1. Introduction
Due to the proliferation of Artificial Intelligence (AI), the Internet of Things (IoT), Social Network Services (SNS), and e-health, a huge amount of data is generated, integrated and aggregated for the decision making process [
1]; however, the quality of the data is questionable, along with associated risks [
2,
3]. It has been estimated that 40% of the expected value from business targets could not be achieved due to the bad data quality, and it affects 20% on the productivity of laborers [
4]. In the article [
5], it is mentioned that 70% of participants reveal that their business faced hardships due to poor data quality. The data produced and used in the organizations contain 1–5% of poor data quality [
6]. This may be one of the reasons that organizations face hardship and could not be able to sustain the business for a longer duration. According to the estimation done by the International Data Corporation (IDC) that the big data market will increase to 136 billion per year and the bad data cost can also be increased with the same speed [
7]. The 2016 Harvard business review report indicates that the knowledge workers waste 50% time in data hunting and fixing of errors. Similarly, data scientist spends 60% of their time on the cleaning and organization of data [
8]. Therefore, the quality of data is important for the organizations and it should be checked and measured before using it in the applications and services.
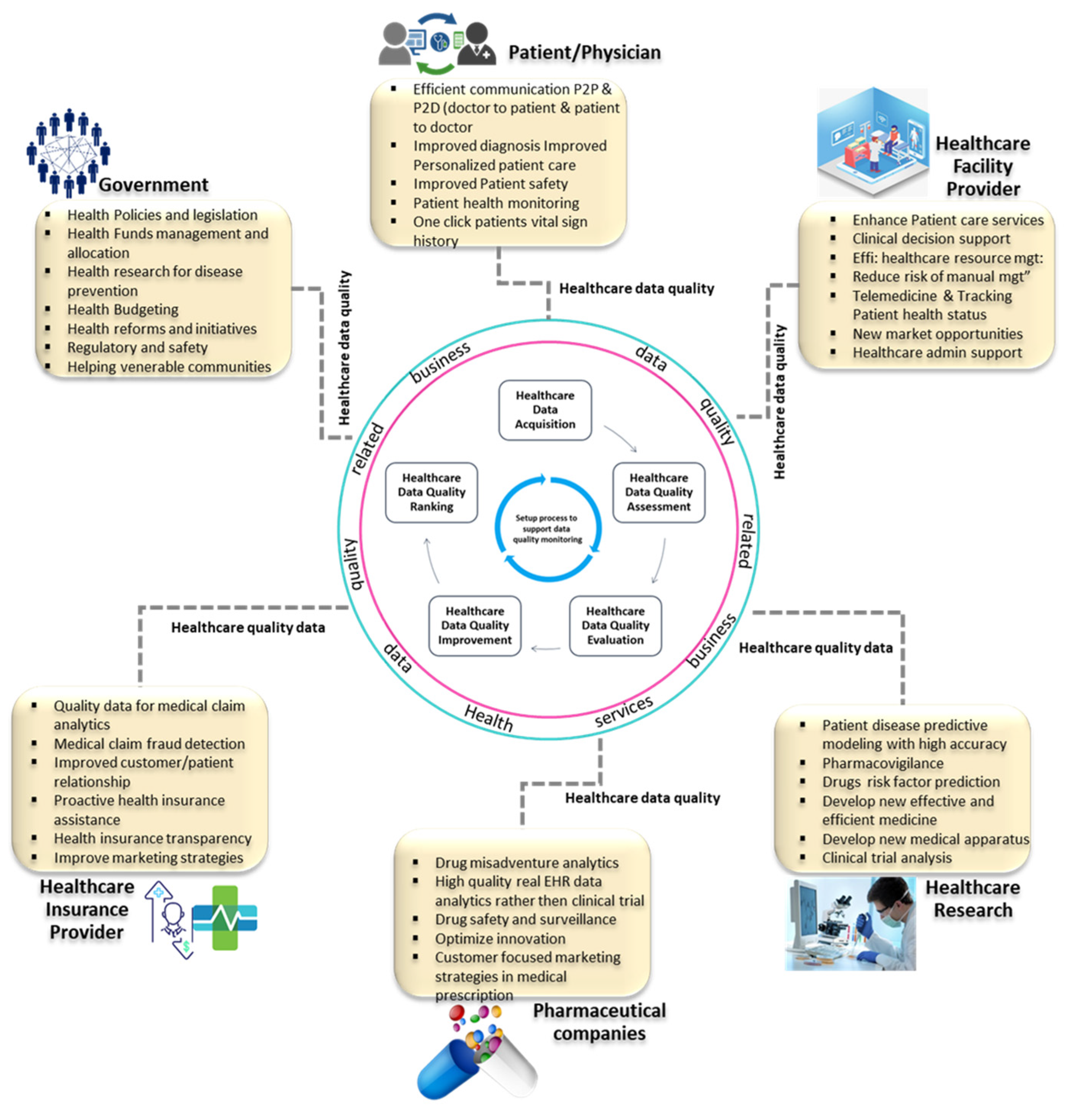
Data quality is more important in the healthcare domain. The magnificent assessment of data quality leads to provide better services and efficient resource management. The data used in the services should be checked in terms of quality for accurate planning and decisions. On the other hand, unchecked data from unreliable resources may cause serious damages to the reputation and loss of businesses. In the healthcare domain, a large quantity of data is collected such as electronic health records, laboratory results, patients’ health status monitoring data through wearable and non-wearable sensors, etc. However, the potential of that data could not be exploited because of poor quality and low confidence [
9,
10,
11]. There are many reasons for poor quality healthcare data such as wear and tear of healthcare equipment, untrainable staff, and different formats, etc. By using machine learning or deep learning models, we can estimate the quality of healthcare data by eliminating the deficiencies of subjective measures. So that the healthcare data could be fully utilized without any risk for better patient care and delivery of high-quality services. In the healthcare domain, there are various governmental, non-profit organization and business stakeholders who can get benefits from well-defined contextual data quality assessment mechanisms. The advantages of contextual data quality analytics for various stakeholders in the healthcare environment have been summarized in
Figure 1.
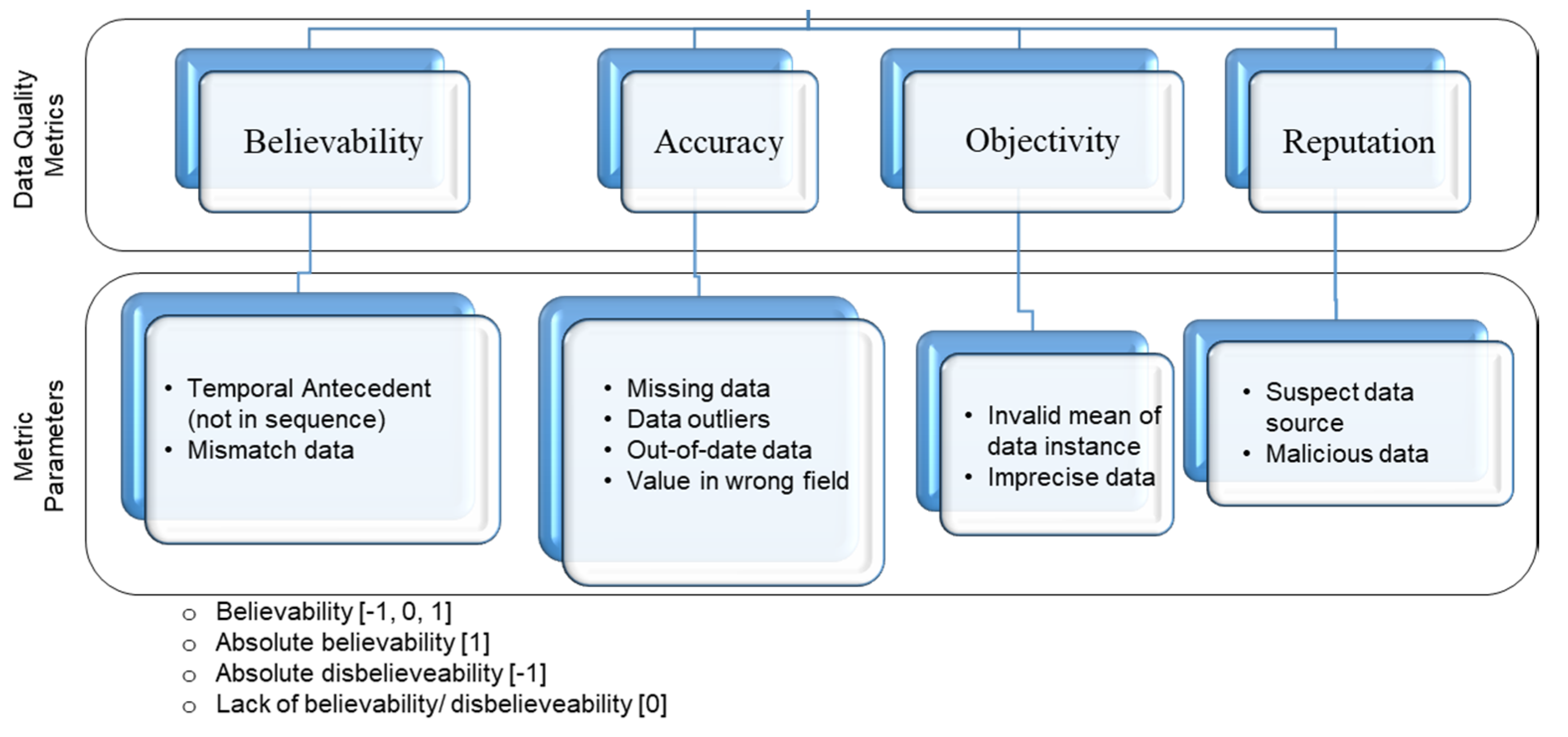
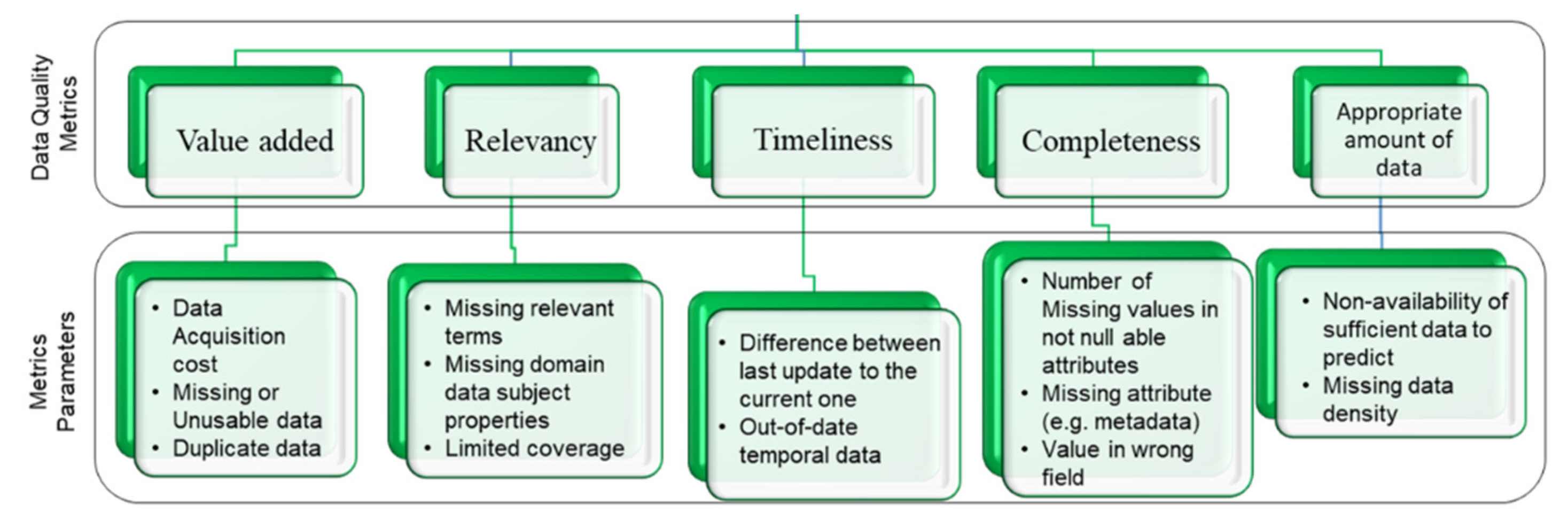
Quality of the same data may be different for the various applications and users; because each application has its context and requirements to use that data. Data quality refers that the data is fit for use in a specific context and it can be defined as “the standard of something as measured against other things of a similar kind” [
12,
13]. The International Organization for Standardization (ISO) defines data quality as “characteristics of data that relate to their ability to satisfy stated requirements”. Moreover, data quality can be specified as the “degree to which the characteristics of data satisfy stated and implied need when used under specified conditions”. To assess data quality various metrics have been used such as completeness, accuracy, timeliness, uniqueness, reliability, consistency, reputation, interpretability, and relevancy, etc. [
10,
11,
14]. Zaveri et al. [
15,
16], have discussed sixty nine data quality metrics and all these may not be used in the context of single application data, some are important for one case that others will be more suitable in another context. Therefore, it is also a significant contribution to identify the required data quality metrics in the application’s context and nature of data.
The quality of data should be analyzed in the application or business context impartially [
17,
18]. Normally the data quality is assessed with some business rules that can be applied to the data. For example, to measure the accuracy aspect of data quality, the percentage of values with errors is divided by the total number of values in a data instance [
19]. However, the contextual data quality assessment is a complex mechanism that needs automatic learning procedures to identify many patterns of incorrect or malicious data. To overcome the aforementioned issues, we present a contextual data quality assessment mechanism that supports data quality assessment for web objects healthcare applications by using deep learning models and semantic ontologies. The proposed data quality assessment mechanism is evaluated with two healthcare applications that provide services based on the emotion data received from wearable sensors. The Web of Objects (WoO) is a simple but efficient services platform that supports a robust way to develop application services with data abstraction using Virtual Objects (VOs) and Composite Virtual Objects (CVOs) [
20]. It fosters to analyze a very huge amount of data using microservices and VOs and CVOs ontologies [
21]. The intrinsic and contextual data quality assessment processing services are distributed and scaled into many microservices to increase the availability of quality data for the semantic data applications [
22,
23]. The proposed model supports to analyze data quality with intrinsic and contextual metric parameters at the data acquisition, assessment and service level. The functionality of WoO based data quality assessment mechanism can be generalized and extended to other applications by incorporating data quality requirements and assessment business rules. Moreover, the contributions of this article have been summarized as follows:
The data quality requirements have been identified for WoO based healthcare applications with respect to data acquisition, assessment and measurement of the quality of objects.
The contextual data quality assessment metric parameters and functions for WoO have been defined with respect to the data acquisition, data quality assessment level, and service level.
The intrinsic and contextual data quality assessment metric parameters have been presented.
The deep learning model has been developed to perform the WoO based data quality assessment with respect to the contextual aspect of data quality.
We present a comprehensive web objects based data quality assessment model for the healthcare applications. This model is based on semantic ontologies and deep learning models.
