
An Acoustic Way to Support Japanese Children’s Effective English Learning in School Classrooms


Abstract
:1. Introduction
2. Methods
2.1. Participants
- At the school, the grade 6 children had been taking three English lessons every fortnight, taught mainly by a Japanese native teacher in the English learning room, dedicated for English lessons of the grade five and six, for roughly 17 months before the current study began.
- They also had an English native teacher assisting in some lessons, typically once a week.
- Each lesson was 45-min-long.
2.2. English Listening Test
2.3. Sound Amplification Systems for a Classroom
2.4. Acoustic Measurements
2.5. Statistical Analyses
2.6. Ethical Notes
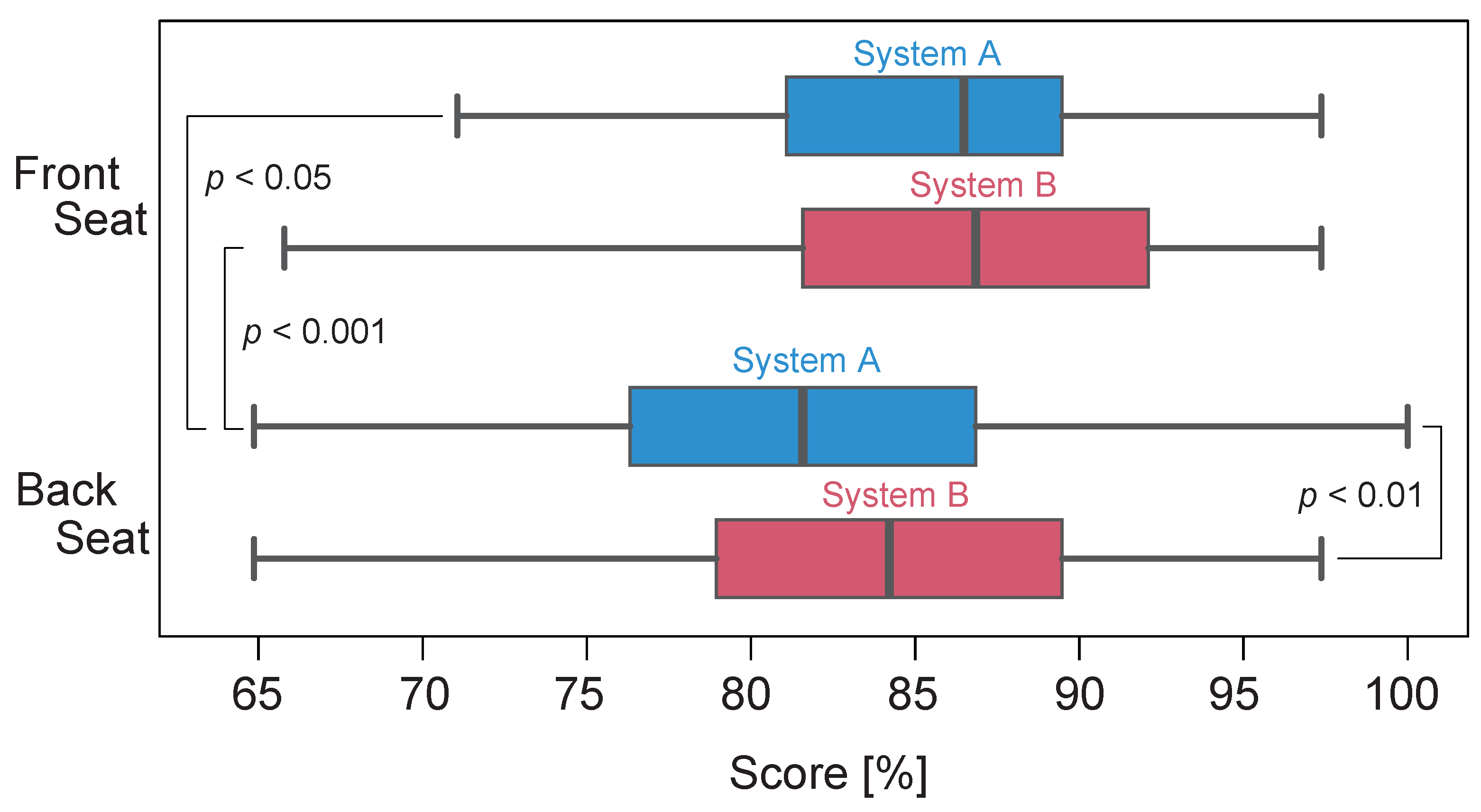
3. Results and Discussions
3.1. Acoustic Measurements
3.2. English Test
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- EF Education First. EF English Proficiency Index: A Ranking of 100 Countries and Regions by English Skills; Technical Report; EF Education First Ltd.: Lucerne, Switzerland, 2020; Available online: https://www.ef.com/epi/ (accessed on 28 June 2021).
