
An Effective Adaptive Combination Strategy for Distributed Learning Network

Abstract
:1. Introduction
Motivation and Contribution
2. The ATC Diffusion LMS Algorithm
2.1. Model Assumption
2.2. ATC Algorithm
3. Adaptive Combination Scheme
3.1. Minimum Variance Unbiased Estimation
3.2. Fixed-Point Iteration Solution
| Algorithm 1 ATC with the proposed AC strategy |
| For each node k, set and choose so that . Given a small positive constant and step size , at each time instant , compute at each node k: 1. Update the intermediate weight estimate through (2). 2. Update combiner consecutively through (25), (16), (23), (17) and (19). 3. Update the local weight estimate through (3). |
4. Mean Convergence
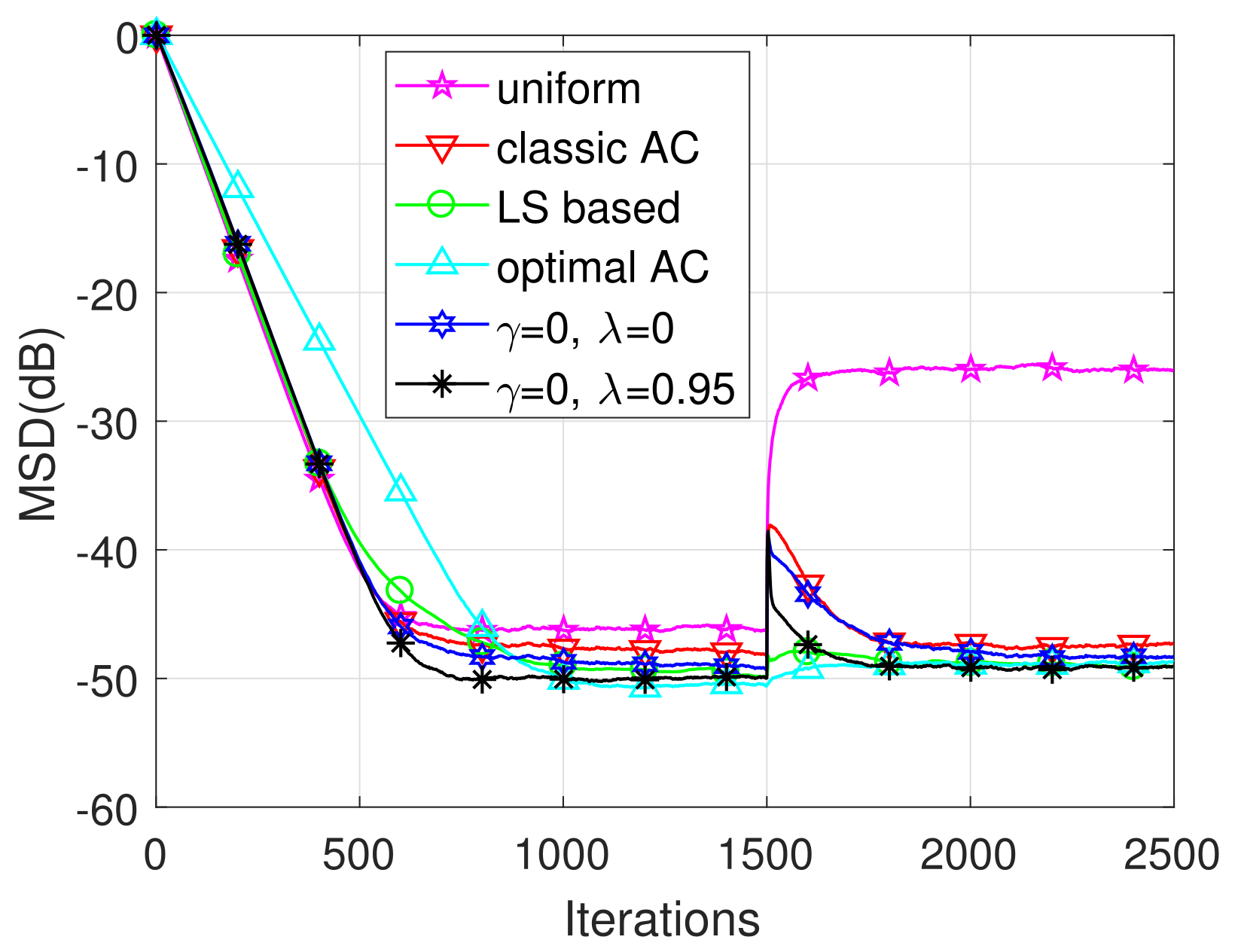
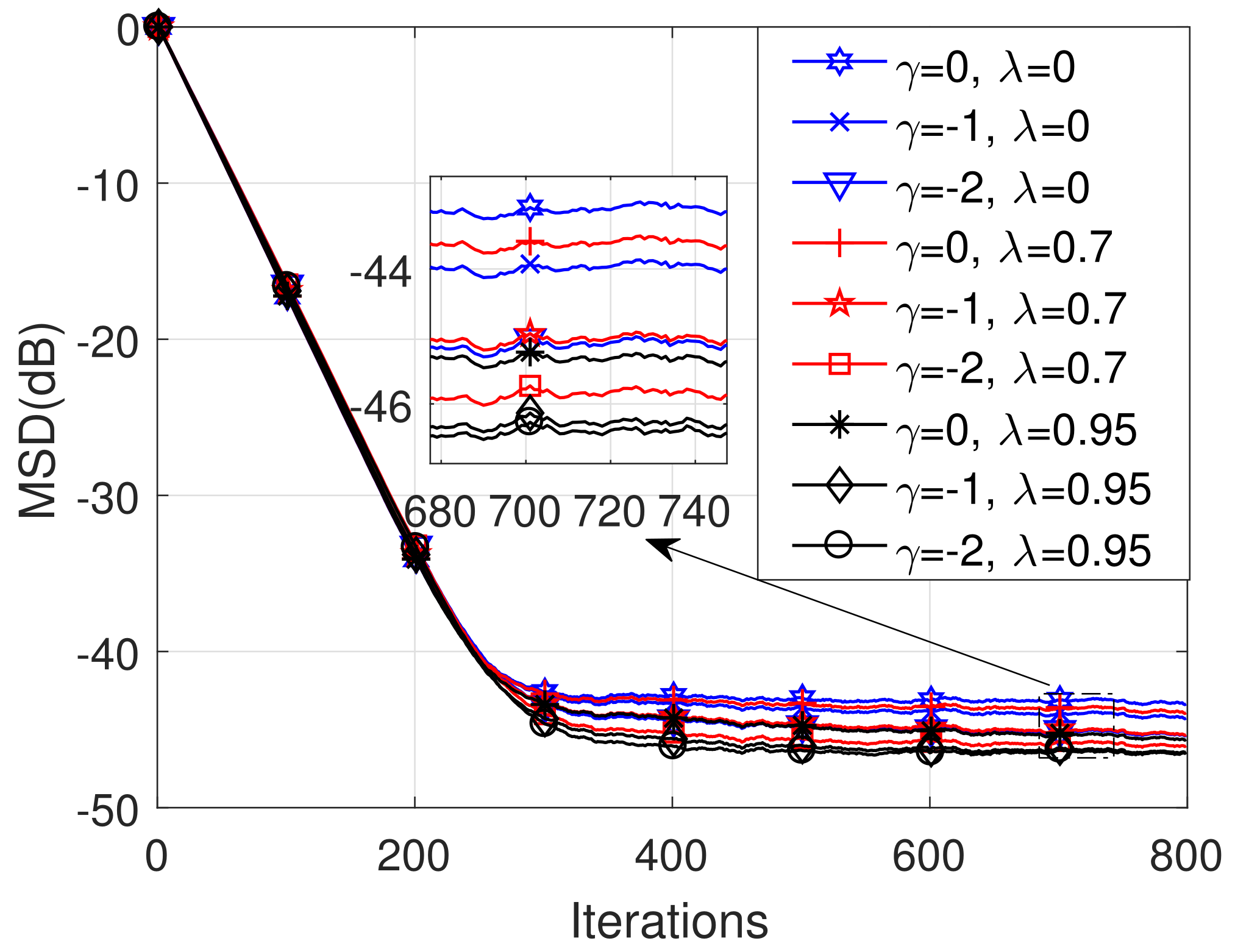
5. Simulation Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A. Mean Convergence Analysis
References
- Cattivelli, F.S.; Sayed, A.H. Diffusion LMS Strategies for Distributed Estimation. IEEE Trans. Signal Process. 2010, 58, 1035–1048. [Google Scholar] [CrossRef]
- Lee, H.S.; Kim, S.E.; Lee, J.W.; Song, W.J. A Variable Step-Size Diffusion LMS Algorithm for Distributed Estimation. IEEE Trans. Signal Process. 2015, 63, 1808–1820. [Google Scholar] [CrossRef]
- Ahn, D.C.; Lee, J.W.; Shin, S.J.; Song, W.J. A new robust variable weighting coefficients diffusion LMS algorithm. Signal Process. 2017, 131, 300–306. [Google Scholar] [CrossRef]
- Huang, W.; Li, L.; Li, Q. Diffusion Robust Variable Step-Size LMS Algorithm Over Distributed Networks. IEEE Access 2018, 6, 47511–47520. [Google Scholar] [CrossRef]
