A Novel Ensemble Framework Based on K-Means and Resampling for Imbalanced Data

Abstract
:1. Introduction
2. Related Works
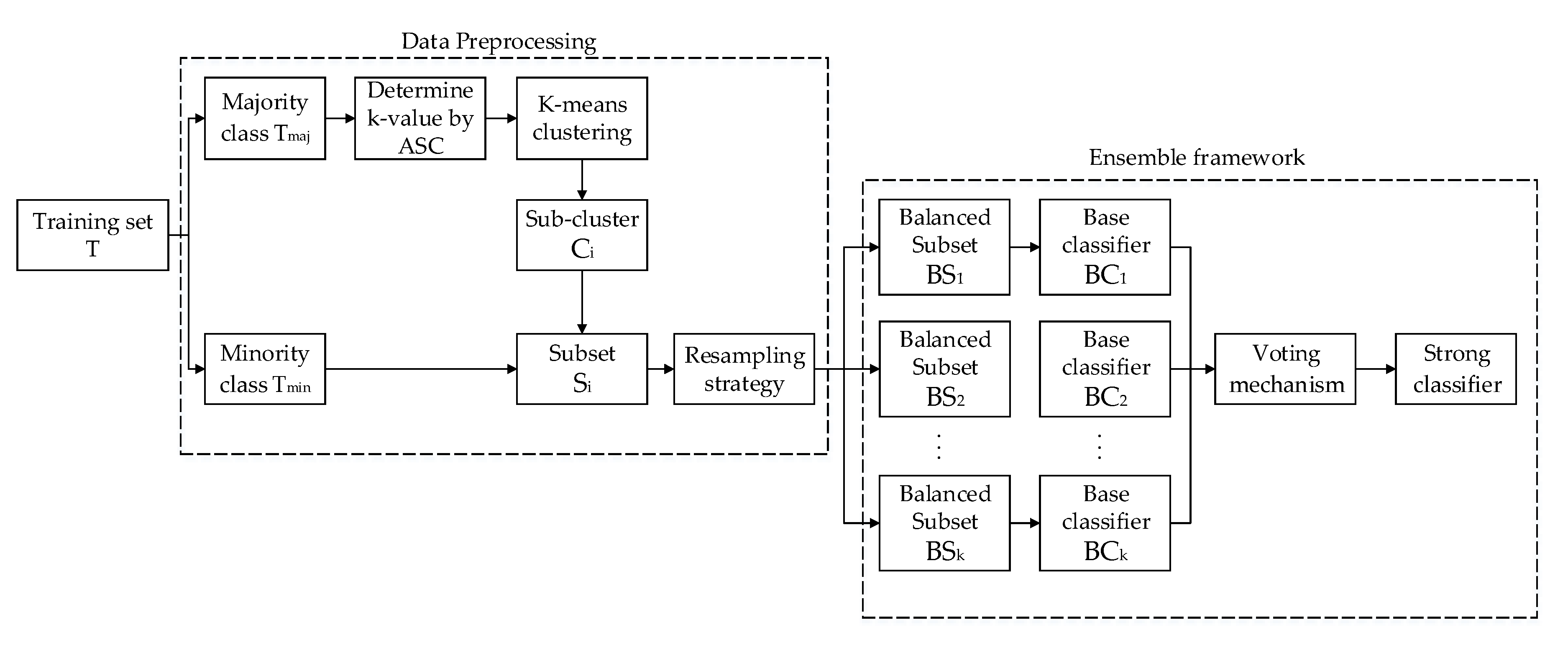
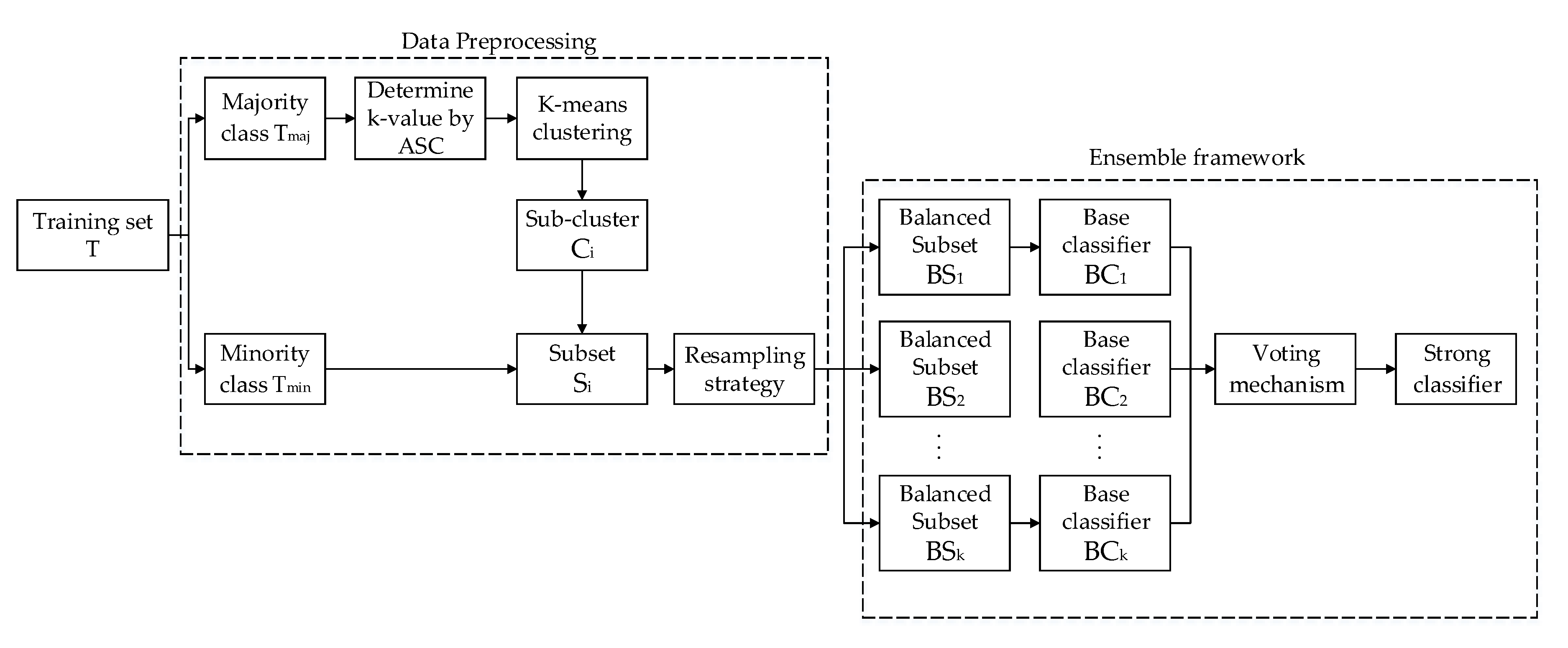
3. The Proposed Approach EKR
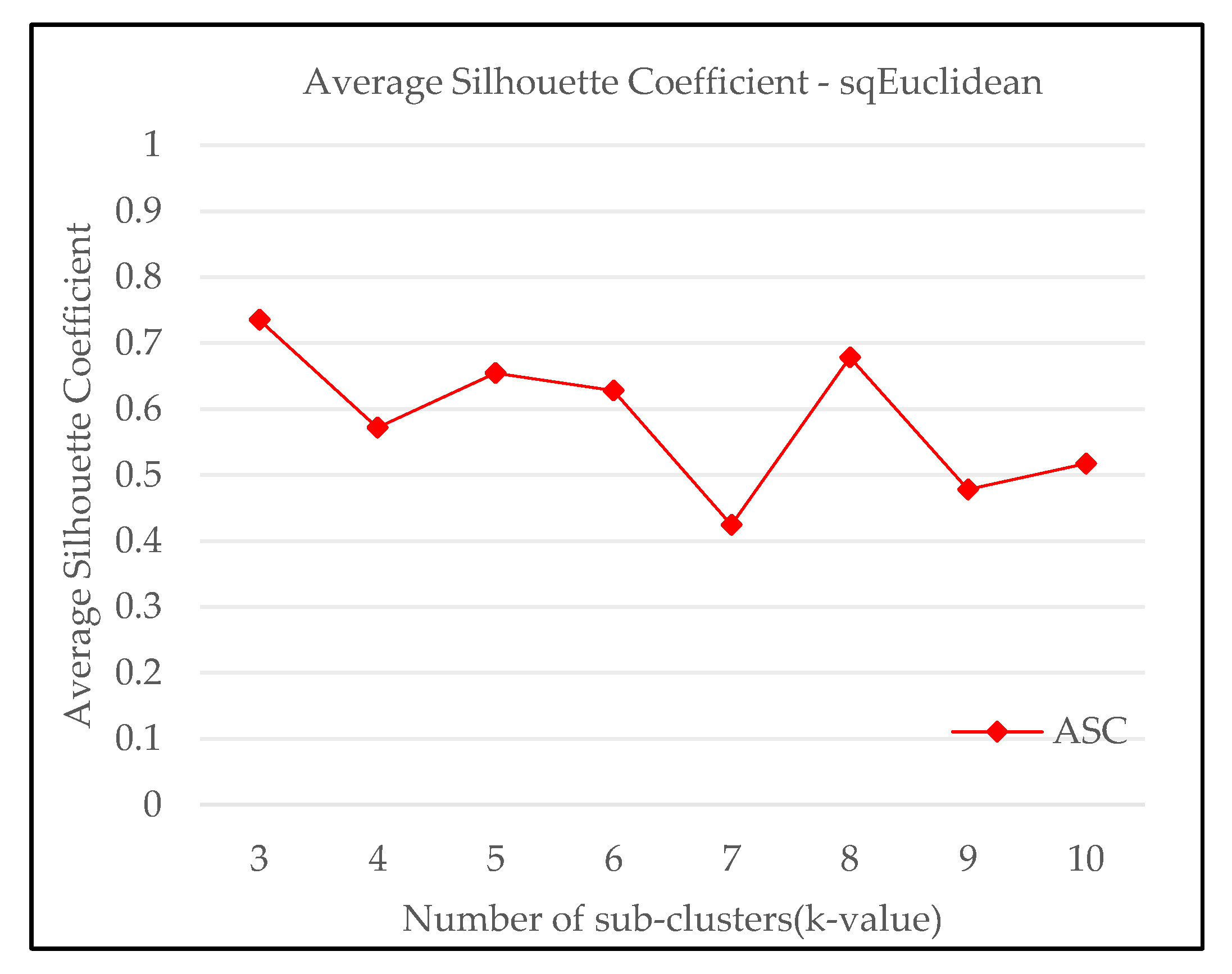
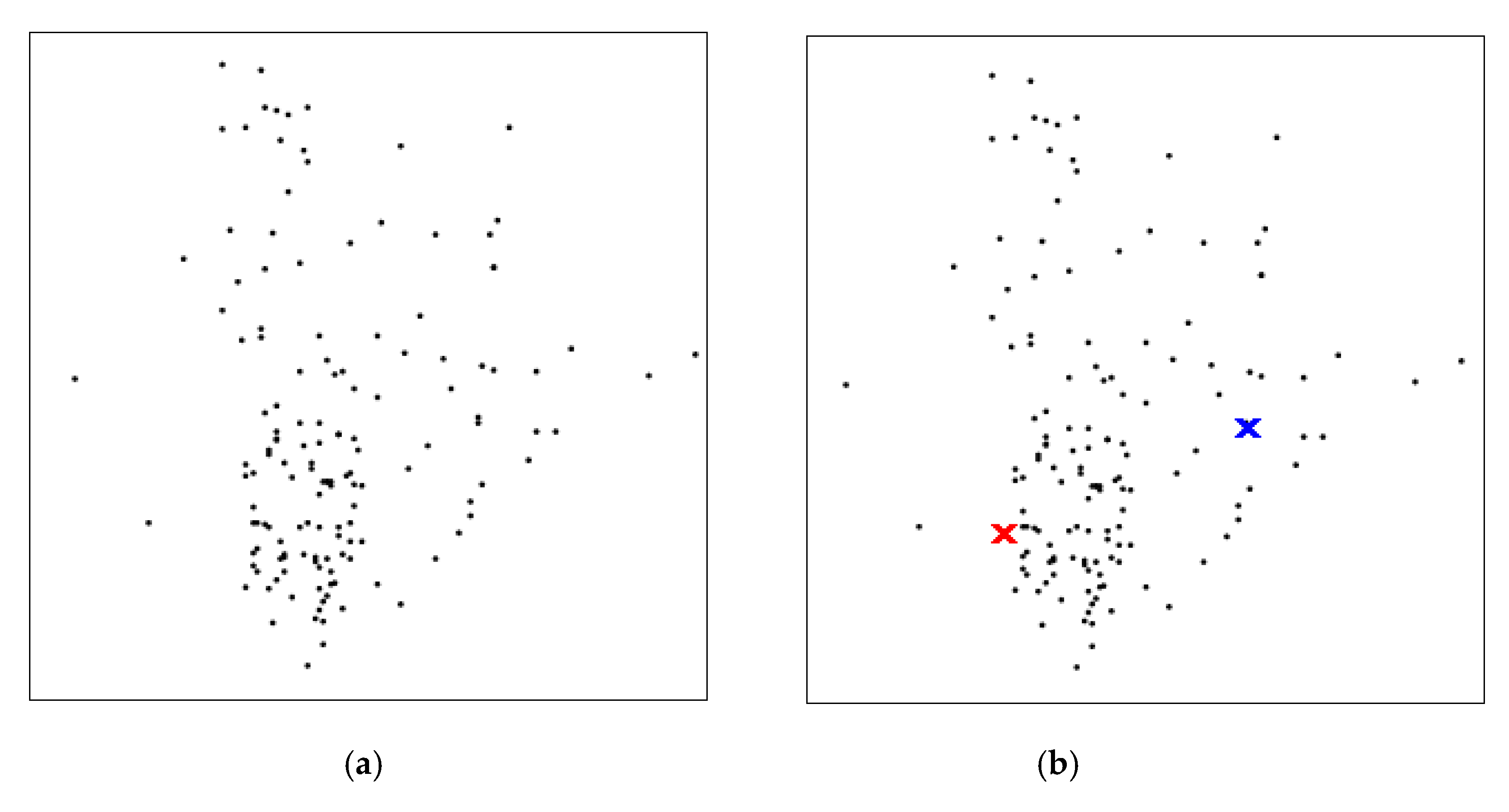
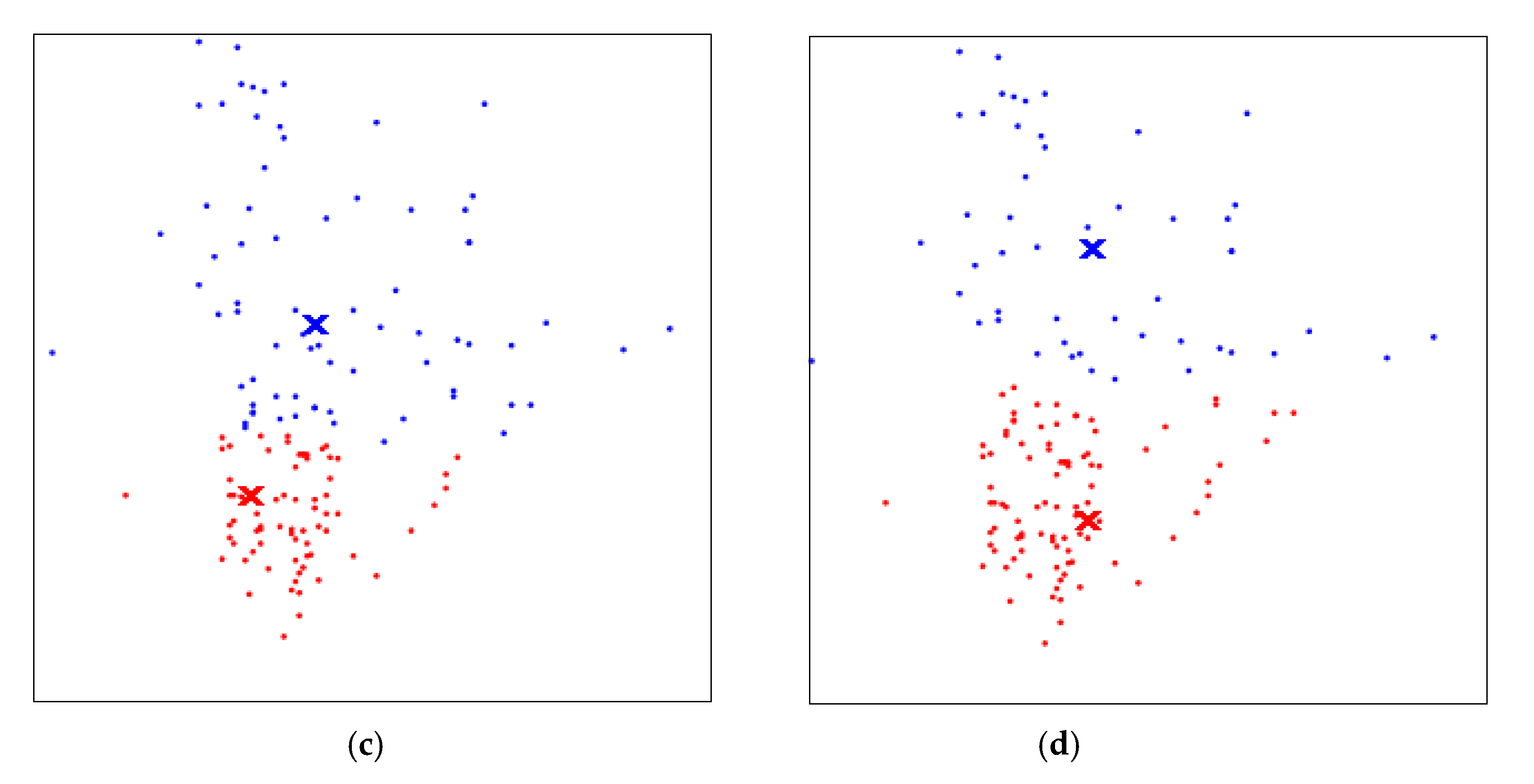
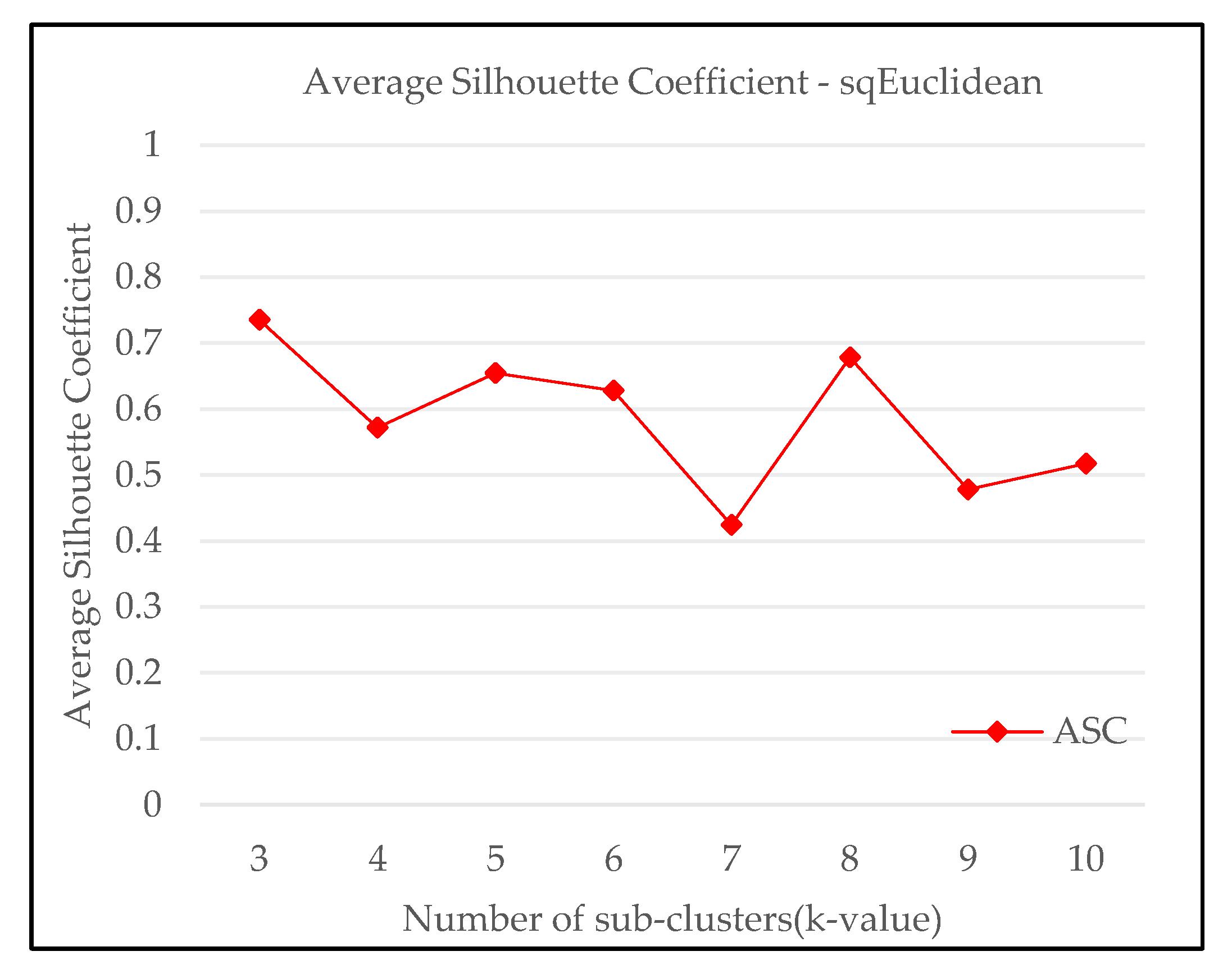
3.1. K-Means Clustering
3.2. Resampling Strategy
3.3. The Ensemble Framework based on K-Means and Resampling Technology
4. Experiment Preparation and Result Analysis
4.1. Datasets
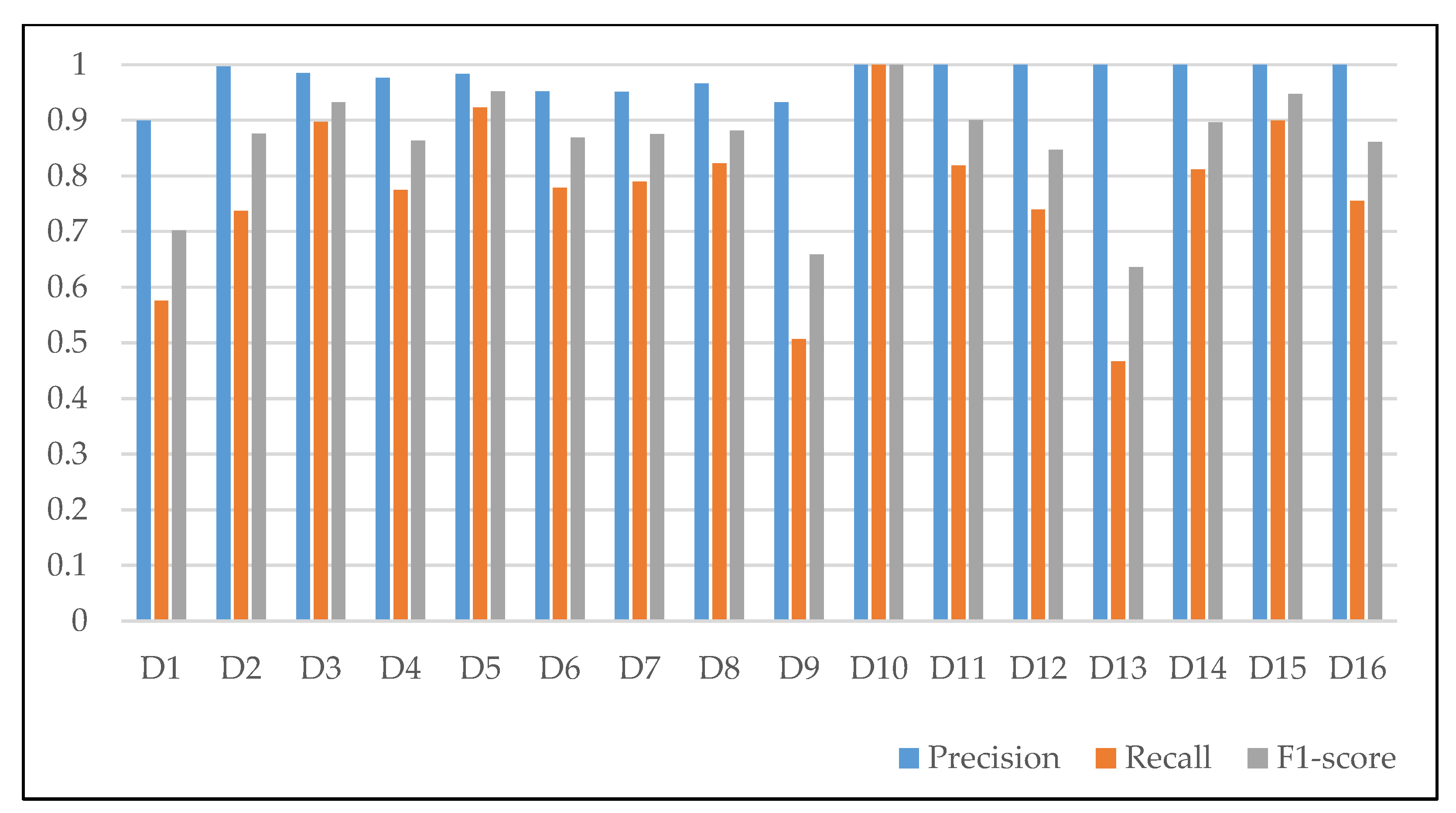
4.2. Metrics for Performance Evaluation
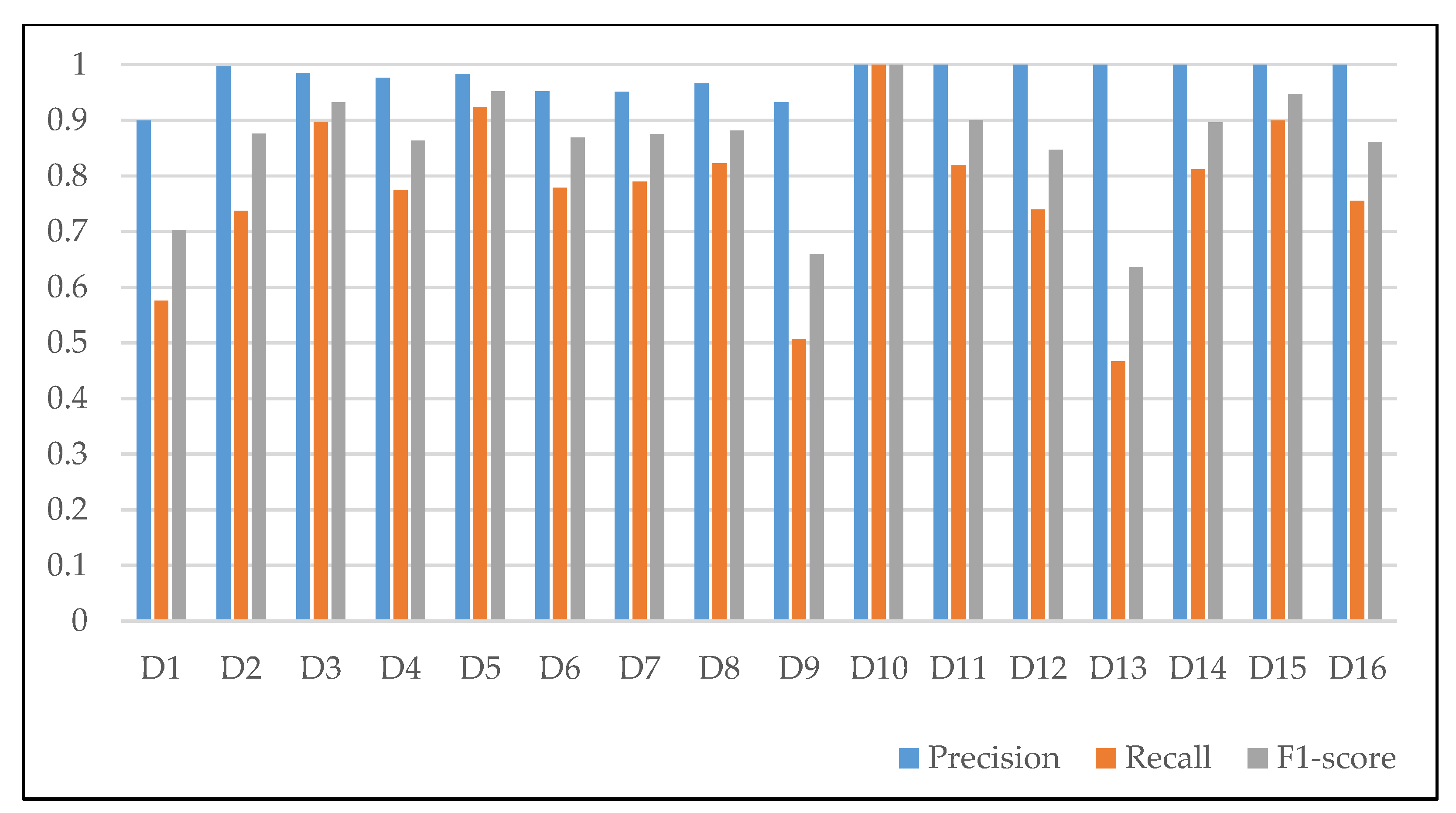
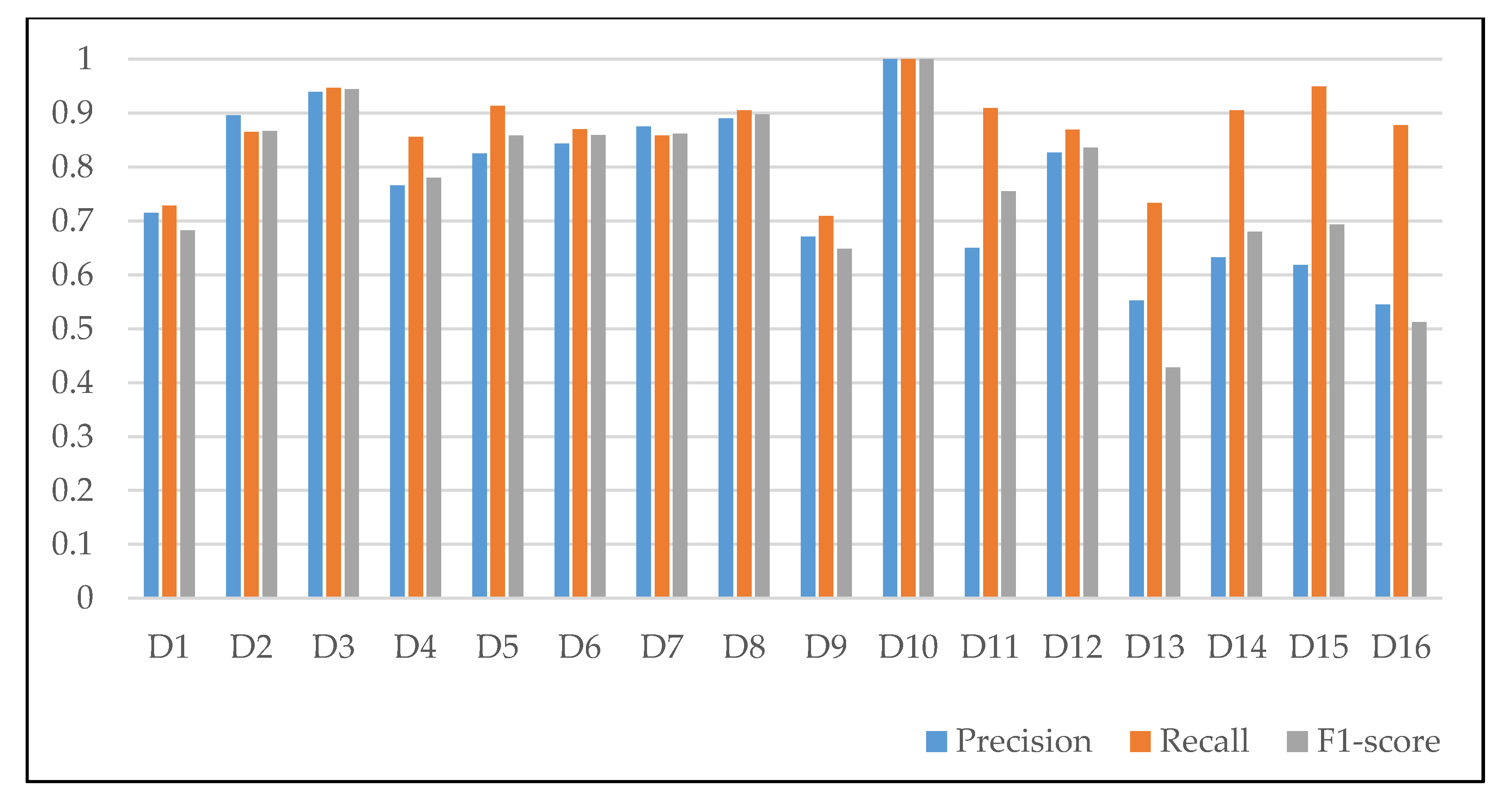
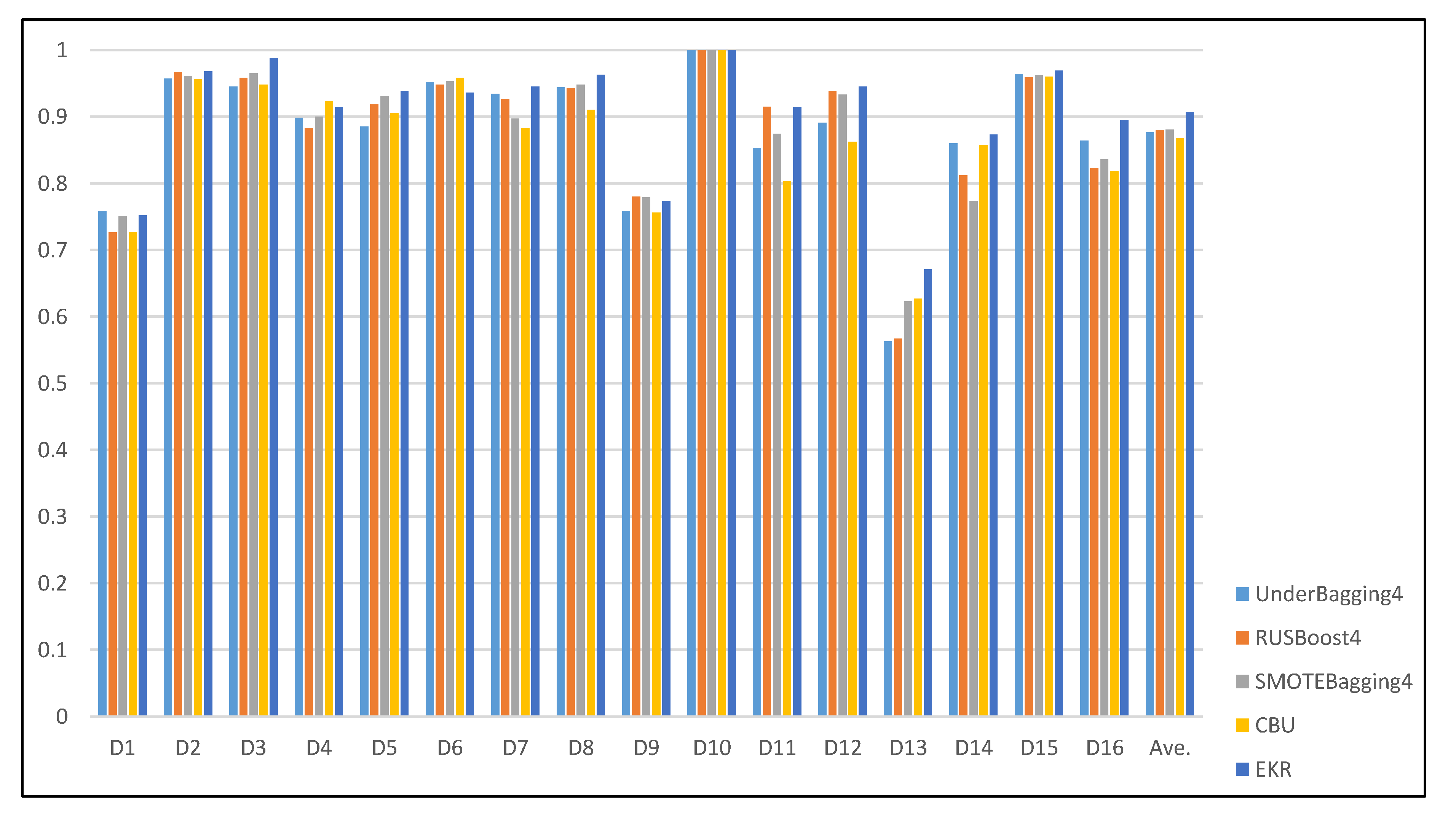
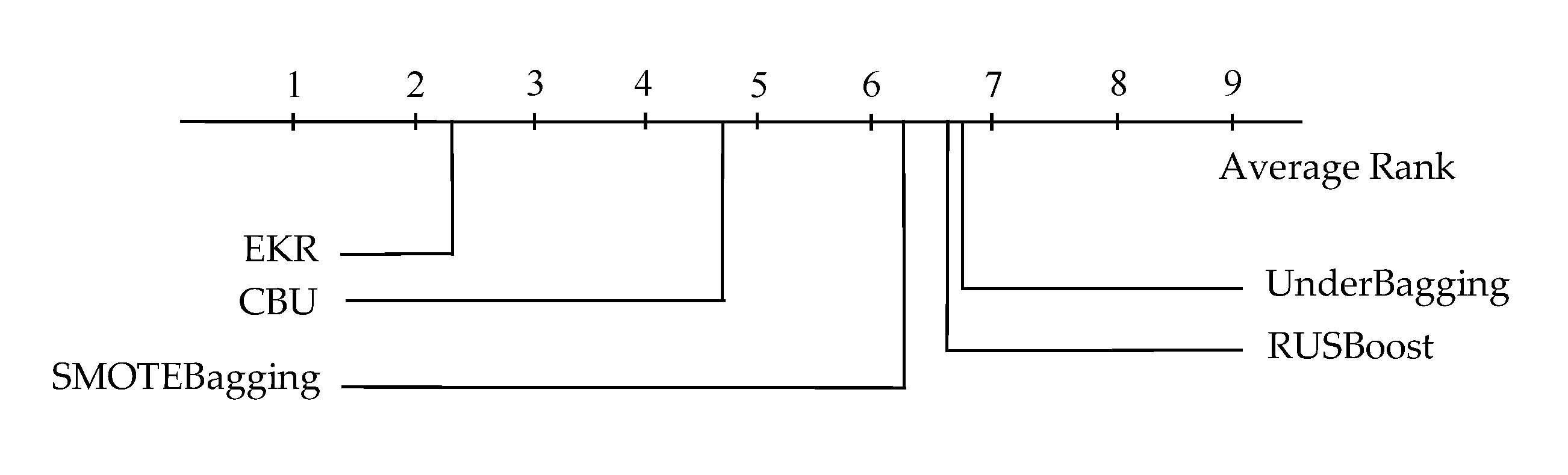
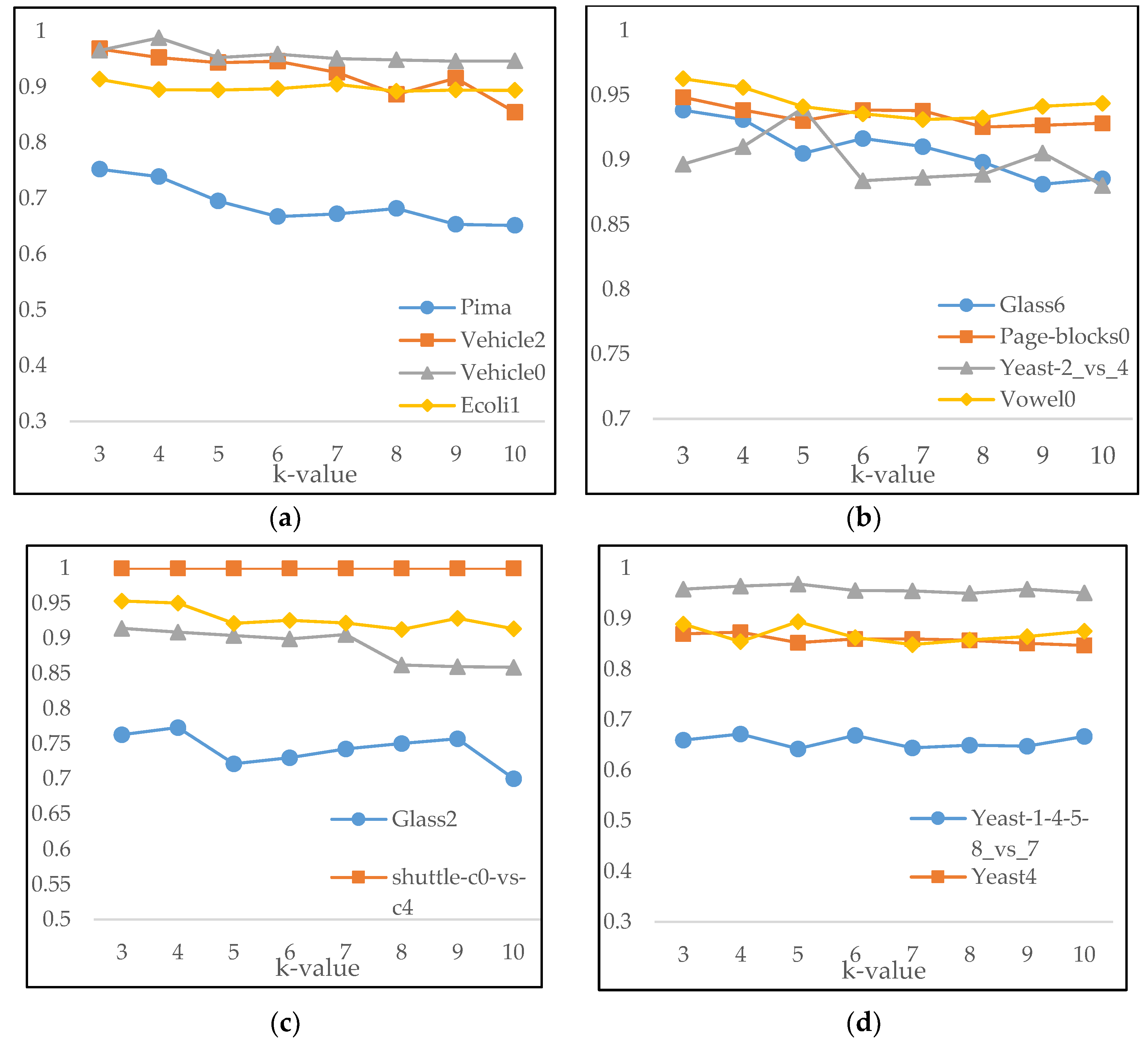
4.3. Experimental Results and Analysis
5. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parvin, H.; Minaei-Bidgoli, B.; Alinejad-Rokny, H. A new imbalanced learning and dictions tree method for breast cancer diagnosis. J. Bionanosci. 2013, 7, 673–678. [Google Scholar] [CrossRef]
- Tsai, C.F.; Hsu, Y.F.; Lin, C.Y.; Lin, W.Y. Intrusion detection by machine learning: A review. Expert Syst. Appl. 2009, 36, 11994–12000. [Google Scholar] [CrossRef]