- Nuttall, L. Comparative Education: Why Does Japan Continue to Struggle with English? Read. Matrix Int. Online J. 2019, 19, 74–92. [Google Scholar]
- Okumura, S. Homeroom Teachers or Specialist Teachers? Considerations for the Workforce for Teaching English as a Subject at Elementary Schools in Japan. Asian J. Educ. Train. 2017, 3, 1–5. [Google Scholar] [CrossRef]
- Houtgast, T. The effect of ambient noise on speech intelligibility in classrooms. Appl. Acoust. 1981, 14, 15–25. [Google Scholar] [CrossRef]
- Bradley, J.S. Speech intelligibility studies in classrooms. J. Acoust. Soc. Am. 1986, 80, 846–854. [Google Scholar] [CrossRef] [PubMed]
- Hétu, R.; Truchon-Gagnon, C.; Bilodeau, S.A. Problems of noise in school settings: A review of literature and the results of an exploratory study. J. Speech-Lang. Pathol. Audiol. 1990, 14, 31–39. [Google Scholar]
- Rosenberg, G.G.; Blake-Rahter, P.; Heavner, J.; Allen, L.; Redmond, B.M.; Phillips, J.; Stigers, K. Improving Classroom Acoustics (ICA): A three-year FM sound field classroom amplification study. J. Educ. Audiol. 1999, 7, 8–28. [Google Scholar]
- Nelson, P.B.; Soli, S. Acoustical Barriers to Learning: Children at Risk in Every Classroom. Lang. Speech Hear. Serv. Sch. 2000, 31, 356–361. [Google Scholar] [CrossRef] [PubMed]
- ASHA Working Group on Classroom Acoustics. Acoustics in Educational Settings: Technical Report; American Speech-Language-Hearing Association: Manchester, MD, USA, 2005. [Google Scholar]
- Sato, H.; Bradley, J.S. Evaluation of acoustical conditions for speech communication in working elementary school classrooms. J. Acoust. Soc. Am. 2008, 123, 2064–2077. [Google Scholar] [CrossRef] [Green Version]
- Rabbitt, P. Recognition: Memory for words correctly heard in noise. Psychon. Sci. 1966, 6, 383–384. [Google Scholar] [CrossRef] [Green Version]
- Key, A.P.; Gustafson, S.J.; Rentmeester, L.; Hornsby, B.W.Y.; Bess, F.H. Speech-Processing Fatigue in Children: Auditory Event-Related Potential and Behavioral Measures. J. Speech Lang. Hear. Res. JSLHR 2017, 60, 2090–2104. [Google Scholar] [CrossRef]
- Evans, G.W.; Lepore, S.J. Nonauditory Effects of Noise on Children: A Critical Review. Child. Environ. 1993, 10, 31–51. [Google Scholar]
- Anderson, K.L. Kids in noisy classrooms: What does the research really say. J. Educ. Audiol. 2001, 9, 21–33. [Google Scholar]
- Shield, B.M.; Dockrell, J.E. The Effects of Noise on Children at School: A Review. Build. Acoust. 2003, 10, 97–116. [Google Scholar] [CrossRef]
- Anderson, K. The Problem of Classroom Acoustics: The Typical Classroom Soundscape Is a Barrier to Learning. Semin. Hear. 2004, 25, 117–129. [Google Scholar] [CrossRef]
- Shield, B.M.; Dockrell, J.E. The effects of environmental and classroom noise on the academic attainments of primary school children. J. Acoust. Soc. Am. 2008, 123, 133–144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tiesler, G.; Machner, R.; Brokmann, H. Classroom Acoustics and Impact on Health and Social Behaviour. Energy Procedia 2015, 78, 3108–3113. [Google Scholar] [CrossRef] [Green Version]
- Magimairaj, B.; Nagaraj, N.; Benafield, N. Children’s Speech Perception in Noise: Evidence for Dissociation From Language and Working Memory. J. Speech Lang. Hear. Res. 2018, 61, 1294–1305. [Google Scholar] [CrossRef]
- Peng, J.X.; Jiang, P. The Effects of the Noise and Reverberation on the Working Memory Span of Children. Arch. Acoust. 2018, 43, 123–128. [Google Scholar]
- Cucharero, J.; Hänninen, T.; Lokki, T. Influence of Sound-Absorbing Material Placement on Room Acoustical Parameters. Acoustics 2019, 1, 644–660. [Google Scholar] [CrossRef] [Green Version]
- Leavitt, R.; Flexer, C. Speech degradation as measured by the Rapid Speech Transmission Index (RASTI). Ear Hear. 1991, 12, 115–118. [Google Scholar] [CrossRef]
- Iannace, G.; Trematerra, A.; Trematerra, P. Acoustic correction using green material in classrooms located in historical buildings. Acoust. Aust. 2013, 41, 213–218. [Google Scholar]
