A New Approach to Identifying Crash Hotspot Intersections (CHIs) Using Spatial Weights Matrices



Abstract
:1. Introduction
2. Methodology
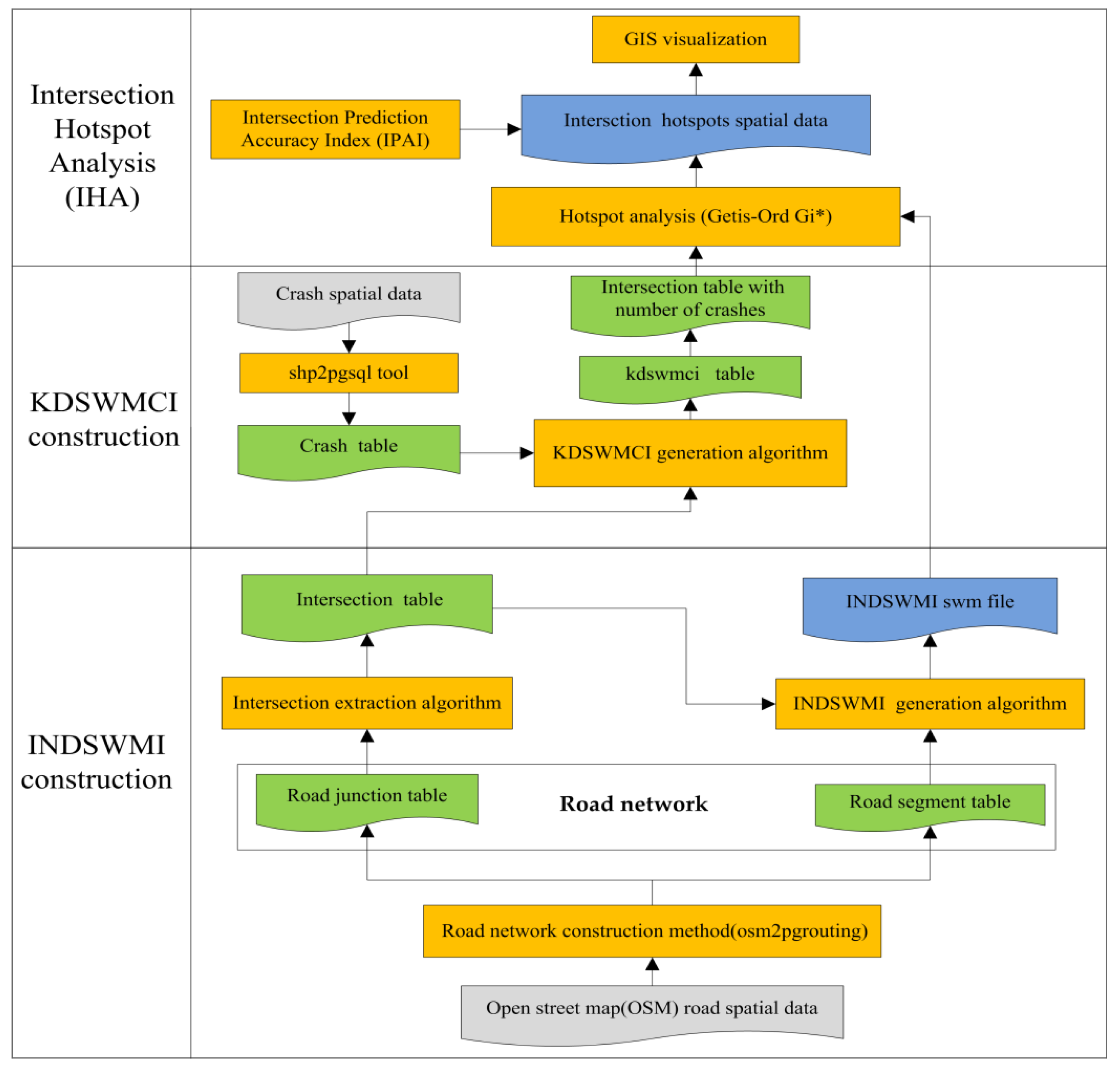
2.1. Process Map
- (a)
- (b)
- Intersection extraction. Note that a road junction that links with three or more road segments is considered an intersection, which is a junction of traffic flow and pedestrian flow [37,38] in this research. We developed an intersection extraction algorithm to extract intersections, such as T-intersection, Y-intersections, cross-intersections, and X-intersections [39], from the road junction table and create the intersection table. The intersection extraction algorithm can be described as the following structured query language (SQL) script:”create table public.intersection as select * from public.road_junction a where a.degree> 2”.