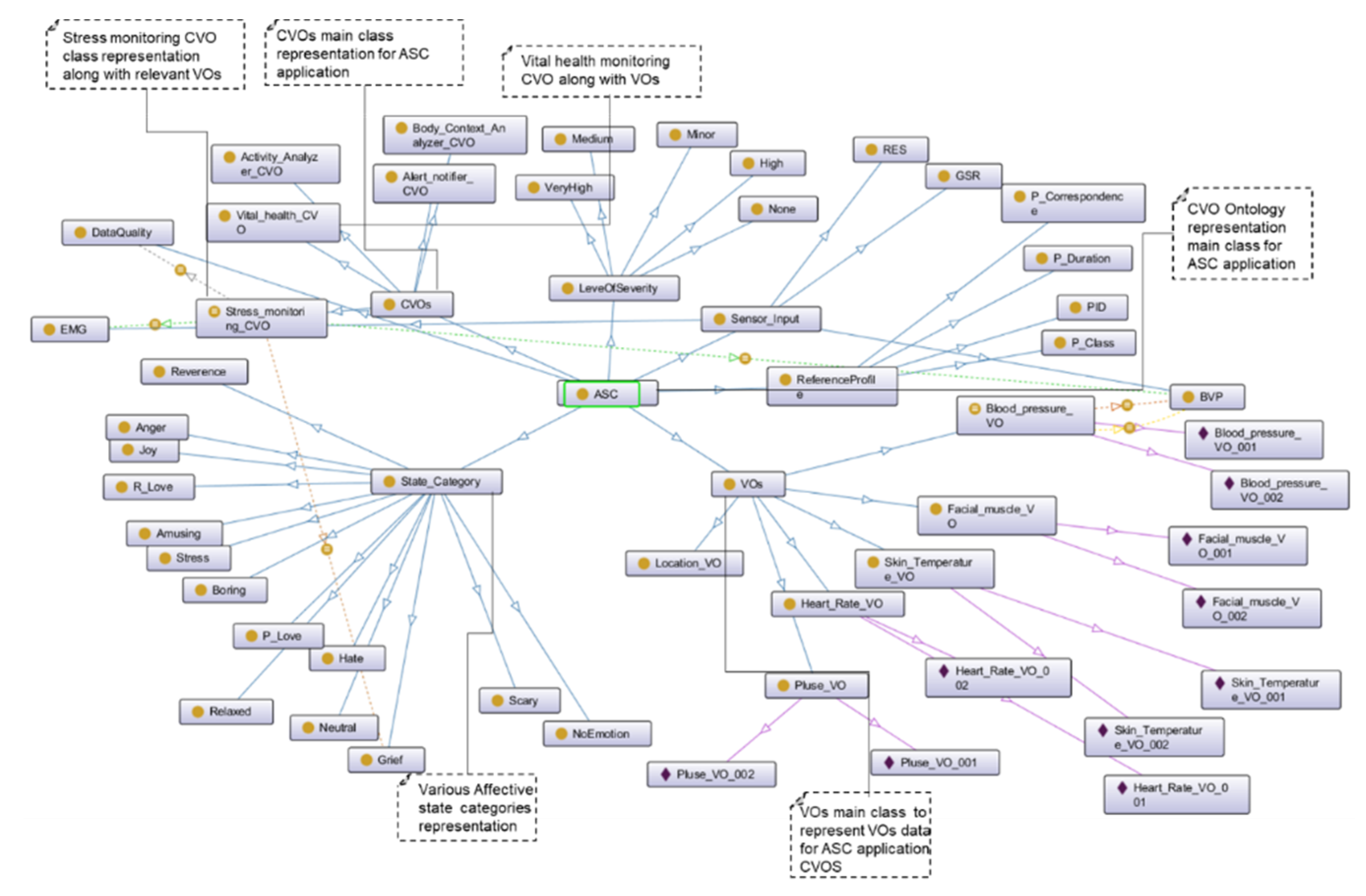
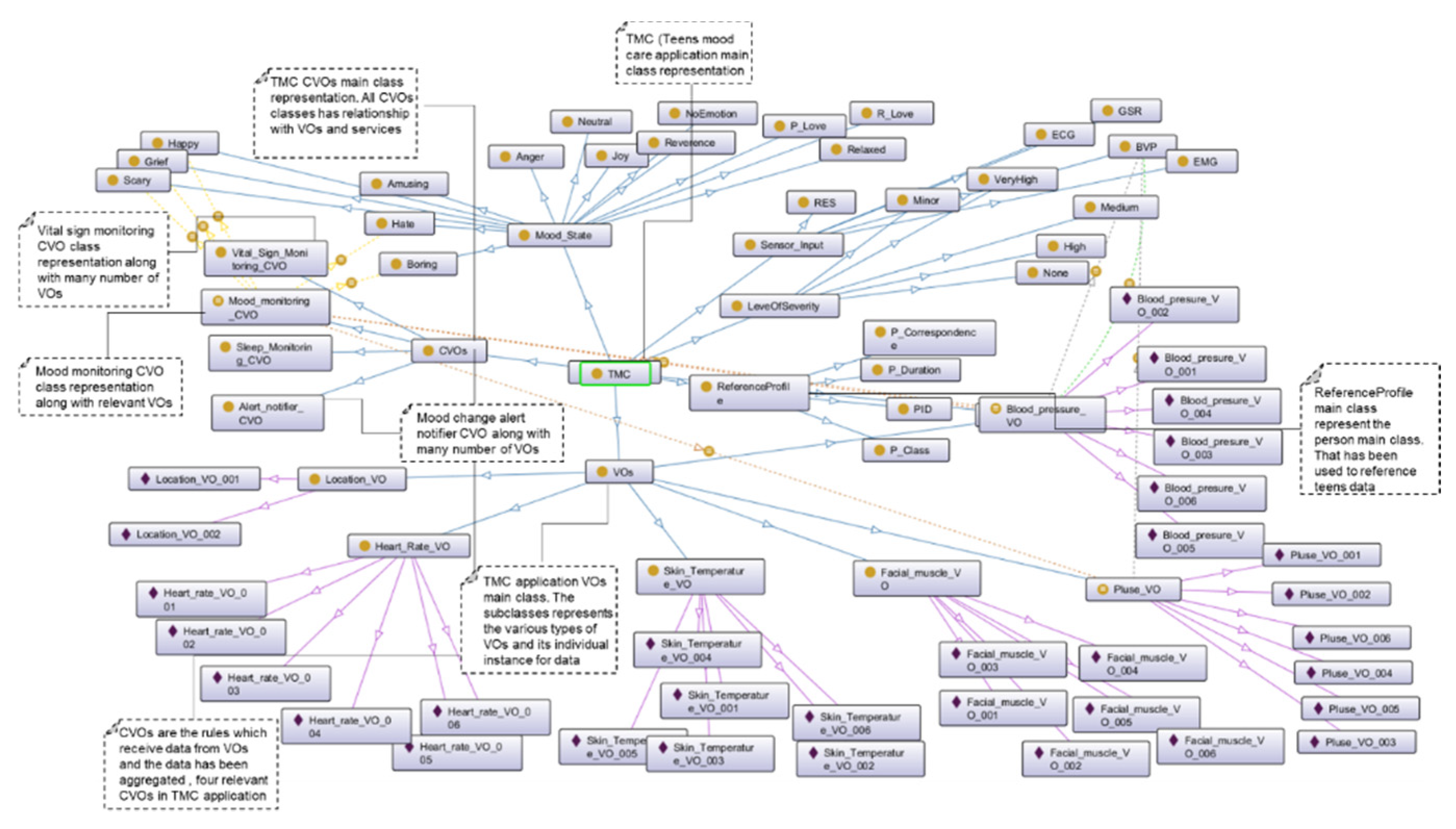
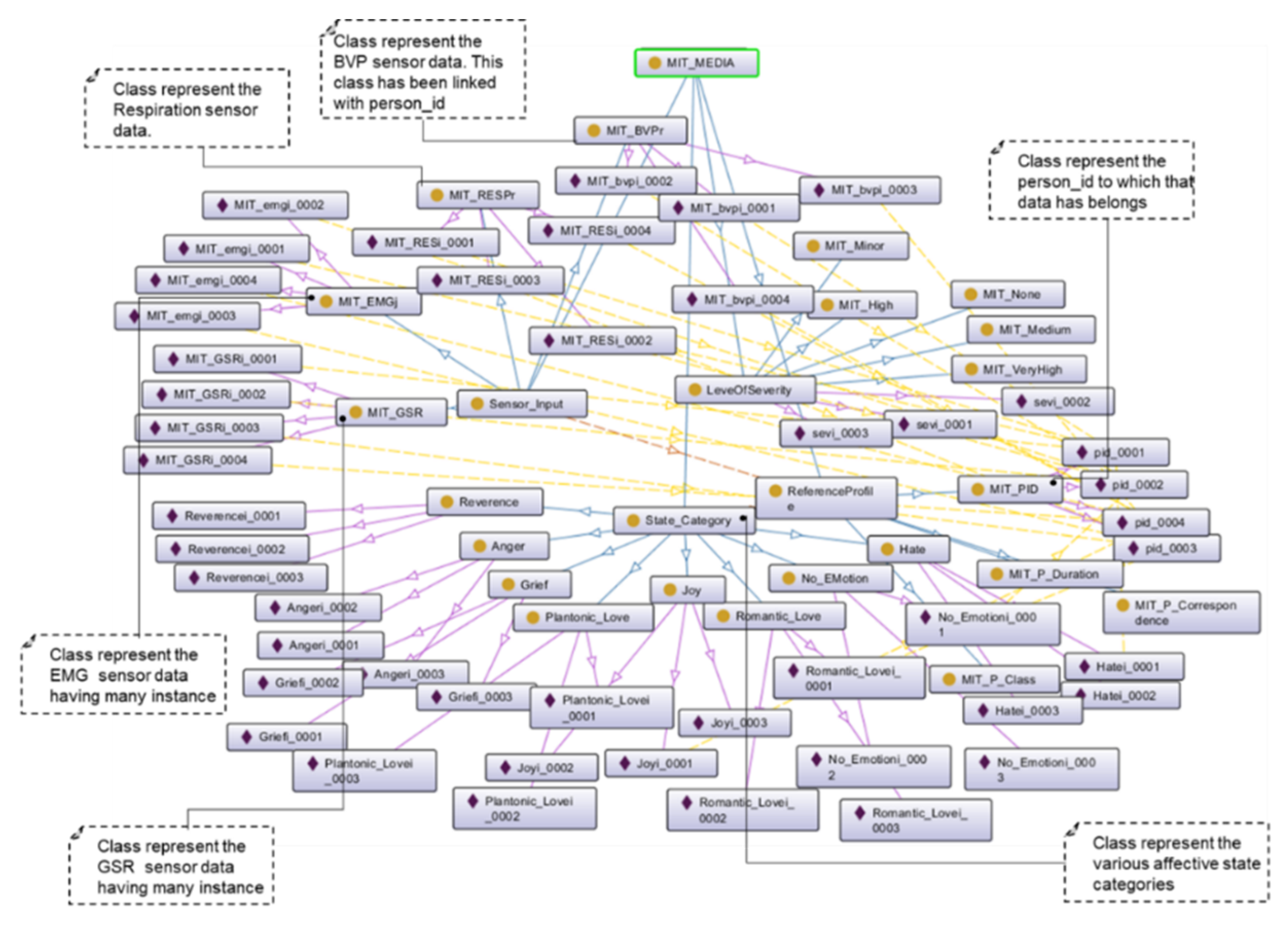
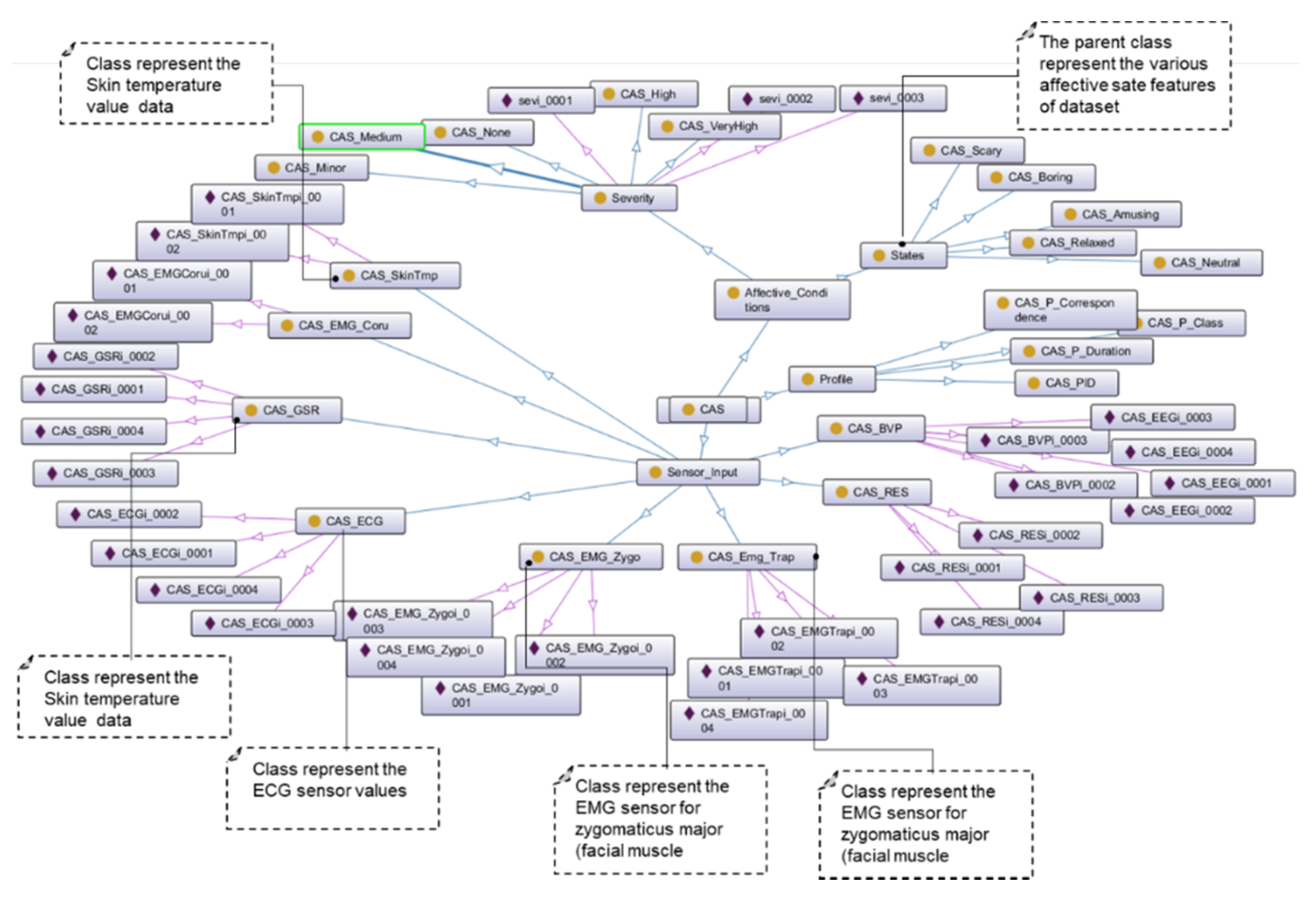
To validate the proposed approach of data quality assessment, we developed the Affective Stress Care (ASC) and Teens’ Mood Care (TMC) application ontologies.
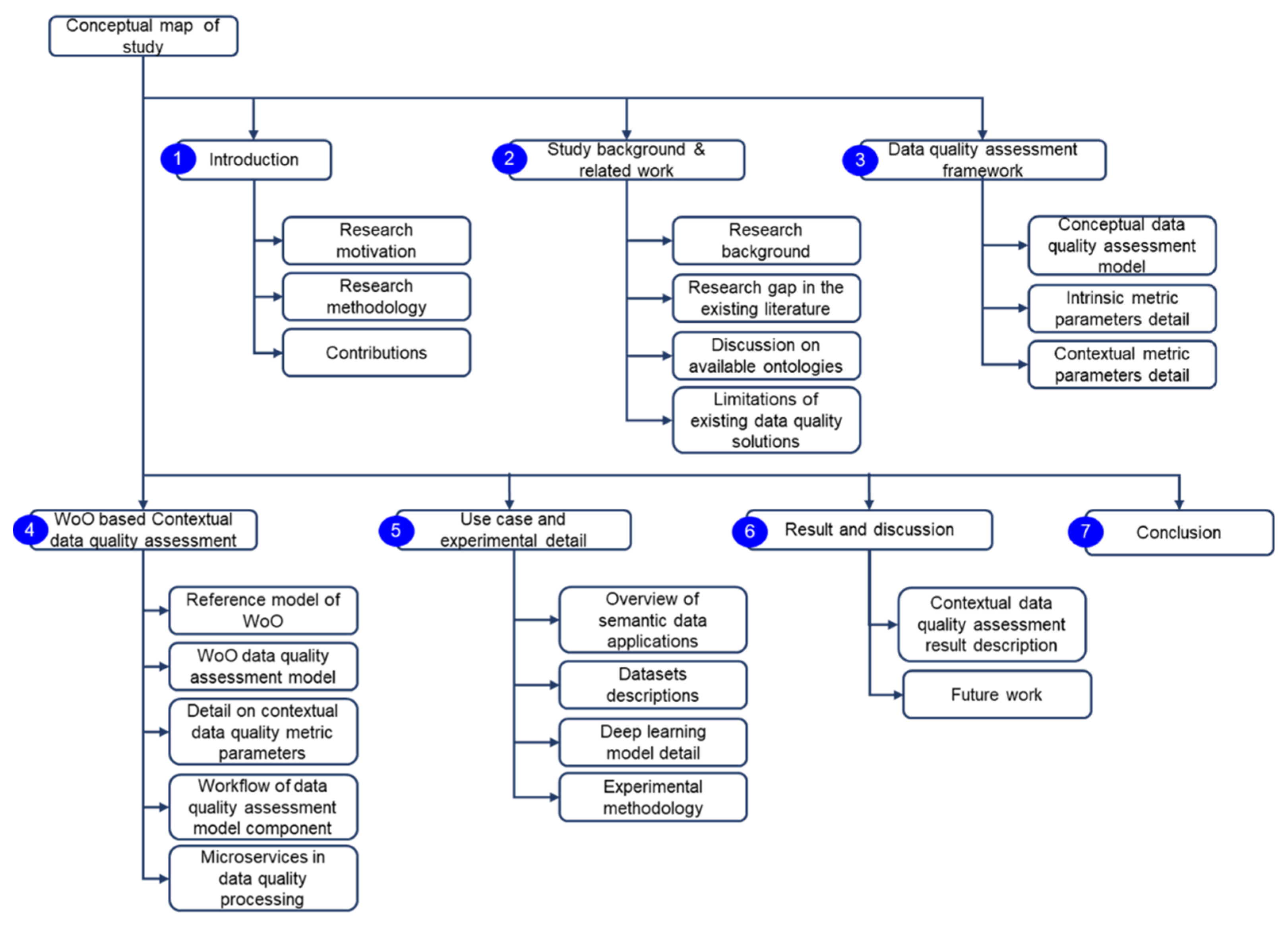
The conceptual map of this study is illustrated in
Figure 2. The study background and research gap are covered in
Section 2; the conceptual framework of data quality assessment and intrinsic and contextual metric parameters are covered in
Section 3; WoO based contextual data quality assessment model is discussed in
Section 4; use case and experimental model is elaborated in
Section 5; Results, future work, and conclusion have been covered in
Section 6 and
Section 7 respectively.