- Berardi, U.; Iannace, G.; Trematerra, A. Acoustic Treatments Aiming to Achieve the Italian Minimum Environmental Criteria (CAM) Standards in Large Reverberant Classrooms. Can. Acoust. Can. 2019, 47, 73–80. [Google Scholar]
- Kuusinen, A.; Saariniemi, E.; Sivonen, V.; Dietz, A.; Aarnisalo, A.A.; Lokki, T. An exploratory investigation of speech recognition thresholds in noise with auralisations of two reverberant rooms. Int. J. Audiol. 2021, 60, 210–219. [Google Scholar] [CrossRef]
- Kaplanis, N.; Bech, S.; Lokki, T.; van Waterschoot, T.; Holdt Jensen, S. Perception and preference of reverberation in small listening rooms for multi-loudspeaker reproduction. J. Acoust. Soc. Am. 2019, 146, 3562–3576. [Google Scholar] [CrossRef] [PubMed]
- Mealings, K. Classroom acoustic conditions: Understanding what is suitable through a review of national and international standards, recommendations, and live classroom measurements. In Proceedings of the Acoustics 2016: The Second Australasian Acoustical Societies’ Conference, Brisbane, Australia, 9–11 November 2016. [Google Scholar]
- Freeman, S.; Eddy, S.L.; McDonough, M.; Smith, M.K.; Okoroafor, N.; Jordt, H.; Wenderoth, M.P. Active learning increases student performance in science, engineering, and mathematics. Proc. Natl. Acad. Sci. USA 2014, 111, 8410–8415. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rowe, K. Effective teaching practices for students with and without learning difficulties: Constructivism as a legitimate theory of learning AND of teaching? Stud. Learn. Process. 2006, 10, 1–24. [Google Scholar]
- Johnson, C.E. Children’s phoneme identification in reverberation and noise. J. Speech Lang. Hear. Res. 2000, 43, 144–157. [Google Scholar] [CrossRef]
- Northern, J.L.; Downs, M.P. Hearing in Children; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2014. [Google Scholar]
- Lyberg-Åhlander, V.; Haake, M.; Brännström, J.; Schötz, S.; Sahlén, B. Does the speaker’s voice quality influence children’s performance on a language comprehension test? Int. J. Speech Lang. Pathol. 2015, 17, 63–73. [Google Scholar] [CrossRef]
- Rantala, L.; Sala, E. Associations between Classroom Conditions and Teacher’s Voice Production. Energy Procedia 2015, 78, 3120–3125. [Google Scholar] [CrossRef] [Green Version]
- Cantor Cutiva, L.C.; Vogel, I.; Burdorf, A. Voice disorders in teachers and their associations with work-related factors: A systematic review. J. Commun. Disord. 2013, 46, 143–155. [Google Scholar] [CrossRef]
- Puglisi, G.; Cutiva, L.C.; Pavese, L.; Castellana, A.; Bona, M.; Fasolis, S.; Lorenzatti, V.; Carullo, A.; Burdorf, A.; Bronuzzi, F.; et al. Acoustic Comfort in High-school Classrooms for Students and Teachers. Energy Procedia 2015, 78, 3096–3101. [Google Scholar] [CrossRef] [Green Version]
- Architectual Institute of Japan Environmental Standard. Standard and Design Guidelines for School Environment in School Buildings; Architectual Institute of Japan: Tokyo, Japan, 2020. [Google Scholar]
- Slavin, R.E. Evidence-Based Education Policies: Transforming Educational Practice and Research. Educ. Res. 2002, 31, 15–21. [Google Scholar] [CrossRef] [Green Version]
- Odom, S.L.; Brantlinger, E.; Gersten, R.; Horner, R.H.; Thompson, B.; Harris, K.R. Research in Special Education: Scientific Methods and Evidence-Based Practices. Except. Child. 2005, 71, 137–148. [Google Scholar] [CrossRef] [Green Version]
- Baker, A. Tree or Three? Student’s Book and Audio CD: An Elementary Pronunciation Course, 2nd ed.; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Baker, A. Ship or Sheep? Book and Audio CD Pack: An Intermediate Pronunciation Course, 3rd ed.; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Steinberg Media Technologies GmbH. The True Art of Mastering: WAVELAB. 2021. Available online: https://new.steinberg.net/wavelab/ (accessed on 17 April 2021).
