
Content Management Based on Content Popularity Ranking in Information-Centric Networks

Abstract
:1. Introduction
2. Related Work
2.1. Information-Centric Networking
2.2. Content Popularity Prediction
2.3. Content Caching and Removal Schemes
3. Content Management Based on Content Popularity Ranking
3.1. The CPR Mechanism
3.2. Content Caching Scheme Using the CPR Mechanism
| Algorithm 1: cache_content () | |
| INPUT new content i, node n, number of total content m | |
| 1. | READ labels of the following tags of content i |
| 2. | |
| 3. | EXTRACT value of the download counter |
| 4. | , of content i at node n |
| 5. | DETERMINE values of the tags |
| 6. | Using Equation (4) |
| 7. | CALCULATE CPR of content i |
| 8. | Using Equation (5) |
| 9. | |
| 10. | CALCULATEpopularity threshold of node n |
| 11. | Using Equation (6) |
| 12. | |
| 13. | IF |
| 14. | CACHE content i at node n |
| 15. | ELSE DISCARD content i |
| 16. | END IF |
3.3. Updating the Labels of the Tags
| Algorithm 2: initialize () | |
| INPUT existing content i, node n, number of total content m | |
| 1. | READ labels of the following tags of content i |
| 2. | |
| 3. | EXTRACT value of the download counter |
| 4. | , of content i at node n |
| 5. | SET the following time variables |
| 6. | |
| 7. | INITIALIZE the following time variable |
| 8. | |
| 9. | CALCULATE the average download counter of node n |
| 10. | Using Equation (8) |
| 11. | |
| 12. | CALL update_labels () |
| Algorithm 3: update_labels () | |
| 1. | IF |
| 2. | ; |
| 3. | ; |
| 4. | ELSE IF |
| 5. | IF |
| 6. | ; |
| 7. | ; |
| 8. | ; |
| 9. | ELSE IF |
| 10. | ; |
| 11. | ; |
| 12. | ELSE IF |
| 13. | ; |
| 14. | CALL delete_content (i, n) |
| 15. | END IF |
| 16. | END IF |
| 17. | CALL initialize () |
3.4. Content Removal Scheme Using CPR Mechanism
| Algorithm 4: delete_content (content, node) | |
| INPUT existing content i, node n | |
| 1. | |
| 2. | ERASE content i from node n |
| Algorithm 5: remove_content () | |
| INPUT new content i, existing content z, node n | |
| INPUT popularity threshold of node n, | |
| INPUT CPR of all existing content z, | |
| 1. | READ labels of the following tags of all existing content z |
