5.1. Ranking of the Criticality of Single Neurons
To profile the criticality of the three CNNs, Algorithm 1 was executed to assign resilience scores to individual neurons. As stated before, the MNIST, SVHN, and CIFAR-10 training data sets were used to assign resilience scores. In contrast, their test data sets were used for the fault injections experiments (both at the software and RTL level).
5.1.1. Class-Oriented Analysis (CoA)
Initially, each training data set was divided into subclasses, i.e., the number of outputs. More specifically, in our case study, we had ten outputs for all CNNs, but the same reasoning applies to a different number of output classes. Each sub-class contained only the images representing the selected output class. Hence, the proposed algorithm was executed to obtain the ten final score maps for each CNN. Each of them ordered the total neurons from the one activated with the highest average value to the one with the lowest (from the most critical to the least one) for that particular output class.
Next, we performed software FI campaigns (i) to shed light on the importance of the class-oriented analysis, and (ii) to show that individual output classes hold different robustness levels with respect to errors. This certainly depends on the training phase and the structure of the data set that is used to train the network (typically, in the training set, training images are not evenly distributed among the output classes). We exploited the dropout probability fault model (
p-dropout) in which a fraction of the neurons outputs is set to zero, and thus, their contribution is canceled. The same fixed amount of neuron outputs (
p) was set to zero in two scenarios and, after the injection, the resulting accuracy of each CNN was measured by running the total test set of images (which was different from the training set used to gather the resilience scores). For each output class, in the first scenario (
Random), neurons were randomly chosen from the class score map. In the second (
Critical), the same number of neurons was neatly selected always starting from the top of the class score map, i.e., from the most critical neurons. As for the
Random scenario, since we relied on a random choice of neurons to kill, the experiments were repeated 1000 times (every time picking up different
p random neurons); we report in
Figure 4,
Figure 5 and
Figure 6 the average percentage obtained through the experiments. The experiments were conducted for each output class of the targeted CNNs and, particularly, they were replicated for growing
p-percentages:
p equal to 0.1% (
Figure 4a,
Figure 5a and
Figure 6a);
p equal to 0.5% (
Figure 4b,
Figure 5b and
Figure 6b);
p equal to 1% (
Figure 4c,
Figure 5c and
Figure 6c);
p equal to 1.5% (
Figure 4d,
Figure 5d and
Figure 6d).
The experimental results for the three FI campaigns are reported in
Figure 4,
Figure 5 and
Figure 6. The scenario
Fault-free is the golden accuracy of the class and, as for the
Random and
Critical scenarios, it was computed by running only the inferences of the images belonging to the given output class. As shown, it is evident that random injections do not affect, or only to a negligible extent (when
p gets bigger), the behavior of the neural network. Indeed, in all cases, the accuracy fluctuates around the
Fault-free one, apart from the third and fourth cases (
p = 1% and
p = 1.5%) where it slightly decreases. This confirms the theory under which neural networks are equipped with more neurons than they need [
4]. In fact, up to a certain point, they can obtain enough of some neurons and still work correctly. On the other hand, this is not confirmed in the
Critical scenario. The accuracy of the output classes considerably drops when killing the
p highest neurons.
Concerning MNIST LeNet, for
p = 0.1% (
Figure 4a), the maximum percentage variation from the
Fault-free accuracy to scenario
Critical is equal to 6.13% and corresponds to the last class (digit 9). Then, when killing
p = 0.5% critical neurons (
Figure 4b), the highest percentage variation drastically increases, reaching 44.33% for the second class (digit 1), where the CNN accuracy drops from
Fault-free 99.33% to 54.54%.
The situation worsens with
p = 1% for all the classes, except for digits 5 and 7, where the accuracy keeps close to 60% (
Figure 4c). In the last scenario, when dropping
p = 1.5% critical neurons from the classes, the correct predictions become zero or close to it. As illustrated in
Figure 4d, it turns out that for LeNet trained on MNIST data set, the most robust class corresponds to digit 5, while the least robust is digit 4.
