
COVID-19 Vaccination Awareness and Aftermath: Public Sentiment Analysis on Twitter Data and Vaccinated Population Prediction in the USA


Abstract
:1. Introduction
- We performed sentiment analysis to have an overview of people’s opinion regarding the COVID-19 vaccination.
- −
- We analyzed the tweets on seven different types of COVID-19 vaccine and find public sentiments. This analysis is useful to figure out whether people are reluctant to vaccinate considering the side effects of some of the vaccines. In addition, this response indicates people’s interest and showing willingness to take vaccines in response to the vaccination campaign.
- −
- We collected tweets mentioning vaccination with different terms related to health guidelines. Public sentiment on these tweets help us learn people’s opinion on how they are following the health guidelines after getting vaccinated.
- We performed a time series forecasting on the vaccination scenario of the USA and predict the percentage of population that will be vaccinated by a certain timeline.
2. Related Works
3. Preliminaries
3.1. Sentiment Analysis
- Supervised machine learning or deep learning approaches.
- Unsupervised lexicon-based approaches.
3.1.1. TextBlob
3.1.2. VADER
3.2. Time Series Forecasting
3.2.1. Performance Metrics
- Mean Absolute Percentage Error (MAPE): The Mean Squared Error (MSE) is the average of the square of the forecast error. As the square of the errors are taken, the effect is that larger errors have more weight on the score. In this case, MAPE comes in handy where the data are not understood from the error measure itself. As MAPE is a percentage error, it gives a good idea of the relative error. MAPE is the most widely used unit-free measure.
- Direction accuracy: DAC is a measure of prediction accuracy of a forecasting method in statistics. It compares the forecast direction (upward or downward) to the actual realized direction. DAC is similar to a binary evaluation. The metric only considers the upward or downward direction in the time series and is independent of the quantitive value of the increase or decrease. DAC provides the probability that the forecasting method can detect the correct direction of the time series [41].
- Relative Absolute Error (RAE): Relative measures give an indication of how well the forecaster’s predictions are doing compared to just using the last known target value as the prediction. For RAE, the comparison is done with respect to absolute error with the last known target. RAE takes the total absolute error and normalizes it by dividing by the total absolute error of the simple predictor (i.e., the last known target).
- Root Relative Squared Error (RRSE): RRSE is similar to RAE. The difference is that RRSE takes the square root of the total squared error and normalizes it by dividing by the square root of the total squared error of the simple predictor (i.e., the last known target).
- Root Mean Squared Error (RMSE): MSE is more vulnerable to outliers since it gives extra weight to large errors. In addition, the squared errors are on different scale from the original data. Thus, RMSE, which is the square root of MSE, is often preferred to MSE as it is on the same scale as the data. However, RMSE is also sensitive to forecasting outliers. Researchers now seem to prefer unit-free measures for comparing methods [42,43].
3.2.2. Machine Learning Algorithms
- Support Vector Machine (SVM) for regression: The ability of SVM to solve nonlinear regression estimation problems makes SVM successful in time series forecasting. SVM regression acknowledges the presence of non-linearity in the data and provides a proficient prediction model. In the SVM regression method, the sequential minimal optimization algorithm from Alex Smola and Bernhard Scholkopf [44] is used. The utilization helps to replace all the missing values and transform the nominal attributes to binary values. It also helps to normalize the attributes by default values.
- k-Nearest Neighbor (KNN): KNN works by storing the entire training dataset and querying it to locate the k most similar training patterns when making a prediction. KNN regression calculates the average of the numerical target of the K nearest neighbors [45]. KNN regression uses the same distance functions as KNN classification. KNN is better than LR when the data have less noise. KNN requires much less hyperparameter tuning compared to MLP.
- Linear Regression (LR): Linear regression is a statistic approach to model the correlations between the scalar dependent variable Y and single or several explanatory variables denoted x. In this regression approach, linear predictor functions are used to model the correlations and the unknown parameters of the functions are evaluated by the data [46]. Decision trees support non-linearity, whereas LR only supports linear solutions.
- Random Forest (RF): RF regression contains several decision trees and targets the class that is the mode of the classes’ target by individual trees. The number of trees to be grown in the forest and the quantity of features or variables chosen at every node to develop a tree are the two standard parameters [47].
- M5 model tree: M5 tree is a decision tree learner for regression problems. The M5 algorithm assigns linear regression functions at the terminal nodes and fits a multivariate linear regression model to each subspace by classifying or dividing the whole data space into several subspaces. The M5 tree method deals with continuous class problems instead of discrete classes and can handle tasks with very high dimensions. It reveals piece-wise information of each linear model constructed to approximate nonlinear relationships of the dataset [48].
- Gaussian process for regression: The Gaussian algorithm is a very useful tool in non-linear multiple variate interpolation. It belongs to a kind of statistical framework in which observations happen in the continuous domain. During the process, each point of a certain continuous inputting space is related to the generally distributed random variable [49].
- Multilayer Perceptron (MLP): MLP is also known as Artificial Neural Networks (ANN). Neural networks are a complex algorithm to use for predictive modeling. This algorithm is inspired by a model of biological neural networks in the brain where small processing units called neurons are organized into layers that if configured well are capable of approximating any function. In regression problems, the interest lies in approximating a function that best fits the real value output [40]. MLP needs large training data compared to LR model and becomes slow due to its complex structure.
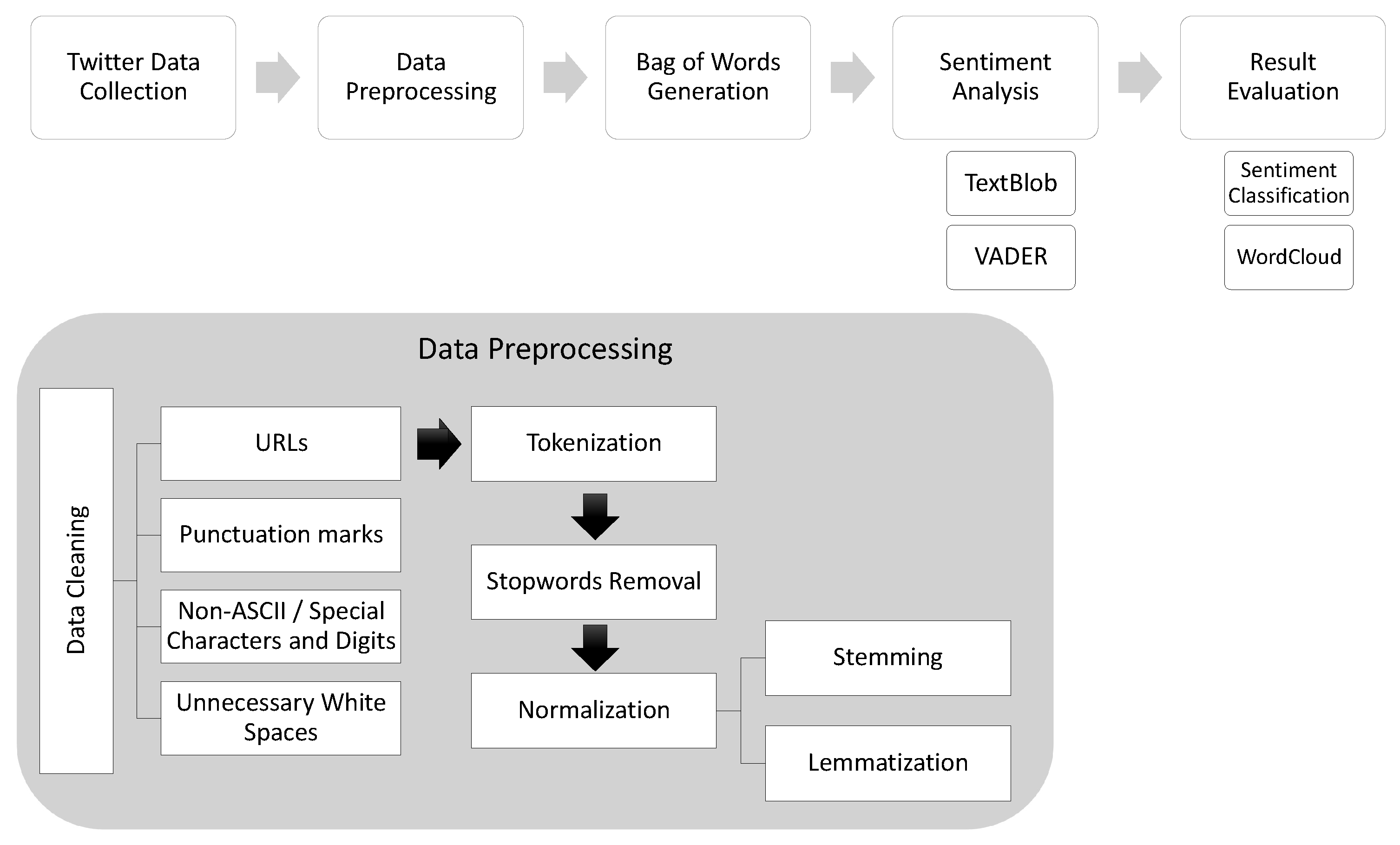
4. Methodology
4.1. Computational Tools/Libraries
4.2. Environment
4.3. Sentiment Analysis
4.3.1. Twitter Data Collection
- Twitter Dataset 1: The first dataset has all the tweets related to different vaccines. In Table 2, we show the total number of tweets collected for each of the vaccines. We also list the keywords that we used to scrap those tweets. We also mention the unique number of tweets based on different pre-processing steps of the Twitter data done before the sentiment analysis.