- West, J.; Bhattacharya, M. Intelligent Financial Fraud Detection: A Comprehensive Review. Comput. Secur. 2015, 57, 47–66. [Google Scholar] [CrossRef]
- Barandelaa, R.; Sanchez, J.S.; Garcia, V. Strategies for learning in class imbalance problems. Pattern Recognit. 2003, 36, 849–851. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Liu, X.Y. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Trans. Knowl. Data Eng. 2006, 18, 63–77. [Google Scholar] [CrossRef]
- Nikulin, V.; Mclachlan, G.J.; Ng, S.K. Ensemble Approach for the Classification of Imbalanced Data. In Proceedings of the Australasian Joint Conference on Advances in Artificial Intelligence, Melbourne, Australia, 1–4 December 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 291–300. [Google Scholar]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20. [Google Scholar] [CrossRef]
- Ahmad, A.; Dey, L. A k-mean clustering algorithm for mixed numeric and categorical data. Data Knowl. Eng. 2007, 63, 503–527. [Google Scholar] [CrossRef]
- You, C.; Li, C.; Robinson, D.P. René Vidal A Scalable Exemplar-Based Subspace Clustering Algorithm for Class-Imbalanced Data. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, W.C.; Tsai, C.F.; Hu, Y.H.; Jhang, J.S. Clustering-based undersampling in class-imbalanced data. Inf. Sci. 2017, 409, 17–26. [Google Scholar] [CrossRef]
