A Method of Increasing Digital Filter Performance Based on Truncated Multiply-Accumulate Units



Abstract
1. Introduction
2. Materials and Methods
2.1. Digital Filters
2.2. Multiply-Accumulate Units
2.3. Proposed FIR Filter Architecture Using Truncated MAC Units
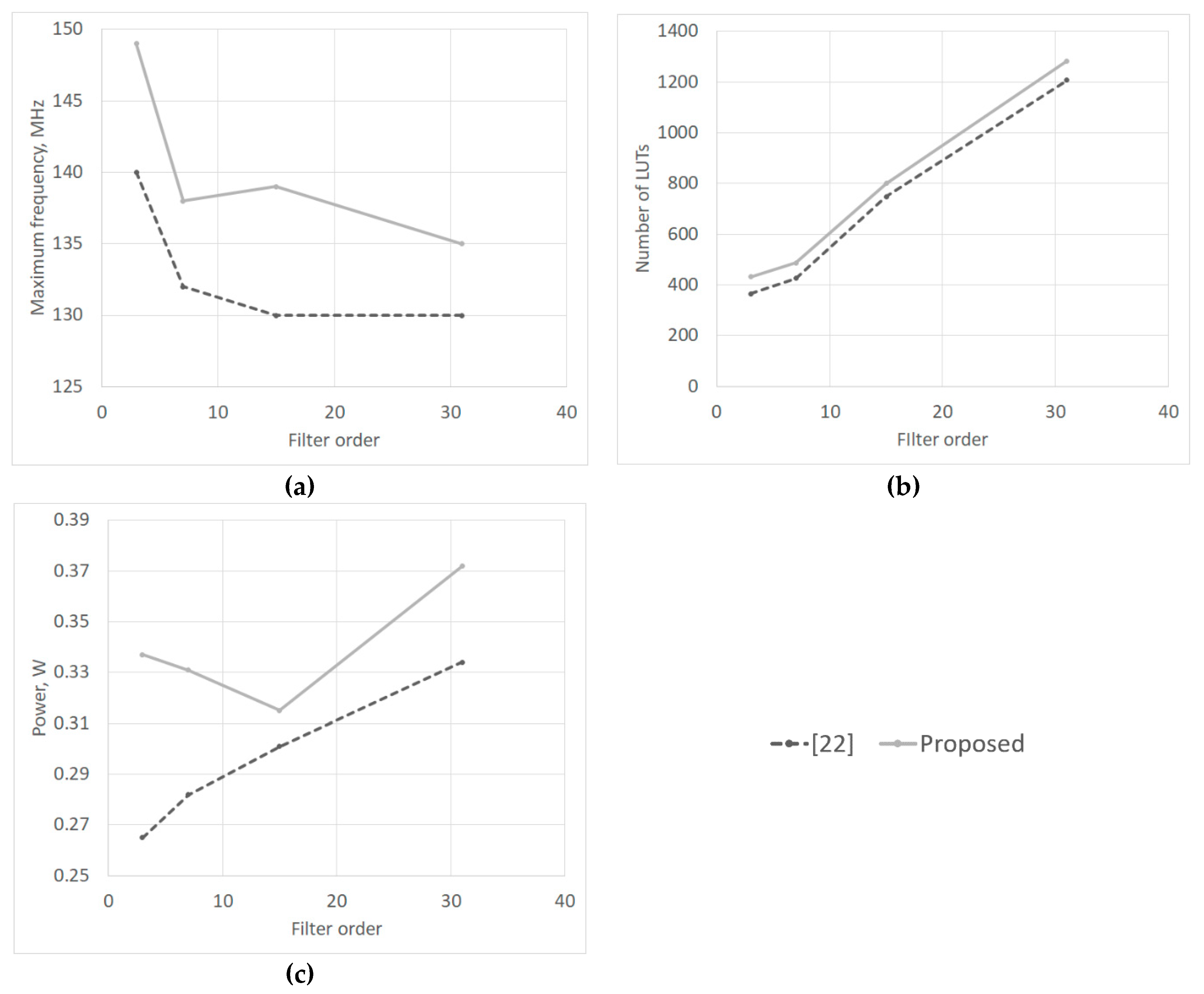
3. Results
3.1. Digital Filters Theoretical Comparative Analysis
3.2. Hardware Simulation of Digital Filters
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bhaskar, P.C.; Uplane, M.D. FPGA based digital FIR multilevel filtering for ECG denoising. In Proceedings of the 2015 International Conference on Information Processing (ICIP), Pune, India, 16–19 December 2015; pp. 733–738. [Google Scholar]
- Kurbiel, T.; Göckler, H.G.; Alfsmann, D. Oversampling Complex-Modulated Digital Filter Bank Pairs Suitable for Extensive Subband-Signal Amplification. 2009, pp. 2658–2662. Available online: https://ieeexplore.ieee.org/document/7077454 (accessed on 19 October 2020).
