1. Introduction
We could argue that words have specific meanings set in stone, or rather written in dictionaries. Much evidence seems to indicate that this view is far too simplistic and ignores the important influence of the context in which these words are used. Not only can the same word have a different meaning depending on the context, but its meaning can also slowly change with time [
1,
2,
3]. Contextual information can also help us learn new words, including in different languages, or new forms of languages [
4,
5].
With the development of mobile phones a couple of decades ago followed by the rise of instant text conversations came alternative forms of written language meant to optimize the content that could be inserted into messages with a limited number of characters. Shortened words such as “Kdo” for “cadeau” (French for “gift”) started being used by young people to the dismay of older people for whom deciphering messages sent by their own children became a task of its own. Thus started the spread of an alternative form of written language referred to as “textism” [
6]. Even though this specific form of writing gradually decreased with the ability to write longer messages and automatic spell-checkers (in particular, the contractive forms of textisms, while messages that include more emotional content like smileys or additional punctuation marks: “Oh yeah!!!! :)” have instead been spreading [
7,
8]), it is an interesting example of an alternative form of written language worth investigating for two main reasons. The first one is that textism takes its roots in a language already well known by people, but changes how it is written. This makes it difficult to decipher when one is not used to this form of writing if additional clues indicating the meaning of the message are not present. Thus, it is a valuable tool to study the progressive acquisition of meaning and the establishing of links between the form of a word and its underlying concept. The second reason is that although intensive use of textism (messages written solely in textisms) has decreased, many symbols and practices that have been developed in it are still widely used to this day (e.g., the very common “lol”, “mdr” in French, and many others, but also content that creates a bridge with the oral form of communication by writing down emotional clues that would have been present in the intonation of facial expressions, such as smileys) [
7,
8].
In this paper, we explored whether accessing the semantic content of messages written in textism requires a higher cognitive cost for people who are not particularly versed in using it and, more importantly, if context can offer pragmatic clues helping with retrieving the meaning of messages.
2. The Importance of Context in Conversations
A whole field of study in psychology and linguistics is specialized in the investigation of the importance of context in our use of language: the pragmatics of language. Today, one of its findings, that the context greatly influences the way we interpret utterances, is well established not only in conversations [
9,
10], but also in problem-solving tasks [
11,
12,
13,
14]. While the importance of context when inferring meaning has been generally ignored in the design of digital agents made to converse with humans, it is now starting to be applied to allow artificial agents to more efficiently understand the meaning of sentences in a conversation by using contextual information and user expectations [
15,
16].
Why is this? The reason is that what we say is not directly what we mean. This aspect of language was described first by Grice [
17] who tried to formalize the rules of discourse. The main aspect of Grice’s findings is that participants in a conversation follow a principle of cooperation, essentially meaning that they are trying to make what they mean as clear as possible so that it is correctly understood by the other. In other words, people in a conversation say what they believe needs to be said to convey what they mean to the other. A simple example of this would be saying “It’s cold in here” to mean “Can you close the window because I feel cold here and I do not like to feel cold”, or “Can you pass the salt?” to mean “Give me the salt because you are closer and I cannot reach it myself”.
This framework was then expanded by relevance theory [
18], which generalized Grice’s conversational maxims to be more cognitively anchored with what was understood of the brain thanks to advances in the field of neuroscience. This theory suggests that the relevance of an utterance depends on two main attributes: contextual effects (i.e., what effects does the utterance have on the mental representations of the listener; does it change them at all?) and the cognitive cost required to interpret them (i.e., how many resources do I need to allocate to the processing of the sentence to make it understandable?).
Not only are the sentences in the examples above simpler, but they are also perceived as being more polite through the use of indirect speech. Being direct could indeed be perceived as being commanding and would be detrimental to the relationship [
19].
Neither of these examples directly tells the person what to do, and yet, they will be broadly understood as “They want me to do something about it, and not just tell me about their physical condition (window example) or asking about my ability to do something (salt example)”.
Therefore, what we say is not directly what we mean, and this difference is expected by our interlocutors and understood as such: words are used as clues to gain access to the meaning, and what they represent can be narrower or broader than their usual definition in a dictionary, depending on the context in which they are being used [
20,
21,
22,
23]. Thus, the form of production should not impede gaining access to the meaning as long as enough clues are given.