2. Background and Related Work
As in our daily life, we assess objects in the real-world based on some attributes and do the comparison in order to use them for a specific purpose. Similarly, in the data quality literature, the data is assessed based on data metadata and properties. These data attributes are called data quality dimensions, which are used to measure the quality of data [
15,
24,
25]. The measurement procedure of these data quality dimensions is called data quality metrics or indicators [
15,
25]. The assessment of data quality is very crucial when it comes to choose one dataset over the other or rank the dataset for specific information need and application context [
26,
27,
28]. The data quality assessment is performed based on the metrics, and these have been classified into four categories such as intrinsic, contextual, representational and accessibility [
29,
30,
31]. In the literature, the existing data quality frameworks perform data quality assessment using metrics. However, the acquisition level data quality measurement in terms of security, privacy, and retrieval efficiency, etc., have not given much attention [
30,
32].
In articles [
19,
33], the authors have discussed the data quality analytics frameworks to assess the quality of data received from the physiological sensors. These frameworks support data quality assessment based on the data quality metrics and rules. Both frameworks do not support data acquisition and contextual level data quality analytics. In most of the literature, the data quality accuracy metric has been widely focused [
34]. Such as in the article [
35], authors analyze the multivariate anomalies with principal component analysis and compute the accuracy of the healthcare dataset that contain the vital sign of patients who were admitted in the intensive care unit. To predict the mortality and length of staying in the hospital various benchmarking deep learning models have been applied and evaluated based on the model accuracy [
36]. The data quality is also important in the situation where the decisions are taken based on the machine learning model results. In order to measure the quality of training data for machine learning models, an incremental data quality validation framework has been discussed [
37]. This framework validates the quality of data with dynamic rules and constraints in terms of accuracy, consistency, and completeness.
To analyze the quality of sensor data deployed in the sea, the ensemble machine learning classification framework has been designed [
38]. In which the few samples of sensors data have been analyzed in the data quality assessment classifier. Authors [
38] have used cluster sampling and believe that this sampling method can better represent the distribution of a dataset. The ensemble framework used in this research article is only able to classify data quality qualitatively without any context. However, our data quality assessment mechanism classifies the quality of data quantitatively in the application context.
To perform enterprise data quality assessment, Gürdür et al. [
39] have discussed a six step methodology that focuses on the identification of most relevant data quality metrics. The six step includes identification of stakeholder that will be involved in the data quality assessment process, extraction of data quality requirements, identification of relevant metrics and rules, querying data, visualization, and improvement of data. The research gap in article [
39] is the focus on data quality assessment based on metrics which are not sufficient for the contextual data quality; however, our proposed model supports deep learning and semantic ontology based data quality assessment methodology. To analyze data quality of the healthcare data, authors [
40] developed the data quality knowledge repositories; that contain the characteristics of data quality rules. These rules have been used to measure the quality of healthcare data. The concepts of data quality rules in the knowledge repositories have been represented with the Dublin Core Metadata standard.
The data quality has an impact on contextual services and applications. Sundararaman et al. [
41] proposed a framework to link data quality with the business outcome. Authors [
41] indicate data quality metrics as factors of data quality and have shown the correlation between the data quality factors and the impact on the business outcome. The data quality is measured with its relevance factors such as weight and the business impact. In the evaluation of this framework, a survey questionnaire filled by the domain experts has been used. To conduct this survey the authors defined a hypothesis that “there is a direct relation between business outcomes and data quality factors”. To know the impact of data quality in the business process, a runtime data quality verification mechanism has been discussed [
42]. This mechanism checks data quality in two aspects that the business process completed well with the provided data and whether the completed process affect the stored data negatively.
To model data quality assessment various ontologies have been developed in the past. The popular data quality ontologies include W3C data quality ontology, the quality model ontology, evaluation results ontology, and the dataset quality ontology [
43,
44,
45,
46]. We developed WoO VOs/CVOs ontologies to acquire the relevant data for the services and tasks and then perform the contextual data quality analytics on individual and aggregated data. Currently to perform data quality analytics various open source and commercial solutions are available. Among them, IBM infoSphere information analyzer, Uniserv data quality scorecard, Talend for data quality analysis, and Collibra data governance and data quality solutions have been widely discussed in the literature [
47,
48,
49,
50]. Among them, only Talend supports data quality analytics with machine learning and other tools follow the rule-based approach. All these tools do not support metric parameters based data quality assessment for individual and aggregated data in the application context; however, our proposed model supports contextual data quality assessment with deep learning models and semantic ontologies.
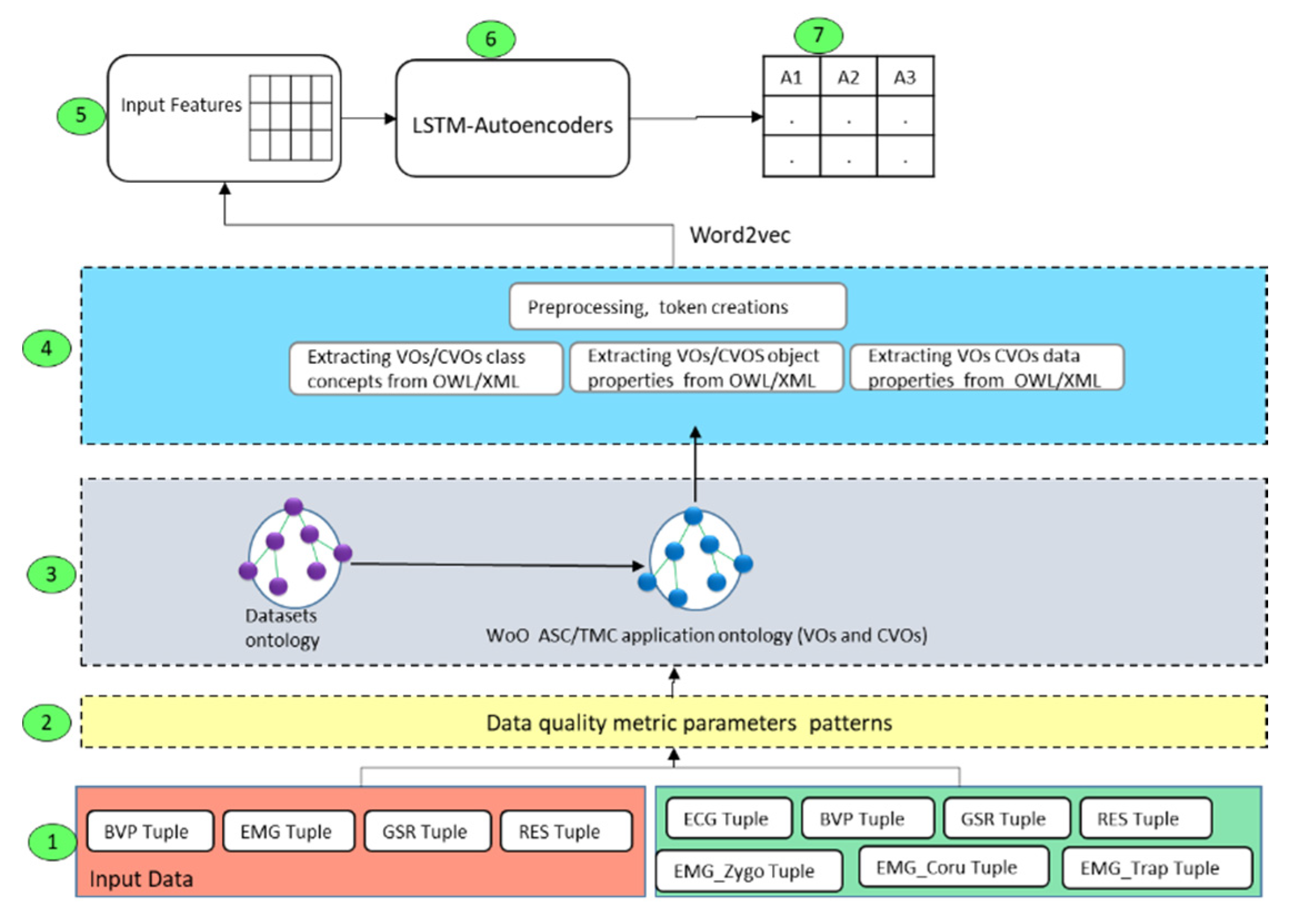
4. Web of Objects Based Contextual Data Quality Assessment Model
4.1. Web of Objects Model
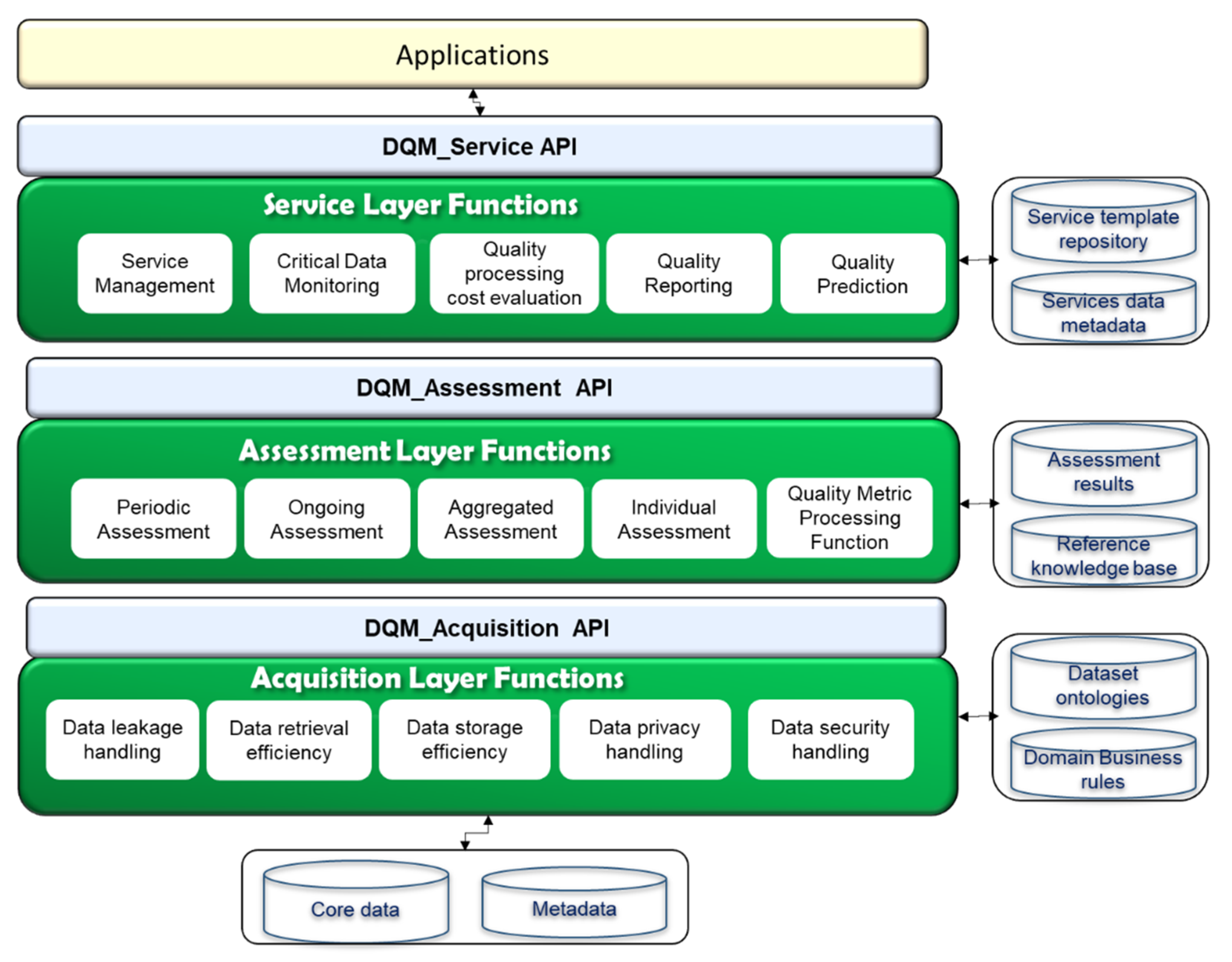
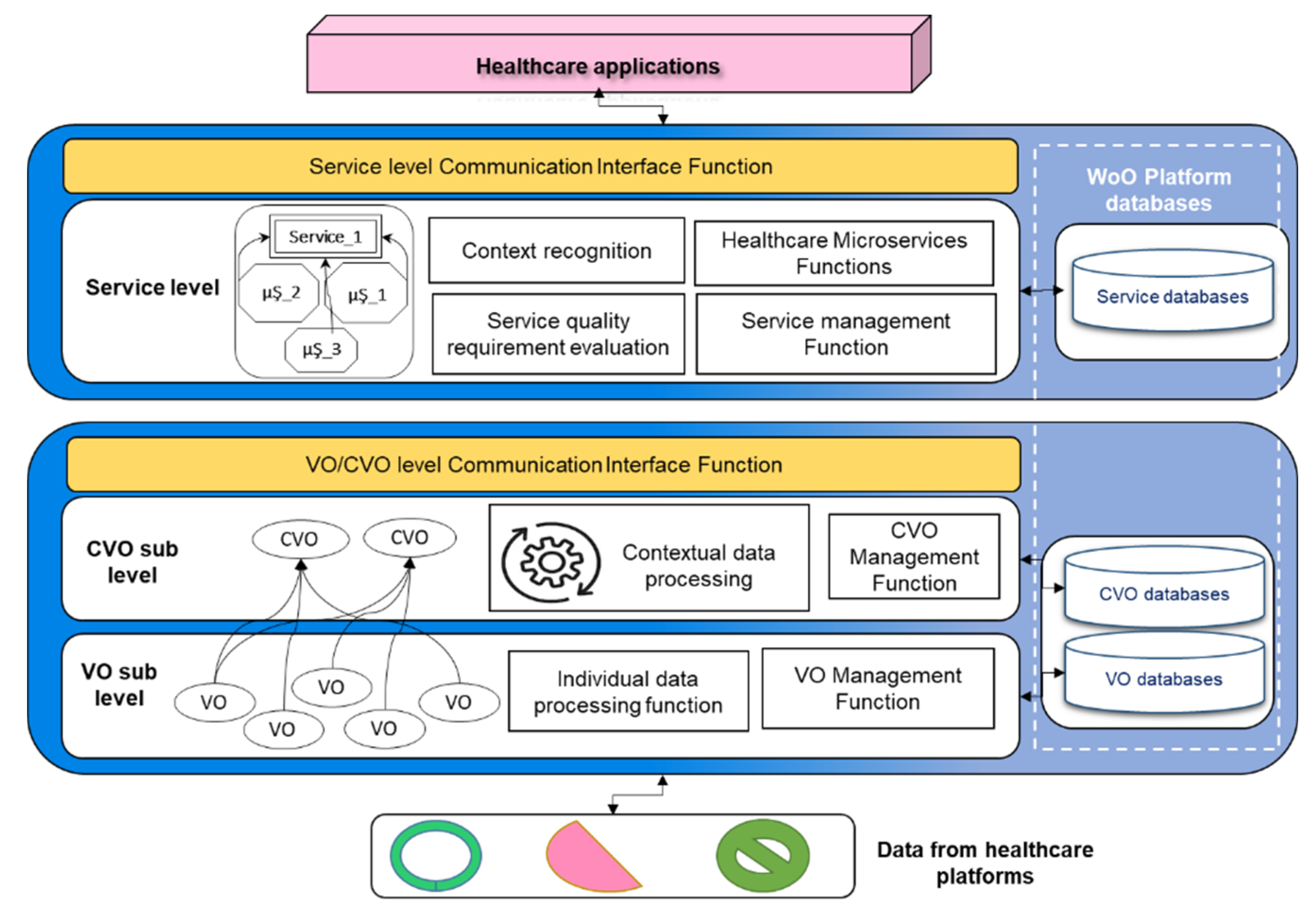
The WoO foster an efficient and simple service provisioning platform that processes the data for the provision of high quality healthcare services [
51]. The Virtual Object (VO) and Composite Virtual Object (CVO) are the two building blocks of the WoO platform, that harmonize the real-world objects, by using semantic ontologies for connecting, interpreting, and sharing of data among various services [
52]. The functional model of the web of objects (ITU-T Y.4452) [
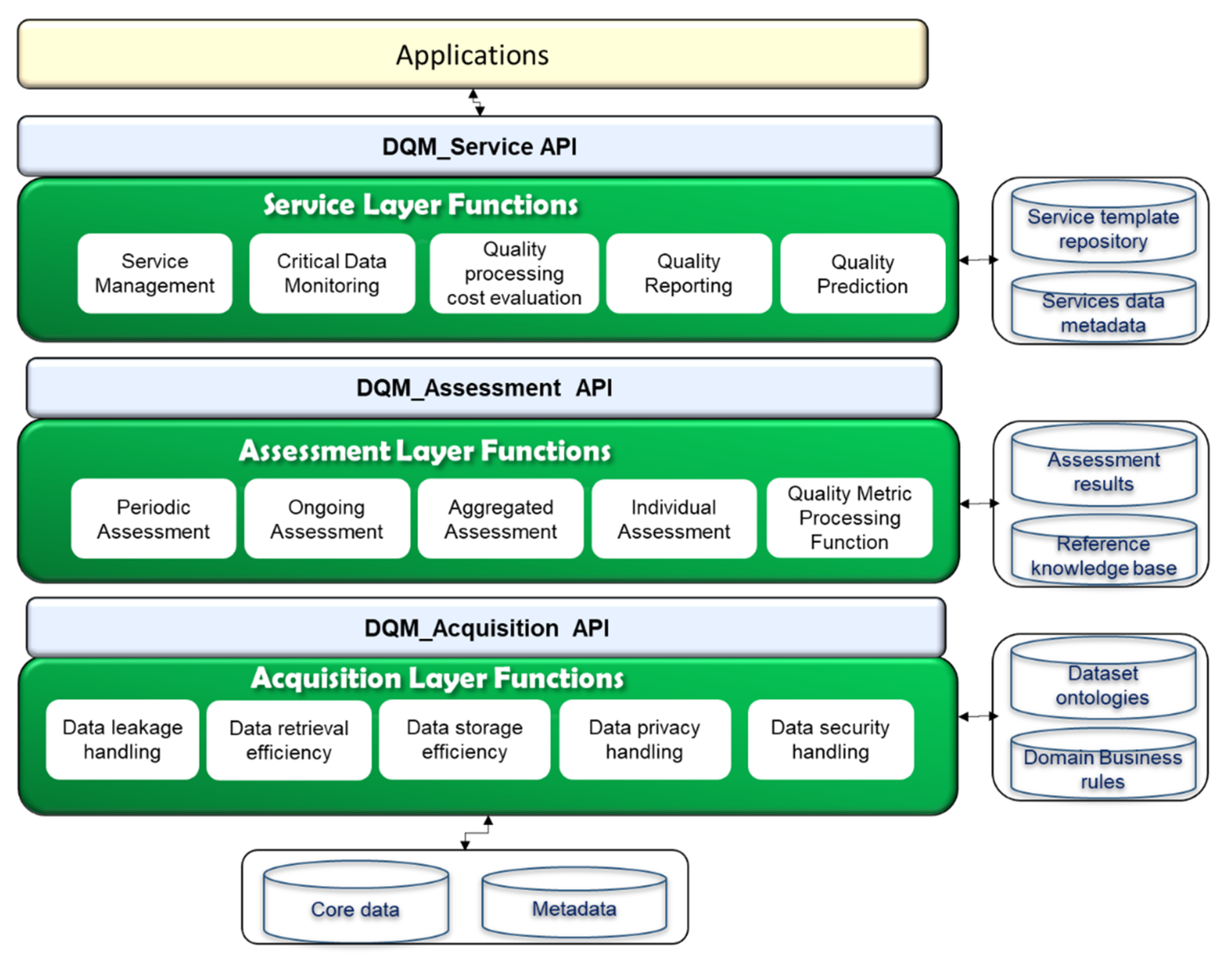
51] with additional functions for data quality assessment is shown in
Figure 7.