- (c)
- INDSWMI construction. We developed the INDSWMI generation algorithm to construct the INDSWMI, which can conceptualize the spatial relationships between intersections, with road network constraints based on the intersection table and road segment table. The INDSWMI is saved in the swm file format which is compatible with ArcGIS.
2.2. Data Types
2.2.1. The Input Data
2.2.2. The Intermediate Data
2.2.3. Output Results
2.3. Methods
2.3.1. The INDSWMI Generation Algorithm
2.3.2. The KDSWMCI Generation Algorithm
- Condition 1: The shortest distance between the crash and the intersection is less than or equal to the threshold distance.
- Condition 2: The intersection-related crash relates to one, and only one, intersection. That means that the k-nearest neighbor is the same as the 1st-nearest neighbor. Therefore, if crash i occurs on intersection j, then the shortest distance between crash i and intersection j should be the minimum distance in all datasets.
- Premise 1
- Crash GPS coordinates have a positioning error of approximately 10 m [52]. A crash is considered to occur on the intersection if its coordinates are within 10 m of the buffer of the intersection considering the positioning error.
- Premise 2
- As the Interstate Highway standards for the U.S. Interstate Highway System use a 12 foot (3.7 m) standard lane width, a crash occurring on the intersection can be determined if its coordinates are within (3.7 × n/2) m of the buffer of the intersection, where n is the number of lanes of the intersection.
2.3.3. Intersection Hotspot Analysis (Getis–Ord Gi*)
2.3.4. The Intersection Prediction Accuracy Index (IPAI)
3. Original Data
3.1. The Road Network
3.2. Intersection-Related Crashes
4. Results and Discussion
4.1. Results
4.1.1. The INDSWMI of Spencer City
4.1.2. The Results of Intersection Hotspot Analysis (Getis–Ord Gi*) of Spencer City
4.2. A Performance Comparison of IHA between INDSWMI and IEDSWMI
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Federal Highway Administration (US); Federal Transit Administration (US). 2015 Status of the Nation’s Highways, Bridges, and Transit Conditions & Performance Report to Congress; Federal Highway Administration (US), Federal Transit Administration (US), Ed.; Government Printing Office: Washington, DC, USA, 2017.