| 2. | |
| 3. | IF |
| 4. | ERASE ALL content z from node n |
| 5. | IF sufficient space to cache content i |
| 6. | BREAK |
| 7. | END IF |
| 8. | ELSE IF |
| 9. | WHILE |
| 10. | ERASE ALL content z from node n |
| 11. | END WHILE |
| 12. | IF sufficient space to cache content i |
| 13. | BREAK |
| 14. | END IF |
| 15. | ELSE IF |
| 16. | SORT all matching content in terms of |
| 17. | lowest to highest |
| 18. | WHILE content z exists matching this condition |
| 19. | IF |
| 20. | ERASE content z from node n |
| 21. | END IF |
| 22. | IF sufficient space to cache content i |
| 23. | BREAK |
| 24. | END IF |
| 25. | END WHILE |
| 26. | ELSE SORT all the remaining content in terms of |
| 27. | lowest to highest |
| 28. | WHILE not enough space to cache content i |
| 29. | ERASE content z from node n |
| 30. | IF sufficient space to cache content i |
| 31. | BREAK |
| 32. | END IF |
| 33. | END WHILE |
| 34. | END IF |
4. Performance Analysis
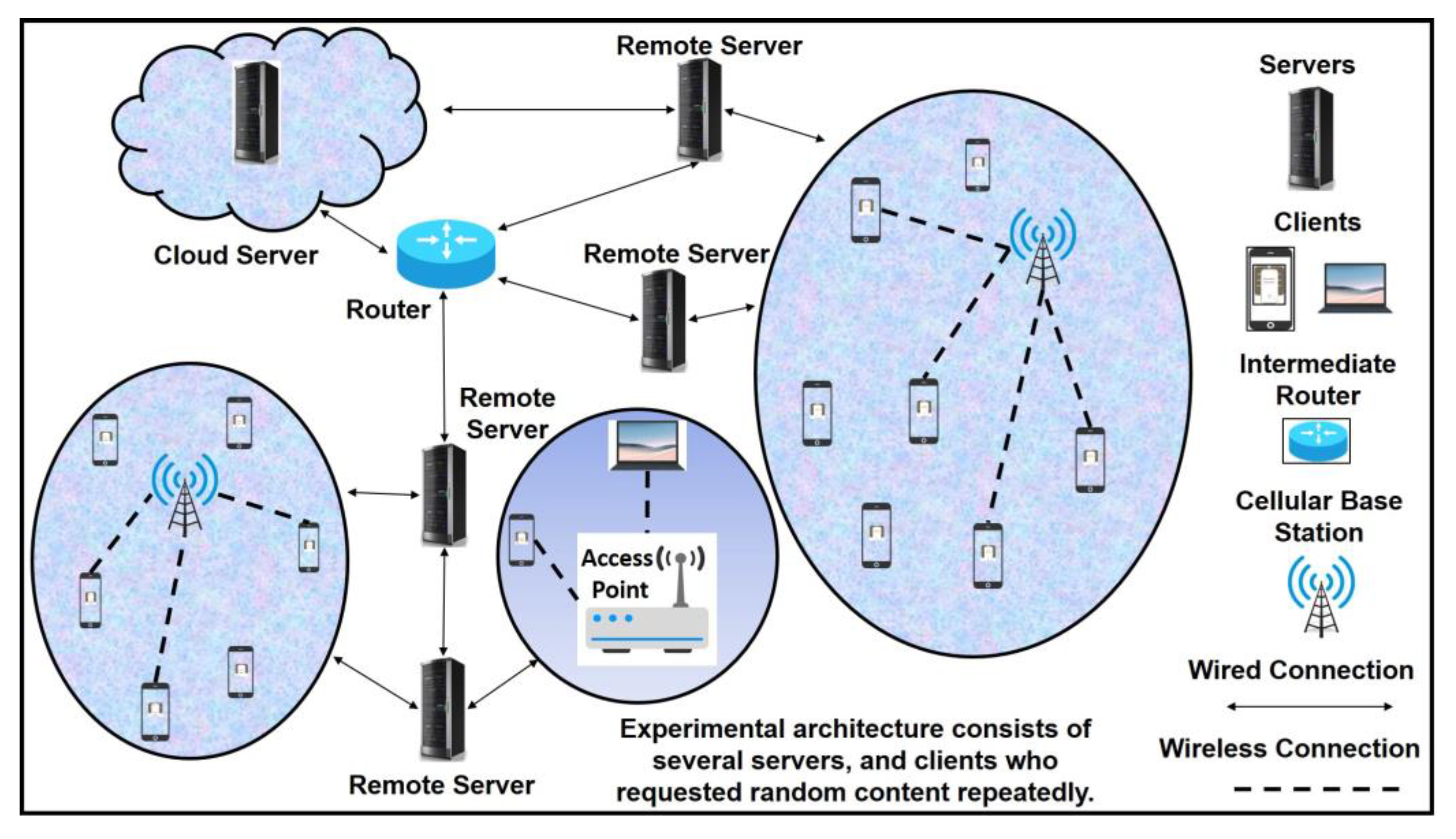
4.1. The Network Topology and the Experimental Procedures
4.2. Average Hop Count
4.3. Cache Hit Ratio
4.4. Content Delivery Time
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AHC | Average Hop Counts |
| ARMA | Autoregressive Moving Average |
| CCN | Content-Centric Networking |
| CPR | Content Popularity Ranking |
| CDT | Content Delivery Time |
| COMET | COntent Mediator architecture for content-aware nETworks |
| CHR | Cache Hit Ratio |
| DONA | Data-Oriented Network Architecture |
| EHCP | Efficient Hybrid Content Placement |
| FIFO | First In First Out |
| ICN | Information-Centric Networking |
| IMDB | Internet Movie Database |
| LCE | Leave Copy Everywhere |
| LCD | Leave Copy Down |
| LRU | Least Recently Used |
| LFU | Least Frequently Used |
| MICC | Most Interested Content Caching |
| MCD | Move Copy Down |
| MB | MegaBytes |
| NDN | Named-Data Networking |
| NetInf | Network of Information |
| PURSUIT | Publish-Subscribe Internet Technology |
| PSIRP | Publish-Subscribe Internet Routing Paradigm |
| RAND | Random |
| SAIL | Scalable & Adaptive Internet soLutions |
| s | Seconds |
| 4WARD | Architecture and Design for the Future Internet |
