
Variational Reward Estimator Bottleneck: Towards Robust Reward Estimator for Multidomain Task-Oriented Dialogue


Abstract
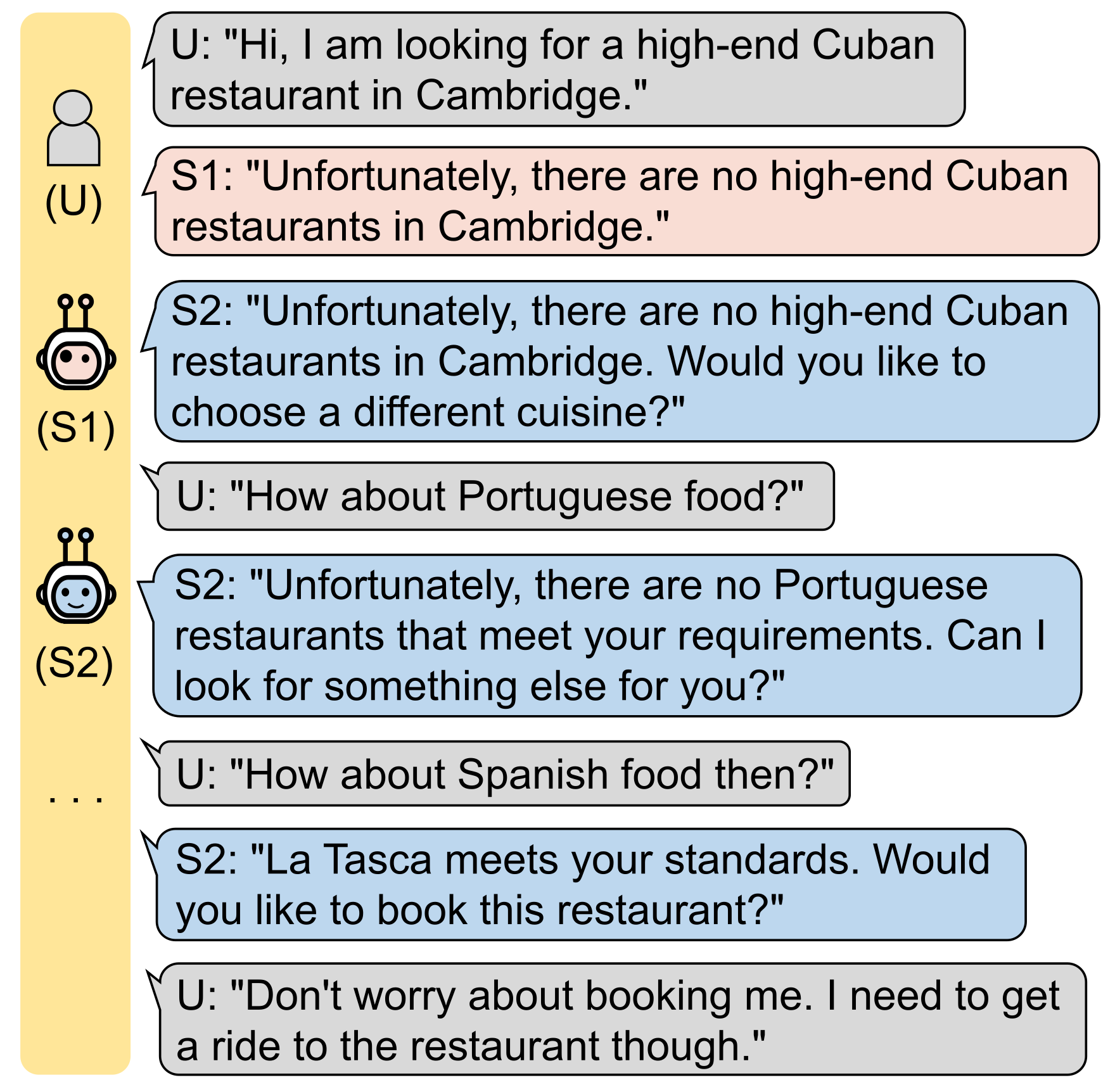
1. Introduction
2. Background
2.1. Dialogue State Tracker
2.2. User Simulator
2.3. Policy Generator
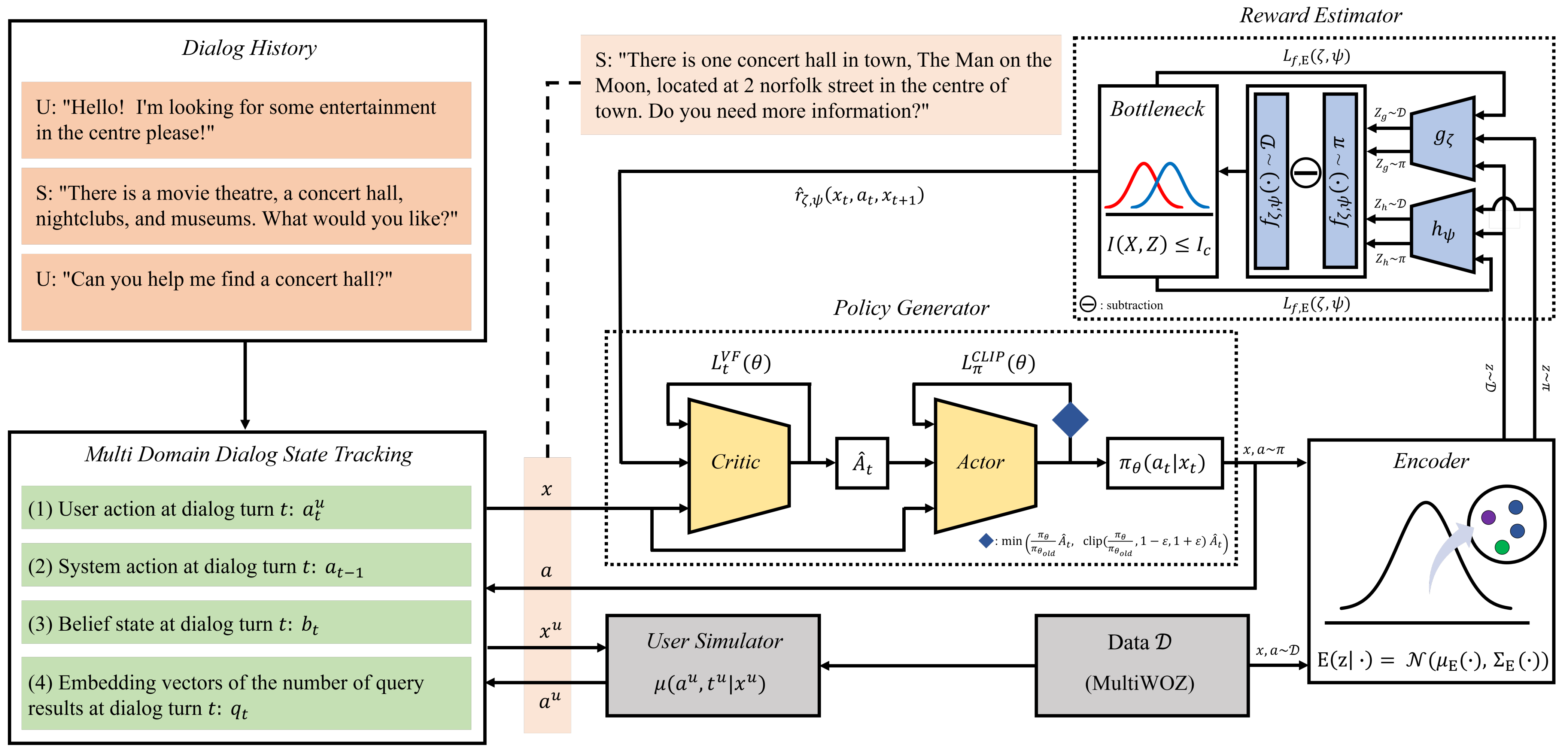
3. Proposed Method
3.1. Notations on MDP
3.2. Reward Estimator
3.3. Variational Reward Estimator Bottleneck