- Tsai, C.F.; Lin, W.C.; Hu, Y.H.; Yao, G.T. Under-sampling class imbalanced datasets by combining clustering analysis and instance selection. Inf. Sci. 2018, 477, 47–54. [Google Scholar] [CrossRef]
- Ofek, N.; Rokach, L.; Stern, R.; Shabtai, A. Fast-CBUS: A fast clustering-based undersampling method for addressing the class imbalance problem. Neurocomputing 2017, 243, 88–102. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Georgios, D.; Fernando, B.; Felix, L. Improving imbalanced learning through a heuristic oversampling method based on K-means and smote. Inf. Sci. 2018, 465, 1–20. [Google Scholar]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-smote: A new over-sampling method in imbalanced data sets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Ma, L.; Fan, S. CURE-SMOTE algorithm and hybrid algorithm for feature selection and parameter optimization based on random forests. BMC Bioinform. 2017, 18, 169. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bolón-Canedo, V.; Alonso-Betanzos, A. Ensembles for feature selection: A review and future trends. Inf. Fusion 2019, 52, 1–12. [Google Scholar] [CrossRef]
- Nejatian, S.; Parvin, H.; Faraji, E. Using sub-sampling and ensemble clustering techniques to improve performance of imbalanced classification. Neurocomputing 2018, 276, 55–66. [Google Scholar] [CrossRef]
- Parvin, H.; Mirnabibaboli, M.; Alinejad-Rokny, H. Proposing a classifier ensemble framework based on classifier selection and decision tree. Eng. Appl. Artif. Intell. 2015, 37, 34–42. [Google Scholar] [CrossRef]