3. Textisms as a Phonological Approach to Spelling
One way to change the form of linguistic production without changing its meaning is to use alternative forms of writing. Textism is a form of writing used in text messages in phone-mediated conversations. As initially text messages were limited in the number of characters that could be sent without additional costs and by the time required to write a single letter on a phone with nine buttons, young adults around the world developed various forms of writing used to make the most out of a limited number of characters while still being able to communicate efficiently.
For French variations, Panckhurst [
24] described and classified the many liberties taken in SMS messages compared to traditional spelling for various words and expressions. Fairon et al. [
25] also reported similar observations while pointing out some areas of resistance, such as the use of the digrams “ph”, “rh”, or “th”, which are counterintuitively kept in French textisms, even though the traditional spelling of some other languages abandoned them (like Italian). Most of the changes drastically simplify the spelling of particular sounds, such as “o”, which replaces “eau” (water) and can also be found in other words like “Kdo” for “cadeau” (gift), “bato” for “bateau” (boat), and many others. Some of these changes include removing silent letters: “vou” for “vous” (you), “douch” for “douche” (shower), and of course, truncations “ordi” for “ordinateur” (computer) and acronyms such as “lol” for “laughing out loud”.
For people not used to this way of spelling, this can make understanding messages quite complex and become a form of exclusion. It often contributes towards making inter-generational conversations difficult especially since this form of writing tends to be used mostly by young adults who generally use texting more often than other age groups [
26].
Thus, it is likely that the use of textism requires a higher cognitive cost in order to understand the meaning of a message for people who are not used to it, but this higher cognitive cost might be decreased by giving contextual clues of the meaning of the words. For example, the meaning of the word gift (“cadeau” or “Kdo” in textism) is easier to infer in the sentence “tu ve 1 Kdo pr ton anniv ?” (Do you want a gift for your birthday?) than in the sentence “jéT ds la voiture ac un Kdo” (I was in the car with a gift). Indeed, in the first sentence, the setting of the birthday is quickly related to the concept of gift, and that will very likely decrease the amount of effort (cognitive cost) required to reach the conclusion that “Kdo” means gift, as this interpretation gives the most contextual effect. In the other sentence, the words car and gift are not related, and understanding one does not give any clue to help infer the meaning of the other.
Studies exploring cognitive cost in the use of textisms are few, but they seem to indicate that the use of textisms is correlated with an increase in reading time and also has an effect on some measures linked to cognitive effort: studies using eye-trackers indicate that more fixations are made on sentences that contain textisms and that fixations last significantly longer than with sentences containing standard English [
27,
28]. Similar results were observed between Chinese Net-Speak and standard Chinese, with Net-Speak increasing the response time during a task of text recognition [
29].
4. Response Times to Estimate the Cognitive Cost
The cognitive cost (the amount of mental resources required to process information) is not directly accessible for observation and yet is an important element of many theories in psychology, in particular for relevance theory [
18]. Depending on the experiments, indirect measures can be made to estimate the cognitive cost required to process stimuli and to respond to them. Some of these indirect measures include recording pupil dilation (which requires specific instruments and heavy control to mitigate the influence of other factors) [
30], the success rate in primary or secondary tasks [
31], and latencies such as response times used in the present research (or reaction times for fast processes) [
32,
33].
Response times have the benefit of being non-invasive for participants who are not distracted in their task by the measure. They also have the benefit of being quite easy to implement in online experiments and do not require any specific equipment. Still, they are only a potential indicator of the cognitive cost and not a direct measure. Any interpretation should take this fact into account. Response times are easy to record in online conversations, and different studies have shown that they are compatible with how the cognitive cost should vary when studying violations of conversational expectations [
32,
33]. Jacquet et al. [
32,
33] indeed showed that during a Turing test (i.e., a test evaluating how human a conversational agent feels by comparing two conversations, one with the tested agent and the other with a human reference [
34,
35]), the participants’ response times were significantly higher when the experimenter violated Grice’s maxim of relation and Grice’s maxim of quantity (giving too much information) in a conversation, compared to a conversation in which the Gricean maxims were respected.