- Ashkezari-Toussi, S.; Sadoghi-Yazdi, H. Robust diffusion LMS over adaptive networks. Signal Process. 2019, 158, 201–209. [Google Scholar] [CrossRef]
- Nassif, R.; Vlaski, S.; Sayed, A.H. Adaptation and Learning Over Networks Under Subspace Constraints—Part I: Stability Analysis. IEEE Trans. Signal Process. 2020, 68, 1346–1360. [Google Scholar] [CrossRef] [Green Version]
- Tu, S.Y.; Sayed, A.H. Mobile adaptive networks with self-organization abilities. In Proceedings of the 2010 7th International Symposium on Wireless Communication Systems, York, UK, 19–22 September 2010; pp. 379–383. [Google Scholar] [CrossRef]
- Cattivelli, F.S.; Sayed, A.H. Modeling Bird Flight Formations Using Diffusion Adaptation. IEEE Trans. Signal Process. 2011, 59, 2038–2051. [Google Scholar] [CrossRef]
- Cattivelli, F.S.; Sayed, A.H. Distributed detection over adaptive networks using diffusion adaptation. IEEE Trans. Signal Process. 2011, 59, 1917–1932. [Google Scholar] [CrossRef]
- Chen, J.; Sayed, A.H. Diffusion Adaptation Strategies for Distributed Optimization and Learning Over Networks. IEEE Trans. Signal Process. 2012, 60, 4289–4305. [Google Scholar] [CrossRef] [Green Version]
- Tu, S.; Sayed, A.H. Mobile Adaptive Networks. IEEE J. Sel. Top. Signal Process. 2011, 5, 649–664. [Google Scholar] [CrossRef]
- Takahashi, N.; Yamada, I.; Sayed, A.H. Diffusion Least-Mean Squares with adaptive combiners: Formulation and performance analysis. IEEE Trans. Signal Process. 2010, 58, 4795–4810. [Google Scholar] [CrossRef]
- Tu, S.; Sayed, A.H. Optimal combination rules for adaptation and learning over networks. In Proceedings of the 2011 4th IEEE International Workshop Computational Advances in Multi-Sensor Adaptive Processing, San Juan, Puerto Rico, 13–16 December 2011; pp. 317–320. [Google Scholar] [CrossRef]