References
- Barnett, T.; Jain, S.; Andra, U.; Khurana, T. Cisco Visual Networking Index (VNI), Complete Forecast Update, 2017–2022. 2018. Available online: https://s3.amazonaws.com/media.mediapost.com/uploads/CiscoForecast.pdf (accessed on 30 June 2021).
- Jacobson, V.; Smetters, D.K.; Thornton, J.D.; Plass, M.F.; Briggs, N.H.; Braynard, R.L. Networking named content. In Proceedings of the 5th International Conference on Emerging Networking Experiments and Technologies, Rome, Italy, 1–4 December 2009; pp. 1–12. [Google Scholar]
- Xylomenos, G.; Ververidis, C.N.; Siris, V.A.; Fotiou, N.; Tsilopoulos, C.; Vasilakos, X.; Katsaros, K.V.; Polyzos, G.C. A survey of information-centric networking research. IEEE Commun. Surv. Tutor. 2013, 16, 1024–1049. [Google Scholar] [CrossRef]
- Cheriton, D.R.; Gritter, M. TRIAD: A New Next-Generation Internet Architecture. 2000. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.33.5878 (accessed on 30 June 2021).
- Zhang, L.; Afanasyev, A.; Burke, J.; Jacobson, V.; Claffy, K.C.; Crowley, P.; Papadopoulos, C.; Wang, L.; Zhang, B. Named data networking. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 66–73. [Google Scholar] [CrossRef]
- Koponen, T.; Chawla, M.; Chun, B.G.; Ermolinskiy, A.; Kim, K.H.; Shenker, S.; Stoica, I. A data-oriented (and beyond) network architecture. In Proceedings of the 2007 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Kyoto, Japan, 27–31 August 2007; pp. 181–192. [Google Scholar]
- Trossen, D.; Parisis, G. Designing and realizing an information-centric internet. IEEE Commun. Mag. 2012, 50, 60–67. [Google Scholar] [CrossRef]
- FP7 PURSUIT Project. Available online: http://www.fp7-pursuit.eu/ (accessed on 21 August 2018).
- Lagutin, D.; Visala, K.; Tarkoma, S. Publish/Subscribe for Internet: PSIRP Perspective. Future Internet Assem. 2010, 84, 75–84. [Google Scholar]
- FP7 PSIRP Project. Available online: http://www.psirp.org/ (accessed on 21 August 2018).
- FP7 SAIL Project. Available online: http://www.sail-project.eu/ (accessed on 21 August 2018).
- FP7 4WARD Project. Available online: http://www.4ward-project.eu/ (accessed on 21 August 2018).
