A Deep Learning-Based Method to Detect Components from Scanned Structural Drawings for Reconstructing 3D Models


Abstract
:1. Introduction
2. Literature Review
2.1. Traditional Methods for Components Recognition
2.2. Deep Learning Methods for Object Detection
2.3. Selection for Structural Component Detection
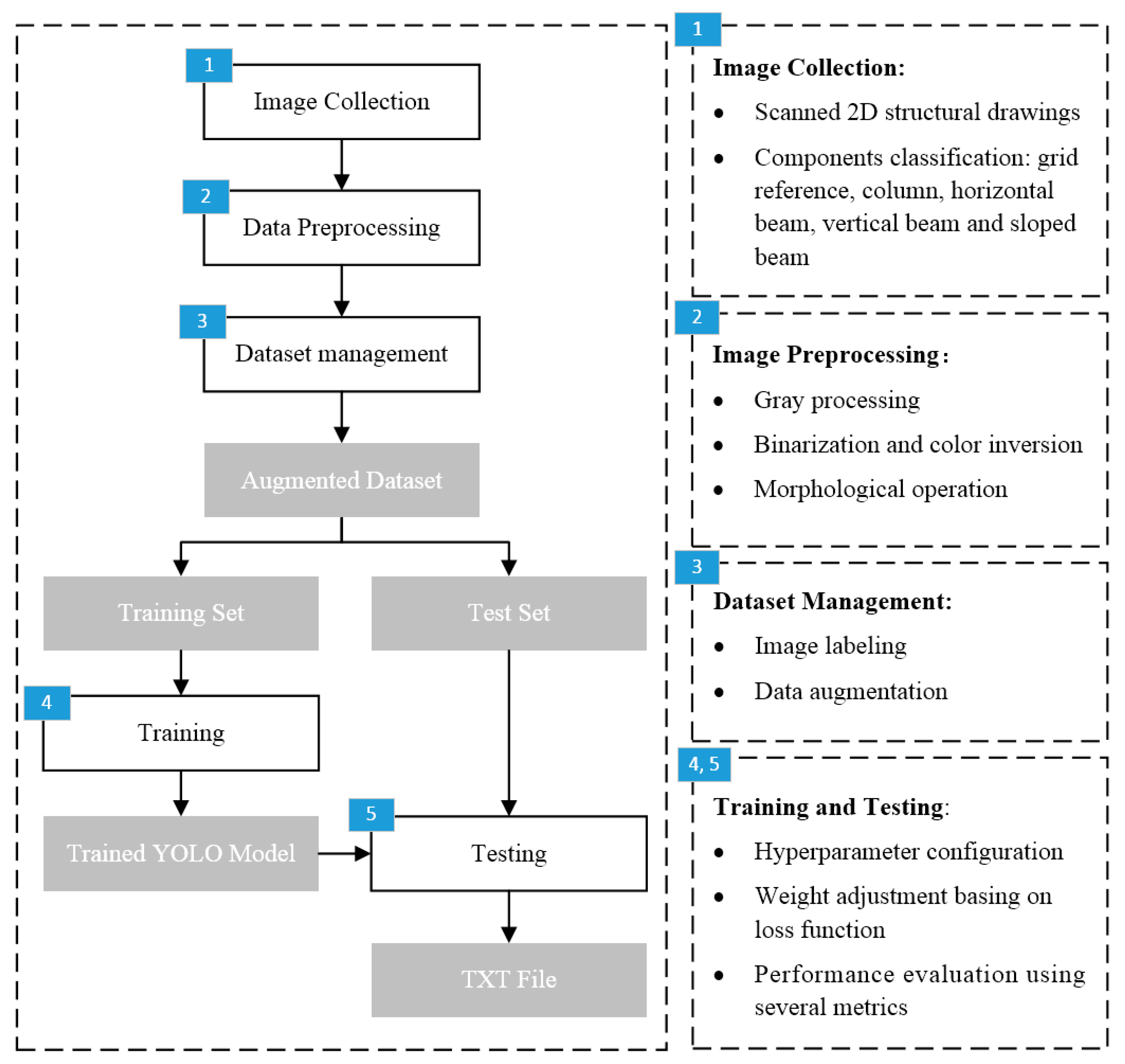
3. Methodology
3.1. Image Preprocessing
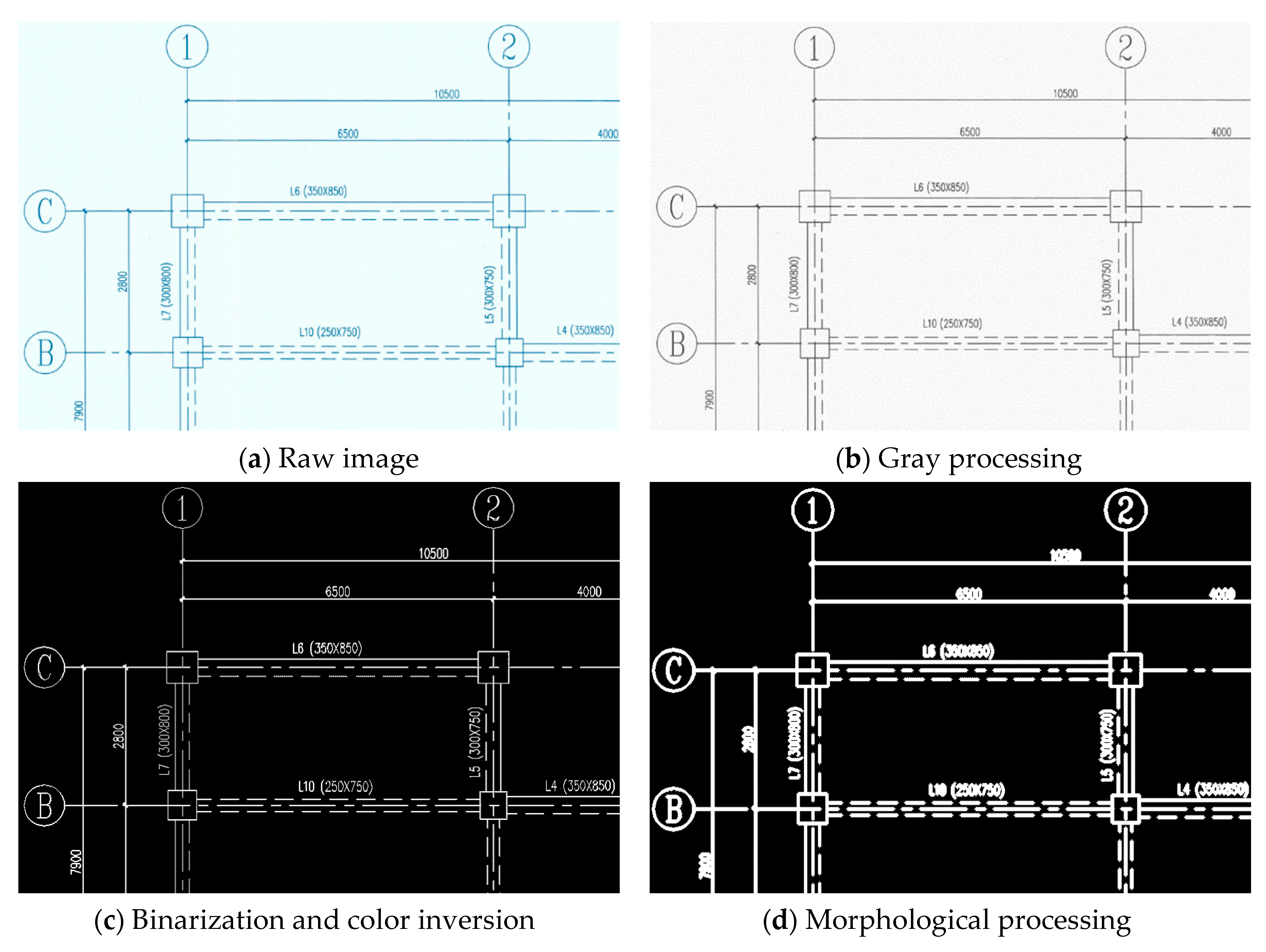
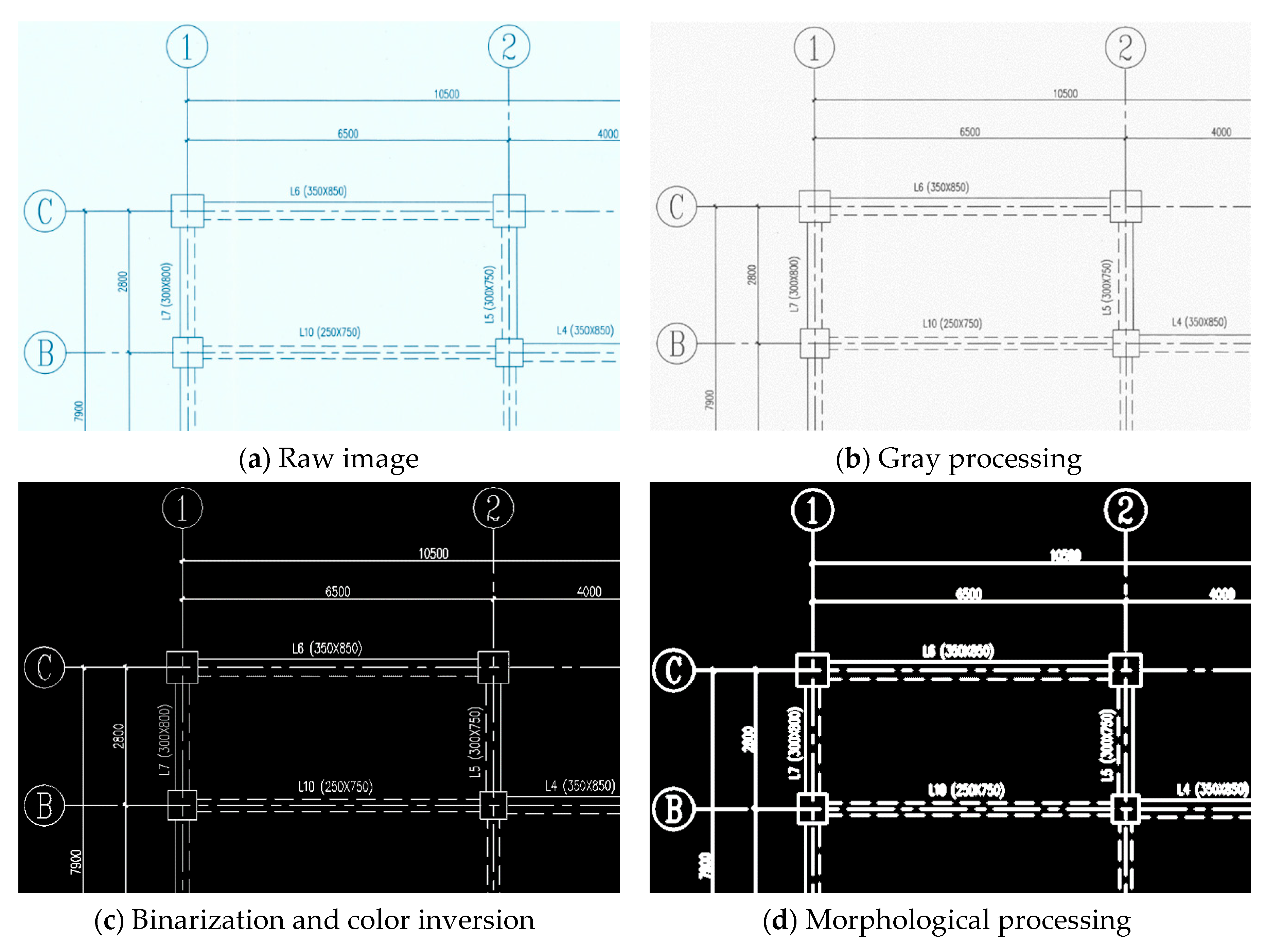
3.1.1. Gray Processing
3.1.2. Binarization and Color Inversion
3.1.3. Morphological Operation
3.2. YOLO for Structural Components Detection
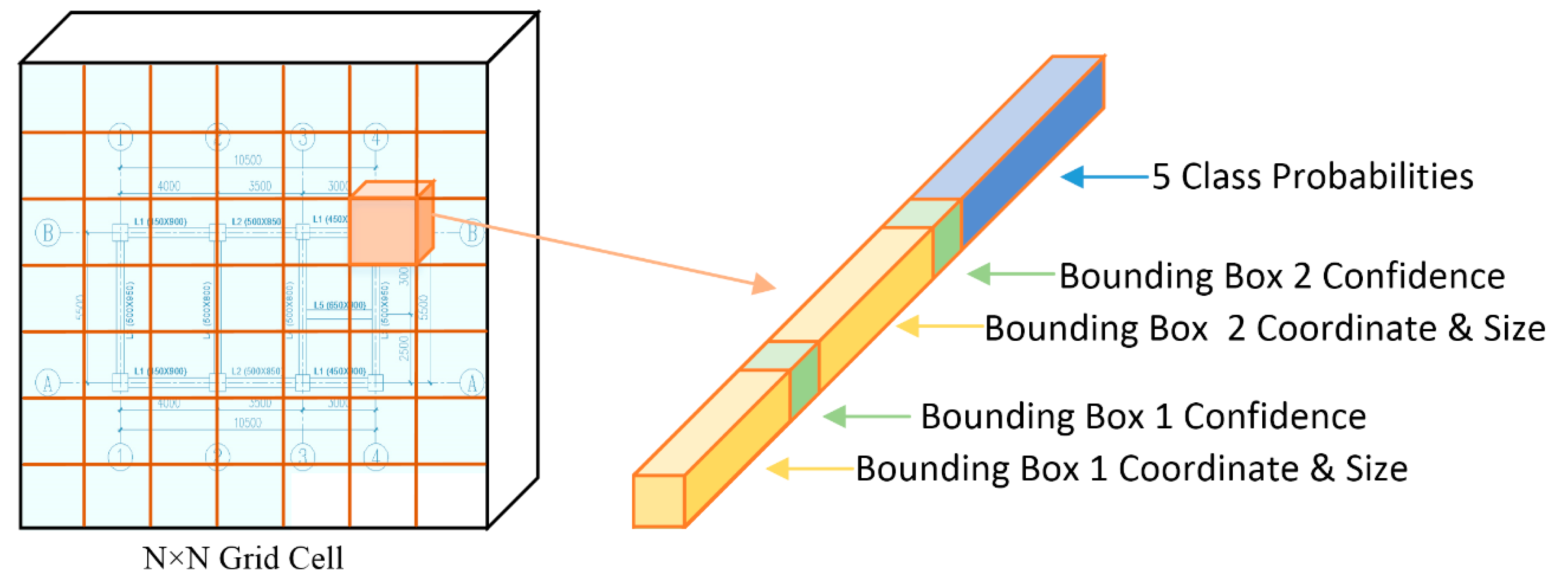