- Peng, J.; Xiao, L.; Zhang, J.; Cai, C.S.; Wang, L. Flexural behavior of corroded HPS beams. Eng. Struct. 2019, 195, 274–287. [Google Scholar] [CrossRef]
- Huo, L.; Li, C.; Jiang, T.; Li, H.-N. Feasibility study of steel bar corrosion monitoring using a piezoceramic transducer enabled time reversal method. Appl. Sci. 2018, 8, 2304. [Google Scholar] [CrossRef] [Green Version]
- Frangopol, D.M.; Tsompanakis, Y. Maintenance and Safety of Aging Infrastructure; Structures and Infrastructures Series; Frangopol, D.M., Tsompanakis, Y., Eds.; CRC Press: Boca Raton, FL, USA; Leiden, The Netherlands, 2014; ISBN 978-0-415-65942-0. [Google Scholar]
- Zhu, J.; Ho, S.C.M.; Kong, Q.; Patil, D.; Mo, Y.-L.; Song, G. Estimation of impact location on concrete column. Smart Mater. Struct. 2017, 26, 055037. [Google Scholar] [CrossRef]
- Qi, B.; Kong, Q.; Qian, H.; Patil, D.; Lim, I.; Li, M.; Liu, D.; Song, G. Study of impact damage in pva-ecc beam under low-velocity impact loading using piezoceramic transducers and pvdf thin-film transducers. Sensors 2018, 18, 671. [Google Scholar] [CrossRef] [Green Version]
- Yin, X.; Song, G.; Liu, Y. Vibration suppression of wind/traffic/bridge coupled system using Multiple Pounding Tuned Mass Dampers (MPTMD). Sensors 2019, 19, 1133. [Google Scholar] [CrossRef] [Green Version]
- Kong, Q.; Robert, R.; Silva, P.; Mo, Y. Cyclic crack monitoring of a reinforced concrete column under simulated pseudo-dynamic loading using piezoceramic-based smart aggregates. Appl. Sci. 2016, 6, 341. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Zhang, M.; Yin, X.; Huang, Z.; Wang, L. Debonding detection of reinforced concrete (RC) beam with near-surface mounted (NSM) pre-stressed carbon fiber reinforced polymer (CFRP) plates using embedded piezoceramic smart aggregates (SAs). Appl. Sci. 2019, 10, 50. [Google Scholar] [CrossRef] [Green Version]
- Li, N.; Wang, F.; Song, G. New entropy-based vibro-acoustic modulation method for metal fatigue crack detection: An exploratory study. Measurement 2020, 150, 107075. [Google Scholar] [CrossRef]
- Du, B.; Huang, R.; Chen, X.; Xie, Z.; Liang, Y.; Lv, W.; Ma, J. Active CTDaaS: A data service framework based on transparent iod in city traffic. IEEE Trans. Comput. 2016, 1. [Google Scholar] [CrossRef]
- Wang, H.; Wu, X.; Sun, L.; Du, B. Passenger behavior prediction with semantic and multi-pattern LSTM model. IEEE Access 2019, 7, 157873–157882. [Google Scholar] [CrossRef]
- 2017 Quick Facts. Available online: https://crashstats.nhtsa.dot.gov/ (accessed on 19 February 2020).
- Iowa Department of Transportation’s Public Platform. Available online: https://data.iowadot.gov/ (accessed on 20 December 2019).
- Achu, A.L.; Aju, C.D.; Suresh, V.; Manoharan, T.P.; Reghunath, R. Spatio-temporal analysis of road accident incidents and delineation of hotspots using geospatial tools in Thrissur District, Kerala, India. Kn J. Cartogr. Geogr. Inf. 2019, 69, 255–265. [Google Scholar] [CrossRef]
- Getis, A.; Ord, J.K. The analysis of spatial association by use of distance statistics. Geogr. Anal. 2010, 24, 189–206. [Google Scholar] [CrossRef]
