We comprehensively evaluated the APN using the MS COCO dataset and the 2018 WAD dataset, and our results outperform the baseline, i.e., the original FPN. In addition, The parameters and running time of the APN are presented to prove how lightweight the network is, and we use the legend to show the actual effect of object detection and segmentation. To prove the validity of the adaptive transformation and feature attention block, we conducted comparative experiments on them separately. We present our results following the standard evaluation metrics [
18], denoted as Intersection over Union (
) and Average Precision (
), respectively, as well as using the instance segmentation average precision, denoted as
.
4.1. Dataset and Metrics
The MS COCO dataset is one of the most challenging datasets for object detection task due to data complexity. It consists of 115 k images for training and 5 k images for validation (new split of 2017). In total, 20 k images were used in the test-dev and 20 k images were used as a test-challenge. Ground-truth labels of both test-challenge and test-dev are not publicly available. The MS COCO dataset has 80 classes with bounding box annotation. We trained our models on the train-2017 subset and report results on the val-2017 subset for ablation study. We also report results for the test-dev for comparison with the single model result.
In addition, the 2018 WAD dataset comes from the 2018 CVPR workshop on autonomous driving, which was sponsored by Baidu Inc. This dataset consists of approximately 35 K images for training and 5 K images for validation. In total, 2 K test images were used in the test challenge. The dataset includes seven classes with pixel-wise instance mask annotation. Ground-truth labels of the test challenge are not publicly available. We trained our models on the training dataset and report our results for the test-dev for comparison.
We followed the standard evaluation metrics, i.e., ,, , , , , and . The last three measure performance corresponding to objects with different scales. Since our framework is general to both object detection and instance segmentation, we also report the result for instance segmentation.
Below is the definition of
:
where
is the prediction region from the detection/segmentation network and
is the ground-truth body region. We used the mean IoU calculated from all test images.
The
is defined as follows:
where
means the true positive,
means the false positive, and
N means the number of the detection/segmentation results.
in Equation (6) represents the averaged value of all categories. Traditionally, this is called “mean average precision” (
). In the MS COCO dataset, it makes no distinction between
and
. Specifically, the MS COCO dataset uses 10
thresholds of 0.50:0.05:0.95. This is a break from tradition, where
is computed at a single IoU of 0.5 (which corresponds to our metric
).
4.2. Experiment on the MS COCO Dataset
We experimented on the Mask R-CNN [
18] baselines, re-implemented based on the Tensorflow. All pre-trained models that we used in experiments are publicly available. We replaced FPN with APN during training, where the corresponding models were pre-trained from ImageNet. We adopted the same end-to-end training as in the Mask R-CNN; however, we chose slightly different hyperparameters.
We took two images in one image batch for training and used two NVidia TitanX GPUs (one image per GPU). The shorter and longer edges of the images were 800 and 1333, if not otherwise noted. For object detection, we trained our model with a learning rate that starts from 0.01, which decreased by a factor of 0.1 after 960 k and 1280 k iterations and finally terminated at 1440 k iterations. This training schedule resulted in 12.17 epochs over the 118,287 images in the MS COCO 2017 training dataset. The rest of the hyperparameters remained the same as the Mask R-CNN.
We evaluated the performance of the proposed APN on the MS COCO dataset and compared the
test-dev results with the recent state-of-art models with different feature map fusion methods. The results of our proposed ResNet-50 based APN are presented in
Table 1. As shown in
Table 1, our model, trained and tested on single-scale images, outperforms the baselines by a large margin over all of the compared evaluation metrics. Especially, it represents an improvement of 1.8 points for the
when compared to the original module.
