
Human–Robot Collaborative Assembly Based on Eye-Hand and a Finite State Machine in a Virtual Environment


Abstract
:1. Introduction
- (1)
- The robot and scene are built in a Unity environment, and the robot joints are controlled by the kinematics model in Simulink software.
- (2)
- Hand data is collected by a Leap-motion sensor. We divide hand gestures into nine categories, use the joint angles of the fingers as features, and train them using a neural network to achieve good recognition results.
- (3)
- In this virtual desktop interactive scene, a PRM is used to plan the robot’s trajectory to avoid collisions.
- (4)
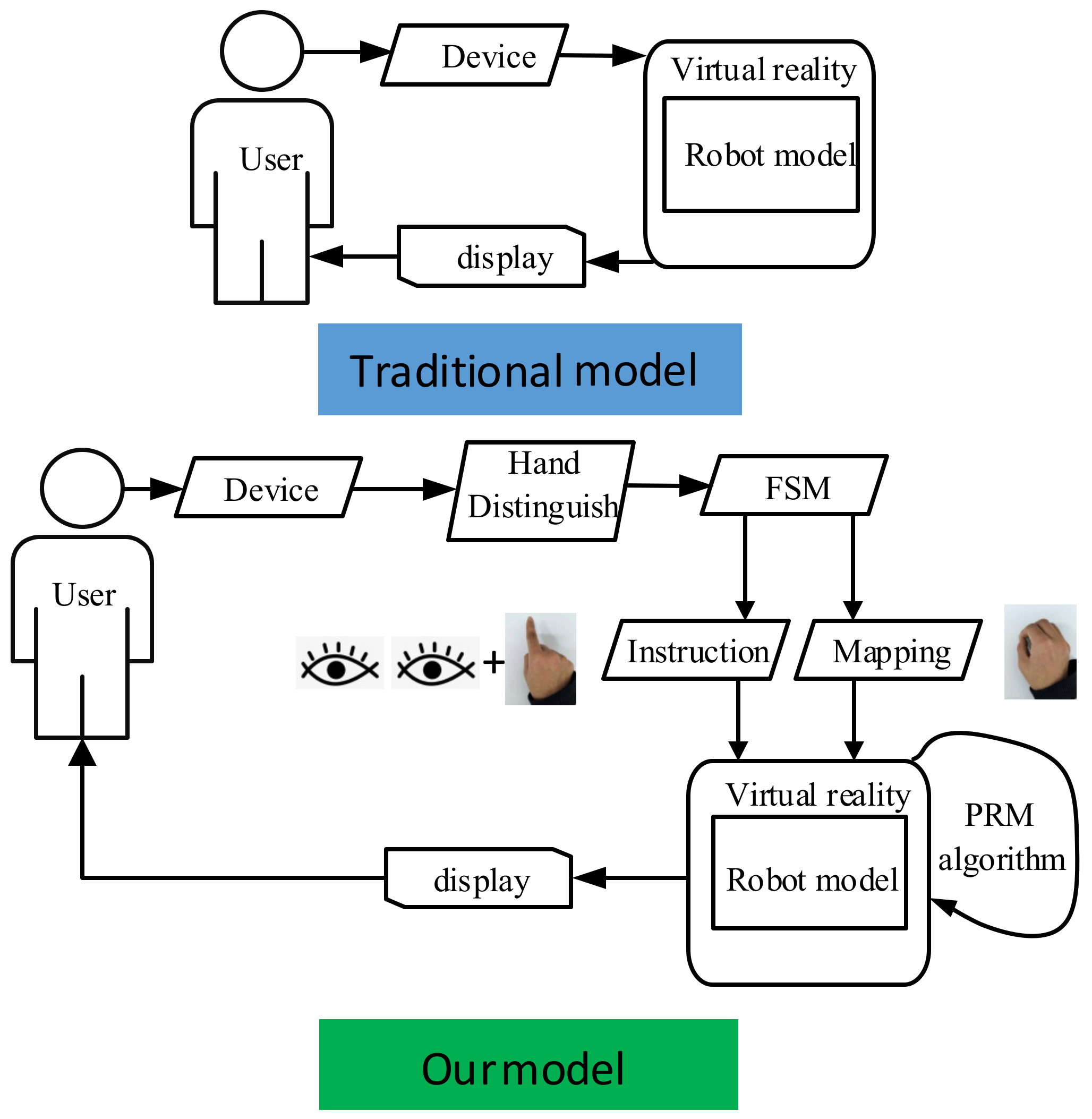
- A model based on eye–hand cooperation with an FSM to change the robot’s state is proposed. Based on the classification of previous gestures, the interaction mode is roughly divided into “instruction” and “mapping” modes. The robot deals with the fixed part based on PRM, while the human deals with the flexible part.
2. Experimental Setup
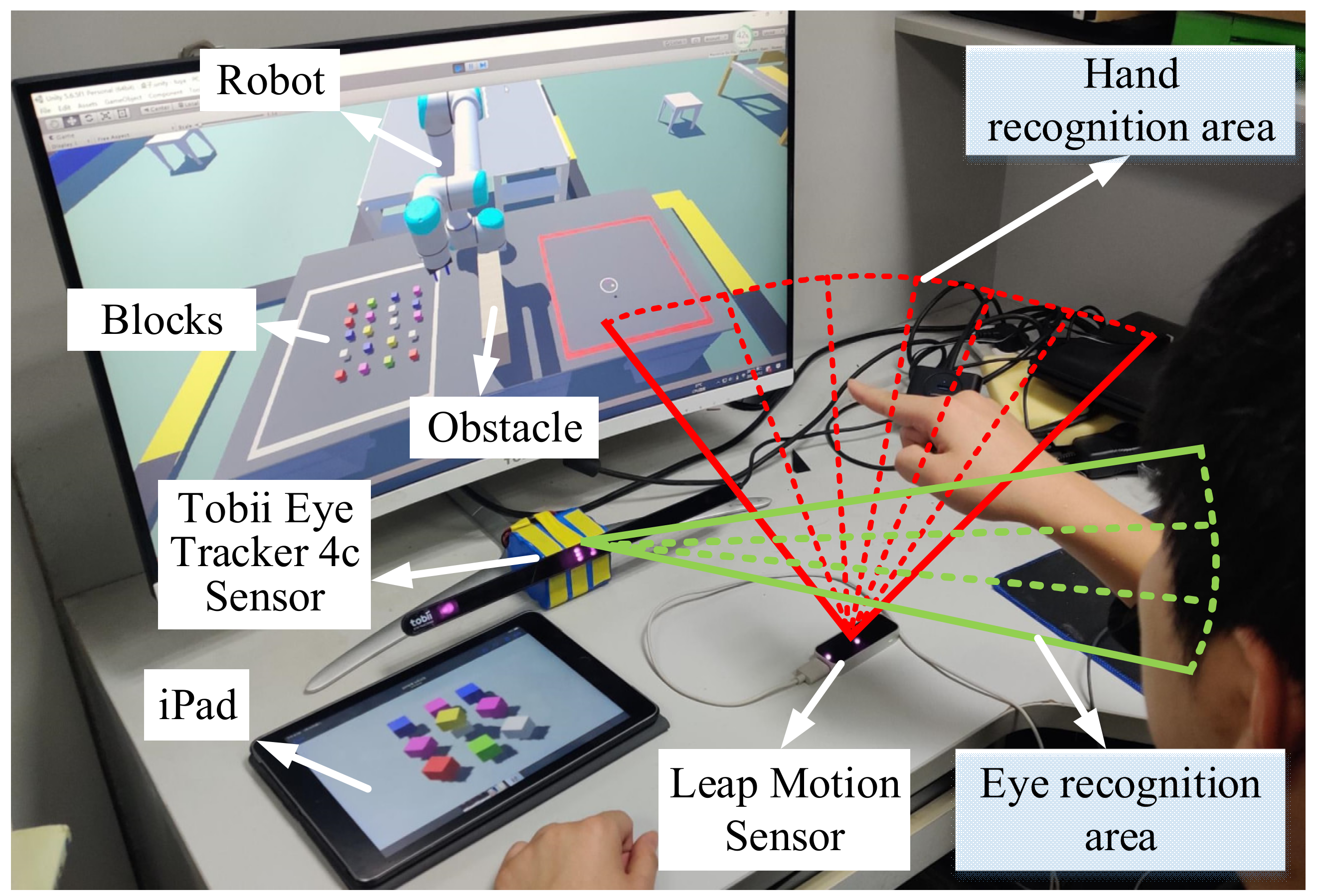
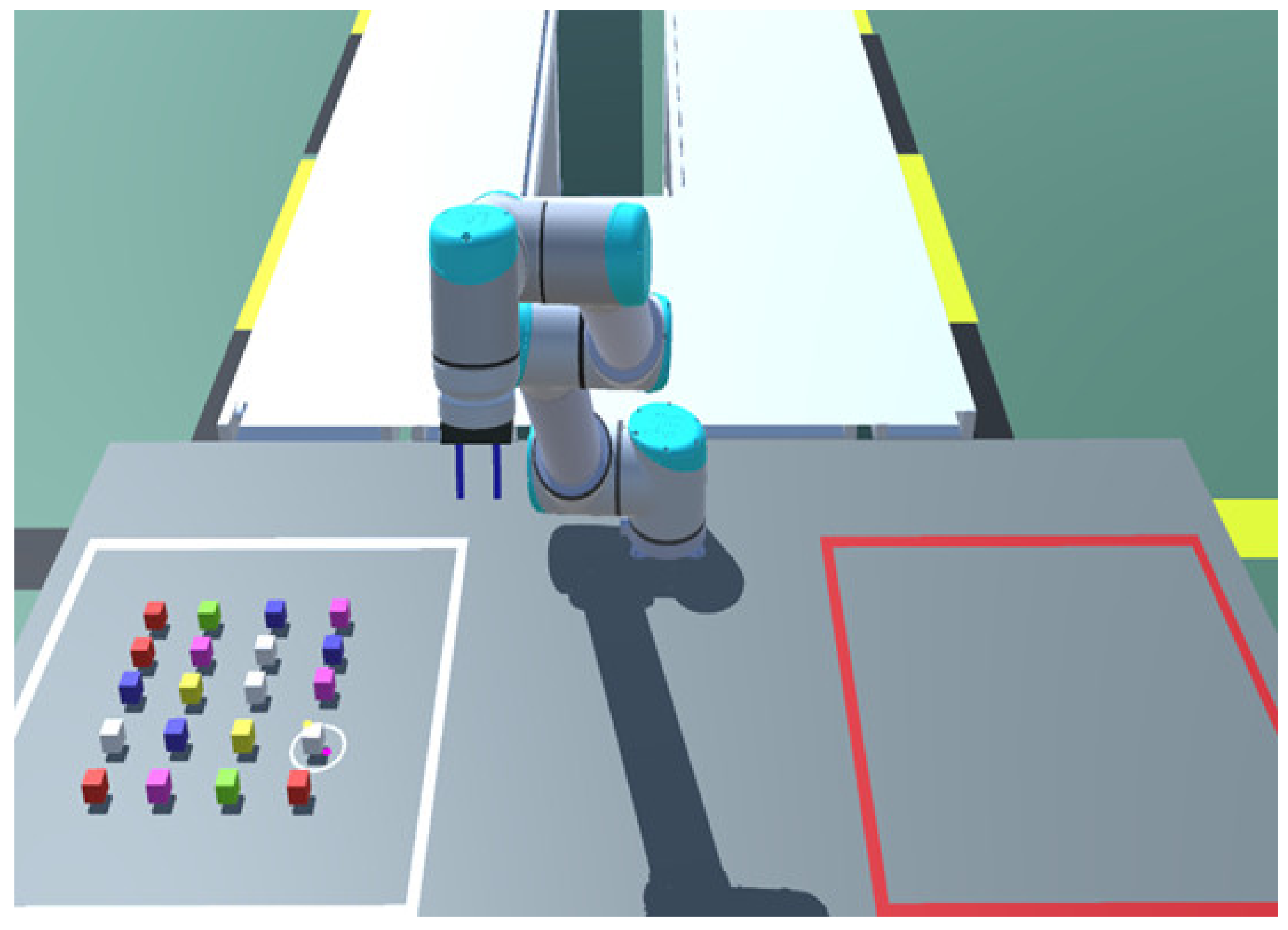
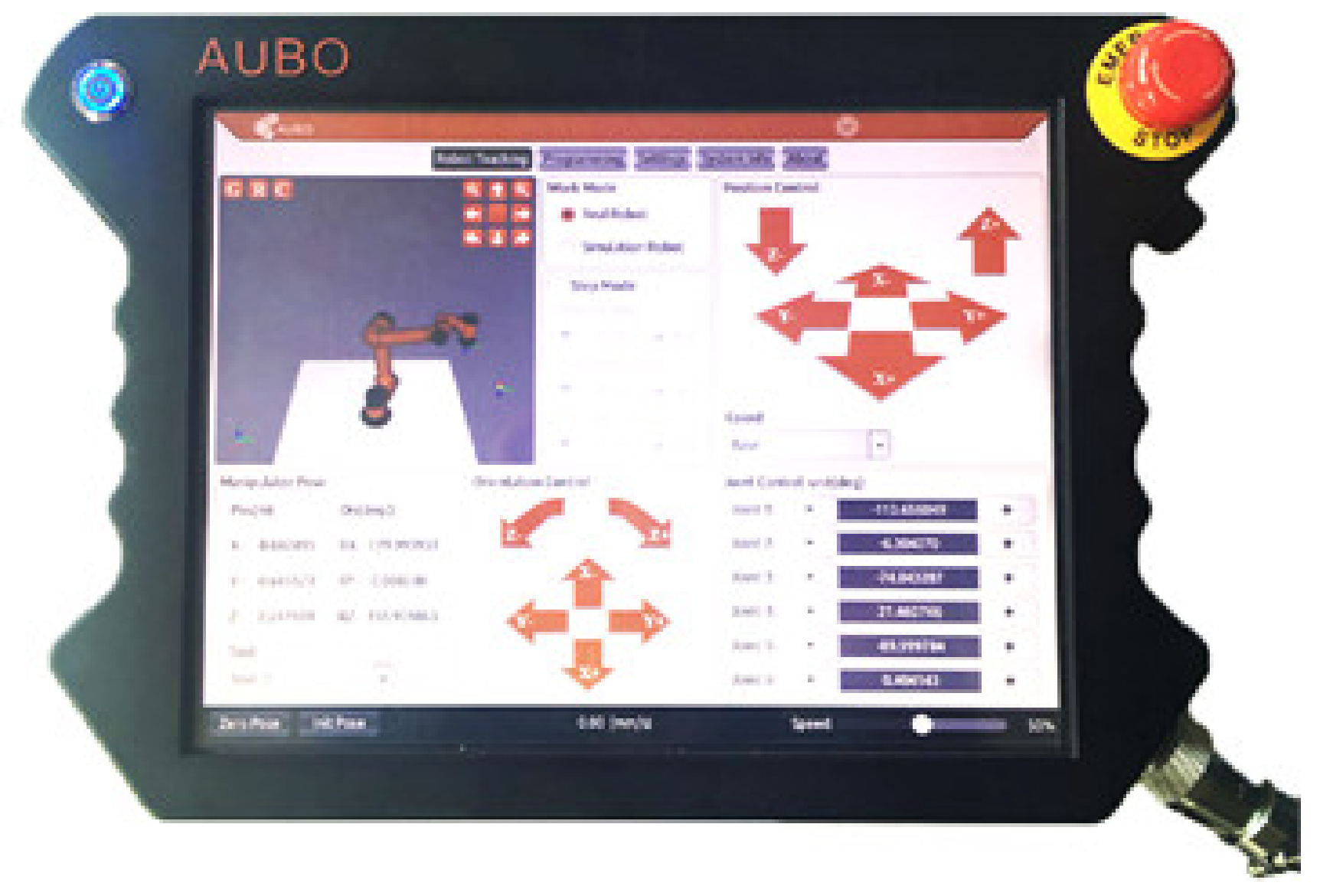
2.1. Components of the Test
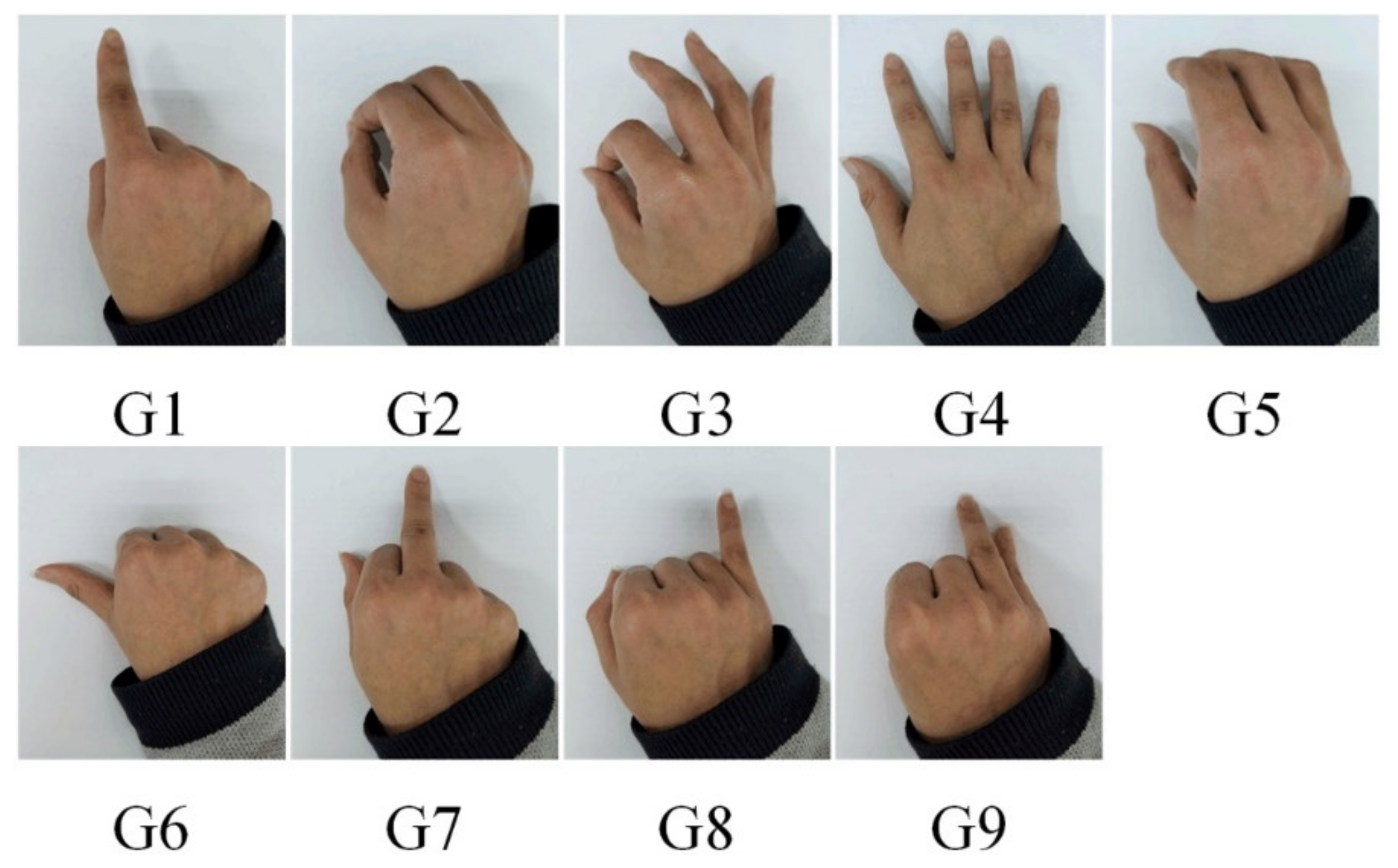
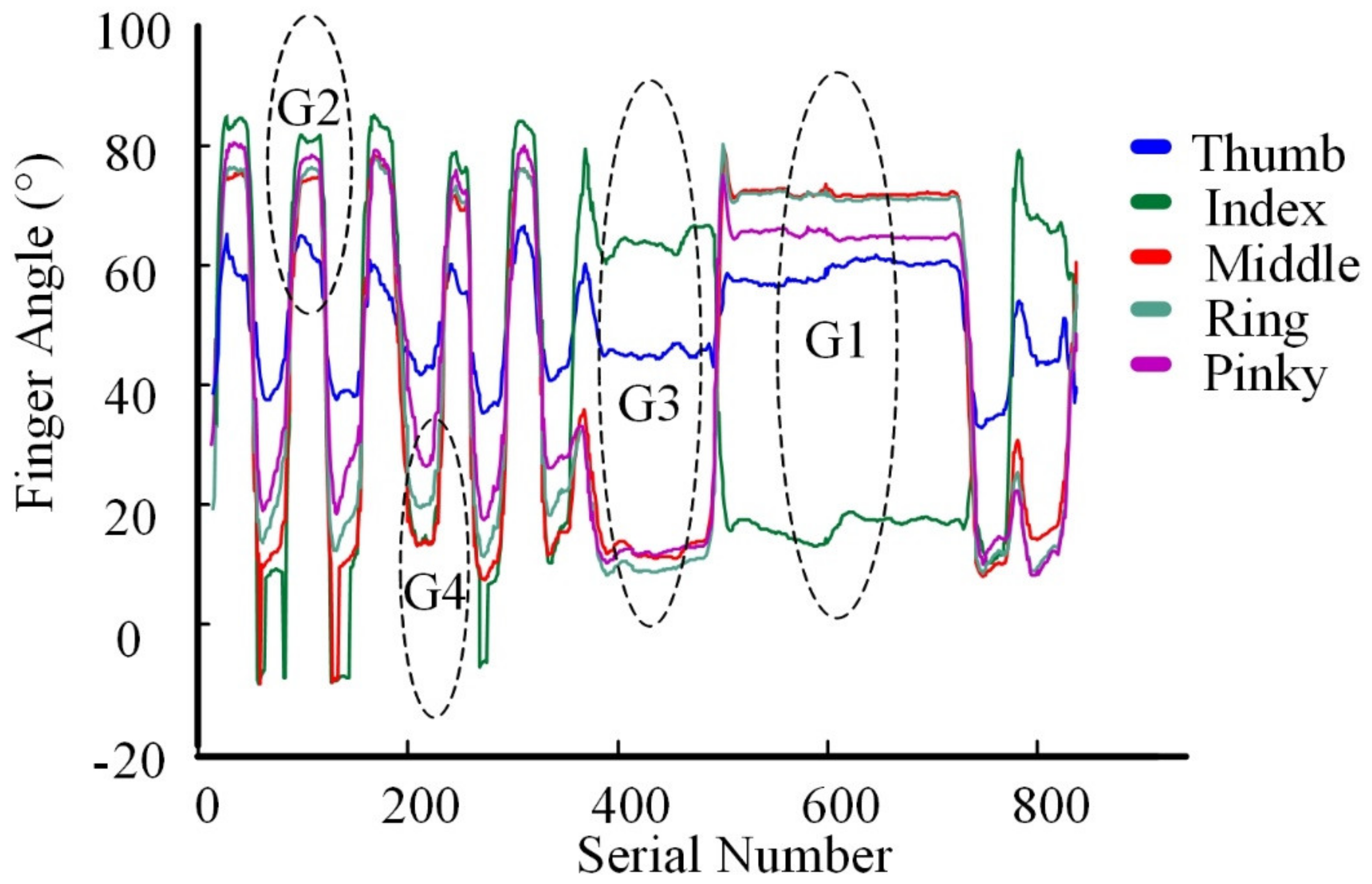
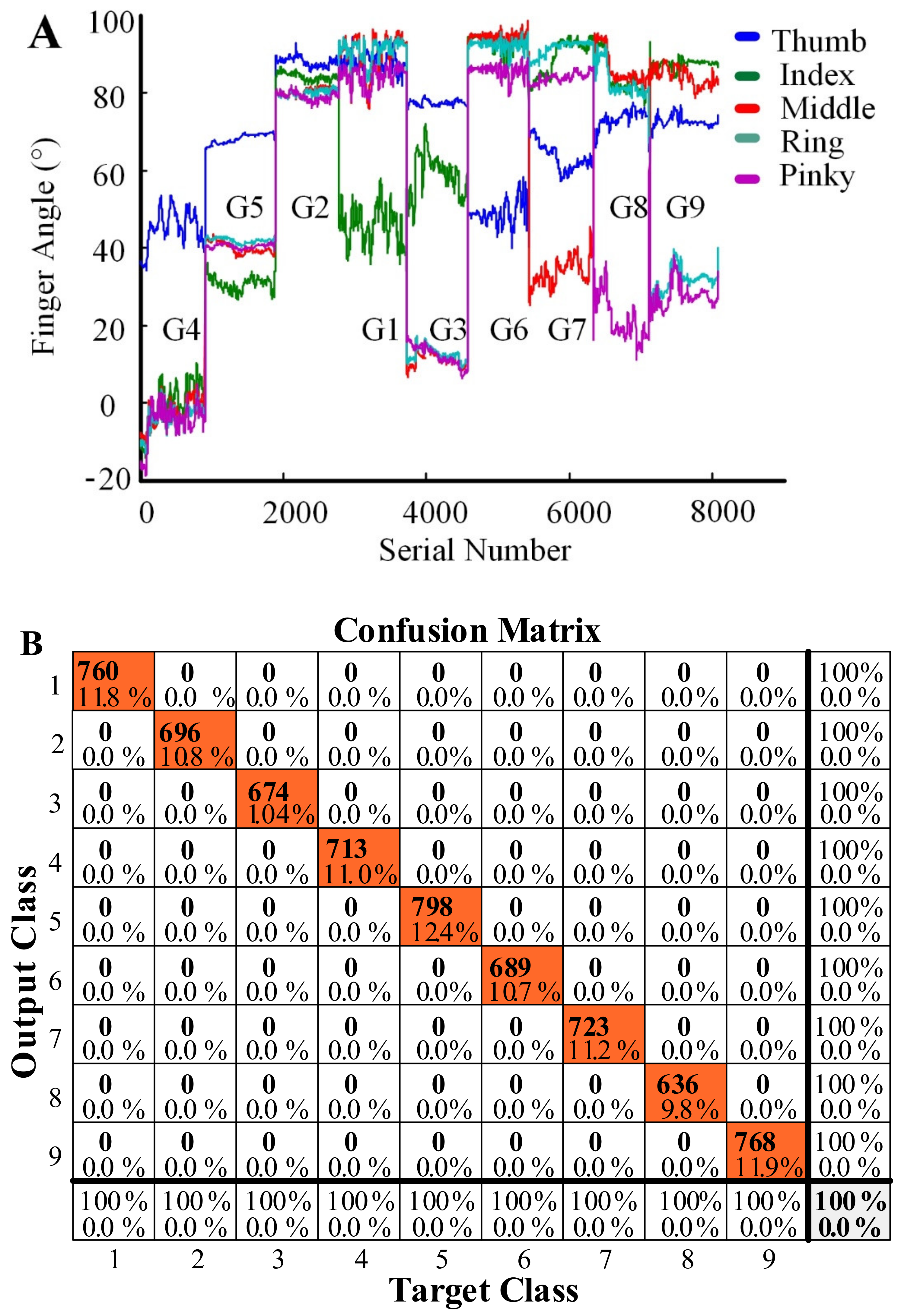
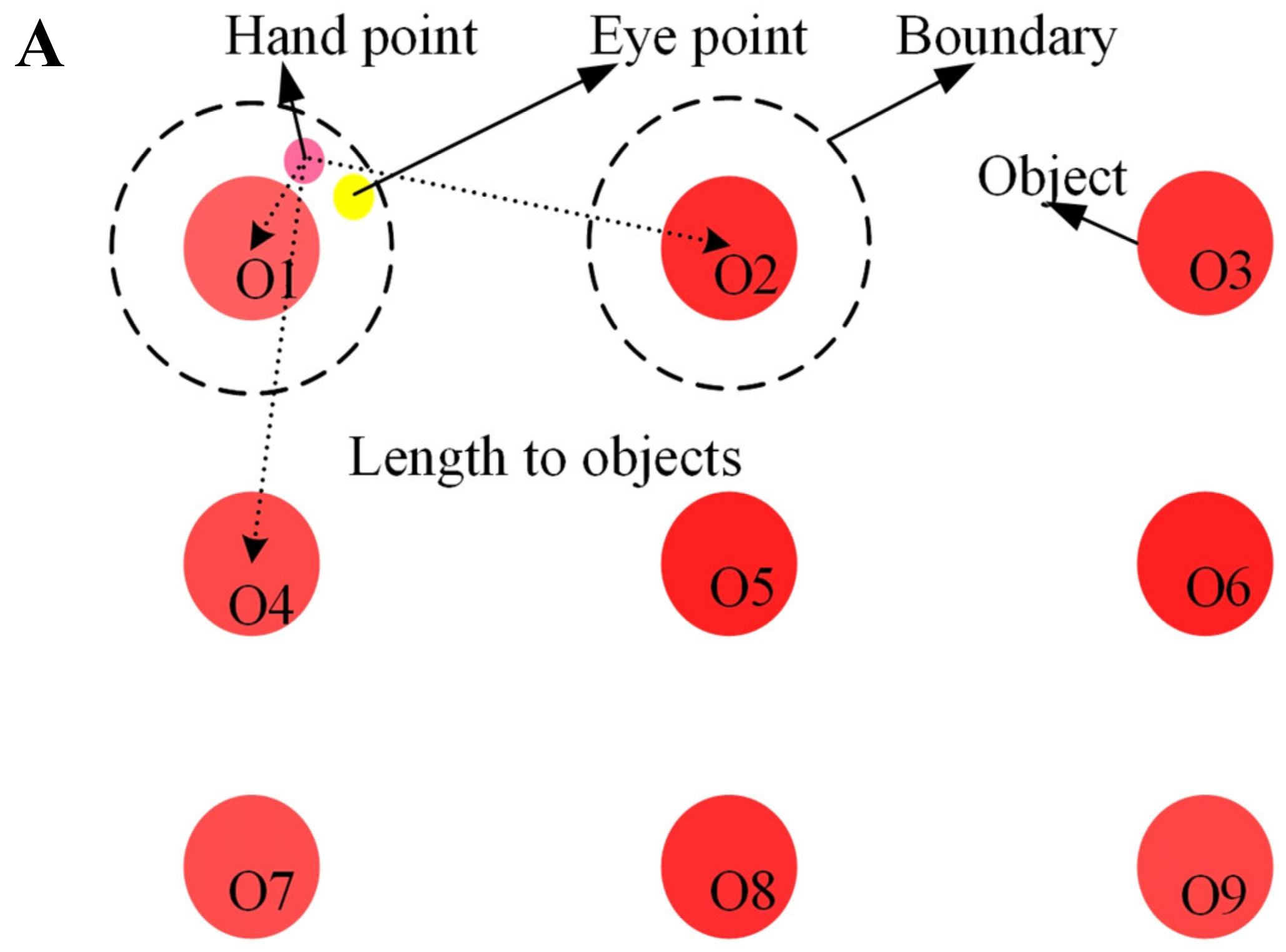
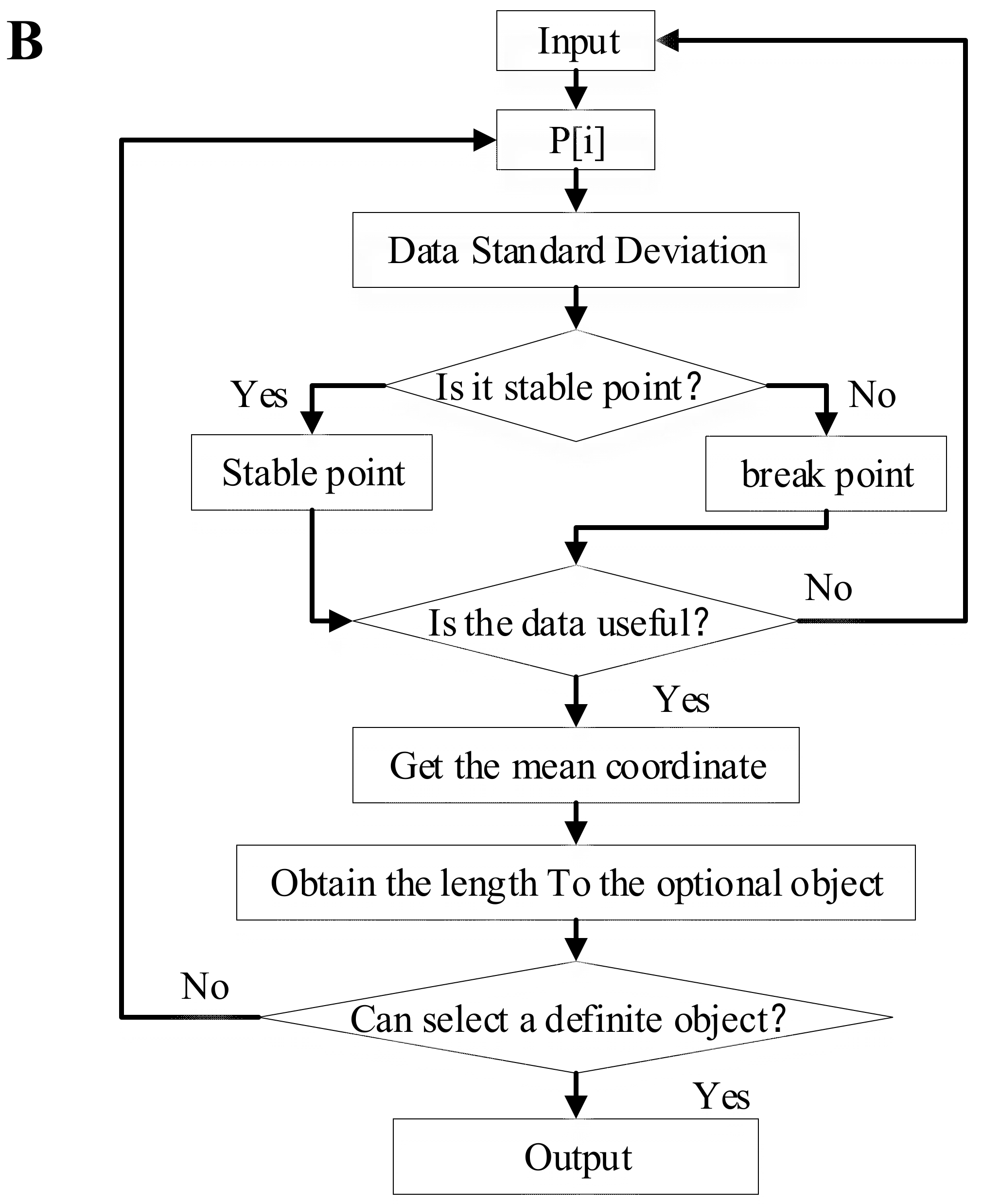
2.2. Gesture Recognition and Object Selection
2.3. Probabilistic Roadmap Planner
| Algorithm 1. The probabilistic roadmap planner (PRM). |
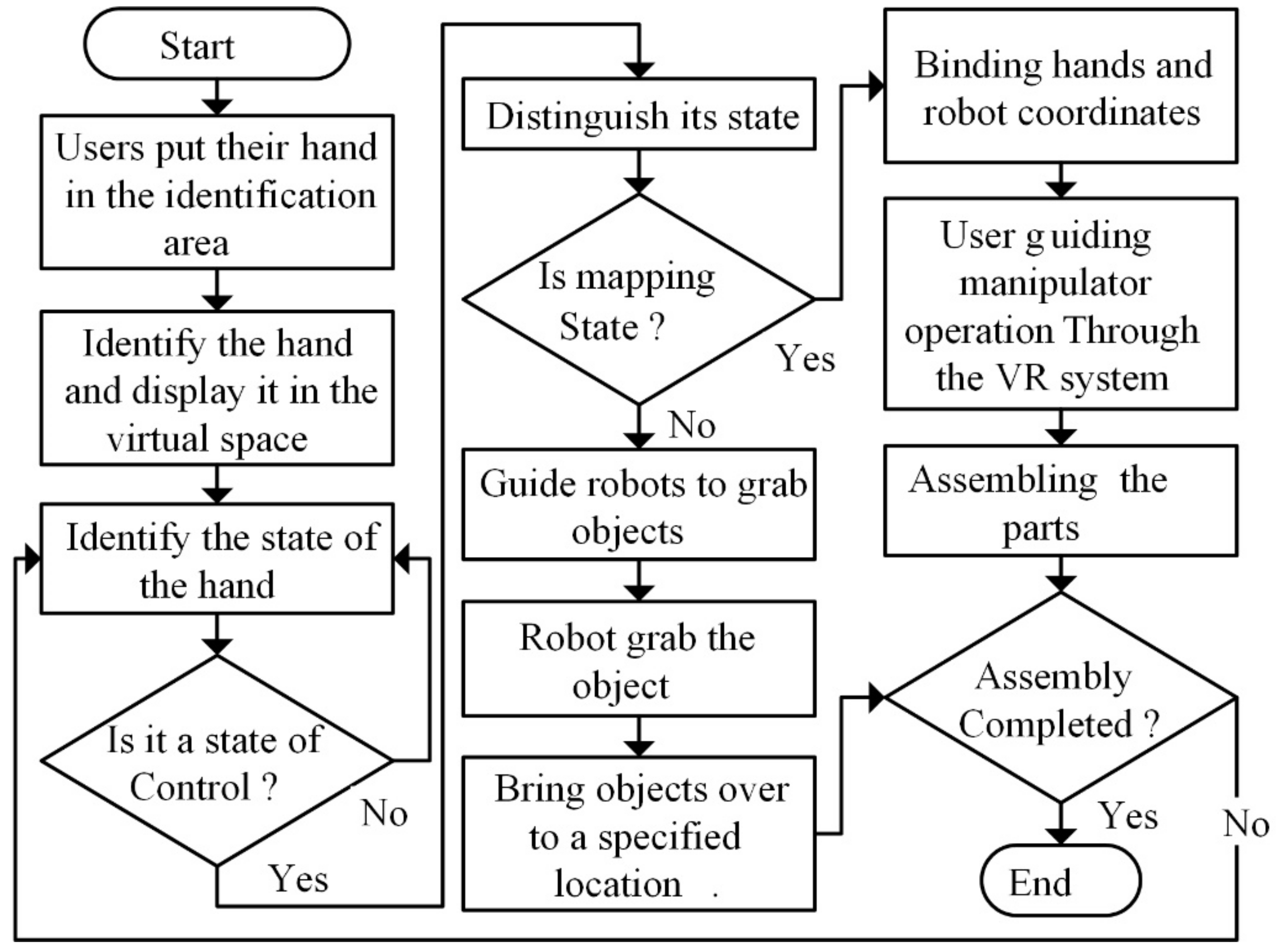
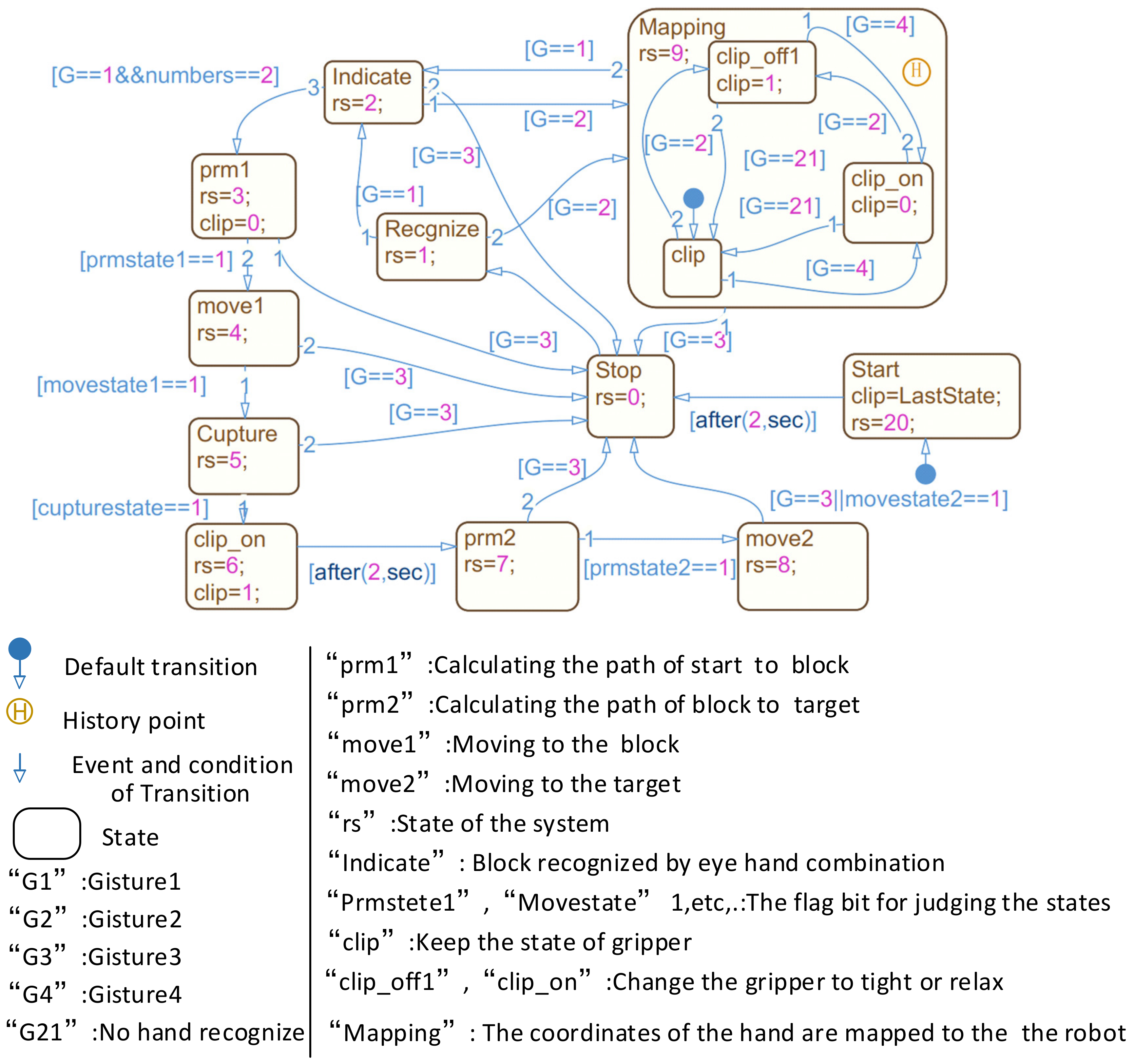
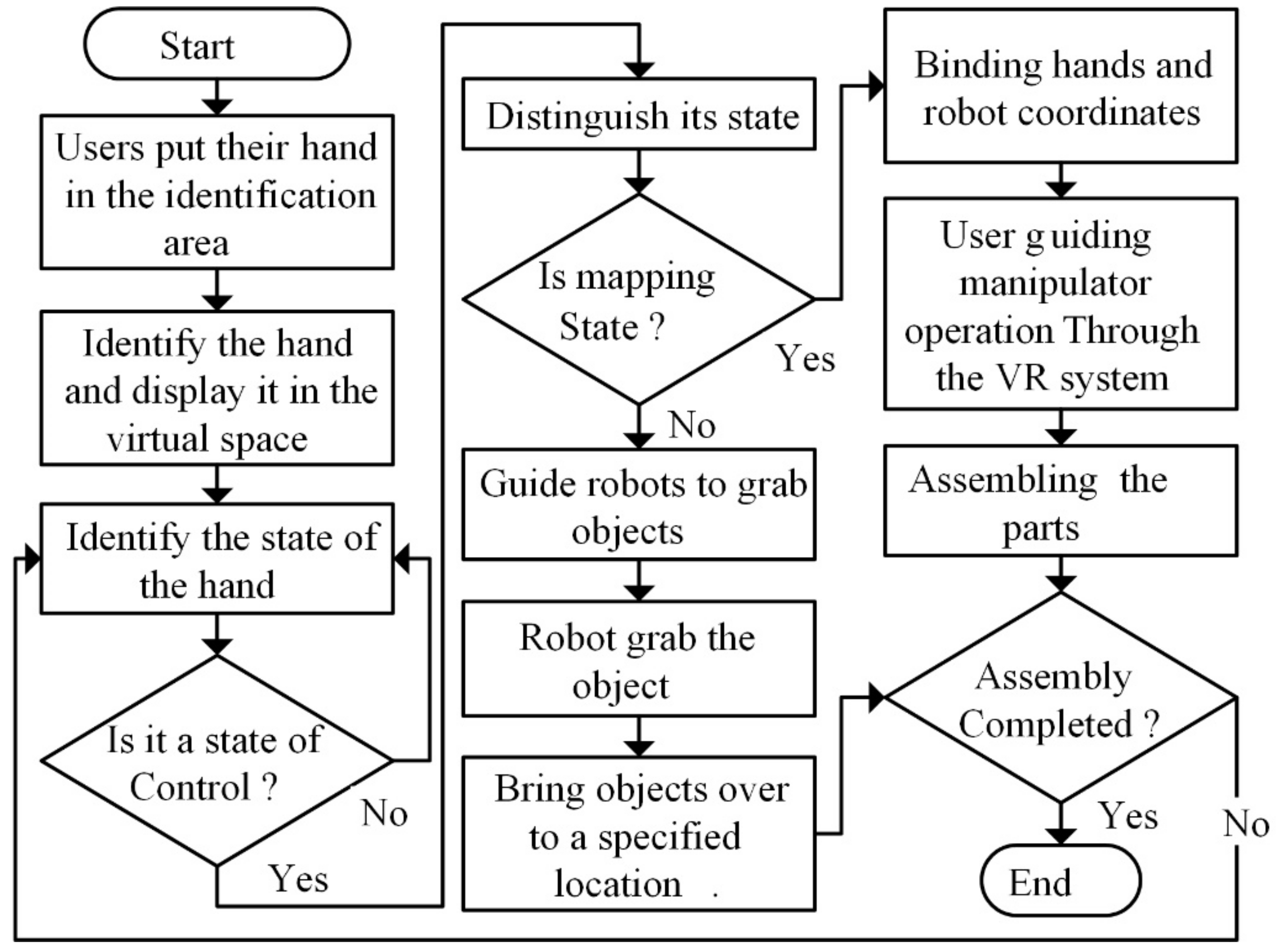
2.4. Finite State Machine for Human-Robot Collaboration
3. Measurement Methods
3.1. Experimental Scene
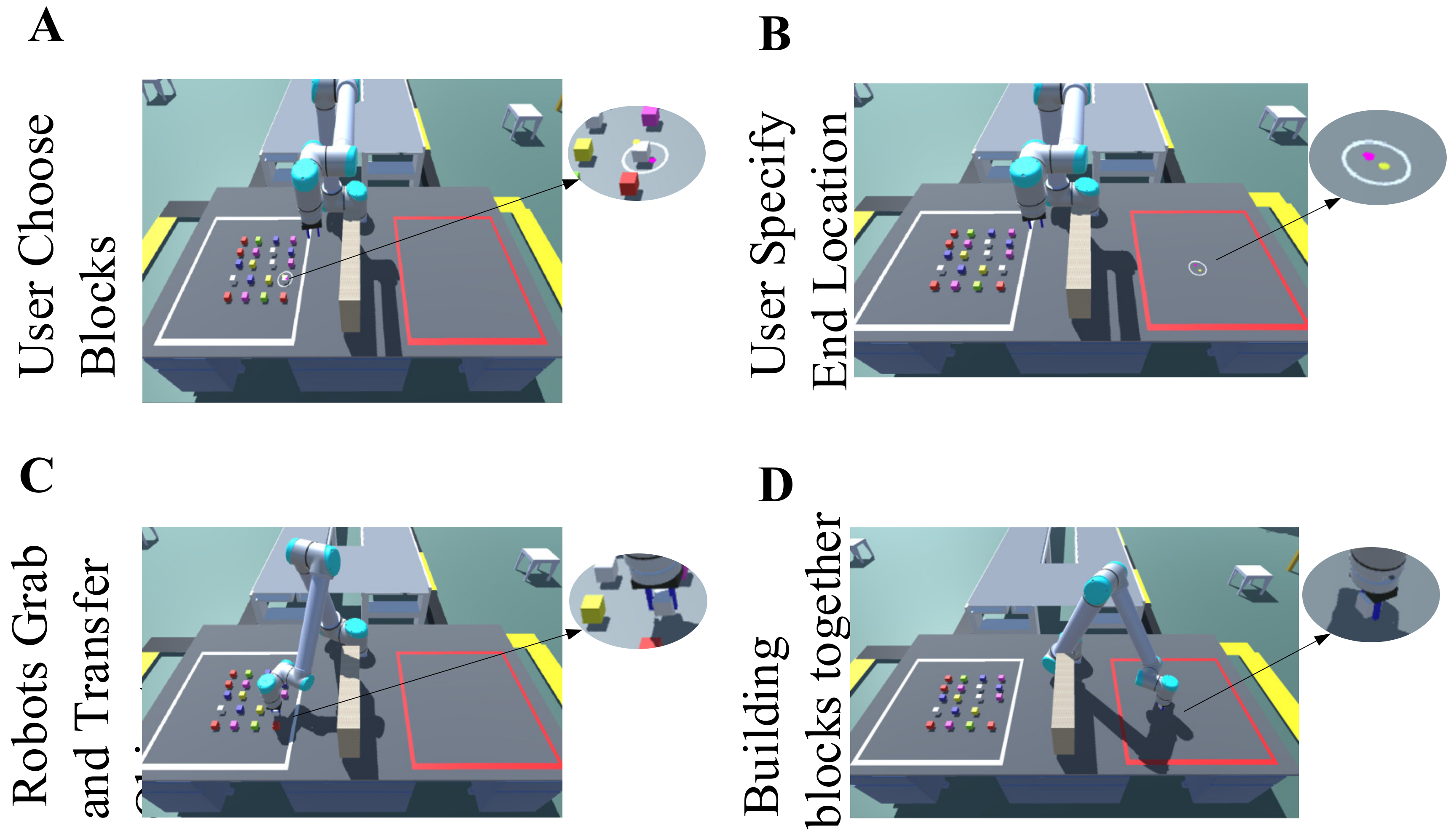
3.2. Experimental Methods
4. Experimental Results and Discussion
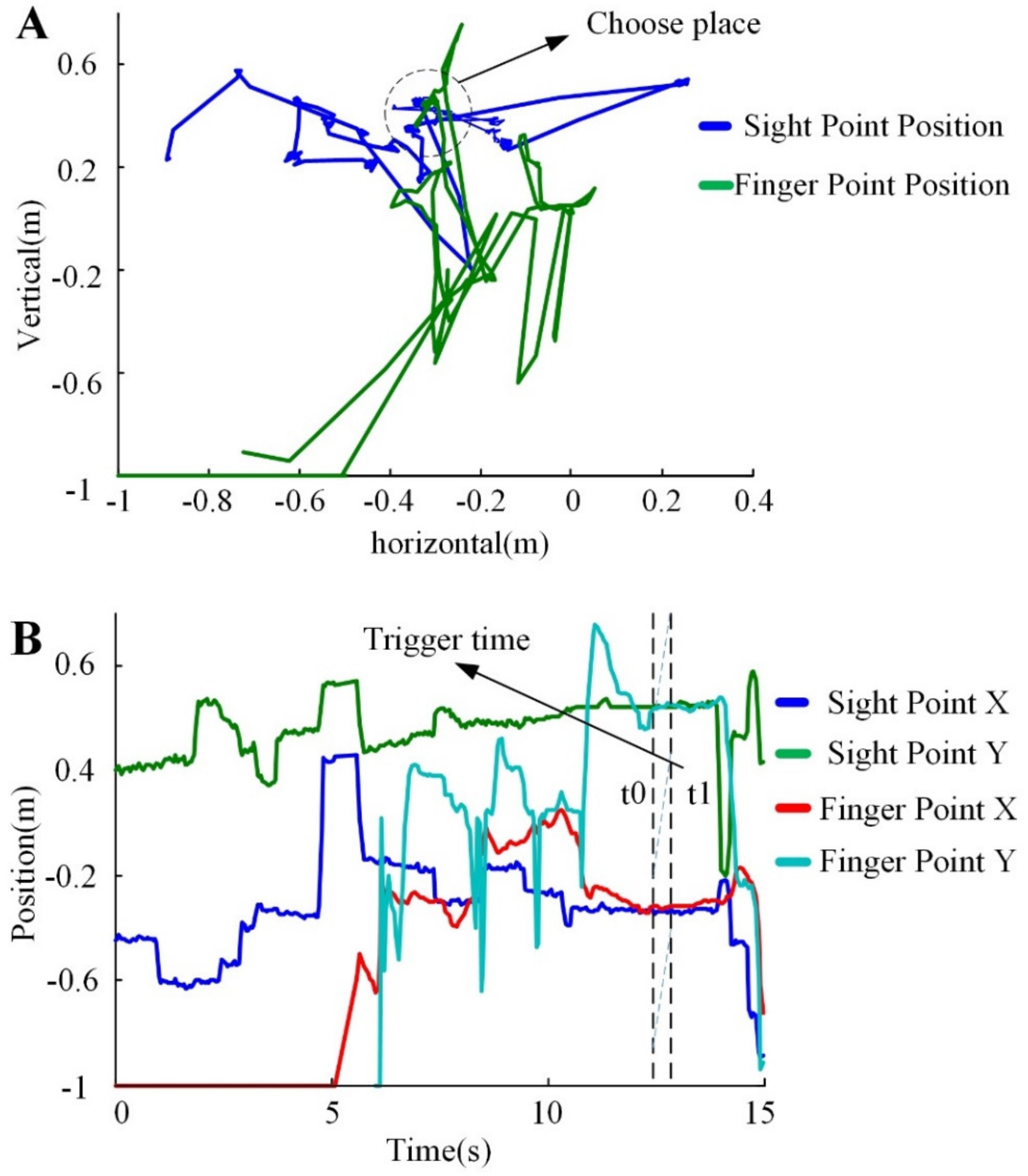
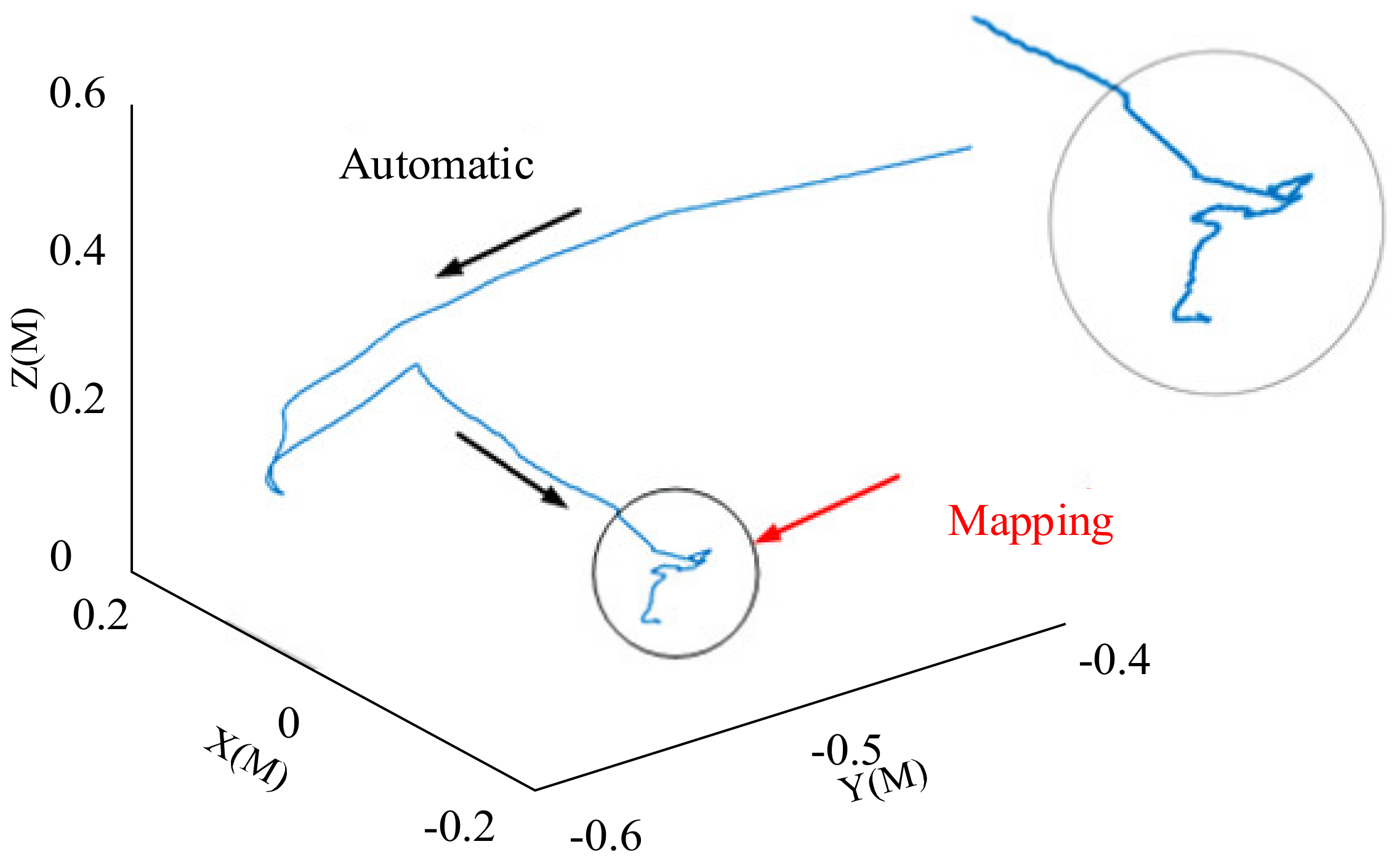
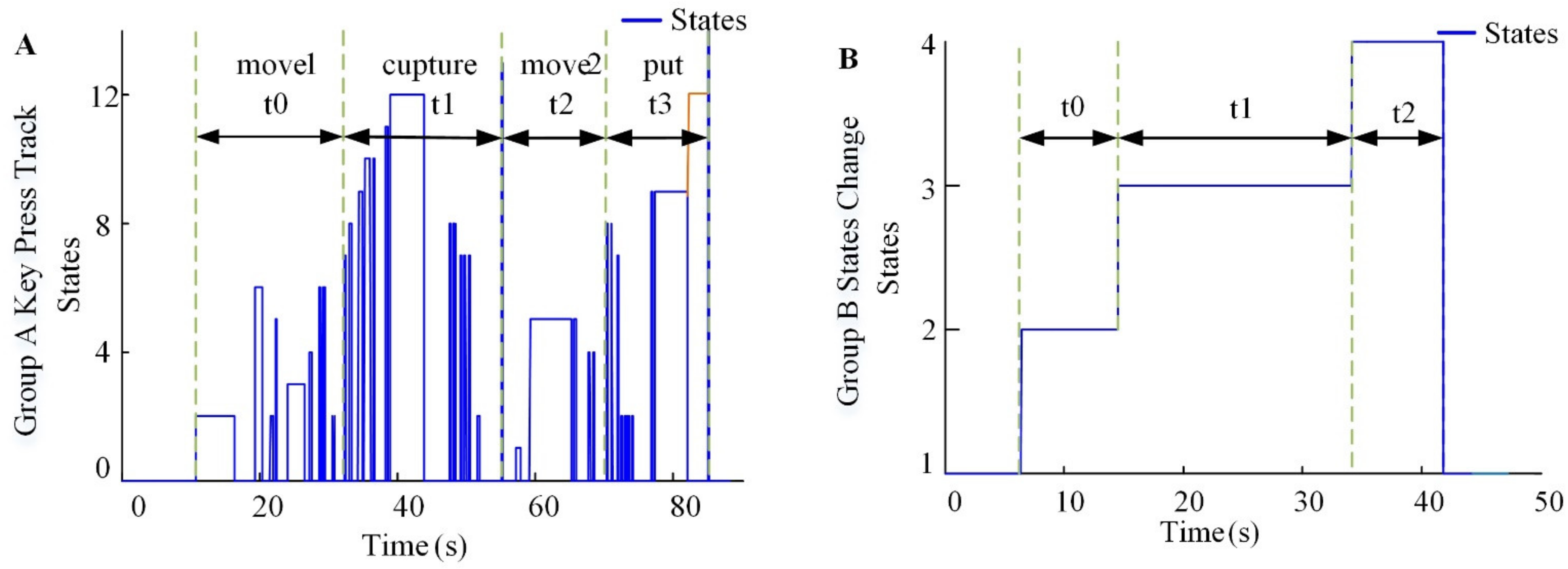
4.1. Experimental State Change
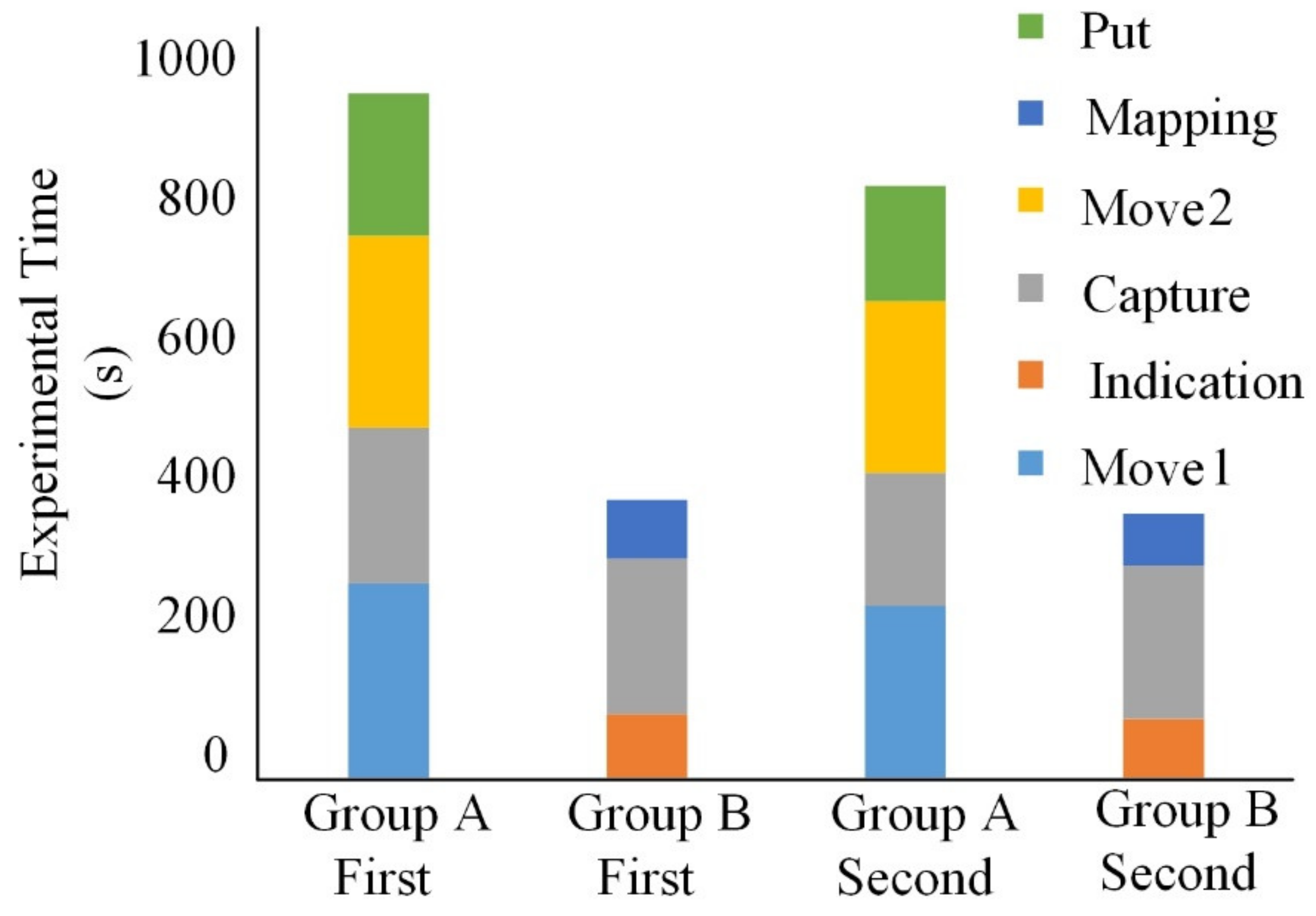
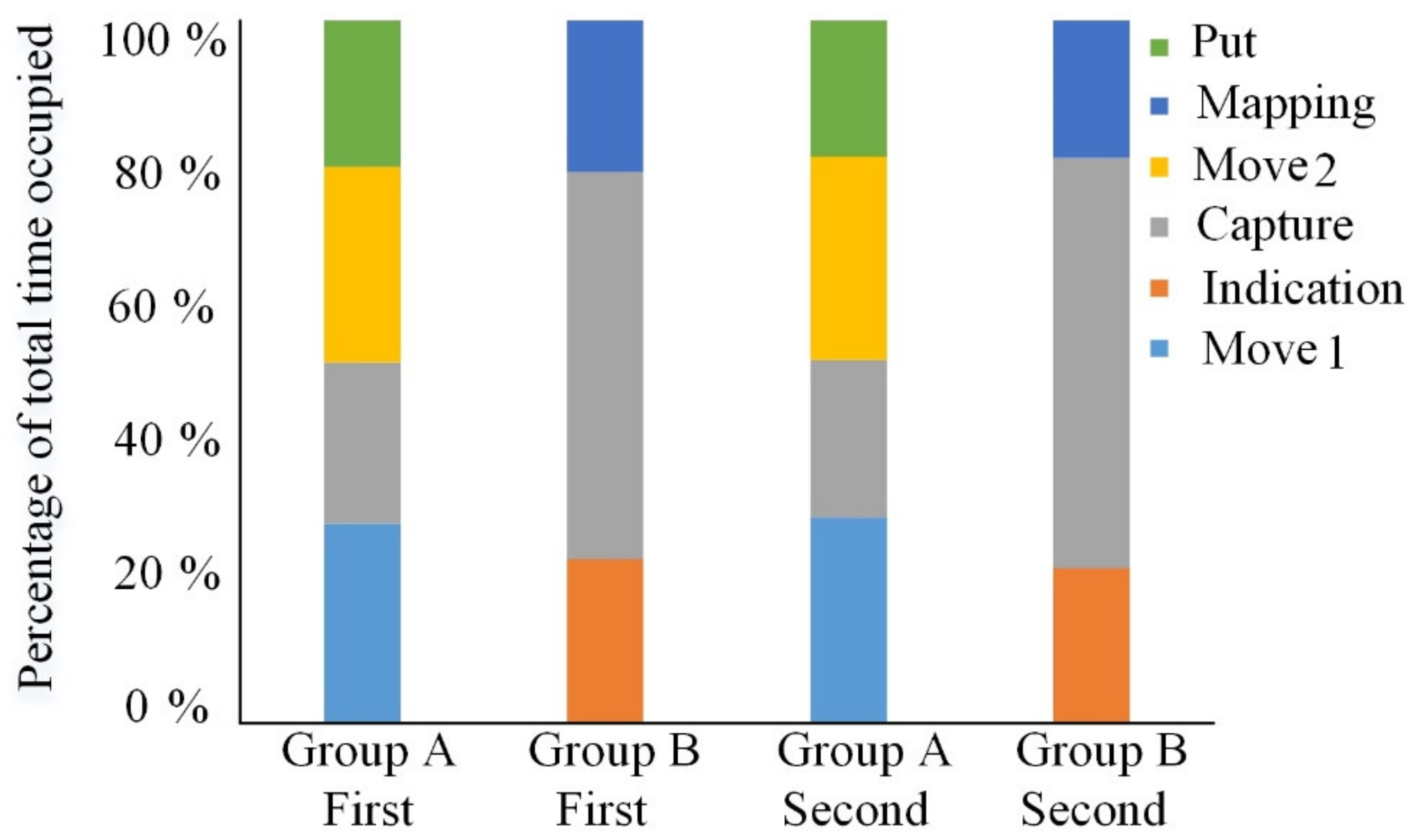
4.2. Experimental Time Consumption