- García, G. COMET: Content mediator architecture for content-aware networks. In Proceedings of the 2011 Future Network & Mobile Summit, Warsaw, Poland, 15–17 June 2011; pp. 1–8. [Google Scholar]
- Dannewitz, C.; Kutscher, D.; Ohlman, B.; Farrell, S.; Ahlgren, B.; Karl, H. Network of information (netinf)—An information-centric networking architecture. Comput. Commun. 2013, 36, 721–735. [Google Scholar] [CrossRef]
- Nancy, J.G.A.; Kumar, D. Content popularity prediction methods—A survey. In Proceedings of the 2018 3rd International Conference on Communication and Electronics Systems (ICCES), Coimbatore, Tamil Nadu, India, 15–16 October 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Gursun, G.; Crovella, M.; Matta, I. Describing and forecasting video access patterns. In Proceedings of the 2011 Proceedings IEEE INFOCOM, Shanghai, China, 15–16 April 2011; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar]
- Ahmed, M.; Spagna, S.; Huici, F.; Niccolini, S. A peek into the future: Predicting the evolution of popularity in user generated content. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining—WSDM ’13, Rome, Italy, 4–8 February 2013; ACM Press: New York, NY, USA, 2013. [Google Scholar]
- Lerman, K.; Hogg, T. Using a model of social dynamics to predict popularity of news. In Proceedings of the 19th International Conference on World Wide Web—WWW ’10, Raleigh, NC, USA, 26–30 April 2010; ACM Press: New York, NY, USA, 2010. [Google Scholar]
- Kong, S.; Feng, L.; Sun, G.; Luo, K. Predicting lifespans of popular tweets in microblog. In Proceedings of the Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR ’12, Portland, OR, USA, 12–16 August 2012; ACM Press: New York, NY, USA, 2012. [Google Scholar]
- Li, Y.; Li, R.; Yu, M. A distributed content placement strategy based on popularity for ICN. In Proceedings of the 2019 IEEE International Conference on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Xiamen, China, 16–18 December 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Laoutaris, N.; Che, H.; Stavrakakis, I. The LCD interconnection of LRU caches and its analysis. Perform. Eval. 2006, 63, 609–634. [Google Scholar] [CrossRef]
- Dabirmoghaddam, A.; Barijough, M.M.; Garcia-Luna-Aceves, J.J. Understanding optimal caching and opportunistic caching at “the edge” of information-centric networks. In Proceedings of the 1st International Conference on Information-Centric Networking—INC ’14, Paris, France, 24–26 September 2014; ACM Press: New York, NY, USA, 2014. [Google Scholar]
- Suksomboon, K.; Tarnoi, S.; Ji, Y.; Koibuchi, M.; Fukuda, K.; Abe, S.; Motonori, N.; Aoki, M.; Urushidani, S.; Yamada, S. PopCache: Cache more or less based on content popularity for information-centric networking. In Proceedings of the 38th Annual IEEE Conference on Local Computer Networks, Sydney, NSW, Australia, 21–24 October 2013; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Arianfar, S.; Nikander, P.; Ott, J. On content-centric router design and implications. In Proceedings of the Re-Architecting the Internet Workshop on—ReARCH ’10, Philadelphia, PA, USA, 30 November 2010; ACM Press: New York, NY, USA, 2010. [Google Scholar]
- Psaras, I.; Chai, W.K.; Pavlou, G. In-network cache management and resource allocation for information-centric networks. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 2920–2931. [Google Scholar] [CrossRef]
- Naeem, N.; Hassan, K. Compound popular content caching strategy in named data networking. Electronics 2019, 8, 771. [Google Scholar] [CrossRef] [Green Version]
- Gui, Y.; Chen, Y. A cache placement strategy based on compound popularity in named data networking. IEEE Access 2020, 8, 196002–196012. [Google Scholar] [CrossRef]
- Naeem, M.A.; Ali, R.; Alazab, M.; Meng, Y.; Zikria, Y.B. Enabling the content dissemination through caching in the state-of-the-art sustainable information and communication technologies. Sustain. Cities Soc. 2020, 61, 102291. [Google Scholar] [CrossRef]