In
Table 1, when the FPN is applied to the Mask R-CNN, the best effect is achieved in the related baseline methods. The ResNet-100 is used by the network as the backbone network, and ResNet-100 can usually achieve better recognition than ResNet-50 [
21]. The backbone network of Our APN is ResNet-50, but it still achieved a better effect than the FPN applied to the Mask R-CNN, which uses ResNet-100 as the backbone network. Therefore, our APN network is more effective than FPN in object recognition. In addition, we plotted the performance comparison curves for the APN and baseline methods. In
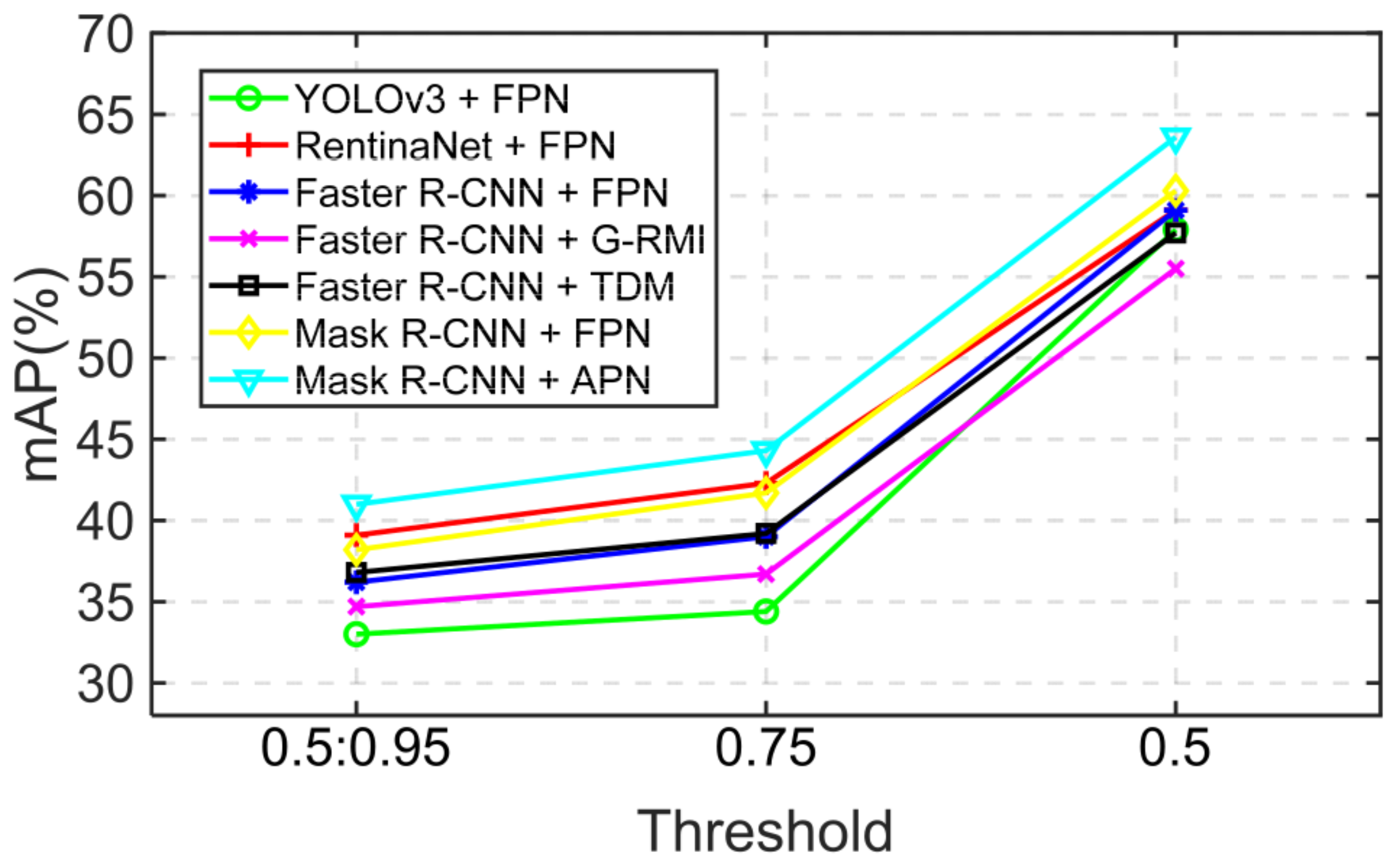
Figure 4, the abscissa is the threshold of IoU, and the ordinate is the AP value of the APN and baseline methods. We use different color polylines to distinguish different methods. Obviously, we can see that the APN proposed by us has higher AP values than any other methods in any threshold range.
Figure 5 shows the comparison of the methods based on our model and the FPN. According to the results, we can see that our improvement model detects more qualitative objects, which means our model can detect those objects that highly overlap, but that belong to different individuals. The design of our models takes advantage of the contextual information from the whole feature pyramid to fulfill the object detection.
Then, we performed the instance segmentation experiments on the COCO dataset. We report the performance of the proposed APN on the COCO dataset for comparison. As shown in
Table 2, the APN applied to Mask R-CNN trained and tested on single-scale images already outperforms the FPN applied to Mask R-CNN, and both use ResNet-50 as their backbone network. All instantiations of our proposed model outperform the base variants of the latter model by nearly 2.0 points on average.
Moreover,
Figure 6 shows the partial examples of the segmentation results using the APN. In
Figure 6, we can see that different classes of objects can be accurately segmented.