In the present experiment, we used a similar experimental protocol, adapted to investigate the influence of the use of textisms by the experimenter on participants’ response times. Would the use of textisms significantly increase the response times of participants in a conversation compared to the use of a more traditional writing style? Would this increase be mitigated if the conversation written in textisms followed another on the same topic, but without the use of textisms, thus indicating that the context can help decipher this form of writing? These two questions were the object of this study.
5. Materials and Methods
The experiment was adapted from Jacquet et al. [
32,
33]. The main differences were that in these experiments, the authors investigated the influence of violations of the Gricean conversational maxims on the response times of participants in a Turing test [
34], with the experimenter violating the maxims in one conversation and respecting them in the other. In this experiment, we instead made use of textisms in one of the two conversations as a replacement of the violations of the maxims.
The experimental protocol used in this study was evaluated by the Ethics Committee of the P-A-R-I-S association (Document is available at
https://osf.io/eua6w/).
5.1. Participants
All participants were young adults, native French speakers, and used their phones to send text messages on a regular basis (their use of texting being evaluated at the beginning of the experiment). All participants agreed to participate in this experiment and were informed that they could cancel their participation at any point. The mean age was 23 (). There were 23 males and 11 females, and four chose not to answer this question. We initially included two more participants who were later removed from the study as they showed an expertise in using textism in conversations (they communicated with textisms themselves) and thus were not homogeneous with the other participants and could not be included in the analyses. Other participants did not attempt to write in textisms back to the experimenter, and some even asked them to “speak normally” instead (despite the age of the participants, this was not unexpected for multiple reasons: (1) because of the decrease of the contractive forms of textisms and (2) because textisms are mostly used in informal conversations with people one already knows, which was not the case here as they knew neither the experimenter nor the fictive character).
5.2. Materials
The experiment was implemented via an online chat designed specifically for this study. Participants first answered a set of socio-demographic questions, as well as how frequently they used text messages. All participants were asked to use a phone to participate in the experiment. After agreeing to a virtual informed consent form and confirming that they were native French speakers, they were sent to a different page with an interactive conversation with the experimenter. The experimenter took two roles during the conversations: the role of moderator and the role of “Elsa”, who was introduced to the participant as being a fictive character that would be played by two different “actors”, one being a chatbot and one being human, even though they were both played by the same experimenter. In order to standardize conversations as much as possible despite the potentially chaotic nature of conversations, “Elsa” had a pre-defined character sheet with all their personal information. If the experimenter received an unexpected question, he/she wrote down the answer to ensure he/she would use a similar answer with all participants in the future should the same question arise. Conversations were recorded, and the precise timing (to the ms) of the reception of each message on the server was also recorded. The recorded delay between messages corresponded to the difference between the time when the message was received by the participant and the time when he/she sent his/her reply. Following the experiment, participants answered additional questions to test their skills in understanding textisms.
5.3. Methods
Participants were first introduced to the conversations by the experimenter displayed as “Moderator”. The moderator explained to the participant he/she would be taking part in a Turing test (i.e., finding out which of the two actors playing Elsa was in fact a chatbot and which one was a human, after one conversation with each actor). This was used to give the participants the motivation to actively converse with the two actors with a goal that was not explicitly related to the use of textisms in conversations. This way, participants did not expect one of the two conversations to be written with textisms. Each participant conversed with Elsa twice, once with the experimenter playing her through messages written in traditional spelling (conversation type: normal) and once through messages written in textisms (conversation type: textisms). Whether participants conversed first with Elsa writing with traditional spelling or textisms was randomly decided with adjustments to achieve a similar number of participants in each condition. At the end of each of the two conversations, the participants told the moderator if they thought the first actor they had conversed with was a chatbot/artificial intelligence or a human. They were able to stop the conversation at any moment if they had made up their mind; otherwise, each conversation lasted 7 min.