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hentout, A.; Aouache, M.; Maoudj, A.; Akli, I. Human–Robot interaction in industrial collaborative robotics: A literature review of the decade 2008–2017. Adv. Robot. 2019, 33, 764–799. [Google Scholar] [CrossRef]
- Rane, A.; Sudhakar, D.; Sunnapwar, V.K.; Rane, S. Improving the performance of assembly line: Review with case study. In Proceedings of the 2015 International Conference on Nascent Technologies in the Engineering Field (ICNTE), Navi Mumbai, India, 9–10 January 2015; IEEE: New York, NY, USA, 2015; pp. 1–14. [Google Scholar]
- Aziz, R.A.; Rani, M.R.A.; Rohani, J.M.; Adeyemi, A.J.; Omar, N. Relationship between working postures and MSD in different body regions among electronics assembly workers in Malaysia. In Proceedings of the 2013 IEEE International Conference on Industrial Engineering and Engineering Management, Bangkok, Thailand, 10–13 December 2013; IEEE: New York, NY, USA, 2013; pp. 512–516. [Google Scholar]
- Patel, R.; Hedelind, M.; Lozan-Villegas, P. Enabling robots in small-part assembly lines: The “ROSETTA approach”—An industrial perspective. In Proceedings of the German Conference; VDE: Munich, Munich, Germany, 21–22 May 2012; VDE: Frankfurt am Main, Germany, 2012. [Google Scholar]
- Fryman, J.; Matthias, B. Safety of industrial robots: From conventional to collaborative applications. In Proceedings of the ROBOTIK 2012, 7th German Conference on Robotics. Munich, Germany, 21–22 May 2012; VDE: Frankfurt am Main, Germany, 2012; pp. 1–5. [Google Scholar]
- Vicentini, F.; Pedrocchi, N.; Beschi, M.; Giussani, M.; Iannacci, N.; Magnoni, P.; Pellegrinelli, S.; Roveda, L.; Villagrossi, E.; Askarpour, M.; et al. PIROS: Cooperative, Safe and Reconfigurable Robotic Companion for CNC Pallets Load/Unload Stations. In Bringing Innovative Robotic Technologies from Research Labs to Industrial End-Users; Springer: Berlin/Heidelberg, Germany, 2020; pp. 57–96. [Google Scholar]
