This section considers the background to the practical work conducted in this study in two parts. In the first, evaluation methodologies for intelligent systems are reviewed, while the second part introduces the CEGRA and TOPSIS algorithms used for decision making in this study.
2.1. Review of Evaluation Methodologies for Intelligent Systems
Determining how to increase the product yield and reduce the costs of small- and medium-sized enterprises is a major challenge. In the semiconductor industry, manufacturers have gradually integrated with smaller firms to increase production and reduce costs [
13]. Since current manufacturing systems employ 24-hour production cycles, capacities can decrease, producing fewer profits, if the system or a machine malfunctions [
14,
15]. To help factory operators to quickly undertake measures to prevent accidents, prediction of the risk index is significant. Hence, a number of techniques have been developed for quantifiable risk evaluation and decision making. By combining the concepts of fuzzy set theory, entropy, and ideal and grey relational analysis, Liao et al. developed a fuzzy grey relational method for multiple criteria decision-making problems [
16]. Tzeng and Huang [
17] proposed a grey relational analysis approach for selecting and reconfiguring aspired-for global manufacturing and logistics systems. In optimization of electrical discharge machining processes, Pradhan [
18] used grey relational analysis to estimate the effect of machining parameters on a tool’s response, and determined the weights of responses using principal component analysis (PCA), further evaluating the weights of the responses using a response surface methodology. Mondal et al. [
19] combined Taguchi and grey relational analysis to evaluate optimal parameters for laser cladding of a steel surface. Sun [
20] combined grey relational analysis and information entropy, finding that, in evaluation of the performance of notebook companies, the results obtained with their technique were more objective than those obtained with other decision-making methods. Fayaz et al. [
21] proposed a hierarchical fuzzy logic model to assess significant risks of accidents in underground facilities. With their technique, the risk index is predicted using a Kalman filter after a risk is assessed.
Each decision-making method has its advantages and disadvantages, as well as timing and use restrictions. For example, the analytic hierarchy process (AHP) [
22] is applied to decision making in uncertain situations where the majority of the evaluation criteria is known. However, the AHP has the following shortcomings: (1) the evaluation scale is a subjective one to nine judgment; (2) the number of elements in the hierarchy should not exceed seven, as it will affect the consistency of the level; and (3) the consistency of the results of analysis is affected by deviation from the selection criteria and evaluation by too large a number of experts. Shih et al. [
23] reported that in considering the benefit or the cost criterion, the TOPSIS method can only reflect the relative proximity of the evaluation criteria within each assessment scheme, and does not reflect the relative proximity to the ideal optimal scheme. Shannon [
24] suggested that if data can be obtained directly from the decision-making environment, the entropy algorithm can be used to calculate the objective weight of the criterion. More chaotic measurements increase the weight of this criterion, reflecting larger differences between the importance of different criteria. For such measurements, the entropy method is more effective in managing uncertainty, and the reduction of subjective factors is greater. With CEGRA, both qualitative and quantitative relationships can be identified from complex factors with insufficient information. The main feature of CEGRA is that it can be applied when information is limited, and can support an objective decision based on different data. This method combines the advantages of AHP’s expert evaluation, entropy, and TOPSIS, and can be used to effectively manage decision uncertainty, multi-criteria input, and discrete data.
2.2. The CEGRA Method
The CEGRA method can use decision-making and information evaluation to incompletely explore the degree of association between two series, quantify the distance between observed and target values using discrete measures, conduct correlation analyses, establish models, and enable decision making between various schemes. CEGRA can effectively manage uncertainty, multivariate input, and discrete data in decision problems [
25,
26,
27].