5.4. Analyses
Because of the great variability of messages in a conversation, it is not possible to directly link the delay between messages to the cognitive cost required to process them. Indeed, the part of the delay of interest to us (linked to the cognitive cost of understanding the message and preparing a reply to it) can be overshadowed by other factors that have a strong effect on the response times of participants. Thus, it was important to reduce this noise before doing any further analysis.
A factor of noise that can be clearly identified is the length of sentences. Indeed, longer messages take more time to read, and writing long replies also takes more time. Eliminating these two aspects as much as possible greatly diminishes the noise in collected data.
To do this, we used a linear regression model taking into account the length of the experimenter’s message (
) and the length of the participant’s reply (
) to predict the theoretical delay in normal conversations (
D). Just as in [
32,
33], we used a simple linear model here to define the average reading and writing speed of participants, as the number of turns during a conversation was generally not enough to get a good model for each individual participant.
This allowed us to calculate
: the difference between the observed response time (
d) and the theoretical delay (
D), which gave us a measure where the noise from the length of the messages was filtered out.
This process is similar to calculating residual reading times (see [
36,
37], for examples), with the distinction that we were also taking into account residual writing times in the calculation of
.
It is this difference that was then analyzed using a type III ANOVA, with the order and the type of conversation as the two factors. The data were tested for normality, and the outliers were cleaned (beyond 3 standard deviations above or below the mean, which removed 10 out of 873 measures).
6. Results
The final equation of the linear model calculated on normal conversations was:
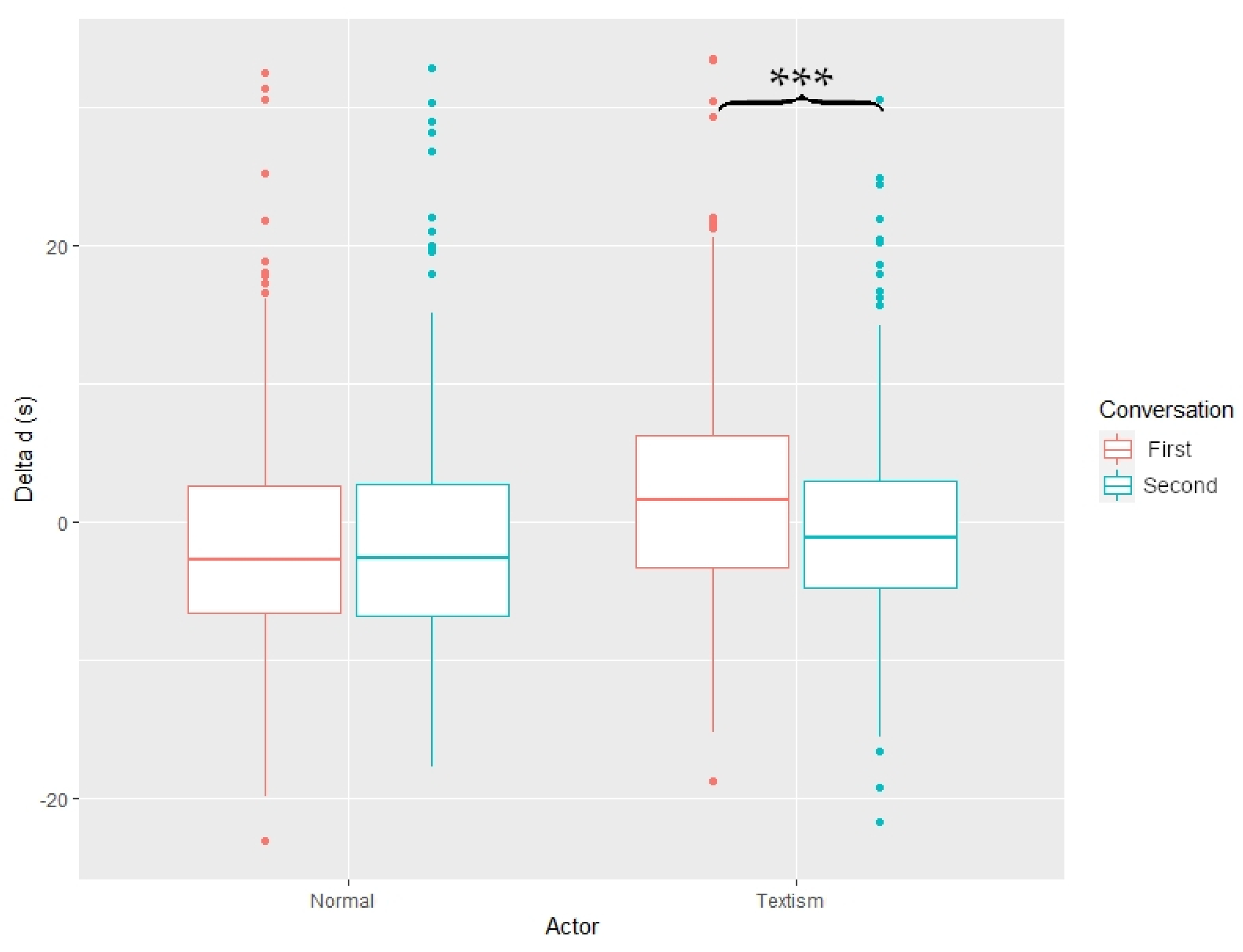
for each condition are shown in
Figure 1. We observed a significant main effect of the type of conversations (normal or textisms) on
(
). There was a significant interaction between the order of conversations (first or second) and the type of conversations (normal or textisms) (
). Indeed, while
was similar in normal conversations (
) regardless of whether they came first (
) or second (
), conversations with textisms had a significantly higher
when they were the first conversation (
) compared to when they were in the second (
) (
). While it was not the direct object of interest of this study, we did not observe any significant effect of textisms on the answers in the Turing test (whether using textisms made Elsa feel more human-like or not). We also did not find any statistically significant effect of the gender of participants in this study.
7. Discussion
As we anticipated, textism significantly increased the response time of participants in our experiment. This was consistent with the results found in previous studies [
27,
28,
