1. Introduction
Automatic hand posture recognition is an important research topic in computer science [
1]. The overall goal is to understand the body language and then create more functional and efficient human–computer interfaces. Application areas are vast; from driver support via hand-controlled cockpit elements [
2], through to home automation with consumer electronics driven by gestures [
3], gaming industry applications [
4], interaction with virtual objects [
5], and finally, technological support for people with disabilities [
6]. Solutions available on the market are either limited, very simple, or have background and illumination requirements that are difficult to meet in real-life scenarios. Therefore, it is desirable to continue research on the automatic interpretation of hand gestures.
Available approaches can be divided into two groups: (i) using special gloves with sensors [
7] or cameras and (ii) computer vision methods [
8]. Vision-based solutions seem to be more attractive because they are more comfortable, do not require any additional equipment limiting the user’s freedom of movement, mimic natural interaction, and avoid stigmatization. However, building a reliable vision-based system is quite a challenge. Color-based methods, frequently used to segment hands, fail in the cases of complex backgrounds containing other skin-colored objects or users wearing short-sleeved clothing [
9]. It is also very difficult to achieve the color constancy under varying scene illumination. Fortunately, new depth-sensing devices recently appeared in the market. They combine the visible and near-infrared part of the spectrum to obtain good quality depth maps. Some of them, based on time-of-flight principle, can even work in a completely dark room.
Therefore, in recent literature on hand gestures recognition, a shift to depth modality has been observed [
10]. The new devices can acquire good quality 3D data, which can be then used to extract the hand skeleton containing information about the spatial configuration of bones corresponding to fingers. The main advantage of skeletal data—compared to images, point clouds, and depth maps—is its small size. The features calculated based on skeletons can also be a good addition to typical image-based or depth-based features. We can also expect that there will be more and more accurate devices providing this type of data. Therefore, there is a need to develop new recognition algorithms based on hand skeletons.
In this paper, a problem of hand posture recognition based on skeletal data extracted by a depth sensor was tackled. The method is based on a novel hand descriptor combined with another one that was previously developed. The experimental tests were performed using four different classification methods and a proposed modification of the nearest neighbor classifier.
The main contributions of this paper are as follows:
The novel hand descriptor encoding information about distances between selected hand points;
The modified nearest neighbor classifier, suitable for posture recognition in the case where some of the classes differ mostly in hand orientation;
Experimental verification of the proposed methods using challenging datasets.
The remaining parts of this paper are organized as follows. The related works are characterized in
Section 2. The proposed hand posture recognition method is presented in
Section 3.
Section 4 discusses the used datasets and performed experiments.
Section 5 concludes the paper.
2. Related Work
One of the devices that can be used to obtain skeletal data for hands is the Leap Motion (LM) sensor [
11]. In literature, there are several works devoted to the study of its usefulness for gesture recognition. In [
12], the authors estimated the accuracy and repeatability of hand position measurement and found that this sensor outperforms competitive solutions with a similar price range. In [
13], the sensor’s usefulness for recognizing Australian Sign Language was assessed. Hand shapes for which the sensor does not work were identified. The authors concluded that the solution has great potential, but requires refining the API. In [
14], the usefulness of the device for hand tracking was assessed. The authors noticed that further development of the sensor is needed to implement professional systems.
It is expected that sensors for the acquisition of hands skeletal data will be improved soon. Therefore, work is underway to use them to recognize sign languages: American [
15,
16,
17,
18,
19,
20,
21,
22,
23,
24], Arabic [
25,
26,
27,
28], Australian [
13], Indian [
29,
30,
31], Mexican [
32], Pakistani [
33], and Polish [
34].
In [
15], a subset of hand shapes from the American Finger Alphabet was recognized using features based on skeletal data: angle, distance, and elevation of the fingertips. The support vector machine (SVM) classifier was used. The recognition rate was 80.88%. After adding features obtained with the Kinect sensor—curvature and correlation—recognition efficiency increased to 91.28%.
The 26 letters of the American Finger Alphabet, shown by two people, were also recognized in [
16]. The feature vector consisted of pinch strength, grab strength, average distance, spread and tri-spread between fingertips, determined from skeletal data. The recognition rate was 72.78% for the nearest neighbor (kNN) classifier and 79.83% for SVM.