- Twitter Dataset 2: We selected five topics related to maintaining safety/precautions in response to COVID-19 pandemic. We selected the precautionary actions for individuals that help reduce virus transmission during pandemics including social distancing, wearing face masks, hand hygiene, and restricting interpersonal contact to outdoor settings [11]. Additionally, we added another topic related to “travel” that was very restricted during the pandemic. For Twitter Dataset 2, we aimed to collect those tweets that have been shared by vaccinated people about their lifestyle after getting vaccines. Thus, we used the keywords [vaccine, vaccination, vaccinated, shot, fully vaccinated, first dose, second dose, 1st dose, 2nd dose] to scrap those tweets along with the keywords for particular topics, as listed in Table 3.
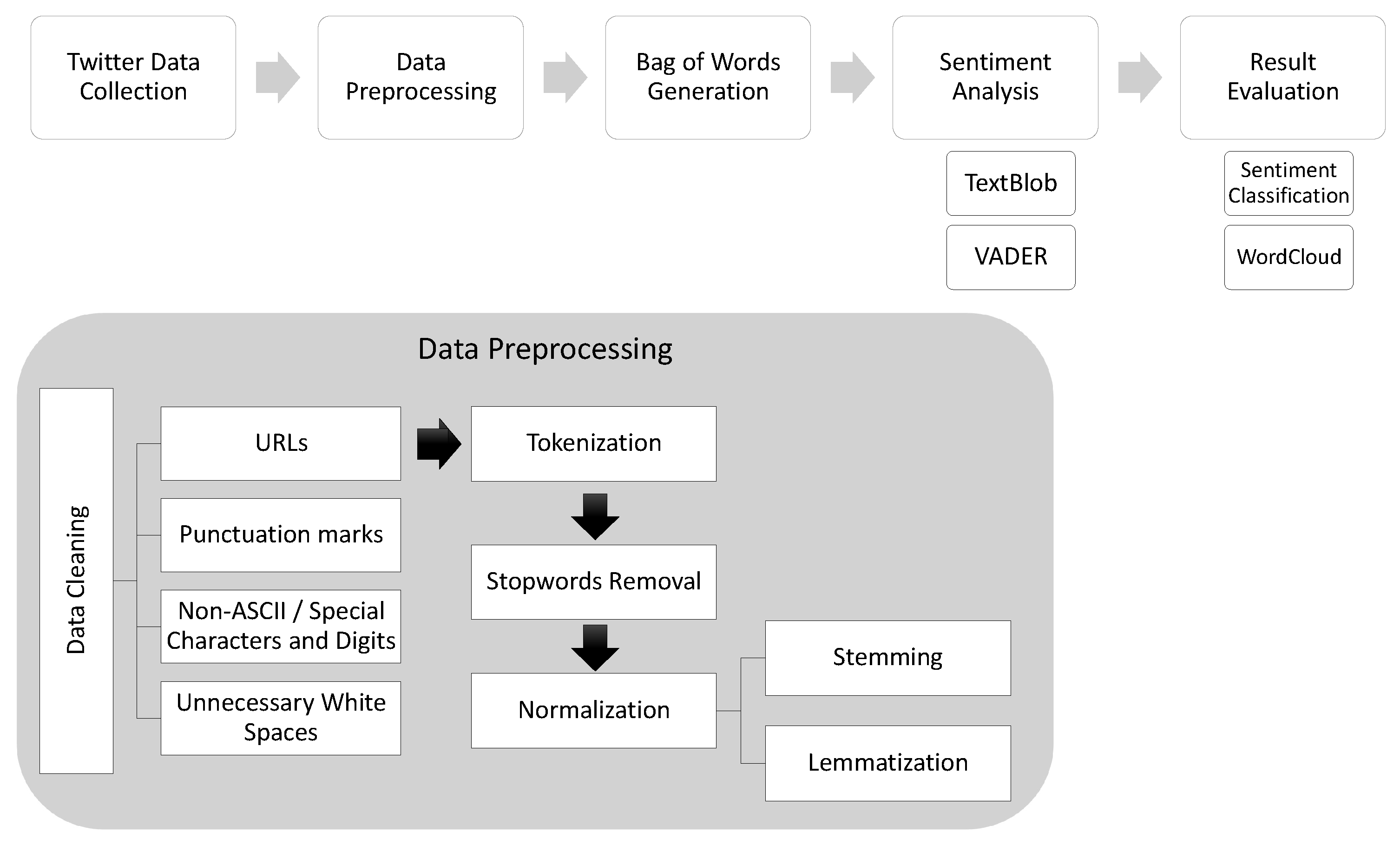
4.3.2. Pre-Processing of Data
- Data Cleaning: We removed the urls, punctuation marks, and special characters in this step.
- Tokenization: Text is divided into words (the smallest unit) in this step.
- Stopwords Removal: Some words such as “and”, “but”, “so”, and others are frequently used in the text but are not useful in the analysis. We do not use the predefined stopwords from any libraries because “not” or similar negative words, if removed, would change the sentiment of the sentence completely. Thus, we used our own list of stopwords that we made by modifying the most comprehensive collection of stopwords for the English language [56,57]. We removed all negative words from this mentioned list so that it does not impact sentiment analysis.
- Data Normalization:
- −
- Stemming: In this step, we normalized the words by truncating the words to their stem words. We used Porter Stemmer from the NLTK library.
- −
- Lemmatization: Next, we lemmatized words to get the root words according to the part of speech.
4.3.3. Sentiment Categorization
4.4. Forecasting Model for COVID-19 Vaccination in the USA
4.4.1. Vaccination Dataset
4.4.2. Feature Selection
4.4.3. Time Series Forecasting Classifier
- Forecast Time Unit: We used two different time units, for the prediction of Fully Vaccinated Population. The shorter time period is 1 week (7 days) and the longer time period is 2 months (60 days). By definition, parameter values of 7 days indicate that we are setting up our system to forecast 7 days ahead from the last date of the input training dataset. For the prediction of partially vaccinated population, along with these two units, we also predict a middle timeline, that is 39 days, to get the prediction for 4 July, the Independence Day of the USA.
- Time stamp: We have a “Date” attribute in our dataset. Date was set for the “Time Stamp” parameter of our system.
- Periodicity: Periodicity allows the user to specify the periodicity of the data. As we predicted the vaccinated population on a daily basis, we chose “Daily” for this parameter value.
- Skip list: For daily forecasting, it might happen that the entity remains closed on certain days or holidays, for example, businesses, the stock market, etc. For such entities, these time periods do not count. In such cases, “Skip list” is used to supply these types of time periods that are not to be considered. For our dataset, we do not have any such time period for which the regular operation does not continue. Thus, we do not need to set the “Skip List” parameter.
- Confidence intervals: This parameter is used for the system to compute confidence bounds on the predictions that it makes. We used as the parameter value, which is also the default value of the parameter. The confidence level means that of the true target values fell within the interval. The confidence intervals were computed for each step-ahead level independently.
