3.2. Semantic Information Processing
Our Semantic Information Processing (SIP) module endows the robot with cognitive vision capability, inspired by the human ability, that tends to recognize the places by the objects present there, such as “computer lab” or “printer room,” which are common terms that are used by human to recognize the places based on their objects. Similarly, humans identify outdoor places by distinguishing different features or objects, such as billboards.
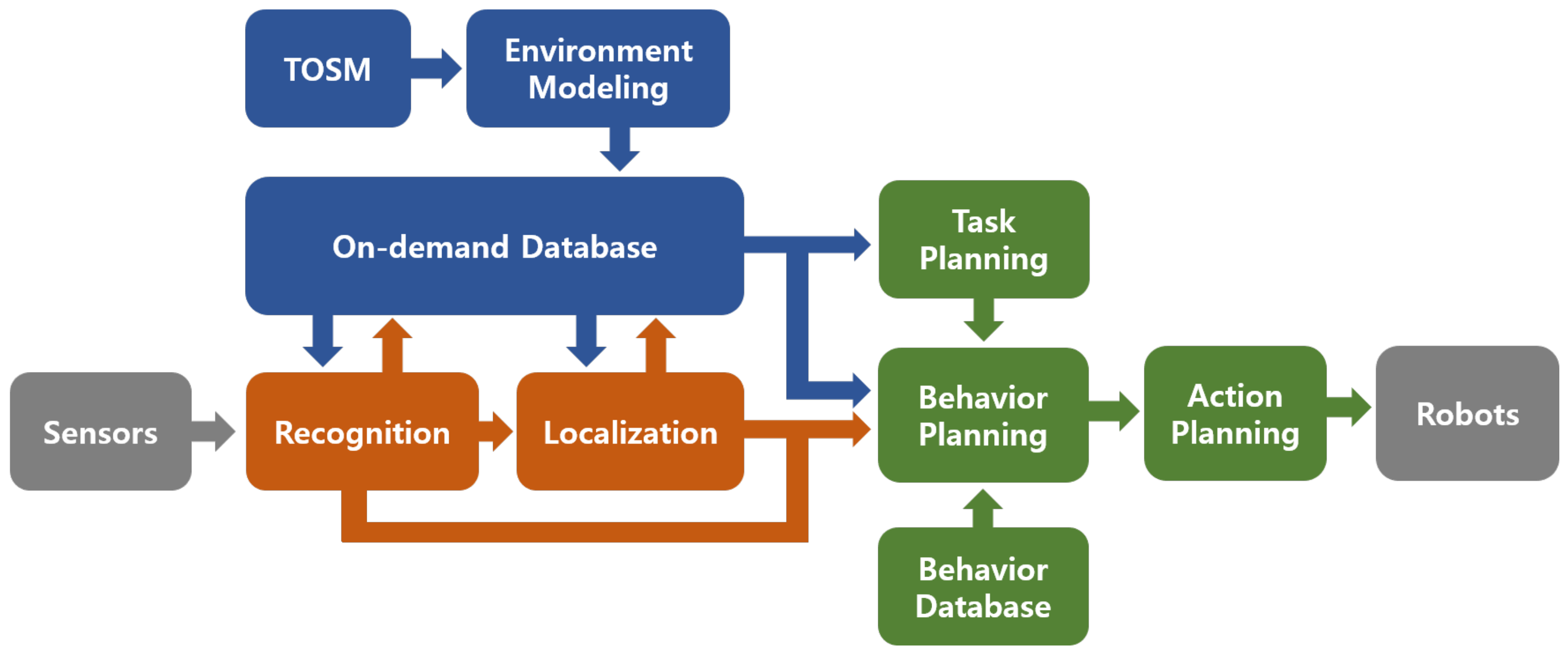
Motivated by these ideas, our SIP module also uses an objects-based recognition approach to form a symbolic abstraction of the places. In the SIP module, first, the objects are recognized by a CNN model, then the inference is performed to leverage the recognized objects with their semantic information stored in the on-demand database. It also infers the robot’s relationship information based on the spatial information of recognized objects in the environment. Our SIP module aims at performing recognition and localization tasks with semantically meaningful information to effectively guide the robot’s behaviors to reach a goal location. To achieve this, we combine our recognition model with the on-demand database, as shown in
Figure 4, and perform the inference on recognized objects against their semantic information stored in the on-demand database.