- Python Software Foundation. Python 3.7.4. 2019. Available online: https://docs.python.org/release/3.7.4/ (accessed on 17 April 2021).
- International Organization for Standardization. ISO 1996-1:2016 Acoustics—Description, Measurement and Assessment of Environmental Noise—Part 1: Basic Quantities and Assessment Procedures; ISO: Geneva, Switzerland, 2016. [Google Scholar]
- Neitzel, R. Determination of Risk of Noise-Induced Hearing Loss Due to Recreational Sound: Review; Technical Report; World Health Organization: Geneva, Switzerland, 2017. [Google Scholar]
- Farina, A. Simultaneous Measurement of Impulse Response and Distortion with a Swept-Sine Technique. In Proceedings of the Audio Engineering Society Convention 108, Paris, France, 19–22 February 2000. [Google Scholar]
- International Electrotechnical Commission. IEC 61672-1:2013 Electroacoustics—Sound Level Meters—Part 1: Specifications; IEC: Geneva, Switzerland, 2013. [Google Scholar]
- Farina, A. Advancements in Impulse Response Measurements by Sine Sweeps. In Proceedings of the Audio Engineering Society Convention 122, Vienna, Austria, 5–8 May 2007. [Google Scholar]
- AFMG Technologies GmbH. SysTune 1.2. 2020. Available online: https://systune.afmg.eu/index.php/st-software-en.html (accessed on 17 April 2021).
- International Organization for Standardization. ISO 3382-2:2008 Acoustics—Measurement of Room Acoustic Parameters —Part 2: Reverberation Time in Ordinary Rooms; ISO: Geneva, Switzerland, 2008. [Google Scholar]
- International Electrotechnical Commission. IEC 60268 Sound System Equipment—Part16: Objective Rating of Speech Intelligibility by Speech Transmission Index; IEC: Geneva, Switzerland, 2020. [Google Scholar]
- Houtgast, T.; Steeneken, H.J.M. A review of the MTF concept in room acoustics and its use for estimating speech intelligibility in auditoria. J. Acoust. Soc. Am. 1985, 77, 1069–1077. [Google Scholar] [CrossRef]
- AFMG Ahnert Feistel Media Group. Systune 1.3 Manual, 5th ed.; AFMG Technologies GmbH: Berlin, Germany, 2014. [Google Scholar]
- Harrell, F.F.J. Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis, 2nd ed.; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Steyerberg, E.W.; Harrell, F.E.J.; Borsboom, G.J.; Eijkemans, M.J.; Vergouwe, Y.; Habbema, J.D. Internal validation of predictive models: Efficiency of some procedures for logistic regression analysis. J. Clin. Epidemiol. 2001, 54, 774–781. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. 2019. Available online: https://www.r-project.org/ (accessed on 17 April 2021).
