1. Introduction
Speech is a sign that contains a lot of personal information. Together with the developing technology, a wide variety of applications are developed using the information obtained from this speech signal. Segmentation represents a procedure of breaking down a speech signal into smaller acoustic units. It is possible to define speech segmentation as the procedure of finding limits in a natural spoken language between words, syllables, or phonemes [
1]. In this study, Kurdish phoneme segment detection is investigated. Speech segment detection is one of the most commonly used technologies for recognizing spoken words and expressions and converting them into a format that can be understood by machines, especially computers.
A phoneme, which is characterized by some distinct pertinent properties that distinguish it from other phonemes of the language, represents a language sound element. Phonemes are classified either as vowels or consonants. Sounds that are obtained by oscillating the vibrations acquired with the vocal cords in the sound path are called vowels. Consonants are the sounds produced by obstructions created to the flowing air in any position of the sound path.
In consonants, vocal cord vibrations are not important. When vocal sounds obtained with the vibration of the vocal cords are examined in the time domain, it is observed that they have a periodic structure, while non-vocal sounds have a non-periodic structure. All vowels and some consonants are vocal. This makes it difficult to distinguish between vowel phonemes and consonant phonemes [
2]. It is possible to categorize words into various types in accordance with the position of the occurrences of vowels and consonants in them. The placement of vowels and consonants in a word of any language is very significant for identifying various types of words [
3]. The acoustic phoneme constitutes the basis of a wide variety of the existing speech processing systems, such as medium to large vocabulary speech recognition, speaker recognition systems, and language identification systems [
4].
The accuracy of a speech processing system highly depends on the spoken language phoneme set and has more challenges due to alterations in the pronunciation of words due to dialects, the speaker’s age and gender, and neighboring words. Furthermore, certain difficulties come to the forefront during the creation of a voice database. In addition, the voice segment detection process becomes more difficult due to factors including the toning effect and syllable stress. In this respect, the gated recurrent unit (GRU), which is a special recurrent neural network (RNN) model, was used to deal with these difficulties for the efficient speech segment detection. This model is now widely used in various speech processing tasks. In Ravanelli et al. [
5], GRUs were reviewed and a compact single-gate model replacing a hyperbolic tangent with rectified linear unit activations having a simplified architecture was suggested for the purpose of automatic speech recognition (ASR). The long short-term memory (LSTM) and GRU were assessed for the purpose of comparing the performances they exhibited upon a reduced Technology Entertainment Design - Laboratoire Informatique de l’Université du Maine (TED-LIUM) speech data set [
6]. In Cernak and Tong [
7], a solution was suggested with the aim of training a phone attribute detector without phone alignment by utilizing end-to-end phone attribute modeling on the basis of the connectionist temporal classification. In Zheng et al. [
8], general emotion features were produced in speech signals from various angles, and an ensemble learning model was employed for the purpose of carrying out emotion recognition tasks. The design of the expert roles of speech emotion recognition was performed by utilizing convolutional neural networks (CNNs) and GRU. In Chen et al. [
9], a practical approach with three steps was introduced for singing voice detection on the basis of a GRU.
Recently, speech segment detection has been addressed in a deep neural network (DNN), CNN, and RNN models [
10,
11,
12]. Franke et al. [
11] examined the automatic detection of phoneme boundaries in audio recordings using deep bidirectional LSTMs. The first experiments operated on Texas Instruments Massachusetts Institute of Technology (TIMIT) and BUCKEYE datasets containing an American English language speech corpus and then a Basaa dataset containing a Bantu language speech corpus. An F1-score of 77 with a tolerance of 20 ms was achieved with the above-mentioned method. In Wang et al. [
12], it is reported that GRU forget gate activations in trained recurrent acoustic neural networks correlate very well with phoneme boundaries in speech activation, which ensures the validation of numerous approaches to speech recognition and other sequence modeling problems, including recurrent networks. This study uses a TIMIT corpus. The GRU can take temporal context into account. Therefore, it should exhibit a better performance in comparison with conventional machine learning techniques [
13]. Alternatively, LSTM is a slightly more complex structure variation of the GRU [
14]. The GRU ensures the control of the information flow, similar to the LSTM unit, but without a need to utilize a memory unit. It only provides the exposure of the complete hidden content without any control. The GRU has a simpler structure compared to standard LSTM models, and its popularity is gradually increasing. Therefore, it is preferable for this study. Lee et al. [
15] suggested phoneme segmentation by utilizing cross-entropy loss with connectionist temporal classification loss in deep speech architecture for the purpose of performing speech synthesis. In order to assess the suggested method, female Korean speech found in the Speech Information Technology & Industry Promotion Center (SITEC) speech database was utilized. The suggested method ensured the improvement in the quality of phoneme segmentation since it could provide the model with a higher number of non-blank classes or force the setting of a blank class to a non-blank class. The experimental findings demonstrated that a decrease of more than 20% occurred in the boundary error. In Graves and Schmidhuber [
16], a comparison of a bidirectional LSTM with other neural network architectures for the purpose of framewise phoneme classification on the TIMIT speech database was made. In the past, speech segment detection has been addressed in different conventional models. In Weinstein et al. [
17], the development of a system to conduct the acoustic–phonetic analysis of continuous speech was performed with the aim of serving as a part of an automatic speech understanding system. In Leung et al. [
18], a segmental approach was employed for the purpose of phonetic recognition. Multi-layer perceptrons were utilized to detect and classify phonemes for a segmental framework. In Ali et al. [
19], the acoustic and phonetic properties of the American English stop consonants were examined. In Natarajan and Jothilakshmi [
20], the segmentation of the continuous speech into smaller speech units was performed, and every unit was classified as a consonant or vowel by utilizing the formant frequencies and support vector machines (SVMs). It is reported that the Gaussian kernel yielded higher accuracy in comparison with the other kernels utilized. In Ades [
21], differences between vowels and consonants and between speech and nonspeech with regard to the context range in which they are set were explained. Identification, discrimination, and delayed recognition tests, in which the discrimination of vowels and consonants was performed at various levels, were explained regarding the higher range of the vowel series over the consonant series and the tasks’ memory demands. In Ooyen et al. [
22], two tests with vowels and consonants as the targets of phoneme detection in real words were performed. In the first test, the comparison of two comparatively distinct vowels with two confusable stop consonants was performed. In the second test, the comparison of two comparatively distinct vowels with the semivowels corresponding to them was carried out. The two tests demonstrated that the detection of English vowels was difficult in comparison with stop consonants but easy in comparison with semivowels. A novel method to segment phonemes by utilizing multilayer perceptron (MLP) was suggested in Suh and Lee [
23]. The suggested segmenter’s structure includes three parts, i.e., a preprocessor, an MLP-based phoneme segmenter, and a postprocessor. The pre-processor utilized feature parameters for every speech frame in accordance with the acoustic phonetic information. The MLP-based phoneme segmenter was utilized for the purpose of learning the ability to determine the boundaries in question and segment continuous speech into corresponding phonemes. In post-processing, the positions of the phoneme boundaries were decided by utilizing the MLP output. The best performance of phoneme segmentation was found to be approximately 87% with an accuracy of 15 ms.
In recent years, more researchers have effectively combined CNN and RNN models [
24]. These models were applied to different speech processing tasks to improve the accuracy [
25,
26,
27,
28,
29]. In general, it is beneficial to use CNN and RNN methods together. Therefore, in our work we used this model.
This paper presents an extensive and first study for finding optimal feature parameter sets by using the GRU for Kurdish speech segment detection. Also, it is the first time speech detection has been developed for the Kurdish language. The effects of varying hybrid features, window type, window size, and different classification methods were investigated for Kurdish speech segment detection. The identified optimal parameter features were analyzed using a novel Kurdish speech dataset collected from a television broadcast.
Kurdish represents the language that is spoken by an estimated seventeen million speakers in Turkey, Armenia, Syria, Azerbaijan, Iran, and Iraq. It is the most widely spoken language in Middle East after Arabic, Turkish, and Persian. Therefore, the speech segment detection study to be conducted on Kurdish is important.
2. Materials and Methods
Kurdish sound samples were collected from both males and females. Prior to phoneme segmentation, the continuous speech signal was segmented into words.
The phoneme segment detection of the spoken language has mainly focused on utilizing short-time energy and short-time zero crossing rate (ZCR) features. Since errors cause a low accuracy in speech segment detection, an effective algorithm should be used for the segment detection of the Kurdish speech at different speaking speeds. The mel frequency cepstral coefficient (MFCC) is known to mimic human hearing system [
30]. MFCC coefficients are orthogonal to each other and the mel filter bank also models the perceptions of the human ear system, and it yields better results in comparison with other feature extraction methods. Therefore, we used a hybrid feature vectors of the voice samples. Evaluation and comparison of the system performance were performed on the basis of energy, ZCR, and MFCC along with its first- and second-order derivatives. Thus, we used three types of hybrid feature vectors: energy, ZCR, and MFCC (EZMFCC); energy, ZCR, and delta-MFCC (EZDMFCC); and energy, ZCR, and delta-delta-MFCC (EZDDMFCC). Hybrid feature vectors were extracted using Hamming, Hanning, and rectangular windowing with 20, 25, 30, and 35 ms window sizes of the speech segment to see the effect of the different window types and window sizes with GRU training on the classification performance of the classifiers. For classification, convolutional neural network (CNN), multilayer perceptron (MLP), and the standard classifiers naive Bayes, random forest (RF), support vector machine (SVM), and k-nearest neighbors (k-NN) were used. Here, the details regarding the Kurdish speech corpus preparation and implementation of the segment detection architecture are explained. For this operation, the PRAAT 6.0.49 tool [
31], MATLAB R2018a (MathWorks, Natick, MA 01760-2098, USA), Keras Library [
32], Weka 3.9.3 [
33], and WekaDeeplearning4j [
34] are used.
2.1. Kurdish Phoneme Set and Its Properties
Kurdish is part of the Western Iranian group of the Indo-Iranian branch of the Indo-European language family. It is considerably similar to European languages, such as French, English, Russian, and German. Nevertheless, Kurdish is most similar to Persian among the European languages. However, both languages have a completely unique vocabulary, morphological structures, phonetic properties, and grammatical structures [
35]. Based on Latin letters, Kurdish consists of thirty-one phonemes, including twenty-three consonants and eight vowels. Five vowels of Kurdish are accepted as long vowels (/a/, /ê/, /î/, /û/, /o/), and the other three are accepted as short vowels (/e/, /i/, /u/). Despite the fact that they are generally named as long and short vowels, vowels are presently differentiated according to the position of articulation. There are a total of twenty-three consonants, including six labial consonants (/b/, /f/, /m/, /p/, /v/, /w/), seven fronto-palatal and dental consonants (/d/, /l/, /n/, /r/, /s/, /t/), five palatal consonants (/c/, /ç/, /j/, /ş/, /y/), and five anterior palatal and laryngeal consonants (/g/, /k/, /h/, /q/, /x/). In this paper, we detected phonemes consisting of the silent, eight vowels, and twenty-three consonants. The phonemes of Kurdish are presented in
Table 1, in which Kurdish letters, International Phonetic Alphabet (IPA) notations, and phonetic descriptions are given [
35,
36,
37].