In order to foster data quality processing and the requirement of business context independently, the VO layer functions have been designed. The WoO functional model’s VO layer is used to represent and virtualize the semantic data attributes and quality metrics. The VO/CVO layer is also used to virtualize the real-world objects and provide a communication interface to the data quality assessment model in order to receive data quality requirements and process it accordingly. In a real-world implementation scenario it may be possible that different functions could be deployed on different machines in the cloud. The CVO layer has been proposed to apply data quality business rules and to select data attributes in the form of VOs; because the CVO is the mashup of multiple VOs that are composed in a specific context. The semantic rules have been applied over the list of VOs to achieve the functionality of CVO and then the CVO executes the features of services. In WoO, real-world objects and other data objects have been annotated with VOs semantically; in order to create knowledge for the actions on objects. For example, receiving current humidity, temperature, weather update, and the detection of occupancy of persons in the conference room for regulating conference room temperature automatically. To provide high quality services in the healthcare environment, we defined data quality requirements, and types of assessment for each layer of WoO. The intrinsic metric parameters are applied at the VO sub-level because at this level there is no context of the application or task in hand. Each VOs semantic data could be analyzed individually using deep learning models. The contextual metric parameters have been applied at the CVO level, because the CVO composes the VOs data in the context of application and service.
4.2. Web Objects Based Data Quality Assessment for Semantic Data Applications
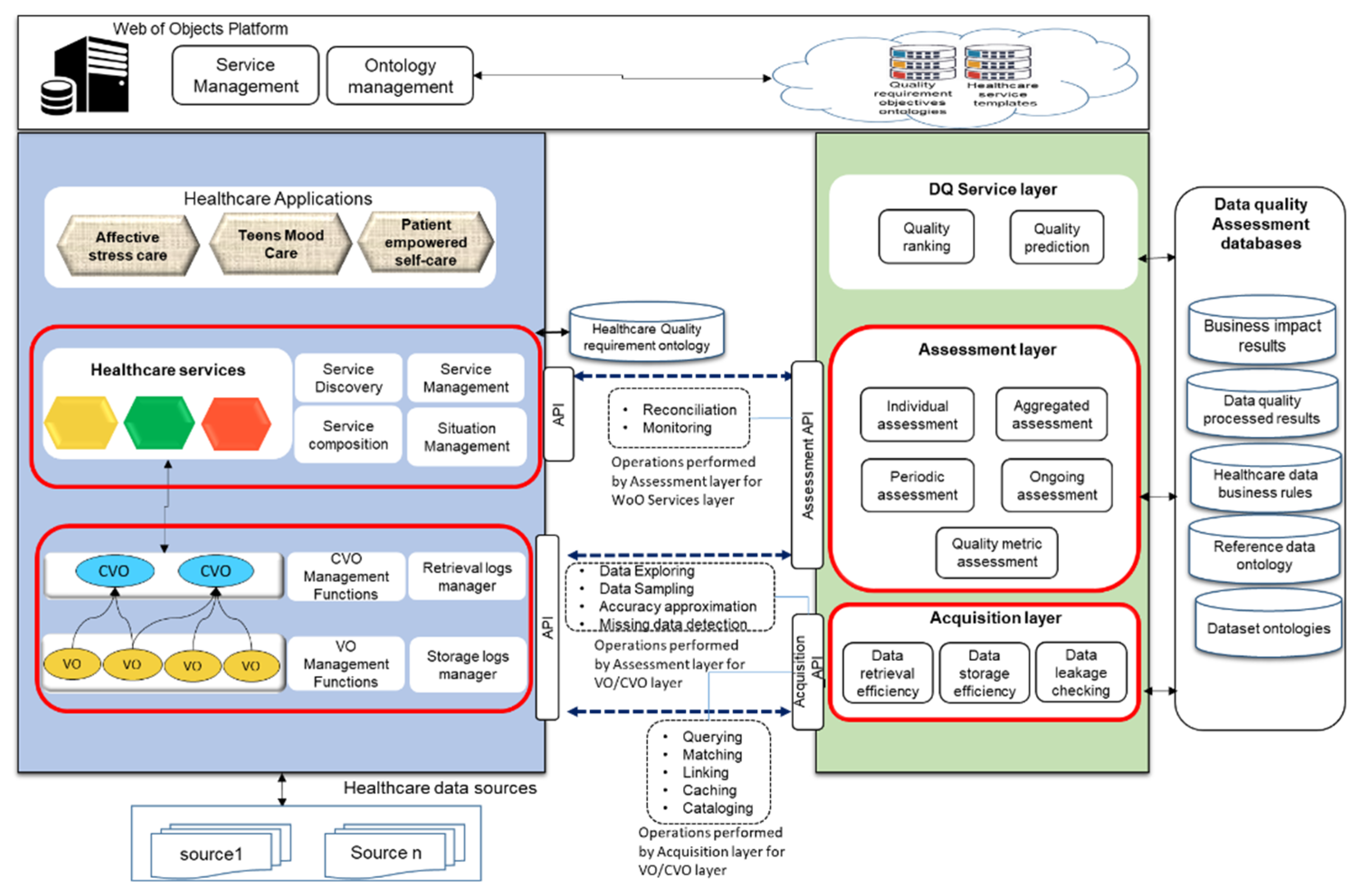
In this section, we discuss the mapping of a data quality assessment functions with WoO enabled healthcare applications model. In the WoO platform, the incoming data will be received from healthcare sources. It will be harmonized with VOs and CVOs for healthcare service features. The healthcare data quality issues can occur during data life cycles such as collection, transformation, retrieval, and analytics. The data quality assessment for WoO based healthcare applications data is shown in
Figure 8.
In order to show WoO based data quality assessment, the layer to layer mapping has been performed between the WoO services platform and data quality assessment functions. The acquisition layer has been mapped with the WoO VO and CVO layer for assessing the acquisition level data quality. In this case, it will check VOs/CVOs creation, storage and retrieval efficiency, and harmonization of incoming healthcare data from heterogeneous sources. The data quality assessment layer has been mapped with the WoO VOs/CVOs layer and data quality model service layer. At the VO/CVO level, it assesses the quality of VOs and CVOs data as per the healthcare application requirements. The intrinsic and contextual metric parameters have been applied with the individual, aggregated and periodic assessments. The ongoing assessment has been performed for critical healthcare data. During the data quality assessment at the acquisition and assessment level, various operations have been performed. These operations include querying, matching, linking, cataloging, caching, data exploring, sampling, accuracy approximation, and missing data detection. The assessment layer monitors the overall data quality with respect to the healthcare services at the WoO service level. Here the data quality assessment model performs the operation of reconciliation and monitoring of data in the services’ context.
4.3. Contextual Data Quality Assessment Metric Parameters Mechanism
The process to perform contextual data quality assessment with respect to defined metric parameters have been described for each contextual metric in the WoO semantic data applications. All these metric parameters analytics process is implemented using microservices. The contextual metric parameters microservices are used with data quality assessment model functions such as individual assessment and aggregated data assessment, etc. The detailed process for each contextual data quality metric parameters is presented in the following sub-sections.
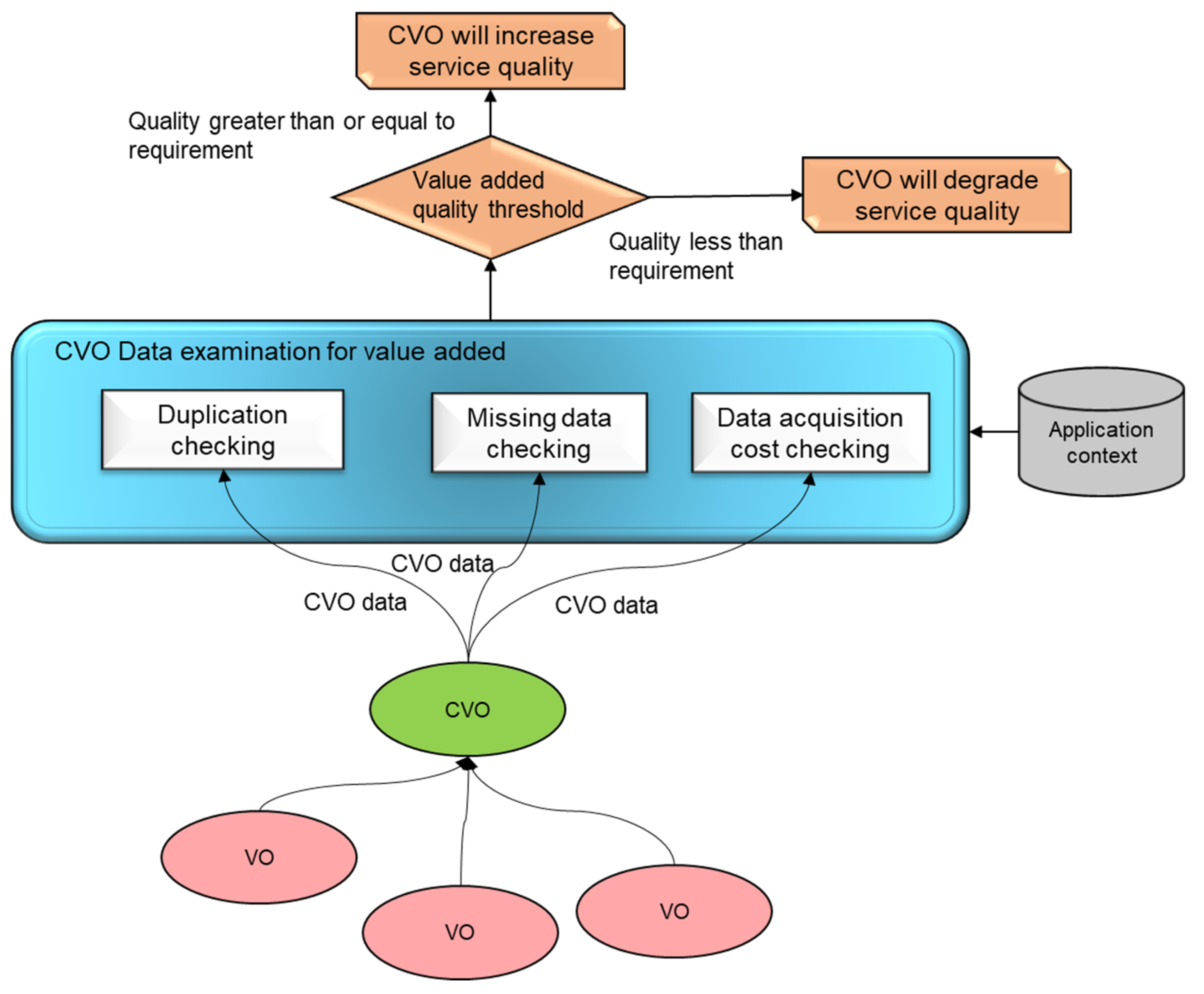
4.3.1. Value Added Metric Assessment Mechanism
In WoO enabled data quality assessment, the value-added metric assessment emphasis on the benefits and advantages of using the semantic data in a CVO context and its impact on service quality. The value-added metric is applied to the VOs data which are aggregated in the CVO context. To analyze this metric the VOs duplication data, missing data, and the data acquisition cost parameters are analyzed with respect to each CVO for the semantic data applications. In order to assess the contextual data quality aspect for CVO, it is necessary that the data assessing time duration should be defined clearly. Based on the results of this metric the data quality impact of CVO is decided in the service or application context. If the CVO quality with respect to this metric is low, then based on the required threshold value we could say that this data is not suitable for the CVO or otherwise. The value-added assessment mechanism block diagrams are shown in
Figure 9.