- Porshnev, S.V.; Kusaykin, D.V.; Klevakin, M. On accuracy of periodic discrete finite-length signal reconstruction by means of a Whittaker-Kotelnikov-Shannon interpolation formula. In Proceedings of the 2018 Ural Symposium on Biomedical Engineering, Radioelectronics and Information Technology, Yekaterinburg, Russia, 7–8 May 2018; pp. 165–168. [Google Scholar] [CrossRef]
- Tang, F.; Wang, Z.; Xia, Y.; Liu, F.; Zhou, X.; Hu, S.; Lin, Z.; Bermak, A. An Area-Efficient Column-Parallel Digital Decimation Filter With Pre-BWI Topology for CMOS Image Sensor. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 2524–2533. [Google Scholar] [CrossRef]
- Kiran, S.; Shafik, A.; Tabasy, E.Z.; Cai, S.; Lee, K.; Hoyos, S.; Palermo, S. Modeling of ADC-Based Serial Link Receivers with Embedded and Digital Equalization. IEEE Trans. Components Packag. Manuf. Technol. 2018, 9, 536–548. [Google Scholar] [CrossRef]
- Lakkadi, A.; Debrunner, L.S. Radix-4 modular pipeline fast Fourier transform algorithm. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Acific Grove, CA, USA, 29 October–1 November 2017; pp. 440–444. [Google Scholar]
- Medus, L.D.; Iakymchuk, T.; Frances-Villora, J.V.; Bataller-Mompean, M.; Rosado-Muñoz, A. A Novel Systolic Parallel Hardware Architecture for the FPGA Acceleration of Feedforward Neural Networks. IEEE Access 2019, 7, 76084–76103. [Google Scholar] [CrossRef]
- Tan, L.; Jiang, J. Digital Signal Processing, 3rd ed.; Elsevier: Amsterdam, The Netherlands, 2018; ISBN 9780128150726. [Google Scholar]
- Wang, H. A New Separable Two-dimensional Finite Impulse Response Filter Design with Sparse Coefficients. IEEE Trans. Circuits Syst. I: Regul. Pap. 2015, 62, 2864–2873. [Google Scholar] [CrossRef]
- Jaiswal, M.; Sharma, S.; Sharma, A. Implementation of high-speed–low-power adaptive finite impulse response filter with novel architecture. J. Eng. 2015, 2015, 86–91. [Google Scholar] [CrossRef]
- Hatai, I.; Chakrabarti, I.; Banerjee, S. An Efficient Constant Multiplier Architecture Based on Vertical-Horizontal Binary Common Sub-expression Elimination Algorithm for Reconfigurable FIR Filter Synthesis. IEEE Trans. Circuits Syst. I: Regul. Pap. 2015, 62, 1–10. [Google Scholar] [CrossRef]
- Maeda, Y.; Fukushima, N.; Matsuo, H. Taxonomy of Vectorization Patterns of Programming for FIR Image Filters Using Kernel Subsampling and New One. Appl. Sci. 2018, 8, 1235. [Google Scholar] [CrossRef]
- Kaplun, D.; Butusov, D.N.; Ostrovskii, V.; Veligosha, A.; Gulvanskii, V. Optimization of the FIR Filter Structure in Finite Residue Field Algebra. Electronics 2018, 7, 372. [Google Scholar] [CrossRef]
- Rakesh, H.; Sunitha, G.S. Design and Implementation of Novel 32-Bit MAC Unit for DSP Applications. In Proceedings of the 2020 International Conference for Emerging Technology, Belgaum, India, 5–7 June 2020; pp. 1–6. [Google Scholar]
- Patil, P.A.; Kulkarni, C. Multiply Accumulate Unit Using Radix-4 Booth Encoding. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018; pp. 1076–1080. [Google Scholar]
- Lahari, P.; Bharathi, M.; Shirur, Y.J. An Efficient Truncated MAC using Approximate Adders for Image and Video Processing Applications. In Proceedings of the 2020 4th International Conference on Trends in Electronics and Informatics (ICOEI) (48184), Tirunelveli, India, 15–17 June 2020; pp. 1039–1043. [Google Scholar]
- Masadeh, M.; Hasan, O.; Tahar, S. Input-Conscious Approximate Multiply-Accumulate (MAC) Unit for Energy-Efficiency. IEEE Access 2019, 7, 147129–147142. [Google Scholar] [CrossRef]
