1. Introduction
Vocal fatigue may be diagnosed through a series of voice symptoms, which include, for example, hoarse and breathy vocal qualities, pitch breaks, reduced pitch and loudness ranges, throat discomfort, and unsteady voice [
1]. Vocal fatigue may be experienced by any individuals during their life time, but it is more frequently encountered by professional voice users in occupational settings. Vocal fatigue increases vocal effort and decreases speaking stamina. Ultimately, vocal fatigue can lead to voice disorders, such as vocal hyperfunction or vocal nodules. Vocal fatigue is difficult to define because many factors, such as self-reported feelings, doctor-rated symptoms, and instrumental measures, could be criteria for its determination. For example, a self-reported feeling of vocal fatigue might be due to psychological stress, thereby not causing much detectable change in physiological measures [
2]. Standards for assessing vocal fatigue are therefore difficult to establish. Nevertheless, most current research adopted the definition of vocal fatigue as a sense of increased vocal effort [
3].
Considerable progress has been made in the evaluation of voice quality. Perceptual, acoustic, and aerodynamic measurements, along with self-administered tests, have been used to characterize changes in voice quality and performance in laboratorial settings [
4,
5]. The most commonly used method of voice quality evaluation in clinics is auditory perception, which relies on listeners’ personal experience and expertise. Commonly used subjective evaluation tools included the GRBAS (Grade, Roughness, Breathiness, Asthenia and Strain) proposed by the Japan Society of Logopedics and Phoniatrics, the CAPE-V (Consensus Auditory-Perceptual Evaluation of Voice) proposed by the American Speech-Language and Hearing Association, and the SAVRa (Self-Administrated Voice Rating) proposed by the National Center for Voice and Speech in the United States. These tools require specific vocal stimuli. For example, the CAPE-V requires the completion of three defined phonation tasks assessed through perceptual rating. This therefore limits the applicability of these tools in situations where the vocal stimuli are varied or unspecified. Many studies have investigated uncertainties in subjective judgment methodologies for voice quality evaluation. Kreiman and Gerratt investigated the source of listener disagreement in voice quality assessment using unidimensional rating scales, and found that no single metric from natural voice recordings allowed the evaluation of voice quality [
6]. Kreiman also found that individual standards of voice quality, scale resolution, and voice attribute magnitude also significantly influenced intra-rater agreement [
7]. Objective metrics obtained using various acoustic instruments have been investigated, and attempts have been made to correlate these with perceptual voice quality assessments [
8,
9,
10,
11,
12].
A plethora of temporal, spectral, and cepstral metrics have been proposed to evaluate voice quality [
13,
14]. Commonly used features or vocal metrics include fundamental frequency (
), loudness, jitter, shimmer, vocal formants, harmonic-to-noise ratio (HNR), spectral tilt (H1-H2, harmonic richness factor), maximum flow declination rate (MFDR), duty ratio, cepstral peak prominence (CPP), Mel-frequency cepstral coefficients (MFCCs), power spectrum ratio, and others [
15,
16,
17,
18,
19]. Self-reported feelings of decreased vocal functionality have been used as a criterion for vocal fatigue in many previous studies [
1,
4,
20,
21,
22]. Standard self-administered questionnaires, such as the SAVRa and the Vocal Fatigue Index (VFI), have been used to identify individuals with vocal fatigue, and to characterize their symptoms [
23,
24,
25]. Hunter and Titze used the SAVRa to quantify vocal fatigue recovery based on 86 participants’ tracking reports. The results showed a self-reported 50% recovery within 4–6 h, and 90% recovery within 12–18 h [
24]. Halpern et al. used one of the three dimensions in SAVRa, i.e., the inability to produce soft voice (IPSV), to track vocal changes in school teachers. The SAVRa scores were then compared with two clinicians’ ratings of the participants’
, and loudness [
26]. The overall correlation between self-ratings and clinician ratings was not significant. The average absolute difference score was 1.7. This showed that the clinicians and the teachers had different rating standards.