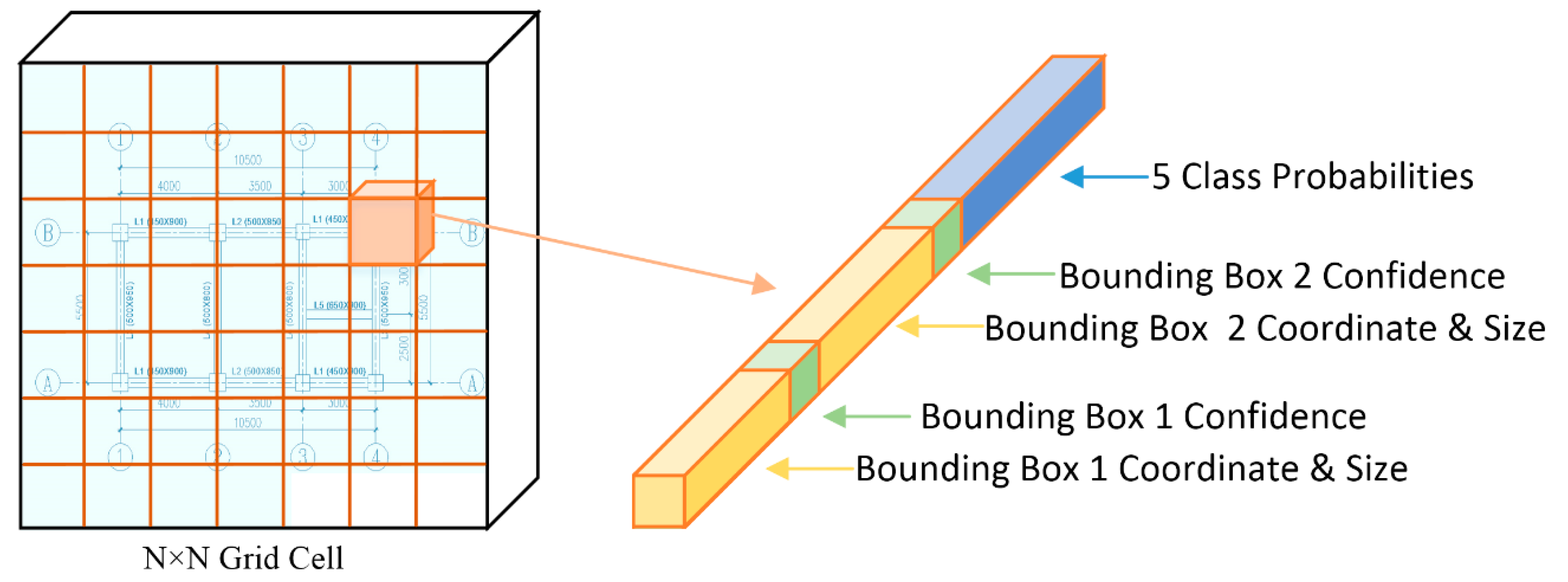
3.2.1. Architecture of YOLO
3.2.2. Loss Function
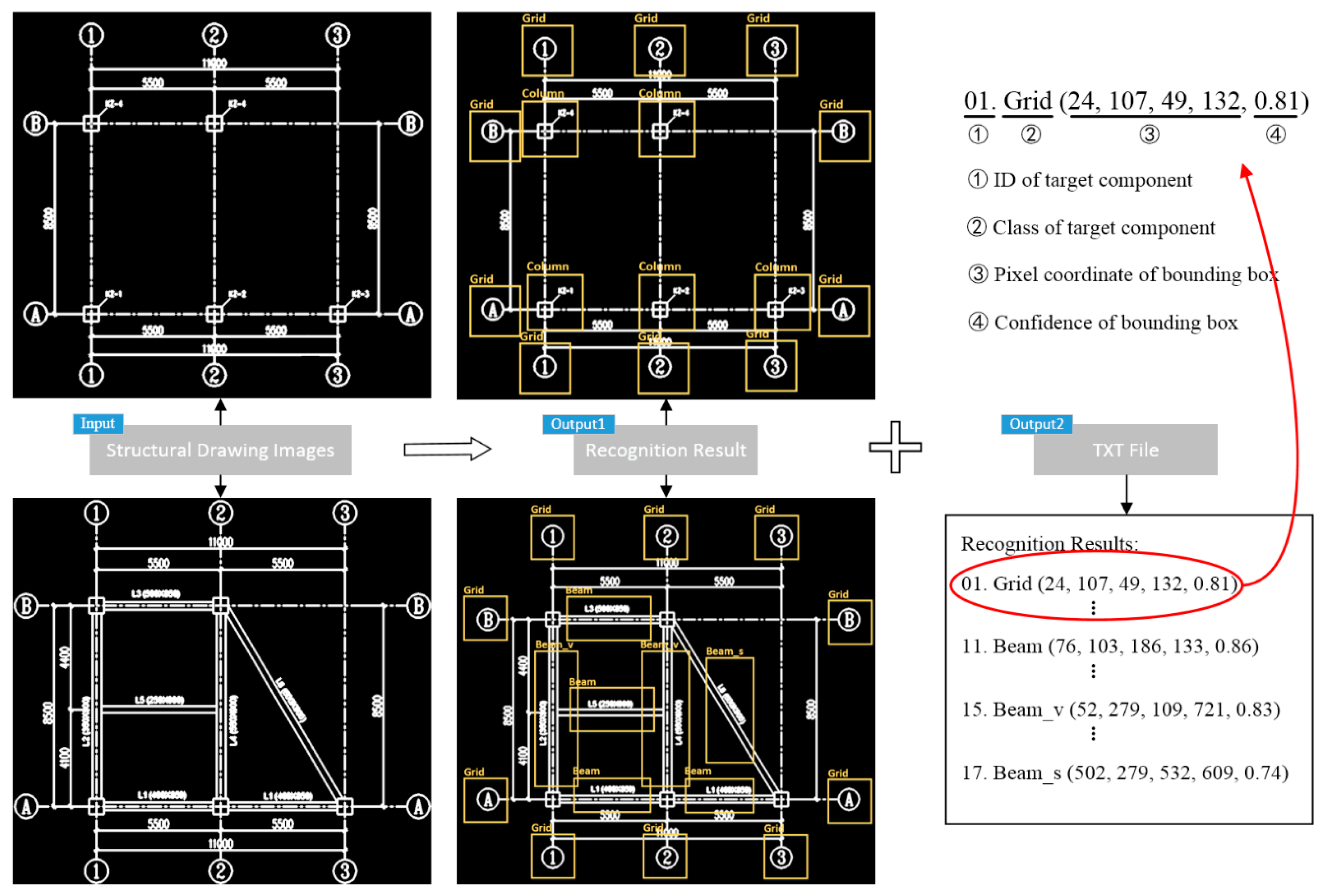
3.3. Detection Result Export
4. Experiment and Results
4.1. Data Preparation
4.1.1. Image Labeling
4.1.2. Data Augmentation
4.2. Experiment Design
4.2.1. Experiment Environment and Strategy