- Yu, C.; Sayed, A.H. A strategy for adjusting combination weights over adaptive networks. In Proceedings of the 2013 IEEE International Conference Acoustic, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 4579–4583. [Google Scholar] [CrossRef]
- Fernandez-Bes, J.; Arenas-García, J.; Sayed, A.H. Adjustment of combination weights over adaptive diffusion networks. In Proceedings of the 2014 IEEE International Conference Acoustic, Speech and Signal Processing, Florence, Italy, 4–9 May 2014; pp. 6409–6413. [Google Scholar] [CrossRef]
- Abdolee, R.; Vakilian, V. An Iterative Scheme for Computing Combination Weights in Diffusion Wireless Networks. IEEE Wireless Commun. Lett. 2017, 6, 510–513. [Google Scholar] [CrossRef]
- Fernandez-Bes, J.; Azpicueta-Ruiz, L.A.; Arenas-García, J. Distributed estimation in diffusion networks using affine least-squares combiners. Dig. Signal Process. 2015, 36, 1–14. [Google Scholar] [CrossRef]
- Fernandez-Bes, J.; Arenas-García, J.; Silva, M.T.M. Adaptive Diffusion Schemes for Heterogeneous Networks. IEEE Trans. Signal Process. 2017, 65, 5661–5674. [Google Scholar] [CrossRef] [Green Version]
- Sayed, A.H. Adaptive Networks. Proc. IEEE 2014, 102, 460–497. [Google Scholar] [CrossRef]
- Zhao, X.; Sayed, A.H. Asynchronous Adaptation and Learning Over Networks-Part I: Modeling and Stability Analysis. IEEE Trans. Signal Process. 2015, 63, 811–826. [Google Scholar] [CrossRef]
- Chen, J.; Richard, C.; Bermudez, J.C.M. Nonnegative Least-Mean-Square Algorithm. IEEE Trans. Signal Process. 2011, 59, 5225–5235. [Google Scholar] [CrossRef] [Green Version]