Prolonged or inappropriate voice use is commonly regarded as one of the causes of vocal fatigue. Vocal loading tasks (VLTs) are often used to investigate the relationship between voice use and vocal fatigue in laboratorial settings [
1]. Previous VLT studies have typically instructed participants to complete standardized reading tasks of prescribed durations at specific loudness levels [
1,
4,
24]. Perceptual, acoustic, and aerodynamic measurements have been used to evaluate changes in voice quality and performance before and after VLTs [
4]. Unfortunately, the findings from these studies were often reported as inconsistent. Comparisons across different studies have been at times contradictory. This may have been caused by multiple factors: (1) the prescribed VLT might not have induced a detectable level of vocal fatigue across individuals, (2) the amount of vocal loading across participants may not have been consistent due to the lack of a universal method to quantify vocal loading, and (3) there may have been variability in experimental settings. A more robust vocal loading protocol for VLT is therefore needed to improve consistency, and to allow comparisons across different studies.
Amongst methods of quantifying voice use for vocal fatigue assessment, the vocal distance dose,
, first proposed by Titze et al., was adopted in the present study [
27]. The vocal distance dose attempts to approximately quantify the distance traveled by vocal folds during vocal oscillation [
27,
28]. It is usually calculated in terms of the fundamental frequency, the sound pressure level, the voicing duration, and the vocal duty ratio. Whether
correspondes to the true cumulative vocal fold displacement has not yet been verified. But, as a four-parameter estimates, vocal distance dose is more comprehensive than other metrics that are based on one single parameter. Svec et al. described the procedures to calculate the distance dose using synchronized microphone and EGG data [
29]. The EGG signal was used to locate the peak position for each vocal cycle in the time domain. The microphone signal was used to quantify loudness. Carroll et al. used cumulative vocal dose data correlations with subjective measurements in vocal fatigue experiments. An abrupt increase in vocal loading was closely related to a harsher subjective self-reported rating [
30]. Echternach et al. found that a 10-min intensive VLT with a >80 dB loudness level was comparable to a 45-min teaching task in terms of vocal dose [
31]. Remacle et al. showed that kindergarden teachers had significantly greater distance doses than elementary school teachers based on an investigation of 12 kinderdarten and 20 elementary school female teachers [
5]. Bottalico and Astolfi calculated the vocal distance dose and the sound pressure level (SPL) for school teachers during their daily teaching assignments. They found that female teachers had on average a higher (>3.4 dB) loudness level than male teachers, but vocal distance doses did not differ very much between female and males teachers [
32]. Morrow and Connor used an ambulatory phonation monitor to record and calculate the SPL and the distance dose for elementary music teachers with and without voice amplification [
33]. The results showed that voice amplification significantly decreased the average SPL and the distance dose. These studies used the vocal distance dose as a quantitative measure of voice use in the VLTs or routine phonation tasks. Despite progress, no definitive correlations have been yet made between subjective assessments and objective measures in vocal fatigue studies. The distance dose prospectively offers a quantitative metric for vocal loading. Such framework is essential for cross-participants or cross-sessions comparisons to be meaningful and reasonable.
In the present study, a uniquely designed VLT was investigated. Ten human subjects were recruited and participated in the study. The vocal distance dose was used to quantify the participants’ vocal loading online during the experiment. Subjective and objective measures were used to assess participants’ voice qualities. A cross-session comparison was made to investigate the relationship between total distance dose and voice quality.