2.2. Speech Dataset
In this study, a novel Kurdish dataset was created and used. The speech corpus was a collection of speech recordings from Turkish Radio and the Television Corporation (TRT) Nûçe news channel. For this study, the speech corpus was selected from different Kurdish sources, such as education news, culture news, art news, economy news, health news, and political news. The collected Kurdish voice samples of sentences and clauses of different lengths were taken from four male and three female speakers in the age group of 20–45 years. The speech sentences contained CV (consonant–vowel), VC (vowel–consonant), CVC (consonant–vowel–consonant), CCV (consonant–consonant–vowel), CVCC (consonant–vowel–consonant–consonant) and CCVCC (consonant–consonant–vowel–consonant–consonant) as different types of words. The recordings were performed in a quiet setting using a high-quality (low noise) desktop microphone at a sampling frequency of 44,100 Hz with 16-bit quantization and a mono-channel. Speech data were stored in the “wav” format. The whole speech corpus was randomly split into two parts: 66% for training, and the remaining 33% for testing the system.
The phoneme segment detection method was implemented on the continuous Kurdish speech containing almost 6819 phonemes in total.
Table 2 and
Table 3 present the dataset of phonemes from male and female speakers, respectively.
2.3. Proposed Model
In this study, the focus was placed on the recently suggested gated recurrent unit (GRU)-based model, the research on which had not been conducted for Kurdish speech before this study. The RNN was customized for speech segment detection based on the discrimination between consonants, vowels, and silence.
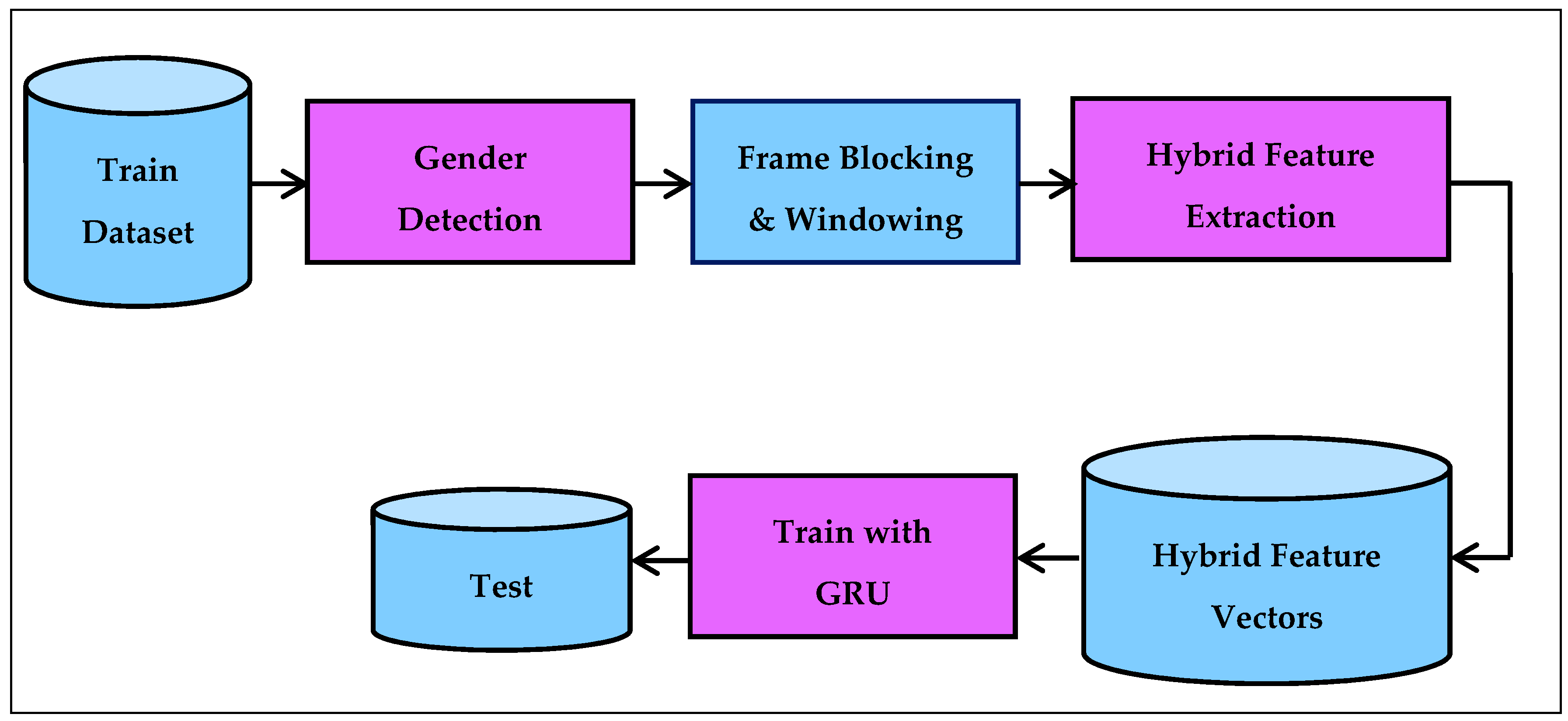
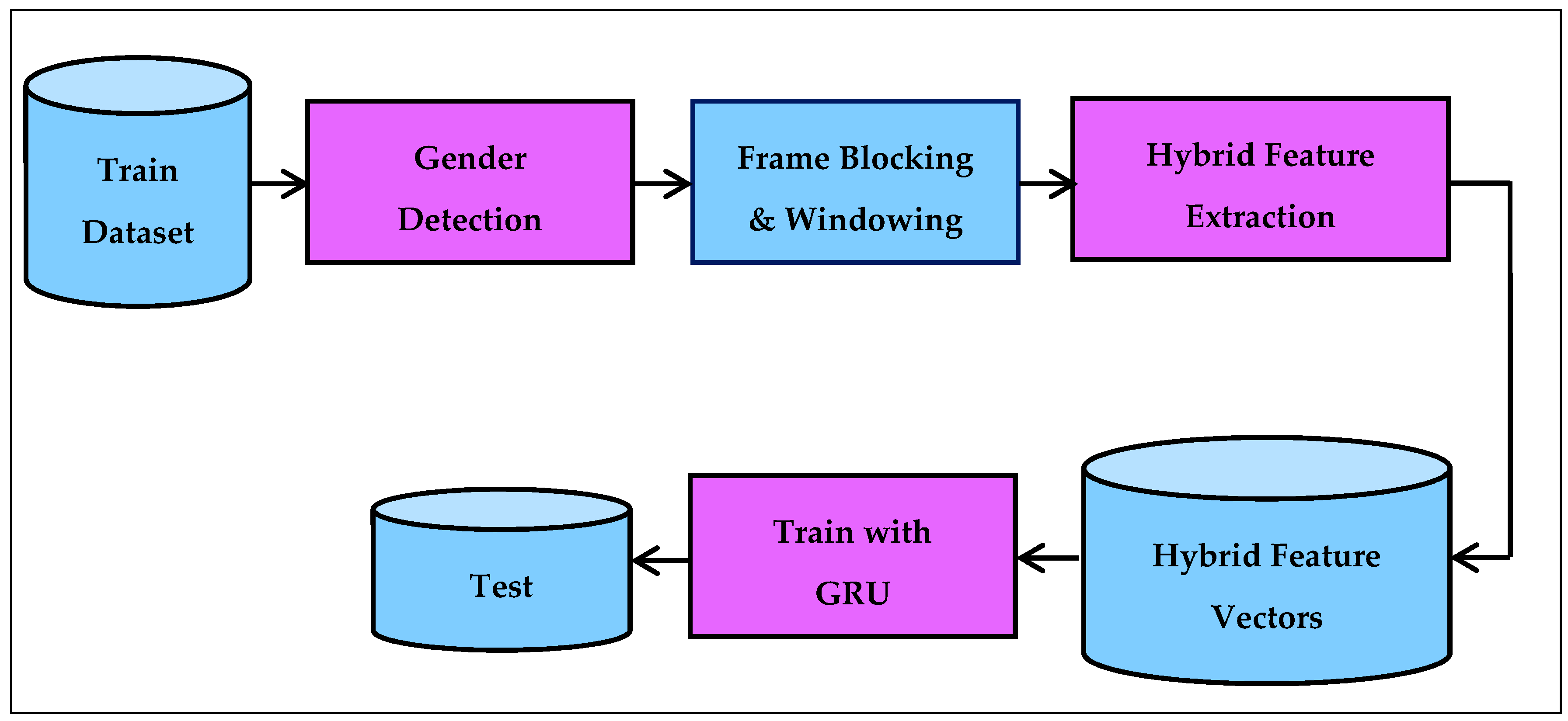
Figure 1 shows the general steps of the proposed architecture for the Kurdish C/V/S speech segment detection.
The training dataset contained C/V/S speech data that was tagged manually. The gender detection step identified the gender of a speaker from these tagged speech signals. In the frame blocking and windowing step, the tagged speech signals were segmented into small duration blocks of 20, 25, 30, and 35 ms known as frames. After that, each frame was multiplied with a Hamming, Hanning, or rectangular window function. In the hybrid feature extraction step, each windowed frame feature was obtained using “energy, ZCR, MFCC (EZMFCC)” or “energy, ZCR, D-MFCC (EZDMFCC)” or “energy, ZCR, DD-MFCC (EZDDMFCC)” techniques. In the hybrid feature vectors step, 15-, 28-, or 41-dimensional hybrid feature vectors were generated per frame. In the training with the GRU step, each different dimensional hybrid feature vectors were given to the GRU for learning a C/V/S pattern. The GRU computation was performed by the gated recurrent unit, which modulates information inside the unit without having a separate memory cell. It combines the “forget gate” and “input gate” into a single “update gate” and has an additional “reset gate.”
A GRU network accepts an input sequence x = (x1; …; xt). Each xt represents a hybrid feature frame vector during the training process. The hybrid feature frame vector training set is introduced into the network as a GRU block series.
Each j.GRU block was computed in evolutionary terms based on the following equations in an iterative way from t = 1 to T.
At time t, the activation of the j.GRU output is the .GRU unit.
The activation
of the GRU at time
t is a linear interpolation between the previous activation
and the candidate activation
are represented in Equations (1) and (2):
where
refers to a set of reset gates, and ∗ refers to an element-wise multiplication.
The update gate
decides how much of an update of its activation the unit performs and checks how much the past state must mean at the moment. There will be active reset gates
r in units having short-term dependencies, while there are active update gates
z in units having long-term dependencies. The update gates are given as Equation (3):
In case of the off reset gate (
= 0), it ensures that the unit forgets the past. This is similar to allowing the unit to read the first symbol of an input sequence, where
is the sigmoid function.
is the weight vector for the update gate, and
is the weight vector for the reset gate.