We have selected the third version of YOLO [
42] for object recognition because it presents a good trade-off between execution time and accuracy, compared with other object detectors. For example, its accuracy is almost similar to RetinaNet [
96]; however, it is four times faster. Moreover, it is much better than SSD variants and Darknet-53 as its backbone network architecture makes it 1.5 times faster than ResNet-101 [
42].
First, we train state-of-the-art one-stage CNN based model, YOLOv3 [
42] for object recognition with our own data set. When a mobile robot navigates in the environment, visual data captured by a camera is passed to the CNN model; it produces a sequence of layered activations, which generate feature vectors that have a deeply learned representation of high-level features. We perform pre-processing step to remove the noise before passing the visual data captured by the robot’s camera to the CNN model. Both the raw-data and the CNN model are hosted by short-term memory (STM). Raw-data does not have access to the on-demand database, while the CNN model, which holds the recognition components, has access to the on-demand database.
Object and
Place models are initially stored in this database. We download these semantically enriched models of recognized objects from the on-demand database when required by the robot.
Our YOLO-based recognition model consists of two phases: the processing phase and the retrieving phase.
The processing phase is also known as an offline or training stage in which we train the YOLOv3 model for object recognition using our dataset. The training phase involves three major steps; (i) Dataset annotation: we label objects in each image using the YOLO-Mark tool. (ii) Convolution weights: we use YOLOv3 weights trained on ImageNet for convolutional layers. (iii) Configuration set-up: we prepare a model configuration file that loads 64 images in the forward pass for each iteration during the training process. The model updates the weights when backpropagating after gradients’ calculation. Thus, for each iteration, our model uses 64 batch size with 16 mini-batches, and four images are loaded for each mini-batch. In our configuration file, we define filter size to 60, the maximum number of iterations 30,000 for 15 classes. The YOLOv3 has three YOLO layers; therefore, we generate nine anchors to recognize small, medium, and large size object at its three YOLO layers. Finally, when the training phase is completed, we get new weights for our dataset.
The retrieval phase is known as an online or testing stage. In the testing phase, weights that were generated during model training, are used to recognize objects in a real-world environment.
In our SIP module, after object recognition using the CNN model, inference for semantic information is performed at run-time by integrating the recognized objects with their semantic information that contains spatial relationships between objects, described in
Table 2. Through these spatial relationships among recognized objects, we infer the relationship information of the robot by leveraging with the semantic objects and space stored in the on-demand database as follows:
Assume
x is an object recognized in the environment by the CNN model, while
X is the subclass of
EnvironmentalElement (e.g.,
Furniture,
Door, and
). Then the class of object
x is defined by a class definition function
, which indicates that object
x is class
X. As shown in
Figure 4, there are two objects in the environment: table and chair. The class definition function
and
states that in both cases, the class of the table is
Table and the chair is
Chair. When the class is defined, we can get the datatype properties of the object from the database based on the robot’s pose and relative pose of the object. In other words,
Chair is specified
chair2 (we call this
) that is an instance of
Chair by the database query such as illustrated in the gray table inside
Figure 4.
We also use a relationship inference function to define relationships between recognized objects, other objects, and places in the database. According to the class definition function, indicates an instance of class X. describes a spatial relationship between and , such that “ ” (e.g., “ ”.) Similarly, we can infer the robot’s relationship in the environment; in that case, the is an instance of .
So, when the robot navigates in a real-world environment, and it finds two objects, table and chair, shown in
Figure 4, the robot recognizes these two objects using the CNN model and infers these objects with their semantic information that is saved in the database. As a result, we get spatial relationships such as “
”, “
”, “
”, and “
”.
We can also see that the recognition model and the TOSM-based on-demand database share human-like memory architecture when working together for visual semantic recognition. The SIP module is processed in working memory (Short Term Memory, STM), while prior semantic knowledge stored in the on-demand database is hosted by Long-Term Memory (LTM), as shown in
Figure 5. When the mobile robot navigates in a real-world environment, it sends the sensory data to SIP, which passes the pre-processed data to the recognition model that is stored in working memory and gets the periodic visual updates as robot navigates.
3.3. Semantic Autonomous Navigation
The Semantic Autonomous Navigation (SAN) module allows the robot to perform complex missions through a hybrid hierarchical planning scheme. The knowledge base, combined with a behavior database, enables autonomous navigation in a variety of environments while taking the robot capabilities into account. Throughout this section, we use a single mission example for a clearer understanding. Consider a multi-story building represented by the database displayed in
Figure 3, where elevators and staircases connect each floor; a robot located on the 2nd floor inside the building; a mission given by a human that says it should retrieve a package at the sidewalk outside of the main entrance located on the first floor. The following sections demonstrate, through this mission, how the SAN module can enable robots to perform high-level multi-story navigation.