4.2.2. Dataset Division
4.2.3. Metrics for Performance Evaluation
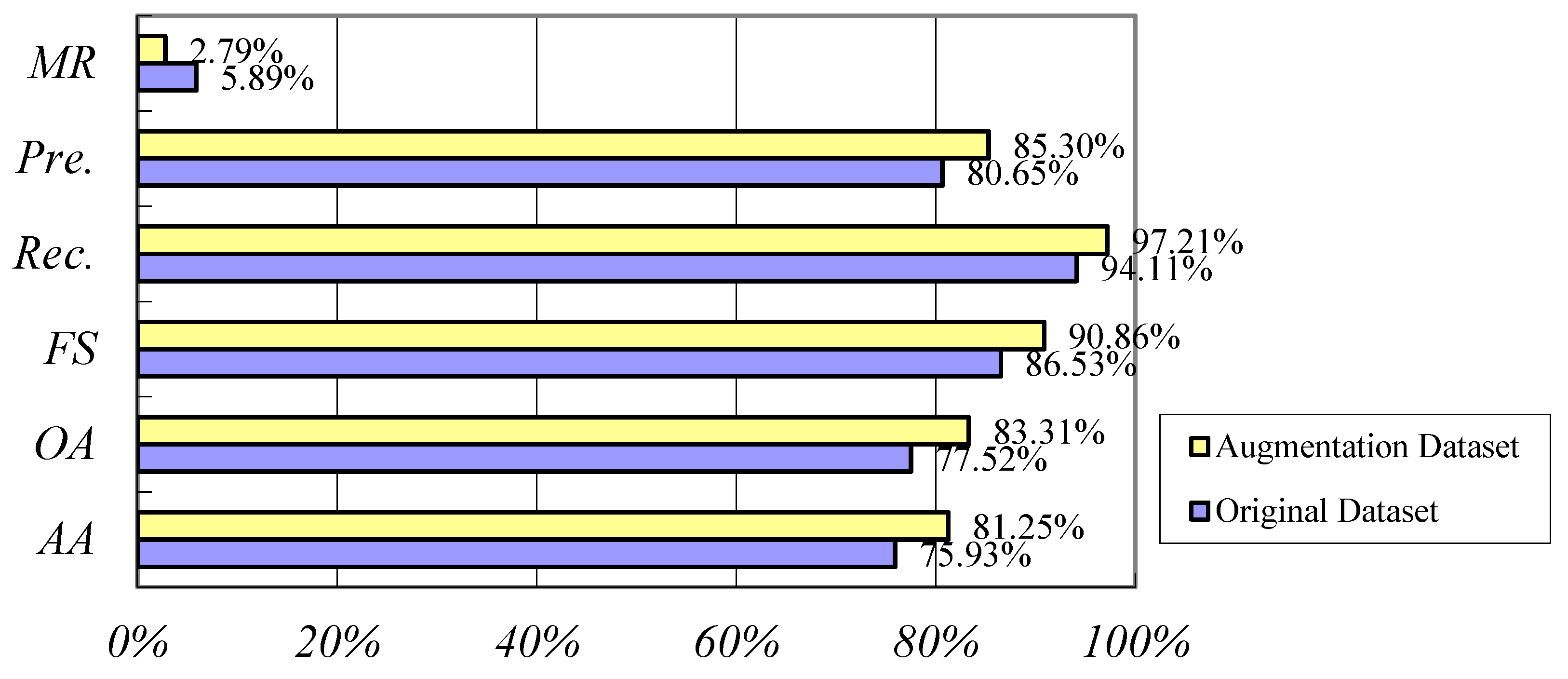
4.3. Experiment Results
5. Discussion
5.1. Accuracy-Influencing Factors Analysis
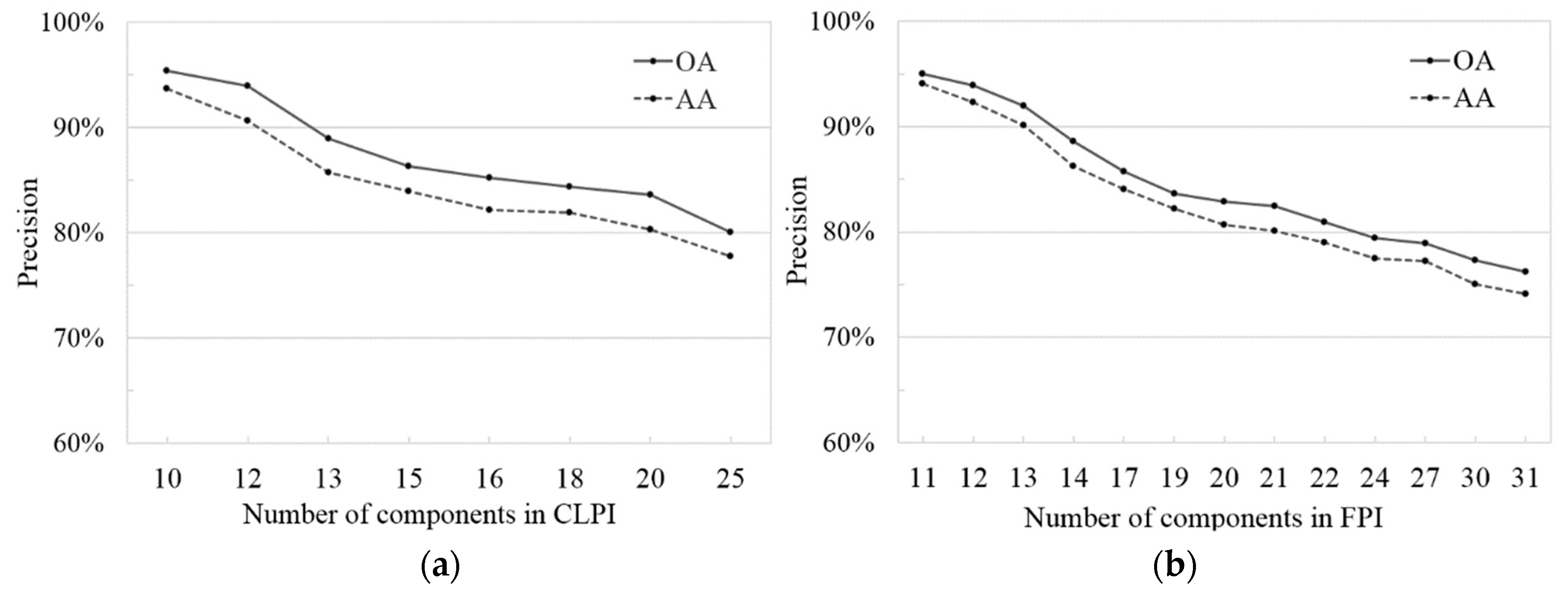
5.1.1. The Size of Dataset
5.1.2. The Number of Components in the Image
5.1.3. Other Factors
5.2. Error Analysis
6. Conclusions
- The experiment of component detection in this paper is focused on limited structural components (e.g., beam and column). To further improve the proposed method, more structural elements (such as floor, shear wall and pile) need to be tested in future research.