- ASHA Working Group on Classroom Acoustics. Acoustics in Educational Settings: Position Statement; American Speech-Language-Hearing Association: Manchester, MD, USA, 2005. [Google Scholar]
- Acoustical Society of America. ANSI/ASA S12.60-2020/Part 1 American National Standard Acoustical Performance Criteria, Design Requirements, and Guidelines for Schools, Part 1: Permanent Schools; Acoustical Society of America: New York, NY, USA, 2010. [Google Scholar]
- Iverson, P.; Ekanayake, D.; Hamann, S.; Sennema, A.; Evans, B.G. Category and perceptual interference in second-language phoneme learning: An examination of English /w/-/v/ learning by Sinhala, German, and Dutch speakers. J. Exp. Psychol. Hum. Percept. Perform. 2008, 34, 1305–1316. [Google Scholar] [CrossRef] [PubMed]
- Werker, J.F.; Tees, R.C. Cross-language speech perception: Evidence for perceptual reorganization during the first year of life. Infant Behav. Dev. 1984, 7, 49–63. [Google Scholar] [CrossRef]
- Best, C.C.; McRoberts, G.W. Infant perception of non-native consonant contrasts that adults assimilate in different ways. Lang. Speech 2003, 46, 183–216. [Google Scholar] [CrossRef] [Green Version]
- Strange, W.; Dittmann, S. Effects of discrimination training on the perception of /r-l/ by Japanese adults learning English. Percept. Psychophys. 1984, 36, 131–145. [Google Scholar] [CrossRef]
- Logan, J.S.; Lively, S.E.; Pisoni, D.B. Training Japanese listeners to identify English /r/ and /l/: A first report. J. Acoust. Soc. Am. 1991, 89, 874–886. [Google Scholar] [CrossRef] [Green Version]
- Benesty, J.; Sondhi, M.M.; Huang, Y. (Eds.) Springer Handbook of Speech Processiing; Springer: Berlin/Heideberg, Germany, 2008. [Google Scholar]
- Gordon, P.C.; Keyes, L.; Yung, Y.F. Ability in perceiving nonnative contrasts: Performance on natural and synthetic speech stimuli. Percept. Psychophys. 2001, 63, 746–758. [Google Scholar] [CrossRef] [PubMed]
- Kuhl, P.K.; Andruski, J.E.; Chistovich, I.A.; Chistovich, L.A.; Kozhevnikova, E.V.; Ryskina, V.L.; Stolyarova, E.I.; Sundberg, U.; Lacerda, F. Cross-Language Analysis of Phonetic Units in Language Addressed to Infants. Science 1997, 277, 684–686. [Google Scholar] [CrossRef] [PubMed] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Week One | Week Two | |||
|---|---|---|---|---|
| Day One | Day Two | Day One | Day Two | |
| (Monday) | (Tuesday) | (Monday) | (Tuesday) | |
| Lesson 1 | N/A | 36 | N/A | 34 |
| Lesson 2 | 35 | 36 | 34 | 35 |
| Lesson 3 | 36 | 33 | 35 | 27 |
| Lesson 4 | N/A | 36 | N/A | 36 |
| Question Difficulty Level | Correct Answer Rate |
|---|---|
| Level 4 | 40% |
| Level 3 | 40% 60% |
| Level 2 | 60% 80% |
| Level 1 | 80% |
| Explanation of the Explanatory Variable | |
|---|---|
| Difficulty Level (1, 2, 3, 4) | difficulty of word pair in question |
| Test Identifier (1st, 2nd) | habituation effects within each lesson |
| Week (1, 2) | habituation effects over two weeks |
| Sound Amplification System (A, B) | acoustic characteristics |
