Air Quality Prediction in Smart Cities Using Machine Learning Technologies Based on Sensor Data: A Review




Abstract
:1. Introduction
2. Methods
2.1. Research Questions
- Which machine learning techniques are used to predict air quality in the smart city domain?
- How do the proposed methods handle different types of data in terms of air pollution?
- What temporal resolutions were analysed with the proposed techniques?
2.2. Search Strategy and Inclusion/Exclusion Criteria
- Are the research aims clearly specified?
- Was the study designed to achieve these aims?
- Are the used techniques clearly described and their selection justified?
- Are the data collection methods adequately described?
- Is the purpose of the data analysis clear?
- Are the findings convincing?
- How clear are the links between data, interpretation and conclusions?
3. Results
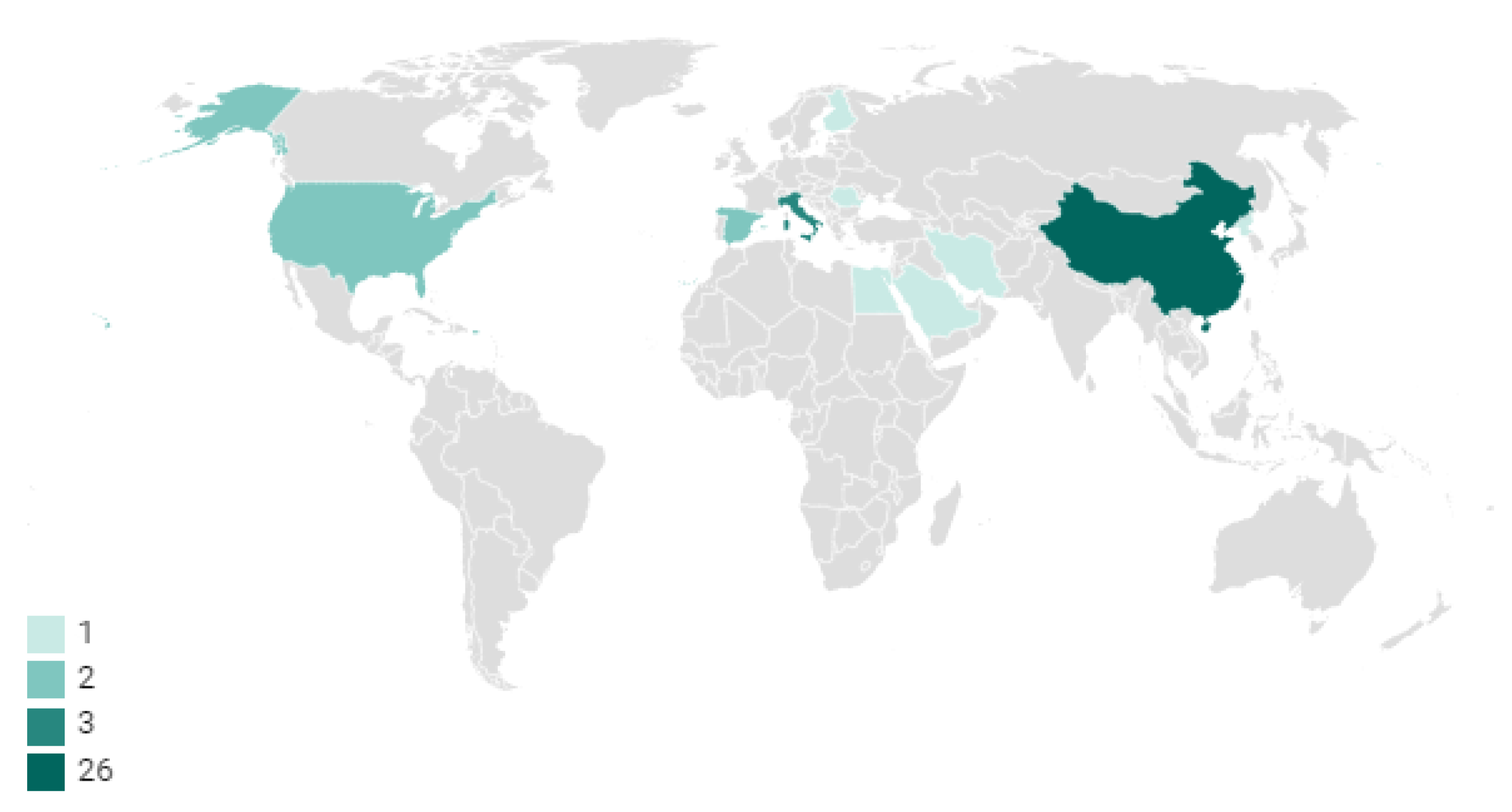
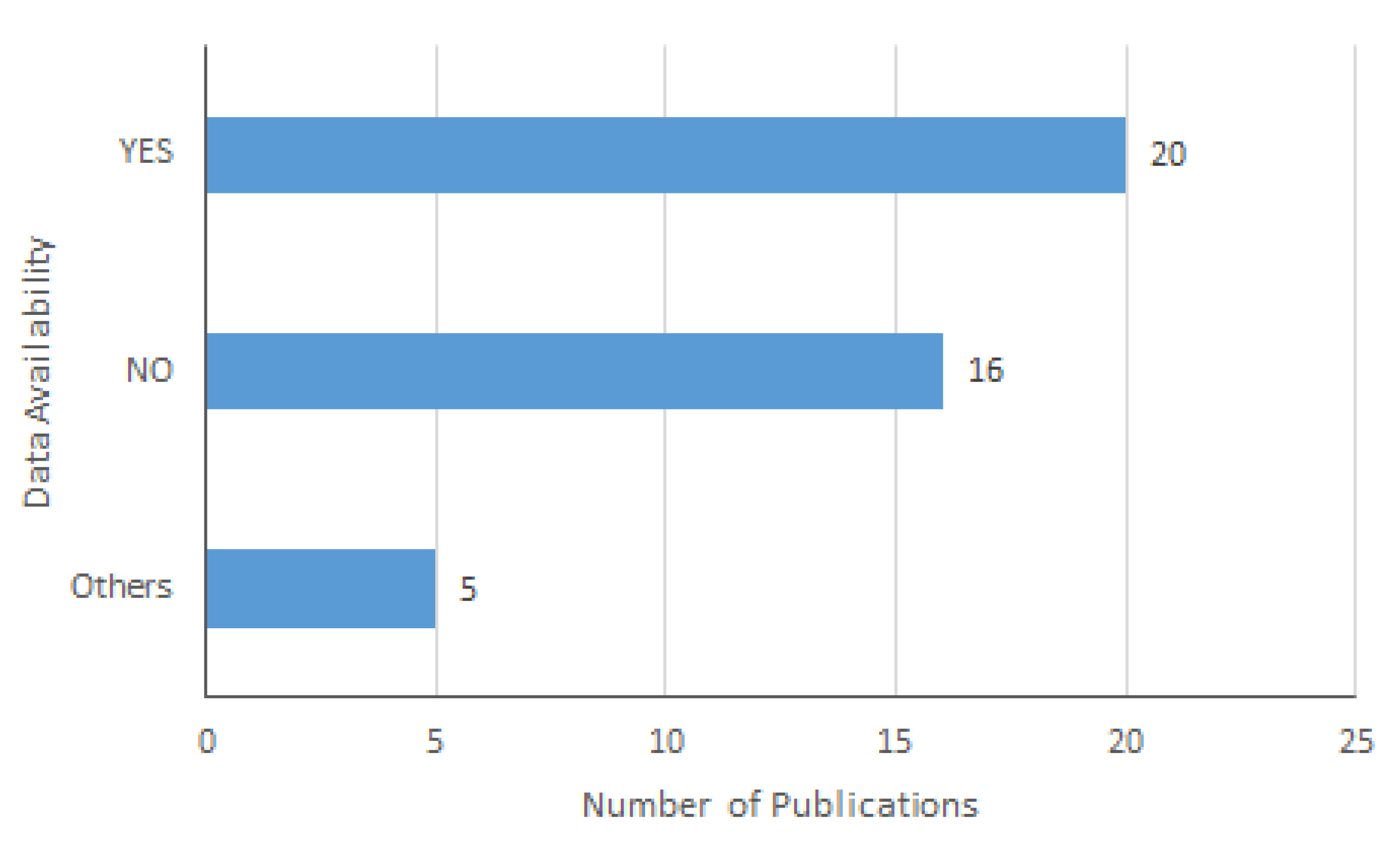
3.1. Overview of the Included Studies
3.2. Exhaustive Descriptions of Included Studies
3.2.1. Group 1: Neural Network (NN)
3.2.2. Group 2: Regression
3.2.3. Group 3: Ensemble
3.2.4. Group 4: Hybrid Model
3.2.5. Group 5: Others
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| UN | United Nations |
| ICT | Information and Communication Technology |
| WHO | World Health Organisation |
| PM2.5 | Particulate matter with diameter equal to 2.5 micrometers |
| IoT | Internet of Things |
| NN | Neural Network |
| SLI-ESN | Supplementary Leaky Integrator Echo State Network |
| mRMR | minimum Redundancy Maximum Relevance |
| ESN | Echo State Network |
| LI-ESN | Leaky Integrator Echo State Network |
| ELM | Extreme Learning Machine |
| PM10 | Particulate matter with diameter equal to 10 micrometers |
| NO2 | Nitrogen dioxide |
| CO | Carbon monoxide |
| O3 | Ground-level ozone |
| SO2 | Sulfur dioxide |
| RMSE | Root Mean Square Error |
| NRMSE | Normalised Root Mean Square Error |
| MAE | Mean Absolute Error |
| SMAPE | Symmetric Mean Absolute Percentage Error |
| R | Pearson correlation coefficient |
| BLSTM | Bi-directional Long Short-Term Memory |
| IDW | Inverse Distance Weighting |
| ARIMA | AutoRegressive Integrated Moving Average |
| SVR | Support Vector Regression |
| GBDT | Gradient Boosting Decision Tree |
| ANN | Artificial Neural Network |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
| CNN-LSTM | Convolutional Neural Network-LSTM |
| MAPE | Mean Absolute Percentage Error |
| CBGRU | Convolutional-based Bidirectional Gated Recurrent Unit |
| BGRU | Bidirectional Gated Recurrent Unit |
| GBR | Gradient Boosting Regression |
| DTR | Decision Tree Regression |
| GRU | Gated Recurrent Unit |
| UCI | The University of California, Irvine |
| CNN | Convolutional Neural Network |
| SVM | Support Vector Machine |
| RF | Random Forest |
| DT | Decision Tree |