- Petruck, H.; Faber, M.; Giese, H.; Geibel, M.; Mostert, S.; Usai, M.; Mertens, A.; Brandl, C. Human-Robot Collaboration in Manual Assembly—A Collaborative Workplace. In Congress of the International Ergonomics Association; Springer: Berlin/Heidelberg, Germany, 2018; pp. 21–28. [Google Scholar]
- Bauer, A.; Wollherr, D.; Buss, M. Human-Robot Collaboration: A Survey. Int. J. Hum. Robot. 2008, 5, 47–66. [Google Scholar] [CrossRef]
- Tsarouchi, P.; Makris, S.; Chryssolouris, G. Human–robot interaction review and challenges on task planning and programming. Int. J. Comput. Integr. Manuf. 2016, 29, 916–931. [Google Scholar] [CrossRef]
- Roveda, L.; Magni, M.; Cantoni, M.; Piga, D.; Bucca, G. Human–robot collaboration in sensorless assembly task learning enhanced by uncertainties adaptation via Bayesian Optimization. Robot. Auton. Syst. 2021, 136, 103711. [Google Scholar] [CrossRef]
- Akkaladevi, S.C.; Plasch, M.; Chitturi, N.C.; Hofmann, M.; Pichler, A. Programming by Interactive Demonstration for a Human Robot Collaborative Assembly. Procedia Manuf. 2020, 51, 148–155. [Google Scholar] [CrossRef]
- Lasota, P.A.; Shah, J.A. Analyzing the Effects of Human-Aware Motion Planning on Close-Proximity Human–Robot Collaboration. Hum. Factors J. Hum. Factors Ergon. Soc. 2015, 57, 21–33. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Magrini, E.; Ferraguti, F.; Ronga, A.J.; Pini, F.; De Luca, A.; Leali, F. Human-robot coexistence and interaction in open industrial cells. Robot. Comput. Manuf. 2020, 61. [Google Scholar] [CrossRef]
- Seth, A.; Vance, J.M.; Oliver, J.H. Virtual reality for assembly methods prototyping: A review. Virtual Real. 2010, 15, 5–20. [Google Scholar] [CrossRef] [Green Version]
- Demirdjian, D.; Ko, T.; Darrell, T. Untethered gesture acquisition and recognition for virtual world manipulation. Virtual Real. 2005, 8, 222–230. [Google Scholar] [CrossRef] [Green Version]
- Sibert, L.E.; Jacob, R.J.K. Evaluation of eye gaze interaction. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, The Hague, The Netherlands, 1–6 April 2000; ACM: New York, NY, USA, 2000; pp. 281–288. [Google Scholar]
