1. Introduction
The “Made in China 2025 strategy” puts forward new requirements for China’s agricultural equipment and requires continuous improvement of the ability of agricultural machinery intelligence and precision operation [
1]. The horticultural tractor is an important piece of agricultural machinery working in orchards, forest gardens, and other environments. One of the basic tasks of realizing intelligent operation of the horticultural tractor is to identify the working environment. With the development of science and technology, more and more methods are being used for environmental recognition, such as lidar for scanning and recognizing the surrounding environment. However, due to the high cost of lidar, it is difficult to apply to agricultural products. In contrast, the use of ordinary cameras as sensors has many advantages, like comprehensive information collection and low price [
2]. For vision-based environmental recognition, related algorithms based on the target of achieving rapid and accurate recognition have mainly been formulated.
In the research of environment recognition, Radcliffe [
3] developed a small autonomous navigation vehicle in a peach orchard based on machine vision. The machine vision system was based on the use of a multispectral camera to capture real-time images and process the images to obtain trajectories for autonomous navigation. Lyu [
4] used naïve Bayesian classification to detect the boundary between the trunks and the ground of an orchard and proposed an algorithm to determine the centerline of the orchard road for automatic driving of the orchard’s autonomous navigation vehicle. In order to enable agricultural robots to extract effective navigation information in a complex, open, non-structural farmland environment, and solve the instability of navigation information extraction algorithm caused by light changes, An [
5] proposed to use the color constancy theory to solve lighting problems in machine vision navigation. Zhao [
6] proposed a vision-based agricultural vehicle guidance system, using the Hough transform method to extract guidance parameters, and designed a path recognition method based on centerline detection and erosion algorithm.
The environmental recognition method in the literature basically solves the problem of recognition in a specific environment and has specificity, which has certain limitations. In recent years, there has been rapid development of deep learning, which has shown excellent performance in environment recognition [
7] and target detection [
8]. Environment recognition algorithms based on deep learning have the advantages of strong robustness and high accuracy. In the research of environment recognition based on deep learning, Oliveira [
9] used the high-order features in convolutional neural network learning scenarios to segment road scenes and generated training labels by training on image data sets, then used the new textures based on color layer fusion to obtain the maximum consistency of the road area, and finally combined the offline and online information to detect urban road areas. Badrinarayanan [
10] proposed the Segnet network for road scene understanding. The network architecture is based on an encoding–decoding network, but the segmentation of road boundary details still needs to be improved. He [
11] used the Spatial Pyramid Pooling Network (SPP-Net) to extract roads from remote sensing images and used structural similarity (SSIM) as the loss function for road extraction, which can extract the fuzzy prediction in the extraction results and improve the image quality of the extracted roads. Li [
12] constructed a semantic segmentation model of field road scenes based on the hollow convolutional neural network for complex field road scenes in hilly and mountainous areas. The model includes a front-end module and a context module. The front-end module is an improved structure of VGG-16 (Visual Geometry Group Network) fusion cavity convolution, and the context module is a cascade of the convolutional layer with different expansion coefficients. The two-stage training method was adopted to train the model, and the model showed good adaptability to shadow interference. Wang used the YOLOV3 (You Only Look Once) convolutional neural network to extract the feature points on road images from orchards, generated the navigation line by the least square method [
13], and conducted experiments in a variety of different natural environments, with a deviation of 3.5 cm. Zhang [
14] combined the strengths of U-Net and residual learning to construct a seven-layer deep residual U-type network for road extraction from aerial images and achieved good results. Anita [
15] used a deep residual U-Net convolutional nerve network for lung CT image segmentation in the field of biomedicine, and the segmentation effect was significantly improved, which effectively helped in the early diagnosis and treatment of lung diseases.
Environment recognition algorithms based on deep learning have greatly improved the accuracy of recognition [
16], but they are mainly used in the recognition of structured roads or environments with few distractors, and the application scenarios are relatively singular. The orchard environment is complex and changeable, and the span between different objects is larger. Recognizing these objects requires a deeper network, but this will cause problems such as gradient disappearance, increased parameters, and difficulty in training. Therefore, this paper takes a U-type network as the main body of the network model; gives full play to its advantages, such as fewer parameters and high recognition accuracy; and adds residual blocks in the feature extraction process to deepen the network and improve the extraction ability of object edge information, finally building an orchard environment recognition algorithm based on a deep residual U-shaped network. Pixel-level semantic segmentation is used for the image of the orchard environment to obtain various information on the orchard environment, laying the foundation for autonomous operation of the gardening tractor in the future.