In this study, novel algorithms were designed to assess the decision making of an IAMS for the online manufacturing of sports shoes. The implementation of the algorithms used in this study are based on the CEGRA and grey situation decision-making system proposed by Deng [
11]. The steps in the algorithms are described as follows:
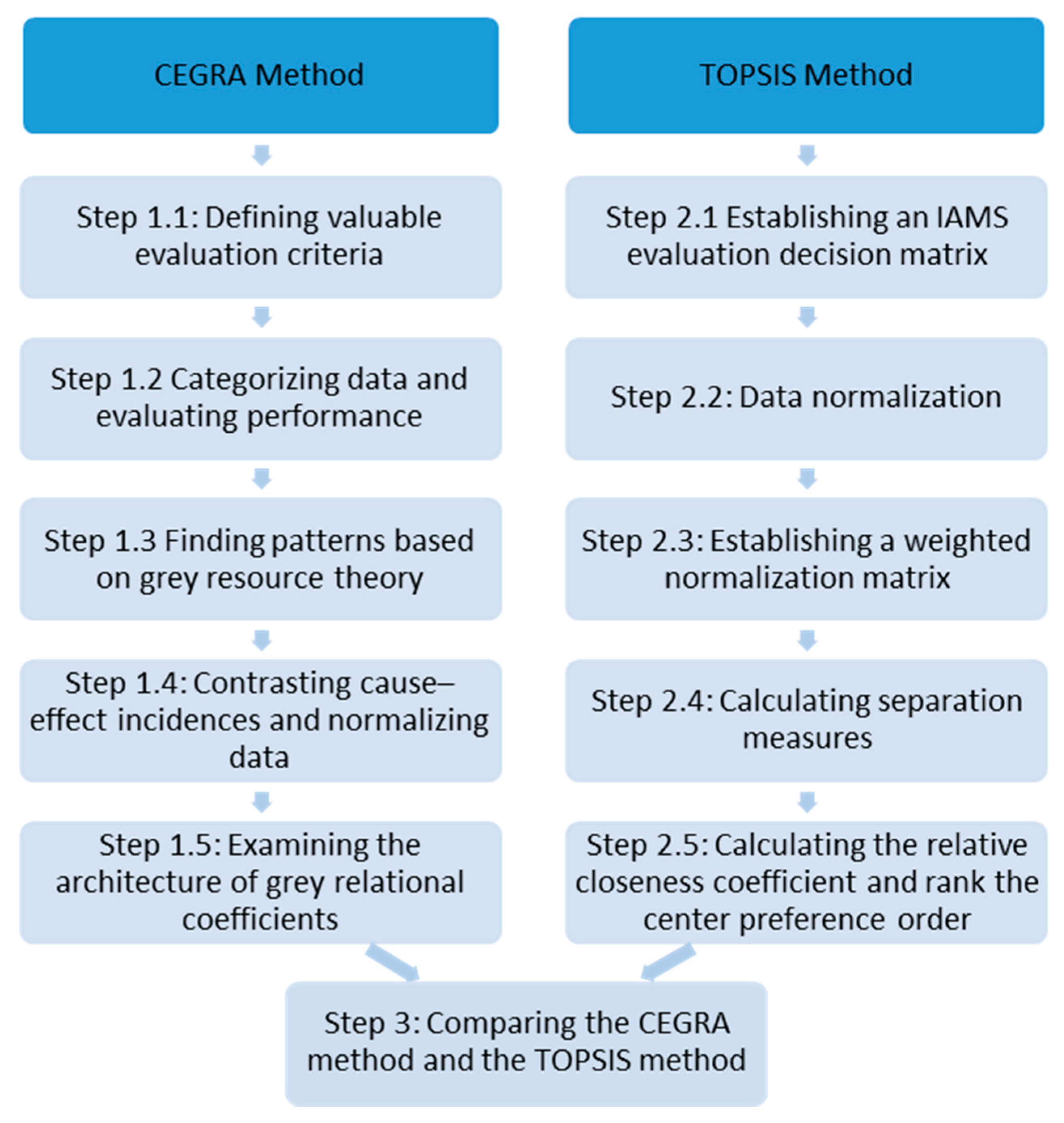
Step 1.1: Defining evaluations valuable for assessing online sports shoe online manufacturing IAMSs.