- Ulak, M.B.; Ozguven, E.E.; Vanli, O.A.; Horner, M.W. Exploring alternative spatial weights to detect crash hotspots. Comput. Environ. Urban Syst. 2019, 78, 101398. [Google Scholar] [CrossRef]
- Ouni, F.; Belloumi, M. Pattern of road traffic crash hot zones versus probable hot zones in Tunisia: A geospatial analysis. Accid. Anal. Prev. 2019, 128, 185–196. [Google Scholar] [CrossRef] [PubMed]
- Khan, G.; Qin, X.; Noyce, D.A. Spatial analysis of weather crash patterns. J. Transp. Eng. 2008, 134, 191–202. [Google Scholar] [CrossRef]
- Prasannakumar, V.; Vijith, H.; Charutha, R.; Geetha, N. Spatio-temporal clustering of road accidents: Gis based analysis and assessment. Procedia Soc. Behav. Sci. 2011, 21, 317–325. [Google Scholar] [CrossRef] [Green Version]
- Erdogan, S.; Ilçi, V.; Soysal, O.M.; Kormaz, A. A model suggestion for the determination of the traffic accident hotspots on the turkish highway road network: A pilot study. Bulletin of Geodetic Sciences. 2015, 21, 169–188. [Google Scholar] [CrossRef]
- Kuo, P.-F.; Zeng, X. Guidelines for choosing hot-spot analysis tools based on data characteristics, network restrictions, and time distributions. In Proceedings of the 91st Annual Meeting of the Transportation Research Board, Washington, DC, USA, 22–26 January 2012; pp. 22–26. [Google Scholar]
- Zahran, E.-S.M.M.; Tan, S.J.; Tan, E.H.A.; Mohamad’Asri Putra, N.A.A.B.; Yap, Y.H.; Abdul Rahman, E.K. Spatial analysis of road traffic accident hotspots: Evaluation and validation of recent approaches using road safety audit. J. Transp. Saf. Secur. 2019, 1–30. [Google Scholar] [CrossRef]
- Colak, H.E.; Memisoglu, T.; Erbas, Y.S.; Bediroglu, S. Hot spot analysis based on network spatial weights to determine spatial statistics of traffic accidents in Rize, Turkey. Arab. J. Geosci. 2018, 11, 151. [Google Scholar] [CrossRef]
- Mitra, S. Spatial autocorrelation and bayesian spatial statistical method for analyzing intersections prone to injury crashes. Transp. Res. Rec. 2009, 2136, 92–100. [Google Scholar] [CrossRef]
- Cheng, Z.; Zu, Z.; Lu, J. Traffic crash evolution characteristic analysis and spatiotemporal hotspot identification of urban road intersections. Sustainability 2018, 11, 160. [Google Scholar] [CrossRef] [Green Version]
- Cinnamon, J.; Schuurman, N.; Hameed, S.M. Pedestrian injury and human behaviour: Observing road-rule violations at high-incident intersections. PLoS ONE 2011, 6, e21063. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Getis, A. Spatial weights matrices: Spatial weights matrices. Geogr. Anal. 2009, 41, 404–410. [Google Scholar] [CrossRef]
- Getis, A.; Aldstadt, J. Constructing the spatial weights matrix using a local statistic. Geogr. Anal. 2004, 36, 90–104. [Google Scholar] [CrossRef]
- Zhang, R.; Du, Q.; Geng, J.; Liu, B.; Huang, Y. An improved spatial error model for the mass appraisal of commercial real estate based on spatial analysis: Shenzhen as a case study. Habitat Int. 2015, 46, 196–205. [Google Scholar] [CrossRef]
- Zhang, Z.; Ming, Y.; Song, G. Identify road clusters with high-frequency crashes using spatial data mining approach. Appl. Sci. 2019, 9, 5282. [Google Scholar] [CrossRef] [Green Version]
- Jun, M.-J.; Kim, H.-J. Measuring the effect of greenbelt proximity on apartment rents in Seoul. Cities 2017, 62, 10–22. [Google Scholar] [CrossRef]