- Wu, D.; Zhen, X.; Fan, X.; Hu, Y.; Zhu, H. A virtual environment for complex products collaborative assembly operation simulation. J. Intell. Manuf. 2010, 23, 821–833. [Google Scholar] [CrossRef]
- Chen, F.; Zhong, Q.; Cannella, F.; Sekiyama, K.; Fukuda, T. Hand Gesture Modeling and Recognition for Human and Robot Interactive Assembly Using Hidden Markov Models. Int. J. Adv. Robot. Syst. 2015, 12, 48. [Google Scholar] [CrossRef]
- Kim, W.; Lorenzini, M.; Balatti, P.; Nguyen, D.H.P.; Pattacini, U.; Tikhanoff, V.; Peternel, L.; Fantacci, C.; Natale, L.; Metta, G.; et al. Adaptable Workstations for Human-Robot Collaboration: A Reconfigurable Framework for Improving Worker Ergonomics and Productivity. IEEE Robot. Autom. Mag. 2019, 26, 14–26. [Google Scholar] [CrossRef] [Green Version]
- Weng, C.-Y.; Yuan, Q.; Suarez-Ruiz, F.; Chen, I.-M. A Telemanipulation-Based Human–Robot Collaboration Method to Teach Aerospace Masking Skills. IEEE Trans. Ind. Inform. 2020, 16, 3076–3084. [Google Scholar] [CrossRef]
- Li, Z.; Jarvis, R. Visual interpretation of natural pointing gestures in 3D space for human-robot interaction. In Proceedings of the 11th International Conference on Control Automation Robotics & Vision, Singapore, 7–10 December 2010; IEEE: New York, NY, USA, 2010; pp. 2513–2518. [Google Scholar]
- Mayer, S.; Schwind, V.; Schweigert, R.; Henze, N. The Effect of Offset Correction and Cursor on Mid-Air Pointing in Real and Virtual Environments. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; ACM: New York, NY, USA, 2018; p. 653. [Google Scholar]
- Shahid, A.A.; Roveda, L.; Piga, D.; Braghin, F. Learning Continuous Control Actions for Robotic Grasping with Reinforcement Learning. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; IEEE: New York, NY, USA, 2020; pp. 4066–4072. [Google Scholar]
- Apolinarska, A.A.; Pacher, M.; Li, H.; Cote, N.; Pastrana, R.; Gramazio, F.; Kohler, M. Robotic assembly of timber joints using reinforcement learning. Autom. Constr. 2021, 125, 103569. [Google Scholar] [CrossRef]
