Sign Language Recognition Using Two-Stream Convolutional Neural Networks with Wi-Fi Signals


Abstract
1. Introduction
- This work shows how to process sign language data based on CSI traces through SVD. It not only makes sign language features more prominent, but also reduces noise and outliers to a certain extent. SVD helps to improve the recognition accuracy of the two-stream network, and has the characteristics of fast running, robustness, and generalization ability.
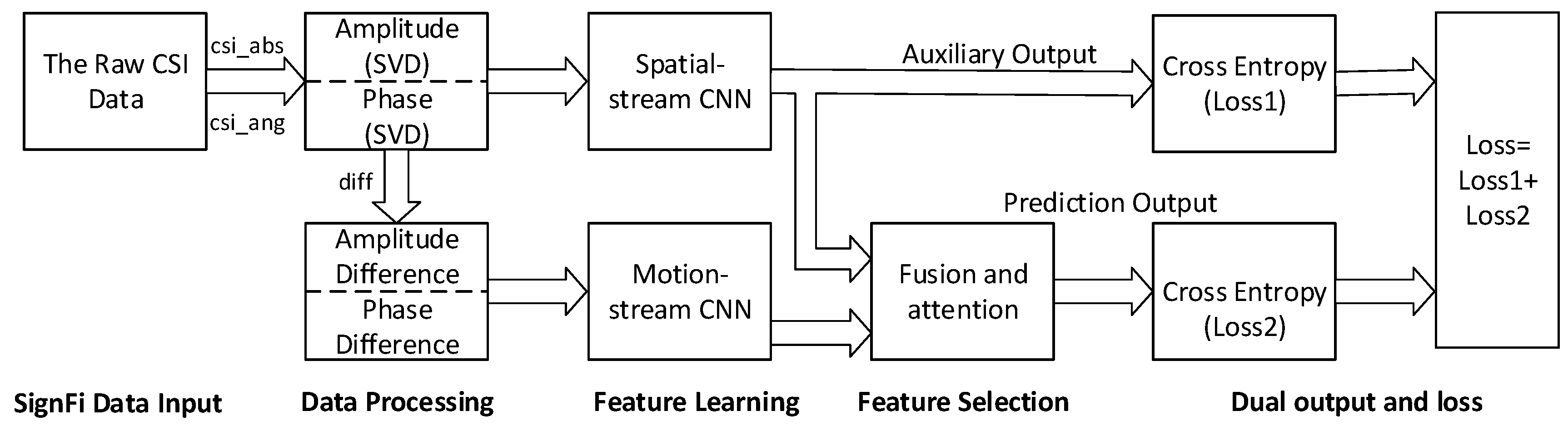
- We explored a novel scheme, dual-output two-stream network. The two-stream network consists of a spatial-stream network and a motion-stream network. The input of the spatial stream network is a three-dimensional array (similar to an array of RGB images) composed of the amplitude and phase of each gesture. The array differences, which represent the amplitude and phase changes, are fed into the motion stream network. The convolutional features from the two streams are fused, and then an attention mechanism automatically selects the most descriptive features. The experimental results show that the dual output can effectively alleviate the back propagation problem of two-stream CNN and improve the accuracy.
- The fine-tuning of an ImageNet pre-trained CNN model on CSI datasets has not yet been exploited. We explored CNN architectures with different model layers on CSI data.
