1. Introduction
The evolution of cloud computing paves the way for realizing the long-held dream of the deliverance of computing resources as a utility to users. The applications, development environments and infrastructure services are delivered to the users through large and small datacenters [
1]. However, the datacenters persistently suffer from their ever-increasing energy consumption and CO
2 emissions. Besides this, the money spent on energy consumption by a datacenter plays a crucial role in deciding the cloud provider’s service cost [
2]. According to the natural resources defense council (NRDC) report [
3], U.S. datacenters’ energy consumption is expected to reach 140 billion kilowatt-hours of electricity in the current year of 2020, which is equivalent to 50 large coal-based power plants emitting nearly 150 million tons of carbon dioxide (CO
2). Further, the report emphasizes that the best energy efficiency practices and policies could reduce electricity use by 40%. Due to this, energy consumption reduction has become a crucial design parameter in modern datacenters [
4]. Interestingly, the primary source of energy consumption in a datacenter is its enterprise servers, which consume more than 60% of the overall energy [
5]. At the granular level, the power consumption of enterprise servers can be categorized into static and dynamic: static power consumption is due to powered-on servers with no circuit activity, whereas dynamic power consumption is due to the switching of transistors during workload execution. On average, 30% of the existing servers are comatose, meaning that they are idle and contributing to static power consumption [
6]. Further, more than 80% of the information technology (IT) budget is spent to keep them running as an essential measure to ensure availability, which is an overestimated resource requirement. To meet the service level agreement, it is essential to keep all servers running. An idle server consumes approximately two-thirds energy of its 100% utilization at full load [
7,
8,
9]. In addition, it is noteworthy that idle power and dynamic power consumption on a utilization level varies based on the different power models of physical servers. The energy reduction caused by shrinking the number of existing resources by virtual machine (VM)-consolidation may spin-off lower-level resource availability resulting in jeopardizing the goodwill and credibility of the provider. Utilization of the server at a high voltage results in a high temperatures and shorter lifetime. Optimal server utilization provides an optimized power consumption of central processing unit (CPU) resources resulting in the increased lifetime of the resource with a power consumption that is limited to its specification. The computation capacities of the servers have to be realized and optimum utilization of resources should be achieved [
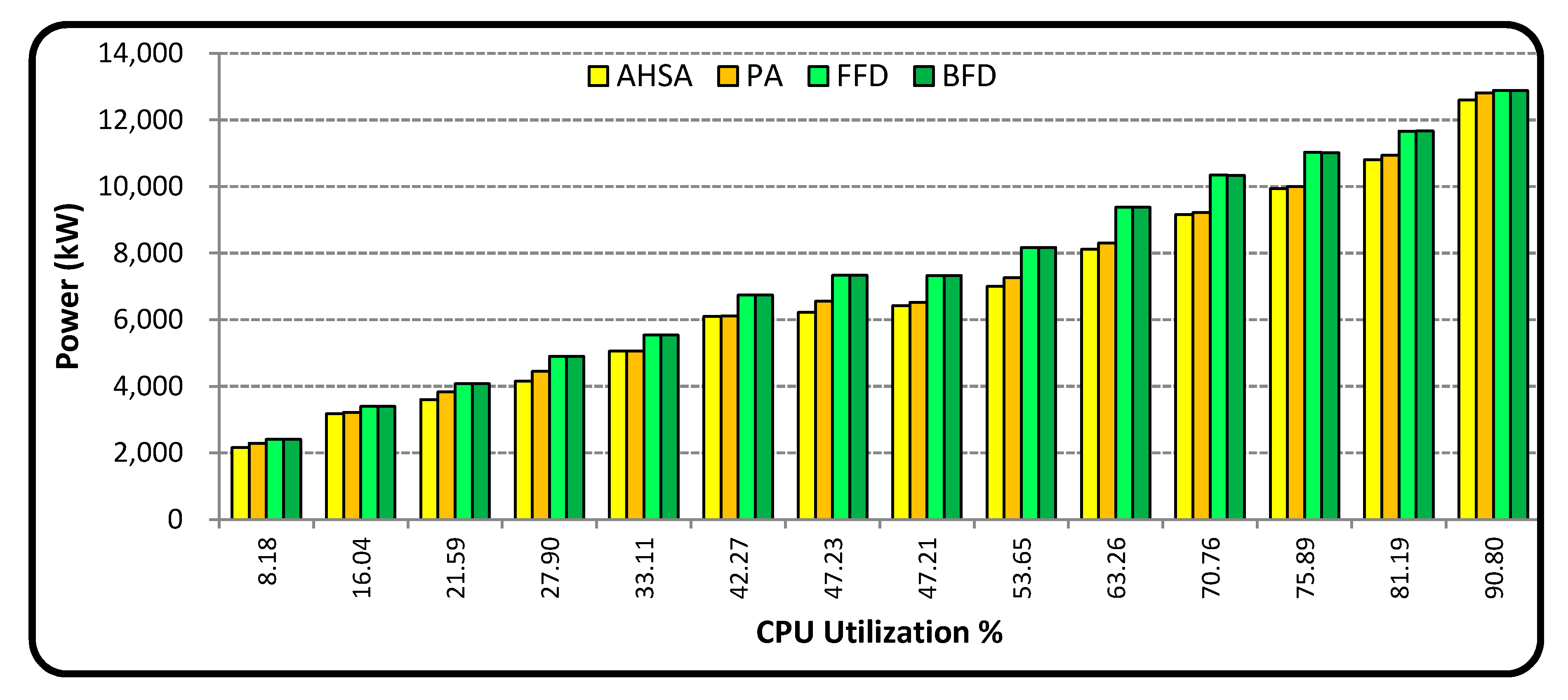
10] to reduce idle and active servers’ power consumption. By considering the above-mentioned advantage, in this research work an adaptive harmony search algorithm (AHSA) and power award (PA) algorithm is proposed to achieve minimum power consumption of the servers.
