1. Introduction
Non-Intrusive Load Monitoring (NILM) is the technique used to estimate the consumption of individual household appliances based on the aggregate consumption of a home. This allows the monitoring of the consumption of household appliances without the need to install dedicated sensors for the individual appliances, avoiding electrical system complications and related costs.
The load disaggregation starting from the measurement of the power used over time can be a valuable resource for both the users of an electricity distribution service, (domestic and/or industrial) and for the power utilities themselves, allowing a better understanding of the needs of users and to offer them personalized services [
1]. Several studies have also shown that knowledge of the consumption of individual devices can have a positive effect on user behavior allowing savings of up to 12% on annual consumption [
2]. The savings result from a more conscious behaviour of the user of the electrical service, who can identify the appliances with the highest consumption and limit their use or replace them with more efficient ones. The NILM technique can also be used in association with a home management system [
3], or with a price-sensitive demand side management system [
4].
The NILM technique was introduced by Hart’s pioneering work in the mid-1980s when he was the first to use active and reactive power transient analysis to detect when household appliances were turned on and off. Since then, many research papers have been published as well as several excellent state of the art reviews, such as [
5,
6,
7] and, more recently [
8].
Following the approach described in [
8], we can describe the disaggregation process through three steps, the identification of events, the synthesis of necessary and optimal features for classification, and the actual load classification and disaggregation. The events correspond to changes in the state of household appliances, and are used to synthesize features that are then used for load classification. In [
8], a characterization is proposed on the basis of the sampling rate of the features themselves, which are divided into
very slow (less than 1 min),
slow (between 1 min and 1 s),
medium (higher than 1 Hz but slower than the fundamental frequency),
high (up to 2 kHz) and
very high (between 2 and 40 KHz). The features of the
slow and
very slow category can be used directly, as in [
9,
10], through statistical characterization of time-series sub-sequences as well as with signal processing [
11,
12,
13]. Higher sampling rates allow for more detailed characterization of transients in the consumption of household appliances [
14]. If the sampling rate is high, it is possible to realize a signal transformation like a Fourier transform or a discrete wavelet transform that allow to obtain significant new features on which to base the classification [
15,
16,
17].
Very high sampling frequencies allow to obtain information about the load waveform of household appliances, for example through the calculation of voltage-current trajectories as in [
18,
19].
Extremely high sampling rates enable to capture a richer set of harmonics as well as the electric noise [
20,
21]. Some authors have integrated the features derived from the consumption measurement with other information such as the frequency of use of household appliances [
22,
23] or weather conditions [
24].
The last step of the disaggregation process consists in identifying the loads from the features. Many different approaches have been proposed in the literature to address this step. A first group uses optimization methods applied to combinatorial search [
25,
26,
27,
28], but these methods are limited by the necessary computational resources. The community has therefore focused on both supervised and unsupervised machine learning techniques. Among the supervised techniques, several neural network architectures have been proposed, such as Multi Layer Perceptron (MLP) [
29], Convolutional Neural Network (CNN) [
30,
31,
32,
33,
34,
35,
36], Recurrent Neural Network (RNN) [
30,
37,
38,
39], Extreme Learning Machine [
40], techniques based on Support Vector Machines (SVM) [
16,
41], K-Nearest Neighbors (kNN) [
41,
42] naive Bayes classifiers [
15], Random Forest classifier [
43] and Conditional Random Fields [
44]. Among the unsupervised techniques, it was mainly those based on Hidden Markov Model that were used in this field [
26,
28,
45,
46,
47,
48], although clustering techniques were also used [
49,
50].
The use of high sampling rates, if on the one hand enables to process signals richer in information, and therefore potentially generate more effective features for disaggregation, on the other hand requires the use of dedicated hardware for the measurement of the total load. The increasing diffusion of smart meters for household users, although typically operating at
low or
very low sampling frequency, allows to conceive a direct use of the power measurements obtainable from them for the purpose of disaggregation [
28].
Therefore we focus on a hypothesis of using data from smart meters already widespread in Europe, with the idea of verifying the applicability of disaggregation methodologies even in the absence of dedicated measurement instrumentation. In the lack of specific data for this application we will use a literature dataset limiting the sampling rate to 1 min.
Starting from the observation that a reasonably experienced user is potentially able to realize a realistic disaggregation of the load starting from the aggregate load graph, in this work we propose an approach based on deep convolutional networks, using techniques developed in the field of image recognition. The choice of a deep neural network allows the automatic learning of the features, which are derived from the raw signal of the overall active power through convolutive filters and sampling at different time scales.