- Minaei-Bidgoli, B.; Asadi, M.; Parvin, H. An ensemble based approach for feature selection. Eng. Appl. Neural Netw. 2011, 363, 240–246. [Google Scholar]
- Li, F.L.; Zhang, X.Y.; Zhang, X.Q.; Du, C.L.; Xu, Y.; Tian, Y.C. Cost-sensitive and hybrid-attribute measure multi-decision tree over imbalanced datasets. Inf. Sci. 2018, 422, 242–256. [Google Scholar] [CrossRef]
- Qian, Y.; Liang, Y.; Li, M.; Feng, G.; Shi, X. A resampling ensemble algorithm for classification of imbalance problems. Neurocomputing 2014, 143, 57–67. [Google Scholar] [CrossRef]
- Kang, P.; Cho, S. EUS SVMs: Ensemble of Under-Sampled SVMs for Data Imbalance Problems. In Proceedings of the International Conference on Neural Information Processing, Hong Kong, China, 3–6 October 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 837–846. [Google Scholar]
- Lu, W.; Li, Z.; Chu, J. Adaptive ensemble undersampling-boost: A novel learning framework for imbalanced data. J. Syst. Softw. 2019, 132, 272–282. [Google Scholar] [CrossRef]
- Sun, B.; Chen, H.; Wang, J.; Xie, H. Evolutionary under-sampling based bagging ensemble method for imbalanced data classification. Front. Comput. Sci. 2017, 12, 331–350. [Google Scholar] [CrossRef]