The outcome of the software fault injection for the SVHN network (ConvNet) is shown in
Figure 5. When crashing
p = 0.1%
Critical neurons, the CNN accuracy decreases until reaching a maximum percentage variation equal to 7.3% for digit 9 (
Figure 5a). With the increase in the dropped critical neurons
p = 0.5%, we observe a considerable drop in accuracy, with a maximum of 61.9% of variation percentage still for digit 9 (
Figure 5b). The correct functionality of the neural network worsens considerably for
p = 1% until it reaches zero in almost all classes for
p = 1.5% (
Figure 5c,d). Overall, the most robust class turns out to be the third one, i.e., digit 2. In fact, despite the dropped neurons, it is able to keep an accuracy close to 80% with the highest neurons dropped of 927 (
p = 0.5%). On the other hand, the least resilient class is the last one (digit 9). In fact, it is significantly sensitive to removed neurons (starting from
p = 0.1%).
With respect to LeNet (MNIST) and ConvNet (SVHN), All-CNN (CIFAR-10) demonstrates greater sensitivity. As shown in
Figure 6a, we can observe a greater reduction in accuracy from
p = 0.1% (the maximum drop in accuracy is for Class “
Horse” and corresponds to 16.2% from the
Fault-free value). In addition, for
p = 0.5%, all the classes’ accuracy stays under 60%, with the maximum variation percentage from the golden accuracy equal to 69.82% for the class “
Horse” (
Figure 6b). When the dropped neurons become
p = 1% from each class (meaning about 1854 neurons over the total 185,374), the accuracy of the classes drops below 20%, except for the class “
Car” with 21.4% (
Figure 6c). The experimental results indicate that the most robust class is the class “
Car”, while the least resilient one is class “
Horse” (
Figure 6d).
Overall, data from
Figure 4,
Figure 5 and
Figure 6 suggest similar conclusions, and the different per-class resilience is confirmed in the three targeted CNNs. It is clear that the
p-percentage refers to different CNNs of different sizes: the CIFAR-10 network contains almost 7.54× and 4× the number of neurons than the MNIST and SVHN networks, respectively. It means that the former starts misbehaving with about 361 neurons crashed (
p = 0.1%), while the other two (with the same percentage) with about 49 and 185, respectively. Finally, these outcomes experimentally demonstrate the initial assumption stating that there are neurons playing a key role, and therefore, are defined critical for the output classes.
To avoid confusion, we used the p parameter to indicate the amount of neurons dropped from the individual classes, and the t parameter to represent the set of critical neurons in the network-oriented score map. They are both percentages working on the score maps, but the first is used in the class-oriented analysis and is used to drop neurons, while the second in used in the network-oriented analysis and serves as a parameter to indicate the reliability level of the system.
5.1.2. Network-Oriented Analysis (NoA)
So far, we have performed software FI campaigns to demonstrate that each output class owns a set of neurons that are more important than others for correctly predicting their images. If this is considered when ranking the network’s neurons based on their criticality, we experimentally demonstrate that the reliability analysis becomes more accurate. In this phase, we computed the neurons’ resilience scores without differentiating among the output classes. Hence, the entire MNIST, SVHN, and CIFAR-10 training data sets were used to collect the neurons’ scores. We obtained a network-oriented score map for each CNN (LeNet, ConvNet, All-CNN). For the sake of clarity, these lists do not consider the contribution of the classes yet.
5.1.3. Final Network-Oriented Score Map
After the CoA and NoA, a final network-oriented score map was obtained based on the analysis of the class-oriented approach and given the
t parameter. This
t value represents the amount of neurons taken from the classes score maps (always starting from the top positions). By applying (
3), i.e., the union (without repetition) operation, we removed duplicate neurons by keeping the highest values assumed among the classes rankings. Therefore, with each
t value, we computed the percentage of neurons with the Equation (
3) in the CoA: their value will be compared with that obtained in the initial NoA. Then, for each neuron in the set (
3), if its value was higher than that in the NoA, its value was updated in the final score map; otherwise, the highest from the NoA was kept.