The rest of the paper is organized as follows: Firstly, general facts about the datacenter power consumption are outlined in
Section 1. Secondly, several closely associated research works are given in
Section 2. Following that, the research problem formulation is given in
Section 3. Subsequently,
Section 4 elaborates on the algorithms that are considered in this research work. Afterwards, the virtual machine distribution algorithm is explained in
Section 5. Then, the experimental set-up for evaluation, results and discussions about the significance of load balancing are discussed in
Section 6. Finally,
Section 7 concludes the findings of this research work.
2. Related Works
A multi-objective genetic algorithm is proposed for dynamic demand prediction to minimize energy consumption and increase resource utilization [
11]. Many heuristic algorithms have been used in the VM placement problem: ant-colony-based VM placement is formulated as a multidimensional bin-packing problem to control resource wastage and energy consumption simultaneously [
12]. Group technology-based cuckoo optimization technology is used to control the datacenter’s operating cost, considering task migration, VM creation and energy consumption [
13]. An improved practical swarm optimization is used to increase the quality of service with reduced power consumption [
14]. A nature-inspired genetic algorithm and bacterial-foraging algorithm are used for efficient task scheduling to reduce energy consumption and to minimize the overall makespan of the task [
15]. A modified genetic algorithm is proposed by generating an initial population with the Max–Min approach to get a better makespan [
16]. A new heuristic embedded with the ant colony is proposed to reduce energy consumption [
17]. The nature of the harmony search algorithm adopts itself to suit both discrete and continuous variable problems [
18]. Virtual machine consolidation is performed using harmony memory search by reducing the number of active machines along with the quality of service requirement [
19]. Ant-colony-based consolidation of VMs is utilized to minimize energy consumption with acceptable performance levels [
20]. The modified practical swarm optimization approach is used to perform virtual machine consolidation with an aim to reduce power reduction using CloudSim [
21]. Meta-heuristic approaches are a considerable alternate to obtaining a solution that offers a trade-off between computational cost and the best fitness solution for NP (non-deterministic polynomial-time)-hard problems. There is no single global optimal algorithm that derives the best optimal solution in all optimization schemes [
22]. A few optimization algorithms, like ant colony and genetic algorithms, follow the search path of recently generated partial solutions, few others provide a single-point search solution, in which the search path is decided based on the solution generated at each interval. Many meta-heuristic algorithms are population-based, storing a set of feasible solutions in the search path, which paves the way for efficient exploration in global search space.