3.3.1. Task Planner
After receiving a mission, such as
robotAt place1 (navigation) and
inspected place2 (inspection), the SMF creates the robot’s on-demand database based on the mission and its capabilities. For example, different robots have different capabilities: some can go up and downstairs, while others can operate an elevator autonomously, as shown in
Figure 6. Considering a robot that can operate the elevator, the on-demand database does not need to contain the staircases’ information.
The task (i.e., mission) planner access only to the on-demand database speeding up the queries during the plan execution. The environmental implicit information, namely
isConnectedTo property together with the robot’s location, is used to populate the ROSPLAN [
11] knowledge base. The robot’s implicit information is also used to provide the domain PDDL file. Thereupon, ROSPLAN is used to generate a valid behavior sequence. To generate a behavior sequence, PDDL planners require two files: domain and problem. The domain file describes the environment predicates and robot actions. As different robots can perform a distinct set of actions, a comprehensive set of domain actions, all sharing common predicates between them, is stored into the behavior database. Given the robot’s implicit TOSM data, a matching domain file is generated and fed to ROSPLAN by the behavior database; the problem file is generated automatically by ROSPLAN knowledge base. It needs, however, the environment state information to do so. ROSPLAN state update services are used to feed the map data into the knowledge base. After that, the behavior sequence is generated through the Partial Order Planning Forwards (POPF) planner [
97]. Despite the current state of the behavior database not including temporal-actions, we have plans to also support them in the future. Therefore, we opted to use the POPF planner due to its ability to deal with both simple and durative actions. ROSPLAN also sends the current behavior to the Behavior Planner through the medium of the Plan Dispatcher node.
In our example, the 02 robot shown in
Figure 6b receives the multi-floor navigation mission. The robot then receives the on-demand database generated by the SMF based on the robot’s implicit information (i.e., its capabilities). This on-demand database contains the building floors and the elevators, but no stairs, as the robot cannot transverse through them. Moreover, a domain file containing all the possible robot actions is sent to the ROSPLAN knowledge base. An example action, which sends a robot to a waypoint on the same floor, is shown on Listing 1. The predicates are general and shared between all actions stored on the database, thus making possible generating the domain file simply by querying which actions can be performed by the robot. Subsequently, the environment TOSM data is used to populate the ROSPLAN knowledge base environment state, adding connected waypoints, elevator, robot, and goal predicates. After running the POPF planner, the behavior sequence shown on Listing 2 is generated and sent by the dispatcher node to the Behavior Planner module.
Listing 1.
Move to waypoint action.
Listing 1.
Move to waypoint action.
(: action goto_waypoint : parameters ( ?v — robot ?from ?to — waypoint ?fl — floor ) : precondition (and (outside _ elevator ?v) (robot_at ?v ?from) (waypoint_at_floor ?from ?fl) (waypoint_at_floor ?to ?fl) (hallway_waypoint ?from) (hallway_waypoint ?to) (connected_to ?from ?to) ) :effect (and (robot_at ?v ?to) (not (robot_at ?v ?from)) ) )
|
Listing 2.
A behavior sequence generated by ROSPLAN.
Listing 2.
A behavior sequence generated by ROSPLAN.
(goto_waypoint 02robot wp0 wp1 fl2) (goto_waypoint 02robot wp1 wp4 fl2) (goto_waypoint 02robot wp4 wp5 fl2) (enter_elevator 02robot wp5 wp18 elevator2 fl2 fl1) (exit_elevator 02robot wp18 elevator2 fl1) (goto_waypoint 02robot wp18 wp21 fl1) (goto_waypoint 02robot wp21 wp22 fl1)
|
3.3.2. Behavior Planner
The behavior planner can be divided into two modules: the waypoint generator and the behavior handler. After receiving the next goal from the task planner, one of those two modules takes care of breaking down this behavior into atomic actions. The waypoint generator handles motion behaviors. While complex specific activities, such as entering and exiting an elevator or going up or downstairs, are processed by the behavior handler.