In detail in this paper we will:
Introduce a Temporal Pooling module to add context information in the recognition of activation states;
Show that this approach allows to achieve high performances recognising the on/off state of the appliances;
Show that this approach has good generalization properties;
Improve the state of the art performance in a reference dataset.
The paper is structured as follows: the problem is formulated in
Section 2, the proposed methodology for its solution is described in
Section 3,
Section 4 describes the numerical experiments conducted on a reference dataset, whose results are presented in
Section 5 and discussed in
Section 6. Conclusions are drawn in
Section 7, where also some possible further developments are presented.
2. Problem Formulation
The problem can be formulated as follows: if
represents the total active electrical power used in a system at the instant
t, and we indicate with
the active power absorbed by the appliance with index
i at the same time, the total load can be expressed as the sum of the absorptions of the individual devices and of an unmeasured part:
where
N is the number of appliances considered and
is the unidentified residual load.
The problem is to get the values of
when only the measure of
is known, that is to get an approximation of
:
where
F is the operator that, when applied to the total active power, returns
N distinct values that are the best estimate of the power absorbed by individual appliances. Note that in general the
does not represent the totality of household appliances, but a fraction of all those present in a house. The term
, not known, therefore takes into account the loads due to unmonitored appliances.
The problem of finding an approximation of the F operator can be set as a supervised learning problem when simultaneous measurements of the aggregate load and consumption of individual equipment are available.
If, as in our case, we are primarily interested in the cumulative consumption and activation times, the estimated
consumption of the individual appliances can be approximated with a function that is constant during the activation period of the device:
where
is the average consumption of the appliance
i and the
is an estimate of the state of activation of the individual appliance at the time
t, which has a unit value if the appliance is in operation and is consuming energy and zero value otherwise.
Therefore, the method we propose seeks to obtain the most accurate possible estimate of the state of activation of the appliances starting from the aggregate load,
and obtains an estimate of consumption using the (
3) after knowing the average nominal consumption of the appliances examined.
3. Methodology
To obtain the we will use a convolutional neural network, which has as input a time interval of the consumption of a house and provides an estimate of the state of activation of the equipment for each instant considered.
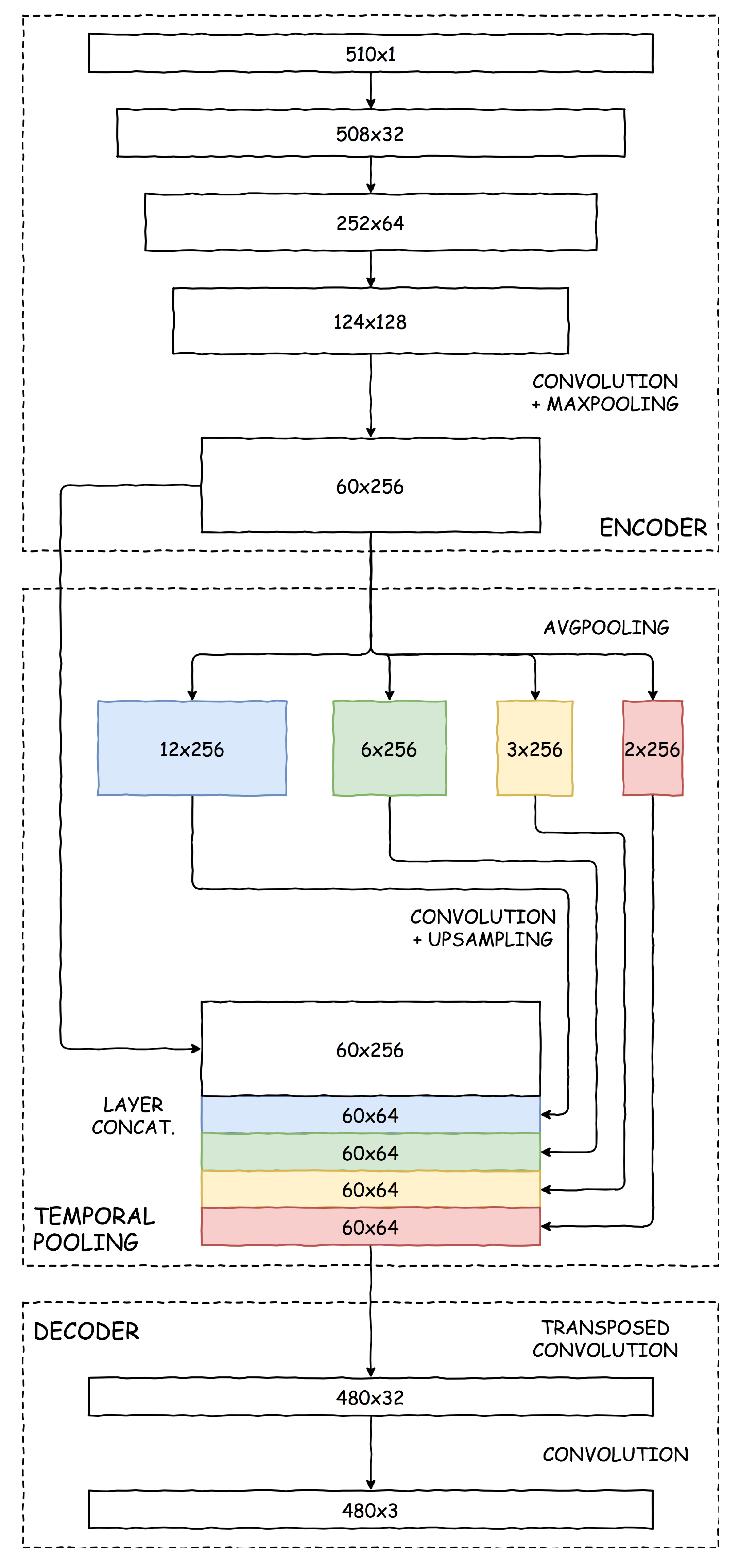
The network architecture used, which we will call Temporal Pooling NILM (TP-NILM), is an adaptation and simplification of the network called PSPNet (Pyramid Scene Parsing Network) proposed by Zhao et al. in [
51] for the semantic segmentation of images. The general scheme follows the classic approach to the semantic segmentation of images, in which we have an encoder, characterised by alternating convolution and pooling modules and which allows to increase the space of the features of the signal at the cost of its temporal resolution, and a decoder module which, starting from the obtained features, reconstructs an estimate of the activation status of the equipment at the same resolution as the original signal. To these is added a module called Temporal Pooling that realizes an aggregation of the features at different resolutions, generating a form of temporal context, that embraces long periods without losing completely the resolution in the description of the signal, for the purpose of an accurate reconstruction of the activation status. The network layout is shown in the