The reset gate is computed using Equation (4):
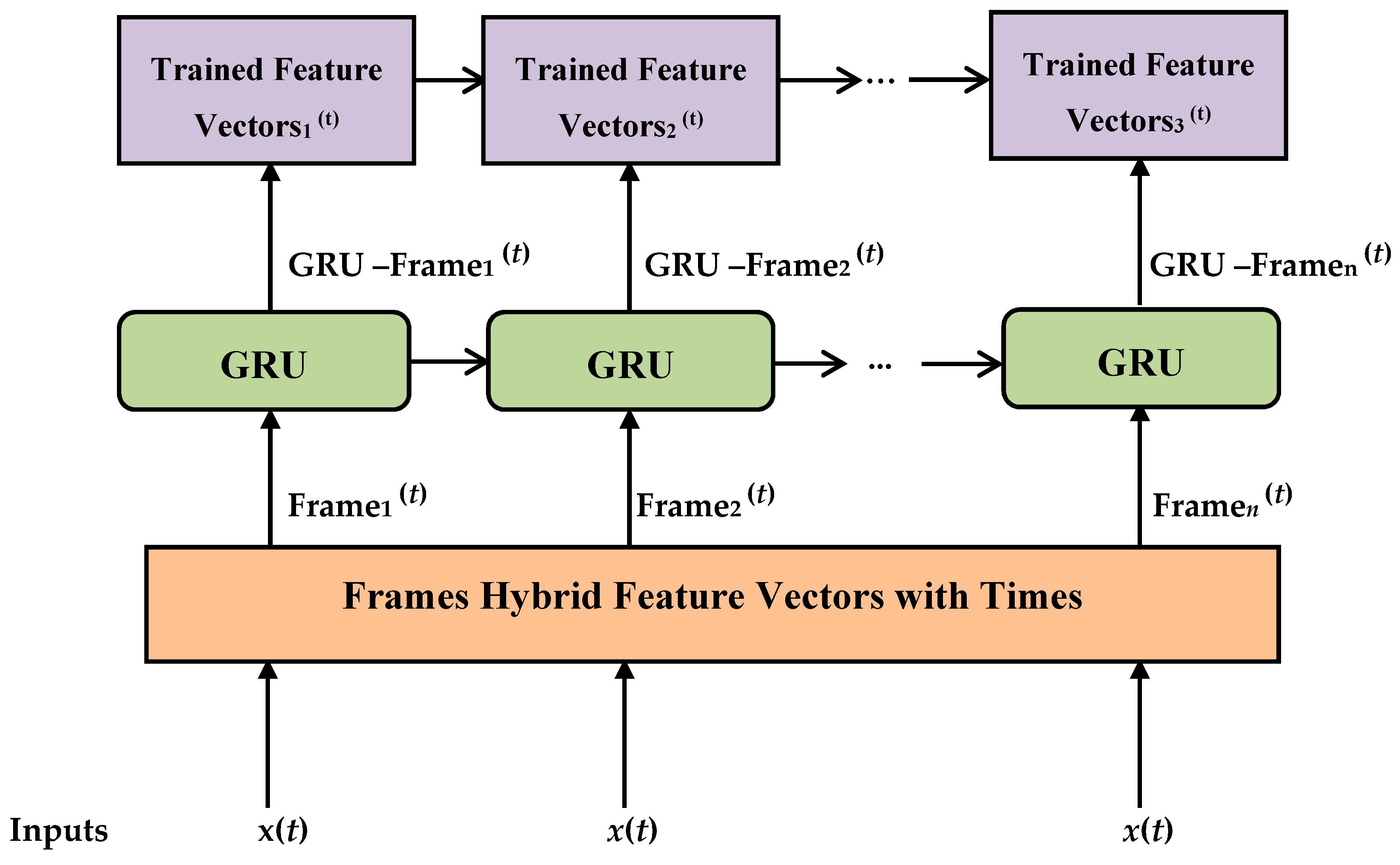
Hybrid feature frame vectors were utilized by GRU blocks in order to strongly match C/V/S patterns.
Figure 2 describes the proposed GRU-trained model.
The GRU-based trained feature vectors are used by CNN, MLP, naive Bayes, SVM, random forest, and k-NN classifiers in the testing step.
2.3.1. Created Tagged Speech
First, the voice data obtained in this study were subjected to a Wiener filter as a preprocessing step to eliminate noises from environmental factors and microphone noises [
38]. The Wiener filter is a method performed in frequency space, where
y(
n) is a noisy speech signal that is expressed using Equation (5):
where
x(
n) is the clean signal,
v(
n) is the white Gaussian noise, and
n is the discrete time variable.
The error signal (
ex(
n)) between the clean speech sample at time
n and its estimate can be defined using Equation (6):
where the superscript
T denotes the transpose of a vector or a matrix.
is a Finite Impulse Response (FIR) filter of length
L and its transpose is given in Equation (7).
is a vector containing the most recent samples of the observation signal
y(
n) and its transpose is given in Equation (8).
The Wiener filter coefficients are obtained by minimizing the average squared error expressed by .
To create a dataset and assign an appropriate speech class (C/V/S) to each speech signal, every speech sentence should have an associated phoneme-level segmentation.
In this work, to create a reference dataset, manual segmentation methods were used. For this purpose, the “Pratt” package was used as a major tool. Every speech sentence was carefully examined and labeled manually using the selected tool. After labeling was completed, a tagged speech label file was created.
The manual segmentation method is considered to exhibit more accurate performance in comparison with automatic segmentation [
39,
40,
41]. Therefore, manual segmentation was employed to create the unique labeled Kurdish dataset to be used in other studies in the future.
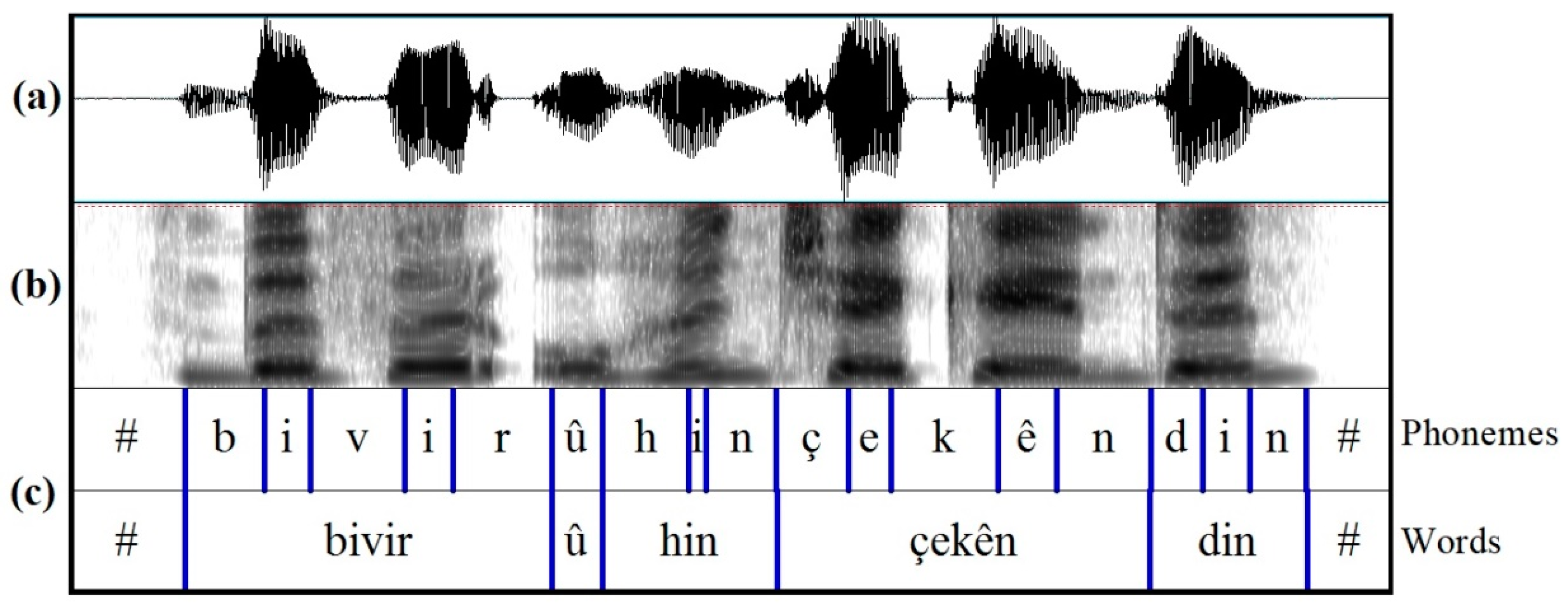
The phoneme segmentation is represented in
Figure 3. In this figure, a sample annotated speech waveform and its spectrogram representing the Kurdish sentence “Bivir û hinçekên din” spoken by an adult female are shown.
2.3.2. Gender Detection
The short-time autocorrelation and average magnitude difference function (AMDF) was used collectively by assigning some weightage factor and setting a threshold based on the fact that males have a lower fundamental frequency of approximately 120 Hz compared to a female fundamental frequency of approximately 200 Hz [
42].
2.3.3. Frame Blocking and Windowing
The speech signals were processed efficiently between short-time periods of 20 to 35 ms since distinctive features of sound signals were stable only within short periods of time. The speech data was divided into short periods of time intervals frame by frame.