- Ahish, S.; Kumar, Y.; Sharma, D.; Vasantha, M. Design of high performance Multiply-Accumulate Computation unit. In Proceedings of the 2015 IEEE International Advance Computing Conference (IACC), Banglore, India, 12–13 June 2015; pp. 915–918. [Google Scholar]
- Camus, V.; Enz, C.; Verhelst, M. Survey of Precision-Scalable Multiply-Accumulate Units for Neural-Network Processing. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Hsinchu, Taiwan, 18–20 March 2019; pp. 57–61. [Google Scholar]
- Yang, T.; Sato, T.; Ukezono, T. An Approximate Multiply-Accumulate Unit with Low Power and Reduced Area. In Proceedings of the 2019 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Miami, FL, USA, 15–17 July 2019; pp. 385–390. [Google Scholar]
- Zhang, H.; He, J.; Ko, S.-B. Efficient Posit Multiply-Accumulate Unit Generator for Deep Learning Applications. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar]
- Howal, P.S.; Upla, K.P.; Patel, M.C. HDL implementation of digital filters using floating point vedic multiplier. In Proceedings of the IEEE International Conference on Circuits and Systems, ICCS 2017, Banglore, India, 12–13 June 2015; pp. 274–279. [Google Scholar]
- Spoorthi, H.R.; Narendra, C.P.; Mohan, U.C. Low Power Datapath Architecture for Multiply—Accumulate (MAC) Unit. In Proceedings of the 2019 4th International Conference on Recent Trends on Electronics, Information, Communication & Technology (RTEICT), Bangalore, India, 17–18 May 2019; pp. 391–395. [Google Scholar]
- Suguna, R.; Rathinasabapathy, V. A novel high speed Low Latency Column Bit Compressed MAC architecture for Wireless Sensor Network applications. Comput. Commun. 2020, 150, 739–746. [Google Scholar] [CrossRef]
- Parhami, B. Computer Arithmetic: Algorithms and Hardware Designs; Oxford University Press: Oxford, UK, 2010; ISBN 9780195328486. [Google Scholar]
- Kogge, P.M.; Stone, H.S. A Parallel Algorithm for the Efficient Solution of a General Class of Recurrence Equations. IEEE Trans. Comput. 1973, 786–793. [Google Scholar] [CrossRef]
- Zimmermann, R. Binary adder architectures for cell-based VLSI and their synthesis; Hartung-Gorre: Konstanz, Germany, 1998; ISBN 978-3896492890. [Google Scholar]
- Tung, C.-W.; Huang, S.-H. A High-Performance Multiply-Accumulate Unit by Integrating Additions and Accumulations into Partial Product Reduction Process. IEEE Access 2020, 8, 87367–87377. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| [22] | Proposed | Difference, % | [22] | Proposed | Difference, % | |
|---|---|---|---|---|---|---|
| 8 | 502 | 352 | 29.86 | 8848 | 8289 | 6.32 |
| 16 | 643 | 463 | 27.99 | 34,832 | 33,009 | 5.23 |
| 32 | 784 | 574 | 26.79 | 136,720 | 131,649 | 3.71 |
| 64 | 925 | 685 | 25.95 | 538,640 | 525,633 | 2.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyakhov, P.; Valueva, M.; Valuev, G.; Nagornov, N. A Method of Increasing Digital Filter Performance Based on Truncated Multiply-Accumulate Units. Appl. Sci. 2020, 10, 9052. https://doi.org/10.3390/app10249052
Lyakhov P, Valueva M, Valuev G, Nagornov N. A Method of Increasing Digital Filter Performance Based on Truncated Multiply-Accumulate Units. Applied Sciences. 2020; 10(24):9052. https://doi.org/10.3390/app10249052
Chicago/Turabian StyleLyakhov, Pavel, Maria Valueva, Georgii Valuev, and Nikolai Nagornov. 2020. "A Method of Increasing Digital Filter Performance Based on Truncated Multiply-Accumulate Units" Applied Sciences 10, no. 24: 9052. https://doi.org/10.3390/app10249052
APA StyleLyakhov, P., Valueva, M., Valuev, G., & Nagornov, N. (2020). A Method of Increasing Digital Filter Performance Based on Truncated Multiply-Accumulate Units. Applied Sciences, 10(24), 9052. https://doi.org/10.3390/app10249052