Figure 1.
The encoder is made of three convolutional filters alternated by max pooling layers, using a ReLU activation function, batch normalization downstream of the activations, and a dropout layer for regularization. The encoder reduces the time resolution of the signal by a factor of 8 and increases the signal components from a single aggregate power consumption value to 256 output features.
The temporal pooling block is used to give context information to the decoding block, creating additional features for decoding through aggregations with different resolutions of the encoder output. The encoder output passes through four average pooling modules with different filter sizes, which reduce the time resolution and keep the number of features unchanged, followed by a convolution with unit filter size, which reduces the number of features to a quarter of the input ones. The result of the convolutions constitutes the input of a ReLU activation function, followed again by batch normalization. Finally, a linear upsampling is performed to obtain a temporal resolution at the output of the temporal pooling block equal to that at the output of the encoder. A dropout is also applied to the output to regularize the network. The context features obtained from this block are linked to the detail features obtained from the encoder, doubling the overall number of features in input to the decoder.
The decoder consists of a transposed convolution layer with kernel size and stride equal to 8 that brings the temporal resolution of the signal to 1 min, while reducing the number of features. The activation function is still the ReLU. This is followed by an additional convolution layer with a unitary kernel size that maintains the time resolution and brings the number of output channels to the number of appliances being examined. A sigmoid function is used in the output and not a softmax layer as in the segmentation of the images, since while in the semantic segmentation of the images, each pixel is associated to a single class, in this case, for each time, several appliances can be simultaneously in operation.
Operating in this way, the network performs a decomposition of all appliances at the same time. This should allow, in our idea, to obtain an encoder with more general convolutive filters and not specific for a particular type of appliance and therefore to improve the ability to generalize the neural network.
The weights of the net are obtained via gradient descent optimization. The loss function is a Binary Cross-Entropy applied to each of the output channels that measures the difference between the activations estimated by the net
and the actual ones
for each appliance examined and for each instant of the period of time under scrutiny. The Class-Balanced Sigmoid Cross-Entropy Loss [
52] has also been tested, to consider the different frequency of use of household appliances, with results worse than those obtained with the Binary Cross-Entropy. The network has been implemented using the PyTorch [
53] library.
4. Experimental Setup
This section covers the numerical experiments carried out to verify the validity of the methodology proposed.
We will use the public low-frequency dataset called UK-DALE [
54], which has already been extensively analysed in the literature, and for which the results obtained from different approaches are available for comparison.