- Peternel, L.; Oztop, E.; Babic, J. A shared control method for online human-in-the-loop robot learning based on Locally Weighted Regression. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; IEEE: New York, NY, USA, 2016; pp. 3900–3906. [Google Scholar]
- Tanwani, A.K.; Calinon, S. A generative model for intention recognition and manipulation assistance in teleoperation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: New York, NY, USA, 2017; pp. 43–50. [Google Scholar]
- Zeng, H.; Shen, Y.; Hu, X.; Song, A.; Xu, B.; Li, H.; Wang, Y.; Wen, P. Semi-Autonomous Robotic Arm Reaching with Hybrid Gaze–Brain Machine Interface. Front. Neurorobotics 2020, 13, 111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kavraki, L.; Svestka, P.; Latombe, J.-C.; Overmars, M. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. In Proceedings of the International Conference on Robotics and Automation, Minneapolis, MN, USA, 22–28 April 1996; pp. 566–580. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Xu, Y.; Ni, J.; Wang, Q. Glove-based virtual hand grasping for virtual mechanical assembly. Assem. Autom. 2016, 36, 349–361. [Google Scholar] [CrossRef]
- Niehorster, D.C.; Li, L.; Lappe, M. The Accuracy and Precision of Position and Orientation Tracking in the HTC Vive Virtual Reality System for Scientific Research. i Percept. 2017, 8, 204166951770820. [Google Scholar] [CrossRef] [Green Version]
- Abdelmoumene, H.; Berrached, N.E.; Arioui, H.; Merzouki, R.; Abbassi, H.A. Telerobotics Using a Gestural Servoing Interface. AIP Conf. Proc. 2018, 1019, 414–419. [Google Scholar] [CrossRef]
- Kooij, J.F. SenseCap: Synchronized data collection with Microsoft Kinect2 and LeapMotion. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; ACM: New York, NY, USA, 2016; pp. 1218–1221. [Google Scholar]
- Lariviere, J.A. Eye Tracking: Eye-Gaze Technology. In International Handbook of Occupational Therapy Interventions; Springer: Berlin/Heidelberg, Germany, 2014; pp. 339–362. [Google Scholar]
- Luzanin, O.; Plancak, M. Hand gesture recognition using low-budget data glove and cluster-trained probabilistic neural network. Assem. Autom. 2014, 34, 94–105. [Google Scholar] [CrossRef]