4.4.4. Selection of ML Algorithms
5. Experimental Evaluation
5.1. Public Sentiment on Vaccination
5.1.1. Vaccination Tweets by Location
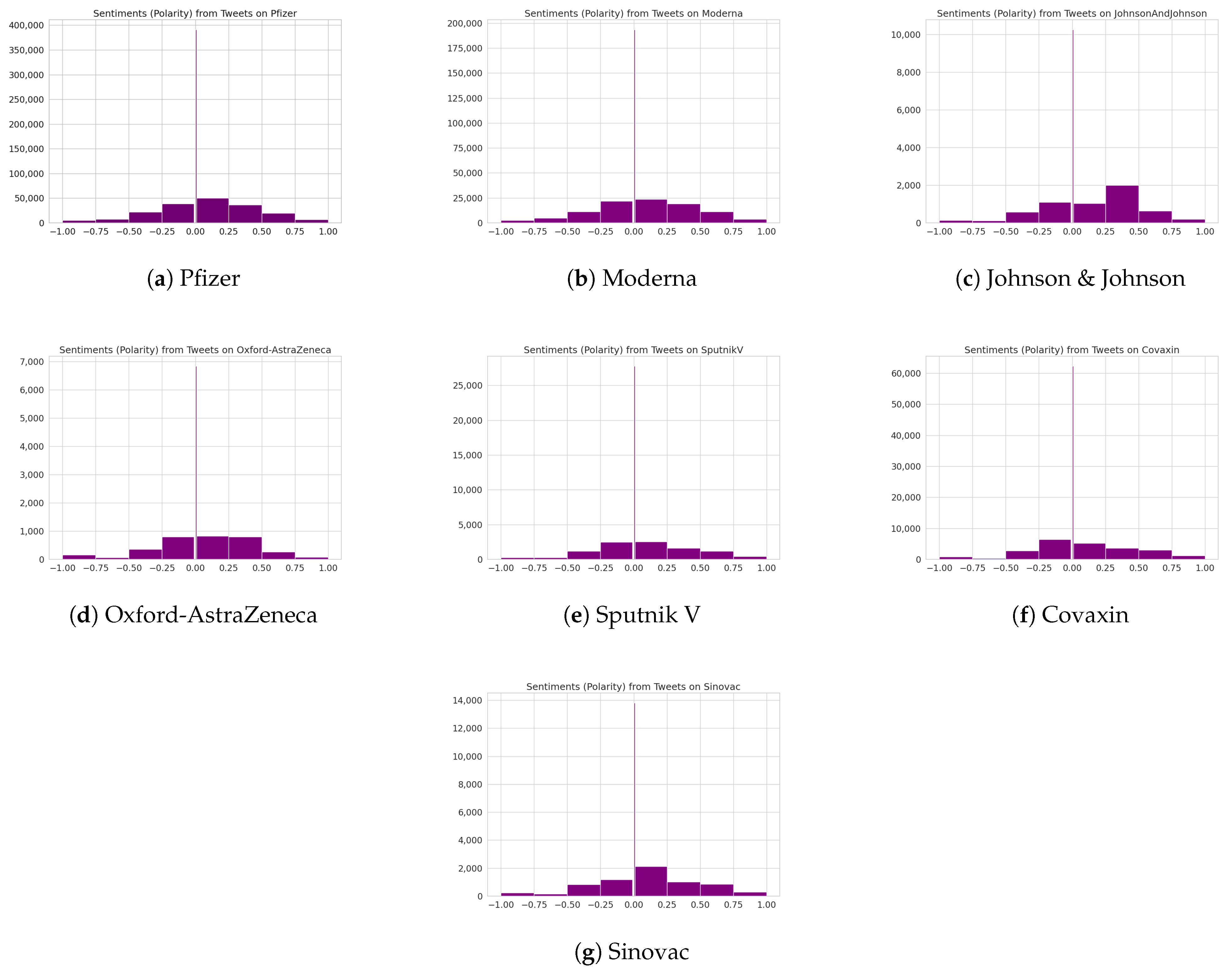
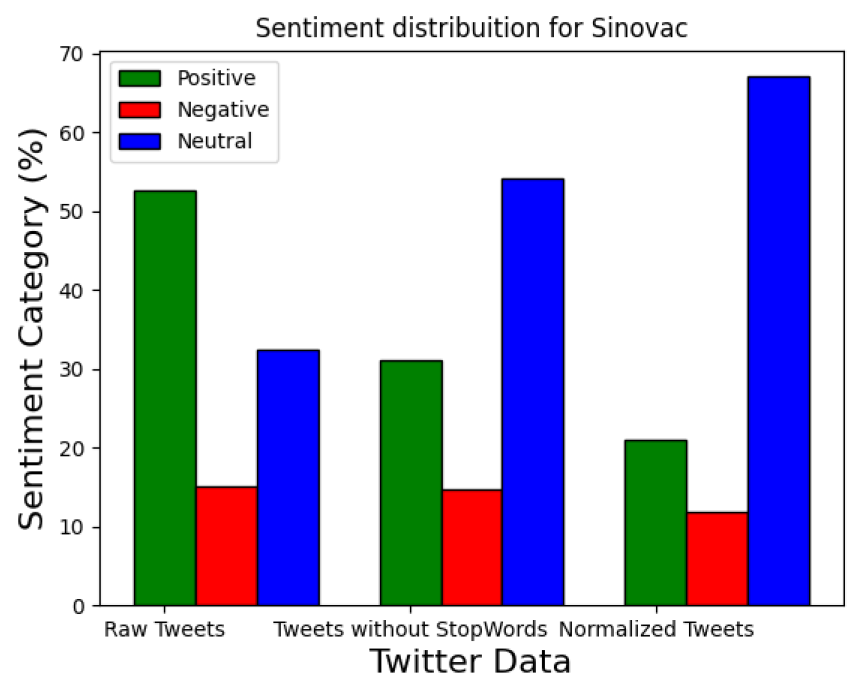
5.1.2. Sentiment Distribution for Vaccination Tweets
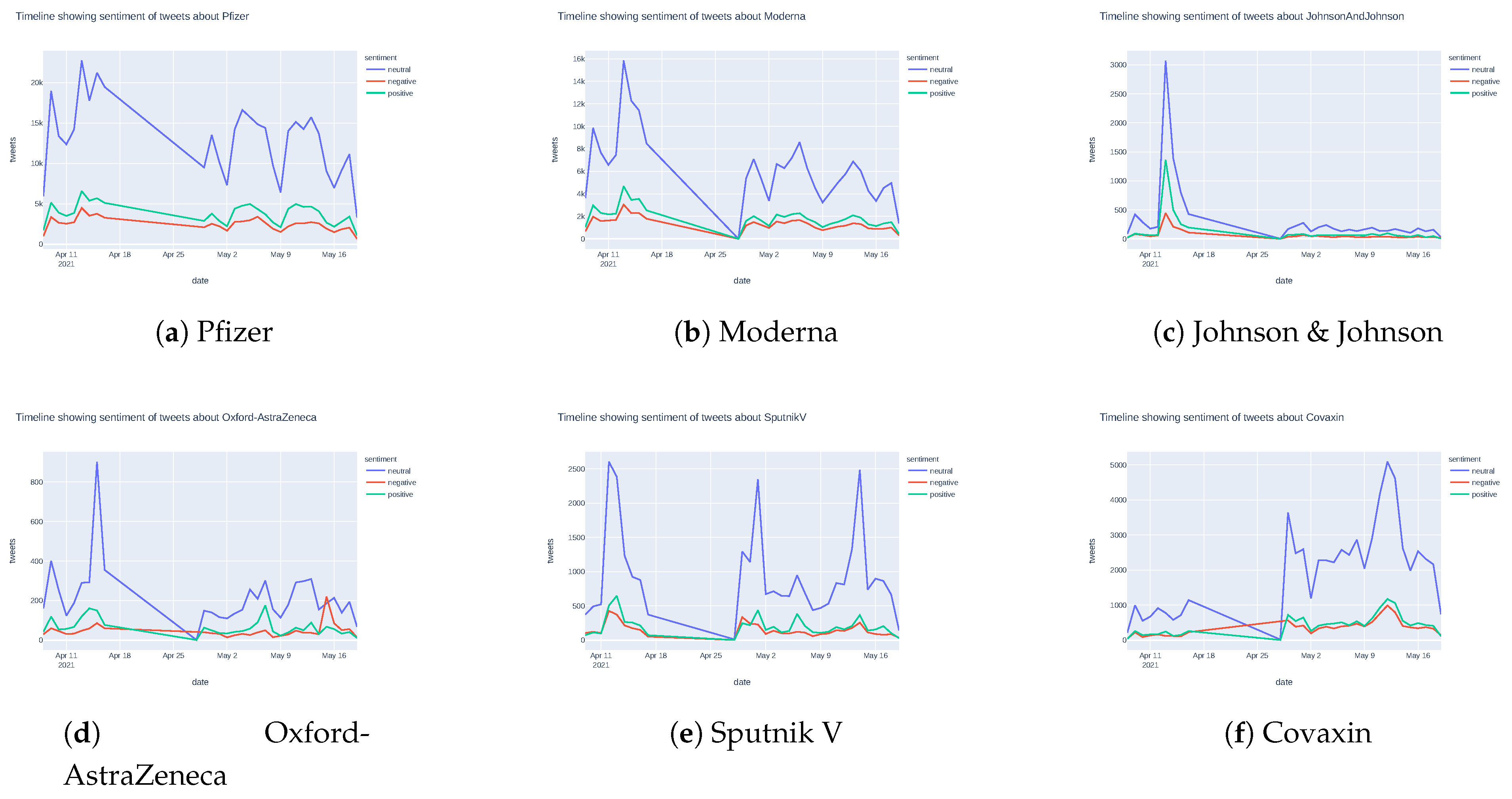
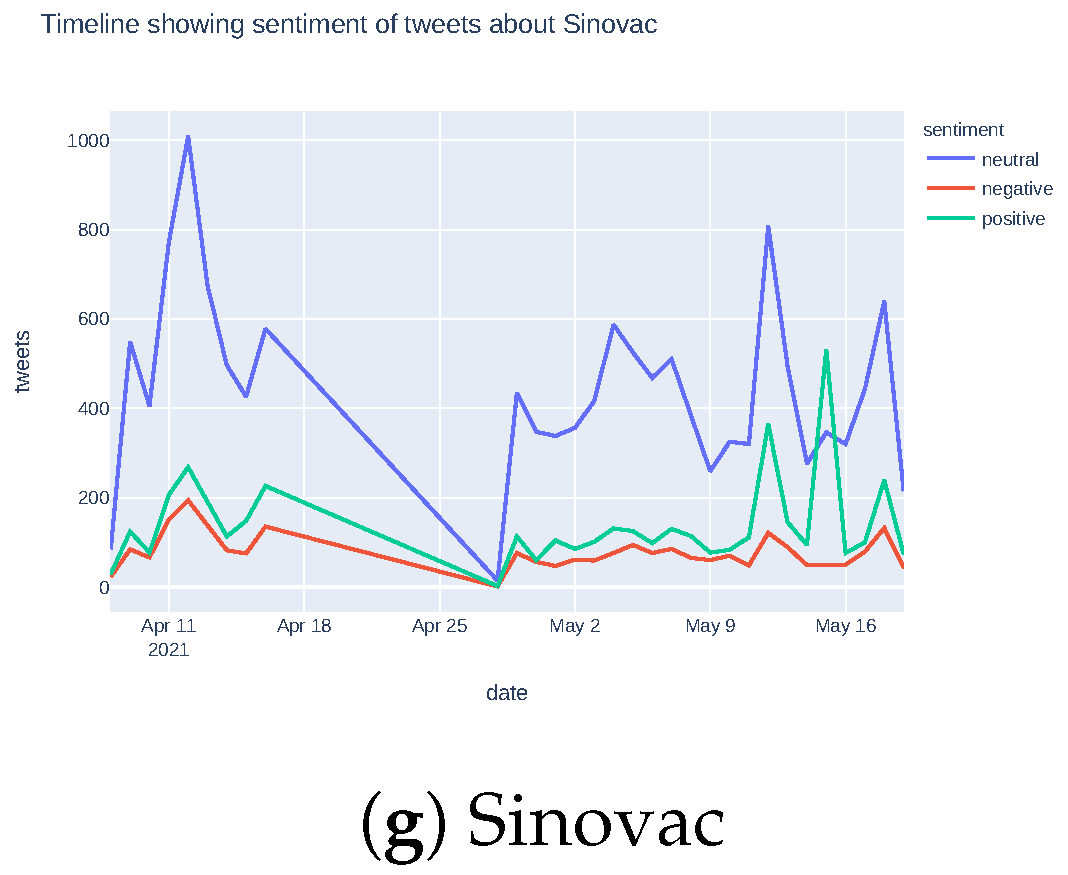
5.1.3. Sentiment Timeline for Vaccination Tweets
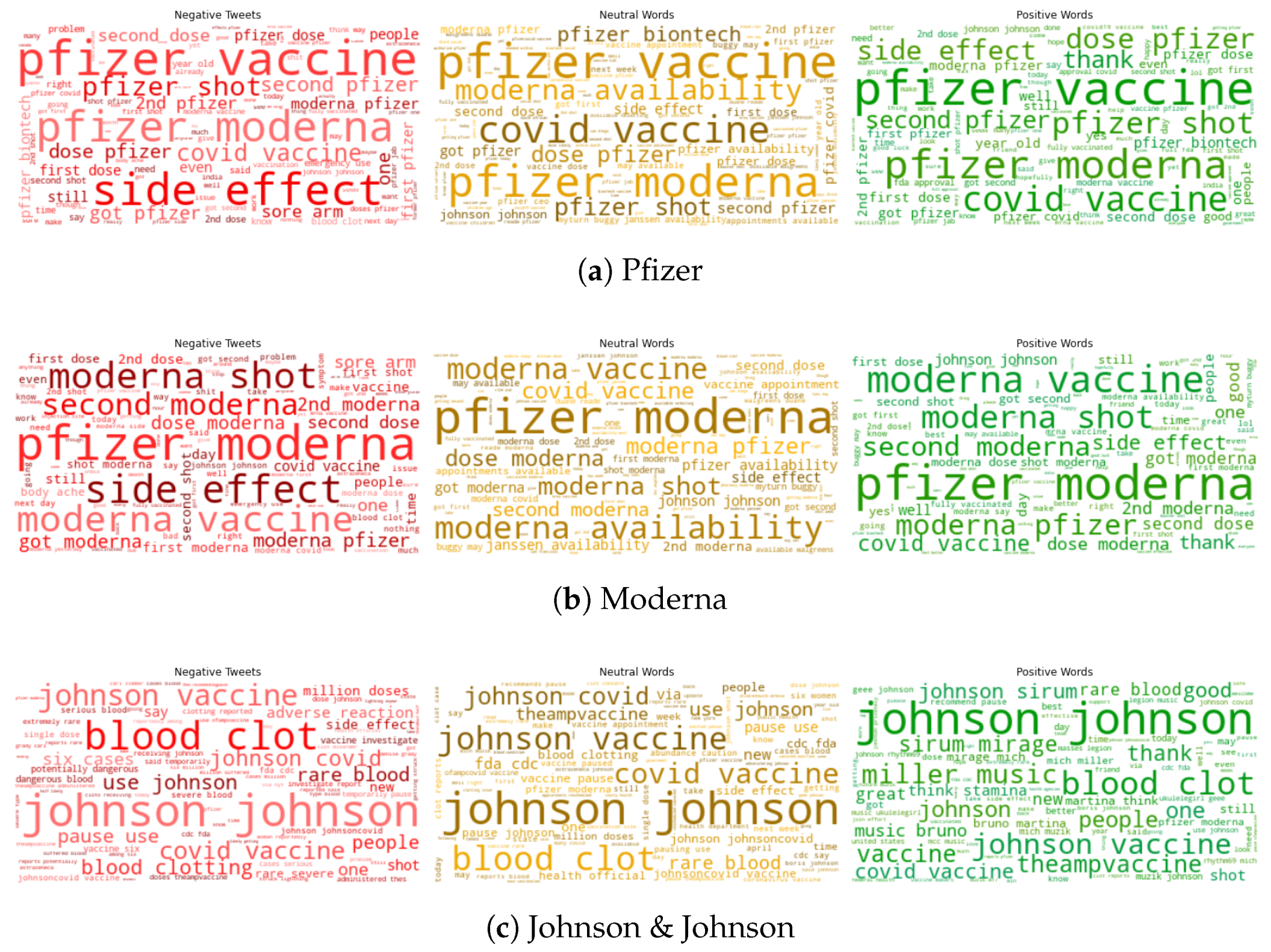
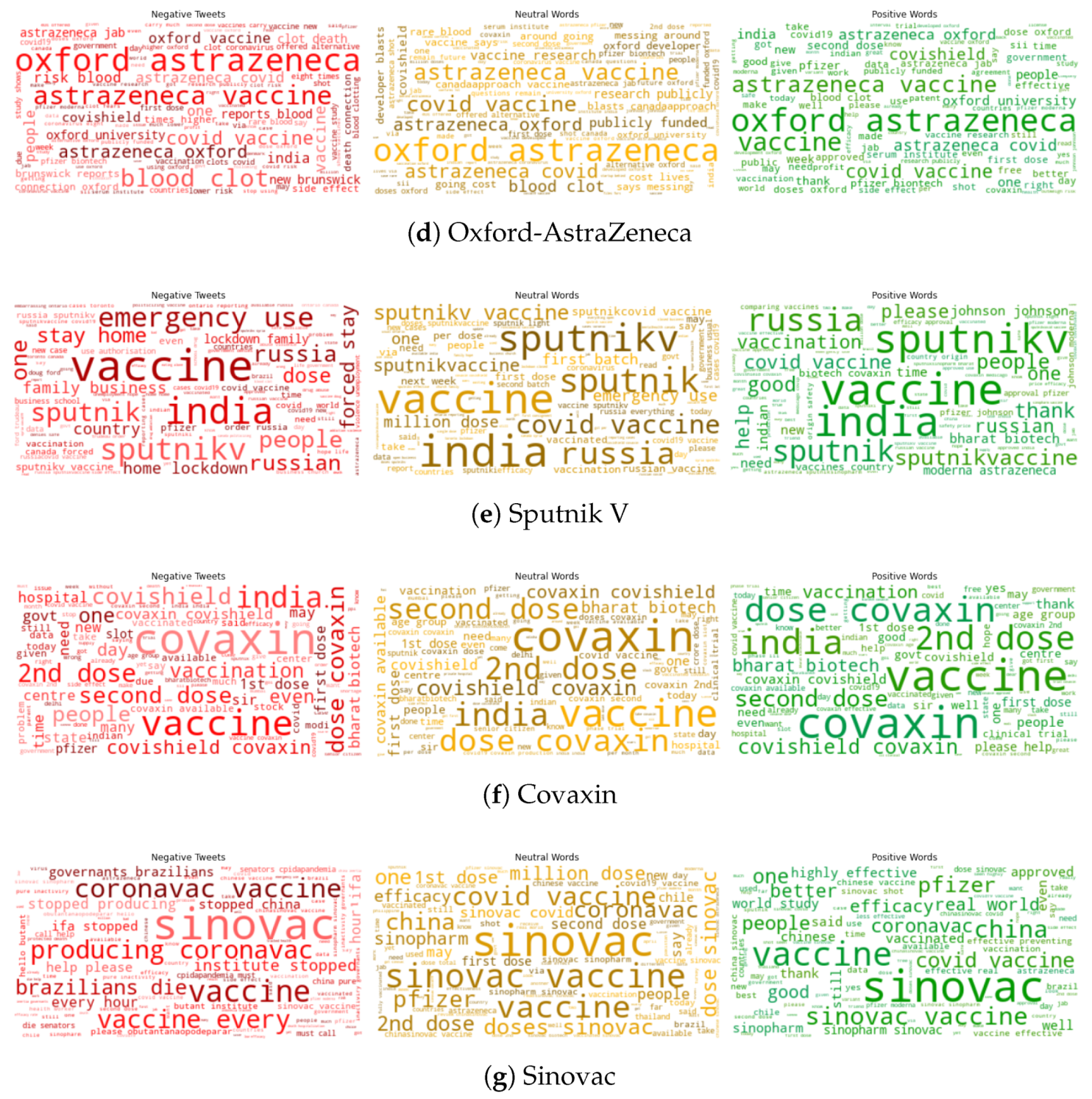
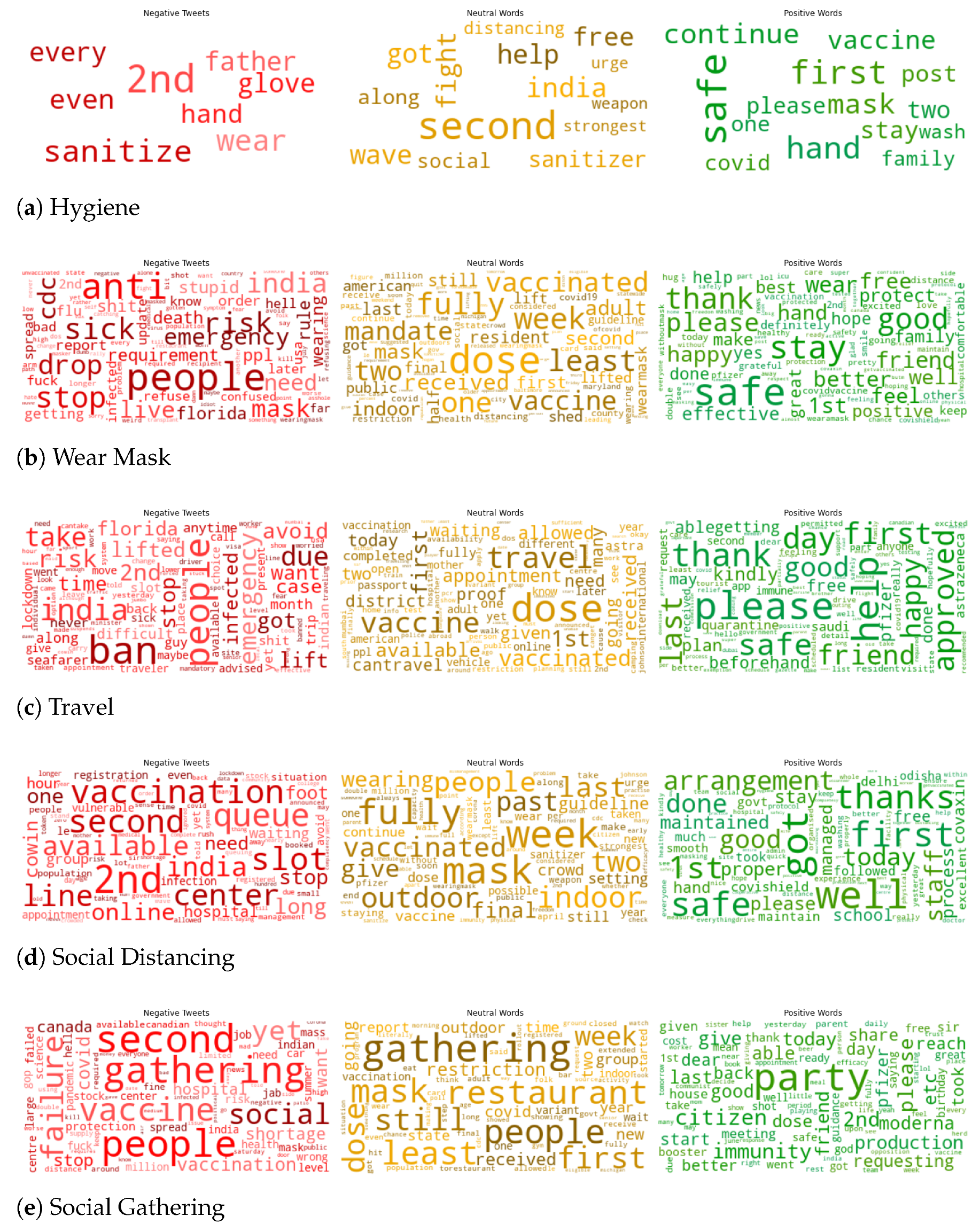
5.1.4. Top Frequency Words (Positive, Negative, Neutral) for Vaccination Tweets
5.2. Public Sentiment on Healthy Lifestyle after Vaccination
5.2.1. Post-Vaccination Tweets on Healthy Lifestyle by Location
5.2.2. Sentiment Distribution for Post-Vaccination Tweets on Healthy Lifestyle
5.2.3. Sentiment Timeline for Vaccination Tweets
5.2.4. Top Frequency Words (Positive, Negative, Neutral) for Post-Vaccination Tweets on Healthy Lifestyle
5.3. COVID-19 Vaccination Forecast for the USA
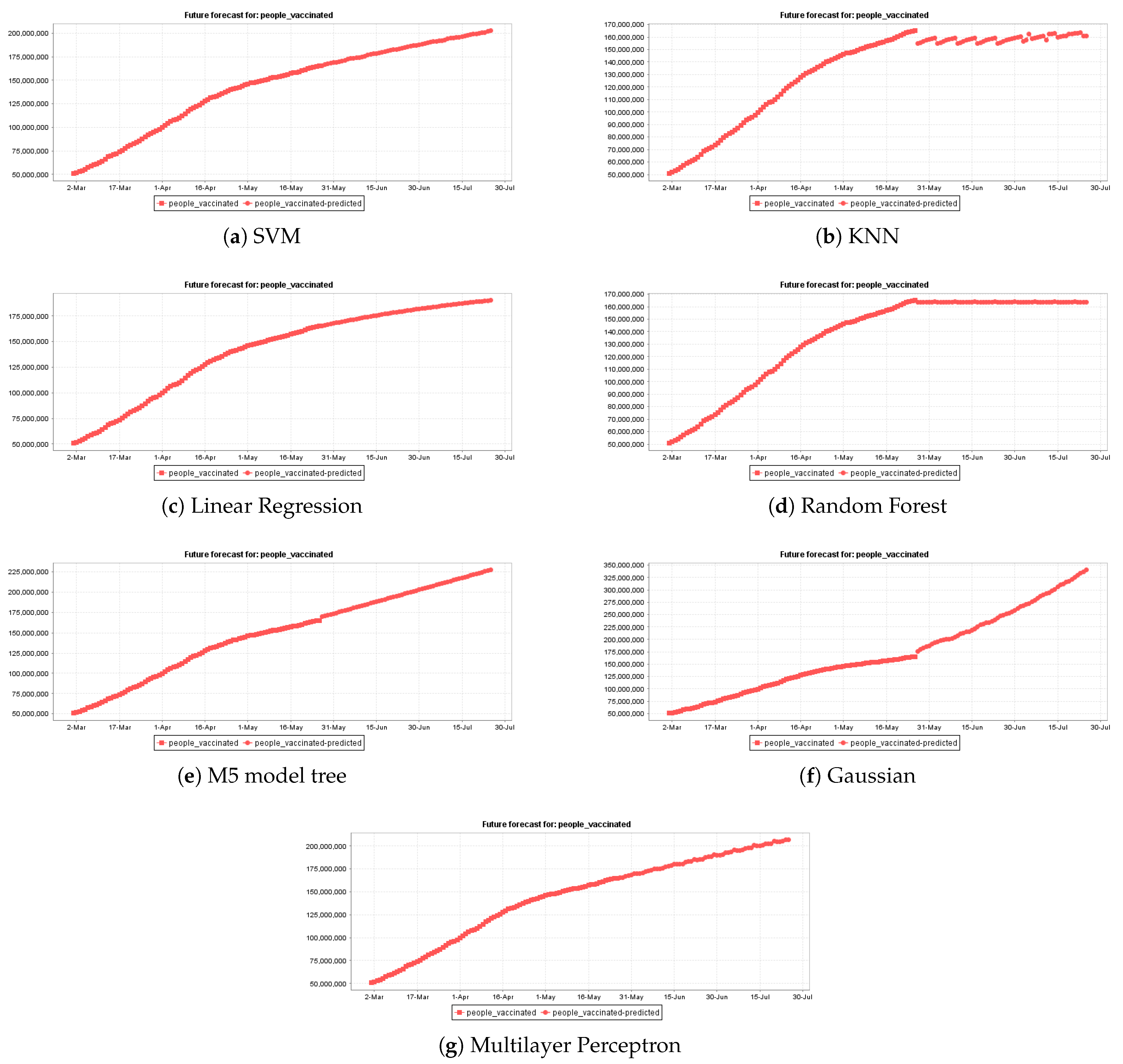
5.3.1. Fully Vaccinated Population Prediction
5.3.2. Partially Vaccinated Population Prediction
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| CDC | Centers for Disease Control and Prevention |
| NLP | Natural Language Processing |
| NLTK | Natural Language Toolkit |
| VADER | Valence Aware Dictionary for Sentiment Reasoning |
| WEKA | Waikato Environment for Knowledge Analysis |
| SVM | Support Vector Machine |
| KNN | k-Nearest Neighbor |
| LR | Linear Regression |
| RF | Random Forest |
| MLP | Multilayer Perceptron |
Appendix A. Sentiment Analysis for Different Vaccines


Appendix B. Sentiment Analysis on Maintaining Healthy Lifestyle after Vaccination



Appendix C. COVID-19 Vaccination Forecast in the USA

References
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Patel, R.; Passi, K. Sentiment Analysis on Twitter Data of World Cup Soccer Tournament Using Machine Learning. IoT 2020, 1, 218–239. [Google Scholar] [CrossRef]
- Dandannavar, P.; Mangalwede, S.; Deshpande, S. Emoticons and their effects on sentiment analysis of Twitter data. In EAI International Conference on Big Data Innovation for Sustainable Cognitive Computing; Springer: Berlin/Heidelberg, Germany, 2020; pp. 191–201. [Google Scholar]