- Chen, J.; Fu, J.; Zhang, M. An atmospheric correction algorithm for landsat/tm imagery basing on inverse distance spatial interpolation algorithm: A case study in taihu lake. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 882–889. [Google Scholar] [CrossRef]
- Kataria, A.; Singh, M.D. A review of data classification using k-nearest neighbour algorithm. Int. J. Emerg. Technol. Adv. Eng. 2013, 3, 7. [Google Scholar]
- Graser, A. Integrating open spaces into openstreetmap routing graphs for realistic crossing behaviour in pedestrian navigation. GI_Forum 2016 2016, 1, 217–230. [Google Scholar] [CrossRef] [Green Version]
- Mocnik, F.-B.; Mobasheri, A.; Zipf, A. Open source data mining infrastructure for exploring and analysing OpenStreetMap. Open Geospat. Data Softw. Stand. 2018, 3, 7. [Google Scholar] [CrossRef]
- García, F.; García, J.; Ponz, A.; de la Escalera, A.; Armingol, J.M. Context aided pedestrian detection for danger estimation based on laser scanner and computer vision. Expert Syst. Appl. 2014, 41, 6646–6661. [Google Scholar] [CrossRef] [Green Version]
- García, F.; Jiménez, F.; Anaya, J.; Armingol, J.; Naranjo, J.; de la Escalera, A. Distributed pedestrian detection alerts based on data fusion with accurate localization. Sensors 2013, 13, 11687–11708. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fogliaroni, P.; Bucher, D.; Jankovic, N.; Giannopoulos, I. Intersections of our world. LIPIcs 2018, 3, 15. [Google Scholar]
- Moerbeek, M. Bayesian evaluation of informative hypotheses in cluster-randomized trials. Behav. Res. 2019, 51, 126–137. [Google Scholar] [CrossRef] [PubMed]
- Pelaez, C.G.A.; Garcia, F.; de la Escalera, A.; Armingol, J.M. Driver monitoring based on low-cost 3-d sensors. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1855–1860. [Google Scholar] [CrossRef] [Green Version]
- Carmona, J.; García, F.; Martín, D.; Escalera, A.; Armingol, J. Data fusion for driver behaviour analysis. Sensors 2015, 15, 25968–25991. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, S.; Rajan, K.S. Performance analysis of MongoDB versus PostGIS/PostGreSQL databases for line intersection and point containment spatial queries. Spat. Inf. Res. 2016, 24, 671–677. [Google Scholar] [CrossRef]
- Bucklin, D.; Basille, M. Rpostgis: Linking R with a PostGIS spatial database. R J. 2018, 10, 251. [Google Scholar] [CrossRef]
- Tom-Jack, Q.T.; Bernstein, J.M.; Loyola, L.C. The role of geoprocessing in mapping crime using hot streets. IJGI 2019, 8, 540. [Google Scholar] [CrossRef] [Green Version]
- Lam, C.; Souza, P.C.L. Estimation and selection of spatial weight matrix in a spatial lag model. J. Bus. Econ. Stat. 2019, 1–41. [Google Scholar] [CrossRef]
- Abokifa, A.A.; Sela, L. Identification of spatial patterns in water distribution pipe failure data using spatial autocorrelation analysis. J. Water Resour. Plann. Manag. 2019, 145, 04019057. [Google Scholar] [CrossRef]
- Griffith, D.A.; Paelinck, J.H.P. General conclusions about spatial statistics. In Morphisms for Quantitative Spatial Analysis; Springer International Publishing: Cham, Switzerland, 2018; Volume 51, pp. 113–121. [Google Scholar]