- Gleeson, B.; MacLean, K.; Haddadi, A.; Croft, E.; Alcazar, J. Gestures for industry Intuitive human-robot communication from human observation. In Proceedings of the 2013 8th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Tokyo, Japan, 3–6 March 2013; IEEE Press: New York, NY, USA, 2013; pp. 349–356. [Google Scholar]
- Li, G.; Tang, H.; Sun, Y.; Kong, J.; Jiang, G.; Jiang, D.; Tao, B.; Xu, S.; Liu, H. Hand gesture recognition based on convolution neural network. Clust. Comput. 2019, 22, 2719–2729. [Google Scholar] [CrossRef]
- Salvucci, D.D.; Goldberg, J.H. Identifying fixations and saccades in eye-tracking protocols. In Proceedings of the Eye Tracking Research & Applications Symposium, Palm Beach Gardens, FL, USA, 6–8 November 2000; ACM: New York, NY, USA, 2000; pp. 71–77. [Google Scholar] [CrossRef]
- Mayer, S.; Wolf, K.; Schneegass, S.; Henze, N. Modeling Distant Pointing for Compensating Systematic Displacements. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; ACM: New York, NY, USA, 2015; pp. 4165–4168. [Google Scholar]
- Ichnowski, J.; Prins, J.; Alterovitz, R. Cloud-based Motion Plan Computation for Power-Constrained Robots. In Algorithmic Foundations of Robotics XII: Proceedings of the Twelfth Workshop on the Algorithmic Foundations of Robotics; Goldberg, K., Abbeel, P., Bekris, K., Miller, L., Eds.; Springer International Publishing: Cham, Germany, 2020; pp. 96–111. [Google Scholar]
- Zhang, T.; Su, J. Collision-free planning algorithm of motion path for the robot belt grinding system. Int. J. Adv. Robot. Syst. 2018, 15, 1729881418793778. [Google Scholar] [CrossRef] [Green Version]
- Ye, G.; Alterovitz, R. Demonstration-Guided Motion Planning. In Proceedings of the International Symposium on Robotic; Springer International Publishing: Cham, Germany, 2017; pp. 291–307. [Google Scholar]
- Ichter, B.; Harrison, J.; Pavone, M. Learning Sampling Distributions for Robot Motion Planning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; IEEE: New York, NY, USA, 2018; pp. 7087–7094. [Google Scholar]