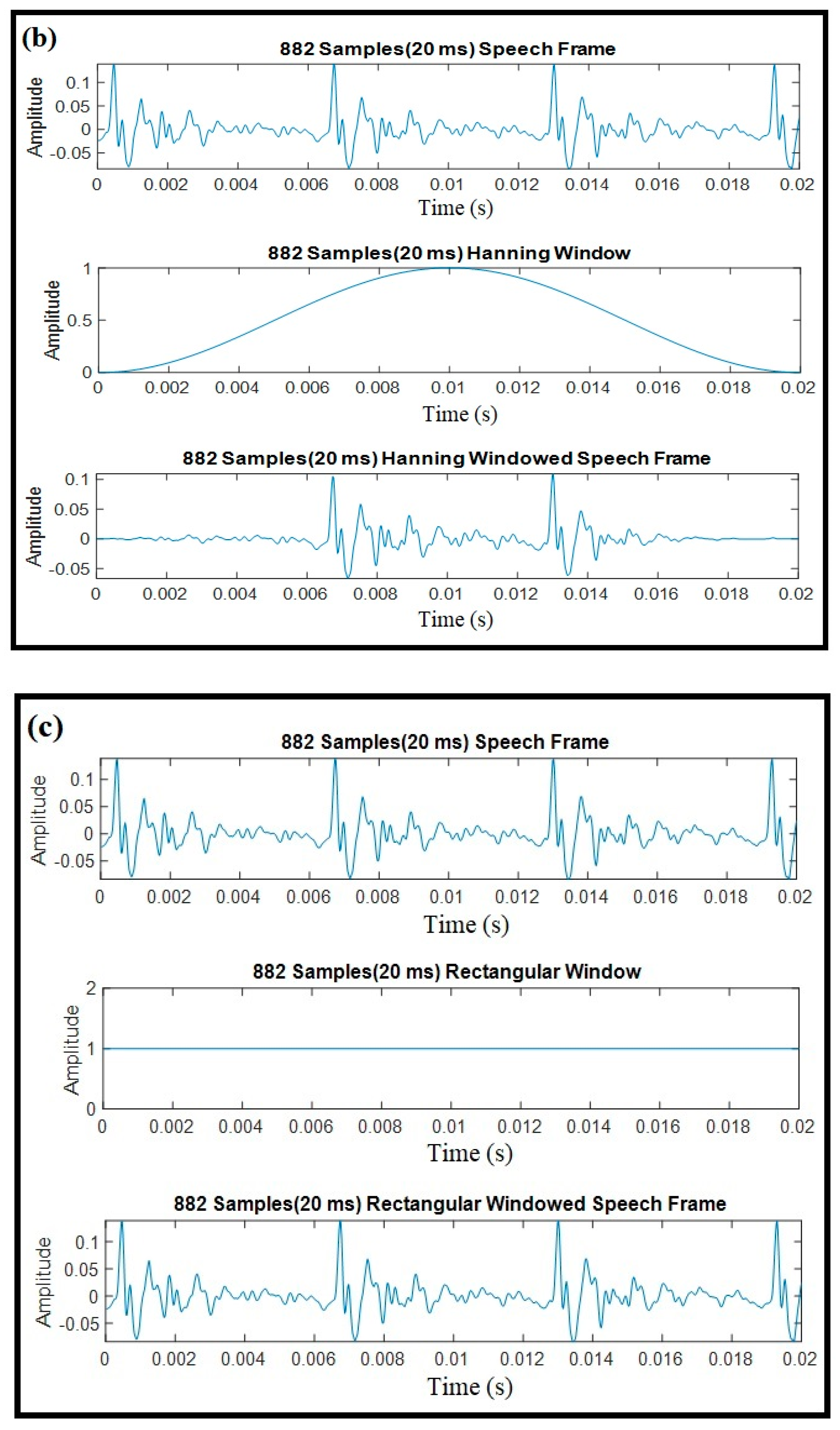
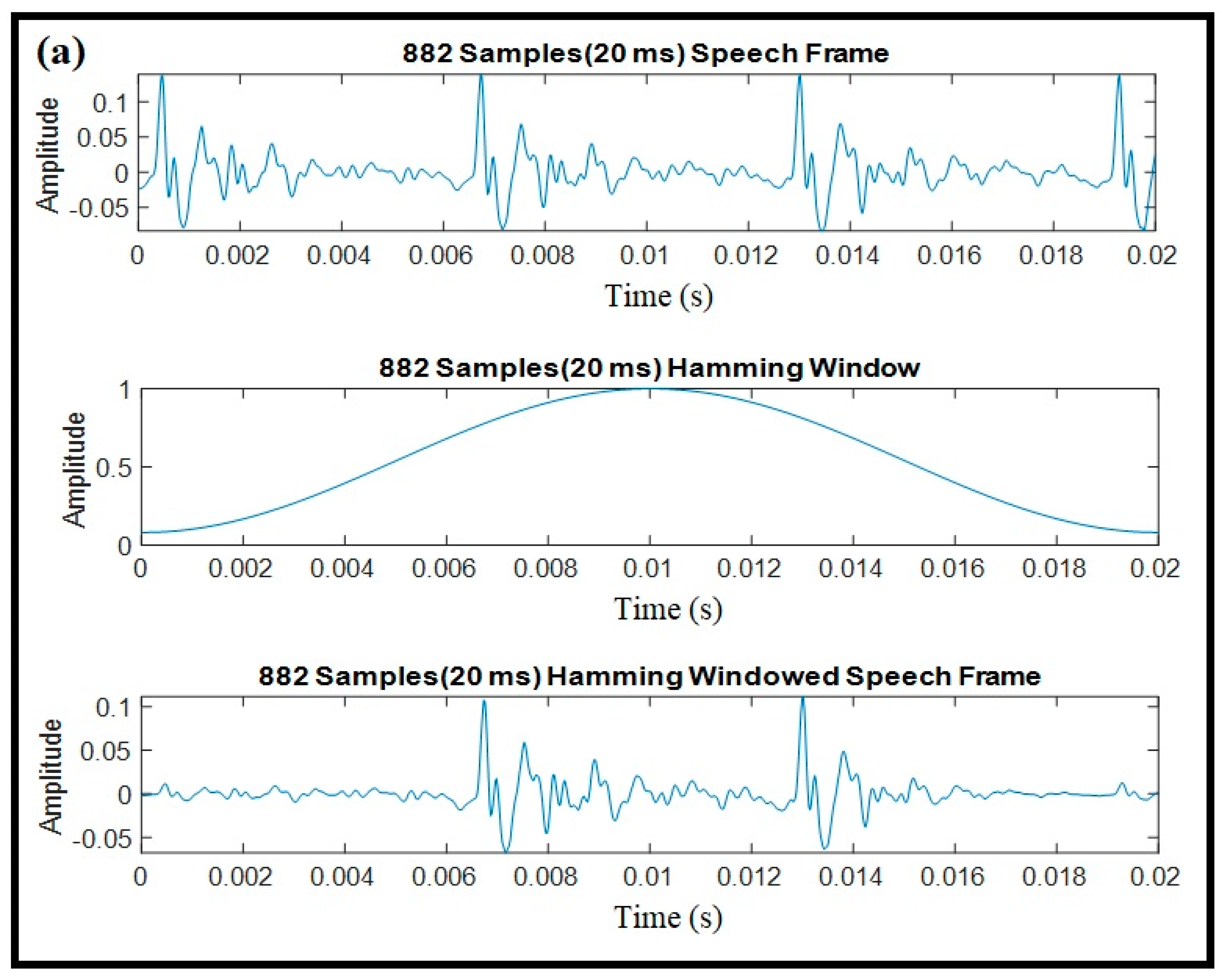
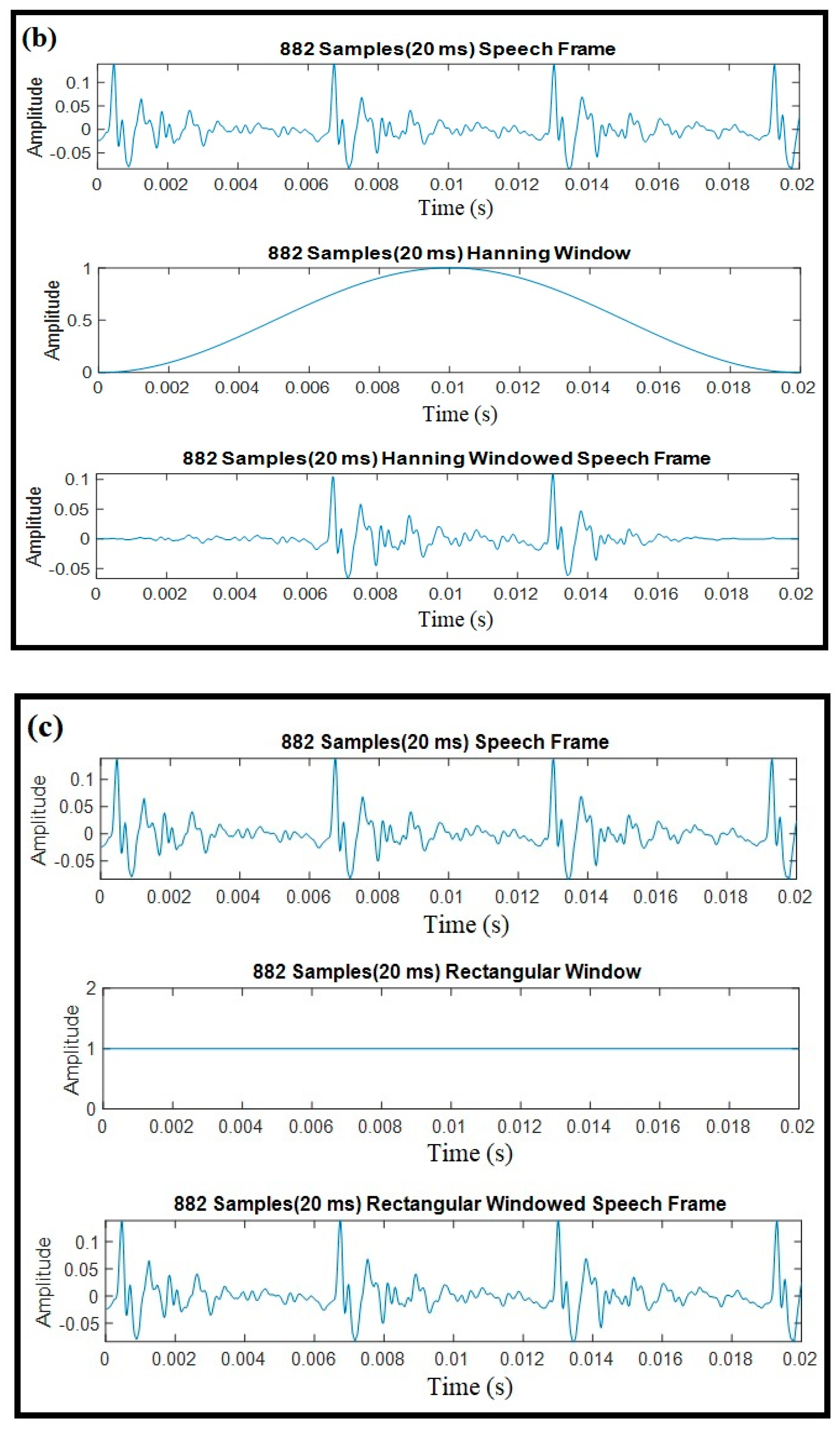
Windowing was applied to framed speech signals. The purpose of this step was to eliminate discontinuities at the beginning and end of each frame [
43]. This operation can be accomplished using a function that is called the window function. The most commonly used windowing functions are the Hamming, Hanning, and rectangular windowing techniques [
44,
45]. Windowing examples with these functions for 20 ms speech recorded from a female speaker are illustrated in
Figure 4.
A windowing operation is simply the multiplication of the speech data and windowing function for each data frame. For the purpose of performance analysis, three window functions were implemented and the corresponding outputs are indicated.
2.3.4. Hybrid Feature Extraction
1. Short-Time Signal Energy
Short-time energy represents the dominant and most natural characteristic utilized. From a physical aspect, energy constitutes a measure of how much signal there is at any moment. The calculation of a signal’s energy is generally performed on a short-term basis as a result of windowing the signal at a specific time, squaring samples, and obtaining the average [
46,
47,
48]. The square root of the signal’s energy is known as the root mean square (RMS) value. The short-time energy function (
) of a speech frame having length
N is described in Equation (9):
The RMS energy (
) of the frame in question can be presented as in Equation (10):
where
x(
m) denotes the discrete-time audio signal,
n is the time index of the short-time energy, and
w(
m) denotes the window function.