| MLP | Multilayer Perceptron |
| IA | Index of agreement |
| seq2seq | Sequence-to-sequence |
| AAQP | Attention-based Air Quality Predictor |
| FC | Fully Connected |
| R2 | Determination coefficient |
| AIS-RNN | Adaptive Input Selection with Recurrent Neural Network |
| WNN | Wavelet Neural Network |
| FNN | Fuzzy Neural Network |
| LSSVM | Least Squares Support Vector Machine |
| DBN | Deep Belief Network |
| DBN-H | DBN-based urban haze prediction |
| DNN | Deep Neural Network |
| ACC | Accuracy |
| NOx | Nitrogen oxide |
| FFANN-BP | FeedForward Neural Network based on Back Propagation |
| MLR | Multiple Linear Regression |
| BPNN | Back Propagation Neural Network |
| C6H6 | Benzene |
| NMHC | Non-methane hydrocarbons |
| STELM | Spatio-Temporal Extreme Learning Machine |
| MRE | Mean Relative Error |
| M5P | Decision tree for regression |
| PTA | Prediction Trend Accuracy |
| NO | Nitric oxide |
| PCA | Principal Component Analysis |
| ARBF | Adaptive Radial Basis Function |
| RSP | Respirable Suspend Particles |
| WIA | Willmott’s index of agreement |
| RFR | Random Forest Regression |
| KNN | K Nearest Neighbors |
| C7H8 | Toluene |
| XIL | Xileno |
| DWT | Discrete Wavelet Transform |
| chWSVR | Chance Weighted Support Vector Regression |
| z’ | Fisher r-to-z transformation |
| nu-SVR | nu-Support Vector Regression |
| NIEHS | National Institute of Environmental Health Sciences |
| NESCAUM | The Northeast States for Coordinated Air Use Management |
| “IMPROVE” | The Interagency Monitoring of Protected Visual Environments |
| EPA | The U.S. Environmental Protection Agency |
| NAS | The Normative Aging Study |
| LR | Linear Regression |
| QR | Quantile Regression |
| GAM | Generalised Additive Model |
| BRT1 | Boosted Regression Trees 1-way |
| BRT2 | Boosted Regression Trees 2-way |
| MBE | Mean Bias Error |
| FACT2 | The fraction of prediction within a Factor of Two |
| RBF | Radial Basis Function |
| LightGBM | Light Gradient Boosting Machine |
| MSE | Mean Square Error |
| MKSVC | Multiple kernel learning model with support vector classifier |
| AQHI | Air Quality Health Index |
| IAQL | Individual Air Quality Level |
| WP | Weighted Precision |
| WR | Weighted Recall |
| WF | Weighted F1-score |
| PPB | Parts Per Billion |
| STE | Spatial-Temporal Ensemble |
| RT | Regression Tree |
| MELSA | Multi-channel Ensemble Learning via Supervised Assignment |
| AQI | Air quality index |
| RAE | Relative Absolute Error |
| RSE | Relative Squared Error |
| NMSE | Normalized Mean Square Error |
| DRR | Discounted Ridge Regression |
| IPSO | Improved Particle Swarm Optimization |
| PSO | Particle Swarm Optimization |
| CEEMD | Complementary Ensemble Empirical Mode Decomposition |
| PSOGSA | Particle Swarm Optimization and Gravitational Search Algorithm |