- Barandela, R.; Valdovinos, R.M.; Sánchez, J.S. New applications of ensembles of classifiers. Pattern Anal. Appl. 2003, 6, 245–256. [Google Scholar] [CrossRef]
- Wang, S.; Yao, X. Diversity Analysis on Imbalanced Data Sets by Using Ensemble Models. In Proceedings of the IEEE Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009. [Google Scholar]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. SMOTEBoost: Improving Prediction of the Minority Class in Boosting. In Proceedings of the European Conference on Principles and Practice of Knowledge Discovery in Databases, Cavtat-Dubrovnik, Croatia, 22–26 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 107–119. [Google Scholar]
- Seiffert, C.; Khoshgoftaar, T.M.; Hulse, J.V.; Napolitano, A. RUSBoost: A hybrid approach to alleviating class imbalance. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2010, 40, 185–197. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| #No. | #Datasets | #Features | #Samples | IR | k-Value |
|---|---|---|---|---|---|
| D1 | Pima | 9 | 768 | 1.87 | 3 |
| D2 | Vehicle2 | 18 | 846 | 2.88 | 3 |
| D3 | Vehicle0 | 18 | 846 | 3.25 | 4 |
| D4 | Ecoli1 | 7 | 336 | 3.36 | 3 |
| D5 | Glass6 | 9 | 214 | 6.38 | 3 |
| D6 | Page-blocks0 | 10 | 5472 | 8.79 | 3 |
| D7 | Yeast-2_vs_4 | 8 | 514 | 9.08 | 5 |
| D8 | Vowel0 | 9 | 988 | 9.98 | 3 |
| D9 | Glass2 | 9 | 214 | 11.59 | 4 |
| D10 | Shuttle-c0-vs-c4 | 9 | 1829 | 13.87 | 5 |