The main contributions of this paper are as follows:
Section 1 introduces the current research status of environment identification and proposes an orchard environment identification algorithm based on the deep residual U-type network.
Section 2 describes the acquisition and processing of orchard environment data sets.
Section 3 presents the construction of the orchard environment model and constructs the deep residual U-type network segmentation mode by analyzing the characteristics of the residual network and the U-type network and combining the actual needs of the orchard environment identification. In the fourth section, experimental comparative analysis is carried out on the fully convolutional neural network, the U-type network, the Front-end+Large network, and the deep residual U-type network. Finally, the conclusions and future work are presented in
Section 5.
3. Construction of the Orchard Environmental Identification Model
In recent years, with the application of fully convolutional networks (FCNs), convolutional neural networks (CNNs) have been used to generate semantic segmentation charts of any size on the basis of feature diagrams, which can split images at the pixel level [
19]. Based on this method, many algorithms have been derived, such as the deep-splitting network framework DeepLab series [
20,
21], the scene resolution network PSPNet using a pyramid pooling module [
22], and the U-Net network for medical image segmentation [
23].
The U-Net network can still achieve better model segmentation accuracy with few samples, and for the first time, used the skip connection to add encoded features to decoding features, creating an information propagation path that allows signals to spread more easily between low-level and advanced features; this not only facilitates backpropagation during training but also improves model segmentation accuracy. However, the U-Net network has insufficient ability to obtain contextual information from images, especially for complex scene data with large differences in category scales. Multi-scale fusion is usually used to increase the depth of the network to improve the U-Net network’s ability to obtain contextual information from images. However, with increasing network depth, the accuracy of model recognition decreases rapidly after saturation rapidly declines, and the recognition error increases. To solve this problem, He et al. [
24] proposed a deep residual network that used identity mapping to obtain more contextual information. The error did not increase with the depth of the network, which solved the problem of training degradation.
3.1. Residual Network
In traditional convolutional neural networks, multi-layer features become more abundant with the superimposition of network layers, but simple superposition networks will cause the problem of gradient disappearance and hinder the convergence of the model. In order to improve the accuracy of environment recognition and prevent gradient disappearance, a residual network was considered for addition into the network structure.
The residual network is mainly designed as a residual block with a shortcut connection, which is equivalent to adding a direct connection channel in the network, so that the network has a stronger identity mapping ability, thus expanding the network depth and improving the network performance without overfitting. The residual network consists of a series of stacked residual units. Each residual unit can be expressed in a general form:
where
is the input of the residual unit of layer
i;
is the network parameters of the residual unit of layer
i;
denotes the residual function;
denotes the identity mapping function; and
denotes the activation function.
The residual neural network unit consists of two parts: the identity mapping part and the residual part. Identity mapping mainly integrates the input with the output processed by the residual, which facilitates the fusion of subsequent feature information, and the residual part is generally composed of multiple converse neural networks, normalized layers, and activation functions. Through the superposition of identity mapping and residuals to realize information interaction, the problem of poor ability to extract underlying features in the residual part is compensated.
Figure 3 shows the difference between the common neural network unit and the residual neural network unit.
Figure 3a is the structure of the common neural network unit, and
Figure 3b is the structure of the residual neural network unit.
3.2. Construction of the Deep Residual U-Net Model
Based on the characteristics of the deep residual network and U-Net network, we propose the deep residual U-type network, which introduces a residual layer to deepen the U-Net structure and avoids the occurrence of excessive training time, too many training parameters, and overfitting. In semantic segmentation, it is necessary to use both low-level detailed information and high-level semantic information for better results. The deep residual U-type network can well retain the information of both. The deep residual U-type network has two specific benefits: (1) For complex environment recognition, adding residual units will help the network training, improving recognition accuracy. (2) The long connection of low-level information and high-level information of the network and the skip connection of the residual unit are conducive to the dissemination of information, the parameter update distribution is more uniform, and the network model can have better performance.