| GRNN | Generalized Regression Neural Network |
| GCA | Grey Correlation Analysis |
| SD | Secondary Decomposition |
| WD | Wavelet Decomposition |
| VMD | Variational Mode Decomposition |
| SE | Sample Entropy |
| BA | Bat Algorithm |
| CC | Consecutive Close |
| Baseline | The baseline model with standard Frobenius norm regularization |
| Heavy–F | The heavy model with standard Frobenius norm regularization |
| Light–F | The light model with standard Frobenius norm regularization |
| Heavy–ℓ2,1 | The heavy model with ℓ2,1-norm regularization |
| Heavy–nuclear | The heavy model with nuclear-norm regularization |
| Heavy–CCL2 | The heavy model with CC regularization using the ℓ2-norm |
| Heavy–CCL1 | The heavy model with CC regularization using the ℓ1-norm |
| Light–ℓ2,1 | The light model with ℓ2,1-norm regularization |
| Light–nuclear | The light model with nuclear-norm regularization |
| Light–CCL2 | The light model with CC regularization using the ℓ2-norm |
| Light–CCL1 | The light model with CC regularization using the ℓ1-norm |
| LMA-AV | Lansing Municipal Airport-Alsip Village |
| LU-LV | Lewis University-Lemont Village |
| SPM | Suspended Particulate Matter |
| BC | Black carbon |
| AQ | Air quality data |
| MET | Meteorological data |
| WFD | Weather forecast data |
| TIF | Traffic intensity features |
| N/S | Not Specified |
References
- Urban Population (% of Total Population). Available online: https://data.worldbank.org/indicator/SP.URB.TOTL.IN.ZS?name_desc=false (accessed on 13 March 2020).
- Urban Population Change. Available online: https://www.un.org/development/desa/en/news/population/2018-revision-of-world-urbanization-prospects.html. (accessed on 13 March 2020).
- Giffinger, R.; Fertner, C.; Kramar, H.; Kalasek, R.; Pichler-Milanović, N.; Meijers, E. Smart cities: Ranking of european medium-sized cities. vienna, austria: Centre of regional science (srf), vienna university of technology. Available online: http://www.smart-cities.eu/download/smart_cities_final_report.pdf (accessed on 31 March 2020).
- Wan, J.; Li, D.; Zou, C.; Zhou, K. M2M communications for smart city: An event-based architecture. In Proceedings of the 2012 IEEE 12th International Conference on Computer and Information Technology, Chengdu, China, 27–29 October 2012; pp. 895–900. [Google Scholar]
- Trilles, S.; Calia, A.; Belmonte, Ó.; Torres-Sospedra, J.; Montoliu, R.; Huerta, J. Deployment of an open sensorized platform in a smart city context. Future Gener. Comput. Syst. 2017, 76, 221–233. [Google Scholar] [CrossRef]
- Granell, C.; Kamilaris, A.; Kotsev, A.; Ostermann, F.O.; Trilles, S. Internet of Things. In Manual of Digital Earth; Springer: Singapore, 2020; pp. 387–423. [Google Scholar]
- Air Pollution. Available online: https://www.who.int/health-topics/air-pollution#tab=tab_1/ (accessed on 13 March 2020).