6. Discussion and Conclusions
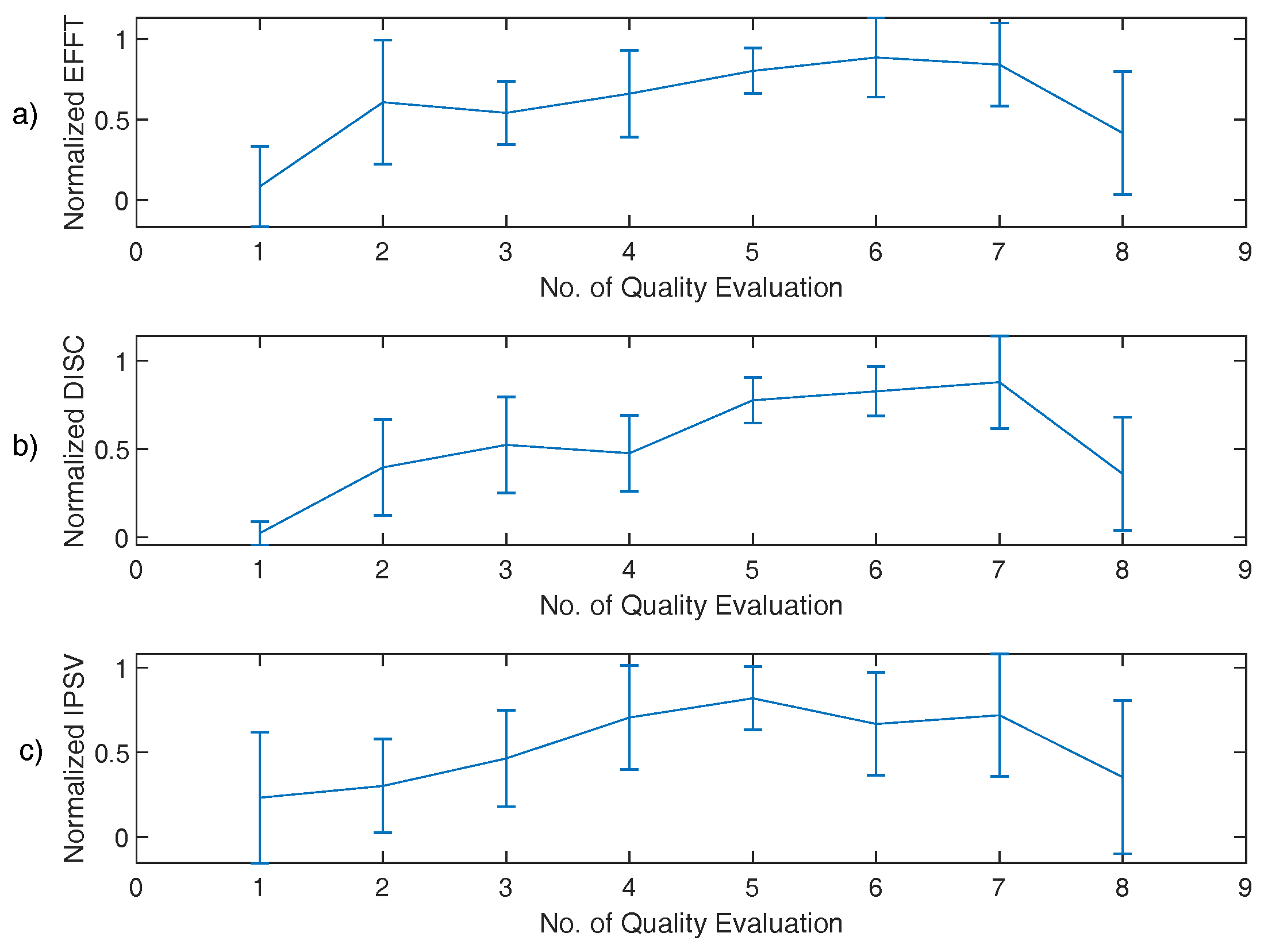
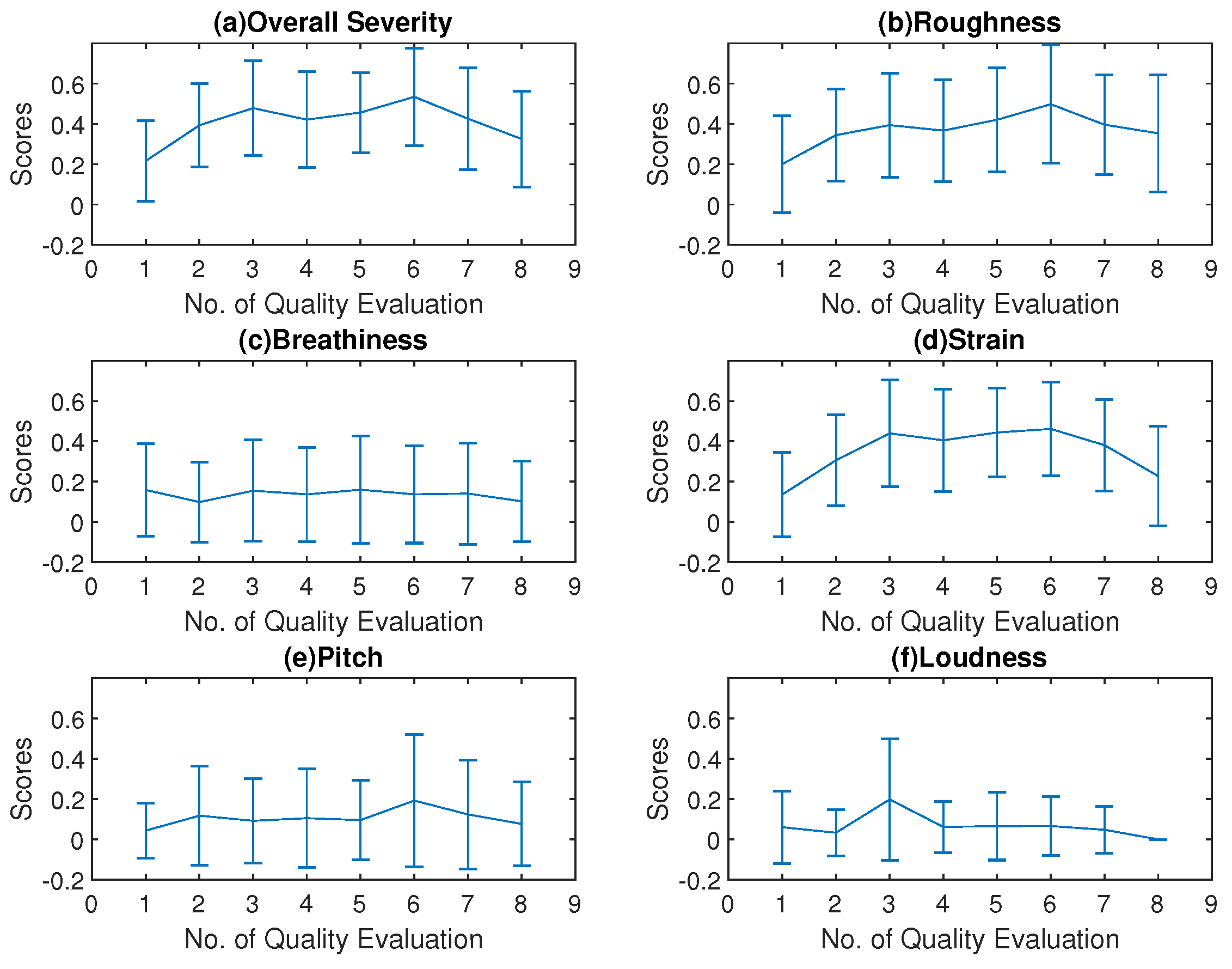
The primary finding in the SAVRa results was that the ratings show an arch-shaped variation trajectory from QE1 to QE8. This trend was also observed in the CAPE-V rating results. In the SAVRa ratings, the rapid increase of the vocal effort, the vocal discomfort level, and the severity of the soft phonation quality indicated a voice adjustment period. Over this period, the participants’ vocal folds were abruptly exposed to a heavy vocal loading, and thus the subjects’ feelings of vocal fatigue were strong over this period. After this period, the degrees of the participants’ perceived vocal fatigue remained constant at a high level, or increased moderately from QE2 to QE7. The vocal loading intensity for each VLT session was identical. The participants gradually adapted to the vocal loading intensity, thus the increasing rate slowed down after this period. After the S1, the accumulation effect of the vocal loading led to a