Next, to study the influence of the CoA on the NoA with a growing
t percentage, we performed a further study on the three CNNs. The first experiment is shown in
Figure 7a and targets LeNet (MNIST). The x-axis represents the increasing
t percentage, whereas the y-axis shows the corresponding percentage of neurons over the total. The red line outlines the percentage of critical neurons calculated with (
3) after the CoA, for the corresponding
t value. The blue line illustrates the percentage of neurons that are updated in the final network-oriented score map due to their higher criticality value. As it turns out, the lower the
t percentage, the higher the percentage of neurons in the set (
3), whose value is updated in the final network-oriented score map. For example, when
t = 5% in LeNet (MNIST), the union without repetition (
3) includes 6291 critical neurons (red point), meaning the 12% of the total 48,650 neurons. A total of 6212 neurons (blue point) over 6291 (red point) are overwritten with the values obtained from the CoA (
3). In other words, 98.74% of neurons has a different level of criticality when moving from the class-oriented to the network-oriented methodology. For higher
t values, this percentage reduces, reaching 45% for
t = 80%.
Furthermore, as illustrated in
Figure 7b,c, the same analysis was reproduced for ConvNet (SVHN) and All-CNN (CIFAR-10). Similar to what was discussed for LeNet, the lower the set of critical neurons in (
3) (determined by the
t percentage and showed as a red line), the higher the percentage of neurons in this set that will be updated in the final network-oriented score map (blue line). Overall, we can say that even with the highest
t = 80%, the number of neurons with a criticality higher in the CoA is approximately half of the total neurons and, as experimentally demonstrated, it depends also on the size of the neural network. Specifically, when
t = 80%, we updated 45.57%, 55.64%, 69.04% of neurons (respectively for LeNet, ConvNet, and All-CNN) in the final network-oriented score map. A further observation related also to the size of the targeted neural networks is that the initial set of critical neurons for
t = 5%. The smaller the network size, the higher the probability of having replicated neurons. In other words, when
t = 5%, the union without repetition yields the following figures: 12.93%, 19.18%, and 35.93% for LeNet, ConvNet, and All-CNN, respectively.
Finally, to demonstrate how the proposed profiling methodology behaves with respect to the existing methodology [
48] discussed in
Section 2.3, we present a further analysis. As stated, the final network-oriented score map contains the network’s neurons ordered based on their criticality, reinforced by a
t percentage with the CoA.
We carried out software FI campaigns for the three CNNs. Specifically, a fixed percentage of critical neurons was set to zero in three scenarios: the proposed methodology (CoA + NoA), the proposed methodology without the CoA, and the Taylor-based [
48]. Then, the accuracy of the neural network over the entire test set was computed. Specifically, we removed 2%, 5%, 10%, 20%, 50%, and 70% of critical neurons from the respective ordered network-oriented lists. For the purpose, two different network-oriented score maps were created following our proposed approach, each one with a growing set of critical neurons (
t = 10%,
t = 20%). The aim was to demonstrate that with a growing
t, we obtained a more robust network-oriented score map.
Figure 8 shows the results of our FI simulations with the dropout model for the MNIST, SVHN, and CIFAR-10 CNNs. Moreover, its effectiveness is compared against [
48] (green line) and our proposed methodology without the contribution of the class-oriented analysis (red line). As it turns out, the accuracy that the CNN under assessment achieves is always lower when removing the same percentage of critical neurons from our network-oriented score map. It means that, first, the ordering of the critical neurons greatly affects the reliability of the system; second, our final score map holds (in the highest positions) neurons that are critical not only to the entire neural network, but also to individual output classes. Finally, the time required to perform the process described in [
48] is 3×, 4.1×, and 4.7× larger than the proposed one for the custom LeNet-5, ConvNet, and All-CNN, respectively.
5.2. Mapping and Optimal Scheduling
To demonstrate the reliability improvements of the proposed ILP scheduling, we compared two different approaches:
Traditional static scheduling: It is the traditional method where the same range of neurons are assigned always to the same PE, as depicted in
Figure 3.