29]. Yet, the impact of messages written in textism seemed to have decreased when they were used in a second conversation following a conversation with a more traditional spelling. This was coherent with our initial hypotheses. Indeed, the decrease of the delay when textisms were used in the second conversation indicated that the participants had quicker access to the semantic content of the messages. Since the only difference between the two conversations was the presence or absence of clues given in a previous conversation, we can readily assume that this effect would be caused by prior knowledge extracted from the first conversation.
Since the topic of conversations was similar in both conversations (how participants experienced the confinements in France, what they liked doing, and their contacts with their family), participants must have used their prior knowledge acquired during the first conversation in order to help them understand the meaning of Elsa’s messages. A similar effect was shown in the experiment of Jacquet et al. [
33]: a more complicated way of reading information (in their case, by giving too much unnecessary information) did not have any effect on the response times when it happened in a second conversation in which participants had prior knowledge of the information about to be given. The authors explained that this difference was caused by an effect of surprise when the violations happened in the first conversation. Indeed, in that case, the irrelevant information added did not change much of the mental representations of the participants as additional information was not what they had any interest in (low contextual effect), while the longer sentence increased the effort required to process it. In the second conversation, participants already knew of the piece of information given in the answer. For them, it was only a confirmation of something they already knew (low contextual effect), but because of that, the irrelevant pieces of information added did not significantly increase the effort required to process the sentence (the cognitive cost remained fairly low).
Similarly, in our case, the same information about Elsa was given in the two conversations. When participants met and conversed with Elsa, they had no prior knowledge of what was going to be said. When this information was given in textisms, the only way to understand the meaning was to decipher the textisms directly (high contextual effect and high cognitive cost). When textisms were used in the second conversation, participants already had most of the information being told, and the same information was simply given in a different way (low contextual effect as there was not much change on the participant’s mental representations). Furthermore, the effort required to get that information was smaller as two alternative paths could be used: one involved the participant’s memory of the previous conversation (effect of the context of the conversation: the influence of the previous conversation on the second conversation), and the other involved deciphering textisms. Both of these methods could also be used at the same time to converge to a single interpretation of the message, thus decreasing the cognitive cost (The participants did not need to spend as much time deciphering the textisms as the information in their memory already provided a good amount of the meaning).