2. Materials and Methods
2.1. Received Signal Strength Indicator and Channel State Information
2.2. Singular Value Decomposition
2.3. SignFi Dataset
2.4. Data Preprocessing
2.5. Dual-Output Two-Stream Convolutional Neural Network
3. Experimental Results
3.1. Network Training and Test Settings
3.2. SignFi Dataset Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ma, Y.; Zhou, G.; Wang, S.; Zhao, H.; Jung, W. SignFi: Sign language recognition using WiFi. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, March 2018; Association for Computing Machinery: New York, NY, USA, 2018; Volume 2, p. 23. [Google Scholar]
- Ahmed, H.F.T.; Ahmad, H.; Aravind, C. Device free human gesture recognition using Wi-Fi CSI: A survey. Eng. Appl. Artif. Intell. 2020, 87, 103281. [Google Scholar] [CrossRef]
- Farhana Thariq Ahmed, H.; Ahmad, H.; Phang, S.K.; Vaithilingam, C.A.; Harkat, H.; Narasingamurthi, K. Higher Order Feature Extraction and Selection for Robust Human Gesture Recognition using CSI of COTS Wi-Fi Devices. Sensors 2019, 19, 2959. [Google Scholar] [CrossRef] [PubMed]
- Grimes, G.J. Digital Data Entry Glove Interface Device. US Patent 4,414,537, 8 November 1983. [Google Scholar]
- Shukor, A.Z.; Miskon, M.F.; Jamaluddin, M.H.; bin Ali, F.; Asyraf, M.F.; bin Bahar, M.B. A new data glove approach for Malaysian sign language detection. Procedia Comput. Sci. 2015, 76, 60–67. [Google Scholar] [CrossRef]
- Kanokoda, T.; Kushitani, Y.; Shimada, M.; Shirakashi, J.-I. Gesture prediction using wearable sensing systems with neural networks for temporal data analysis. Sensors 2019, 19, 710. [Google Scholar] [CrossRef]
- Ma, Y.; Zhou, G.; Wang, S. WiFi sensing with channel state information: A survey. ACM Comput. Surv. (CSUR) 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Koller, O. Quantitative survey of the state of the art in sign language recognition. arXiv 2020, arXiv:2008.09918. [Google Scholar]
- Cui, R.; Liu, H.; Zhang, C. A deep neural framework for continuous sign language recognition by iterative training. IEEE Trans. Multimed. 2019, 21, 1880–1891. [Google Scholar] [CrossRef]
- Pu, J.; Zhou, W.; Li, H. Iterative alignment network for continuous sign language recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4165–4174. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M.M. Hand gesture recognition in real time for automotive interfaces: A multimodal vision-based approach and evaluations. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2368–2377. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, W.; Li, H.; Li, W. Sign language recognition using 3d convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Multimedia and Expo (ICME), Turin, Italy, 29 July 2015; pp. 1–6. [Google Scholar]
- Aly, W.; Aly, S.; Almotairi, S. User-independent American sign language alphabet recognition based on depth image and PCANet features. IEEE Access 2019, 7, 123138–123150. [Google Scholar] [CrossRef]
- Melgarejo, P.; Zhang, X.; Ramanathan, P.; Chu, D. Leveraging directional antenna capabilities for fine-grained gesture recognition. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; pp. 541–551. [Google Scholar]
- Shang, J.; Wu, J. A robust sign language recognition system with multiple Wi-Fi devices. In Proceedings of the Workshop on Mobility in the Evolving Internet Architecture, Los Angeles, CA, USA, 25 August 2017; pp. 19–24. [Google Scholar]
- Li, H.; Yang, W.; Wang, J.; Xu, Y.; Huang, L. WiFinger: Talk to your smart devices with finger-grained gesture. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 250–261. [Google Scholar]