| Seat Group (1, 2, 3, 4, 5) | Seat position defined in Figure 3 |
| System A | ||||
|---|---|---|---|---|
| Position | 500 Hz | 1 kHz | 2 kHz | STI |
| (0) | 0.66 | 0.48 | 0.41 | 0.794 |
| (1) | 0.57 | 0.44 | 0.39 | 0.762 |
| (2) | 0.6 | 0.48 | 0.41 | 0.622 |
| (3) | 0.6 | 0.52 | 0.41 | 0.717 |
| (4) | 0.53 | 0.46 | 0.42 | 0.736 |
| (5) | 0.64 | 0.47 | 0.41 | 0.702 |
| (6) | 0.6 | 0.47 | 0.42 | 0.745 |
| (7) | 0.6 | 0.48 | 0.42 | 0.775 |
| (8) | 0.61 | 0.51 | 0.42 | 0.715 |
| (9) | 0.67 | 0.46 | 0.41 | 0.739 |
| System B | ||||
| Position | 500 Hz | 1 kHz | 2 kHz | STI |
| (0) | 0.57 | 0.45 | 0.41 | 0.848 |
| (1) | 0.58 | 0.48 | 0.42 | 0.775 |
| (2) | 0.56 | 0.48 | 0.43 | 0.781 |
| (3) | 0.53 | 0.49 | 0.44 | 0.801 |
| (4) | 0.57 | 0.5 | 0.43 | 0.814 |
| (5) | 0.55 | 0.51 | 0.44 | 0.784 |
| (6) | 0.67 | 0.55 | 0.63 | 0.792 |
| (7) | 0.57 | 0.52 | 0.43 | 0.805 |
| (8) | 0.59 | 0.53 | 0.43 | 0.796 |
| (9) | 0.57 | 0.5 | 0.45 | 0.797 |
| Word 1 | Word 2 | Correct Answer Rate (%) | Number of Samples | Difficulty Level |
|---|---|---|---|---|
| light | right | 17.2 | 412 | 4 |
| long | wrong | 20.6 | 413 | 4 |
| tim | tin | 21.8 | 412 | 4 |
| pull | pool | 33.4 | 413 | 4 |
| tennis | dennis | 41.9 | 413 | 3 |
| track | truck | 48.9 | 413 | 3 |
| top | top | 52.4 | 412 | 3 |
| coat | goat | 59.1 | 411 | 3 |
| cap | cab | 63.8 | 412 | 2 |
| class | glass | 69.6 | 411 | 2 |
| men | men | 71.2 | 413 | 2 |
| sheep | cheap | 73.1 | 412 | 2 |
| fool | fool | 74.3 | 412 | 2 |
| lock | look | 74.8 | 412 | 2 |
| cot | pot | 75.3 | 413 | 2 |
| bin | bin | 77.7 | 412 | 2 |
| car | cow | 78.2 | 413 | 2 |
| cart | card | 78.9 | 413 | 2 |
| bag | bug | 83.1 | 413 | 1 |
| snore | snow | 83.5 | 412 | 1 |
| vine | wine | 84.3 | 413 | 1 |
| pot | pot | 87.1 | 412 | 1 |
| bell | bell | 88.6 | 413 | 1 |
| could | could | 88.9 | 413 | 1 |
| pear | bear | 90.8 | 413 | 1 |
| Bobby | Bobby | 93.0 | 413 | 1 |
| cab | cab | 94.2 | 413 | 1 |
| pig | peg | 94.7 | 413 | 1 |
| wood | good | 96.1 | 413 | 1 |
| ten | pen | 96.6 | 412 | 1 |
| pat | pat | 96.6 | 413 | 1 |
| cup | cup | 96.6 | 413 | 1 |
| fan | fan | 96.6 | 413 | 1 |
| jeer | jeer | 97.8 | 412 | 1 |
| hill | hill | 98.1 | 413 | 1 |
| sand | sand | 98.8 | 413 | 1 |
| walk | walk | 99.0 | 413 | 1 |
| wig | fig | 99.3 | 412 | 1 |
| cut | cut | 99.3 | 413 | 1 |
| toy | toy | 99.3 | 413 | 1 |
| jam | yam | 99.3 | 413 | 1 |
| rack | rock | 99.8 | 413 | 1 |
| Univariate | Multivariate | |||
|---|---|---|---|---|
| OR | 95% CI | OR | 95% CI | |
| Difficulty Level | ||||
| Level 2 vs. Level 1 | 0.17 *** | (0.15–0.19) | 0.17 *** | (0.15–0.19) |
| Level 3 vs. Level 1 | 0.06 *** | (0.06–0.07) | 0.06 *** | (0.06–0.07) |
| Level 4 vs. Level 1 | 0.02 *** | (0.01–0.02) | 0.02 *** | (0.02–0.02) |
| Test Identifier of a lesson | ||||
| 2nd Test vs. 1st Test | 1.08 * | (1.00–1.16) | 0.88 ** | (0.80–0.96) |
| Week | ||||
| Week 2 vs. Week 1 | 1.15 *** | (1.07–1.24) | 1.23 *** | (1.13–1.34) |