Proposed ILP and variance-based scheduling: It is the proposed approach described in
Section 3.3. It assigns portions of neurons to PEs depending on their criticality.
First, we computed the number of critical neurons that each PE has to elaborate in a static scheduling. As illustrated in
Figure 3, in static scheduling, chunks are assigned to PEs in an orderly fashion. In other words, the first chunk of the first layer is assigned to the first PE
0, the second chunk to the second PE
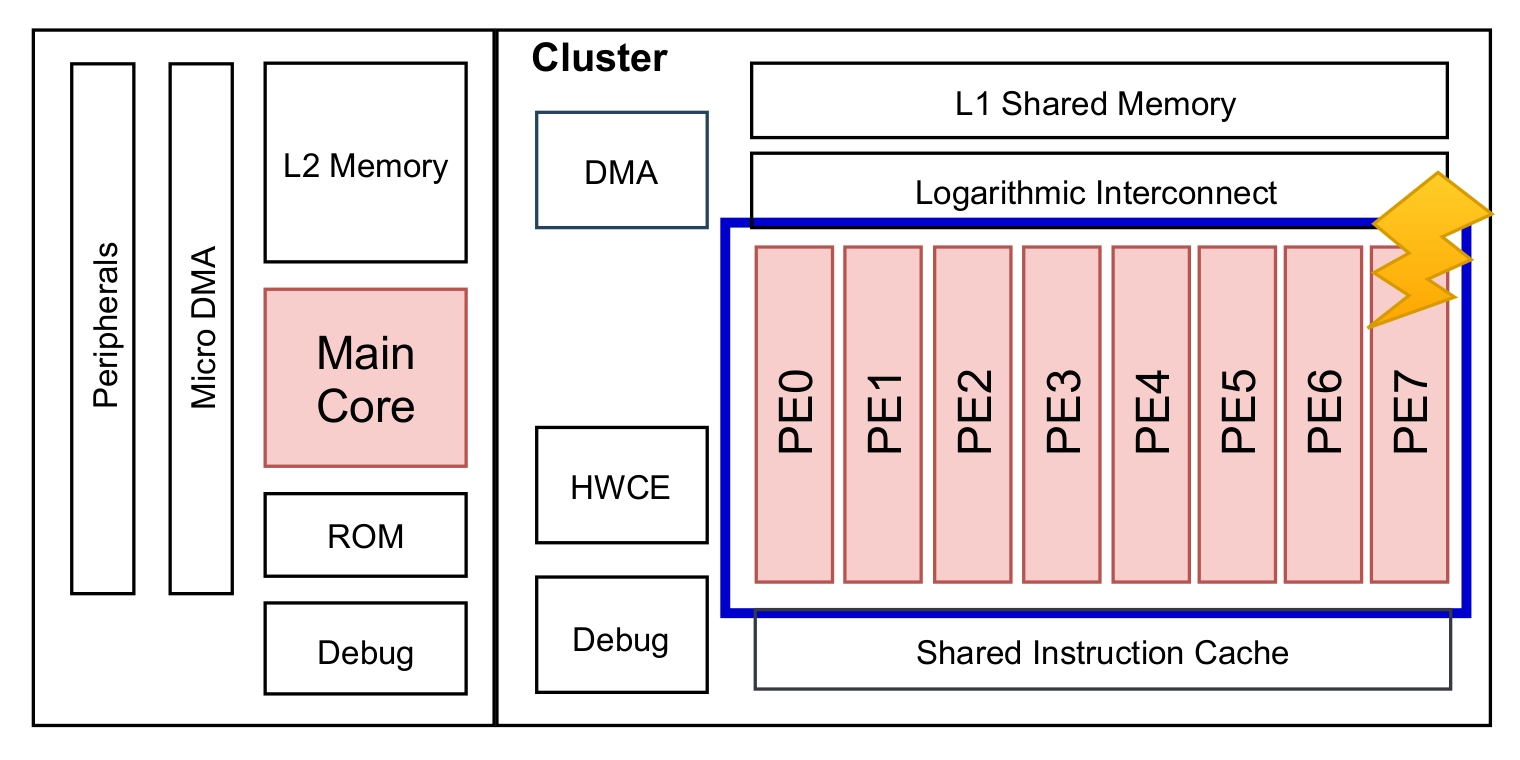
1, and so on. It is, thus, fairly straightforward to compute the number of critical neurons assigned to each PE. In our case study, the LeNet (MNIST) was scheduled on an AI-oriented multiprocessor SoC with 8 identical PEs (
Figure 9). Hence, the workload of each layer was split into 8 chunks of neurons and statically assigned to the 8 PEs of the cluster. To determine the criticality of each chunk in a static scheduling, we relied on the final network-oriented score map and assigned a value to each chunk of neurons by computing the variance metric, i.e., Equation (
4) described in
Section 3.2. Figures are provided in
Table 2. It should be noted that the numbers are converted into integers for complying with the next ILP-based methodology. The second column provides the total amount of neurons for each layer: each chunk is composed of that number divided by the available PEs. This reasoning cannot be applied for the last fully connected layer since there is not a precise division during the inference: having the neurons all connected between them, every PE elaborates all neurons. From the third to the last columns, the variance numbers are provided for each chunk of the layer. In the main, data in
Table 2 suggest that the PE elaborating the highest quantity of critical neurons is PE
0: the sum of the variances is equal to 83, the highest. On the contrary, PE
7 is the one with least critical load: the sum of the variances is the lowest among the PEs and is equal to 28.
To prove the efficacy of the proposed scheduling as well as the reliability improvements of the targeted NCS (i.e., LeNet CNN running on GAP-8), a FI campaign was executed at the architectural level (RTL). We injected permanent faults (stuck-at-0 or stuck-at-1) into the RTL design of the PULP platform running the LeNet CNN.