slow and persistent increase of the participants’ perceived vocal fatigue in the late sessions. This indicates that, given constant vocal stimuli for different sessions, the participants’ perceived vocal fatigue increased over time (or vocal distance dose). The notable decrease of the SAVRa scores from QE7 to QE8 reflects the effect of vocal rest on participants’ vocal fatigue feelings. This indicates that the participants felt much better about their vocal functionalities after the 15-min rest session, but the rest was not sufficient to completely recover to the original status at QE1. A longer rest session was thus presumed to enhance the vocal recovery process. The findings in the CAPE-V rating results show that the overall severity, roughness, and strain ratings have the same arch-shaped variation trend with the SAVRa results. This indicates that vocal fatigue degraded the participants’ voice performance by increasing roughness and strain.
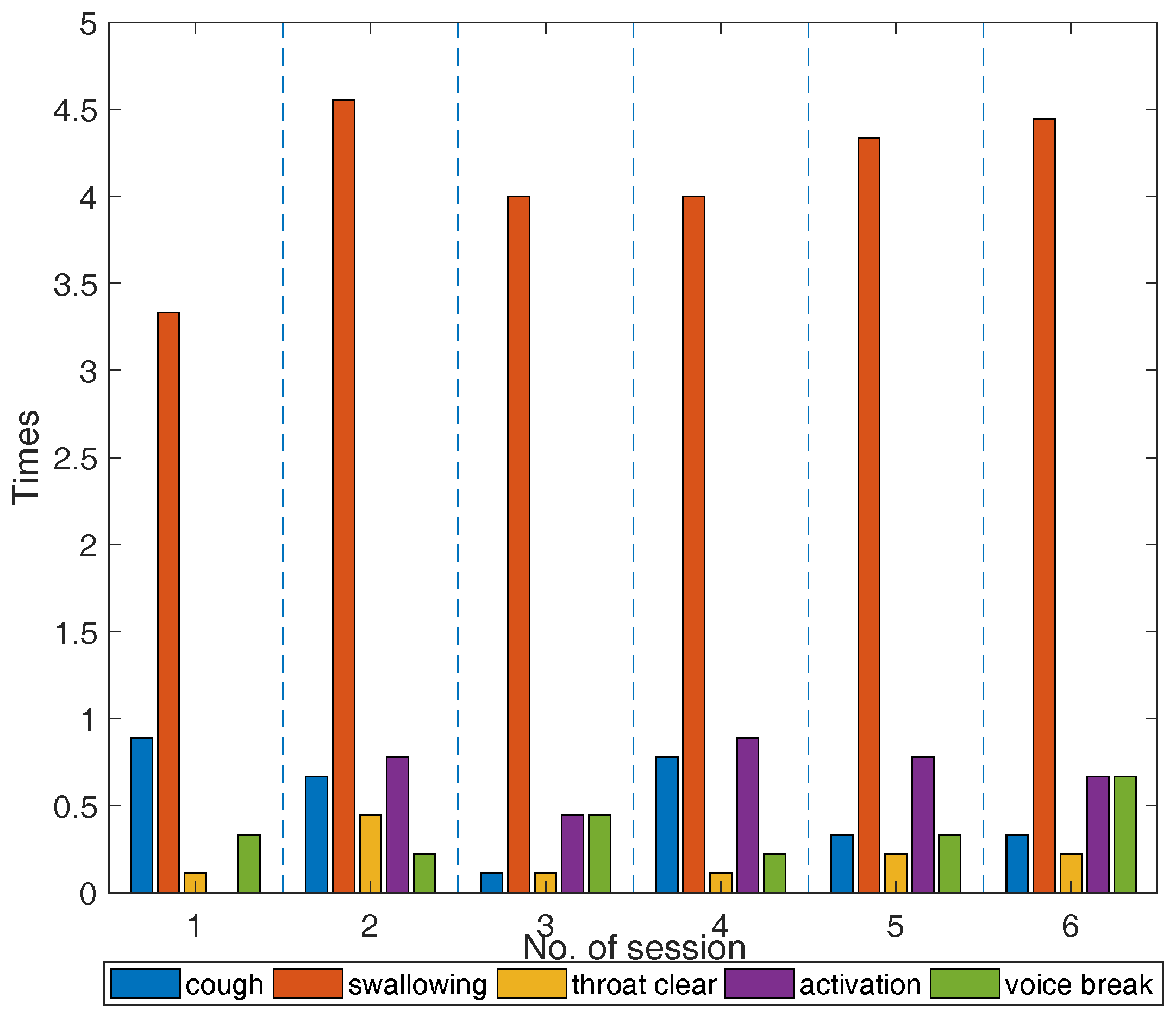