- Apte, J.S.; Brauer, M.; Cohen, A.J.; Ezzati, M.; Pope, C.A., III. Ambient PM2.5 reduces global and regional life expectancy. Environ. Sci. Technol. Lett. 2018, 5, 546–551. [Google Scholar] [CrossRef] [Green Version]
- Cohen, A.J.; Ross Anderson, H.; Ostro, B.; Pandey, K.D.; Krzyzanowski, M.; Künzli, N.; Gutschmidt, K.; Pope, A.; Romieu, I.; Samet, J.M.; et al. The global burden of disease due to outdoor air pollution. J. Toxicol. Environ. Heal. Part 2005, 68, 1301–1307. [Google Scholar] [CrossRef] [PubMed]
- Cohen, A.J.; Brauer, M.; Burnett, R.; Anderson, H.R.; Frostad, J.; Estep, K.; Balakrishnan, K.; Brunekreef, B.; Dandona, L.; Dandona, R.; et al. Estimates and 25-year trends of the global burden of disease attributable to ambient air pollution: an analysis of data from the Global Burden of Diseases Study 2015. Lancet 2017, 389, 1907–1918. [Google Scholar] [CrossRef] [Green Version]
- Rybarczyk, Y.; Zalakeviciute, R. Machine learning approaches for outdoor air quality modelling: A systematic review. Appl. Sci. 2018, 8, 2570. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Ren, W. Prediction of Air Pollution Concentration Based on mRMR and Echo State Network. Appl. Sci. 2019, 9, 1811. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Ding, Y.; Gan, V.J.; Lin, C.; Wan, Z. Spatiotemporal Prediction of PM2.5 Concentrations at Different Time Granularities Using IDW-BLSTM. IEEE Access 2019, 7, 107897–107907. [Google Scholar] [CrossRef]
- Tao, Q.; Liu, F.; Li, Y.; Sidorov, D. Air Pollution Forecasting Using a Deep Learning Model Based on 1D Convnets and Bidirectional GRU. IEEE Access 2019, 7, 76690–76698. [Google Scholar] [CrossRef]
- Liang, X.; Zou, T.; Guo, B.; Li, S.; Zhang, H.; Zhang, S.; Huang, H.; Chen, S.X. Assessing Beijing’s PM2.5 pollution: severity, weather impact, APEC and winter heating. Proc. R. Soc. Math. Phys. Eng. Sci. 2015, 471, 20150257. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.J.; Kuo, P.H. A deep cnn-lstm model for particulate matter (PM2.5) forecasting in smart cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Yan, S.; Li, J.; Qu, G.; Li, Y.; Lang, J.; Gu, R. A Sequence-to-Sequence Air Quality Predictor Based on the n-Step Recurrent Prediction. IEEE Access 2019, 7, 43331–43345. [Google Scholar] [CrossRef]
- Munkhdalai, L.; Munkhdalai, T.; Park, K.H.; Amarbayasgalan, T.; Erdenebaatar, E.; Park, H.W.; Ryu, K.H. An End-to-End Adaptive Input Selection with Dynamic Weights for Forecasting Multivariate Time Series. IEEE Access 2019, 7, 99099–99114. [Google Scholar] [CrossRef]
- UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 13 March 2020).
- Zhang, S.; Li, X.; Li, Y.; Mei, J. Prediction of Urban PM 2.5 Concentration Based on Wavelet Neural Network. In Proceedings of the 2018 Chinese Control And Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 5514–5519. [Google Scholar]
- Lu, H.; Song, J.; Di, T.; Kurdestany, J.M.; Wang, H. A deep belief network based model for urban haze prediction. Teh. ki vjesnik 2018, 25, 519–527. [Google Scholar]
- Yi, X.; Zhang, J.; Wang, Z.; Li, T.; Zheng, Y. Deep distributed fusion network for air quality prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 965–973. [Google Scholar]
- Zheng, Y.; Yi, X.; Li, M.; Li, R.; Shan, Z.; Chang, E.; Li, T. Forecasting fine-grained air quality based on big data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 2267–2276. [Google Scholar]
- Zhang, J.; Zheng, Y.; Qi, D.; Li, R.; Yi, X. DNN-based prediction model for spatio-temporal data. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Burlingame, CA, USA, 31 October–3 November 2016; pp. 1–4. [Google Scholar]
- Yao, H.; Wu, F.; Ke, J.; Tang, X.; Jia, Y.; Lu, S.; Gong, P.; Ye, J.; Li, Z. Deep multi-view spatial-temporal network for taxi demand prediction. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: a factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- A Weather-Forecast-Based Prediction Method. Available online: http://zx.bjmemc.com.cn/ (accessed on 13 March 2020).
- Zhang, J.; Ding, W. Prediction of air pollutants concentration based on an extreme learning machine: the case of Hong Kong. Int. J. Environ. Res. Public Health 2017, 14, 114. [Google Scholar] [CrossRef]
- Ni, X.; Huang, H.; Du, W. Relevance analysis and short-term prediction of PM2.5 concentrations in Beijing based on multi-source data. Atmos. Environ. 2017, 150, 146–161. [Google Scholar] [CrossRef]
- Vidnerova, P.; Neruda, R. Evolving keras architectures for sensor data analysis. In Proceedings of the 2017 Federated Conference on Computer Science and Information Systems (FedCSIS), Prague, Czech Republic, 3–6 September 2017; pp. 109–112. [Google Scholar]
- Keras. Available online: https://github.com/keras-team/keras (accessed on 13 March 2020).