- More advanced YOLOv2 with batch normalization, high resolution classifier, anchor box, and multi-scale training will be tried. In addition, more sensitivity analysis will be conducted to study the influence of various accuracy-influencing factors on the final recognition results.
- Last but not least, as the first step to reconstruct BIM models for existing buildings, this study only solves the problem of extracting geometric information of structural components. How to extract topological and semantic information and match with the corresponding components will be the key research direction in the future.
Author Contributions
Funding
Conflicts of Interest
References
- Volk, J.; Stengel, J.; Schultmann, F. Building information modeling (BIM) for existing buildings—Literature review and future needs. Autom. Constr. 2014, 38, 109–127. [Google Scholar] [CrossRef] [Green Version]
- Becerik-Gerber, B.; Jazizadeh, F.; Li, N.; Calis, G. Application areas and data requirements for BIM-enabled facilities management. J. Constr. Eng. Manag. 2012, 138, 431–442. [Google Scholar] [CrossRef]
- Akcamete, A.; Akinci, B.; Garrett, J.H. Potential utilization of building information models for planning maintenance activities. In Proceedings of the 13th International Conference on Computing in Civil and Building Engineering, Nottingham, UK, 30 June–2 July 2010; pp. 8–16. [Google Scholar]
- Hu, Z.Z.; Peng, Y.; Tian, P.L. A review for researches and applications of BIM-based operation and maintenance management. J. Graph. 2015, 36, 802–810. [Google Scholar]
- Gimenez, L.; Hippolyte, J.; Robert, S.; Suard, F.; Zreik, K. Review: Reconstruction of 3d building in-formation models from 2d scanned plans. J. Build. Eng. 2015, 2, 24–35. [Google Scholar] [CrossRef]
- Li, J.; Huang, W.; Shao, L.; Allinson, N. Building recognition in urban environments: A survey of state-of-the-art and future challenges. Inf. Sci. 2014, 277, 406–420. [Google Scholar] [CrossRef]
- Tang, P.B.; Huber, D.; Akinci, B.; Lipman, R.; Lytle, A. Automatic reconstruction of as-built building information models from laser-scanned point clouds: A review of related techniques. Autom. Constr. 2010, 19, 829–843. [Google Scholar] [CrossRef]
- Cho, C.Y.; Liu, X. An automated reconstruction approach of mechanical systems in building infor-mation modeling (BIM) using 2d drawings. In Proceedings of the ASCE International Workshop on Computing in Civil Engineering 2017, Seattle, WA, USA, 25–27 June 2017; pp. 236–244. [Google Scholar]
- Gimenez, L.; Robert, S.; Suard, F.; Zreik, K. Automatic reconstruction of 3d building models from scanned 2D floor plans. Autom. Constr. 2016, 63, 48–56. [Google Scholar] [CrossRef]
- Huang, H.C.; Lo, S.M.; Zhi, G.S.; Yuen, R.K.K. Graph theory-based approach for automatic recognition of cad data. Eng. Appl. Artif. Intell. 2008, 21, 1073–1079. [Google Scholar] [CrossRef]
- Yin, X.; Wonka, P.; Razdan, A. Generating 3d building models from architectural drawings: A survey. IEEE Comput. Graph. Appl. 2008, 29, 20–30. [Google Scholar] [CrossRef]
- Klein, L.; Li, N.; Becerik-Gerber, B. Imaged-based verification of as-built documentation of operational buildings. Autom. Constr. 2012, 21, 161–171. [Google Scholar] [CrossRef]
- Dominguez, B.; Garcia, A.L.; Feito, F.R. Semiautomatic detection of floor topology from CAD architectural drawings. Comput. Aided Des. 2012, 44, 367–378. [Google Scholar] [CrossRef]
- Lu, Q.C.; Lee, S.; Chen, L. Image-driven fuzzy-based system to construct as-is IFC BIM objects. Autom. Constr. 2018, 92, 68–87. [Google Scholar] [CrossRef]
- Hough, P.V.C. Method and Means for Recognizing Complex Patterns. U.S. Patent 3,069,654, 18 December 1962. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-Invariant features. In Proceedings of the Seventh I-EEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 1150–1157. [Google Scholar]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Mukhopadhyay, P.; Chaudhuri, B.B. A survey of Hough Transform. Pattern Recognit. 2015, 48, 993–1010. [Google Scholar] [CrossRef]