- Zhou, Q.; Xing, J.; Li, J.; Yang, Q. A device-free number gesture recognition approach based on deep learning. In Proceedings of the 2016 12th International Conference on Computational Intelligence and Security (CIS), Wuxi, China, 16–19 December 2016; pp. 57–63. [Google Scholar]
- Kosba, A.E.; Saeed, A.; Youssef, M. Robust WLAN device-free passive motion detection. In Proceedings of the 2012 IEEE Wireless Communications and Networking Conference (WCNC), Paris, France, 1–4 April 2012; pp. 3284–3289. [Google Scholar]
- Yang, Z.; Zhou, Z.; Liu, Y. From RSSI to CSI: Indoor localization via channel response. ACM Comput. Surv. (CSUR) 2013, 46, 1–32. [Google Scholar] [CrossRef]
- Zhou, Z.; Wu, C.; Yang, Z.; Liu, Y. Sensorless sensing with WiFi. Tsinghua Sci. Technol. 2015, 20, 1–6. [Google Scholar] [CrossRef]
- Zheng, W.; Zhang, D. HandButton: Gesture recognition of transceiver-free object by using wireless networks. In Proceedings of the IEEE International Conference on Communications, London, UK, 8–12 June 2015; pp. 6640–6645. [Google Scholar]
- Choi, J.-S.; Lee, W.-H.; Lee, J.-H.; Lee, J.-H.; Kim, S.-C. Deep learning based NLOS identification with commodity WLAN devices. IEEE Trans. Veh. Technol. 2017, 67, 3295–3303. [Google Scholar] [CrossRef]
- Kim, S.-C. Device-free activity recognition using CSI & big data analysis: A survey. In Proceedings of the 2017 Ninth International Conference on Ubiquitous and Future Networks, Milan, Italy, 4–7 July 2017; pp. 539–541. [Google Scholar]
- Kalman, D. A singularly valuable decomposition: The SVD of a matrix. Coll. Math. J. 1996, 27, 2–23. [Google Scholar] [CrossRef]
- Soffer, S.; Ben-Cohen, A.; Shimon, O.; Amitai, M.M.; Greenspan, H.; Klang, E. Convolutional neural networks for radiologic images: A radiologist’s guide. Radiology 2019, 290, 590–606. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. 1962, 160, 106. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Mateen, M.; Wen, J.; Song, S.; Huang, Z. Fundus image classification using VGG-19 architecture with PCA and SVD. Symmetry 2019, 11, 1. [Google Scholar] [CrossRef]
- Zhong, Z.; Jin, L.; Xie, Z. High performance offline handwritten chinese character recognition using GoogLeNet and directional feature maps. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 846–850. [Google Scholar]
- Marsden, M.; McGuinness, K.; Little, S.; O’Connor, N.E. Resnetcrowd: A residual deep learning architecture for crowd counting, violent behaviour detection and crowd density level classification. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–7. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Mobilenets, H.A. Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 20–36. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal multiplier networks for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4768–4777. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Users | Data Groups | Number of Gesture Categories | Number of Gesture Instances | Number of Instances of Each Gesture per User |
|---|---|---|---|---|
| 1 | Home276 | 276 | 2760 | 10 |
| 1 | Lab276 | 276 | 5520 | 20 |
| 1 | Lab + Home276 | 276 | 8280 | 20 + 10 |
| 5 | Lab150 | 150 | 7500 | 10 |
| Data Groups | Accuracy without Attention | Accuracy with Attention |
|---|---|---|
| Home276 | 99.06% | 99.13% |
| Lab276 | 96.52% | 96.79% |
| Lab + Home276 | 97.04% | 97.08% |
| Lab150 | 95.81% | 95.88% |
| Network Model | Modality | Preprocessing | Accuracy |
|---|---|---|---|
| SignFi [1] (9-layer CNN) | combination | no | 93.98% |
| SignFi [1] (9-layer CNN) | combination | Phase Shift | 98.91% |
| HOS-Re [3] (SVM) | combination | no | 98.26% |
| Single-stream ResNet18 | combination | no | 97.90% |
| Single-stream ResNet18 | combination | SVD_20 | 97.83% |