- Liu, B.; Yan, S.; Li, J.; Li, Y. Forecasting PM2.5 concentration using spatio-temporal extreme learning machine. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 950–953. [Google Scholar]
- Shaban, K.B.; Kadri, A.; Rezk, E. Urban air pollution monitoring system with forecasting models. IEEE Sens. J. 2016, 16, 2598–2606. [Google Scholar] [CrossRef]
- Zhao, C.; van Heeswijk, M.; Karhunen, J. Air quality forecasting using neural networks. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–7. [Google Scholar]
- Vong, C.M.; Ip, W.F.; Wong, P.K.; Chiu, C.C. Predicting minority class for suspended particulate matters level by extreme learning machine. Neurocomputing 2014, 128, 136–144. [Google Scholar] [CrossRef]
- Macau Government Meteorological Center. Available online: http://www.smg.gov.mo/www/ccaa/pdf/e_pdf_download.php (accessed on 9 May 2012).
- Wang, W.; Xu, Z.; Lu, J.W. Three improved neural network models for air quality forecasting. Eng. Comput. 2003, 20, 192–210. [Google Scholar] [CrossRef] [Green Version]
- Ameer, S.; Shah, M.A.; Khan, A.; Song, H.; Maple, C.; Islam, S.U.; Asghar, M.N. Comparative Analysis of Machine Learning Techniques for Predicting Air Quality in Smart Cities. IEEE Access 2019, 7, 128325–128338. [Google Scholar] [CrossRef]
- Martínez-España, R.; Bueno-Crespo, A.; Timon-Perez, I.M.; Soto, J.; Muñoz, A.; Cecilia, J.M. Air-Pollution Prediction in Smart Cities through Machine Learning Methods: A Case of Study in Murcia, Spain. J. UCS 2018, 24, 261–276. [Google Scholar]
- Eldakhly, N.M.; Aboul-Ela, M.; Abdalla, A. Air pollution forecasting model based on chance theory and intelligent techniques. Int. J. Artif. Intell. Tools 2017, 26, 1750024. [Google Scholar] [CrossRef]
- Awad, Y.A.; Koutrakis, P.; Coull, B.A.; Schwartz, J. A spatio-temporal prediction model based on support vector machine regression: Ambient Black Carbon in three New England States. Environ. Res. 2017, 159, 427–434. [Google Scholar] [CrossRef] [PubMed]
- Allen, G. Analysis of Spatial and Temporal Trends of Black Carbon in Boston; Technical Report for Northeast States for Coordinated Air Use Management: New York, NY, USA, 2014. [Google Scholar]
- IMPROVE. Available online: http://vista.cira.colostate.edu/improve/ (accessed on 13 March 2020).
- Oprea, M.; Dragomir, E.G.; Popescu, M.; Mihalache, S.F. Particulate matter air pollutants forecasting using inductive learning approach. Rev. Chim. 2016, 67, 2075–2081. [Google Scholar]
- Contreras, L.; Ferri, C. Wind-sensitive interpolation of urban air pollution forecasts. Procedia Comput. Sci. 2016, 80, 313–323. [Google Scholar] [CrossRef] [Green Version]
- AEMET. Available online: http://www.aemet.es/es/portada (accessed on 13 March 2020).
- Sayegh, A.S.; Munir, S.; Habeebullah, T.M. Comparing the performance of statistical models for predicting PM10 concentrations. Aerosol Air Qual. Res. 2014, 14, 653–665. [Google Scholar] [CrossRef] [Green Version]
- Ip, W.F.; Vong, C.M.; Yang, J.; Wong, P. Forecasting daily ambient air pollution based on least squares support vector machines. In Proceedings of the 2010 IEEE International Conference on Information and Automation, Harbin, China, 20–23 June 2010; pp. 571–575. [Google Scholar]
- Wang, W.; Men, C.; Lu, W. Online prediction model based on support vector machine. Neurocomputing 2008, 71, 550–558. [Google Scholar] [CrossRef]
- Lu, W.; Wang, W.; Leung, A.Y.; Lo, S.M.; Yuen, R.K.; Xu, Z.; Fan, H. Air pollutant parameter forecasting using support vector machines. In Proceedings of the 2002 International Joint Conference on Neural Networks—IJCNN’02 (Cat. No. 02CH37290), Honolulu, HI, USA, 12–17 May 2002; Volume 1, pp. 630–635. [Google Scholar]
- Zhang, Y.; Wang, Y.; Gao, M.; Ma, Q.; Zhao, J.; Zhang, R.; Wang, Q.; Huang, L. A predictive data feature exploration-based air quality prediction approach. IEEE Access 2019, 7, 30732–30743. [Google Scholar] [CrossRef]
- Zheng, H.; Li, H.; Lu, X.; Ruan, T. A multiple kernel learning approach for air quality prediction. Adv. Meteorol. 2018, 2018, 3506394. [Google Scholar] [CrossRef]
- Eslami, E.; Salman, A.K.; Choi, Y.; Sayeed, A.; Lops, Y. A data ensemble approach for real-time air quality forecasting using extremely randomized trees and deep neural networks. Neural Comput. Appl. 2019, 1–17. [Google Scholar] [CrossRef]
- Wang, J.; Song, G. A deep spatial-temporal ensemble model for air quality prediction. Neurocomputing 2018, 314, 198–206. [Google Scholar] [CrossRef]
- Zhang, C.; Yan, J.; Li, Y.; Sun, F.; Yan, J.; Zhang, D.; Rui, X.; Bie, R. Early air pollution forecasting as a service: An ensemble learning approach. In Proceedings of the 2017 IEEE International Conference on Web Services (ICWS), Honolulu, HI, USA, 25–30 June 2017; pp. 636–643. [Google Scholar]
- Grell, G.A.; Peckham, S.E.; Schmitz, R.; McKeen, S.A.; Frost, G.; Skamarock, W.C.; Eder, B. Fully coupled “online” chemistry within the WRF model. Atmos. Environ. 2005, 39, 6957–6975. [Google Scholar] [CrossRef]
- Karamchandani, P.; Johnson, J.; Yarwood, G.; Knipping, E. Implementation and application of sub-grid-scale plume treatment in the latest version of EPA’s third-generation air quality model, CMAQ 5.01. J. Air Waste Manag. Assoc. 2014, 64, 453–467. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xi, X.; Wei, Z.; Xiaoguang, R.; Yijie, W.; Xinxin, B.; Wenjun, Y.; Jin, D. A comprehensive evaluation of air pollution prediction improvement by a machine learning method. In Proceedings of the 2015 IEEE International Conference on Service Operations and Logistics, And Informatics (SOLI), Hammamet, Tunisia, 15–17 November 2015; pp. 176–181. [Google Scholar]
- Debry, E.; Mallet, V. Ensemble forecasting with machine learning algorithms for ozone, nitrogen dioxide and PM10 on the Prev’Air platform. Atmos. Environ. 2014, 91, 71–84. [Google Scholar] [CrossRef]
- Li, L.; Ngan, C.K. A Weight-adjusting Approach on an Ensemble of Classifiers for Time Series Forecasting. In Proceedings of the 2019 3rd International Conference on Information System and Data Mining, Houston, TX, USA, 6–8 April 2019; pp. 65–69. [Google Scholar]
- Air Quality Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/Air+Quality (accessed on 13 March 2020).