- Mu, B.; Giamou, M.; Paull, L.; Agha-Mohammadi, A.-A.; Leonard, J.; How, J. Information-based Active SLAM via topological feature graphs. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; IEEE: New York, NY, USA, 2016; pp. 5583–5590. [Google Scholar]
- Wang, P.; Gao, S.; Li, L.; Sun, B.; Cheng, S. Obstacle Avoidance Path Planning Design for Autonomous Driving Vehicles Based on an Improved Artificial Potential Field Algorithm. Energies 2019, 12, 2342. [Google Scholar] [CrossRef] [Green Version]
- Francis, A.; Faust, A.; Chiang, H.-T.L.; Hsu, J.; Kew, J.C.; Fiser, M.; Lee, T.-W.E. Long-Range Indoor Navigation with PRM-RL. arXiv 2019, arXiv:1902.09458. [Google Scholar]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Ferguson, D.; Stentz, A. Using interpolation to improve path planning: The Field D* algorithm. J. Field Robot. 2006, 23, 79–101. [Google Scholar] [CrossRef] [Green Version]
- Syberfeldt, A.; Danielsson, O.; Holm, M.; Wang, L. Visual Assembling Guidance Using Augmented Reality. Procedia Manuf. 2015, 1, 98–109. [Google Scholar] [CrossRef]
- Zhao, X.; Chen, X.; He, Y.; Cao, H.; Chen, T. Varying Speed Rate Controller for Human–Robot Teleoperation Based on Muscle Electrical Signals. IEEE Access 2019, 7, 143563–143572. [Google Scholar] [CrossRef]
- Gorjup, G.; Kontoudis, G.P.; Dwivedi, A.; Gao, G.; Matsunaga, S.; Mariyama, T.; MacDonald, B.; Liarokapis, M. Combining Programming by Demonstration with Path Optimization and Local Replanning to Facilitate the Execution of Assembly Tasks. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; IEEE: New York, NY, USA, 2020; pp. 1885–1892. [Google Scholar]
- Lentini, G.; Settimi, A.; Caporale, D.; Garabini, M.; Grioli, G.; Pallottino, L.; Catalano, M.G.; Bicchi, A. Alter-Ego: A Mobile Robot With a Functionally Anthropomorphic Upper Body Designed for Physical Interaction. IEEE Robot. Autom. Mag. 2019, 26, 94–107. [Google Scholar] [CrossRef]