4.3.2. Relevancy Metric Assessment Mechanism
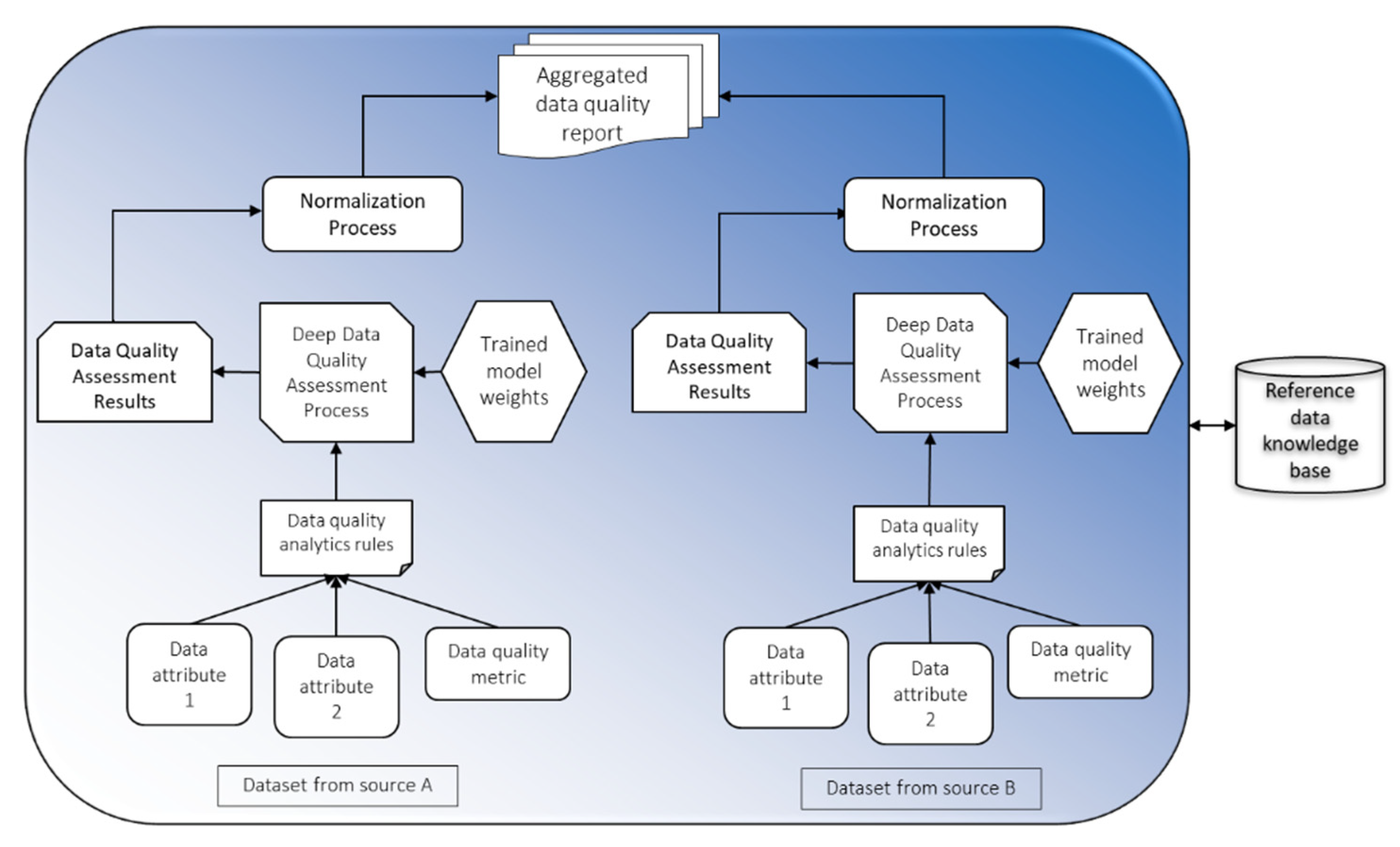
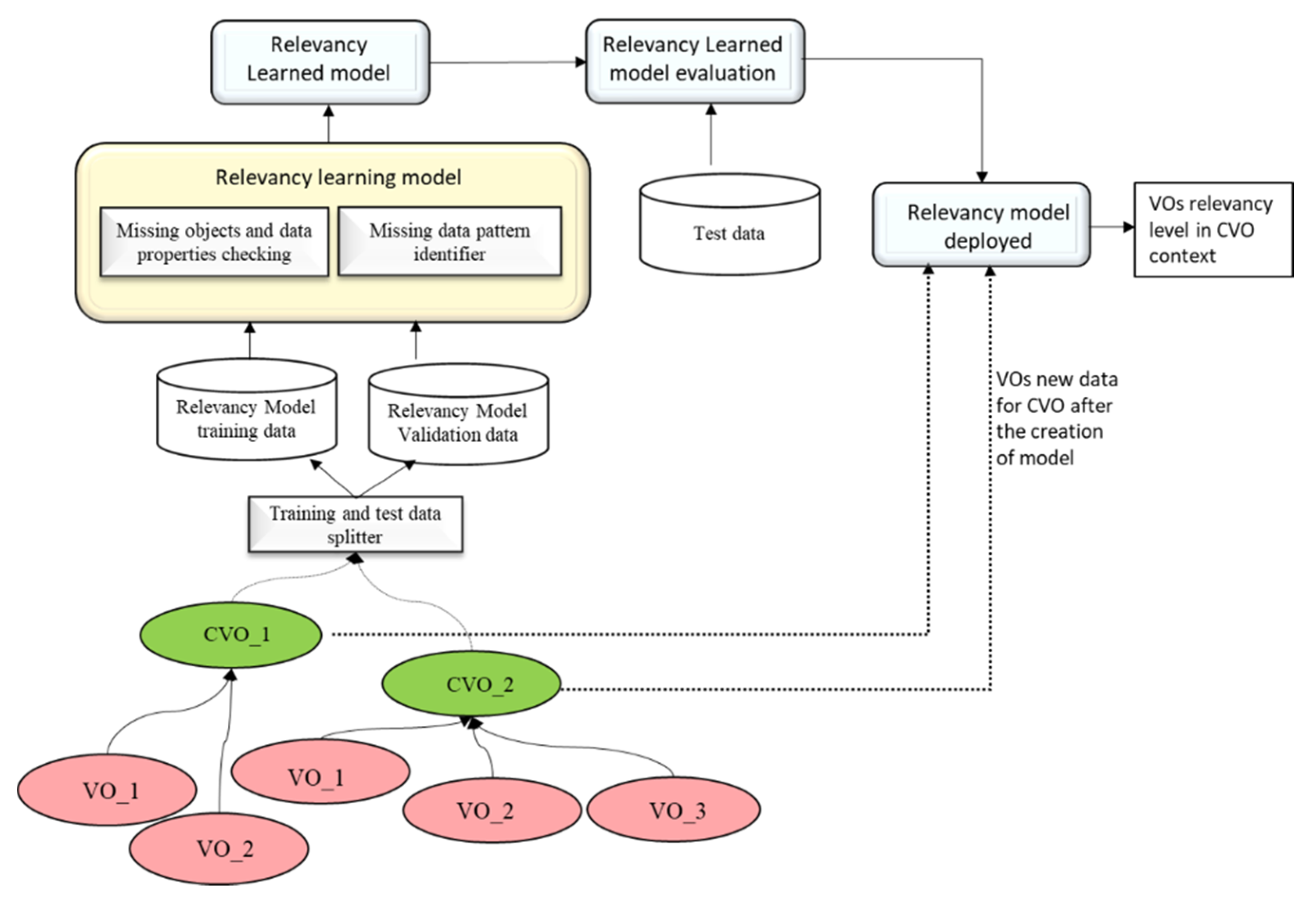
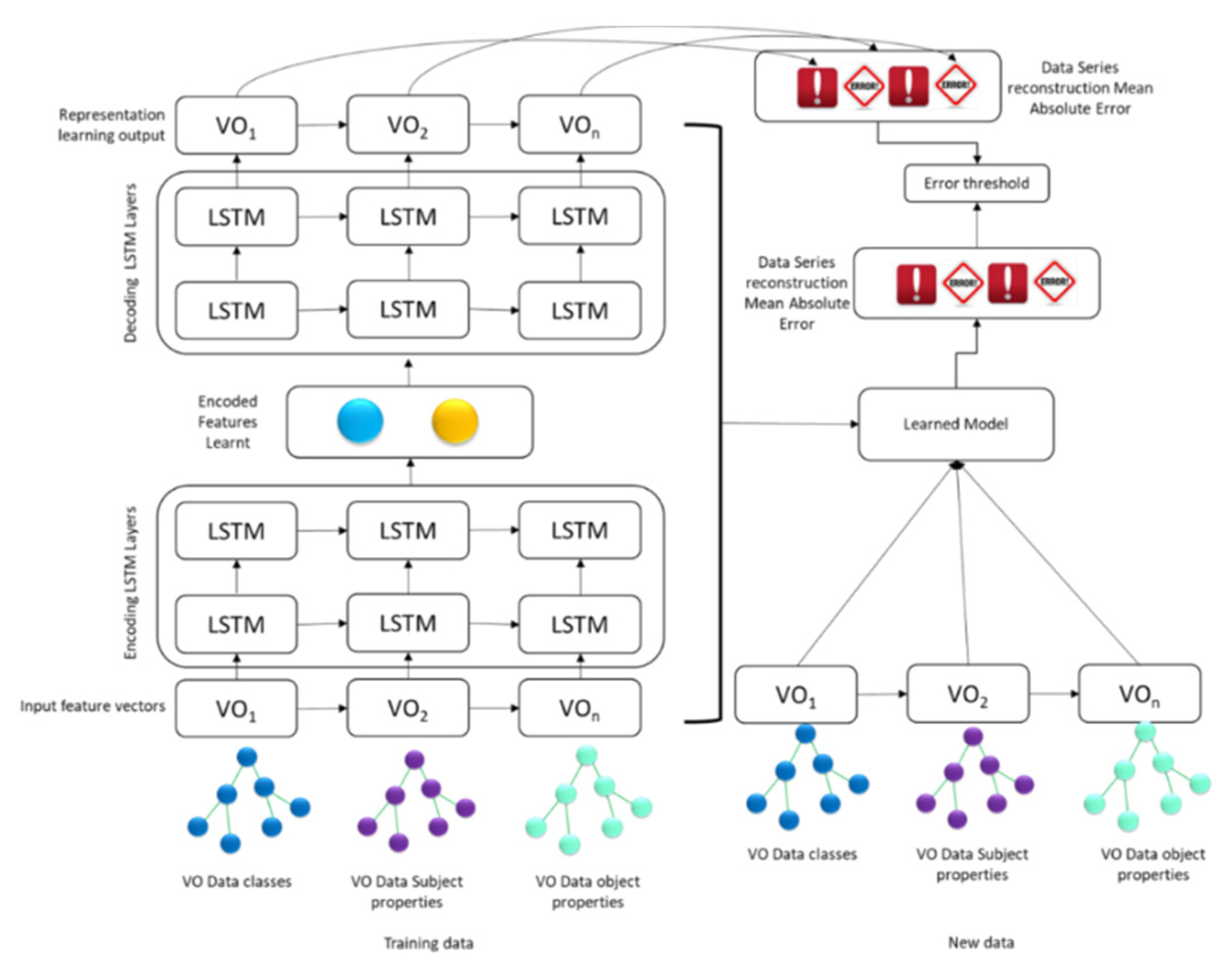
The relevancy metric has been used to identify that the VOs data are relevant for a CVO context. The relevancy metric analyzed that the VOs have complete relevant data for the CVO; and there is no missing object and data properties relation with other supported VOs such as a person’s ID, location, etc. The machine learning or deep learning model can be used to learn above mentioned patterns to find out the relevancy value of VOs in a CVO context. The relevancy assessment learning model for the WoO semantic application data is shown in
Figure 10. In this figure, there are two CVOs (CVO_1, CVO_2). The CVO_1 includes two VOs (VO_1, VO_2) and CVO_2 receives data from the VO_1, VO_2, and VO_3 respectively. In order to learn the contextual relevancy metric parameters model, the VOs data has been distributed into training and testing. The learned model will be used to classify the VOs data relevancy in the CVO context. If the aggregated VOs data quality in terms of relevancy is low, then the relevant CVO will be discarded from the service or the service quality will be resumed partially.
4.3.3. Timeliness Metric Assessment Mechanism
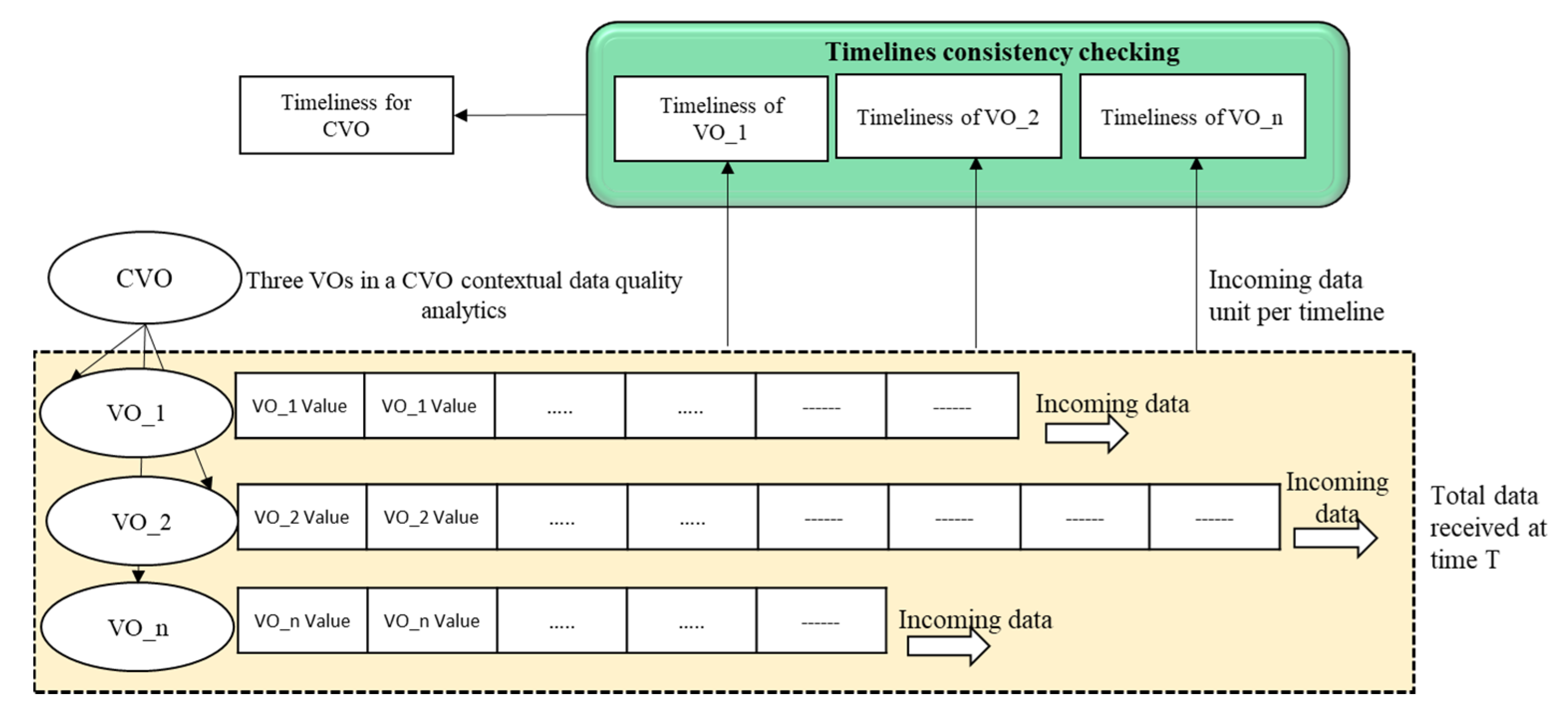
In healthcare data quality analytics, the timeliness is called data currency. The timeliness metric reflects two concepts in the healthcare domain. The first aspect is related to data itself and the second aspect related to the healthcare application infrastructure. The timeliness is considered when the value of the entity is recorded in the database and when it is used for some clinical decisions. In the healthcare domain, the data timeliness feature could be identified by investigating data entry logs, the time difference between the related events within the medical repository. In the WoO enabled healthcare application environment, the timeliness feature could be identified by investigating the data arrival and retrieval consistency for the application and services. In our data quality assessment model, we developed the metric parameters for the data acquisition and data quality assessment level.
In the WoO semantic data application, the VOs have been composed in the CVO context for some features such as to monitor the current state of teen’s mood. In this context, the VOs incoming data should be consistent and synchronized with respect to the time as required by the CVO. If the VOs incoming data timeliness is not consistent, then the CVOs will not perform the expected task. The VOs and CVOs data temporal features are used to analyze the timeliness metric value. Such as three VOs receiving data from physiological sensors with different timeline rates.
Figure 11 illustrates the timeliness metric assessment of VOs in a CVO context for semantic data applications.
4.3.4. Completeness Metric Assessment Mechanism
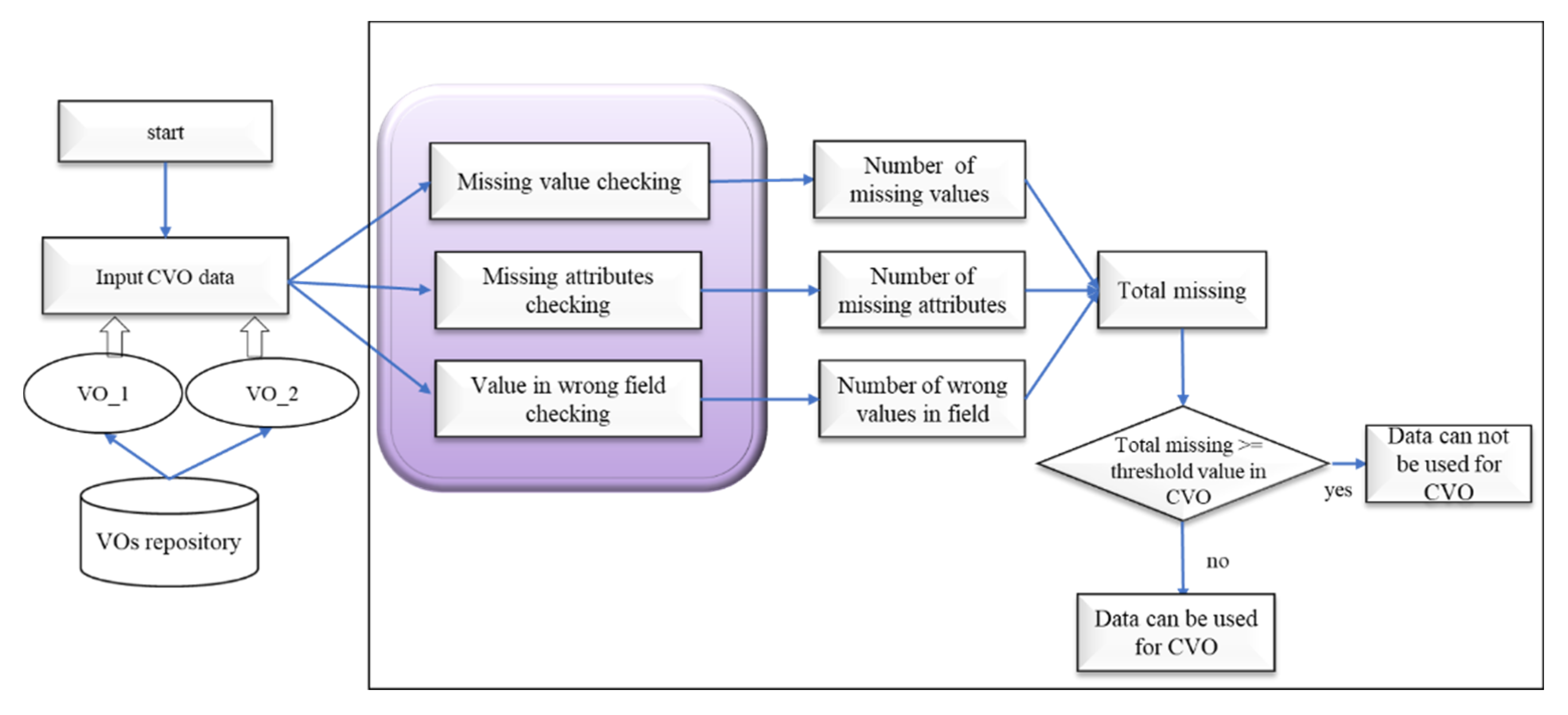
The data quality assessment model can detect and measure data quality in various aspects. Among these data quality aspects, data completeness is one of the most common data quality metrics for healthcare data. The completeness can be described as whether the facts are fully presented. The completeness is a contextual metric that focuses on the selected VOs in the CVO context; that VOs should not have missing data and it contains all the required information for the task to be performed. For example, the electronic health record or physiological sensors data collected is sufficient to predict and classify emotion state or whether the data contains any missing values. In our data quality assessment model for semantic data application, this metric has been applied on person data VOs such as assessing that a persons information is complete, and on sensor data VOs that all the physiological sensor observation has completely received. This metric has three parameters including VOs missing value analysis, VOs missing data attributes analysis, and analysis of wrong field values. The detailed mechanism to use the completeness metric for the contextual data quality assessment in the WoO enabled applications environment is shown in
Figure 12.