The data for the fatigue-indicative symptoms obeyed different trends than the SAVRa results. Previous studies showed that these symptoms were frequently observed on vocally fatigued participants. However, a quantitative relationship between the number of occurrences of these symptoms and the degree of vocal fatigue could not be established. Individual discrepancies in the counts of these symptoms showed varied sensitivities to vocal fatigue. Some participants coughed frequently during the VLT, while others did not cough at all. Swallowing was much more frequently observed than other symptoms for all participants. This finding further validated the results of previous studies on the effect of hydration on vocal fatigue [
44,
48], i.e., superficial vocal fold hydration (swallowing or drinking) could help relieve vocal dysfunction and improve vocal efficiency.
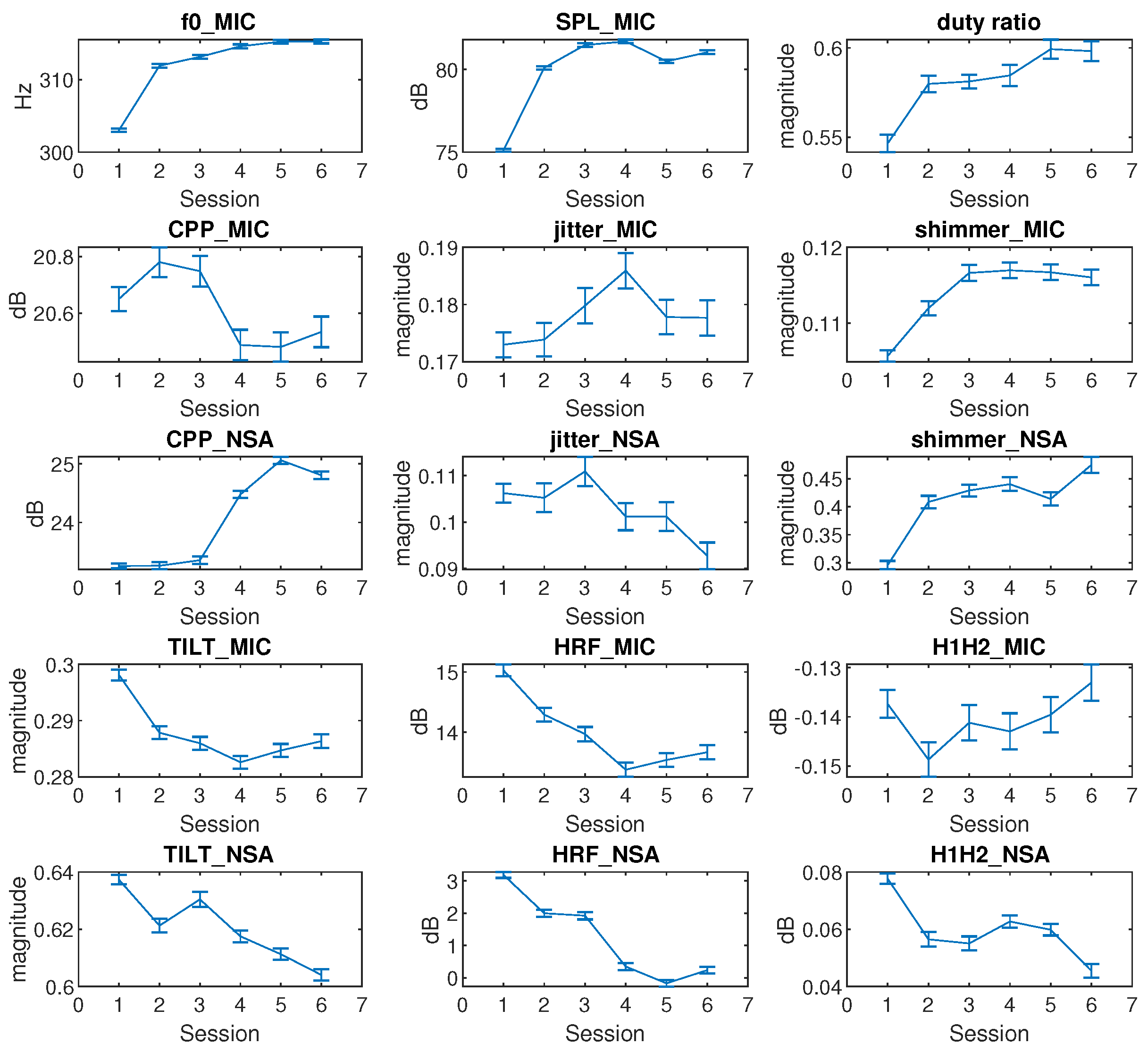
Fifteen voice metrics (features) were studied to track voice quality variation across VLT sessions. The statistical analysis results in
Figure 7 did not include the rest session. The