4.1. Dataset
The UK-DALE dataset contains records of the power used by 5 different households in the UK. The sampling frequency of the aggregate load is 1 Hz, while the consumption of the individual appliances was recorded with a period of 6 s. The duration of the measurements and the number of activations for the appliances of interest are shown in
Table 1.
The data recorded in this dataset are not uniform, neither in terms of timing nor in terms of the type of household appliance used. In our case, we will only consider the data relating to houses 1, 2 and 5. Only these dwellings have the records of the appliances we wanted to analyze in this study: refrigerator, washing machine and dishwasher. The choice of these appliances, and the exclusion of microwave ovens and kettles, for example, often discussed in the literature, is linked to the amount of energy consumption attributable to them and the possibility (for washing machines and dishwashers) to program their use in a perspective of intelligent management of consumption.
Moreover, very short consumption duration such as those of the microwave and the kettle are not well compatible with the sampling frequency chosen for the proposed methodology. The choice of this sampling frequency is linked to the type and quantity of data that it is reasonably possible to obtain from a smart meter without the use of additional energy metering systems as for our working hypothesis.
4.2. Preprocessing
The consumption data of the individual devices and the total of the houses in the dataset were pre-processed before being elaborated by the neural network. The first step was to clip the measurements of the absorbed power of the appliances to filter the measurement errors, so the maximum power was limited to the values shown in the
Table 2. The time series were then sub-sampled to a period of 1 min, taking the average value of the power in the time intervals.
The activation status for individual appliances is derived from power absorption measurements in a similar way to the procedure described in [
30]. A household appliance can be considered in operation when the absorbed power exceeds a certain threshold value. This criterion is sufficient to determine the state of activation of appliances operating in an ON/OFF mode, such as a fridge. When, on the other hand, the functioning of the appliance is more complex, as in the case of a dishwasher or a washing machine, the absorption can drop below the threshold value for short periods, without a washing programme having actually been completed. A minimum time is then set during which the power is maintained below the threshold value so that the appliance can be considered to be actually switched off. Finally, a minimum time is established with absorbed power above the threshold to be considered as actually switched on, in order to filter out spurious activations linked to errors in the metering.
The
Table 2 shows the values used for the above-mentioned parameters for the household appliances under consideration. The values chosen are the same as those used in [
30] and in the recent literature that has reviewed the same dataset.
Aggregate load data is normalized, dividing the load by a reference power value of 2000 W. The disaggregation is carried out on time windows of fixed length, with an extension of 510 samples as input and a valid output of 480 min or 8 h. The difference in size between input and output is due to the convolution filters for which no padding was used. The time series of the absorptions has been therefore divided in segments of 510 elements providing an overlay of 30 elements between successive segments so that a complete time series can be obtained by concatenating the output of the model applied to the single segments. As a last step of preprocessing, the average power absorbed in the range considered is subtracted from the signal so that the set of input values has zero average.
4.3. Postprocessing
The model returns an array of values representative of the probability of activation of each appliance for each instant being considered with a value in the range of
. The activation state is estimated by evaluating the exceeding of an arbitrary threshold, chosen equal to
. Moreover the same procedure of filtering of the activations used in the preprocessing stage is applied whose duration limits are the same as in the
Table 2 already mentioned.
4.4. Training and Testing
Both the case (seen in the following) in which the examined dwelling is part of the training dataset (training and testing time periods are in any case strictly separated) and the case of a network trained on houses other than the one on which the test is conducted (unseen in the following) have been evaluated.
The first problem allows to evaluate the disaggregation capabilities when the signatures of the appliances in use have been measured, and the model should simply distinguish these signatures in a signal with a strong noise component due to the use of other appliances.
The second case, on the other hand, allows us to assess the model’s ability to generalise, i.e., to recognise the generic characteristics of a type of household appliance and therefore to be able to disaggregate the consumption of equipment on which no training has been conducted. The results of this case are of greater applicative interest, as they allow to estimate the performance of the algorithm in a scenario where the types of devices present in a house are known and for which only the measurement of the aggregate consumption is available.
For each house the dataset is divided into three consecutive time intervals, dedicated to training, validation and testing, which cover respectively 80%, 10% and 10% of the measurements. The split of the houses datasets for the two use cases is shown in
Table 3.
For the seen case, the training is run on the first portion of the data collected for houses 1, 2 and 5, the verification is conducted on the testing portion of the data of house 1. During training, network parameters are saved whenever the target function, calculated on the data validation portion, reaches a new minimum.
In the case of unseen the training is conducted on the training portion of houses 1 and 5, the network is tested on the entire time series of house 2 and the weights of the network are saved whenever the target function, calculated on the validation portion of the data of houses 1 and 5, reaches a minimum. In summary, data from dwellings 1 and 5 are used for training and the performance check is conducted on the entire dataset of the house 2, while data from house 2 are used for performance testing only.