In [
25], 28 letters of the Arabic Finger Alphabet were recognized using 12 of 23 values measured by the LM sensor: finger length; finger width; average tip position with respect to
x,
y, and
z-axis; hand sphere radius; palm position with respect to
x,
y, and
z-axis; hand pitch, roll, and yaw. A 98% recognition rate was obtained for the Naive Bayes classifier, while it was 99% for Multilayer Perceptron.
Ten static hand shapes shown by 14 users were recognized in [
18]. The following features were used: fingertip angles, distances, elevations, and positions. For the SVM classifier, the recognition rate was 81.5%. After adding features obtained from the Kinect’s depth image, the recognition rate increased to 96.5%.
The Indian Finger Alphabet letters from A to Z and the numbers from 1 to 9, shown by ten users, were recognized in [
29]. The feature vector consisted of the following distances: the fingertips—the middle of the palm, the index—the middle finger, the index—the ring finger, and the index—the little finger. For the kNN classifier, a recognition efficiency of 88.39% for the Euclidean metric and 90.32% for the cosine distance was obtained.
In [
28], two LM controllers were used to prevent the individual fingers from being obstructed. The 28 letters of Arabic Finger Alphabet were recognized. The feature vector was a concatenation of the following features measured by two controllers: finger length; finger width; average tip position with respect to
x,
y, and
z-axis; hand sphere radius; palm position with respect to
x,
y, and
z-axis; hand pitch, roll, and yaw. The Linear Discriminant Analysis classifier was used. The recognition rate of 97.7% for a fusion of features and 97.1% for a fusion of classifiers was obtained.
Ten static hand shapes that can be used for rehabilitation after cerebral palsy were recognized in [
35]. Features determined by the LM controller and three classification methods; decision tree, kNN, and SVM, were used. The obtained recognition rates of individual gestures ranged from 76.96% to 100%.
In [
20], 26 letters of the American Finger Alphabet were recognized. The features measured by the LM controller and the Multilayer Perceptron (MLP) classifier were used. A recognition rate of 96.15% was achieved.
Forty-nine static gestures (twenty-six letters of the alphabet, ten numbers, and nine words) of Indian Sign Language were recognized in [
31]. The feature vector was composed of the distances between the middle of the hand and the fingertips. The kNN classifier with four different measures of similarity: Euclidean distance measure, cosine similarity, Jaccard similarity, and Dice similarity was used. For gestures performed by ten people, recognition rates ranging from 83.11% to 90% were obtained.
In [
27], forty-four static gestures (twenty-eight letters, ten numbers, and sixteen words) from the Arabic Sign Language were recognized. Two variants of the feature vector consisting of 85 and 70 scalar values measured by the LM controller were considered. The training set consisted of 200 performances of each gesture by two people. Tests were carried out on 200 executions of individual gestures by a third person. Three variants of the classifier were considered: SVM, kNN, and artificial neural network (ANN). The best recognition rate of 99% was obtained for the kNN classifier and the first considered feature vector variant.
Twenty-six letters and ten numbers of the American Finger Alphabet were recognized in [
23]. Six different combinations of the following features were considered: standard deviation of palm position, palm curvature radius, the distance between the palm center and each fingertip, and the angle and distance between two adjacent fingertips. For gestures performed by twelve people and leave-one-subject-out protocol, the recognition rate was 72.79% for SVM and 88.79% for the deep network.
The 24 characters of the American Finger Alphabet shown by five people were recognized in [
24]. Skeletal data in the form of angles between adjacent bones of the same finger and angles between adjacent fingers were used, as well as infrared images obtained with an LM sensor. For the classifier based on deep networks and leave-one-subject-out protocol, a recognition rate of 35.1% was obtained.
In [
34], 48 static hand shapes from the Polish Finger Alphabet and Polish Sign Language were recognized. Gestures were shown 500 times by five users. Two different positions of the LM sensor and changes in the orientation of the hand were considered. Several classifiers, as well as their fusion, were tested. For the leave-one-subject-out protocol, the best recognition rate was 56.7%.
Twenty-four static gestures of the American Finger Alphabet, shown ten times by twelve people, were recognized in [
22]. Features based on the skeletal data returned by the LM controller were used. The classification was carried out using hidden Markov models. For the leave-one-subject-out protocol, the recognition rate was 86.1%.