4.3.5. Appropriate Amount of Data
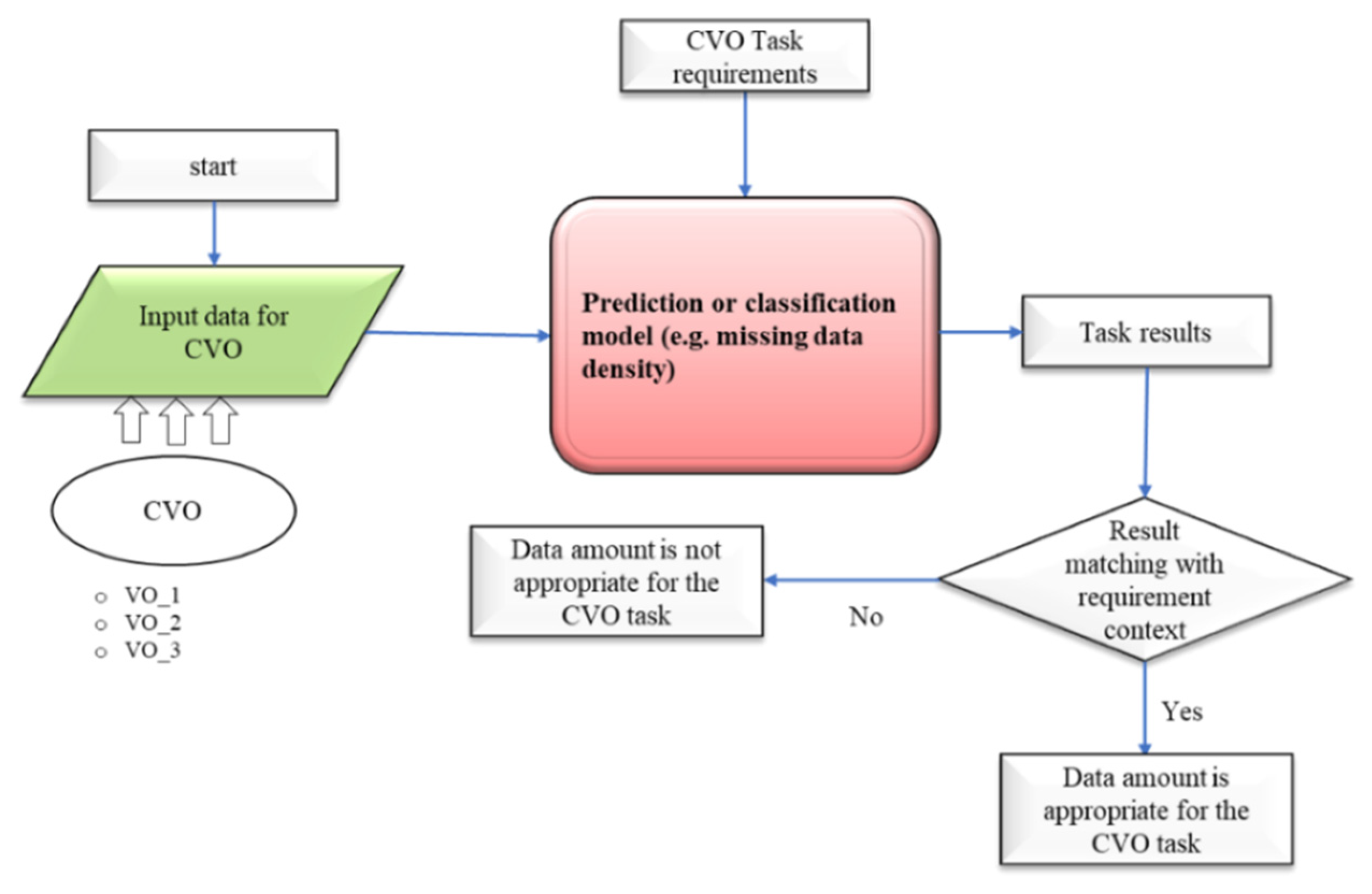
In the contextual data quality assessment, the appropriate amount of data is one of the important data quality metrics. This metric has similar characteristics with respect to the completeness metric. It focusses that the available data is enough for the task or services. In our WoO semantic application data quality assessment model, we designed the metric parameters assessment mechanism and applied it on the CVOs aggregated data. This metric analyzes that the CVOs have enough data to perform relevant tasks according to the requirement of service features. The data quality assessment mechanism for the metric parameters is illustrated in
Figure 13.
The CVO contains VOs data including object and data properties is the input to the learning model. Based on the input data, the model learns that the data is enough for the application and services. The appropriate amount of data value metric parameters has been learned with data prediction and classification models. The decision of whether the data is enough for the service is taken based on the threshold value. The CVO appropriate amount of data threshold value could be fixed and can also be learned based on the service quality requirement in which that CVO will be used. For example, this metric analyzed that the selected VOs data (i.e., EMG_VO, BVP_VO, Skin_temp_VOs) and properties are enough for the CVO features.
4.4. Data Quality Assessment for Semantic Data Applications
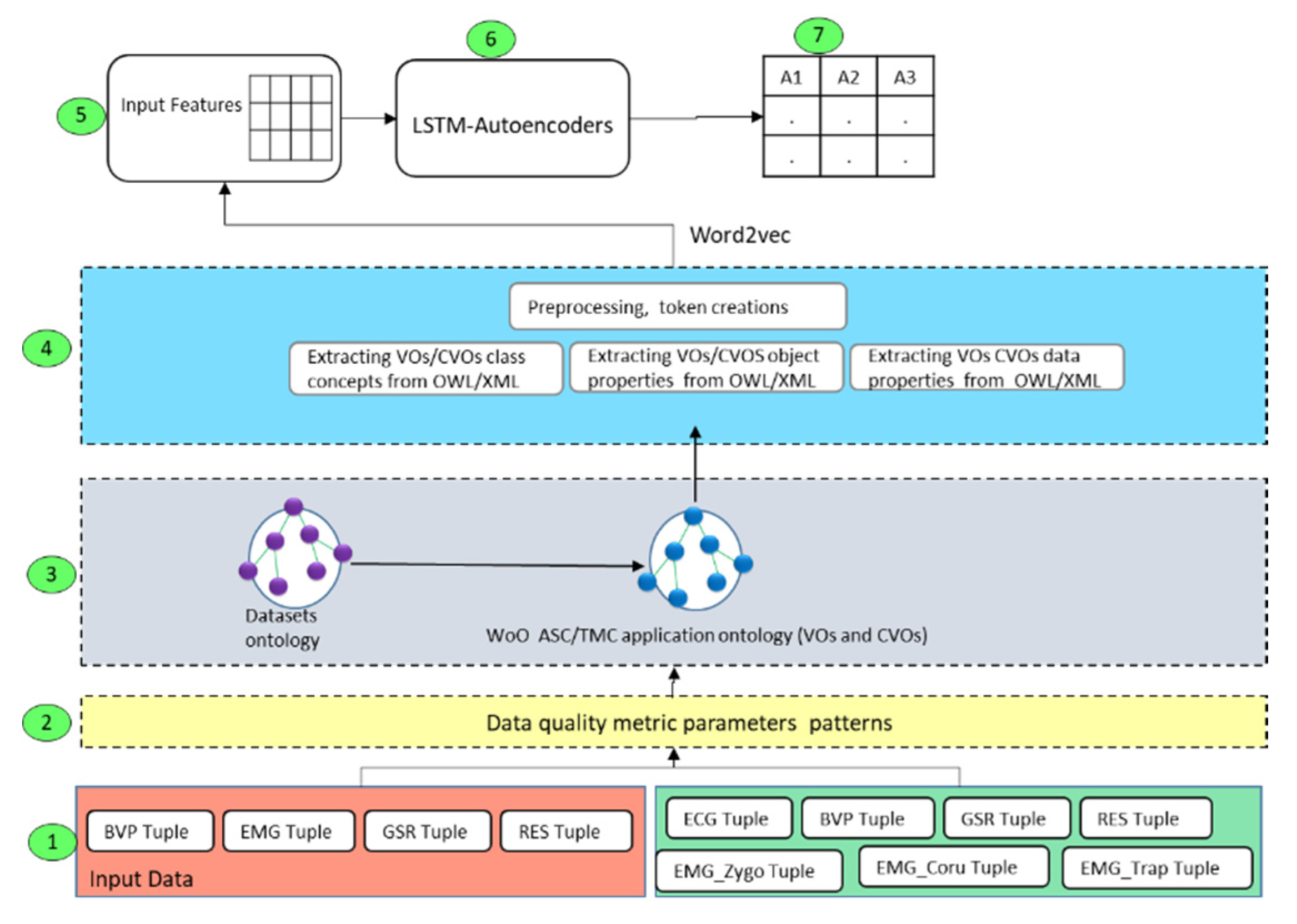
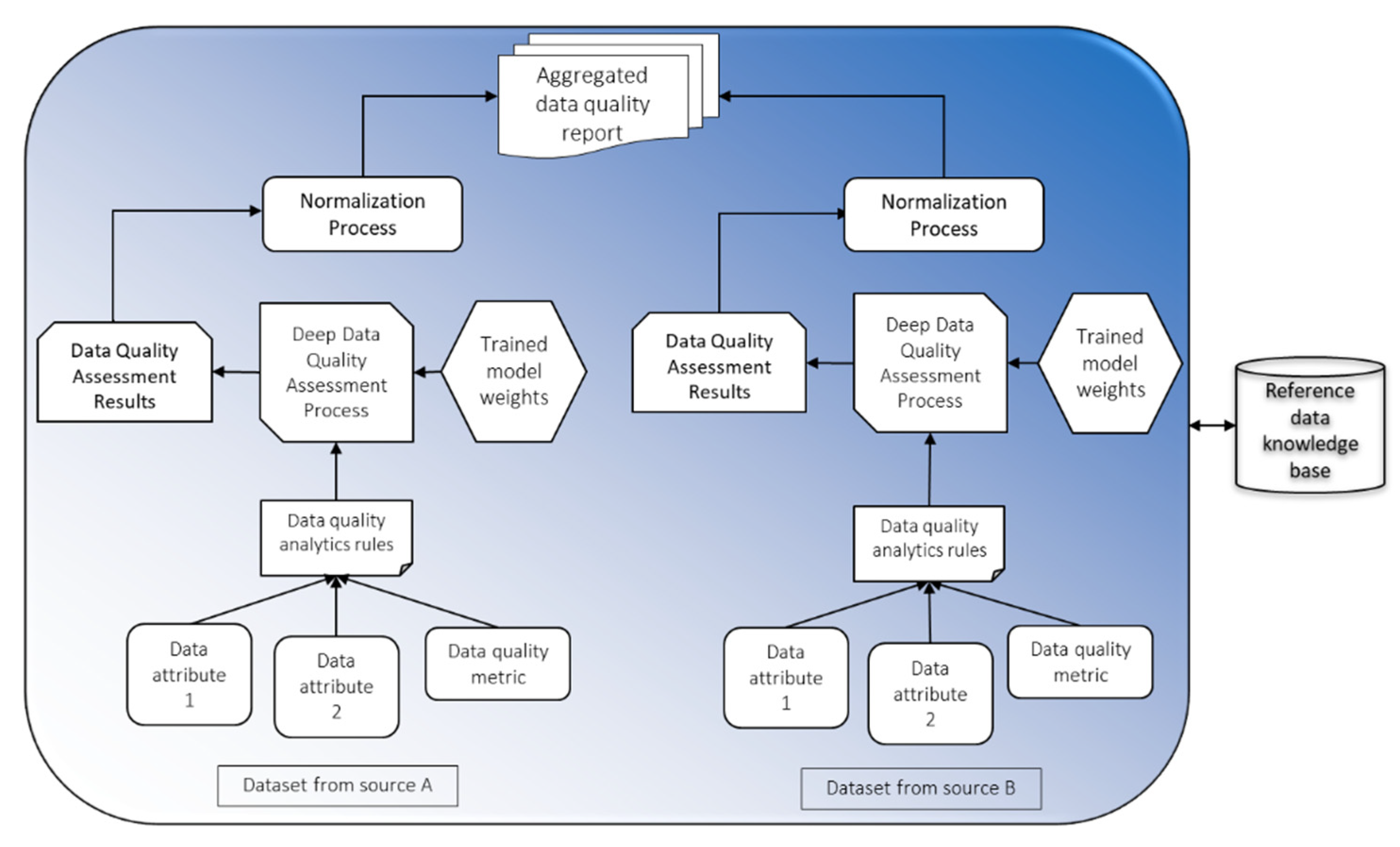
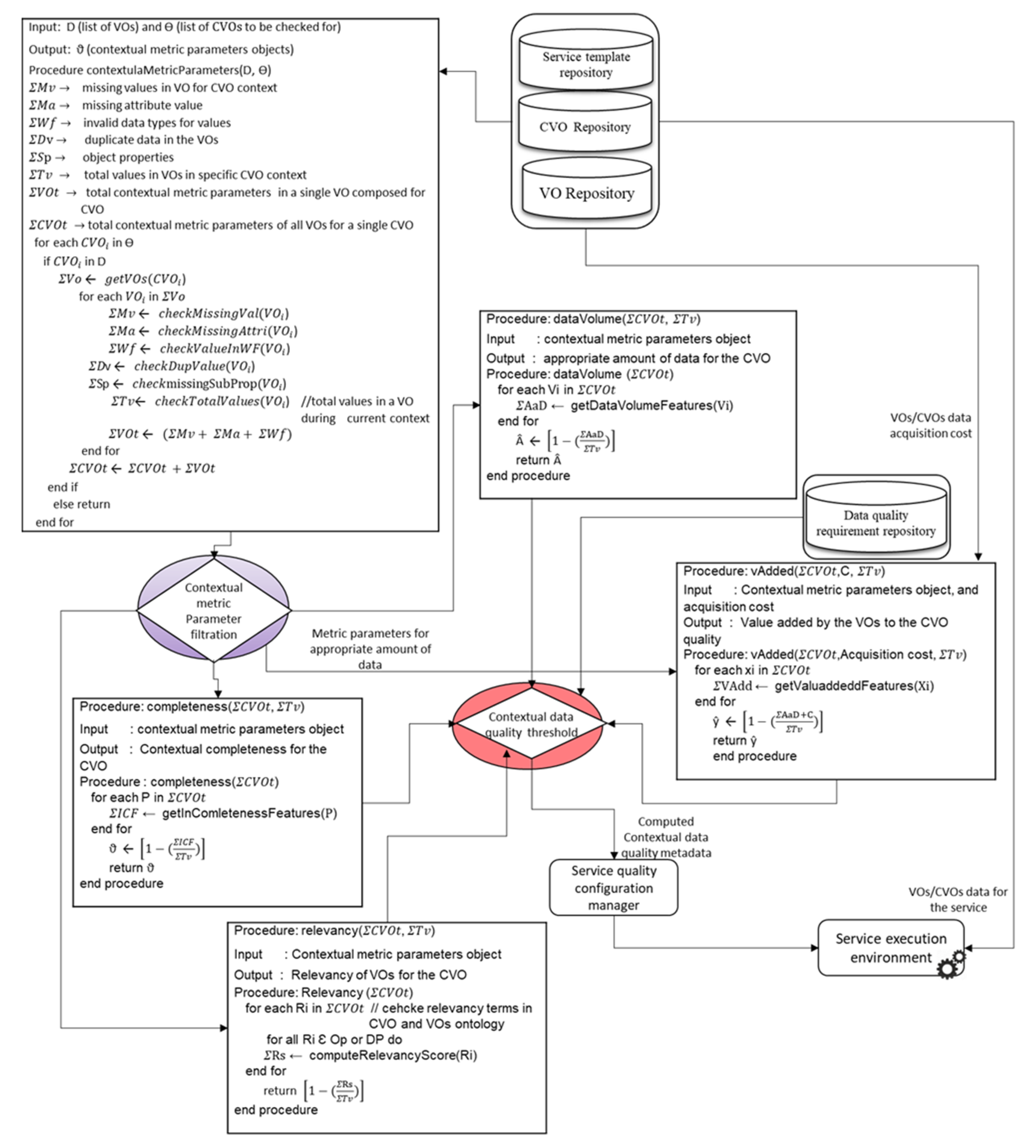
To perform the contextual data quality assessment of the semantic data applications, it is necessary that the incoming data should be transformed into the semantic data using dataset ontologies and VOs/CVOs templates. We applied the contextual data quality assessment metric parameters along with data quality functions at the data acquisition, data quality assessment, and service level. The flow diagram of applied data quality metric parameters algorithm and functions is shown in
Figure 14. For the development of contextual data quality assessment model, we designed many data repositories and data quality processing modules in order to support modularity and scalability. However, in the pseudo-code, we show a few of them for clarity and understandability. The VOs and CVOs repositories are used to store the templates of VOs and CVOs along with incoming semantic data for the applications. Among these repositories, there is a service repository that contains the application services template. We developed the data quality requirement repository, which contains the contextual data quality requirement for the CVOs and services.