One question could be whether the effect we observed could be caused by a lexical priming (seeing a word written once primes the reader to expect it again in the future) [
38,
39] or a topical effect (the knowledge of the information about to be given helps decipher the unfamiliar text). In our experiment, the topics were similar between the two conversations, but no restrictions were imposed on the exact words being used in the experimenter’s replies as long as the information given remained consistent (Elsa could not have two siblings in one conversation and none in another for example, but the experimenter could express it in different ways depending on the question asked). This question could likely be answered in a future experiment by designing a protocol that would independently test the influence of lexical priming and of the topical effect.
All of this indicated that deciphering textisms without prior information about the context of the conversation is a task that requires a significant amount of cognitive effort and that deciphering textisms becomes easier when participants know about the semantic content of the messages, as we expected.
It is also important to note that in our case, participants were young adults who, by definition, while not being experts in textisms, had a higher probability of knowing how they worked. We would expect the differences to be even stronger between traditional writing and textisms if participants were older people who were not used to textisms at all. It is yet unknown how much of a decrease in response times would be observed when older participants would encounter textisms in the second conversation compared to when they would encounter them in the first conversation. Indeed, while older participants might find deciphering textisms to be even more complicated than our younger participants (thus, we would expect a higher than we observed for textisms in the first conversation), we do not know if they would be able to use their knowledge of the first conversation to decipher textisms as well as the younger participants in this study. Two alternative patterns of results could then be considered for such an experiment: older participants would have a higher than we observed in the first conversation with textisms (because of the higher cognitive cost required), but in the second conversation, would also come close to the baseline (around 0 s) if the prior information was enough to fully disambiguate the textisms, or alternatively, could reach a middle level between the value observed in the first conversation and the baseline if the prior information only partially helped to decipher the textisms.
8. Conclusions
Our results seemed to indicate that participants had less difficulty processing messages containing French textisms when they already knew the context of the conversation. This suggested that a good way to get used to alternative forms of language would be to be trained using a familiar context. Further study needs to be performed to examine whether this habituation to this form of writing lasts and could be considered as an actual learning experience or if it is only circumstantial.
This study also gave additional evidence that language understanding does not strictly depend on the shape of the words being used, but rather that expectations about the message being read greatly influence the way we read it and how we understand it.
Author Contributions
Conceptualization, B.J. and J.B.; methodology, B.J. and J.B.; software, B.J.; visualization, B.J.; validation, F.J. and S.G.; formal analysis, B.J.; investigation, C.J.; data curation, B.J.; writing—original draft preparation, B.J. and J.B.; writing—review and editing, B.J, C.J., S.G., F.J., and J.B.; supervision, J.B.; project administration, J.B. All authors read and agreed to the published version of the manuscript.
Funding
This research was funded by the Carnot Institute, for Project LAC (Langages Alternatifs et Cognition).
Institutional Review Board Statement
The study was conducted according to the guidelines of the Declaration of Helsinki and approved by the Ethics Committee of the P-A-R-I-S association (Protocol Code Turing, 13th of February 2018). (Document available at
https://osf.io/eua6w/).
Informed Consent Statement
Informed consent was obtained from all participants involved in the study.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; nor in the decision to publish the results.