- Meng, Y.; Naeem, M.A.; Ali, R.; Kim, B.-S. EHCP: An efficient hybrid content placement strategy in named data network caching. IEEE Access 2019, 7, 155601–155611. [Google Scholar] [CrossRef]
- Naeem, M.; Ali, R.; Kim, B.-S.; Nor, S.; Hassan, S. A periodic caching strategy solution for the smart city in Information-centric Internet of Things. Sustainability 2018, 10, 2576. [Google Scholar] [CrossRef] [Green Version]
- Dan, A.; Towsley, D. An approximate analysis of the LRU and FIFO buffer replacement schemes. In Proceedings of the 1990 ACM SIGMETRICS Conference on Measurement and Modeling of Computer Systems—SIGMETRICS ’90, Boulder, CO, USA, 22–25 May 1990; ACM Press: New York, NY, USA, 1990. [Google Scholar]
- Lee, D.; Choi, J.; Kim, J.-H.; Noh, S.H.; Min, S.L.; Cho, Y.; Kim, C.S. On the existence of a spectrum of policies that subsumes the least recently used (LRU) and least frequently used (LFU) policies. In Proceedings of the 1999 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems—SIGMETRICS ’99, Atlanta, GA, USA, 1–4 May 1999; ACM Press: New York, NY, USA, 1999. [Google Scholar]
- Hasslinger, G.; Heikkinen, J.; Ntougias, K.; Hasslinger, F.; Hohlfeld, O. Optimum caching versus LRU and LFU: Comparison and combined limited look-ahead strategies. In Proceedings of the 2018 16th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt), Shanghai, China, 7–11 May 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Laoutaris, N.; Syntila, S.; Stavrakakis, I. Meta algorithms for hierarchical Web caches. In Proceedings of the IEEE International Conference on Performance, Computing, and Communications, Phoenix, AZ, USA, 15–17 April 2004; IEEE: Piscataway, NJ, USA, 2005. [Google Scholar]
- Zhou, X.; Ye, Z. Popularity and age based cache scheme for content-centric network. In Proceedings of the 2017 3rd International Conference on Information Management (ICIM), Chengdu, China, 21–23 April 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Wang, Q.; Zhu, X.; Ni, Y.; Gu, L.; Zhao, H.; Zhu, H. A new content popularity probability based cache placement and replacement plan in CCN. In Proceedings of the 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi’an, China, 16–19 October 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Ns-3 | A Discrete-Event Network Simulator for Internet Systems. Available online: https://www.nsnam.org/ (accessed on 15 October 2014).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Y-Axis Parameters | X-Axis Parameters | ||||
|---|---|---|---|---|---|
| Average Hop Count | Size of the Cache Repository per Server | 10~150 (MB) | |||
| Cache Hit Ratio | Max Number of Forms of Content a Client can Request | 10~90 | |||
| Content Delivery Time | Max Number of Clients Attached per Server | 5~50 | |||
| Total Resources | Schemes Compared | ||||
| Nodes and Content | Caching | Removal | |||
| Servers | 20 | CPR-Based | |||
| Clients | 100 | LCE | |||
| Content | 150 | LCD | |||
| Network Architectures | |||||
| Host-based Internet Architecture | Basic CCN with Compared Schemes | CCN with Proposed CPR-based Schemes | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nasir, N.A.; Jeong, S.-H. Content Management Based on Content Popularity Ranking in Information-Centric Networks. Appl. Sci. 2021, 11, 6088. https://doi.org/10.3390/app11136088
Nasir NA, Jeong S-H. Content Management Based on Content Popularity Ranking in Information-Centric Networks. Applied Sciences. 2021; 11(13):6088. https://doi.org/10.3390/app11136088
Chicago/Turabian StyleNasir, Nazib Abdun, and Seong-Ho Jeong. 2021. "Content Management Based on Content Popularity Ranking in Information-Centric Networks" Applied Sciences 11, no. 13: 6088. https://doi.org/10.3390/app11136088
APA StyleNasir, N. A., & Jeong, S.-H. (2021). Content Management Based on Content Popularity Ranking in Information-Centric Networks. Applied Sciences, 11(13), 6088. https://doi.org/10.3390/app11136088