In
Table 3, we compare two different designs of our fusion block. Our simple channel-wise addition fusion design results in a severe decrease in bounding box loss
(2.4 points). Compared with the simple channel-wise addition fusion strategy, the convolutional fusion strategy takes all pixels from the feature maps into the calculation. This suggests that the more the spatial information is considered in the fusion block, the better are the results the fusion block gains. The result was tested on the MS COCO
val-2017 set, and the backbone network was ResNet-50. Thus, adding a convolutional layer to fuse the reweighted feature map obtains greater gains over simple channel-wise fusion.
We further tested the efficiency of the APN for the task of object detection on the COCO set
test-dev. The comparison in
Table 4 reveals that, with much fewer parameters, the APN compared with the FPN when the backbone is ResNet-101 can still achieve better performance. Based on the same backbone of ResNet-50, the proposed APN can achieve much better detection results. As shown in
Table 4, the APN based on the ResNet-50 is 2.8 points better than the FPN based on the ResNet-101 with nearly 20 million fewer parameters and the smaller backbone of ResNet-50. As the performance of ResNeXt-101 is better than ResNet-50, and with a larger backbone model, the performance of the APN can achieve better results. To test the efficiency of our design, we carried out more ablation studies of the individual module of the APN.
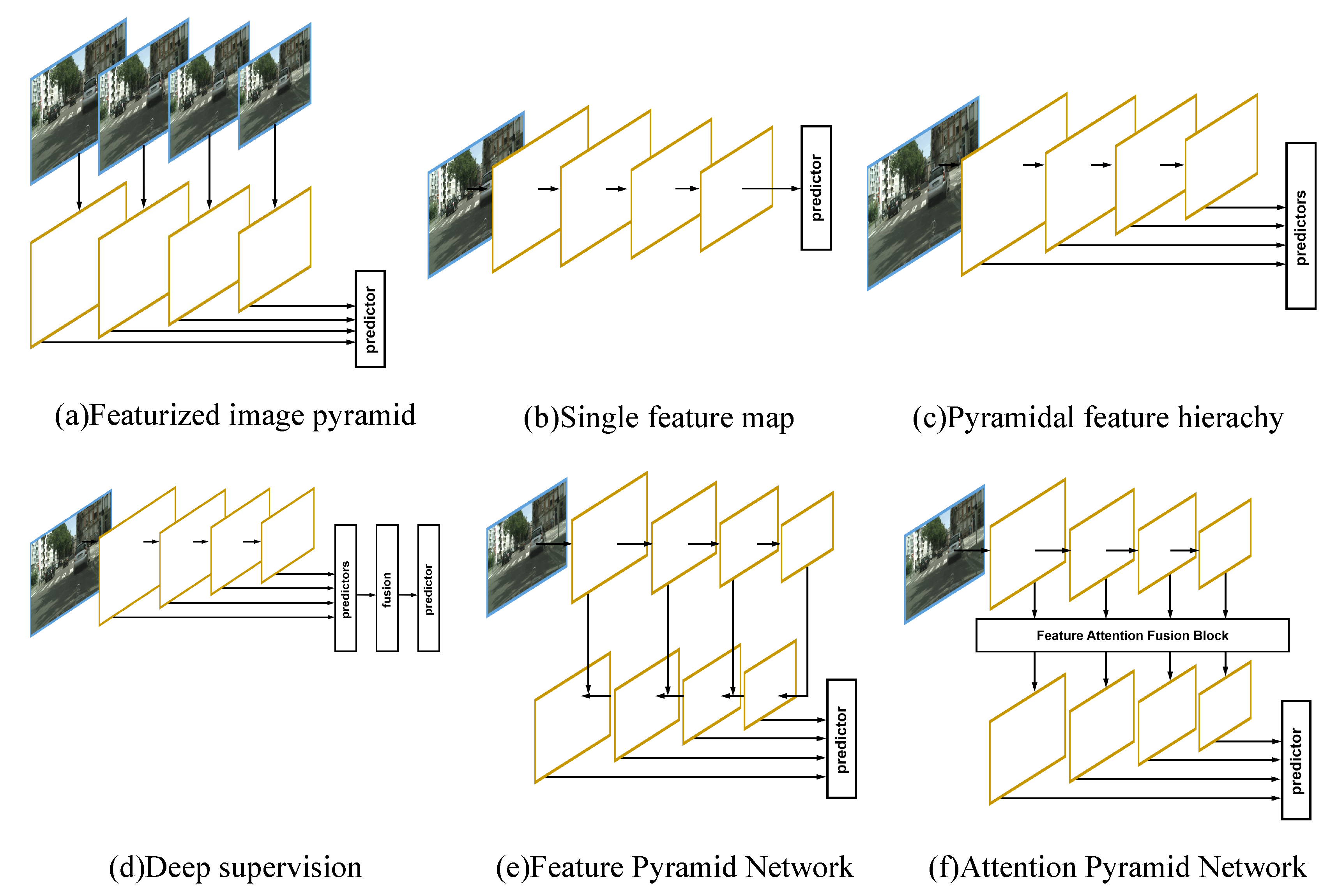
Figure 2 shows that the feature attention fusion block we proposed is composed of the adaptive transformation module and feature attention block and fusion block. Next, we tested the detection performance of the small module in the feature attention fusion block when it is assembled separately and multiplied. In
Table 4, we can see that the third row is the case where the APN only contains the adaptive transformation module, and the fourth row the simultaneous existence of the adaptive transformation module and the feature attention block. The fusion block used in these two cases is channel-wise addition fusion. The fusion block used by the APN in the last row of the table is convolutional fusion, which means that this APN used a complete feature attention fusion block structure.