- Xu, X.; Ren, W. Application of a Hybrid Model Based on Echo State Network and Improved Particle Swarm Optimization in PM2.5 Concentration Forecasting: A Case Study of Beijing, China. Sustainability 2019, 11, 3096. [Google Scholar] [CrossRef] [Green Version]
- Zhu, S.; Lian, X.; Wei, L.; Che, J.; Shen, X.; Yang, L.; Qiu, X.; Liu, X.; Gao, W.; Ren, X.; et al. PM2.5 forecasting using SVR with PSOGSA algorithm based on CEEMD, GRNN and GCA considering meteorological factors. Atmos Environ. 2018, 183, 20–32. [Google Scholar] [CrossRef]
- Wu, Q.; Lin, H. A novel optimal-hybrid model for daily air quality index prediction considering air pollutant factors. Sci. Total. Environ. 2019, 683, 808–821. [Google Scholar] [CrossRef]
- Wang, D.; Wei, S.; Luo, H.; Yue, C.; Grunder, O. A novel hybrid model for air quality index forecasting based on two-phase decomposition technique and modified extreme learning machine. Sci. Total. Environ. 2017, 580, 719–733. [Google Scholar] [CrossRef]
- Zhu, D.; Cai, C.; Yang, T.; Zhou, X. A machine learning approach for air quality prediction: Model regularization and optimization. Big Data Cogn. Comput. 2018, 2, 5. [Google Scholar] [CrossRef] [Green Version]
- Asgari, M.; Farnaghi, M.; Ghaemi, Z. Predictive mapping of urban air pollution using Apache Spark on a Hadoop cluster. In Proceedings of the 2017 International Conference on Cloud and Big Data Computing, London, UK, 17–19 September 2017; pp. 89–93. [Google Scholar]
- Zaragozí, B.M.; Trilles, S.; Navarro-Carrión, J.T. Leveraging Container Technologies in a GIScience Project: A Perspective from Open Reproducible Research. ISPRS Int. J. Geo-Inf. 2020, 9, 138. [Google Scholar] [CrossRef] [Green Version]
- Degbelo, A.; Granell, C.; Trilles, S.; Bhattacharya, D.; Casteleyn, S.; Kray, C. Opening up smart cities: citizen-centric challenges and opportunities from GIScience. ISPRS Int. J. Geo-Inf. 2016, 5, 16. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inclusion Criteria | Exclusion Criteria |
|---|---|
| Papers written in English | Non-English written papers |
| Publications in scientific conferences or scientific journals | Non-reviewed papers, editorials, presentations |
| Publications since 2002 | Publications before 2002 |
| Works focused on smart city services enabled by Internet of Things (IoT) | Papers not related to smart city services enabled by IoT |
| Papers that propose IoT-based solution(s) for smart city services | Papers with no concrete solution/s |
| Duplicated studies |
| Work | Year | Case Study | Methods | Algorithms | Evaluation Metrics | Prediction Target | Time Granularity | Data Rates |
|---|---|---|---|---|---|---|---|---|
| [12] | 2019 | China | SLI-ESN, mRMR | NN | RMSE, NRMSE, MAE, SMAPE, R | PM2.5 | 1 h, 5 h, 10 h | Hourly |
| [13] | 2019 | China | IDW-BLSTM | NN | RMSE, MAE, MAPE | PM2.5 | 1 h, 24 h, 1 week | Hourly |
| [52] | 2019 | China | LightGBM | Ensemble | SMAPE, MSE, MAE | PM2.5 | 24 h | |
| [14] | 2019 | China | CBGRU | NN | RMSE, MAE, SMAPE | PM2.5 | 2 h | Hourly |
| [39] | 2019 | China | DTR, RFR, MLP, GBR | Ensemble, Regression | MAE, RMSE | PM2.5 | 1 week | |
| [61] | 2019 | Italy | ARIMA, SVM, ANN | Hybrid Model | MAE, MAPE | CO | 24 h | Hourly |
| [17] | 2019 | China | AAQP(n-step) | NN | MAE, R2 | PM2.5 | 24 h | Hourly |
| [63] | 2019 | China | ESN-IPSO | Hybrid Model | RMSE, MAE, SMAPE, R | PM2.5 | 1 h, 10 h | Hourly |
| [54] | 2019 | South Korea | DNN(extra-trees) | Ensemble | IA | O3 | 24 h | Hourly |
| [18] | 2019 | Italy | AIS-RNN | NN | RMSE, MAE, MAPE | CO(GT), NO2(GT) | 1 h | Hourly |
| [65] | 2019 | China | SD-SE-LSTM-BA-LSSVM | Hybrid Model | RMSE, MAE, MAPE, R | 24 h | ||
| [40] | 2018 | Spain | Bagging(REPTree), RC(RT), RF, DT(M5P), KNN | Ensemble, Regression | MAE, RMSE, R2 | O3 | 24 h | Hourly |
| [67] | 2018 | USA | Regularization, Optimization | RMSE | O3, PM2.5, SO2 | 24 h | Hourly | |
| [53] | 2018 | China | MKSVC | Ensemble | ACC, MSE, WP, WR, WF | PM2.5 | 1 h, 3 h, 6 h, 9 h, 12 h | Hourly |
| [16] | 2018 | China | APNet(CNN-LSTM) | NN | MAE, RMSE, R, IA | PM2.5 | 1 h | Hourly |
| [20] | 2018 | China | WNN | NN | R2, RMSE, MAPE | PM2.5 | 1 h, 3 h, 6 h | Hourly |