- Ballard, D.H. Generalizing the Hough Transform to detect arbitrary shapes. Pattern Recognit. 1981, 13, 111–122. [Google Scholar] [CrossRef]
- Galambos, C.; Kittler, J.; Matas, J. Gradient based progressive probabilistic Hough Transform. IEE Proc. Vis. Image Signal Process. 2001, 148, 158. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Oja, E.; Kultanen, P. A new curve detection method: Randomized Hough transform (RHT). Pattern Recognit. Lett. 1990, 11, 331–338. [Google Scholar] [CrossRef]
- Kiryati, N.; Lindenbaum, M.; Bruckstein, A.M. Digital or analog hough transform? Pattern Recognit. Lett. 1991, 12, 291–297. [Google Scholar] [CrossRef] [Green Version]
- Izadinia, H.; Sadeghi, F.; Ebadzadeh, M.M. Fuzzy generalized hough transform invariant to rotation and scale in noisy environment. In Proceedings of the IEEE International Conference on Fuzzy Systems, Jeju Island, Korea, 20–24 August 2009; pp. 153–158. [Google Scholar]
- Dosch, P.; Tombre, K.; Ah-Soon, C.; Masini, G. A complete system for the analysis of architectural drawings. Int. J. Doc. Anal. Recognit. 2000, 3, 102–116. [Google Scholar] [CrossRef]
- Mace, S.; Locteau, H.; Valveny, E.; Tabbone, S. A system to detect rooms in architectural floor plan images. In Proceedings of the Ninth IAPR International Workshop on Document Analysis Systems, Boston, MA, USA, 9–11 June 2010; pp. 167–174. [Google Scholar]
- Ahmed, S.; Liwicki, M.; Weber, M.; Dengel, A. Improved automatic analysis of architectural floor plans. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 864–869. [Google Scholar]
- Riedinger, C.; Jordan, M.; Tabia, H. 3D models over the centuries: From old floor plans to 3D representation. In Proceedings of the 2014 International Conference on 3D Imaging, Liege, Belgium, 9–10 December 2014; pp. 1–8. [Google Scholar]
- Lu, T.; Yang, H.F.; Yang, R.Y.; Cai, S.J. Automatic analysis and integration of architectural drawings. Int. J. Doc. Anal. Recognit. 2007, 9, 31–47. [Google Scholar] [CrossRef]
- Lu, Q.C.; Lee, S. A semi-automatic approach to detect structural components from CAD drawings for constructing as-Is BIM objects. In Proceedings of the ASCE International Workshop on Computing in Civil Engineering 2017, Seattle, WA, USA, 25–27 June 2017; pp. 84–91. [Google Scholar]
- Fang, Q.; Li, H.; Luo, X.C.; Ding, L.Y.; Luo, H.B.; Rose, T.M.; An, W.P. Detecting non-hardhat-use by a deep learning method from far-field surveillance videos. Autom. Constr. 2018, 85, 1–9. [Google Scholar] [CrossRef]
- Fang, Q.; Li, H.; Luo, X.C.; Ding, L.Y.; Luo, H.B.; Li, C. Computer vision aided inspection on falling prevention measures for steeplejacks in an aerial environment. Autom. Constr. 2018, 93, 148–164. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Li, B.X.; Yang, E.; Dai, X.X.; Yi, P.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated pixel-level pavement crack detection on 3d asphalt surfaces using a deep-learning network. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Wu, D.; Pigou, L.; Kindermans, P.J.; Le, N.D.H.; Shao, L.; Dambre, J.; Odobez, J.M. Deep dynamic neural networks for multimodal gesture segmentation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1583–1597. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gangwar, A.; Joshi, A. DeepIrisNet: Deep iris representation with applications in iris recognition and cross-sensor iris recognition. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Hu, C.; Bai, X.; Qi, L.; Chen, P.; Xue, G.; Mei, L. Vehicle color recognition with spatial pyramid deep learning. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2925–2934. [Google Scholar] [CrossRef]
- Saxena, S.; Verbeek, J. Heterogeneous face recognition with CNNs. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–491. [Google Scholar]