| D11 | Glass4 | 9 | 214 | 15.47 | 3 |
| D12 | Ecoli4 | 7 | 336 | 15.8 | 3 |
| D13 | Yeast-1-4-5-8_vs_7 | 8 | 693 | 22.1 | 4 |
| D14 | Yeast4 | 8 | 1484 | 28.41 | 4 |
| D15 | Yeast5 | 8 | 1484 | 32.73 | 5 |
| D16 | Yeast6 | 8 | 1484 | 41.4 | 5 |
| Confusion Matrix | Predicted Labels | ||
|---|---|---|---|
| Positive | Negative | ||
| Actual labels | Positive | TP | FN |
| Negative | FP | TN | |
| Datasets | Base Classifiers Used by EKR | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM | Naïve Bayes | KNN | C4.5 | |||||||||||||
| Acc | F1 | GM | AUC | Acc | F1 | GM | AUC | Acc | F1 | GM | AUC | Acc | F1 | GM | AUC | |
| D1 | 0.7197 | 0.6807 | 0.7257 | 0.7520 | 0.7050 | 0.6710 | 0.7020 | 0.7330 | 0.7294 | 0.6824 | 0.7430 | 0.7615 | 0.7255 | 0.6900 | 0.7414 | 0.7594 |
| D2 | 0.9314 | 0.8665 | 0.9469 | 0.9680 | 0.9220 | 0.8550 | 0.9450 | 0.9640 | 0.9124 | 0.8497 | 0.9302 | 0.9527 | 0.9413 | 0.8670 | 0.9510 | 0.9706 |
| D3 | 0.9811 | 0.9447 | 0.9624 | 0.9880 | 0.9490 | 0.9370 | 0.9460 | 0.9450 | 0.9755 | 0.9429 | 0.9506 | 0.9621 | 0.9792 | 0.9450 | 0.9599 | 0.9914 |
| D4 | 0.8403 | 0.7797 | 0.8876 | 0.9140 | 0.8140 | 0.7190 | 0.8690 | 0.8780 | 0.8444 | 0.7801 | 0.8911 | 0.8967 | 0.8529 | 0.7860 | 0.9122 | 0.9267 |
| D5 | 0.9341 | 0.8585 | 0.9365 | 0.9380 | 0.8530 | 0.8340 | 0.9110 | 0.9150 | 0.8920 | 0.8230 | 0.8972 | 0.8993 | 0.9286 | 0.8610 | 0.9357 | 0.9409 |