| [21] | 2018 | China | DBN | NN | R, MAE | PM2.5 | 1 h | Daily |
| [22] | 2018 | China | DNN | NN | ACC, MAE | PM2.5 | 6 h, 12 h, 24 h, 48 h | Hourly |
| [64] | 2018 | China | CEEMD-PSOGSA-SVR- GRNN | Hybrid Model | MAE, MAPE, RMSE, R, IA | PM2.5 | 24 h | Daily |
| [55] | 2018 | China | STE | Ensemble | RMSE, MAE, ACC | PM2.5 | 6 h, 12 h, 24 h, 48 h | Hourly |
| Work | Dataset Type | Open Data | Advantages | Limitation/FutureWork | ||||
| [12] | AQ, MET | YES | mRMR is preferable for future selection. | Longer term is not satisfactory, long time consuming on optimal subset selection and the model optimization. | ||||
| [13] | AQ, Spatial | NO | IDW helped to improve BLSTM by 5.6%. | Using only the historic air pollution data. | ||||
| [52] | AQ, MET, WFD, Spatial | NO | Faster training rate, higher accuracy. | |||||
| [14] | AQ, MET | YES | To obtain a sequence pattern. | |||||
| [39] | AQ, MET | NO | RFR reduces overfitting, detects peak values. | To use additional factors related to the air pollution. | ||||
| [61] | AQ, MET | YES | Relatively better result, time complexity is linear. | To use more than three classifiers and remove classifiers with negative weight. | ||||
| [17] | AQ, MET | ON REQUEST | Reduction of error addition and the training time. | To work on spatial attention, to collect more weather forecast data | ||||
| [63] | AQ, MET | NO | Comparatively better accuracy. | It fails to consider the potential factors in extreme conditions, additional extension—to achieve medium- and long-term forecasts in terms of time factor. | ||||
| [54] | AQ, MET | YES | The models’ computation time for real-time hourly prediction is less compared to the station-specific machine learning models. | high-ozone episodes were underpredicted, particularly during the high-ozone season. | ||||
| [18] | AQ, MET | YES | AIS-RNN outperformed the baselines by up to 38%. | To extend AIS-RNN as an end-to-end ensemble mode. | ||||
| [65] | AQ | YES | ||||||
| [40] | AQ, MET | NO | 80% ≤ R2 ≤ 90%, O3 < 11 g/m. | To consider and analyse new elements, to transfer information to the target groups. | ||||
| [67] | AQ, MET | YES | To improve the convergence of optimization and to speed up the training process for big data. | Consider the commonalities between nearby meteorology stations. | ||||
| [53] | AQ, MET, Temporal | YES | Better for Short-term and severe air pollution prediction. | More exploration must be done. | ||||
| [16] | AQ, MET | YES | Relatively better result. | |||||
| [20] | AQ, MET | NO | High stability and robustness. | Difficulties to make WNN. | ||||
| [21] | AQ, MET | YES | Correlation result is 18% better, while the MAE declines by 15.7 g/m. | The lack of data. | ||||
| [22] | AQ, MET, WFD | NO | 2.4%, 12.2%, 63.2% relative accuracy improvements on short-term, long-term and sudden changes prediction, respectively. | The long-term sudden changes prediction. | ||||
| [64] | AQ, MET | YES | Higher applicability and effectiveness. | To forecast other air pollution indexes, to evaluate the AQ in other cities. | ||||
| [55] | AQ, WFD, Spatial | NO | Effective and reaches nearly 60% in accuracy. | |||||
| Work | Year | Case Study | Methods | Algorithms | Evaluation Metrics | Prediction Target | Time Granularity | Data Rates |
| [68] | 2017 | Iran | Multinomial Naïve Bayes and Multinomial Logistic Regression | Precision, Recall, F1 score | 24 h | Hourly | ||
| [66] | 2017 | China | CEEMD-VMD-DE-ELM | Hybrid model | MAE, MAPE, RMSE | 24 h | Daily | |
| [56] | 2017 | China | MELSA | Ensemble | RAE, RSE, R | PM2.5, PM10, SO2, CO, NOx, O3 | 72 h | |
| [41] | 2017 | Egypt | chWSVR | Regression | RMSE, R, z’, t-value | PM10 | 1 h | Hourly |
| [29] | 2017 | China | ELM | NN | MAE, RMSE, IA, R2 | NO2, NOx, O3, PM2.5, SO2 | 24 h | Daily |
| [30] | 2017 | China | MSA-BPNN-ARIMA | NN | RMSE | PM2.5 | 24 h | Hourly |
| [42] | 2017 | USA | nu-SVM | Regression | R2 | BC | 24 h | Daily |
| [31] | 2017 | Italy | DNN | NN | AVG, SD, MIN, MAX | CO, NO2, NOx, C6H6, NMHC | Hourly | |
| [33] | 2016 | China | STELM | NN | MRE, MAE | PM2.5 | 72 h | Hourly |
| [45] | 2016 | Romania | M5P, REPTree | Regression | R, MAE, RMSE | PM10 | 24 h, 48 h, 72 h | Daily |