As shown in
Table 4, when the APN only contains the adaptive transformation module, the AP value of APN is 0.1 higher than that of the FPN using Resnet-50 as the backbone network. Thus, the adaptive transformation of feature maps from all stages marginally improves performance. However, from the channel-wise addition fusion strategy and the conv fusion on the last two rows of
Table 4, we can see that the AP value of the APN on the last row of the table using the conv fusion strategy is 0.7 more than the APN of the fourth row of the table using the channel-wise addition fusion. Therefore, the conv fusion strategy gains greater benefits from fusing feature maps than the channel-wise addition fusion strategy. In addition, from the third and fourth rows in
Table 4, we can see that, when the APN uses the feature attention block, the AP value is 2.3 more than when the APN only contains the adaptive transformation module. Rather than simply giving all the channels of the feature map the same weight as the FPN, our feature attention block learns to reweight different channels from all network stages. Such a reweight-strategy helps the network learn, through the training dataset, to take advantage of feature maps from different network stages to construct a better fusion feature map.
The APN utilizes both the multiscale feature fusion and the channel-wise attention mechanism to generate new feature pyramids. It can be proven that the FPN is a special case of the APN. We look forward to seeing more application to replace our proposed APN with the FPN and yield better performance. In addition, we also carried out an experiment to analyze the inference time of the proposed module. The proposed APN ran in 4 ms on average during the inference time, which was ignorable compared with the inference time of the backbone ConvNet. The experiment was performed with the ResNet-50 model on a single P40 where the input size of the image was 512 × 512.
4.3. Experiment on the 2018 WAD Dataset
We followed the standard evaluation metrics: the mAP, i.e., AP, AP, AP, AP, AP, and AP. Specifically, our average precision was calculated based on the top 100 proposals. We also used two images in one image batch for the training. Because the dataset is full of images with high resolutions, we chose the minimum and maximum resolutions of the resized images to be 800 and 1024. We adopted stochastic gradient descent training on two NVidia TitanX GPUs with a batch size of one. The initial learning rate was set to 0.001, and it was decreased by a factor of 0.1 after 100 k and 120 k iterations and finally terminated at 140 k iterations. We did not adopt any augmentation for the training, which we found made it harder to converge.
Owing to the small size of the mini-batch, we chose to freeze the batch normalization layer. The learning rate was different from the Mask R-CNN and the FPN because of the different platforms. Other implementation details were the same as He et al. [
18], and models were trained on the training subset and used ResNet-101 [
21]. Moreover,
Figure 7 shows part of the results of object detection.
Table 5b shows the object detection results for the comparison of our model to the baseline FPN. We present the results with ResNet-50 pre-trained on the COCO dataset, which was also trained and tested on single-scale images. According to the results, our model outperforms the baseline by a large margin over all of the compared evaluation metrics. This represents an improvement of 1.7 points for
compared with the original module. To specify the effectiveness of our module, we divided the test-dev into separate classes.
Table 5a presents the results for different separated classes in the
test-dev dataset. Note that the results of the APN show better results across the detection results of all sizes, and achieves nearly two points over all classes and all sizes on average. The performance of the separated classes also improves significantly, which indicates the benefit of using a fusion module with contextual information. Therefore, the APN proposed by us is better than the FPN in target recognition of different categories or the whole.
Similar to the object detection results on the Mask R-CNN, we also report the instance segmentation performance of our proposed module on the WAD test-dev for comparison. As shown in
Table 6, compared with the baseline, our APN consistently improves the performance across different evaluation metrics.
The result of the segmentation on the evaluation metrics shows a significant improvement of 1.3 points for AP compared with the original FPN. In
Figure 7, we can see the results of instance segmentation.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}