The network parameters are optimized with a gradient descent procedure using the Adam [
55] (short for Adaptive Moment Estimation) optimization algorithm, with learning rate of
, and batch size of 32. For the
seen case the training lasts for 300 epochs, while the training stops at 100 epochs for the
unseen case to avoid overfitting. Of course, other values have been tested both for the hyperparameters of the optimization algorithm and for the characteristics of the neural network. The values presented gave good results for the convergence times and for the accuracy obtained but do not claim to represent the combination able to guarantee the maximum accuracy for the case under examination since the aim of the work is mainly to verify the validity of the proposed approach.
Twenty different instances are trained in both cases to verify the stability of performance, and to derive the average performance of an ensemble. The number of instances of the ensemble is a reasonable compromise between the quantization of the Probability Density Function and the calculation time required.
4.5. Performance evaluation
Several metrics will be used to evaluate the performance of the proposed algorithm, aimed at capturing the effectiveness of the methodology for both the identification of the activation status and the estimation of energy consumption.
For a given instant t, indicates the activation status of a device i, unitary if on and null if off, and we indicate with the power absorbed at the same time. We denote with and the activation status and power consumption estimates obtained from the model. The accuracy of the prediction is evaluated on a time series sampled at times with .
We also define True Positive (TP), True Negative (TN), False Positive (FP) and False Negative (FN). TP refers to the number of instants of the time series in which a device is correctly identified as running, while TN is the count of instants in which the device is correctly evaluated switched off. On the contrary, FP indicates the number of instants for which an activation status is reported while the device is actually inactive, and finally FN is the count of instants in which the device is wrongly evaluated as off.
Precision in Equation (
6) denotes the ratio of TPs to all instants classified as positive, while Recall in Equation (
7) represents the ratio of the number of instants for which the appliance is correctly identified as operating to all instants for which the appliance is actually in function. The Accuracy defined in (
5) denotes the ratio of all correctly classified instants (for both states, on or off) to all instants of the verification set. The F1 measurement defined in (
8) represents the weighted average between Precision and Recall, and it is within the range of
, high values indicate a better identification of the state of the appliance. Finally the Matthews Correlation Coefficient is defined in (
9), whose values are in the range
. A value equal to 1 denotes an exact classification, 0 denotes a random prediction while a value equal to
indicates a totally wrong classification.
The accuracy of the estimate of consumption for the individual devices is measured using the Mean Absolute Error (MAE) and the Signal Aggregate Error (SAE).
where MAE is a measure of the average deviation at each instant of the estimated power with respect to the measured power, while SAE is a measure of the relative error in the estimation of the energy used during the entire evaluation period.
5. Results
The first case examined is the one called
seen. The
Table 4 shows the results obtained for the household appliances examined both in terms of identifying the state and in terms of estimating instantaneous and overall consumption over time.
The results are very satisfactory for all three appliances considered, as far as the identification of the activation status is concerned, in particular for the most energy consuming appliances and less for the refrigerator; the latter has a less evident signature as its maximum absorption is much lower than that of the dishwasher and washing machine. The energy performance in the strict sense is also very good, especially for the SAE metric, which identifies the overall energy consumption, with errors of around 3% of the actual value for the refrigerator and below 10% for the dishwasher and washing machine. The MAE measures the error in the instantaneous power estimation, the fact that by methodological choice the power has been modelled as constant during the whole activation period affects the maximum performance achievable on this metric.
The
Table 5 shows the results obtained on the dataset for the
unseen case. The performance achieved in estimating the operational status is worse than in the previous case as expected. On the contrary, the energy performances are in line with the numerical results obtained for the
seen case.
The data for the dwelling not seen during the training of the network, differ from those for other houses. In house 2, in fact, there are unmonitored appliances that are different from those in other households, thus changing the characteristics of the disturbance signal present in the overall load, which is added to the consumption of the three appliances under examination. Moreover, the models of fridge, washing machine and dishwasher are different from those present in the other two houses used in the training: in terms of the power used, the length of the operating cycles and the evolution of consumption itself. In this case, the network has the difficult task of generalising the absorption of a category of household appliance and recognising its footprint in the overall consumption data.
Despite this, we can say that the performance is surprisingly good considering the limited dataset used for training, which although having a significant temporal extension, is related to a few users and therefore does not have many examples of appliances of the same class that would allow a better generalization in the training phase.