- Sorgini, F.; Farulla, G.A.; Lukic, N.; Danilov, I.; Roveda, L.; Milivojevic, M.; Pulikottil, T.B.; Carrozza, M.C.; Prinetto, P.; Tolio, T.; et al. Tactile sensing with gesture-controlled collaborative robot. In Proceedings of the 2020 IEEE International Workshop on Metrology for Industry 4.0 & IoT, Roma, Italy, 3–5 June 2020; IEEE: New York, NY, USA, 2020; pp. 364–368. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distance | Object | Accuracy M(SD) | Object | Accuracy M(SD) | Object | Accuracy M(SD) |
|---|---|---|---|---|---|---|
| 40 | O1 | 0.62(1.10) | O2 | 0.41(0.31) | O3 | 0.99(1.83) |
| O4 | 0.41(1.00) | O5 | 0.78(0.83) | O6 | 0.97(0.46) | |
| O7 | 0.69(1.05) | O8 | 1.26(0.58) | O9 | 0.99(0.44) | |
| 60 | O1 | 0.39(2.48) | O2 | 0.78(0.54) | O3 | 0.70(1.04) |
| O4 | 0.79(1.32) | O5 | 1.00(1.08) | O6 | 1.09(0.66) | |
| O7 | 0.63(1.89) | O8 | 0.70(2.10) | O9 | 1.00(0.91) |
| Distance | Object | Accuracy M(SD) | Object | Accuracy M(SD) | Object | Accuracy M(SD) |
|---|---|---|---|---|---|---|
| Original | O1 | 0.83(0.11) | O2 | 0.42(0.13) | O3 | 0.44(0.21) |
| O4 | 0.98(0.32) | O5 | 0.50(0.20) | O6 | 0.87(0.46) | |
| O7 | 0.72(0.22) | O8 | 0.72(0.17) | O9 | 0.45(0.17) | |
| Filtering | O1 | 0.39(0.21) | O2 | 0.65(0.23) | O3 | 0.22(0.14) |
| O4 | 0.44(0.18) | O5 | 0.46(1.13) | O6 | 0.55(0.27) | |
| O7 | 0.37(0.26) | O8 | 0.20(0.13) | O9 | 0.56(0.12) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; He, Y.; Chen, X.; Liu, Z. Human–Robot Collaborative Assembly Based on Eye-Hand and a Finite State Machine in a Virtual Environment. Appl. Sci. 2021, 11, 5754. https://doi.org/10.3390/app11125754
Zhao X, He Y, Chen X, Liu Z. Human–Robot Collaborative Assembly Based on Eye-Hand and a Finite State Machine in a Virtual Environment. Applied Sciences. 2021; 11(12):5754. https://doi.org/10.3390/app11125754
Chicago/Turabian StyleZhao, Xue, Ye He, Xiaoan Chen, and Zhi Liu. 2021. "Human–Robot Collaborative Assembly Based on Eye-Hand and a Finite State Machine in a Virtual Environment" Applied Sciences 11, no. 12: 5754. https://doi.org/10.3390/app11125754
APA StyleZhao, X., He, Y., Chen, X., & Liu, Z. (2021). Human–Robot Collaborative Assembly Based on Eye-Hand and a Finite State Machine in a Virtual Environment. Applied Sciences, 11(12), 5754. https://doi.org/10.3390/app11125754