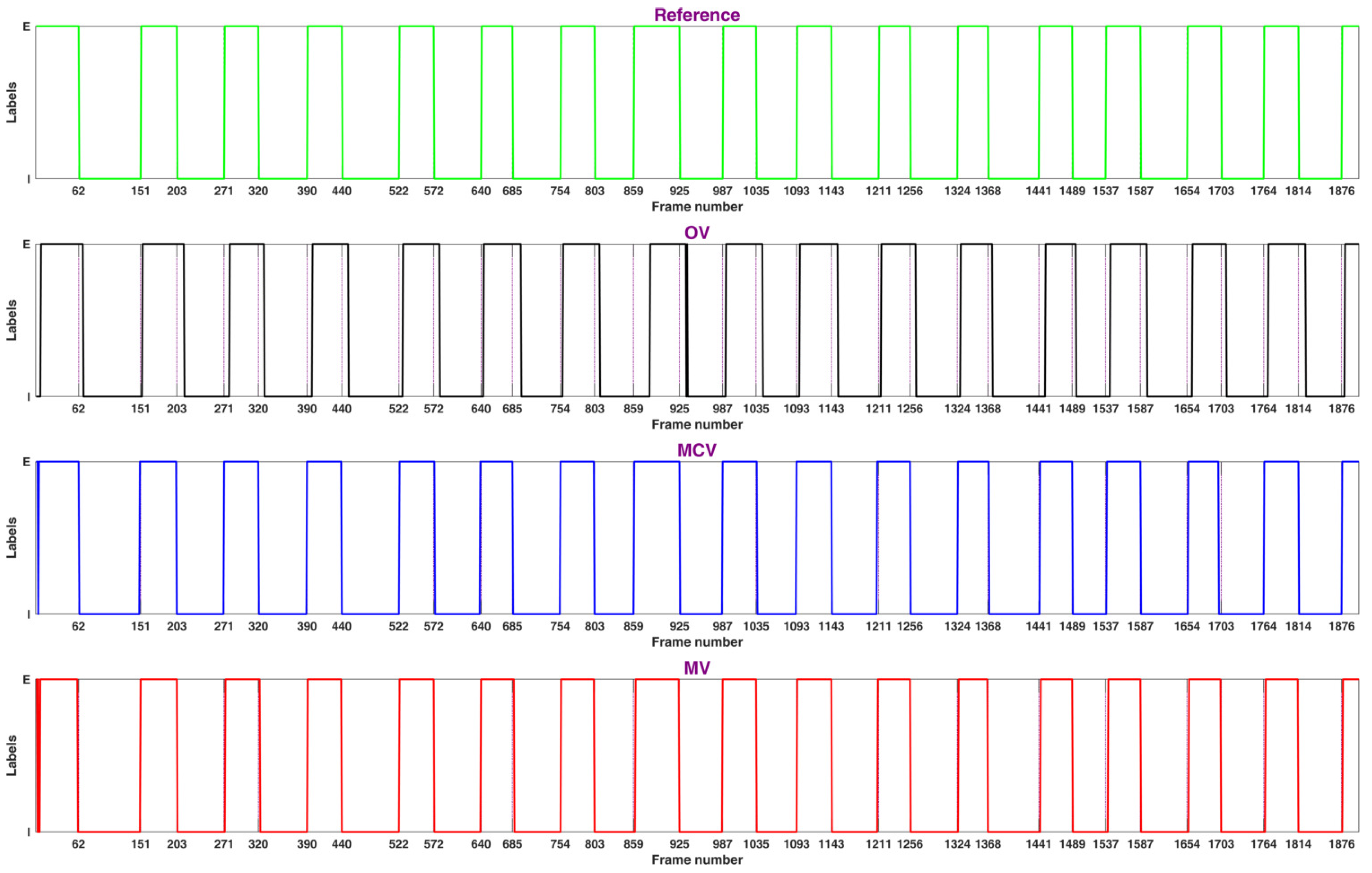
The proposed system succeeded in measuring RR for subjects at rest in different positions. In
Table 5 the quality metrics used in the reviewed works and in our proposal are shown. It is clear that using the MCV strategy, estimation was in close agreement (≈98%,
) with the reference obtained by visual counting in contrast to the MV, where the agreement fell to ≈97% (
) and to the OV strategy, where the agreement fell to ≈96% (
). Hence, it is observed that the difference error with respect to the reference based on the MCV strategy fell to
bpm with a MAE of
while the MV strategy fell to
bpm with a MAE of
and the OV strategy fell to
bpm a MAE of
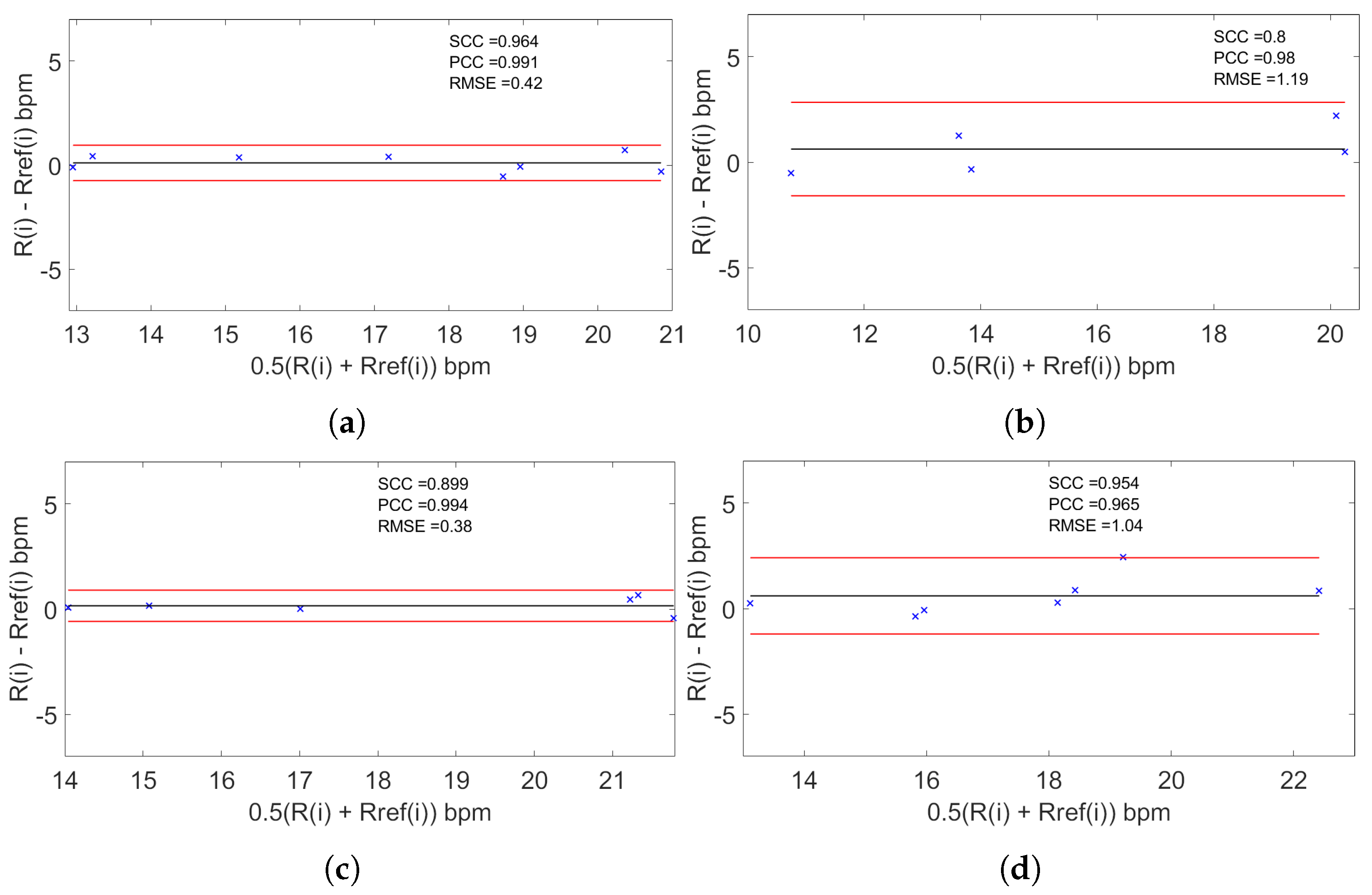
. We observe then that the use of the magnification process and particularly the use of magnifying components instead of the original video or the magnified video improves detection. The use of the magnification process can produce artifacts in the video, but if we take only the magnified components, the presence of these artifacts is minimized. Concerning the position of the subject using the MCV strategy, the results were in close agreement for the ‘S’ position (≈99%,
) and ‘LD’ position (≈99%,
) and fall for ‘F’ position (≈98%,
) and ‘LU’ position (≈97 %,
). These results confirm that our strategy can be used for different positions despite some variability in the agreement.
Compared to other recent works using Bland–Altman analysis, the work of Massaroni et al. [
20] obtains an agreement of ≈98% (
) falling to a difference error with respect of the reference
bpm, consistent with our results. The work of Al-Naji et al. [
30] obtains an agreement of ≈99% (
) falling to a difference error with respect to the reference