| D6 | 0.9493 | 0.8483 | 0.9240 | 0.9340 | 0.9530 | 0.8560 | 0.9340 | 0.9350 | 0.9572 | 0.8594 | 0.9359 | 0.9484 | 0.9638 | 0.8720 | 0.9467 | 0.9573 |
| D7 | 0.9022 | 0.8544 | 0.9215 | 0.9400 | 0.8840 | 0.8420 | 0.9330 | 0.9360 | 0.9307 | 0.8618 | 0.9372 | 0.9383 | 0.9254 | 0.8530 | 0.9277 | 0.9326 |
| D8 | 0.9355 | 0.8981 | 0.9417 | 0.9630 | 0.9290 | 0.8950 | 0.9380 | 0.9540 | 0.9258 | 0.8874 | 0.9385 | 0.9488 | 0.9411 | 0.9100 | 0.9369 | 0.9640 |
| D9 | 0.6822 | 0.6308 | 0.7346 | 0.7730 | 0.6590 | 0.5860 | 0.7070 | 0.7450 | 0.6740 | 0.6484 | 0.7225 | 0.7618 | 0.6836 | 0.6470 | 0.7358 | 0.7683 |
| D10 | 1.0000 | 1.0000 | 1.000 | 1.0000 | 0.9970 | 0.9810 | 0.9990 | 0.9990 | 0.9967 | 0.9763 | 0.9945 | 0.9943 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| D11 | 0.8394 | 0.7416 | 0.8797 | 0.9140 | 0.8220 | 0.7550 | 0.8760 | 0.9130 | 0.8343 | 0.7388 | 0.8628 | 0.9115 | 0.8424 | 0.7530 | 0.8931 | 0.9212 |
| D12 | 0.8971 | 0.8192 | 0.9259 | 0.9450 | 0.8510 | 0.7900 | 0.9170 | 0.9210 | 0.9118 | 0.8360 | 0.9312 | 0.9531 | 0.9076 | 0.8380 | 0.9366 | 0.9519 |
| D13 | 0.5396 | 0.4283 | 0.6547 | 0.6710 | 0.5150 | 0.4100 | 0.6490 | 0.6600 | 0.5036 | 0.4124 | 0.6364 | 0.6507 | 0.5332 | 0.4320 | 0.6587 | 0.6826 |
| D14 | 0.8283 | 0.6798 | 0.8548 | 0.8730 | 0.8080 | 0.6720 | 0.8430 | 0.8720 | 0.7912 | 0.6639 | 0.8610 | 0.8697 | 0.8405 | 0.6860 | 0.8741 | 0.8798 |