A specific FI framework was built relying on a commercial simulator: Modelsim from Mentor Graphics. The reader should note that simulation-based FIs at RTL are computationally intensive and extremely time consuming. A single LeNet inference cycle at RTL took, on average, 25 min (the faults were placed in the GAP-8 RTL design so we could not take advantage of higher level FI frameworks). For this reason, massive injection campaigns were out of our computational scope. However, to speed up the RTL simulations, we exploited the pipelined fault injector proposed in [
42]. It uses the pipeline concept to parallelize the inference cycles and introduces a high-level controller in Python language for moving the fault location and advancing the inferences. In the end, we were able to obtain an inference result about every 10 min. Despite the non-negligible FI time, the real advantage of simulation-based FIs at RTL is that they allow for the possibility of evaluating the NCS reliability before the fabrication process. In this way, the designer can coshape the software application with the target architecture to pursue a wished reliability level by carrying out precise injections on definite locations of the RTL architecture.
The choice of the faulty location was an arduous task. Indeed, when working at RTL, the injection locations are limited to some data path units, microarchitectural units such as registers [
62] or memories. We bounded our analysis to the stuck-at faults on the inputs and outputs of the Flip-Flops composing the registers. In more detail, permanent faults were injected, one at a time, into the 8 RISC-V cores belonging to the cluster domain of the GAP architecture (as illustrated in
Figure 9). To remark, the inference process was completely executed by the cluster’s cores (PEs) in a SIMD configuration. The main core sitting in the fabric controller area was only in charge of turning on the cluster, so assessing its reliability is out of the scope of this paper.
Faults were classified depending on their effect and in line with the ranking proposed in [
34]. However, to cover the NCS in both the application and architectural level, we introduced a component-level metric, which is typically more connected to the hardware but, as suggested in [
63], can be interestingly applied to classification problems: the mean squared error (MSE) of the output vector. Therefore, a fault was
detected when one of the following situations occurred:
SDC-1: A silent data corruption (SDC) failure is a deviation of the network output from the golden network result, leading to a misprediction. Hence, the fault causes the image to be wrongly classified.