References
- Michel, J.B.; Shen, Y.K.; Aiden, A.P.; Veres, A.; Gray, M.K.; Pickett, J.P.; Hoiberg, D.; Clancy, D.; Norvig, P.; Orwant, J.; et al. Quantitative analysis of culture using millions of digitized books. Science 2011, 331, 176–182. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reali, F.; Griffiths, T.L. Words as alleles: Connecting language evolution with Bayesian learners to models of genetic drift. Proc. R. Soc. B Biol. Sci. 2010, 277, 429–436. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wijaya, D.T.; Yeniterzi, R. Understanding semantic change of words over centuries. In Proceedings of the 2011 International Workshop on Detecting and Exploiting Cultural Diversity on the Social Web, Glasgow, UK, 24–28 October 2011; pp. 35–40. [Google Scholar]
- Paribakht, T.S.; Wesche, M. Reading and “incidental” L2 vocabulary acquisition: An introspective study of lexical inferencing. Stud. Second Lang. Acquis. 1999, 21, 195–224. [Google Scholar] [CrossRef]
- Çetinavcı, B.M. Contextual factors in guessing word meaning from context in a foreign language. Procedia Soc. Behav. Sci. 2014, 116, 2670–2674. [Google Scholar] [CrossRef] [Green Version]
- Plester, B.; Wood, C.; Joshi, P. Exploring the relationship between children’s knowledge of text message abbreviations and school literacy outcomes. Br. J. Dev. Psychol. 2009, 27, 145–161. [Google Scholar] [CrossRef] [PubMed]
- Kemp, N.; Grace, A. Txting across time: Undergraduates’ use of ‘textese’in seven consecutive first-year psychology cohorts. Writ. Syst. Res. 2017, 9, 82–98. [Google Scholar] [CrossRef]
- Kemp, N. Textese: Language in the online world. The Oxford Handbook of Cyberpsychology. 2019, p. 151. Available online: https://www.oxfordhandbooks.com/view/10.1093/oxfordhb/9780198812746.001.0001/oxfordhb-9780198812746-e-11 (accessed on 25 May 2021).
- Gallagher, S. What in the world: Conversation and things in context. In Minimal Cooperation and Shared Agency; Springer: Cham, Switzerland, 2020; Volume 11, pp. 59–70. [Google Scholar]
- Jacquet, B.; Baratgin, J. Mind-Reading Chatbots: We Are Not There Yet. In Human Interaction, Emerging Technologies and Future Applications III; Ahram, T., Taiar, R., Langlois, K., Choplin, A., Eds.; Springer International Publishing: Cham, Switzerland, 2021; Volume 1253, pp. 266–271. [Google Scholar]
- Pollard, P.; Evans, J.S.B.T. Content and Context Effects in Reasoning. Am. J. Psychol. 1987, 100, 41–60. [Google Scholar] [CrossRef]
- Jamet, F.; Masson, O.; Jacquet, B.; Stilgenbauer, J.L.; Baratgin, J. Learning by teaching with humanoid robot: A new powerful experimental tool to improve children’s learning ability. J. Robot. 2018, 2018. [Google Scholar] [CrossRef]
- Baratgin, J.; Dubois-Sage, M.; Jacquet, B.; Stilgenbauer, J.L.; Jamet, F. Pragmatics in the false-belief task: Let the robot ask the question! Front. Psychol. 2020, 11, 3234. [Google Scholar] [CrossRef] [PubMed]
- Baratgin, J.; Jamet, F. Le paradigme de « l’enfant mentor d’un robot ignorant et naïf » comme révélateur de compétences cognitives et sociales précoces chez le jeune enfant. In Proceedings of the WACAI 2021, Workshop Affect, Compagnon artificiel interaction, ile d’Oléron, France, 13–15 October 2021. [Google Scholar]
- Ghosh, D.; Fabbri, A.R.; Muresan, S. Sarcasm Analysis Using Conversation Context. Comput. Linguist. 2018, 44, 755–792. [Google Scholar] [CrossRef]
- Jacquet, B.; Baratgin, J. Towards a pragmatic model of an artificial conversational partner: Opening the blackbox. In Proceedings of the International Conference on Information Systems Architecture and Technology, Wrocław, Poland, 15–17 September 2019; pp. 169–178. [Google Scholar]
- Grice, H.P. Logic and conversation. In Speech Acts; Cole, P., Morgan, J.L., Eds.; Brill: Leiden, The Netherlands, 1975; pp. 41–58. [Google Scholar]
- Wilson, D.; Sperber, D. Relevance Theory. In Handbook of Pragmatics; Ward, G., Horn, L., Eds.; Blackwell: Oxford, UK, 2002. [Google Scholar]