The washing machine and the dishwasher may be subject to greater differences in consumption profile, also in relation to the different washing programs available. This translates into a difficulty for the model to generalise in these cases, as mentioned above, hence the greater degradation in the classification accuracy for these two appliances compared to the refrigerator, as can be seen from the comparison of the results in
Table 4 and
Table 5.
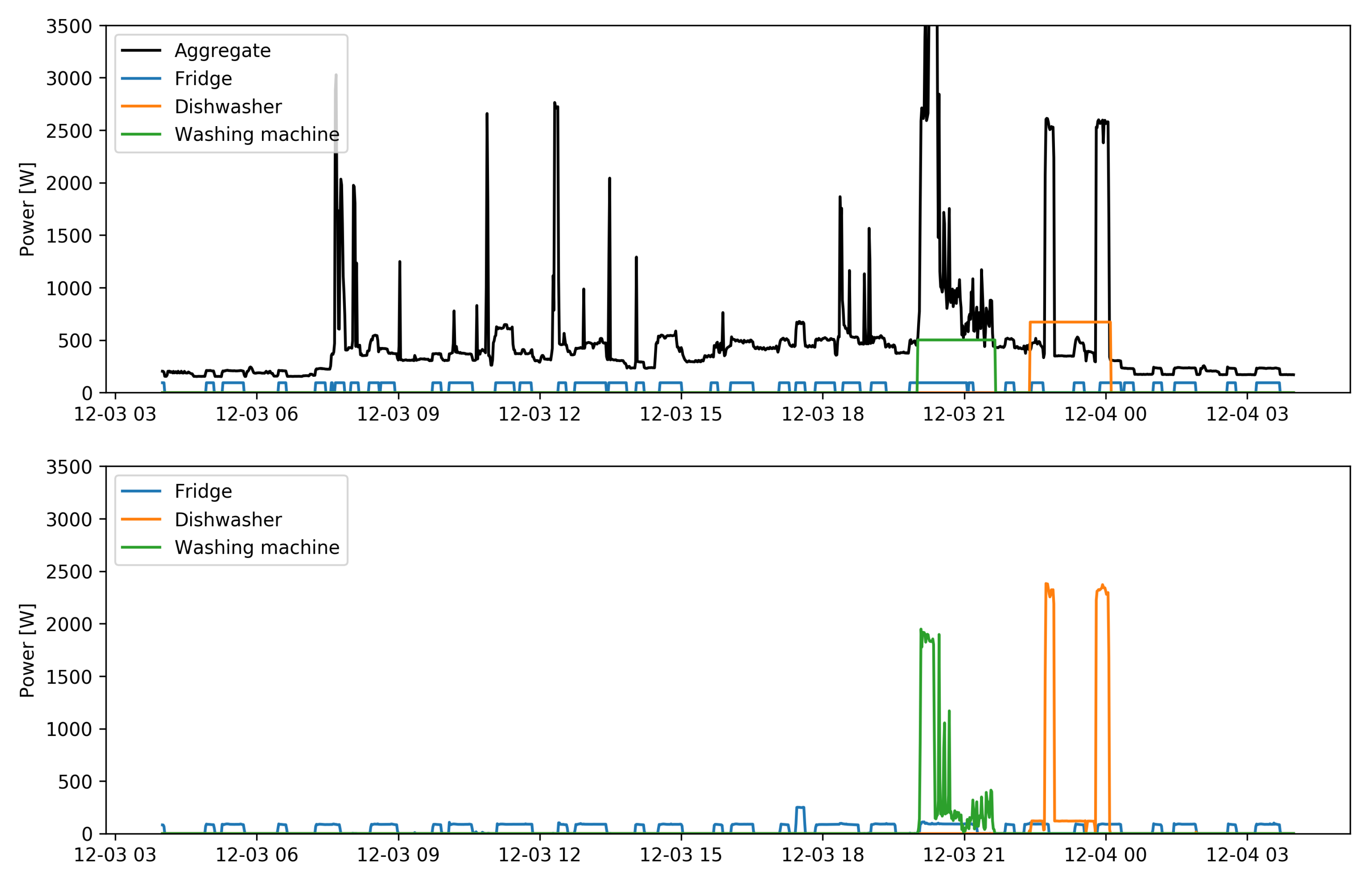
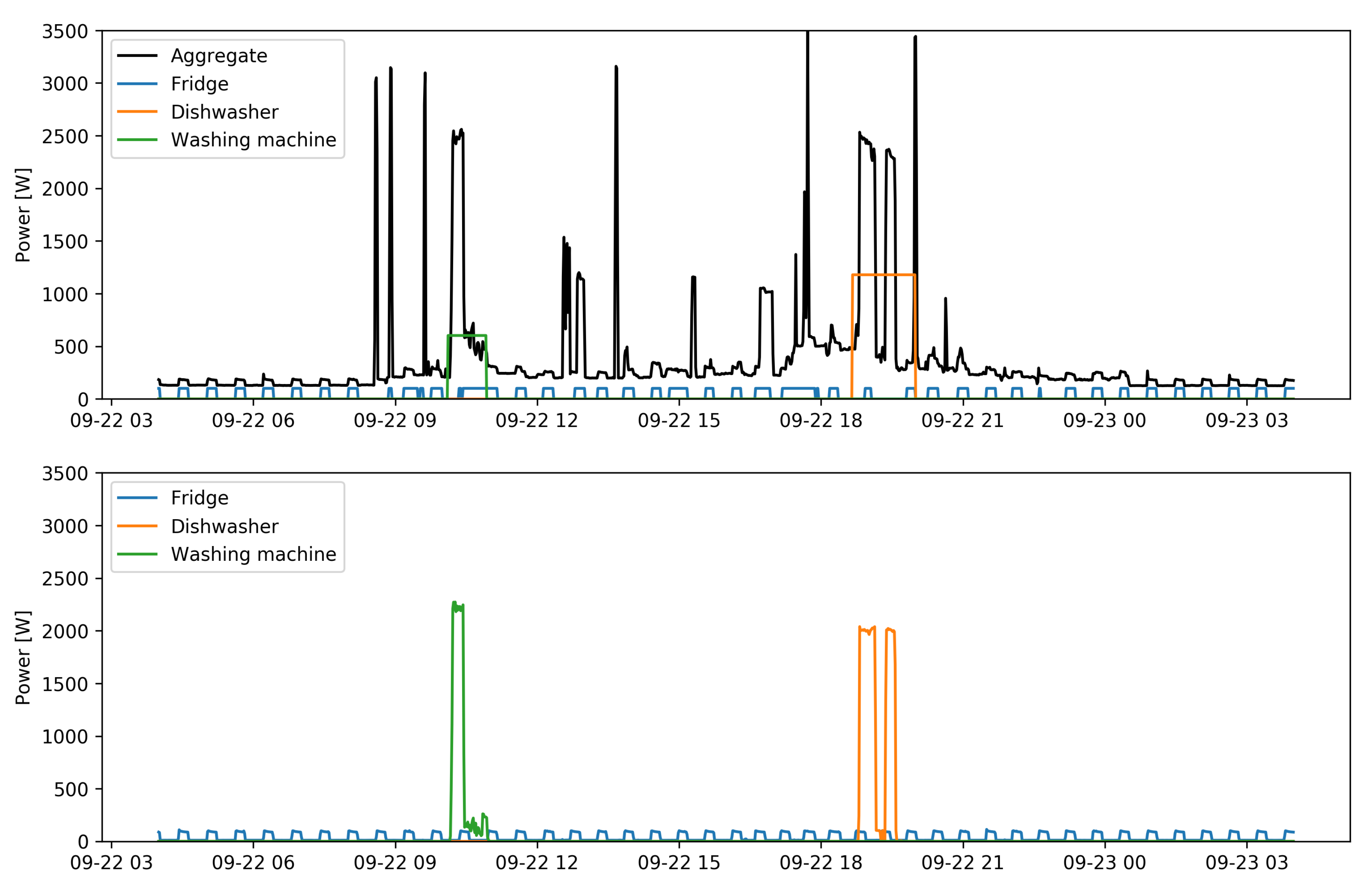
The
Figure 2 and
Figure 3 show an example of the results of the algorithm for a single day of data, for the
seen and
unseen cases respectively. In both figures the lower graph shows a day of the dataset testing portion for houses 1 and 2 respectively. The dishwasher is characterized by a period of heating of the washing water followed by a period of washing and a phase of rinsing with warm water. On the other hand, the washing machine is characterised by a water loading and heating phase followed by a washing phase in which the highly variable absorption is due to the electric motor that drives the basket. In both cases the washing cycles and the maximum absorption of the appliances (and also for the refrigerator, even if in a less evident way) are clearly different. The upper graph for the two figures shows the aggregate load and the estimated average consumption for the appliances examined.
As mentioned above, the network has been trained and tested twenty times for both the
seen and the
unseen cases, and in both tables are reported in addition to the mean value of the ensemble of the results obtained from the 20 models also the intervals of variation of the results obtained for the individual instances. The scores are more stable for the
Table 4, highlighting the need for training conducted on a larger number of users, in order to further improve the performance of the algorithm.