In [
21], 12 dynamic and 18 static gestures of American Sign Language, shown by 20 people, were recognized. The feature vector was composed of the following: the internal angles of the joints between distal and intermediate phalanges, and intermediate and proximal phalanges; 3D displacements of the central point of the palm; 3D displacements of the fingertip positions; and the intrafinger angles. Recursive neural networks were used for the classification. The recognition rate was 96%.
The problem of fingers occlusion, occurring when performing gestures, was considered in [
36]. For this purpose, three LM controllers were used. The feature vector consisted of a hand rotation matrix,
y-component of the fingers directions, and distal phalanges rotation quaternion. Three classification methods available in the scikit-learn library were tested: logistic regression, SVC, and XGBClassifier. An 89.32% recognition rate was obtained for six selected hand gestures.
In [
37], letters from the Israeli Sign Language (ISL) alphabet were recognized using the SVM classifier and feature vector consisting of the Euclidean distances between the fingertips and the center of the palm. The training dataset consisted of six letters performed 16 times by eight users. A system was able to translate fingerspelling into a written word with a recognition accuracy between 85%–92%.
The challenging problem of fistlike signs recognition, occurring in ASL, was described in [
38]. In the proposed method, the area of several polygons defined by fingertip and palm positions, and estimated using the Shoelace formula, was used. The letters from the ASL alphabet were classified using the decision trees (DT). Seven letters performed 30 times by four persons were used as a training set. For 100 repetitions of each gesture by another user, the method achieved the recognition accuracy of 96.1%.
In [
39], static hand postures recognition for a humanlike robot hand was described. Ten digits from ASL were recognized using the multiclass-SVM classifier. The feature vector consisted of the distances between the palm position and each fingertip and the distance between fingertips. The method was validated using a test dataset composed of 2000 static posture samples with an accuracy of 98.25%.
In [
40], five one-handed and five two-handed static gestures of Turkish Sign Language, performed three times by two users, were recognized using artificial neural networks, deep learning, and decision trees. The 3D positions of all bones in the skeletal hand model, measured by the LM controller, were used. The recognition accuracies between 93% and 100% were achieved, depending on the classifier and the number of features used.
In [
41], a deep-learning-based method for skeleton-based hand gesture recognition was described. The network architecture consists of a convolutional layer for extracting features and a long, short-term memory layer for modeling the temporal dimension. Ten static and ten dynamic hand gestures performed 30 times were recognized with an accuracy of 99%.
Based on the literature review, the following conclusions can be drawn:
Despite that the currently available devices for obtaining skeletal data are imperfect, we have recently observed a significant increase in interest of using this modality for gesture recognition. In the last two years, several new publications were recorded.
Most authors do not provide data used in experiments, which makes verification and comparative analysis difficult. Only three datasets available in works [
15,
18,
24,
34] are known to the authors.
Many cited works omit tests using the leave-one-subject-out protocol. These tests are more reliable because they show the method’s dependence on the person performing gestures.
Some of the proposed feature vectors use features directly measured by the sensor. They are not independent of the size of the hand.
Some of the works relate to the recognition of dynamic gestures, in which the hand movement trajectory is a great help.
The problem of recognizing hand postures based on skeletal data has not been fully solved, and further work in this area is advisable.
5. Conclusions
Hand posture recognition is a classical task in computer vision [
1,
6,
8]. Despite many methods, which perform robustly under some limitations, the problem is still exciting. Challenging barriers persist while creating a recognition system able to function in real-world conditions. The most important among them are occlusion of fingers related to the presence of affine transformation while projecting the 3D scene on the 2D image plane, scalability of considered gesture dictionaries, different background illumination, high computational cost, and repeatability of gesture execution by potential users. Currently, new devices working in the field of visible and near-infrared light are being developed, which will allow us to obtain accurate 3D information about the observed scene. There is a chance that the usage of these devices will eliminate some of the restrictions mentioned above. Therefore, in recent literature on hand gesture recognition, a shift to depth modality is observed. In this paper, a novel descriptor was proposed, which encodes information about distances between particular hand points. It is a scale-independent and distinctive alternative to other positional-based and distance-based features describing hand skeleton. Its features include relations between each fingertip and between fingertips and palm center. Unlike most other works, the method has been tested on a data set containing 48 classes, among which many similar shapes can be identified. It has been observed that the independence of the proposed approach from hand orientation is not always desirable and can lead to difficulties in recognizing some hand configurations. Therefore, a modified version of the nearest neighbor classifier was proposed, which can distinguish between very similar or identical postures, differing only in hand orientation. The n-fold cross-validation tests were performed on three challenging datasets. For each dataset, the leave-one-subject-out protocol was used, which usually gives the worst results, but is the most trustworthy. It shows how the method deals with different gesture performances by individual users. The experimental results were compared with our previous work as well as with other methods found in the literature. A significant improvement of results over the compared methods was observed.