2. Short-Time Zero Crossing Rate
The ZCR denotes the number of times speech samples alter the algebraic sign in a specific frame. The rate indicating the occurrence of zero crossings represents a simple measure of the signal’s frequency content. It is also a measure of the number of times in a particular time interval/frame when the amplitude of speech signals passes through a zero value [
46,
47,
48].
The short-time zero crossing (
) of a speech frame and
are described in Equations (11) and (12), respectively:
where:
and
w(
m) refers to a window with length
n, given in the equation.
3. Mel Frequency Cepstral Coefficient (MFCC)
MFCC is one of the most widely used and most effective feature extraction methods in most speech processing systems. One of its significant advantages is that the same words are not affected too much by changes that occur during vocalization.
MFCC imitates the perception of human ears and is calculated by using a fast Fourier transform (FFT), which is a fast algorithm used to implement the discrete Fourier transforms. The discrete Fourier transform (DFT) is expressed as in Equation (13) for an
N-sample frame:
where
f(
n) denotes the DFT,
n is the sample index, and
y refers to the signal windowing results.
Since the human hearing system perceives frequency values up to 1 kHz linearly and frequency values higher than 1 kHz logarithmically, there was a need for a unit that takes the hearing system as a model [
49]. This unit is called the Mel frequency, where linear frequency values are converted into Mel frequency values using Equation (14), where “
f” refers to the frequency in Hz, and “Mel (
f)“ refers to the Mel frequency:
Finally, the Mel spectrum, of which the logarithm has been taken, is converted back to the time domain.
Delta-MFCC (D-MFCC) and the delta-delta-MFCC (DD-MFCC) are the first-order and the second-order derivatives of the MFCC, respectively [
50]. D-MFCC and DD-MFCC are also known under the name of differential and acceleration coefficients.
The D-MFCC coefficients are calculated using Equation (15):
where
dt refers to the delta coefficient at time
t, calculated with regard to the corresponding static coefficients
ct − θ to
ct + θ, and
Θ refers to the size of the delta window.
The DD-MFCC coefficients are computed by taking derivative of Equation (15).
2.3.5. Gated Recurrent Unit Recurrent Neural Networks
The gated recurrent unit (GRU) represents a kind of recurrent neural network. The GRU offers comparable performance and is significantly faster to compute. The network learns how to use its gates to protect its memory such that it is able to make longer-term predictions [
51].
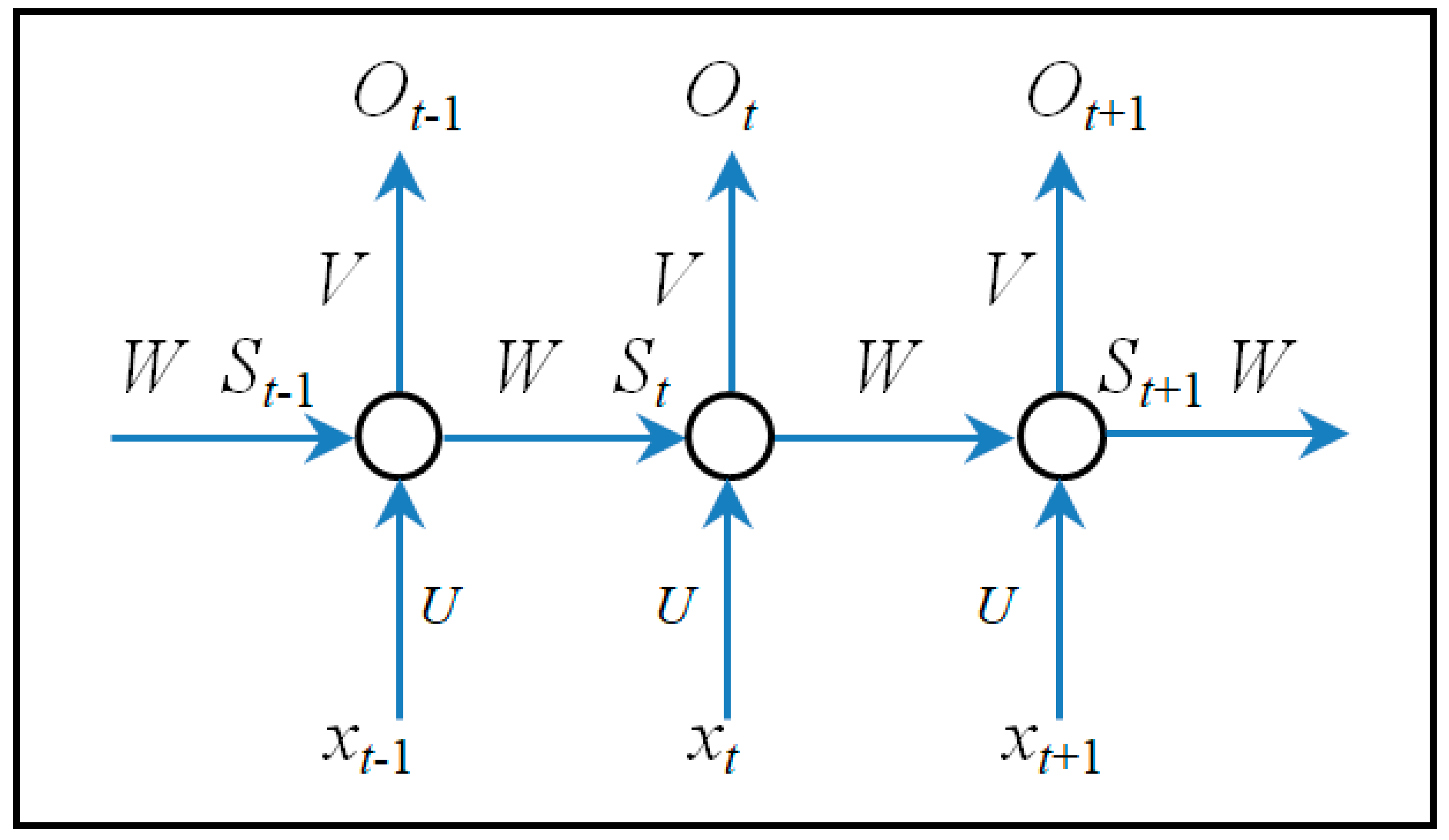
Figure 5 describes the architecture of a recurrent neural network, where
xt and
St denote an input and hidden units for a given time step, respectively, at time
t.
Ot is the output at step
t.
U,
W, and
V are weight vectors for inputs, hidden layers, and outputs, respectively. The GRU recurrent neural network is illustrated in
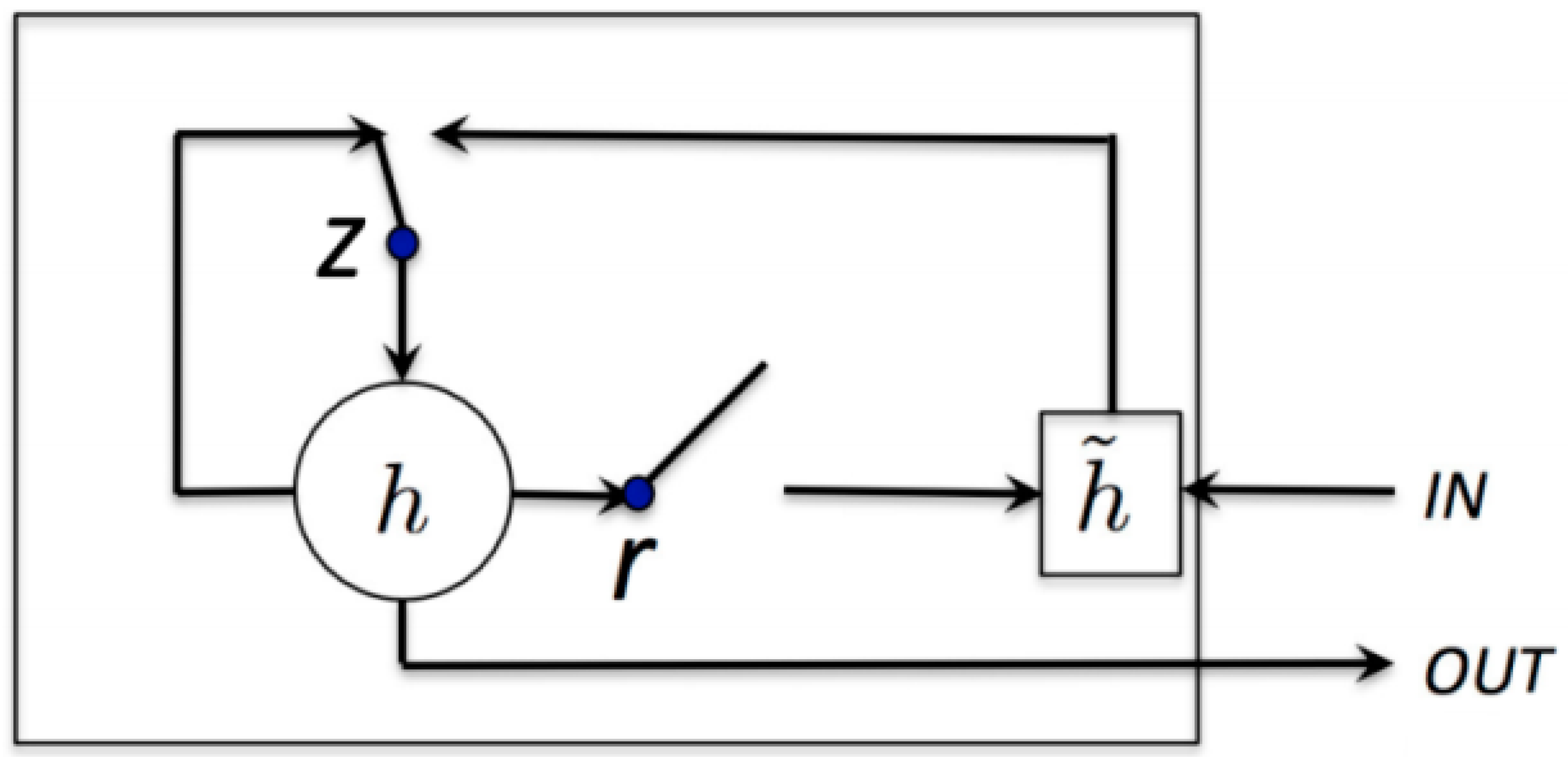
Figure 6, where
z and
r represent the update and reset gate vectors, respectively.
and
are the activation and the candidate activation. The update and reset gates ensure that the cell memory is not taken over by tracking short-term dependencies. This means that we have dedicated mechanisms for when the hidden state should be updated and when it should be reset. The decision on what information is thrown away or kept in the cell is made by the sigmoid layer.