- Behrens, R.T.; Scharf, L.L. Signal processing applications of oblique projection operators. IEEE Trans. Signal Process. 1994, 42, 1413–1424. [Google Scholar] [CrossRef] [Green Version]
- Kailath, T.; Sayed, A.H.; Hassibi, B. Linear Estimation; Prentice-Hall: Englewood Cliffs, NJ, USA, 2000. [Google Scholar]
- Sayed, A.H. Fundamentals of Adaptive Filtering; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Marshall, A.W.; Olkin, I.; Arnold, B.C. Matrix Theory. In Inequalities: Theory of Majorization and Its Applications; Springer: New York, NY, USA, 2011; Chapter 9; pp. 338–347. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Combiners | Uniform | Classic AC | |||
|---|---|---|---|---|---|
| Noise | |||||
| −49.0 | −50.2 | −51.2 | −53.0 | ||
| −46.0 | −48.0 | −49.1 | −50.0 | ||
| −44.3 | −46.6 | −47.7 | −48.3 | ||
| −43.3 | −45.9 | −46.9 | −47.1 | ||
| −42.1 | −45.1 | −46.1 | −46.1 | ||
| −41.2 | −44.3 | −45.2 | −45.3 | ||
| −40.6 | −43.7 | −44.4 | −44.4 | ||
| −40.2 | −43.5 | −44.1 | −44.0 | ||
| −39.6 | −42.9 | −43.5 | −43.3 | ||
| −39.2 | −42.7 | −43.3 | −43.2 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, C.; Li, Q.; Ying, D. An Effective Adaptive Combination Strategy for Distributed Learning Network. Appl. Sci. 2021, 11, 5723. https://doi.org/10.3390/app11125723
Xu C, Li Q, Ying D. An Effective Adaptive Combination Strategy for Distributed Learning Network. Applied Sciences. 2021; 11(12):5723. https://doi.org/10.3390/app11125723
Chicago/Turabian StyleXu, Chundong, Qinglin Li, and Dongwen Ying. 2021. "An Effective Adaptive Combination Strategy for Distributed Learning Network" Applied Sciences 11, no. 12: 5723. https://doi.org/10.3390/app11125723