Summarizing, we did not find any methods for static hand posture recognition based only on hand skeletal data, with which we can compare our methods (mainly because of publicly available datasets) and which are better than our method in terms of recognition rate.
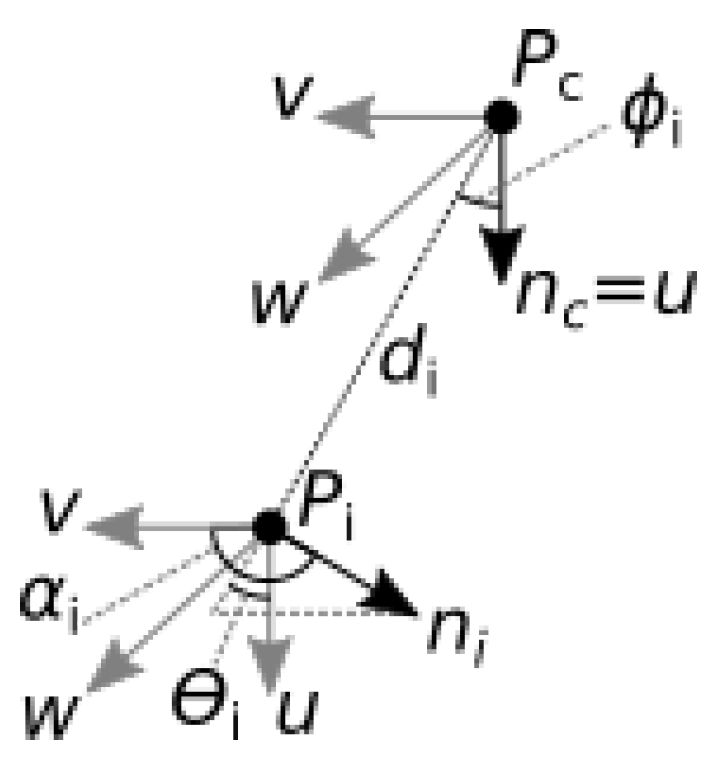
The proposed Distance Descriptor is invariant to position and scale. It is also invariant to rotation. However, this feature is desirable only for datasets not containing classes that differ only in orientation. Using the proposed nearest neighbor classifier with orientation restriction makes the recognition method partially dependent on orientation, enabling it to distinguish between such gestures. The threshold parameter has to be experimentally set based on the orientation of similar postures of the considered sign language; it should be less than the least angle between palm normals of any similar postures classes. However, it also cannot be too small, since that would make the recognition method too strongly dependent on hand orientation. It is worth noting that descriptors and features proposed in the literature are not always invariant to hand size and orientation.
The features of PPD contain the information about angular relations of skeletal joints. The information of DD features is positional and relies on distance between the joints. The results from
Table 3 and
Table 5 show that the angular information of PPD and the positional information of DD complement each other, since the addition of DD to PPD features significantly improved the recognition rate.
The most commonly confused hand postures of the Dataset 1 are B-Bm, C-100, S-F, T-O, Z-Xm, Bz-Cm, and 4z-Cm. These postures are shown in pairs in
Figure 3 Most of these hand-shapes are very similar, even for the human eye.
The proposed recognition method is fast and does not require a specific background, lighting conditions, or any special outfit—e.g., gloves. The main reason for the weaker results of leave-one-subject-out tests is the imperfection of the sensor, which has issues with proper detection of occluding fingers. Therefore, further work may include obtaining more accurate and reliable hand skeletal data using two calibrated depth sensors. Another future study topic may be recognition of letter sequences (finger spelling), understood as quick, highly coarticulated motions. Finally, the developed PPD and DD descriptors can be adopted in a method for recognition of human actions based on whole-body skeletons (e.g., obtained from Kinect camera).






{kind=link}
{kind=link}
{kind=link}