2.3.6. Artificial Neural Network (ANN)
1. Multilayer Perceptron (MLP)
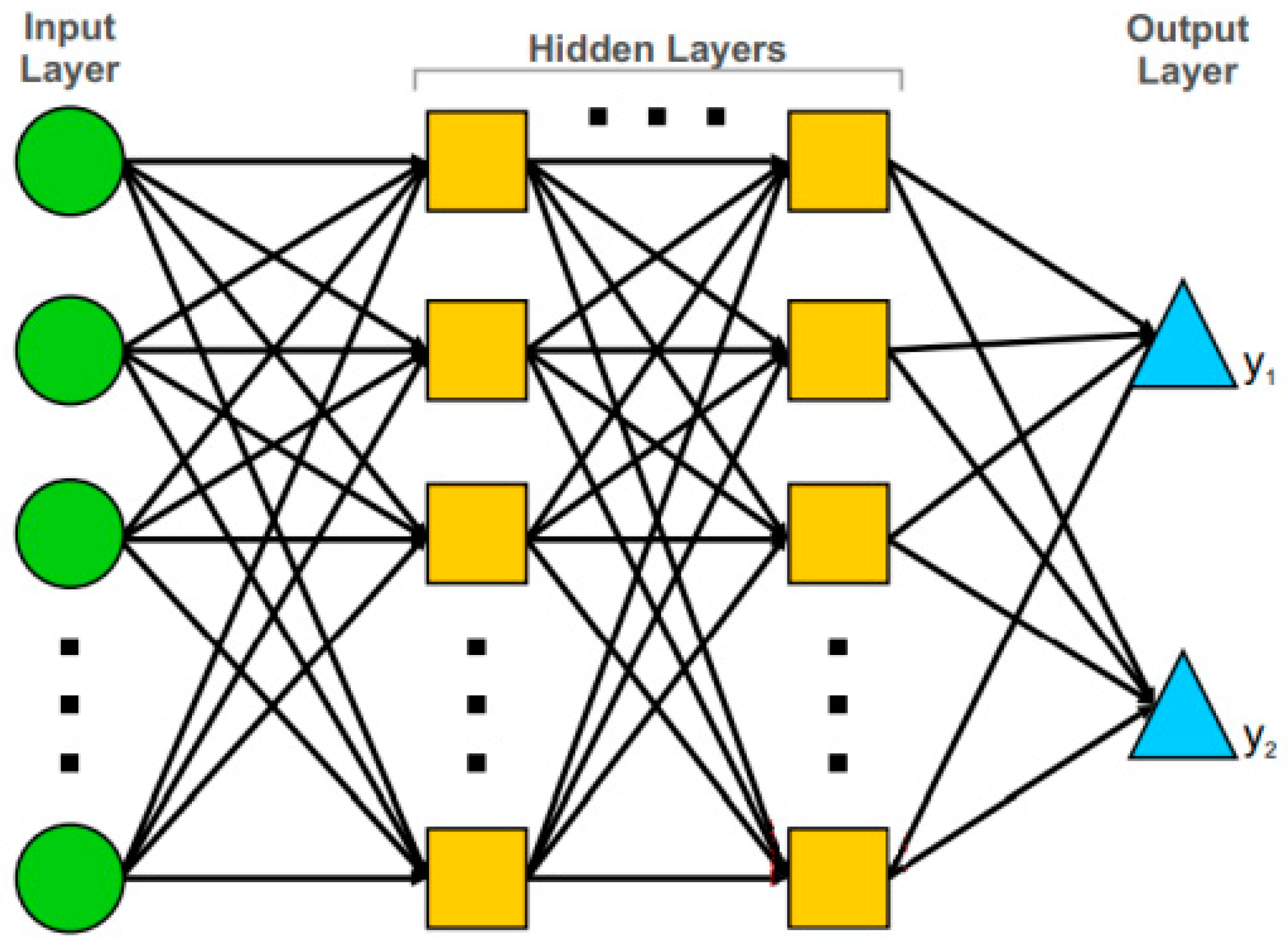
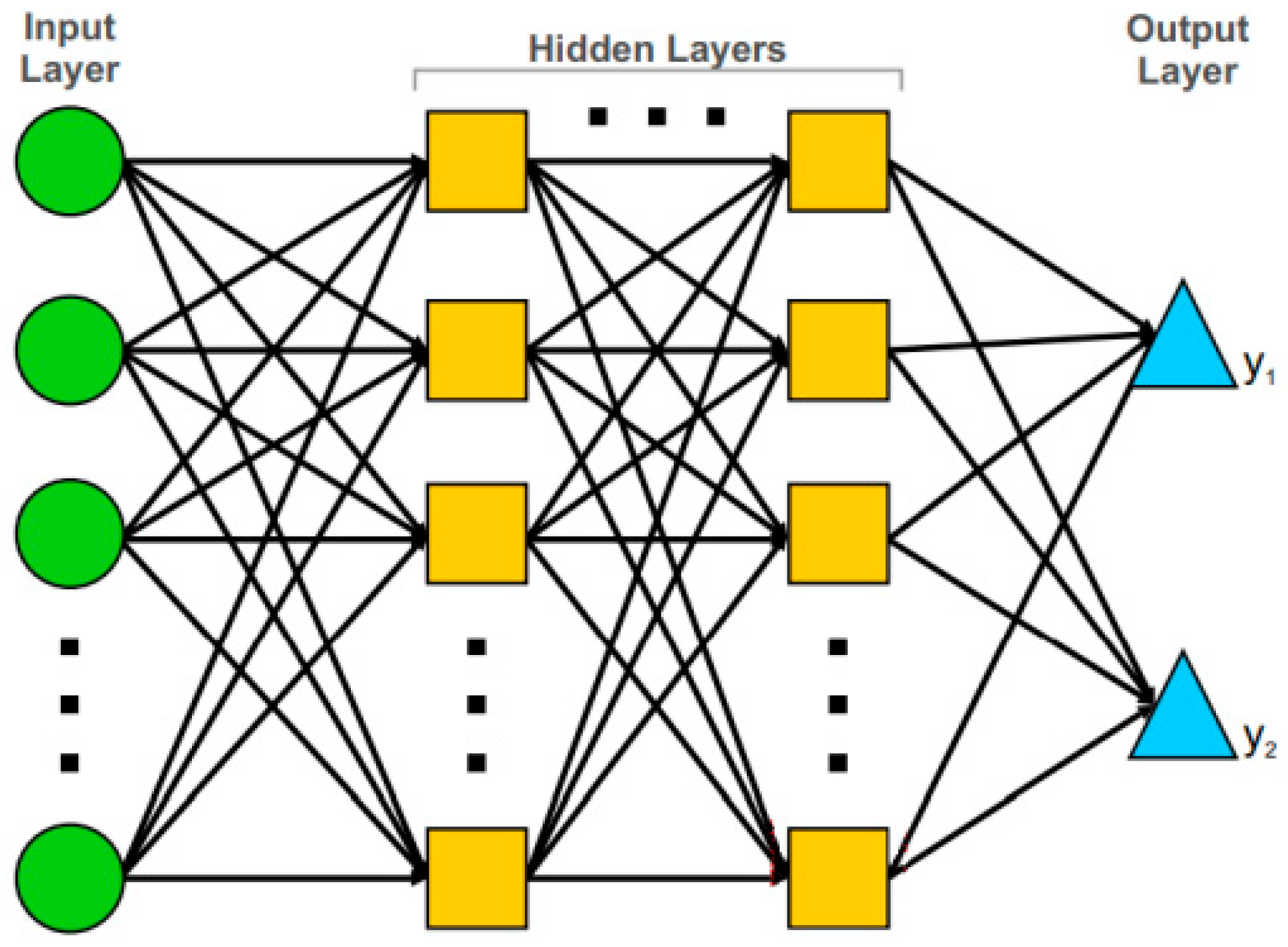
A multilayer perceptron is a thinking structure that is formed by connecting neurons to each other with synaptic connections, which is inspired by the human brain and has a learning algorithm, similar to neural networks in biological systems. An MLP represents a feed-forward artificial neural network (ANN) model, which maps sets of input data onto a set of suitable outputs.
Figure 7 presents the architecture of MLP. An MLP contains multiple layers of nodes in a directed graph, with every layer completely connected to the following one. Apart from the input nodes, every node constitutes a neuron, or a processing element, with a nonlinear activation function. The MLP uses a supervised learning technique that is called back-propagation in order to train the network [
52].
2. Convolutional Neural Network (CNN).
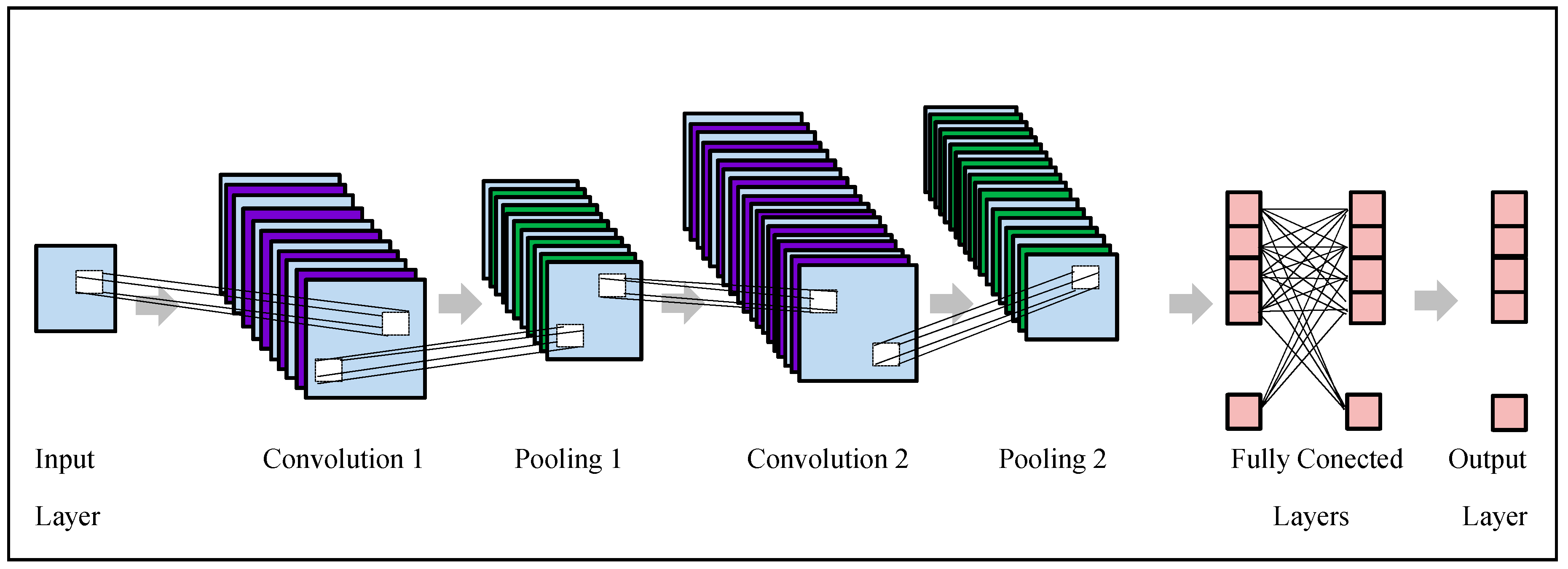
Deep learning is generally applied by utilizing the neural network architecture. With deep learning, the model learns and abstracts the relevant information automatically as the data passes through the network. The term “deep” denotes the number of layers in the network, i.e., the higher the number of layers is, the deeper the network is. Layers are interconnected through nodes, or neurons, with every hidden layer by utilizing the previous layer’s output as its input.