The waypoint generator receives a goal point from the task planner, the current position from the localization module, and a local metric map obtained from the on-demand database and stored into the STM. It then uses the PRM algorithm proposed by [
84], after being adapted for mobile robot navigation, to generate a feasible sequence of waypoints. We start by generating random samples
on the metric map free space
. The PRM algorithm’s goal is to generate a valid path between the current position
and the goal
by creating edges connecting two sample nodes
. Initially, it generates
n random samples on the 2D metric map, eliminating any sample outside of
and re-generating new random samples until
n valid samples are successfully generated, whereas in our approach, PRM works as a low-resolution path-planner,
n can be of a smaller magnitude when compared to the overall map size, speeding up the query step. Thereon, it iterates through every sample generating valid paths connecting to the k-nearest neighbors. A path is considered valid if the two points can be connected by a straight line which is completely inside
and is smaller than a maximum connection distance threshold. This graph generation depends only on the metric map and can be pre-generated by the robot when idle or while executing actions that do not require a large amount of processing power. Finally, to generate a waypoint sequence,
and
are added to the graph and the
Dijkstra’s algorithm [
98] is used to query the shortest path.
The behavior handler receives a specific desired behavior from the task planner and then queries the behavior database for instructions on how to execute such activity. The behavior database (BDB) can be seen as the human implicit memory [
93], which saves cognitive skills learned throughout one’s life. The BDB stores finite state machines (FSM) able to coordinate single behaviors, such as the one shown in
Figure 7. Each state (i.e., action) has a standardized ID and a possible events list that is used to check the transition to the next state. After obtaining the FSM description, the behavior handler sends the initial action ID to the action planner and waits for the returned events. Thereon, it uses the event list to choose the next state and sends it back to the action planner. This sequence is repeated until one of the two final states is reach: success or failure.
Both the waypoint generator and the behavior handler emit a success signal to the task planner when the behavior is completed, allowing the planner dispatcher to send the next one. In case of failure, a homonymous signal is sent back instead, and the PDDL planner is able to perform re-planning starting from the current state.
3.3.3. Action Planner
The action planner can receive two different kinds of actions: a waypoint from the waypoint generator or a specific action ID from the behavior handler.
When receiving an action ID, the action planner looks for the implementation of such action inside the robot’s LTM. Each robot should have its implementation of the needed actions, as their execution is dependent on the robot sensors and actuators. In that case, the planner is unable to find the requested action, it returns a failure event to the behavior planner. On the other hand, if the action implementation is found, the robot executes it and returns the events related to the conclusion of such action.
If the requested action is related to following a waypoint instead, a different structure is used to handle it. A mentally simulated world was generated and used to train an autonomous navigation policy using reinforcement learning algorithms. This process is further explained on
Section 3.3.4 and
Section 3.3.5. The action planner uses the policy returned by the mental simulation in order to navigate towards a waypoint while also avoiding close obstacles. After getting close enough to the goal point, the action handler returns the success event to the behavior planner and waits for the next instruction.
3.3.4. Mental Simulation
Mental simulation is one of the integral cognitive skills, which has been long studied by cognitive science and neuropsychology research [
99]. Nonetheless, just a few works tried to implement such concepts into robotic platforms [
72]. Some usages of the mental simulation are re-enacting memories, reasoning about different possible outcomes, and learning by imagination. In this work, the mental simulation module is used to perform reinforcement learning aiming for autonomous navigation. The simulation building algorithm was originally proposed on [
100].
One of the main issues of performing mental simulation on robots is the need of domain experts to model the simulated world based on the robot working environment. Modeling the environment is not feasible when robots navigate through large-scale dynamic environments. To overcome such limitation, we built a middle-ware capable of generating a simulated world, including the robot itself, using only the information stored on the on-demand database. By doing so, whenever the robot updates its internal knowledge about the environment, the simulation is also updated in the same manner. Whenever the simulated environment is needed, the middle-ware queries the needed data from the on-demand database and generates Universal Robot Description Format (URDF) and Simulation Description Format (SDF) files, which are used to create the virtual world on the Gazebo Simulator.
Figure 8 shows an example output of the simulation building algorithm. It uses the data stored on the on-demand database to generate the simulation environment. To ensure this simulation is robust while also maintaining its consistency with the real world, we use a library containing 3D meshes for common objects such as doors, chairs, and tables. If the robot encounters a real-world object in which there is no 3D model available, a placeholder is automatically generated using the perceived shape and color of the object. Such point can be seen on
Figure 8, where the simulated door uses a 3D mesh, while the vending-machine and the beverage storage are represented by automatically generated shapes.