- Naseem, U.; Razzak, I.; Khushi, M.; Eklund, P.W.; Kim, J. COVIDSenti: A Large-Scale Benchmark Twitter Data Set for COVID-19 Sentiment Analysis. IEEE Trans. Comput. Soc. Syst. 2021. [Google Scholar] [CrossRef]
- Sattar, N.S.; Arifuzzaman, S.; Zibran, M.F.; Sakib, M.M. Detecting web spam in webgraphs with predictive model analysis. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 4299–4308. [Google Scholar]
- Facebook Reports Fourth Quarter and Full Year 2020 Results. Available online: https://investor.fb.com/investor-news/pressrelease-details/2021/Facebook-Reports-Fourth-Quarter\-and-Full-Year-2020-Results/default.aspx (accessed on 1 June 2021).
- Twitter Revenue and Usage Statistics (2021). Available online: https://www.businessofapps.com/data/twitter-statistics/ (accessed on 1 June 2021).
- Boldog, P.; Tekeli, T.; Vizi, Z.; Dénes, A.; Bartha, F.A.; Röst, G. Risk assessment of novel coronavirus COVID-19 outbreaks outside China. J. Clin. Med. 2020, 9, 571. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- WHO Director-General’s Opening Remarks at the Media Briefing on COVID-19. 11 March 2020. Available online: https://www.who.int/director-general/speeches/detail/who-director-general-s-opening-remarks-at-the\-media-briefingon-covid-19---11-march-2020 (accessed on 1 June 2021).
- Roser, M.; Ritchie, H.; Ortiz-Ospina, E.; Hasell, J. Coronavirus pandemic (COVID-19). In Our World in Data; 2020; Available online: https://ourworldindata.org/coronavirus (accessed on 6 June 2021).
- Mathieu, E.; Ritchie, H.; Ortiz-Ospina, E.; Roser, M.; Hasell, J.; Appel, C.; Giattino, C.; Rodés-Guirao, L. A global database of COVID-19 vaccinations. Nat. Hum. Behav. 2021, 1–7. [Google Scholar]
- Glowacki, E.M.; Wilcox, G.B.; Glowacki, J.B. Identifying# addiction concerns on twitter during the COVID-19 pandemic: A text mining analysis. Subst. Abus. 2020, 42, 39–46. [Google Scholar]
- Sanders, A.C.; White, R.C.; Severson, L.S.; Ma, R.; McQueen, R.; Paulo, H.C.A.; Zhang, Y.; Erickson, J.S.; Bennett, K.P. Unmasking the conversation on masks: Natural language processing for topical sentiment analysis of COVID-19 Twitter discourse. medRxiv 2021. [Google Scholar] [CrossRef]