The most popular deep learning network is a convolutional neural network (CNN, or ConvNet). The CNN includes an input layer, an output layer, and several hidden layers. Convolution, activation or using a rectified linear unit (ReLU), and pooling represent the three most frequent layers. The above-mentioned operations are performed repeatedly over tens or hundreds of layers, with every layer learning for the purpose of detecting various features in the input data [
53].
Figure 8 shows the general framework of convolution neural networks (CNNs).
3. Results and Discussion
In this study, we used three types of hybrid feature vectors. The first type of hybrid feature vector comprises EZMFCC parameters. The second type of hybrid feature vector comprises EZDMFCC parameters. The third type of hybrid feature vector comprises EZDDMFCC parameters. The above-mentioned types of hybrid features were extracted for each 20, 25, 30, and 35 ms window duration using the Hamming, Hanning, and rectangular windowing functions. All these parameters were used at the feature extraction stage in the speech segment detection. The hybrid feature extraction process produced hybrid feature vectors, which were introduced as an input into the GRU system for learning a pattern and finding an optimal solution for each speech category (C/V/S). After the GRU was trained with the training set, an optimal hybrid feature parameter was found using the EZDDMFCC. Different experiments have been conducted for the C/V/S segment detection with different classifier models. The most common classifier models are CNN, MLP, naive Bayes, SVM, random forest, and k-NN. For the k-NN, the parameter “k” was set to 3. For the MLP, the number of hidden neurons suggested by the empirical selection was 10, 20, 30, 40, and 50 hidden neurons, which were trained separately, and the performance of every neuron was assessed. For the CNN, two convolutional layers with 20 and 100 feature maps with 5 × 5 patch sizes and 2 × 2 max pooling, respectively, were used.
Weka was utilized for obtaining classification accuracies. Accuracy was taken as the performance measure when counting the number of correct C/V/S speech segment detections. The accuracy function was calculated using Equation (16):
where
TP,
TN,
FP, and
FN are true positive, true negative, false positive, and false negative, respectively.
Table 4,
Table 5 and
Table 6 present the accuracy results obtained with the proposed GRU-based training method for male speakers, while
Table 7,
Table 8 and
Table 9 present the accuracy results obtained with the proposed GRU-based training method for female speakers.
3.1. Results of the Analysis of the Hybrid Features with GRU-Based Training
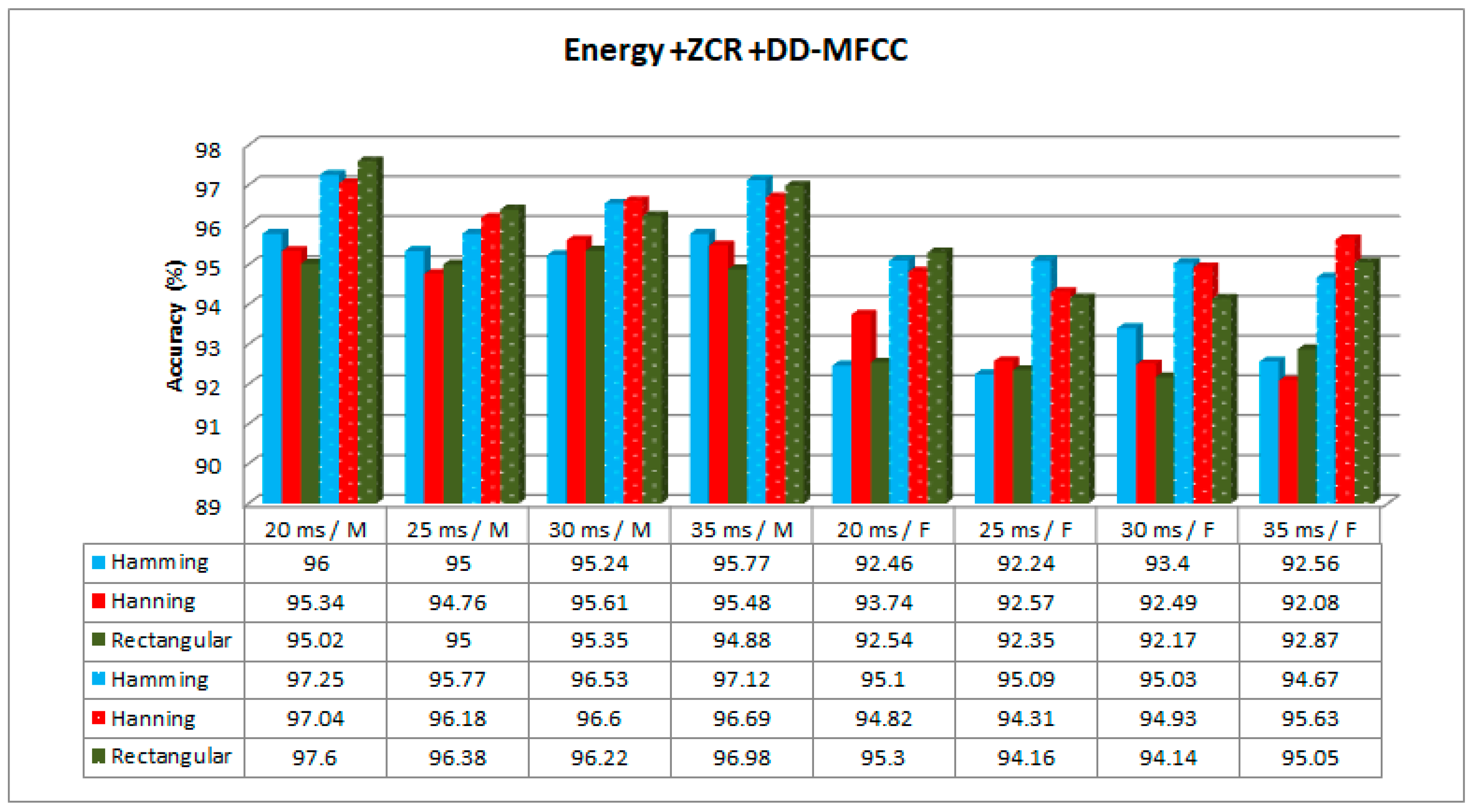
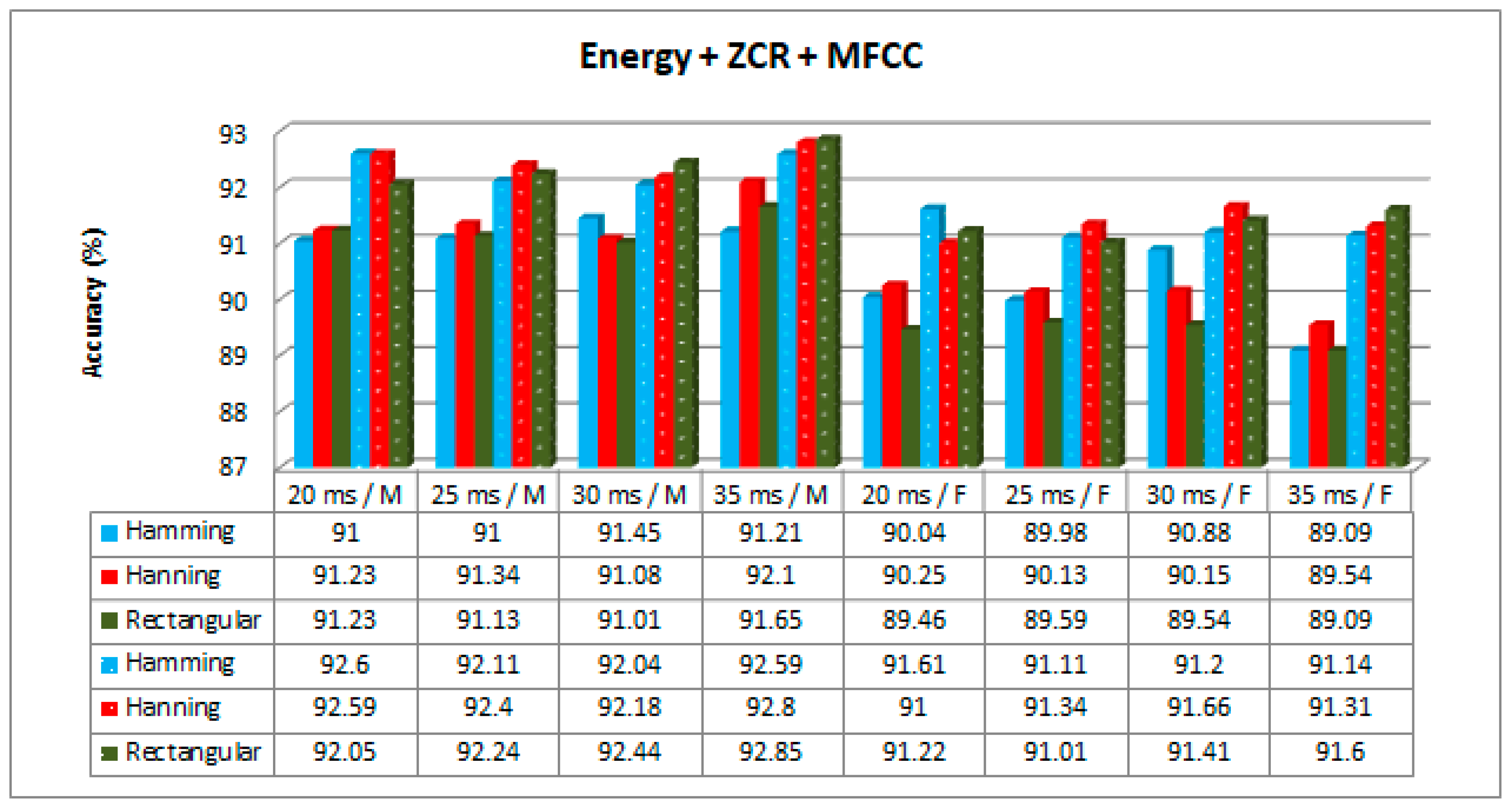
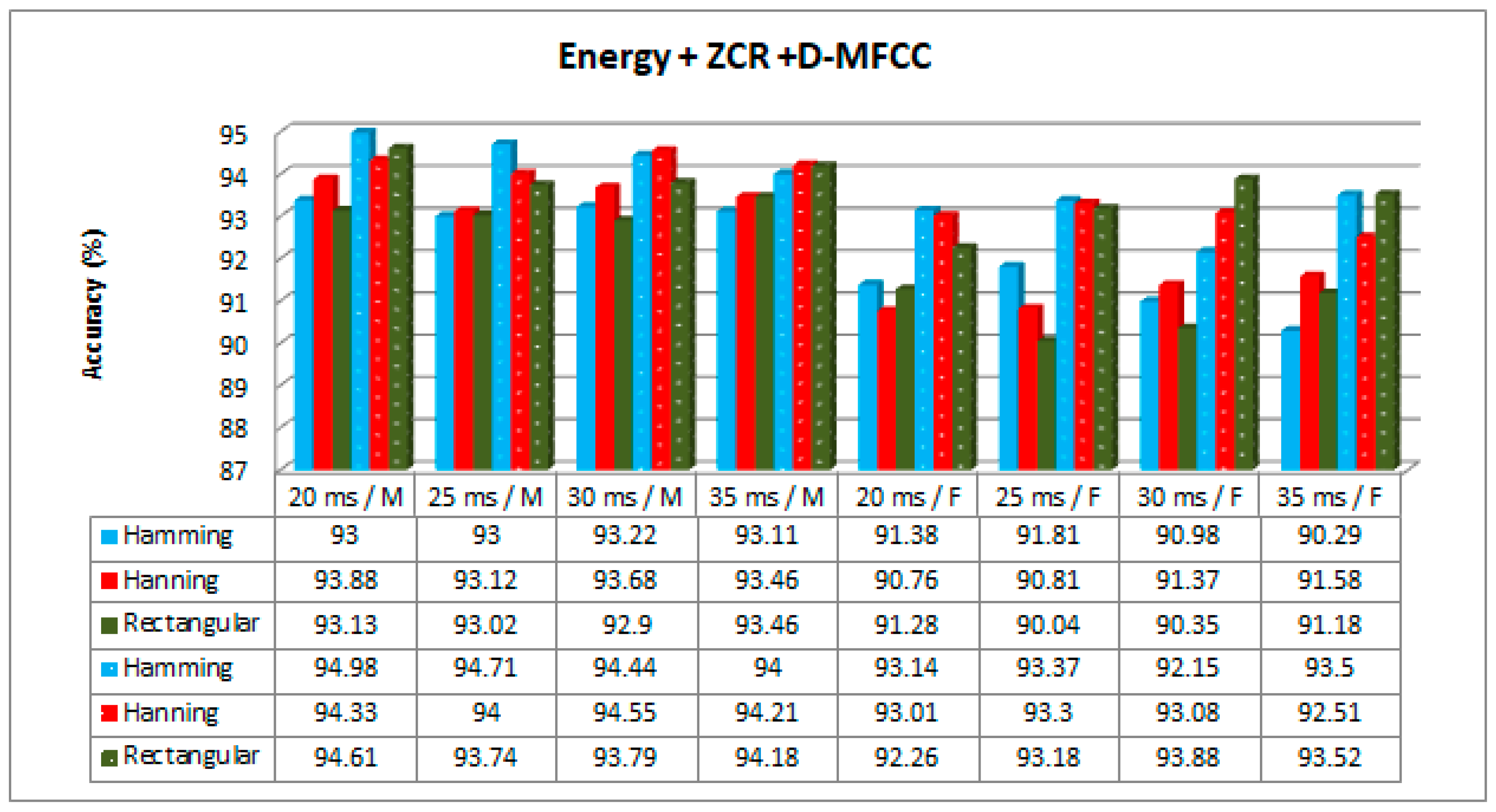
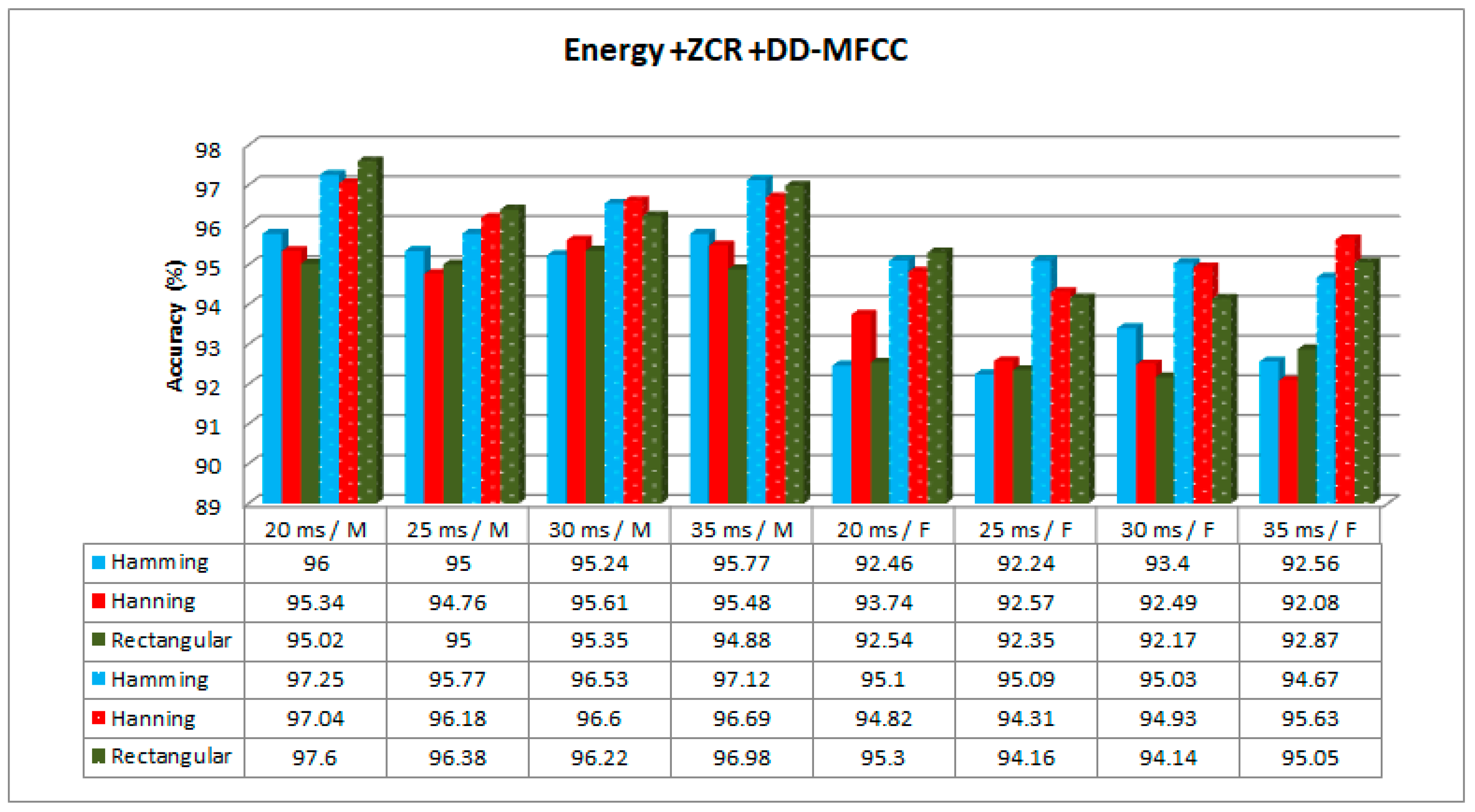
According to the results presented in the tables, the best accuracy was obtained using EZDDMFCC for all window types, window sizes, classification methods, and speaker gender. This might be due to the number of novel features existing in EZDDMFCC as a result of double derivation of the MFCC. The feature dimension of EZDDMFCC was higher than the others. However, it took longer time to compute, as seen in
Table 10.
3.2. Results of the Analysis of the Window Size with GRU-Based Training
The experiment conducted on 20 ms, 25 ms, 30 ms, and 35 ms of speech segments gave the maximum performance accuracies of 97.60%, 96.38%, 96.60%, and 97.12%, respectively, for male speakers, and the maximum performance accuracies of 95.30%, 95.09%, 95.03%, and 95.63%, respectively, for female speakers. According to the results, the effect of window size on the accuracy was insignificant. However, a window size of 20 ms performed slightly better than the others. Actually, performance of the window size depended on the nature of the speech signal.