3.3.5. Reinforcement Learning
The main usage of the mental simulation is to generate experience tuples
, where
is the current state,
is the chosen action,
is the reward and
the next state after performing
, and
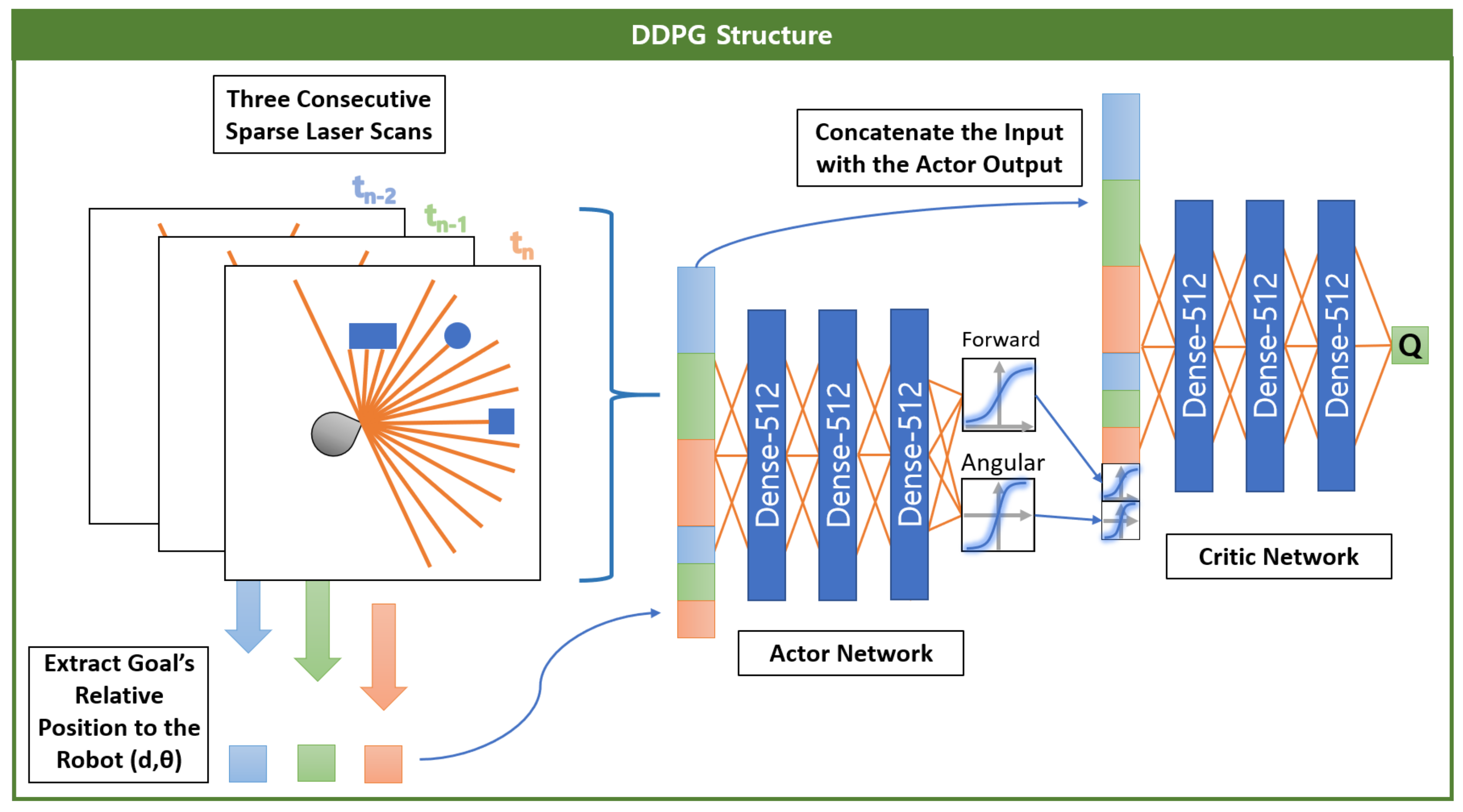
represents whether or not the episode has ended. Those simulated episodic memories are generated whenever the robot is idle, such as when charging. Those memories are then sampled in batches to train a policy using the DDPG algorithm [
90]. The RL structure is shown on
Figure 9. Three consecutive sparse laser scans and relative distances to the goal are concatenated as the algorithm input. This input goes through an actor-network which outputs two different values. A
sigmoid function is used to encode the robot forward speed between 0 and 1, while a
tanh function encodes the angular speed between –1 and 1. Those outputs are concatenated with the input and served to the critic-network, which outputs the Q-value (i.e., the expected future reward) for the action chosen on this given state. Finally, the environment rewards are defined as
where
,
,
and
are positive integers defined trivially.
As the training step only needs to sample the experience tuples, it can be performed either on-board or by using a central cloud service, provided that such structure is accessible by the robot.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