- Leech, G.N. The Pragmatics of Politeness; Oxford University Press: New York, NY, USA, 2014. [Google Scholar]
- Carston, R. Enrichment and loosening: Complementary processes in deriving the proposition expressed. In Pragmatik; Springer: Berlin/Heidelberg, Germany, 1997; pp. 103–127. [Google Scholar]
- Carston, R. Thoughts and Utterances: The Pragmatics of Explicit Communication; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Sperber, D.; Wilson, D. The mapping between the mental and the public lexicon. In Meaning and Relevance; Cambridge University Press: Cambridge, UK, 2012; pp. 31–46. [Google Scholar]
- Wilson, D.; Kolaiti, P. Lexical pragmatics and implicit communication. In Implicitness: From Lexis to Discourse; Cap, P., Dynel, M., Eds.; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2017; pp. 147–175. [Google Scholar]
- Panckhurst, R. Short Message Service (SMS): Typologie et Problématiques Futures. In Polyphonies, pour Michelle Lanvin; Université Paul-Valéry: Montpellier, France, 2009. [Google Scholar]
- Fairon, C.; Klein, J.R.; Paumier, S. Le langage SMS: Révélateur d’1compétence. In Le Français M’a tuer. Actes du Colloque “L’orthographe Française à l’Épreuve du Supérieur”; Presse Universitaire de Louvain: Louvain-la-Neuve, Belgium, 2006; pp. 33–42. [Google Scholar]
- Ling, R. Texting as a life phase medium. J. Comput. Mediat. Commun. 2010, 15, 277–292. [Google Scholar] [CrossRef]
- Perea, M.; Acha, J.; Carreiras, M. Eye movements when reading text messaging (txt msgng). Q. J. Exp. Psychol. 2009, 62, 1560–1567. [Google Scholar] [CrossRef] [PubMed]
- McCausland, S.; Kingston, J.; Lyddy, F. Processing costs when reading short message service shortcuts: An eye-tracking study. Writ. Syst. Res. 2015, 7, 97–107. [Google Scholar] [CrossRef]
- Chen, J.; Huang, S.; Luo, R. Does Net-Speak Experience Interfere with the Processing of Standard Words? Evidence from Net-Speak Word Recognition and Semantic Decisions. Front. Psychol. 2020, 11, 1932. [Google Scholar] [CrossRef]
- Van der Wel, P.; van Steenbergen, H. Pupil dilation as an index of effort in cognitive control tasks: A review. Psychon. Bull. Rev. 2018, 25, 2005–2015. [Google Scholar] [CrossRef] [PubMed]
- Paas, F.; Tuovinen, J.E.; Tabbers, H.; Van Gerven, P.W. Cognitive load measurement as a means to advance cognitive load theory. Educ. Psychol. 2003, 38, 63–71. [Google Scholar] [CrossRef]
- Jacquet, B.; Baratgin, J.; Jamet, F. Cooperation in online conversations: The response times as a window into the cognition of language processing. Front. Psychol. 2019, 10, 727. [Google Scholar] [CrossRef] [PubMed]
- Jacquet, B.; Hullin, A.; Baratgin, J.; Jamet, F. The impact of the gricean maxims of quality, quantity and manner in chatbots. In Proceedings of the 2019 International Conference on Information and Digital Technologies (IDT), Zilina, Slovakia, 25–27 June 2019; pp. 180–189. [Google Scholar]
- Turing, A. Computing Machinery and Intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- Jacquet, B.; Jamet, F.; Baratgin, J. On the pragmatics of the Turing Test. In Proceedings of the 2021 International Conference on Information and Digital Technologies (IDT), Zilina, Slovakia, 22–24 June 2021. [Google Scholar]
- Gibson, E.; Warren, T. Reading-time evidence for intermediate linguistic structure in long-distance dependencies. Syntax 2004, 7, 55–78. [Google Scholar] [CrossRef]
- Lüdtke, J.; Kaup, B. Context effects when reading negative and affirmative sentences. In Proceedings of the 28th Annual Conference of the Cognitive Science Society, Vancouver, BC, Canada, 26–29 July 2006; Volume 27, pp. 1735–1740. [Google Scholar]
- Hoey, M. Lexical priming. In The Encyclopedia of Applied Linguistics; Chapelle, C.A., Ed.; Blackwell Publishing Ltd.: Oxford, UK, 2013. [Google Scholar]
- Bock, J.K. Meaning, sound, and syntax: Lexical priming in sentence production. J. Exp. Psychol. Learn. Mem. Cogn. 1986, 12, 575–586. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, {kind=link}