- Liu, H.; Wang, J. Vulnerability assessment for cascading failure in the highway traffic system. Sustainability 2018, 10, 2333. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Jiang, H.; Hua, L. Anti-congestion route planning scheme based on dijkstra algorithm for automatic valet parking system. Appl. Sci. 2019, 9, 5016. [Google Scholar] [CrossRef] [Green Version]
- Monteiro, F.R.; Garcia, M.A.P.; Cordeiro, L.C.; de Lima Filho, E.B. Bounded model checking of C++ programs based on the Qt cross-platform framework: BMC of C++ programs based on Qt Cross-Platform Framework. Softw. Test. Verif. Reliab. 2017, 27, e1632. [Google Scholar] [CrossRef]
- Wing, M.G.; Eklund, A.; Kellogg, L.D. Consumer-grade global positioning system (gps) accuracy and reliability. J. For. 2005, 103, 169–173. [Google Scholar] [CrossRef]
- Manepalli, U.R.R.; Bham, G.H.; Kandada, S. Evaluation of hotspots identification using kernel density estimation (k) and getis-ord (gi *) on i-630. In Proceedings of the 3rd International Conference on Road Safety and Simulation, Indianapolis, IN, USA, 14–16 September 2011; Transportation Research Board of the National Academies: Washington, DC, USA, 2011; p. 17. [Google Scholar]
- Anselin, L. Local indicators of spatial association-LISA. Geogr. Anal. 2010, 27, 93–115. [Google Scholar] [CrossRef]
- Tobler, W. On the first law of geography: A reply. Ann. Assoc. Am. Geogr. 2004, 94, 304–310. [Google Scholar] [CrossRef]
- Songchitruksa, P.; Zeng, X. Getis–Ord spatial statistics to identify hot spots by using incident management data. Transp. Res. Rec. J. Transp. Res. Board 2010, 2165, 42–51. [Google Scholar] [CrossRef]
- Benmoussa, A.; Gotti, C.; Bourassa, S.; Gilbert, C.; Provost, P. Identification of protein markers for extracellular vesicle (EV) subsets in cow’s milk. J. Proteom. 2019, 192, 78–88. [Google Scholar] [CrossRef]
- Chainey, S.; Tompson, L.; Uhlig, S. The utility of hotspot mapping for predicting spatial patterns of crime. Secur. J. 2008, 21, 4–28. [Google Scholar] [CrossRef]
- Flaxman, S.; Chirico, M.; Pereira, P.; Loeffler, C. Scalable high-resolution forecasting of sparse spatiotemporal events with kernel methods: A winning solution to the NIJ “Real-Time Crime Forecasting Challenge”. Ann. Appl. Stat. 2019, 13, 2564–2585. [Google Scholar] [CrossRef]
- Kajita, M.; Kajita, S. Crime prediction by data-driven Green’s function method. Int. J. Forecast. 2019. [Google Scholar] [CrossRef] [Green Version]
- Thakali, L.; Kwon, T.J.; Fu, L. Identification of crash hotspots using kernel density estimation and kriging methods: A comparison. J. Mod. Transp. 2015, 23, 93–106. [Google Scholar] [CrossRef] [Green Version]
- Bell, D.; Jayne, M. Small Cities? Towards a Research Agenda. Int. J. Urban Reg. Res. 2009, 33, 683–699. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Type | File Format | Feature Type | Description |
|---|---|---|---|---|
| OSM Road | Input | osm | Line/Point/Region | Widely used open access geographic data |
| Crash | Input | shapefile | Point | The geographic data of crashes |
| Road junction | Intermediate | PostGreSQL Table | Point | The road junction spatial table generated by osm2pgrouting software |