3.3. Results of the Analysis of the Window Type with GRU-Based Training
The results based on three different window types gave the highest accuracy values of 97.25% for the Hamming windows, 97.04% for the Hanning windows, and 97.60% for the rectangular windows for male speakers, and 95.10% for the Hamming windows, 95.63% for the Hanning windows, and 95.30% for the rectangular windows for female speakers. According to the results, the effect of the window type on the accuracy was insignificant.
3.4. Results of the Analysis of the Classification Model with GRU-Based Training
According to the results, the CNN showed a relatively high classification performance (97.60% for male and 95.63% for female speakers) compared to others.
Figure 9,
Figure 10 and
Figure 11 show the accuracy results obtained with and without the proposed GRU-based training method for different hybrid features, window sizes, and window types. Only the CNN was employed as a classifier since it outperformed the others. The results demonstrate that the best performance was achieved with EZDDMFCC (
Figure 10). According to the accuracy values presented in
Figure 10, the best performances for male and female speakers were obtained with the GRU rectangular window with a size of 20 ms and Hanning window with a size of 35 ms, respectively.
Algorithms were implemented on a PC with an Intel Core i3-2367M processor, a 4 GB memory size, and a 1.40 GHz clock speed.
Table 10 summarizes the computational times of the implemented algorithms.
In this respect, it is possible to state that: computational complexity/accuracy of the EZMFCC < computational complexity/accuracy of the EZDMFCC < computational complexity/accuracy of the EZDDMFCC.
In this study we used various combination parameters, and the models are summarized in
Table 11.
Various studies have been carried out to investigate speech segmentation. However, although there are studies conducted with standard datasets created by various universities and institutions in different languages, no comprehensive study to determine the optimum feature parameters based on the GRU for Kurdish speech segment detection has been encountered. The Kurdish vocabulary dataset, which was derived from TRT Kurdî Nûçe news speech signals, was used to train the classifier with GRU recurrent neural networks.
In this study the automatic detection of the C/V/S phoneme segmentation method used for the continuous Kurdish speech segmentation was discussed. The results demonstrate that the suggested method yields promising results for identifying the optimal set of feature parameters for the Kurdish language classifier. According to the obtained analysis results, it was observed that the selection of feature extraction methods and the selection of classifier models in male and female speakers were the two main factors affecting the performance of the Kurdish C/V/S speech detection system. For male voices, the optimal choice was the use of the rectangular window with a window size of 20 ms with EZDDMFCC feature parameters and the CNN classifier. For female voices, the optimal choice was the use of the Hanning window with a window size of 35 ms with EZDDMFCC feature parameters and the CNN classifier. We saw better performances for the male class with respect to female. We do not think that the difference in the performances was caused by the imbalance of the two classes. It may be attributed to the difference in the speaking style of female speakers.
As a result, it was observed that as the number of novel features increased, the success rate increased for female and male speakers. The windowing time and windowing techniques had an insignificant and similar contribution. The results demonstrate that CNN deep learning classifiers achieved higher classification performance compared to MLP and standard classifiers.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}