In this paper, the nine-level architecture of the deep residual U-type network was applied to the identification of targets in the orchard environment, and the network consisted of three parts: a coding layer, bottleneck layer, and decoding layer. The first part of the coding layer extracts the features in the image, forming a feature map. The second part of the bottleneck layer connects the coding layer and decoding layer, equivalent to the bridge, to obtain low-frequency information in the image. The third part of the decoding layer restores the feature map to pixel-level classification, that is, semantic segmentation. Residual units were added to the coding and bottleneck layers to obtain contextual information, and the convolutional modules in the network contained a convolution layer, a batch normalization (BN) layer, and an activation function (Rectified Linear Unit, ReLU). Adopting the batch normalization layer can prevent instability of network performance caused by too many data before the activation function, which effectively solves the problem of gradient disappearance or gradient explosion [
25]. Using the ReLU activation function can effectively reduce the amount of calculation and increase the nonlinear relationship between the various layers of the neural network [
26]. The identity mapping connects the input and output of the residual neural network unit. Since the dimensionality of the input image changes during convolution, the corresponding dimension of the input image also needs to be changed during identity mapping. In this paper, a convolution kernel with a size of 1 × 1, a step size of 1, and a batch normalization layer was used as the identity mapping function.
There are four residual units in the coding layer, each of which is activated by the ReLU function after the residual function and constant mapping function are added together, and then the feature graph size is halved by Maxpool, which can effectively reduce parameters, reduce overfitting, improve model performance, and save computational memory [
27]. The decoding layer consists of four basic units, using bilinear upsampling and the convolutional module for decoding. Compared with deconvolution, the above method is easier to implement in engineering and does not involve too many hyperparameter settings [
28]. At the same time, the feature information in the coding layer is fused with the feature information in the decoding layer by a jumping connection, which makes full use of the semantic information and improves the recognition accuracy. After the last layer of decoding, a 1 × 1 convolution and the Softmax activation function are used to achieve multi-classification identification of the orchard environment. The network model in this paper has 25 convolutional layers and 4 maximum pooled layers, and the structure of the network model is shown in
Figure 4.
3.3. Loss Function
When training the segmentation network, the images that need to be trained are split through the segmentation network to get segmentation images
.
is the segmentation network model, and
is the input image. The segmented image
is compared with the corresponding label image
, and the loss function is minimized to make the segmented image close to the original labeled image, which ensures that the segmentation network can produce accurate predictions and has good robustness. In this paper, the standard cross-entropy loss function was used as a loss function to detect the difference between the segmentation image
and the labeled image
[
29]. The expression of the cross-entropy loss function is
where
is the cross-entropy loss function;
is the ground truth (GT);
is the input image;
is the segmentation image; and
denote the height, width, and number of channels of the image, respectively.
4. Orchard Environment Identification Test
The fully convolutional neural network, the U-type network, the Front-end+Large network, and the deep residual U-type network can all achieve image pixel-level semantic segmentation, but the four networks have their own unique characteristics. Among them, the fully convolutional neural network uses deconvolution to achieve semantic segmentation without a bottleneck layer, and it uses the force pooling method to enter the decoding layer from the encoding layer directly. The U-type network adds a bottleneck layer between the encoding and decoding layers to realize a smooth transition, and it adopts upsampling and skip connection for decoding to achieve semantic segmentation. The Front-end+Large network has high recognition accuracy and high adaptability to different images, so it is widely used in farmland road recognition. The deep residual U-type network adopts a U-type network structure. By adding residual blocks in the coding layer and the bottleneck layer, the image context information and multi-layer network are fully utilized to realize detailed processing of the image. We conducted an experimental comparative analysis of the above four networks, as detailed in the following.
4.1. Test Implementation Details
Based on the deep residual U-type network model proposed above, the deep learning framework Pytorch was used to build the orchard environment recognition and segmentation model. There were a total of 6214 training images with a size of 1024 × 512. The hardware environment of the experiment was an Intel Core I7 9700K 8-core processor with a GeForce RTX 2070 and an 8 GB memory capacity.
With the deepening of training, the model is easily caught in the local minimum problem. In order to solve this problem, we adopted the RMSProp algorithm [
30], which, according to the principle of minimization of the loss function, constantly dynamically adjusts the network model parameters to make the objective function converge faster. The initial learning rate in the RMSProp algorithm was set to 0.4, and the weight attenuation coefficient was 10
−8. During model training, the batch size of data loading was 8, the number of iterations was 300, and the loss function value was recorded for each iteration.
4.2. Evaluation Indicators
There are three evaluation criteria for semantic segmentation, namely, execution time, memory footprint, and accuracy. The accuracy is based on the manually annotated image as the basic standard, compared with the prediction image from the segmentation network, and judged by calculating the pixel error between the prediction image and the real annotated image.