Let (
EPF,
X) be the exploiting resource space when
EPF is equipped with mapping functions as follows:
In the above, a general consensus among experts has been reached to establish a model, facilitating the ultimate goal of evaluating the performance of collaboration between technology companies according to CEGRA concepts.
Step 1.2: Categorizing data and evaluating performance.
Data from the IAMSs can be categorized as data resources or resources possessing information,
θ(
d), as shown below:
Otherwise, only digits exist, without a resource.
If
is the entirety of complete decision-making information for event
o, the following data category is obtained:
Step 1.3: Finding patterns based on grey resource theory.
In grey resource theory, the situation, Sij = (ai, bj), is defined as a pattern, where ai is a decision maker and bj is a resource. Hence, the effectiveness of ai and bj can expressed using Sij.
GM is defined as a mapping function,
, where
is the value of the mapping function, such that,
Hence, if the mapping of an event,
, is defined as
, the synthetic measured effectiveness value for this event is defined as:
Step 1.4: Contrasting cause–effect incidences and normalizing data.
In the cause–effect space , a cause–effect relationship can only be obtained between individuals with cause–effect incidences that are essential contrasts; no contrasts are required for irrelevant individuals. In this study, cause–effect incidence contrasting was defined as follows.
First, let α and β be the contrasted individuals, . then represents a comparison gene, and for series comparison, , where denotes melt and indicates irrelevance.
The contrasted result,
v is given as follows:
If is considered a cause–effect related contrast, then or if α and β are irrelevant, such that . Alternatively, if α and β are incident in terms of cause and effect, then .
Before calculation of the grey relational coefficients, the data series can be analyzed based on the linearity of normalized data (required to prevent data from being distorted) [
28,
29], and the following three metrics:
- (1)
The upper-bound effectiveness, measured as
- (2)
The lower-bound effectiveness, measured as
- (3)
Moderate effectiveness, defined as
If
, then:
If
, then:
If
, then:
where
is the objective value of entity
k.
Step 1.5: Examining the architecture of grey relational coefficients.
In a cause–effect resource incidence space
, the architecture of the grey relational coefficients must enable maximum exploitation of ecological benefits according to cause–effect incidence contrasting and the adjustable coefficient,
,
. This coefficient must be based on cause and effect criteria with complete incidence. The architecture of grey relational coefficients is expressed as follows:
The grey relational grade (GRG) for a series
Xi is given as follows:
where
wk is the weight of the
jth entity. If no weights need to be applied, then an average is taken, i.e.,
.
2.3. The TOPSIS Method
The TOPSIS method for multiple attribute group decision making was developed by Hwang and Yoon [
12]. It has subsequently been used to evaluate the purchase of business intelligence systems, product quality improvements, flow control in a manufacturing system, and intelligent home energy management in smart grids [
30,
31,
32,
33].
In this paper, a combination of the TOPSIS method as introduced by Hwang and Yoon [
12], and the implementation described by Dutta et al. [
34] is applied for evaluation. The calculation steps are summarized as follows:
Step 2.1: Establishing an IAMS evaluation decision matrix.
The IAMS decision matrix,
S, is defined as below,
where
ai denotes the evaluated online manufacturing IAMSs,
bj represents the criterion evaluated in
the online manufacturing IAMSs,
i = 1, 2, ...,
m,
j = 1, 2, ...,
n, and
xij indicates the performance rating of an evaluated online manufacturing IAMS
ai with respect to criterion
bj.
Step 2.2: Data Normalization.
Data is transformed to a normalized scale as follows:
Step 2.3: Establishing a weighted normalization matrix
In the TOPSIS framework, the weighted normalized performance matrix is defined as
where
wj denotes the weight of criterion
j.
Step 2.4: Calculating the separation measures
To calculate the separation measures, which, in this study, characterize an IAMS’s proximity to optimal performance, the ideal solution is first calculated as follows
The distance between the ideal solution and the negative ideal solution for each alternative is then calculated as
Step 2.5: Calculating the relative closeness coefficient and rank the center preference order
The relative closeness to the ideal solution of each online manufacturing IAMSs can be calculated as:




{kind=link}