| Road segment | Intermediate | PostGreSQL Table | Line | The road segment spatial table generated by osm2pgrouting software |
| Crash table | Intermediate | PostGreSQL Table | Point | The crash spatial table converted by shp2pgsql tool |
| Intersection | Intermediate | PostGreSQL Table | Point | The intersection spatial table with number of crashes extracted from road junction |
| KDSWMCI table | Intermediate | PostGreSQL Table | / | Stores the crash–intersection spatial relationships |
| INDSWMI file | Output | SWM | / | SWM format file with INDSWMI info from ArcGIS |
| Crash hotspot intersections | Output | Shapefile | Line | The result of intersection hotspot analysis |
| Intersection id and Coordinates | Adjacent Road Segment id and Coordinates | Collision id and Coordinates | Euclidean Distance | Coincidence |
|---|---|---|---|---|
| id:921 point (−95.1464002 43.155801) | id:155 linestring (−95.1464002 43.155801, −95.1463266 43.1557037) | Collision (155,1238) Point (−95.1464002 43.155801) | 0 | √ |
| id:1238 linestring (−95.146636 43.1561124, −95.1464002 43.155801) | Collision (155,1239) Point (−95.1464002 43.155801) | 0 | √ | |
| id:1239 linestring (−95.1461293 43.1559108, −95.1464002 43.155801) | Collision (1238,1239) Point (−95.1464002 43.155801) | 0 | √ |
| Objectid | Gid (Intersection i) | Nid (Intersection j) | Weight (Row-Standardized) | Weight (1/ ndij) | ndij (m) |
|---|---|---|---|---|---|
| 1 | 113 | 584 | 0.042195 | 0.019263 | 51.9122 |
| 2 | 113 | 921 | 0.177271 | 0.080929 | 12.3565 |
| 3 | 113 | 1174 | 0.034016 | 0.015529 | 64.394 |
| 4 | 113 | 1609 | 0.058348 | 0.026637 | 37.5413 |
| 5 | 584 | 113 | 0.060827 | 0.019263 | 51.9122 |
| 6 | 584 | 921 | 0.079828 | 0.025281 | 39.5557 |
| 7 | 584 | 1174 | 0.036251 | 0.011481 | 87.1041 |
| 8 | 584 | 1609 | 0.052408 | 0.016597 | 60.2514 |
| 9 | 921 | 113 | 0.175461 | 0.080929 | 12.3565 |
| 10 | 921 | 584 | 0.054811 | 0.025281 | 39.5557 |
| 11 | 921 | 1174 | 0.041664 | 0.019217 | 52.0375 |
| 12 | 921 | 1609 | 0.086087 | 0.039706 | 25.1848 |
| 13 | 1174 | 113 | 0.03666 | 0.015529 | 64.394 |
| 14 | 1174 | 584 | 0.027102 | 0.011481 | 87.1041 |
| 15 | 1174 | 921 | 0.045365 | 0.019217 | 52.0375 |
| 16 | 1174 | 1609 | 0.087912 | 0.03724 | 26.8527 |
| 17 | 1609 | 113 | 0.066423 | 0.026637 | 37.5413 |
| 18 | 1609 | 584 | 0.041387 | 0.016597 | 60.2514 |
| 19 | 1609 | 921 | 0.099012 | 0.039706 | 25.1848 |
| 20 | 1609 | 1174 | 0.092862 | 0.03724 | 26.8527 |
| Input Parameter | Input Value |
|---|---|
| Input Feature Class | intersection |
| Input Field | num_crash |
| Output Feature Class | c:\data\crash_hotspot_intersections.shp |
| Conceptualization of Spatial Relationships | get_spatial_weights_from_file |
| Standardization | true |
| Distance Band or Threshold Distance | 683.64 |
| Weights Matrix File | c:\data\INDSWMI.swm |
| Apply False Discovery Rate Correction | no_fdr |
| Gid | Name | Num_Crash | Nneighbors | Gi*ZScore | P Value |
|---|---|---|---|---|---|
| 940 | S Grand Ave& S Grand Ave&11th St SW&11th St SE | 32 | 45 | 11.275 | 0.000 |
| 1095 | W 44th St& W 44th St& Highway Blvd | 32 | 11 | 11.218 | 0.000 |