, SPL_MIC, duty ratio, shimmer_MIC, and shimmer_NSA rapidly increased in early sessions, and remained constant afterwards. The variation of
in
Figure 7 was consistent with the results of previous studies, which found that participants’
increased with vocal fatigue [
49,
50]. The shimmer_MIC and shimmer_NSA showed an increase after the VLT session. This finding contradicts Laukkanen’s one-day vocal fatigue study results [
51], but it is consistent with Gelfer’s 60-min vocal fatigue study results [
49]. This might be caused by the different phonation durations.
One limitation of the present study was that the voice type was not considered as a parameter in the voice use quantification. For example, breathy voice obviously had a different vocal loading intensity from pressed voice when the
, SPL, duty ratio, and duration were identical for these two voice types. The impact stress between vocal folds for these two voice types were different. The feelings of vocal fatigue that the breathy and pressed voice brought to participants were therefore different. An improved method of calculating
that considers voice quality is therefore needed to make the voice use quantification more accurate. Another limitation was that calculation of the
from the NSA may be not very accurate because of the rather large uncertainty in the SPL (± 5 dB) estimates from the NSA data [
40]. The accuracy of calculating
would thus be influenced. This issue limits the use of the dose-based voice use quantification method in long-term voice monitoring. The monitoring of neck surface acceleration is preferable to minimize the influence of extraneous noise and potentially reduce discomfort in occupational settings. A method for directly deriving the magnitude of the vocal fold vibration from the skin acceleration level is therefore needed. The last limitation is that normal swallowing on a daily basis was not measured, and thus the fatigue-indicative symptom analysis lacked a baseline to refer to. This baseline could be established in future work.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}