Suppose there are k + 1 categories (k target categories and one background category), Pii represents a correct prediction, and both Pij and Pji represent incorrect predictions. The general evaluation criteria are as follows:
- (1)
Pixel Accuracy (
PA): The ratio of the number of correctly classified pixels to the total number of pixels, and the formula is
- (2)
Mean Pixel Accuracy (
MPA): The average value of the ratio of the number of correct pixels in each category to the total number of pixels in that category,
- (3)
Mean Intersection over Union (
MIoU):
Among the above criteria, the
MIoU is the most representative and easy to implement. Many competitions and researchers use these criteria to evaluate their results [
31]. In this paper,
PA and
MIoU were used as evaluation indicators for different categories of segmentation and overall network models.
4.3. Test Results and Analysis
When the deep residual U-type network model was trained, the model was saved every five iterations, and the model with the highest average intersection ratio among all models was selected as the test model. In order to verify the superiority of the proposed network model, it was compared with the fully convolutional neural network model, the U-type network model, and the Front-end+Large network.
Figure 5,
Figure 6,
Figure 7 and
Figure 8 show the loss values and
MIoU of each iteration of the four network models.
Table 2 reports the highest Pixel Accuracy (
PA) and the highest
MIoU for category segmentation.
From its training effects, the fully convolutional neural network has a larger floating amplitude and higher frequency. After about 100 iterations, the loss value and the
MIoU tended to stabilize, but the floating range was large. The fully convolutional neural network discards the fully connected layer and uses deconvolution to realize semantic segmentation. When recognizing the complex environment of the orchard, there are more network parameters in the fully convolutional neural network, which leads to problems such as the segmentation of the details in the image not being clear enough, the segmentation boundary between different categories being blurred, and the training time being long. The training effect of the U-type network in
Figure 6 was significantly better than that of the fully convolutional neural network. The network tended to be stable after about 60 iterations. Up-sampling was adopted to map the feature images, which greatly reduced the network parameters. However, there were still fluctuations in the preliminary training process, which was due to insufficient network depth and poor ability to distinguish the boundaries of different categories in the image during training. The effect of Front-end-Large network training in
Figure 7 was significantly improved compared with that for the first two networks. The fluctuation in the previous training was small and tended to be stable around 54 iterations. The training effect of the deep residual U-type network in
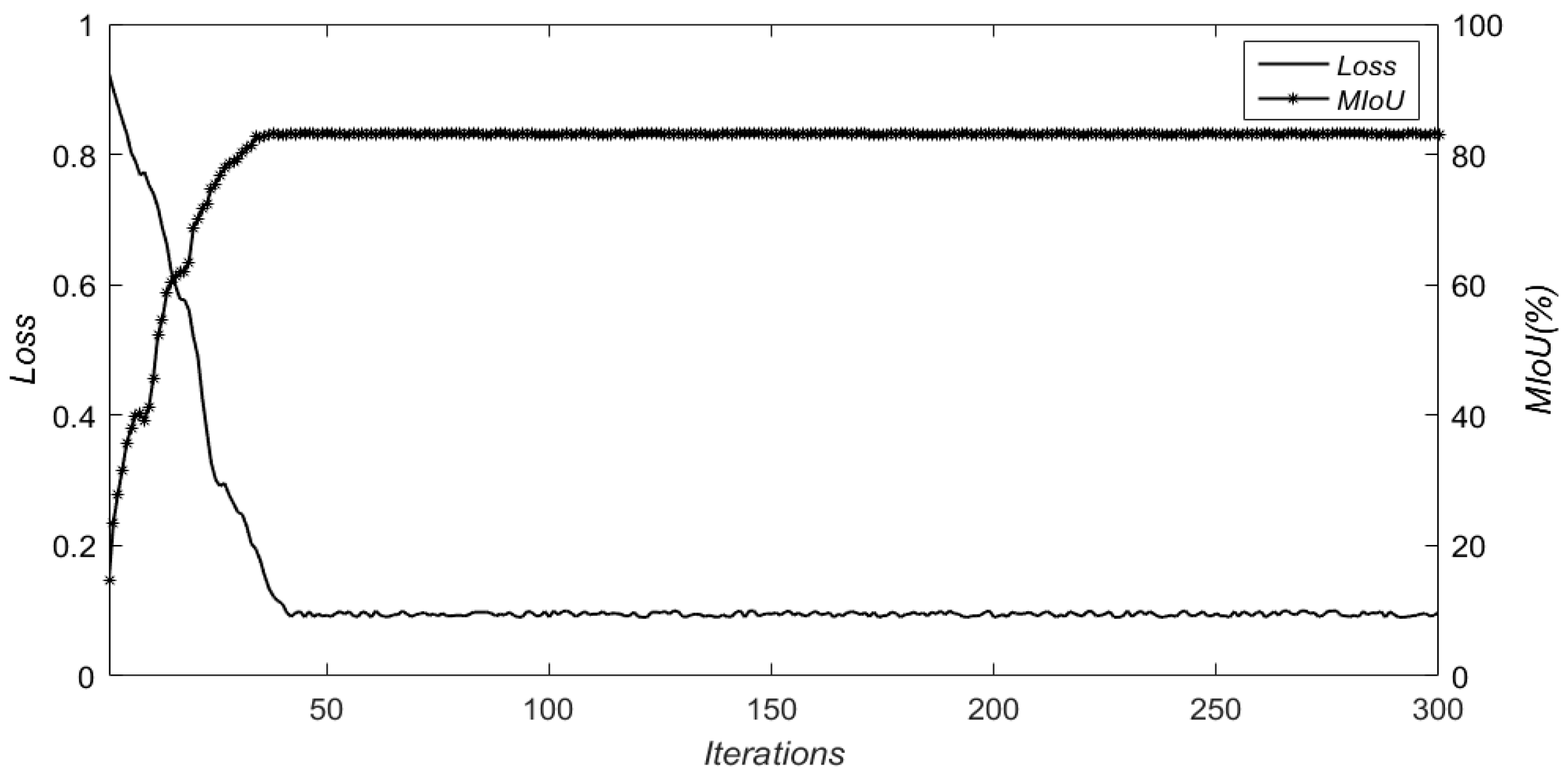
Figure 8 was significantly better than that of the first three networks. There was no obvious fluctuation in the early training period, the change in the loss value and