Initially the semantic data of CVOs and VOs are given the input to the contextual metric parameters procedure (contextualMetricParameters). This procedure receives the two inputs as the list of CVOs (θ) along the corresponding list of VOs (□) in the current context. For each CVO, all the corresponding VOs are extracted from semantic ontology and its semantic data is assessed with various contextual data quality metric parameters. The checkMissingVal method identifies the missing data values in the VOi compulsory fields. To detect the missing attribute in the VOi, the method checkMissingAttri has been designed. This method identifies any missing attribute in the incoming data in the VOs. The information about the data attributes is referred through the semantic dataset and VOs ontology. To assess other data quality parameters that are necessary for the contextual data quality assessment various methods are designed such as method for the identifying of value in the wrong fields (ceheckValueInWF), detection of duplicate data (cehckDupValue), and identification of missing subject properties (checkmissingSubProp), etc. All the contextual metric parameters in the VOs data within the CVOs context are identified and the final contextual metric parameters object () is created for further analysis with respect to the contextual metrics.
The identified contextual data quality metric parameters are filtered by the contextual metric parameter filtration function in order to transport the relevant metric parameters. The completeness procedure takes the input as a contextual metric parameter object () and the total number of values () in VOi in the current context. In order to get the incomplete data values in the VOi the method getInCompletenessFeatures is designed. This method returns all the missing data with respect to the VOi to the and the final completeness score of VOi in the respective CVO is returned as output. The completeness procedure considers the CVOi aggregated data quality as one, therefore the ratio of incomplete data is subtracted from the total quality. In a similar way, the other data quality metric parameters are identified for the value added, relevancy, and appropriate amount of data quality metrics. The output of CVO aggregated data quality metadata is given as the input to the service quality configuration manager. This functional component is used to manage the service execution based on the available CVOs data quality. If the assessed data quality is below the defined threshold, then the service can be executed partially or otherwise. All the procedures shown in the pseudo code have been developed using the microservices pattern.
4.5. Data Quality Assessment for WoO Enabled Applications
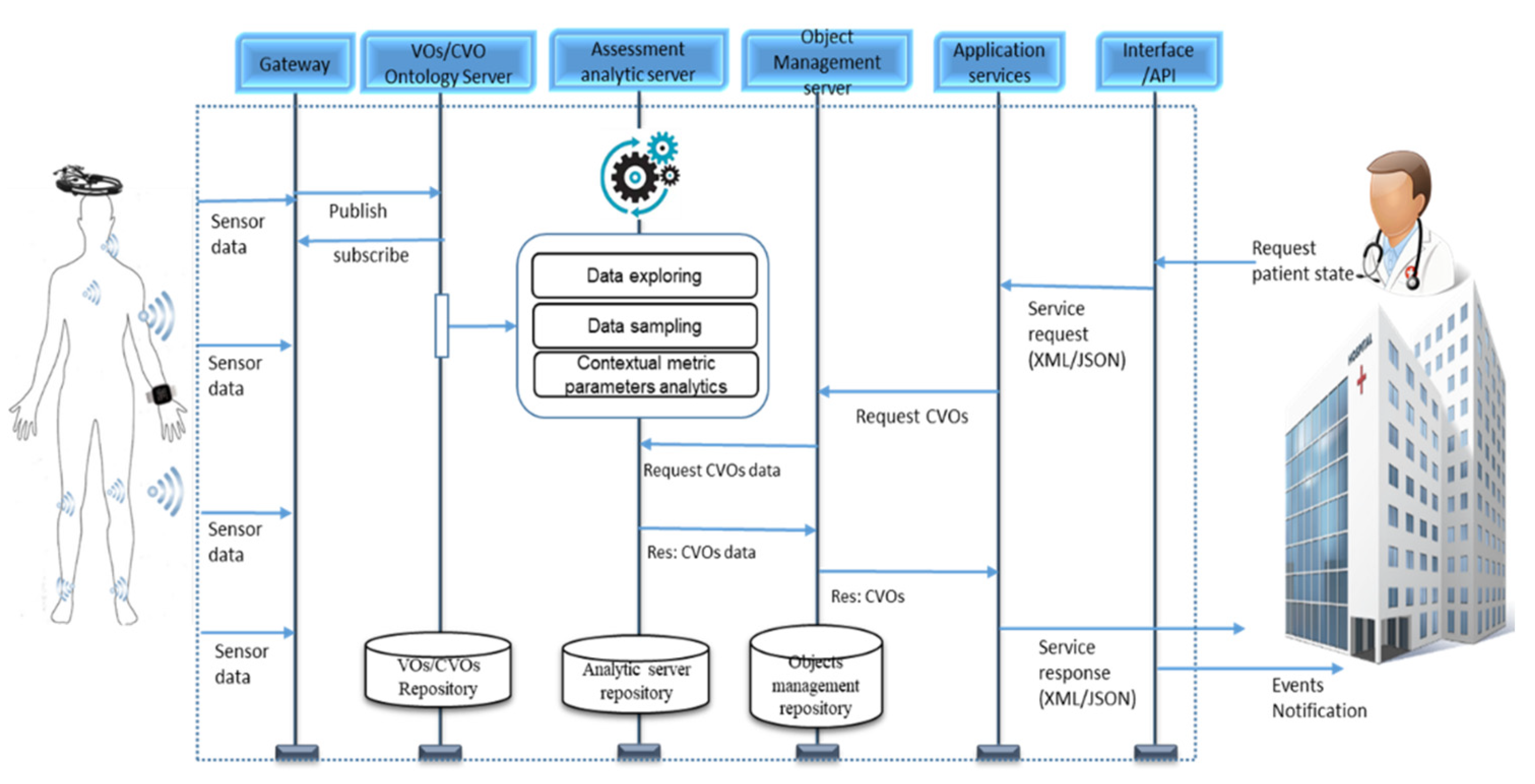
To perform contextual data quality assessment over the CVOs data, the communication between the WoO enabled ASC and TMC healthcare application model and data quality layer functions (see
Figure 8 for WoO and data quality layer to layer communications) have been done through the specially designed API interfaces. These API interfaces have been developed with HTTP REST protocol and the communication with CVOs repositories has been done through the secure SPARQL endpoints. When the CVO (i.e., stress monitoring and mood monitoring CVO) has been composed from the relevant VOs data, then the CVOs data quality analytic request has been sent through HTTP REST interface protocol to the data quality assessment layer. In order to analyze the contextual data quality as requested by the WoO healthcare application; initially, the contextual assessment deep learning models have been trained at the assessment analytics server based on the CVOs’ historical data. For the future CVOs data event only the new incoming data have been validated through contextual assessment functions. The implemented contextual assessment model’s sequence diagram is shown in
Figure 15.
As shown in
Figure 15, the physiological sensor data has been received from users at the VOs/CVOs ontology server by publishing and subscribing (HTTP REST) interfaces. Then this data has been checked and harmonized with VOs ontologies. Later based on the service request, the CVOs are composed of the VOs data and analyzed through contextual data quality assessment functions. In this contextual data quality, metric parameters are applied at the data quality assessment layer. The communication between the VOs/CVOs ontology servers and the assessment analytic server is done through HTTP REST interfaces. The data quality assessment server performs various operations before analyzing the CVOs data with deep learning models. These operations include data querying, exploring, matching and sampling. After the contextual analytics, the data quality result metadata along with CVOs data have been stored at the object management server for further using it in the services.
We developed many databases and servers in order to perform data quality assessment of the WoO enabled healthcare applications. We implemented the VOs and CVOs repository by using the apache Jena triple store. This database contains VOs and CVOs ontologies along with its data and metadata. We developed the data quality assessment analytic server database on OpenTSDB, which is suitable for the scalability and massive amount of analytic data assessment. We developed the objects management database in which the object management server stores the contextual analyzed CVOs results for further using it in the services.
4.6. Microservices for Data Quality Assessment
This section describes the modeling microservices for the contextual data quality assessment statistics and implementation aspect of web objects healthcare applications. The modeling microservices performs various types of data quality computation and statistics tasks. These tasks have been distributed into data quality classification types such as intrinsic, contextual, and representational. The data quality assessment statistics tasks through modeling microservices have been illustrated in
Figure 16.
Initially, the incoming healthcare data have been analyzed at the data acquisition level with data quality representational metrics microservices. This microservices group contains four microservices such as data uniformity, consistency, interpretability assessment, and data cleaning and preprocessing. The common data quality metric parameters are assessed only one time and the value of these parameters are shared among the microservices for metric level data quality assessment and statistics. The data quality assessment model functions such as data leakage, data retrieval efficiency and data storage efficiency checking functions have been implemented as microservices. The common parameters assessment microservices results are shared among the metrics and data quality analytic functions.
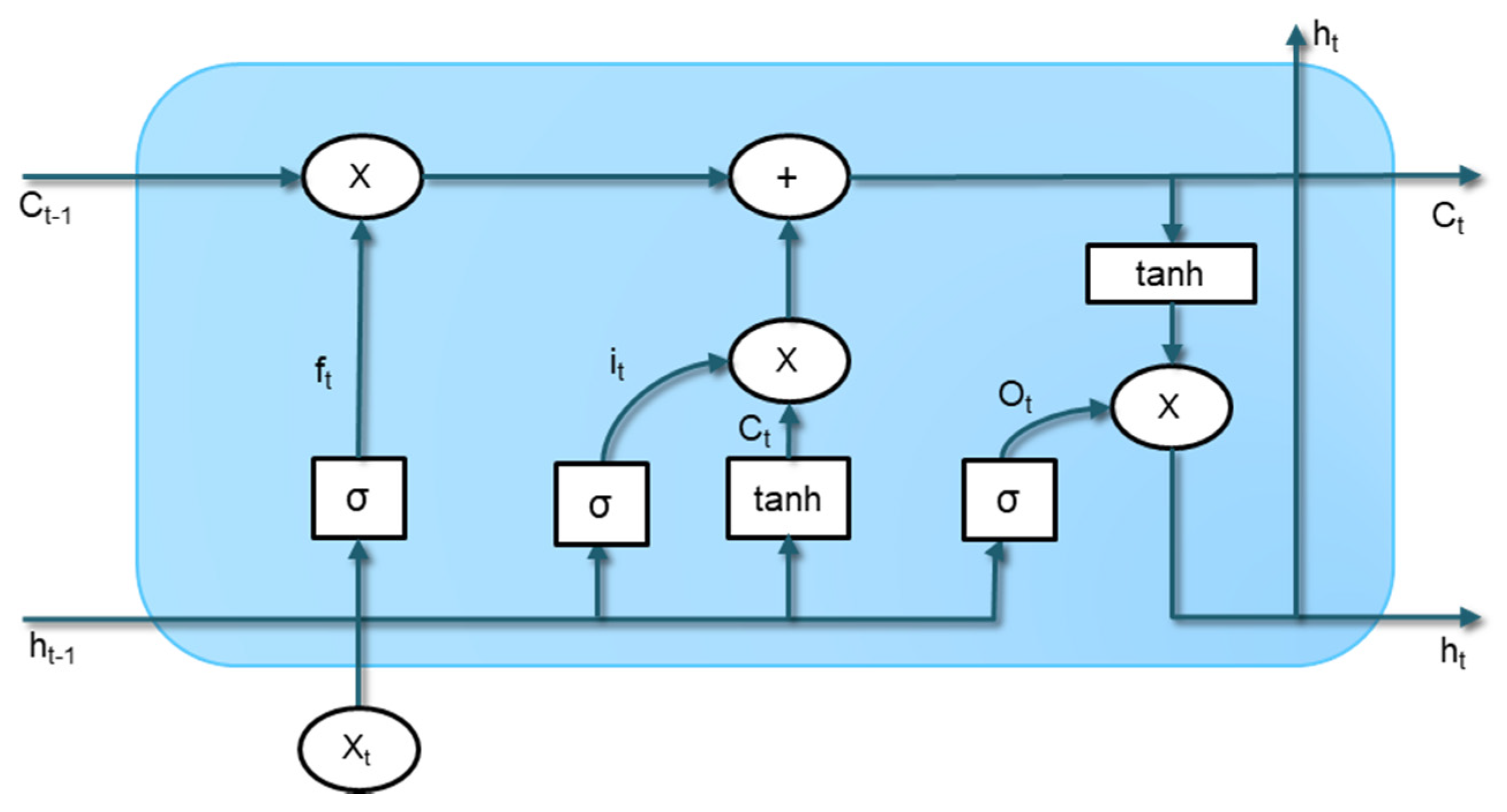
After the representational statistics checking the data has been analyzed by the intrinsic microservices for the intrinsic data quality statistics. The intrinsic statistics microservice used the machine learning and deep learning model to find a more accurate data quality level with respect to raw data. In the learning, history data and validation data are used for the model statistics validation.
The other modeling microservices learn the statistics of data quality in terms of contextual aspects such as completeness, relevancy and value added. The statistical measure such as standard deviation, moving average and mean are used in the model to learn the contextual level feature of data quality. Finally, the data quality results are distributed into high, medium and low scale with respect to the data classification categories and application requirements. The statistical microservices use microcode and deep learning libraries to learn data quality classification and statistics.
6. Result and Discussion
To evaluate the proposed data quality assessment model, an ample number of experiments have been conducted and repeated in order to reduce the chance of errors. In the first experiment, we analyzed the ASC and TMC applications CVOs’ contextual data quality assessment with respect to the completeness metric parameters. In the second experiment, we perform the data quality assessment with respect to the appropriate amount of data quality metrics parameters and in the third experiment, the overall data quality assessment of ASC and TMC VOs and CVOs semantic data has been performed. We also analyzed the data acquisition cost for the semantic data of VOs and CVOs. These data acquisition functions have been implemented with containerized microservices that have many numbers of instances to process semantic VOs and CVOs data from the repositories. The VOs and CVOs semantic data repository has been created using the apache Jena triple store [
61]. In all the experiments of data quality assessment learning model, the datasets have been distributed into 80% and 20%. The 80% data is used in the model training and tuning the parameters; and the samples from 20% data is utilized in the model testing and evaluation, because to keep the testing and evaluation dataset samples away from the training and tuning samples is an independent evaluation approach [
62,
63]. The deep learning model has been configured to 100 epochs with an early stopping parameter setting as used in [
64] and in this setting the developed model converged quite well. We evaluate our data quality assessment deep learning models efficiency based on the f-measure, mean absolute error (MAE), root mean square error (RMSE), and Pearson correlation coefficient (PCC) metrics. The deep data quality assessment model average f-measure, MSE, RMSE, and PCC were 0.98, 0.00079, 0.0089, and 0.97 respectively on both applications (i.e., ASC and TMC) semantic data quality assessment. The data quality assessment learning model has been implemented using TensorFlow. In the experimental model, we used a machine with configuration including Intel Core i7 with 3.4 GHz clocked, 32 GB RAM and NVIDIA GeForce GTX configuration.
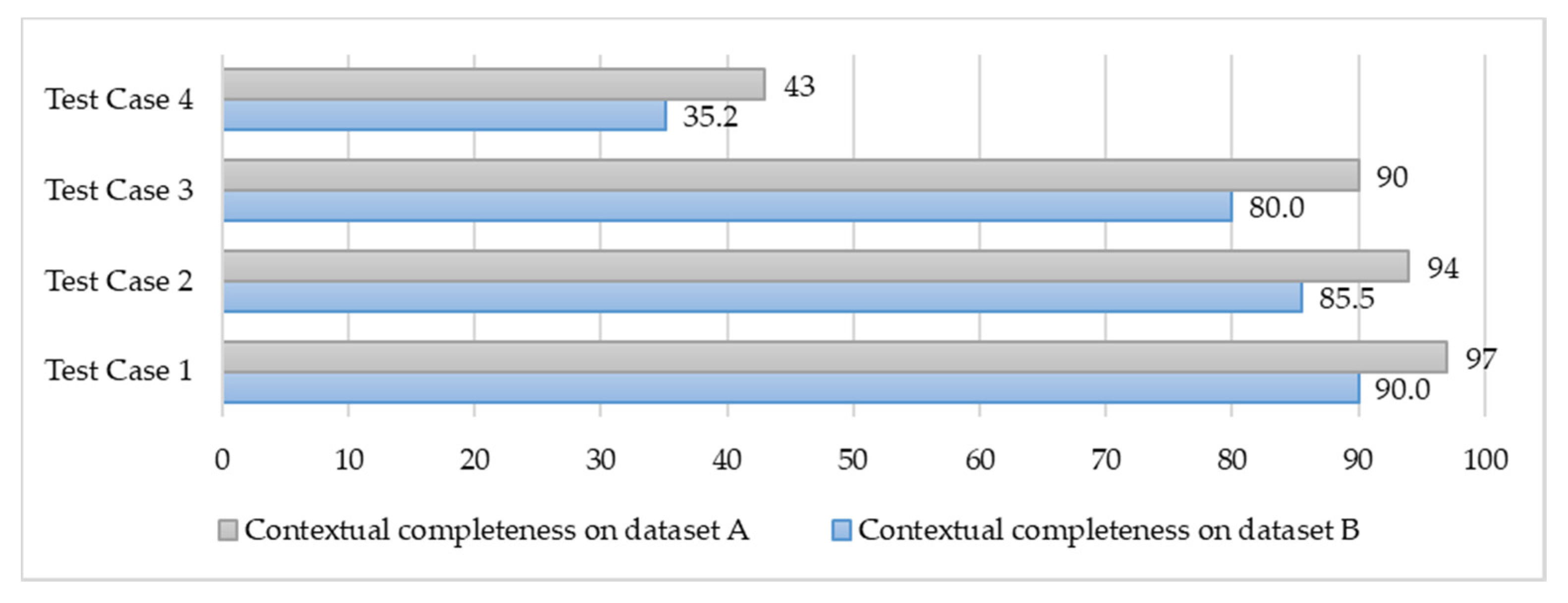
The contextual data quality assessment has been analyzed with aggregated data assessment functions. In the contextual data quality analytics, the VOs (VO_BVP, VO_ECG, VO_Skin_temp, and VO_RES) data have been aggregated and harmonized in a Stress_monitoring_CVO and Mood_monitoring_CVO context by using aggregated assessment function. Therefore, this type of assessment may also be called as aggregated assessment. In
Figure 26 the data values at the x-axis show the model prediction capability with respect to four test cases for the ASC application CVOs with semantic data from dataset A and B. For the contextual completeness assessment, the Stress_monitoring_CVO with four VOs data has been analyzed. In the test case one, VO_BVP, VO_ECG, VO_Skin_temp, and VO_RES data have been considered as 100% complete and we received the model learning capability 97% and 90% with dataset A and B respectively. In the second test case, the Stress_monitoring_CVO data reduced to 90% by manipulating 10% of data from all the relevant VOs. In this case, we received 94% and 85.5% model learning capability with dataset A and B respectively. During the third case, the Stress_monitoring_CVO completeness remains at 60% because we intentionally add 40% invalid data with respect to metric parameters. And in this case, we received 90% and 80% results. In the last fourth case, the Stress_monitoring_CVO completeness model learning capability remains at 43% and 35.2% on dataset A and B respectively.