Metaheuristic algorithms have been identified as efficient tools to solve engineering design problems [
23]. Harmony Search Algorithm (HSA) has been used in the majority of applications, like power and energy management, distributed generation and capacitor placement, transmission network planning, job scheduling, neural network training, water pump switching, water distribution network, heat and power economic dispatch, charge scheduling of energy storage systems with renewable power generators, estimation of life cycle cost and carbon dioxide equivalent emission of the buildings [
24,
25,
26,
27,
28,
29,
30] and so on. A hybrid approach, coral reefs optimization has been used to tackle the feature selection problem for an extreme learning machine prediction model for short-term wind prediction in [
31]. Optimization techniques are widely used in many sustainable energy sources such as building, environment and energy. The finding of much recent scientific research works highlights the growth and popularity of optimization approach towards the reduction in the CO
2, energy consumption and power cost. The potential and strength of meta-heuristic algorithms in exploration and exploitation have made its applicability in sustainable energy optimization problems possible, which is the current need [
32]. The increasing demand for the power and environmental challenges of global warming has made renewable energy (solar, wind and hydro) an inevitable substitute of existing power sources to reduce greenhouse gas emissions. The attention and expansion of solar energy have increased due to a decrease in its installation cost. Despite its cost, there is a need to overcome the regulatory, technical barriers to achieving its growth [
33].
The most efficient server first greedy task scheduling algorithm considers the energy profile of the servers and allocates the task to the servers with a minimum increment in overall power consumption. The energy reduction is achieved by two factors: (i) by reducing the number of active servers, (ii) by choosing an appropriate server for task placement [
34]. The most urgent, CPU-intensive, Bag-of-Task scheduling is performed by introducing a dynamic voltage frequency scaling intelligence in the scheduling algorithm to achieve power reduction [
35]. Energy reduction is achieved by executing the processors in minimum frequency level and the quality of service is maintained by executing the tasks within the deadline. The unbalanced resource usage, high energy usage and the number of migrations are handled by task categorization and a resource utilization square model [
36]. The weight function is applied to each task based on its resource requirement for task categorization. The individual resource is ranked based on its utilization via the resource utilization square model and the resource famine is reduced by efficient VM consolidation by selecting energy-efficient target servers. The sufficient utilization of green energy, maintaining the required resource demand within the datacenter is achieved by combining the heuristics and statistical approaches. The optimization problem for cost reduction is formulated considering the server and cooling device’s power consumption, aiming at overall net revenue.VM migration is based on the joint optimal planning on two parameters: maximum profit and maximum green energy utilization [
37]. Scheduling of workflow considering data file assignment reduces the execution time of the task with reduced overall makespan. The distribution of the tasks and data are considered as a single dependent problem, rather than two independent problems. A hybrid evolutionary algorithm-based task scheduling and data assignment approach outperforms the standard approaches, Min-Min and heterogeneous earliest finish time [
38]. VM placement and data placement are considered as a single problem to reduce cross-network traffic and bandwidth usage. Ant colony optimization was used for the selection of physical machine’s (PMs) for the placement of data adjacent to VMs. Data, placed in close proximity to the VM, with the decrease in VM communication distance, resulted in a reduction in job completion time [
39]. A queuing structure to handle a large set of VMs and crow-search-based multi-objective optimization was used to reduce resource wastage and power consumption in datacenters [
40]. The results were compared against the genetic algorithm and the first fit decreasing approach. The live migration was handled in serial, parallel and improved serial methods. A hybrid krill herd optimization algorithm with an eagle strategy was used for VM expansion during heavy load to maintain the quality of service agreement. The problem of eccentrics and congestion was handled by a new proposed change and response and agreement protocol by monitoring the packet delay, latency and throughput. The experimental results of the hybrid krill herd optimization approach were compared against particle swarm optimization, ant colony optimization, genetic algorithm and simulated annealing [
41].
In this article, AHSA, a population-based method suitable for solving continuous and discrete optimization problems, is proposed to reduce the power consumption of the servers. AHSA holds its strength in obtaining a new solution by considering both the probabilistic parameters of all the individual values of the initial harmony and independent variable tuning (stochastic operators). The additional credit is that the rate of convergence and quality of the solution does not depend on initial values, such as a gradient-search. The objective function used in AHSA could satisfy the analytical and differentiable metric.