- Kong, Y.; Ding, Z.; Li, J.; Fu, Y. Deeply learned view-invariant features for cross-view action recognition. IEEE Trans. Image Process. 2017, 26, 3028–3037. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.R.; Sande, K.E.A.; Gevers, T. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 1904–1916. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with re-gion proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2014, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Yang, H.; Zhou, X. Deep learning-based ID card recognition method. China Comput. Commun. 2016, 21, 83–85. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2008. [Google Scholar]
- Neubeck, A.; Gool, L.V. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- LabelImg. Available online: https://github.com/tzutalin/labelImg (accessed on 15 October 2019).
- Opencv. Available online: https://opencv.org (accessed on 20 December 2019).
- Hoiem, D.; Chodpathumwan, Y.; Dai, Q. Diagnosing error in object detectors. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Name | Filter | Kernel Size/ Stride | Layer | Name | Filter | Kernel Size/ Stride |
|---|---|---|---|---|---|---|---|
| 0 | Covn.1 | 64 | 7 × 7 / 2 | 15 | Conv.13 | 256 | 1 × 1 / 1 |
| 1 | Maxp.1 | / | 2 × 2 / 2 | 16 | Covn.14 | 512 | 3 × 3 / 1 |
| 2 | Covn.2 | 192 | 3 × 3 / 1 | 17 | Covn.15 | 512 | 1 × 1 / 1 |
| 3 | Maxp.2 | / | 2 × 2 / 2 | 18 | Covn.16 | 1024 | 3 × 3 / 1 |
| 4 | Covn.3 | 128 | 1 × 1 / 1 | 19 | Maxp.4 | / | 2 × 2 / 2 |
| 5 | Covn.4 | 256 | 3 × 3 / 1 | 20 | Covn.17 | 512 | 1 × 1 / 1 |
| 6 | Covn.5 | 256 | 1 × 1 / 1 | 21 | Covn.18 | 1024 | 3 × 3 / 1 |
| 7 | Covn.6 | 512 | 3 × 3 / 1 | 22 | Covn.19 | 512 | 1 × 1 / 1 |
| 8 | Maxp.3 | / | 2 × 2 / 2 | 23 | Covn.20 | 1024 | 3 × 3 / 1 |
| 9 | Covn.7 | 256 | 1 × 1 / 1 | 24 | Covn.21 | 1024 | 3 × 3 / 1 |
| 10 | Covn.8 | 512 | 3 × 3 / 1 | 25 | Covn.22 | 1024 | 3 × 3 / 2 |
| 11 | Covn.9 | 256 | 1 × 1 / 1 | 26 | Covn.23 | 1024 | 3 × 3 / 1 |
| 12 | Covn.10 | 512 | 3 × 3 / 1 | 27 | Covn.24 | 1024 | 3 × 3 / 1 |
| 13 | Covn.11 | 256 | 1 × 1 / 1 | 28 | Conn.1 | / | / |
| 14 | Covn.12 | 512 | 3 × 3 / 1 | 29 | Conn.2 | / | / |
| Dataset | Total | Training | Testing |
|---|---|---|---|
| Original | 500 | 400 | 100 |
| Augmented | 1500 | 1200 | 300 |
| Type | Predicted Objects | Actual Objects |
|---|---|---|
| TP | √ | √ |
| FP | √ | × |
| FN | × | √ |
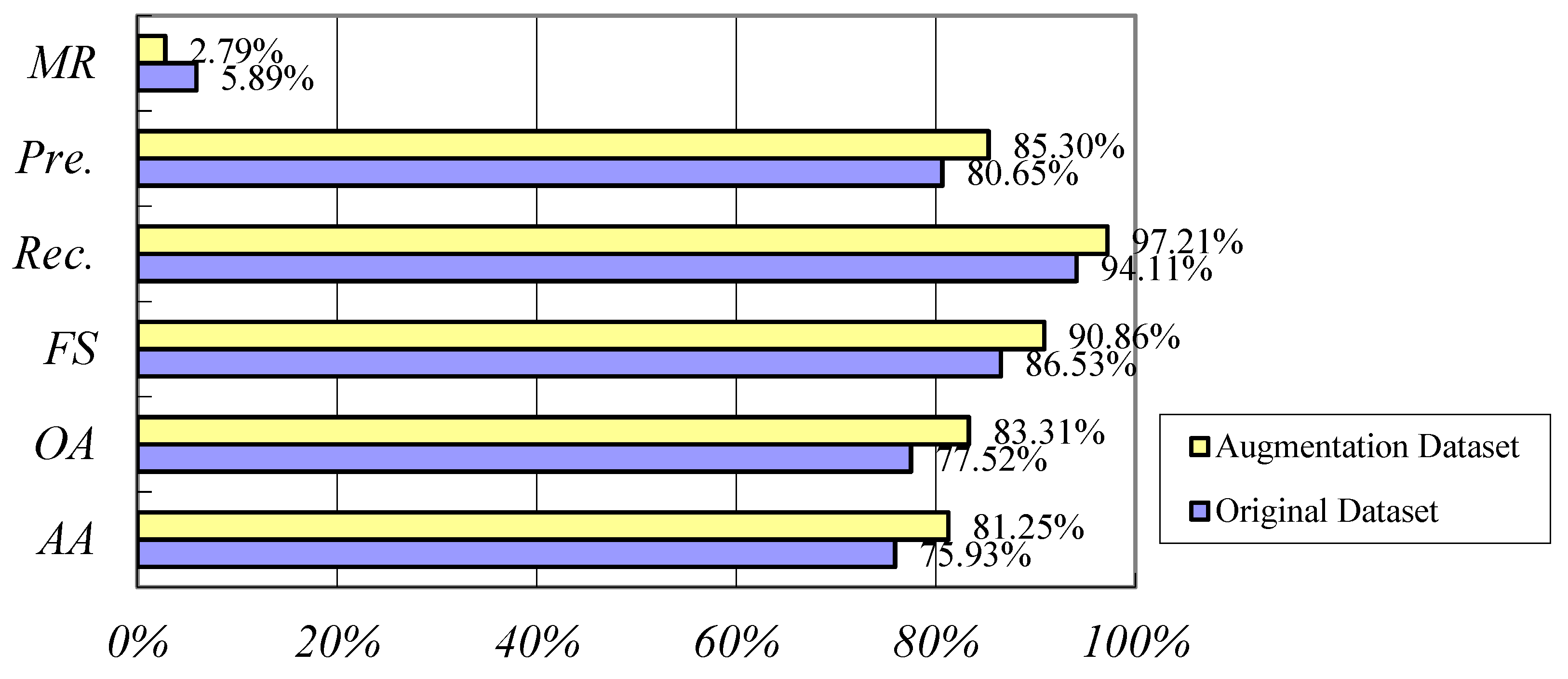
| TP | FP | FN | Pre. | Rec. | MR | FS | |
|---|---|---|---|---|---|---|---|
| Grid | 2967 | 467 | 25 | 86.41% | 99.16% | 0.84% | 92.35% |
| Column | 833 | 158 | 17 | 84.03% | 98.04% | 1.96% | 90.50% |
| Beam | 517 | 108 | 50 | 82.67% | 91.18% | 8.82% | 86.71% |
| Beam_v | 500 | 100 | 42 | 83.33% | 92.31% | 7.69% | 87.59% |
| Beam_s | 125 | 17 | 8 | 88.24% | 93.75% | 6.25% | 90.91% |
| TD | TA | OA | AA | Speed | |
|---|---|---|---|---|---|
| Grid | 3459 | 3125 | 85.78% | 82.67% | - |
| Column | 1008 | 925 | 82.64% | 80.18% | - |
| Beam | 675 | 583 | 76.54% | 77.14% | - |
| Beam_v | 642 | 583 | 77.92% | 78.57% | - |
| Beam_s | 150 | 142 | 83.33% | 85.00% | - |
| Average | 2338 | 2113 | 83.31% | 81.25% | 0.71 s |
| Correct | Localization | Background | Similarity | Classification | Missing | |
|---|---|---|---|---|---|---|
| Average | 69.54% | 10.09% | 8.03% | 5.65% | 2.26% | 4.43% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Deng, X.; Lai, H. A Deep Learning-Based Method to Detect Components from Scanned Structural Drawings for Reconstructing 3D Models. Appl. Sci. 2020, 10, 2066. https://doi.org/10.3390/app10062066
Zhao Y, Deng X, Lai H. A Deep Learning-Based Method to Detect Components from Scanned Structural Drawings for Reconstructing 3D Models. Applied Sciences. 2020; 10(6):2066. https://doi.org/10.3390/app10062066
Chicago/Turabian StyleZhao, Yunfan, Xueyuan Deng, and Huahui Lai. 2020. "A Deep Learning-Based Method to Detect Components from Scanned Structural Drawings for Reconstructing 3D Models" Applied Sciences 10, no. 6: 2066. https://doi.org/10.3390/app10062066
APA StyleZhao, Y., Deng, X., & Lai, H. (2020). A Deep Learning-Based Method to Detect Components from Scanned Structural Drawings for Reconstructing 3D Models. Applied Sciences, 10(6), 2066. https://doi.org/10.3390/app10062066