| 113 | W 18th St& Highway Blvd& W 18th St& Highway Blvd | 27 | 97 | 9.363 | 0.000 |
| 377 | W 4th St& Grand Ave& Grand Ave& E 4th St | 26 | 98 | 9.315 | 0.000 |
| 143 | Grand Ave& W 8th St& E 8th St& Grand Ave | 22 | 112 | 7.806 | 0.000 |
| 1620 | 11th St SW&7th Ave SW&&11th St SW | 22 | 89 | 7.594 | 0.000 |
| 263 | Grand Ave& E 7th St& Grand Ave& W 7th St | 20 | 112 | 7.161 | 0.000 |
| 391 | 4th Ave SW&11th St SW&4th Ave SW& 11th St SW | 19 | 92 | 6.629 | 0.000 |
| 728 | Grand Ave &W 9th St& E 9th St&Grand Ave | 19 | 108 | 6.729 | 0.000 |
| 540 | Grand Ave& W 1st St& Grand Ave& E 1st St | 17 | 83 | 6.002 | 0.000 |
| 1218 | 11th Ave SW&13th St SW&11th Ave SW&13th St SW&11th Ave SW | 16 | 51 | 5.447 | 0.000 |
| 358 | W 11th St& Grand Ave& Grand Ave& E 11th St | 15 | 120 | 5.230 | 0.000 |
| 925 | S Grand Ave&4th St SE& S Grand Ave& 4th St SW | 15 | 39 | 5.155 | 0.000 |
| 1640 | Grand Ave& E 3rd St& W 3rd St& Grand Ave | 14 | 92 | 5.022 | 0.000 |
| 31 | Grand Ave& W 5th St& E 5th St& Grand Ave | 12 | 103 | 4.308 | 0.000 |
| 882 | W 13th St& Grand Ave& E 13th St& Grand Ave | 10 | 127 | 3.432 | 0.001 |
| 995 | E 2nd St& Grand Ave& W 2nd St& Grand Ave | 10 | 89 | 3.558 | 0.000 |
| 1100 | 1st Ave E& E 3rd St& E 3rd St&1st Ave E | 10 | 89 | 3.508 | 0.000 |
| 918 | 8th St SW& S Grand Ave& S Grand Ave | 8 | 47 | 2.642 | 0.008 |
| 1153 | E 4th St&4th Ave E& E 4th St&4th Ave E | 8 | 79 | 2.670 | 0.008 |
| 1515 | 4th Ave E& E 8th St&4th Ave E& E 8th St | 8 | 114 | 2.680 | 0.007 |
| 1538 | 3rd Ave E& E 9th St&3rd Ave E& E 9th St | 8 | 111 | 2.696 | 0.007 |
| 1561 | 2nd Ave SE&11th St SE&11th St SE& 2nd Ave SE | 8 | 43 | 2.671 | 0.008 |
| 270 | E 10th St&6th Ave E& E 10th St& Fairview Ave | 7 | 111 | 2.248 | 0.025 |
| 1152 | E 4th St& E 4th St&1st Ave E | 7 | 87 | 2.298 | 0.022 |
| 187 | 1st Ave E& E 2nd St&1st Ave E& E 2nd St | 6 | 86 | 2.058 | 0.040 |
| 538 | E Park St& Grand Ave& W Park St& Grand Ave | 6 | 70 | 2.047 | 0.041 |
| 720 | W 10th St& Grand Ave& E 10th St& Grand Ave | 6 | 116 | 2.079 | 0.038 |
| 1455 | 1st Ave W& W 7th St&1st Avenue W& W 7th St | 6 | 104 | 2.081 | 0.037 |
| Number of Crashes in CHIs (2008–2014) | Percentage of Crashes in CHIs (2008–2014) | Number of Crashes in CHIs (2015–2017) | Percentage of Crashes in CHIs (2015–2017) | Total Length of Roads within CHIs (m) | Percentage of Total Length of Roads within CHIs | IPAI | |
|---|---|---|---|---|---|---|---|
| IHA with INDSWMI | 29 | 51.68% | 137 | 47.90% | 24,115.51 | 10.01% | 4.79 |
| IHA with IEDSWMI | 30 | 52.42% | 140 | 48.95% | 34,198.16 | 14.19% | 3.45 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Ming, Y.; Song, G. A New Approach to Identifying Crash Hotspot Intersections (CHIs) Using Spatial Weights Matrices. Appl. Sci. 2020, 10, 1625. https://doi.org/10.3390/app10051625
Zhang Z, Ming Y, Song G. A New Approach to Identifying Crash Hotspot Intersections (CHIs) Using Spatial Weights Matrices. Applied Sciences. 2020; 10(5):1625. https://doi.org/10.3390/app10051625
Chicago/Turabian StyleZhang, Zhonggui, Yi Ming, and Gangbing Song. 2020. "A New Approach to Identifying Crash Hotspot Intersections (CHIs) Using Spatial Weights Matrices" Applied Sciences 10, no. 5: 1625. https://doi.org/10.3390/app10051625