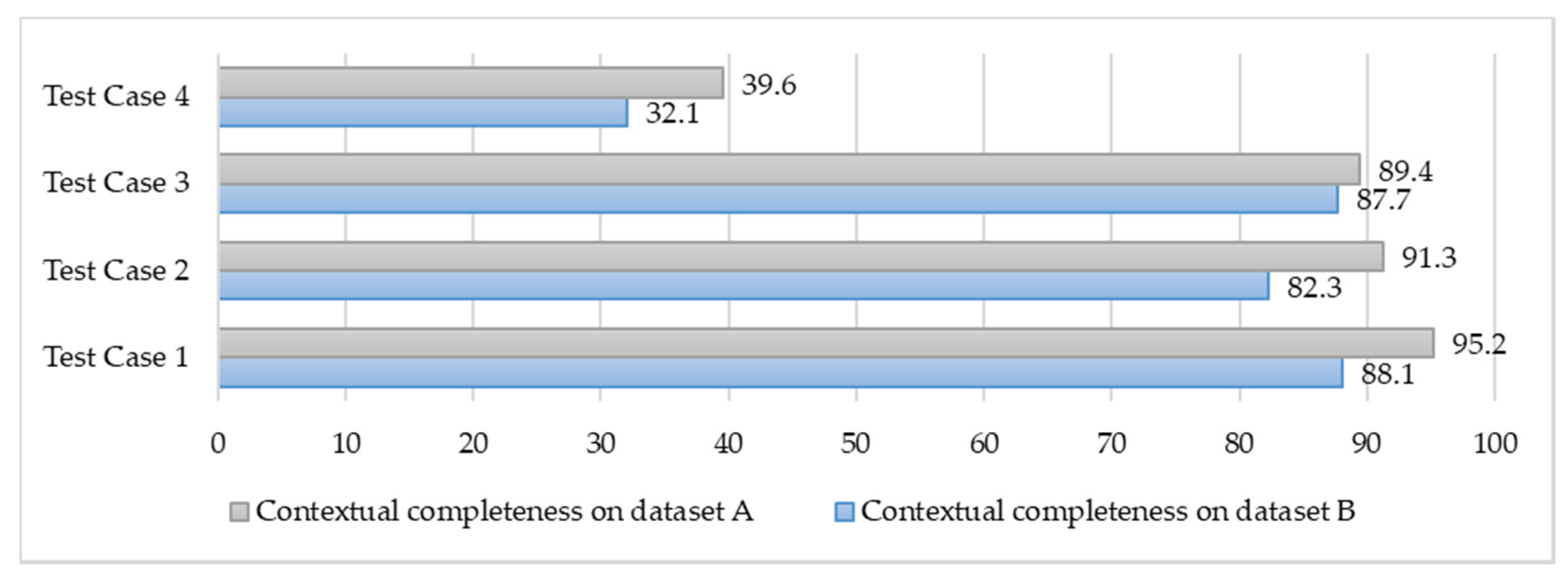
The TMC application’s Mood_monitoring_CVO has been analyzed in the contextual data quality assessment. In the TMC Mood_monitoring_CVO context, VOs (Plus_VO, Skin_temperature_VO, Heart_rate_VO, and Facial_muscle_VO, Blood_presure_VO) data have been aggregated and analyzed simultaneously with a deep learning model. The relevant VOs data for a CVO have been distributed into four test cases as we did for the ASC application, however this time the application ontology is different. As shown in
Figure 27, during the contextual analytics we received the highest classification capability as 95.2% and 88.1% with semantic data from dataset A and B respectively. In this case, we used the master dataset along with VOs (Plus_VO, Skin_temperature_VO, Heart_rate_VO, Facial_muscle_VO, and Blood_presure_VO) in the context of Mood_monitoring_CVO ontology. In the second case, the deep learning model was able to detect the Mood_monitoring_CVO completeness with 91.3% and 82.3% on dataset A and B respectively. In the last test case, the model only received detection capability of 39.6% and 32.1% on dataset A and B respectively. Hence, it has been observed that when there are many invalid data quality metric parameters of completeness metric, the contextual quality of Mood_monitoring_CVO has been decreased significantly.
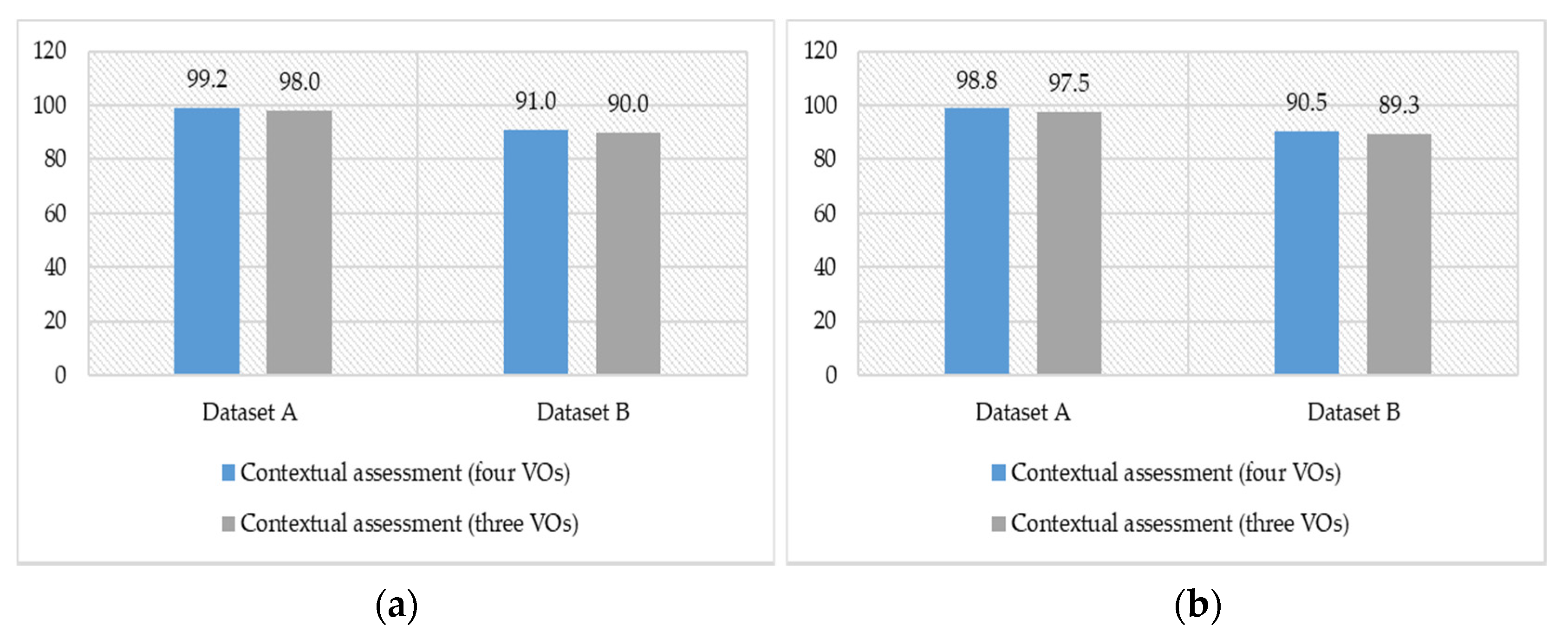
In the second experiment, we applied the appropriate amount of data quality metric parameters and create the representation of semantic data input to the deep learning model. To create the features and data representation of this metric, we applied the aggregated data quality assessment function over the VOs semantic data that have been composed in the CVO context. We also analyzed this metric with four test cases and the average results on both datasets are shown in
Figure 28. In this experiment, two sets of CVOs for ASC and TMC applications have been created. The first set of CVOs includes four VOs and the second one received data from the three VOs. For the ASC application set, the model classification quality assessment with four and three VOs was 99.2% and 98.0% on dataset A and 91% and 90% on dataset B respectively. In the TMC application set, the model classification capability with respect to the appropriate amount of data quality metric is 98.8% and 97.5% for three VOs set and four VOs set respectively when the input data was from dataset A.
During the data quality analytics experimentations, the semantic data repositories of VOs, CVOs, and services have been created. The instances of dataset A and B have been transformed and represented as semantic data with VOs and CVOs ontologies [
52] and stored in the repositories. Then this data has been collected and analyzed in terms of contextual data quality. The results of semantic data acquisition costs are shown in
Figure 29. To demonstrate the features in data acquisition and analytics we simulated semantic data up to 800 CVOs and 1000 VOs. On 600 CVOs and 600 VOs semantic data, the acquisition cost has been observed averagely at 14.45 s and 12.2 s respectively. The data acquisition model for retrieving of VOs and CVOs data have been tested with many concurrent requests by using the Apache HTTP server benchmarking tool [
65].
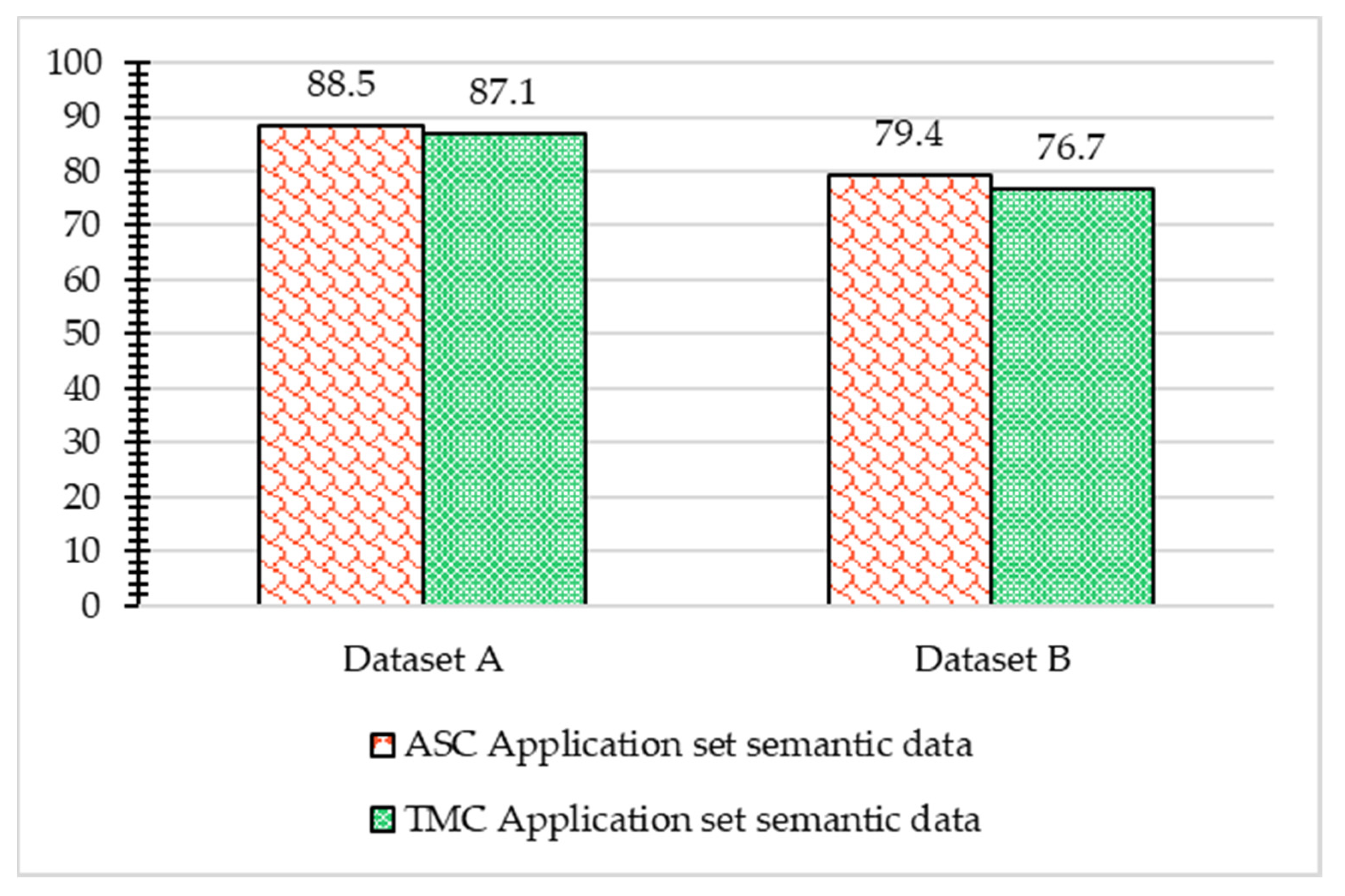
The developed data quality assessment mechanism has also been analyzed with respect to the overall data quality analytics of developed WoO enabled ASC and TMC healthcare applications. The CVOs semantic data of both applications have been evaluated with the incoming data from dataset A and B; The average of all analyzed data quality metric parameters and data transformation and acquisition cost on VOs and CVOs has been considered in the overall data quality of the ASC and TMC applications as shown in
Figure 30.
The ASC application VOs and CVOs semantic data quality remains at 88.5% and 79.4% with dataset A and B respectively and for the TMC applications, the data quality was 87.1% and 76.7% respectively. The trend of data quality assessment results of the ASC and TMC application remains the same in all the data quality metric parameters analytics. Assessment results of both applications re different although the data is similar, because both applications are using different ontology set of VOs, and CVOs with respect to the data quality usage context and requirements. The results of our approach prove that once a deep learning model is trained on high quality semantic data, it can be used to classify the incoming data quality for the task in hand. Moreover, when the quality of data decreases to a certain level, the model’s learning quality also decreases.
7. Conclusions
Due to the technological advancement in Internet of Things (IoT) and Artificial Intelligence (AI), a gigantic amount of data is generated, integrated, and analyzed for the provision of services. Similarly, because of the convergence of these state-of-the-art technologies, a healthcare system accumulates data from numerous heterogeneous sources in a large quantity. The efficient usage of this data can increase the impact and improve the healthcare services quality. However, the quality of that data is questionable due to associated risks. The data quality is a multidimensional concept and the exact meaning of quality of data can be perceived in the application context. Therefore, the data quality should be analyzed in the application aspect. To analyze the quality of data we need many data quality metric parameters and mechanisms to find out the relation among the various types of data and its quality requirement. In this article, we proposed the WoO based data quality assessment classification and analytics mechanism with various data quality metric parameters, VOs and CVOs semantic ontologies. The novelty of this article is the development of data quality assessment metric parameters and assessment mechanisms for WoO enabled healthcare applications. Another important contribution is the advanced semantic ontology based data quality analytics at the data acquisition and assessment level. This model supports the learning of data quality analytics for domain applications such as WoO enabled healthcare applications. The functionality of a proposed data quality assessment mechanism can be generalized to other industry domains by incorporating data quality requirements and contextual services threshold values. For this purpose, the same VOs and CVOs ontologies can be reused; however, the data quality assessment business rules should be changed accordingly. The data quality assessment mechanism proposed in this paper is more useful for a noncapital intensive industry rather than a capital intensive industry, because to deploy high quality data sensing nodes and data quality assessment mechanism at the edge level requires a huge investment. In the future, we would like to evaluate the data quality assessment model with other deep learning models such as transfer learning, etc., and the development of a mechanism for the selection of contextual data quality metric parameters automatically based on the nature of incoming data and applications domain.





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}