- Pano, T.; Kashef, R. A Complete VADER-Based Sentiment Analysis of Bitcoin (BTC) Tweets during the Era of COVID-19. Big Data Cogn. Comput. 2020, 4, 33. [Google Scholar] [CrossRef]
- Bhagat, K.K.; Mishra, S.; Dixit, A.; Chang, C.Y. Public Opinions about Online Learning during COVID-19: A Sentiment Analysis Approach. Sustainability 2021, 13, 3346. [Google Scholar] [CrossRef]
- Villavicencio, C.; Macrohon, J.J.; Inbaraj, X.A.; Jeng, J.H.; Hsieh, J.G. Twitter Sentiment Analysis towards COVID-19 Vaccines in the Philippines Using Naïve Bayes. Information 2021, 12, 204. [Google Scholar] [CrossRef]
- Chaudhri, A.A.; Saranya, S.; Dubey, S. Implementation Paper on Analyzing COVID-19 Vaccines on Twitter Dataset Using Tweepy and Text Blob. Ann. Rom. Soc. Cell Biol. 2021, 25, 8393–8396. [Google Scholar]
- Xue, J.; Chen, J.; Hu, R.; Chen, C.; Zheng, C.; Liu, X.; Zhu, T. Twitter discussions and emotions about covid-19 pandemic: A machine learning approach (2020). arXiv 2020, arXiv:2005.12830. [Google Scholar]
- Chen, T.; Dredze, M. Vaccine images on twitter: Analysis of what images are shared. J. Med. Internet Res. 2018, 20, e130. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Cao, L.J.; Tay, F.E.H. Support vector machine with adaptive parameters in financial time series forecasting. IEEE Trans. Neural Netw. 2003, 14, 1506–1518. [Google Scholar] [CrossRef] [Green Version]
- Rafiuzaman, M. Forecasting chaotic stock market data using time series data mining. Int. J. Comput. Appl. 2014, 101, 27–34. [Google Scholar] [CrossRef]
- Ray, E.L.; Wattanachit, N.; Niemi, J.; Kanji, A.H.; House, K.; Cramer, E.Y.; Bracher, J.; Zheng, A.; Yamana, T.K.; Xiong, X.; et al. Ensemble Forecasts of Coronavirus Disease 2019 (COVID-19) in the us. MedRXiv 2020. [Google Scholar] [CrossRef]
- Liapis, C.M.; Karanikola, A.; Kotsiantis, S. An ensemble forecasting method using univariate time series COVID-19 data. In Proceedings of the 24th Pan-Hellenic Conference on Informatics, Athens, Greece, 20–22 November 2020; pp. 50–52. [Google Scholar]
- Krollner, B.; Vanstone, B.J.; Finnie, G.R. Financial time series forecasting with machine learning techniques: A survey. In Proceedings of the ESANN, Bruges, Belgium, 28–30 April 2010. [Google Scholar]
- Zhang, N.; Lin, A.; Shang, P. Multidimensional k-nearest neighbor model based on EEMD for financial time series forecasting. Phys. A Stat. Mech. Appl. 2017, 477, 161–173. [Google Scholar] [CrossRef]