| Single-stream ResNet50 | combination | no | 99.02% |
| Single-stream ResNet50 | combination | SVD_20 | 98.87% |
| Dual-output two-stream with ResNet18 | combination + difference | no | 97.75% |
| Dual-output two-stream with ResNet18 | combination + difference | SVD_20 | 98.55% |
| Dual-output two-stream with ResNet50 | combination + difference | no | 98.88% |
| Dual-output two-stream with ResNet50 | combination + difference | SVD_20 | 99.13% |
| Network Model | Modality | Preprocessing | Accuracy |
|---|---|---|---|
| SignFi [1] (9-layer CNN) | combination | no | 95.72% |
| SignFi [1] (9-layer CNN) | combination | Phase Shift | 98.01% |
| HOS-Re [3] (SVM) | combination | no | 97.84% |
| Single-stream ResNet18 | combination | no | 95.99% |
| Single-stream ResNet18 | combination | SVD_20 | 95.54% |
| Single-stream ResNet50 | combination | no | 96.47% |
| Single-stream ResNet50 | combination | SVD_20 | 96.30% |
| Dual-output two-stream with ResNet18 | combination + difference | no | 96.32% |
| Dual-output two-stream with ResNet18 | combination + difference | SVD_20 | 96.54% |
| Dual-output two-stream with ResNet50 | combination + difference | no | 96.63% |
| Dual-output two-stream with ResNet50 | combination + difference | SVD_20 | 96.79% |
| Network Model | Modality | Preprocessing | Accuracy |
|---|---|---|---|
| SignFi [1] (9-layer CNN) | combination | no | 92.21% |
| SignFi [1] (9-layer CNN) | combination | Phase Shift | 94.81% |
| HOS-Re [3] (SVM) | combination | no | 96.34% |
| Single-stream ResNet18 | combination | no | 95.97% |
| Single-stream ResNet18 | combination | SVD_20 | 95.95% |
| Single-stream ResNet50 | combination | no | 96.67% |
| Single-stream ResNet50 | combination | SVD_20 | 96.60% |
| Dual-output two-stream with ResNet18 | combination + difference | no | 96.3% |
| Dual-output two-stream with ResNet18 | combination + difference | SVD_20 | 96.75% |
| Dual-output two-stream with ResNet50 | combination + difference | no | 96.78% |
| Dual-output two-stream with ResNet50 | combination + difference | SVD_20 | 97.08% |
| Network Model | Modality | Preprocessing | Accuracy |
|---|---|---|---|
| SignFi [1] (9-layer CNN) | combination | no | - |
| SignFi [1] (9-layer CNN) | combination | Phase Shift | 86.66% |
| HOS-Re [3] (SVM) | combination | no | 96.23% |
| Single-stream ResNet18 | combination | no | 93.60% |
| Single-stream ResNet18 | combination | SVD_20 | 94.20% |
| Single-stream ResNet50 | combination | no | 95.24% |
| Single-stream ResNet50 | combination | SVD_20 | 95.53% |
| Dual-output two-stream with ResNet18 | combination + difference | no | 91.18% |
| Dual-output two-stream with ResNet18 | combination + difference | SVD_20 | 94.67% |
| Dual-output two-stream with ResNet50 | combination + difference | no | 95.75% |
| Dual-output two-stream with ResNet50 | combination + difference | SVD_20 | 95.88% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, C.-C.; Gao, Z. Sign Language Recognition Using Two-Stream Convolutional Neural Networks with Wi-Fi Signals. Appl. Sci. 2020, 10, 9005. https://doi.org/10.3390/app10249005
Lee C-C, Gao Z. Sign Language Recognition Using Two-Stream Convolutional Neural Networks with Wi-Fi Signals. Applied Sciences. 2020; 10(24):9005. https://doi.org/10.3390/app10249005
Chicago/Turabian StyleLee, Chien-Cheng, and Zhongjian Gao. 2020. "Sign Language Recognition Using Two-Stream Convolutional Neural Networks with Wi-Fi Signals" Applied Sciences 10, no. 24: 9005. https://doi.org/10.3390/app10249005
APA StyleLee, C.-C., & Gao, Z. (2020). Sign Language Recognition Using Two-Stream Convolutional Neural Networks with Wi-Fi Signals. Applied Sciences, 10(24), 9005. https://doi.org/10.3390/app10249005