6. Discussion
The use of a public dataset allows to evaluate the results obtained in comparison with other methodologies published in the literature. Unfortunately, not all of the published studies address both proposed cases, the seen case, in which training and verification are conducted on the same home, and the unseen case, in which verification is conducted on a different user than the one on which the network has been trained.
The
Table 6 shows the comparison of the performance of our model (TP-NILM) with the models in the literature for the
seen case.
The TP-NILM model offers good performances as far as the recognition of the state of activation is concerned, also the accuracy in the estimate of the total consumptions (SAE) is satisfactory, while the value of the MAE is affected by the assumption made about the constancy of the consumption for each cycle of activation. The best performance is obtained for high-consumption appliances, while the algorithm we have proposed seems to have more difficulty in correctly identifying the activations of the fridge. In this regard, it is worth remembering that we intentionally under-sampled the time series. In the case of the refrigerator, the maximum power absorbed is much lower than that of a dishwasher or washing machine so that the periodic activations can easily be confused with the noise associated with the many other unmonitored loads that contribute to the overall aggregate load. The absorption of the refrigerator, however, is characterized by the activation of a marked absorption linked to the starting point of the compressor, lasting less than a minute, which can only be detected by the original sampling of the dataset.
Furthermore, it is necessary to specify a detail that is relevant to the practical importance of these services. With the exception of the method described in [
48], all other methods require knowledge of the consumption of individual equipment throughout the training period for a given user. The application of these methods therefore requires the installation of measuring devices for individual household appliances, and that these have been recording energy consumption throughout the training period. It is therefore debatable to define the application of these methods to the same user as Non-intrusive Load Monitoring. In the procedure proposed we use only information relating to the status of activation of the same equipment that can be acquired independently of the reading of consumption, in automatic or semi-automatic mode through interaction with the user.
The
unseen case is certainly more interesting, where the model is applied to a user whose only known time series is the aggregate load, as well as the type and nominal consumption of the appliances to be monitored. The performances obtained with our method are compared with the values published in the literature on the same dataset in the
Table 7.
The procedure is effective both in estimating the state of activation and in energy metrics, obtaining good results when compared with other methods, especially for the dishwasher and washing machine. In general the performance, for each of the methods considered, is worse than in the seen case, demonstrating on the one hand the difficulty of obtaining generic models, and on the other hand the obvious added value of a specific modeling for a given dwelling. In particular, the Deep AE method obtains better performances for the fridge, similar performances for the dishwasher but surprisingly worse for the washing machine, in our opinion due to the marked difference in the consumption curve of this appliance for each of the three houses. Probably the Deep AE method, based on a technique of the Auto Encoder type, does not have the same generalizing capabilities of the method we proposed, which we think derive from the features pooling module at different time scales. Other methods also based on an Autoencoder approach such as seq2seq and seq2point have comparable performance in terms of MAE but unfortunately their accuracy is not declared for the recognition of the activation state. The results of the unseen case are also interesting given the limited number of different appliances on which it was possible to carry out the training, as richer datasets could lead to even better generalization.
7. Conclusions
In this paper we have presented a new methodology for Non Intrusive Load Monitoring and Disaggregation, based on the recognition of the activation states of household appliances. The approach is based on the observation that a sufficiently experienced user is capable of recognizing these activation states by examining an aggregate consumption plot and that a neural network like the one proposed can emulate that ability. Leveraging the latest techniques used for semantic image segmentation, we have introduced a model based on convolutional networks, applicable on datasets with low sampling rate. The space of the features used for the classification has been enriched through the introduction of a temporal pooling module that performs a pooling at different time scales of the features calculated in the first convolution levels, thus increasing the receptive field without compromising the temporal resolution of the output. The approach is based on the multilabel classification of simultaneous active loads, and estimates the consumption of appliances as a constant average value during activation. This approach allows us to obtain good generalization characteristics for the algorithm, allowing the application of a trained network to a household not used for the training with good performance on a reference dataset.
In this work, the disaggregation was carried out by examining the time series of the active power consumed only, but additional variables can be considered. If available, the reactive power data could improve the performance, but also information on the time of use, or the environmental temperature conditions are additional features that could improve the performance of the algorithm. In fact, from the analysis of the time series of dishwashers and washing machines, one can notice habits of use, for example the dishwasher is activated in the evening hours, after dinner; the environmental conditions, on the other hand, can influence the refrigerator and certainly the heating systems not considered in this work.
A further line of research is the realization of an active learning procedure for the optimization of performance on a given user using a reduced feedback from a pre-trained network on users other than the one examined.






{kind=link}
{kind=link}
{kind=link}