- Bandara, K.; Shi, P.; Bergmeir, C.; Hewamalage, H.; Tran, Q.; Seaman, B. Sales demand forecast in e-commerce using a long short-term memory neural network methodology. In Proceedings of the International Conference on Neural Information Processing, Sydney, NSW, Australia, 12–15 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 462–474. [Google Scholar]
- Pavlyshenko, B.M. Machine-learning models for sales time series forecasting. Data 2019, 4, 15. [Google Scholar] [CrossRef] [Green Version]
- Papacharalampous, G.; Tyralis, H.; Koutsoyiannis, D. Univariate time series forecasting of temperature and precipitation with a focus on machine learning algorithms: A multiple-case study from Greece. Water Resour. Manag. 2018, 32, 5207–5239. [Google Scholar] [CrossRef]
- Medar, R.; Angadi, A.B.; Niranjan, P.Y.; Tamase, P. Comparative study of different weather forecasting models. In Proceedings of the 2017 International Conference on Energy, Communication, Data Analytics and Soft Computing (ICECDS), Chennai, India, 1–2 August 2017; pp. 1604–1609. [Google Scholar]
- Gonzalez-Vidal, A.; Jimenez, F.; Gomez-Skarmeta, A.F. A methodology for energy multivariate time series forecasting in smart buildings based on feature selection. Energy Build. 2019, 196, 71–82. [Google Scholar] [CrossRef]
- Mary, M.A.P. Classifying Future Scope in Energy Resources and Predicting Power Demand using Multilayer Perceptron. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 2332–2339. [Google Scholar]
- Usha, T.; Balamurugan, S.A.A. Seasonal based electricity demand forecasting using time series analysis. Circuits Syst. 2016, 7, 3320–3328. [Google Scholar] [CrossRef] [Green Version]
- Humeau, S.; Wijaya, T.K.; Vasirani, M.; Aberer, K. Electricity load forecasting for residential customers: Exploiting aggregation and correlation between households. In Proceedings of the 2013 Sustainable Internet and ICT for Sustainability (SustainIT), Palermo, Italy, 30–31 October 2013; pp. 1–6. [Google Scholar]
- Loria, S. textblob Documentation. Release 0.16. 26 April 2020. Available online: https://buildmedia.readthedocs.org/media/pdf/textblob/latest/textblob.pdf (accessed on 1 June 2021).