bpm, consistent with our work. The two latter methods are dependent on the choice of the ROI in contrast to our CNN-Whole-Image strategy, which is independent of the choice of the ROI. In addition, our approach uses the tagged inhalation and exhalation frames as reference for training the CNN as opposed to other strategies that use a reference obtained by means of a contact standard sensor. Some reviewed works did not use the Bland–Altman analysis as quality metric to compare to other strategies. As shown in
Table 5, Alinovi et al. [
25] obtained a RMSE of 0.05 consistent value compared to our ROI strategy (
) and to our CNN-Whole-Image strategy (
). Alam et al. [
26] proposed a method that did not need to use a ROI to obtain a MAE of 20.11% greater than our CNN-Whole-Image strategy with a MAE of
. Ganfure et al. [
24] proposed a method based on an automatic choosing of the ROI obtain a MAE of 15.4% greater than our two strategies. Finally, Chan et al. [
18] obtained a MAE of 3.02 bpm greater than our ROI strategy (
) and to our CNN-Whole-Image strategy (
). Some of the limitations of this work are the limited number of subjects for the statistical analysis. The influence of the distance of the camera for all the tests was not studied. The influence of the kind of clothes of the participants, for example the use of a close-fit or loose-fit t-shirt, and the influence of some motions of the participant were not taken into account. Further strategies must be carried out to address these points. Our approach is simple to implement, using a basic CNN structure and requiring only the classification of the stages of the respiratory cycle. The conditions of acquisitions take into account not only the thorax area but the surrounding environment, thus it would work in some routine medical examinations where RR in controlled conditions is only required.In addition, we show that our CNN-Whole-Image strategy that did not need the selection of a ROI is competitive to all the strategies using a ROI.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}