| Sound Amplification System | ||||
| System B vs. System A | 1.06 | (0.99–1.15) | 1.11 * | (1.01–1.21) |
| Seat Group | ||||
| Group 2 vs. Group 1 | 0.96 | (0.86–1.08) | 0.94 | (0.82–1.08) |
| Group 3 vs. Group 1 | 0.98 | (0.87–1.10) | 0.97 | (0.85–1.12) |
| Group 4 vs. Group 1 | 0.91 | (0.81–1.02) | 0.87 * | (0.76–1.00) |
| Group 5 vs. Group 1 | 0.83 ** | (0.73–0.93) | 0.76 *** | (0.66–0.88) |
| Original C-Statistic | Optimism | Corrected C-Statistic |
|---|---|---|
| 0.8314 | 0.0002 | 0.8312 |
| Univariate | Multivariate | |||
|---|---|---|---|---|
| OR | 95% CI | OR | 95% CI | |
| Difficulty Level | ||||
| Level 2 vs. Level 1 | 0.17 *** | (0.15–0.19) | 0.17 *** | (0.15–0.19) |
| Level 3 vs. Level 1 | 0.06 *** | (0.06–0.07) | 0.06 *** | (0.06–0.07) |
| Test Identifier of a lesson | ||||
| 2nd Test vs. 1st Test | 0.72 *** | (0.66–0.78) | 0.92 | (0.83–1.01) |
| Week | ||||
| Week 2 vs. Week 1 | 1.20 *** | (1.10–1.31) | 1.26 *** | (1.14–1.38) |
| Sound Amplification System | ||||
| System B vs. System A | 1.13 ** | (1.03–1.23) | 1.17 ** | (1.06–1.28) |
| Seat Group | ||||
| Group 2 vs. Group 1 | 0.90 | (0.78–1.03) | 0.88 | (0.75–1.02) |
| Group 3 vs. Group 1 | 0.93 | (0.80–1.07) | 0.91 | (0.78–1.07) |
| Group 4 vs. Group 1 | 0.81 ** | (0.71–0.92) | 0.77 *** | (0.67–0.90) |
| Group 5 vs. Group 1 | 0.72 *** | (0.63–0.83) | 0.67 *** | (0.58–0.78) |
| Univariate | Multivariate | |||
|---|---|---|---|---|
| OR | 95% CI | OR | 95% CI | |
| Test Identifier of a lesson | ||||
| 2nd Test vs. 1st Test | 0.62 *** | (0.46–0.81) | 0.61 *** | (0.46–0.81) |
| Sound Amplification System | ||||
| System B vs. System A | 0.79 * | (0.63–1.00) | 0.78 * | (0.62–0.99) |
| Seat Group | ||||
| Group 2 vs. Group 1 | 1.40 | (0.96–2.05) | 1.41 | (0.97–2.06) |
| Group 3 vs. Group 1 | 1.41 | (0.96–2.07) | 1.42 | (0.97–2.08) |
| Group 4 vs. Group 1 | 1.76 ** | (1.23–2.53) | 1.77 ** | (1.23–2.55) |
| Group 5 vs. Group 1 | 1.63 * | (1.12–2.40) | 1.64 * | (1.12–2.41) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Evans, N.; Kaneko, M.; Seleznov, I.; Shigematsu, T.; Kiyono, K. An Acoustic Way to Support Japanese Children’s Effective English Learning in School Classrooms. Appl. Sci. 2021, 11, 6062. https://doi.org/10.3390/app11136062
Evans N, Kaneko M, Seleznov I, Shigematsu T, Kiyono K. An Acoustic Way to Support Japanese Children’s Effective English Learning in School Classrooms. Applied Sciences. 2021; 11(13):6062. https://doi.org/10.3390/app11136062
Chicago/Turabian StyleEvans, Naoko, Miki Kaneko, Ivan Seleznov, Taiki Shigematsu, and Ken Kiyono. 2021. "An Acoustic Way to Support Japanese Children’s Effective English Learning in School Classrooms" Applied Sciences 11, no. 13: 6062. https://doi.org/10.3390/app11136062
APA StyleEvans, N., Kaneko, M., Seleznov, I., Shigematsu, T., & Kiyono, K. (2021). An Acoustic Way to Support Japanese Children’s Effective English Learning in School Classrooms. Applied Sciences, 11(13), 6062. https://doi.org/10.3390/app11136062