MIoU was small after about 40 iterations, and the overall training time was short and stable. The deep residual U-type network adopts the U-type network structure but adds a residual block in the coding layer and fuses the image feature information, which better processes the image boundary information. In addition, a jump connection and constraints were added to the decoding layer, which effectively reduced network parameters. Among the four networks, the deep residual U-type network had the lowest loss value, the highest
MIoU, and the best training effect.
As can be seen from
Table 2, in the category segmentation of the orchard environment, the four semantic segmentation network models had high accuracy in pixel recognition for backgrounds and roads, but low accuracy in recognition of fruit trees and debris. The average intersection ratio of the deep residual U-type network proposed in this paper was 85.95%, which is higher than those of the first three network models, and achieved better results in orchard environment recognition.
Figure 9 shows the respective semantic segmentation prediction images from the four network models. Among them, the segmentation image generated by the fully convolutional neural network model has the following shortcomings: One is that some areas’ categories were lost in the segmentation, and small objects such as small branches could not be identified. The other is that for the segmentation of a large region, the boundary detail information processing capability is insufficient; as shown in the figure, the segmentation of the road boundary is not clear enough. This result is due to the fact that the fully convolutional neural network model uses deconvolution in the decoding process. Although this method is simple and feasible, it causes problems such as violent pooling, blurring of segmented images, and lack of spatial consistency. Compared with the fully convolutional neural network model, the segmentation image generated by the U-type network model has higher
MIoU and better segmentation effect. However, for the overlapping parts of the categories, the difference in the features of the separated categories is not obvious, the boundary of the overlapping part is rough, and the overlapping parts are easily lost, such as details of the intersection of fruit trees and sundries. For the complex environment of the orchard, due to insufficient depth of the U-type network, the detailed information of each category cannot be fully utilized, and overfitting occurs in the training process. The segmentation image generated by the Front-end+Large network has improved overall effect compared to those by the fully convolutional neural network and the U-type network, but some details, such as branches and debris, were still lost. It can be seen from the segmentation result image that the orchard environment recognition model based on the deep residual U-type network can well reflect the boundary information in the large area and small region category segmentation. The recognition accuracy was higher than that of the previous three segmentation network models.
In summary, the U-type network model based on deep residuals proposed in this paper can effectively improve the recognition accuracy of orchard environments, and the segmentation model can also show better robustness for complex orchard environments and light changes.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}