Masked with MSE > 0: The network correctly predicts the result, but the MSE of the faulty output vector is different from zero. It means that the top score is correct but the fault causes a variation in the outputs compared to the fault-free execution.
Hang: The fault causes the system to hang and the HDL simulation never finishes.
In the remaining cases, the fault was said to be masked with MSE = 0.
In particular, we propose an ILP and variance-based methodology to schedule portions of neural network layers on the available computing resources, to avoid critical portions of a network all being assigned to a single PE. The approach is described in
Section 3.3 and takes as input the results shown in
Table 2. It should be remarked that the variance figure for each chunk is fixed, regardless of the PE it is assigned to. Therefore, to obtain an optimal scheduling solution able to unify the “critical” load of the PEs, an ILP model was created by following (
5)–(
11), detailed in
Section 3.3. Going into more detail, the constants were tuned to our target NCS, thus,
P = 8 and
L = 6. The reader should note that, as anticipated, the chunk assignment for fully connected layers does not make sense for topological reasons. Hence, in
Table 2 the row
L6 was excluded from the ILP formulation. Once all the formulas were created in a form suitable for the solver, they were passed to the ILP engine. The tool used was Opensolver [
64], an open-source optimizer, and the specific optimization engine was CBC (COIN-OR Branch-and-Cut) solver. Apart from
Table 2, the solver also takes the compilation constraints and the objective function as input. The outcome of the optimizer was the optimal scheduling shown in
Table 3. As illustrated, the optimizer sorts the chunks so that the cumulative variance assigned to each PE during the whole inference cycle is uniformly distributed. Better solutions are not consistent with the integer constraints, which are crucial to comply with (
7) and (
9). Hence, the kernel of the PULP-NN library was changed to match the optimal scheduling order provided by the ILP solver. As discussed before, the chunks assignments to different PEs do not affect at all the final classification results.
The same set of permanent faults was injected in two scenarios: first, when the LeNet CNN application was compiled by following a static scheduling; then, when it was compiled with the proposed optimal scheduling.
A total of 164,000 RTL injections were performed. The same set of 2050 stuck-at-faults were injected in the cluster domain of the GAP-8 RTL design (as shown in
Figure 9). Specifically, the injection targeted the register file of the cluster’s PEs. The injection procedure was the following. A set of 40 images was randomly selected from the MNIST test set. Then, a stuck-at-fault was injected into one of the PEs and the inference of the selected 40 images was performed by compiling the kernel functions of the CNN application with a static scheduling (a total of 82,000 inferences). Then, by keeping the same stuck-at-fault, the inferences of the same set of images was executed by compiling the kernel functions of the CNN application with the proposed scheduling (a total of 82,000 inferences).
As mentioned before, the pipelined framework was used for running the injections. By running 10 parallel processes, the 164,000 injections took about 41 days. The reader should note that for faults producing a simulation hang (i.e., 71,840 and 65,040 images in
Table 4), the pipelined FI framework used a timer for avoiding the inferences of the full set of images.
The data illustrated in
Table 4 show the capability of the proposed ILP and variance-based scheduling in improving the reliability of the NCS. For each row, the number of images that produce the corresponding effect in the static or proposed scheduling is reported along with the related percentage. It is necessary to underline that the new ILP scheduling leads to a 0.6% increase in memory occupation and an increase in simulation times of 3.2% at run-time for a single inference cycle. Nevertheless, the proposed ILP-based scheduling is able to reduce by 24.74% the neural network wrong predictions (SDC-1%). Moreover, as expected, the amount of correct predictions with MSE greater than zero (Masked, MSE > 0) increased by 97.80%. In other words, the new scheduling is able to reduce the risk of wrong predictions, producing, again, evidence of faults in the output vector (MSE > 0) but keeping the prediction correct. A third good point concerns the last row of the table (Masked, MSE = 0): the proposed scheduling is able to improve the masking ability of the neural network by 59.53%.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}