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8. [Google Scholar]
- Time Series Analysis and Forecasting with Weka—Pentaho Data Mining. Available online: https://wiki.pentaho.com/display/DATAMINING/Time+Series+Analysis+and+Forecasting+with+Weka#TimeSeriesAnalysisandForecastingwithWeka-3.1BasicConfiguration (accessed on 1 June 2021).
- Sattar, N.S.; Arifuzzaman, S. Community Detection using Semi-supervised Learning with Graph Convolutional Network on GPUs. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5237–5246. [Google Scholar]
- Sattar, N.S.; Anfuzzaman, S. Data Parallel Large Sparse Deep Neural Network on GPU. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), New Orleans, LA, USA, 18–22 May 2020; pp. 1–9. [Google Scholar]
- Zheng, H. Time Series Forecasting of China Stock Market Using Weka—Part 1. Introduction. 2017. Available online: https://medium.com/@kiaorahao/time-series-forecasting-of-china-stock-market-using-weka-part-1-introduction-71b68aed6d18 (accessed on 1 June 2021).
- Pesaran, M.H.; Timmermann, A. How costly is it to ignore breaks when forecasting the direction of a time series? Int. J. Forecast. 2004, 20, 411–425. [Google Scholar] [CrossRef] [Green Version]
- Armstrong, J.S.; Collopy, F. Error measures for generalizing about forecasting methods: Empirical comparisons. Int. J. Forecast. 1992, 8, 69–80. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Twycross, J.; Garibaldi, J.M. A new accuracy measure based on bounded relative error for time series forecasting. PLoS ONE 2017, 12, e0174202. [Google Scholar] [CrossRef] [Green Version]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Maltamo, M.; Kangas, A. Methods based on k-nearest neighbor regression in the prediction of basal area diameter distribution. Can. J. For. Res. 1998, 28, 1107–1115. [Google Scholar] [CrossRef]
- Seal, H.L. Studies in the History of Probability and Statistics. XV The historical development of the Gauss linear model. Biometrika 1967, 54, 1–24. [Google Scholar] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Kisi, O.; Shiri, J.; Demir, V. Hydrological time series forecasting using three different heuristic regression techniques. In Handbook of Neural Computation; Elsevier: Amsterdam, The Netherlands, 2017; pp. 45–65. [Google Scholar]
- Roberts, S.; Osborne, M.; Ebden, M.; Reece, S.; Gibson, N.; Aigrain, S. Gaussian processes for time-series modelling. Philos. Trans. R. Soc. A 2013, 371, 20110550. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://www.tweepy.org/ (accessed on 1 June 2021).
- Loper, E.; Bird, S. Nltk: The natural language toolkit. arXiv 2002, arXiv:cs/0205028. [Google Scholar]
- Frank, E.; Hall, M.; Holmes, G.; Kirkby, R.; Pfahringer, B.; Witten, I.H.; Trigg, L. Weka-a machine learning workbench for data mining. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1269–1277. [Google Scholar]
- What’s New with Twitter API v2 | Docs | Twitter Developer Platform. Available online: https://developer.twitter.com/en/docs/twitter-api/early-access (accessed on 1 June 2021).
- Wang, Y.; Callan, J.; Zheng, B. Should we use the sample? Analyzing datasets sampled from Twitter’s stream API. ACM Trans. Web (TWEB) 2015, 9, 1–23. [Google Scholar] [CrossRef]
- Developer Agreement and Policy—Twitter Developers|Twitter Developer Platform. Available online: https://developer.twitter.com/en/developer-terms/agreement-and-policy (accessed on 6 June 2021).
- Stopwords-Iso. stopwords-iso/stopwords-en. 2016. Available online: https://github.com/stopwords-iso/stopwords-en/blob\/master/stopwords-en.txt (accessed on 6 June 2021).
- Stopwords-Iso. stopwords-iso/stopwords-iso. 2020. Available online: https://github.com/stopwords-iso/stopwords-iso/blob/master/CREDITS.md (accessed on 6 June 2021).
- Comparing Word Form Counts. Available online: https://wordhoard.northwestern.edu/userman/analysis-comparewords.html#loglike (accessed on 6 June 2021).
- Clement, T.; Plaisant, C.; Vuillemot, R. The Story of One: Humanity scholarship with visualization and text analysis. Relation 2009, 10, 8485. [Google Scholar]
- Dunning, T.E. Accurate methods for the statistics of surprise and coincidence. Comput. Linguist. 1993, 19, 61–74. [Google Scholar]
- Rayson, P.; Garside, R. Comparing corpora using frequency profiling. In Proceedings of the Workshop on Comparing Corpora; Association for Computational Linguistics: Stroudsburg, PA, USA, 2000; pp. 1–6. [Google Scholar]
- Kumar, M.; Thenmozhi, M. Forecasting stock index movement: A comparison of support vector machines and random forest. In Proceedings of the Indian Institute of Capital Markets 9th Capital Markets Conference Paper; 2006; Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=876544# (accessed on 6 June 2021).
- Huang, W.; Nakamori, Y.; Wang, S.Y. Forecasting stock market movement direction with support vector machine. Comput. Oper. Res. 2005, 32, 2513–2522. [Google Scholar] [CrossRef]
- Kim, K.j. Financial time series forecasting using support vector machines. Neurocomputing 2003, 55, 307–319. [Google Scholar] [CrossRef]
- Owid. Owid/Covid-19-Data. Available online: https://github.com/owid/covid-19-data/blob/master/public/data/owidcovid-codebook.csv (accessed on 18 June 2021).
- Solis-Moreira, J. Study Confirms Rare Blood Clotting Risk Linked to ChAdOx1-S Vaccine—Benefits Still Outweigh Risks. 2021. Available online: https://www.news-medical.net/news/20210512/Study-confirms-rare-blood-clotting-risk-linked-to-ChAdOx1-S-vaccine-benefits-still-outweigh-risks.aspx (accessed on 1 June 2021).
- United States Population 2021 (Live). Available online: https://worldpopulationreview.com/countries/united-states-population (accessed on 1 June 2021).