| D15 | 0.9291 | 0.693 | 0.9629 | 0.9690 | 0.9260 | 0.6780 | 0.9610 | 0.9620 | 0.9158 | 0.6795 | 0.9538 | 0.9566 | 0.9334 | 0.7180 | 0.9651 | 0.9770 |
| D16 | 0.8748 | 0.5043 | 0.8912 | 0.8940 | 0.8960 | 0.5130 | 0.8850 | 0.8910 | 0.8519 | 0.4862 | 0.8769 | 0.8715 | 0.8787 | 0.5160 | 0.8881 | 0.8846 |
| Ave. | 0.8615 | 0.7642 | 0.8844 | 0.9020 | 0.8430 | 0.7520 | 0.8760 | 0.8890 | 0.8529 | 0.7590 | 0.8789 | 0.8923 | 0.8673 | 0.7740 | 0.8940 | 0.9068 |
| Winner | 4 | 1 | 5 | 4 | 1 | 1 | 0 | 0 | 3 | 2 | 2 | 2 | 10 | 14 | 11 | 12 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, H.; Wei, Y.; Liu, P.; Yin, H. A Novel Ensemble Framework Based on K-Means and Resampling for Imbalanced Data. Appl. Sci. 2020, 10, 1684. https://doi.org/10.3390/app10051684
Duan H, Wei Y, Liu P, Yin H. A Novel Ensemble Framework Based on K-Means and Resampling for Imbalanced Data. Applied Sciences. 2020; 10(5):1684. https://doi.org/10.3390/app10051684
Chicago/Turabian StyleDuan, Huajuan, Yongqing Wei, Peiyu Liu, and Hongxia Yin. 2020. "A Novel Ensemble Framework Based on K-Means and Resampling for Imbalanced Data" Applied Sciences 10, no. 5: 1684. https://doi.org/10.3390/app10051684
APA StyleDuan, H., Wei, Y., Liu, P., & Yin, H. (2020). A Novel Ensemble Framework Based on K-Means and Resampling for Imbalanced Data. Applied Sciences, 10(5), 1684. https://doi.org/10.3390/app10051684