3. Problem Formulation
Let V = {
V1,
V2,
V3, …,
VN} represent the
N number of reserved VMs with operating frequency (
F1,
F2, F3, …,
FN), cores (
C1,
C2,
C3, …,
CN) and execution time (
τ1,
τ2, …,
τN). Each
Vi where
i ε [1,
N] can be characterized as a triplet (
Fi,
Ci,
τi), thus
Fi represents reserved frequency, and
Ci represents the number of cores,
τi represents the execution time reserved for
Vi. Let
S = {
S1,
S2,
S3, …,
SM} represents
M number of heterogeneous servers, each with
k number of discrete frequencies (
f0,
f1,
f2,
f3, …,
fk+1) with utilization(
U0,
U1,
U2, …,
Uk+1),
U0 = 0%,
Uk+1 = 100% and dynamic power (
P0,
P1,
P2 P3, …,
Pk+1). U
0 is idle state with power consumption
P0. Each
Sj, where
j ∈ [1,
M] with utilization (
Uj,0,
Uj,1,
Uj,2, …,
Uj,k+1) and power consumption (
Pj,0,
Pj,1,
Pj,2,
Pj,3, …,
Pj,k+1) can be characterized as a triplet (
Utlj,
Pj,
TCj), where
Utlj is the current utilization of server
Sj, Pj, is the power consumption of server
Sj, where as the
TCj is the total processing capacity of S
j. The relation
R between
jth physical machine (PM) and
ith VM indicates whether
VMi is placed in
PMj, i.e.,
The Service Level Agreement (SLA) is measured using the Ratio of VM Acceptance (RVA) calculated as
where,
N is the total number of VM requests submitted and
T(
R) is the total number of VM requests accepted and mapped to available PMs. It is derived as
3.1. Objective Function
The VM requests (
ReqQ) are accepted at the beginning of each reservation cycle. The VM request in
ReqQ with
(Fi,
Ci,
τi) remains constant.
τi is the total number of reservation cycles reserved by the VM for the resource (
Fi ×
Ci).
Utlj(t) is the current utilization of server
j. The power consumption of
jth physical machine with utilization
l at time
t is represented as
and derived as [
42]
where,
Uj,l ˂
Utlj(
t) ˂
Uj,l+1, 0 ≤
l <
k + 1.
The energy consumption of
jth PM within a reservation cycle (
rc) can be calculated as
The total energy consumption of all the PMs within a reservation interval [0,
rc] can be calculated as
The energy consumption (
E) of all the physical machines in the data center within an interval [
0,
T] can be partitioned as number of reservation cycles (
nrc) segments and it is obtained by
The resource allocation problem in datacenters is formulated as
The objective function
G(
x) is subject to the following constraints:
The total number of VM’s allocated to a machine should not exceed the servers computing (
CPU) and memory capacity (
mem).
The relation
R between VM and PM is many-to one, i.e.,
R ⊆ N × M if
The total energy (
eng) consumed by all the VM’s should not exceed the available brown energy (
B) at the datacenter
The total brown energy consumed should not exceed the cloud providers’ agreed upon grid electricity consumption (
G)
3.2. System Model Overview
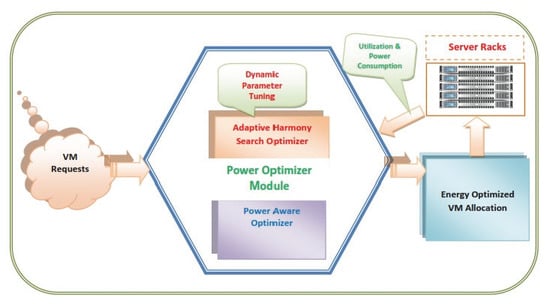
Figure 1 presents the system model of the proposed work. Each component of the system model is explained below:
Request Queue (ReqQ): The ReqQ stores the entire reserved VM provisioning request.
Physical Machine Repository (HostQ): The resource details related to available memory, CPU capacity, current operating frequency, power consumption, percentage of CPU utilization, number of active VMs, state (on/off) about all the PMs are stored in the HostQ.
Target VM Queue (TargetVMQ): TargetVMQ contains VM details about the server assigned, the percentage of CPU time utilized by the VM, submission time, placement time, remaining execution time, power consumption.
Management Node: The allocation and reallocation management (ARM) algorithm is a daemon executed in the management node. It activates the scheduling algorithm for VM to PM mapping, resource deallocation algorithm for resource recovery and task distribution algorithm for VM reallocation at specific intervals. It updates TargetVMQ, HostQ and ReqQ.
Physical Machine Manager (PMM): PMM is a daemon that is executed on each physical machine. It monitors and records the machines functional parameters. It is responsible for updating the HostQ repository with server details.
Virtual Machine Manager (VMM): VMM is a daemon that is executed on each VM. It is responsible for updating the TargetVMQ with VM functional parameter details.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}