| [34] | 2016 | Qatar | SVM, ANN, M5P | Regression, NN | PTA, RMSE, NRMSE | O3, NO2, SO2 | 1 h, 8 h, 12 h, 24 h | 15 min |
| [46] | 2016 | Spain | LR, QR, IBKreg, M5P, RF | Regression, Ensemble | RMSE | SO2, O3, NO, NO2 | 3 h | Hourly |
| [35] | 2016 | Finland | ELM | NN | 1 h | Hourly | ||
| [59] | 2015 | China | RF, GB, SVM | Ensemble | 24 h | Daily | ||
| [60] | 2014 | DRR | Ensemble | RMSE | O3, NO2, PM10 | 24 h, 48 h, 72 h | Hourly | |
| [36] | 2014 | China | ELM | NN | PM10 | 24 h | Daily | |
| [48] | 2014 | Saudi Arabia | MLR, QR, GAM, BRT1, BRT2 | Regression | MBE, MAE, RMSE, FACT2, R, IA | PM10 | 1 h | Hourly |
| [49] | 2010 | China | LSSVM | Regression | Relative Error | SPM, SO2, NO2, O3 | 24 h | Daily |
| [50] | 2008 | China | online SVM | Regression | MAE, RMSE, WIA | RSP(PM10), NOx, SO2 | 24 h, 1 week | Hourly |
| [38] | 2003 | China | ARBF/ARBF-PCA/SVM | NN | MAE, RMSE, WIA | RSP (PM10) | 72 h | Hourly |
| [51] | 2002 | China | SVM | Regression | MAE | RSP(PM10) | 24 h, 1 week | Hourly |
| Work | Dataset Type | Dataset Type | Advantages | Limitation/Future Work | ||||
| [68] | AQ, MET | NO | To use SVM, DT and hybrid algorithms to improve the accuracy in existence of imbalanced datasets, to use spatial indexing method. | |||||
| [66] | AQ | YES | To eliminate the non-stationary characteristics | |||||
| [56] | AQ, MET, WFD | YES | ||||||
| [41] | AQ, MET, Temporal | NO | To forecast other air pollutants. | |||||
| [29] | AQ, MET, Temporal | NO | Precision, robustness, generalization | |||||
| [30] | AQ, MET, Social Media | NO | Long-term prediction is a challenging task | |||||
| [42] | AQ, MET, Spatial, Temporal | Partially | Lack of monitors. | |||||
| [31] | AQ, MET | YES | To extend the algorithm, to include more parameters. | |||||
| [33] | AQ, MET, Spatial | NO | To improve the precision and reduce the absolute errors. | |||||
| [45] | AQ, MET | YES | ||||||
| [34] | AQ, MET, Temporal | NO | M5P outperforms others because of the tree structure efficiency and powerful generalization ability. | To consider data changes over time for real-time forecasting. For increasing data seasonality to include more data. | ||||
| [46] | AQ, MET, TIF, Temporal | YES | To include local features of the target points. | |||||
| [35] | AQ, MET | YES | The method is flexible and reliable. | To use ensemble methods. | ||||
| [59] | AQ, WFD, Chemical | Link is not available | Combined model outperforms single model by 3%. | |||||
| [60] | AQ, MET | YES | ||||||
| [36] | AQ, MET | YES | The short training time, the small model size and managing imbalance dataset. | To compare different imbalance strategies. | ||||
| [48] | AQ, MET | NO | QRM captures the contributions of covariates at different quantiles. | To use data from different monitoring sites over a longer period of time, to include traffic characteristics data. | ||||
| [49] | AQ, MET | YES | ||||||
| [50] | AQ, MET | NO | Online SVM determine dynamically the optimal prediction model. | Computational problem because of dimensionality. | ||||
| [38] | AQ, MET | NO | To provide more effective and practical models. | |||||
| [51] | AQ, MET | NO | SVM is better than RBF. | To impove SVM method. | ||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iskandaryan, D.; Ramos, F.; Trilles, S. Air Quality Prediction in Smart Cities Using Machine Learning Technologies Based on Sensor Data: A Review. Appl. Sci. 2020, 10, 2401. https://doi.org/10.3390/app10072401
Iskandaryan D, Ramos F, Trilles S. Air Quality Prediction in Smart Cities Using Machine Learning Technologies Based on Sensor Data: A Review. Applied Sciences. 2020; 10(7):2401. https://doi.org/10.3390/app10072401
Chicago/Turabian StyleIskandaryan, Ditsuhi, Francisco Ramos, and Sergio Trilles. 2020. "Air Quality Prediction in Smart Cities Using Machine Learning Technologies Based on Sensor Data: A Review" Applied Sciences 10, no. 7: 2401. https://doi.org/10.3390/app10072401
APA StyleIskandaryan, D., Ramos, F., & Trilles, S. (2020). Air Quality Prediction in Smart Cities Using Machine Learning Technologies Based on Sensor Data: A Review. Applied Sciences, 10(7), 2401. https://doi.org/10.3390/app10072401