- Lovelace, B., Jr.; Breuninger, K. Biden’s New Covid Vaccination Goal Is for 70 of Adults to Have at Least One Shot by July 4. 2021. Available online: https://www.cnbc.com/2021/05/04/covid-vaccines-biden-wants-70percent-with-at-least-1-shot-by-july-4.html (accessed on 1 June 2021).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Equation | Notation |
|---|---|---|
| Mean Absolute Percentage Error (MAPE) | Sample Size | |
| Direction Accuracy (DAC) | Predicted Value Actual Value | |
| Relative Absolute Error (RAE) | Actual Current Actual Previous | |
| Root Relative Squared Error (RRSE) | Predicted Current Predicted Previous | |
| Root Mean Squared Error (RMSE) | Target Previous |
| Vaccine | Keywords | Total Collected Tweets | Unique Tweets for Analysis | Unique Raw Tweets (Cleaned) | Unique Tweets (Stopwords Removed) | Unique Tweets (Normalized) |
|---|---|---|---|---|---|---|
| Pfizer | pfizer, Pfizer-BioNTech, BioNTechpfizer | 681,660 | 580,126 | 521,186 | 496,050 | 493,755 |
| Moderna | Moderna, moderna_tx, Moderna-NIAID, NIAID, NIAID-Moderna | 301,782 | 292,965 | 271,182 | 258,141 | 257,092 |
| Johnson & Johnson | Johnson & Johnson, Johnson and Johnson, Janssen, Janssen Pharmaceutical, J&J | 17,709 | 16,104 | 12,994 | 12,711 | 12,703 |
| Oxford-AstraZeneca | OXFORDVACCINE, Oxford-Astraeneca, OxfordAstraZeneca, AstraZeneca, Vaxzevria, Covishield | 10,740 | 10,223 | 8388 | 8147 | 8140 |
| SputnikV | Sputnik V, sputnikv, sputnikvaccine | 41,136 | 37,804 | 33,175 | 31,809 | 31,697 |
| Covaxin | covaxin, BharatBiotech | 101,128 | 85,927 | 80,630 | 78,371 | 78,216 |
| Sinovac | coronavac, sinovac | 21,947 | 20,591 | 18,621 | 18,095 | 18,060 |
| Tweet Topic | Keywords | Total Collected Tweets | Unique Tweets for Analysis | Unique Raw Tweets (Cleaned) | Unique Tweets (Stopwords Removed) | Unique Tweets (Normalized) |
|---|---|---|---|---|---|---|
| Hygiene | hand sanitizer, sanitizer, wash hands, wash face, soap, soap water, hand soap, sanitize | 99 | 84 | 84 | 83 | 83 |
| Wear Mask | mask, wearamask, masking, N95, face cover, face covering, face covered, mouth cover, mouth covering, mouth covered, nose cover, nose covering, nose covered, cover your face, coveryourface | 2962 | 2954 | 2862 | 2852 | 2848 |
| Travel | travel, outing, camping, air-travel | 1132 | 1126 | 1089 | 1086 | 1086 |
| Social Distancing | social distancing, physical distancing, 6 feet, social distance, physical distance | 727 | 726 | 707 | 705 | 705 |
| Social Gathering | social gathering, gathering, party, restaurant | 622 | 622 | 601 | 601 | 600 |
| No. | Feature | Description |
|---|---|---|
| a | total_vaccinations | Total number of COVID-19 vaccination doses administered |
| b | people_vaccinated | Total number of people who received at least one vaccine dose |
| c | people_fully_vaccinated | Total number of people who received all doses prescribed by the vaccination protocol |
| d | new_vaccinations | New COVID-19 vaccination doses administered (only calculated for consecutive days) |
| e | new_vaccinations_smoothed | New COVID-19 vaccination doses administered (7-day smoothed) [For countries that do not report vaccination data on a daily basis, it is assumed that vaccination changed equally on a daily basis over any periods in which no data were reported. This produces a complete series of daily figures, which is then averaged over a rolling 7-day window.] |
| f | total_vaccinations_per_hundred | Total number of COVID-19 vaccination doses administered per 100 people in the total population |
| g | people_vaccinated_per_hundred | Total number of people who received at least one vaccine dose per 100 people in the total population |
| h | people_fully_vaccinated_per_hundred | Total number of people who received all doses prescribed by the vaccination protocol per 100 people in the total population |
| i | new_vaccinations_smoothed_per_million | New COVID-19 vaccination doses administered (7-day smoothed) per 1,000,000 people in the total population |
| Original Tweet | TextBlob | VADER |
|---|---|---|
| The vaccine is safe and poses a significantly lower risk (6/7,000,000) of harm than COVID19. Risk can always be scary. The data helps me feel safe. I’m a 33yo woman and I would feel relieved to take the J&J vaccine. #410ASpr21 https://t.co/Vij1FjTRgN (accessed on 13 April 2021) | positive | negative |
| CDC investigates death of Virginia woman who died after J&J vaccine https://t.co/LWqfApXfl3 (accessed on 13 April 2021) via @MailOnline | neutral | negative |
| 6 people who received J&J had rare blood clotting. Out of 6.9 million people. I received the one-shot J&J vaccine and had no side effects other than a slightly sore arm (same as the flu shot.) I am very grateful I got it. https://t.co/M6I2PgeOCb (accessed on 13 April 2021) | positive | negative |
| DASSIT. Nobody will EVER trust that J&J vaccine from here on out. Dont matter what the analyses render. But fuck Johnson & Johnson. Them pieces of shit been fucking people over for decades and are responsible for countless deaths w their other products. I don’t blame the caution https://t.co/fJAXKNBw0 (accessed on 13 April 2021) | negative | negative |
| Original Tweet | TextBlob | VADER |
|---|---|---|
| Today marks my two weeks post second dose, so I am fully vaccinated. Still going to do the thing and wear my mask and social distance, though. I never know what difficulties people around me may have, so I would be mortified if I caught this again and spread it to someone else. | positive | negative |
| Finally got the first Dose of #covid19 Vaccine. Got Vaccinated We will still wear mask and practice social distancing. Lets fight together against Covid. #staysafeandkeepsafe #gotvaccine #vaccinesafety #Vaccination2021 | positive | negative |
| No. Frankly I’m not changing social distancing practice until two or three weeks after we’ve both had our second dose of vaccine. https://t.co/OhgAwLmuLq (accessed on 5 June 2021) | positive | negative |
| Received my First Dose of COVID Vaccination. Urge all eligible (18–45 years)to get your shot soon at your nearest Vaccination Centres. Vaccination & Social Distancing are the only few weapons to defeat the virus. #IndiaFightsCorona #We4Vaccine #CoWIN #VaccinationForAll #WearMasks https://t.co/fsCKguM9jr (accessed on 5 June 2021) | positive | negative |
| @MeidasTouch Received my second dose at the beggining of the year. Had no secondary effects with first or second dose. I’m 67 and I’m still following guidelines, wearing a mask, social distancing, not going out into large group events. | positive | negative |
| Forecast Time-Unit | 7 Day | 2 Months | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ML Models | RRSE | RAE | MAPE | DAC | RRSE | RAE | MAPE | DAC | Predicted Output [25 July 2021] | Percentage of US Population (%) |
| SVM | 9.6839 | 7.9317 | 1.0053 | 100 | 0.7 | 0.611 | 0.4085 | 100 | 158,875,385.30 | 47.998 |
| KNN | 33.2298 | 16.3643 | 1.5781 | 97.2603 | 5.4676 | 3.5357 | 2.2319 | 95.2381 | 127,340,119.67 | 38.471 |
| LR | 22.2554 | 19.3555 | 2.1925 | 98.6301 | 19.7441 | 9.0889 | 6.5237 | 70 | 244,335,203.02 | 73.817 |
| RF | 5.1035 | 3.8572 | 0.3873 | 97.2603 | 0.518 | 0.4019 | 0.2706 | 100 | 130,586,698.55 | 39.452 |
| M5 | 12.5456 | 10.6901 | 1.1793 | 100 | 1.1796 | 0.9642 | 0.6379 | 100 | 206,719,783.86 | 62.453 |
| Gaussian | 97.8654 | 89.2647 | 10.5854 | 83.7838 | 6.6613 | 5.7836 | 3.8304 | 100 | 389,530,057.65 | 117.682 |
| MLP | 8.3374 | 7.1726 | 0.7369 | 100 | 0.8495 | 0.7206 | 0.4823 | 100 | 165,131,860.07 | 49.888 |
| Forecast Time-Unit | 39 Days [4 July 2021] | 2 Month [25 July 2021] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ML Model | RRSE | RAE | MAPE | DAC | Predicted Population (Millions) | Population (%) | RRSE | RAE | MAPE | DAC | Predicted Population (Millions) | Population (%) |
| SVM | 1.15 | 1.03 | 0.38 | 100 | 190,723,081.48 | 57.62 | 0.77 | 0.63 | 0.33 | 100 | 202,710,056.47 | 61.24 |
| LR | 2.51 | 1.94 | 0.74 | 98.63 | 183,414,075.51 | 55.41 | 0.76 | 0.69 | 0.36 | 100 | 190,327,481.30 | 57.50 |
| M5 | 3.66 | 3.41 | 1.24 | 100 | 206,800,303.87 | 62.48 | 2.29 | 1.96 | 1.00 | 100 | 227,425,170.13 | 68.71 |
| Gaussian | 15.07 | 13.93 | 5.17 | 82.93 | 271,329,235.75 | 81.97 | 7 | 6.02 | 3.08 | 85 | 340,424,892.64 | 102.85 |
| MLP | 1.24 | 1.04 | 0.39 | 100 | 193,044,659.42 | 58.32 | 0.60 | 0.54 | 0.28 | 100 | 206,691,736.49 | 62.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sattar, N.S.; Arifuzzaman, S. COVID-19 Vaccination Awareness and Aftermath: Public Sentiment Analysis on Twitter Data and Vaccinated Population Prediction in the USA. Appl. Sci. 2021, 11, 6128. https://doi.org/10.3390/app11136128
Sattar NS, Arifuzzaman S. COVID-19 Vaccination Awareness and Aftermath: Public Sentiment Analysis on Twitter Data and Vaccinated Population Prediction in the USA. Applied Sciences. 2021; 11(13):6128. https://doi.org/10.3390/app11136128
Chicago/Turabian StyleSattar, Naw Safrin, and Shaikh Arifuzzaman. 2021. "COVID-19 Vaccination Awareness and Aftermath: Public Sentiment Analysis on Twitter Data and Vaccinated Population Prediction in the USA" Applied Sciences 11, no. 13: 6128. https://doi.org/10.3390/app11136128
APA StyleSattar, N. S., & Arifuzzaman, S. (2021). COVID-19 Vaccination Awareness and Aftermath: Public Sentiment Analysis on Twitter Data and Vaccinated Population Prediction in the USA. Applied Sciences, 11(13), 6128. https://doi.org/10.3390/app11136128