| Algorithm 1 Algorithm of Variational Reward Estimator Bottleneck |
 |
4. Experimental Setup
4.1. Dataset Details
4.2. Models Details
4.3. Evaluation Details
5. Main Results
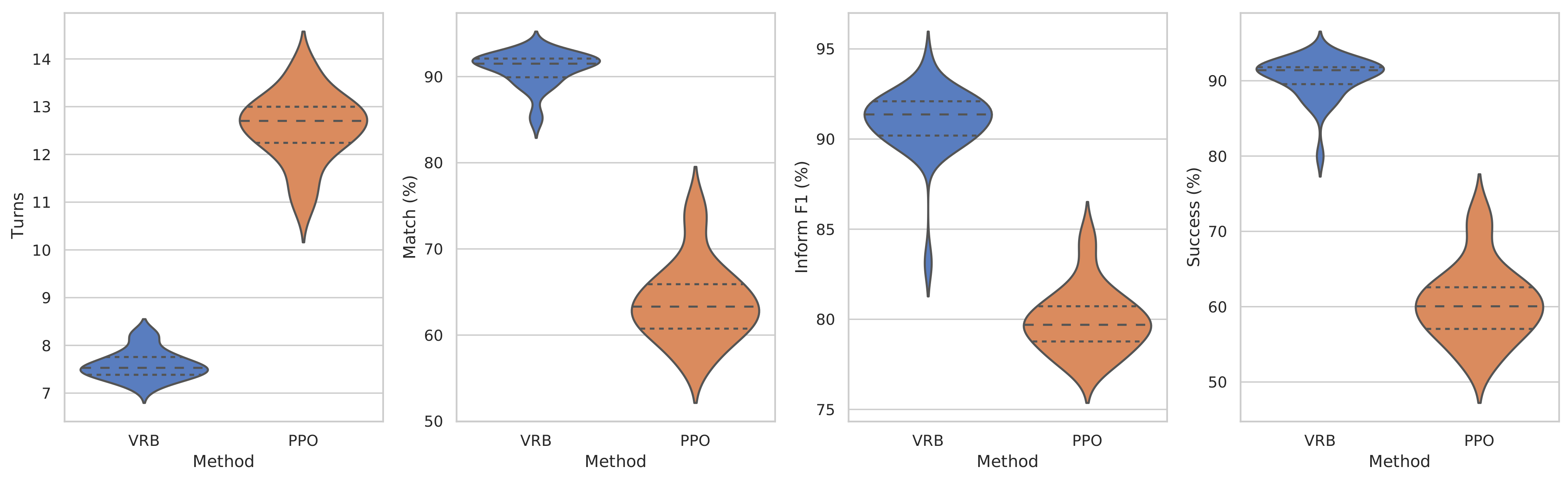
5.1. Experimental Results of Agenda-Based User Simulators
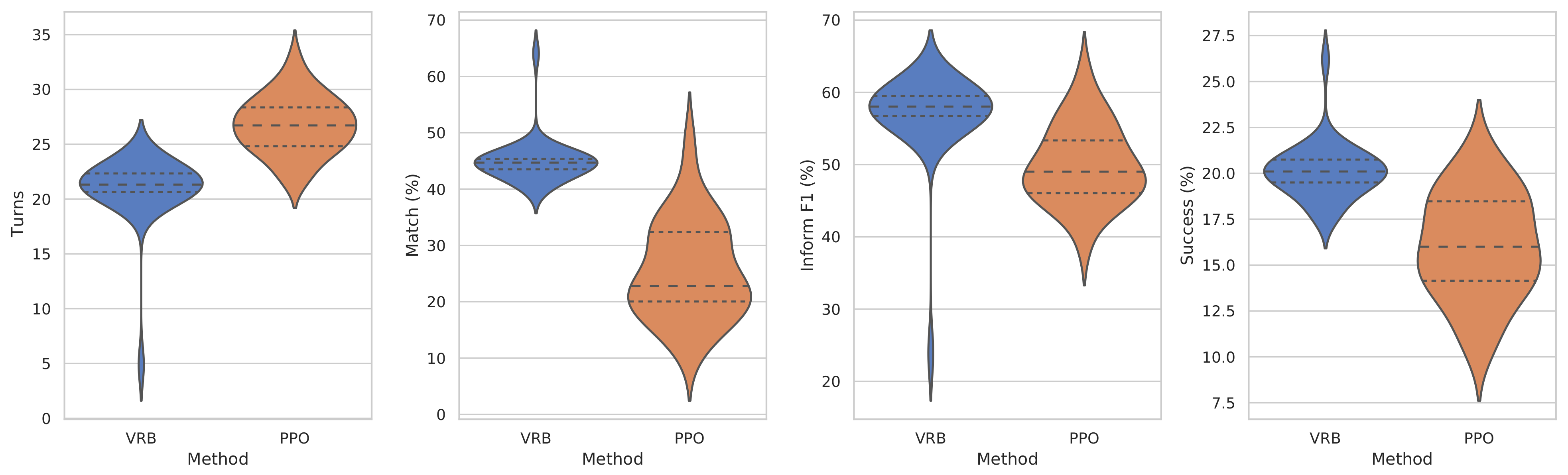
5.2. Experimental Results of VHUS-Based User Simulators
5.3. Verification of Robustness
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. CoRR 2019. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–503. [Google Scholar] [CrossRef] [PubMed]
- Campbell, M.; Hoane, A.; hsiung Hsu, F. Deep Blue. Artif. Intell. 2002, 134, 57–83. [Google Scholar] [CrossRef]
- Schaeffer, J.; Culberson, J.; Treloar, N.; Knight, B.; Lu, P.; Szafron, D. A world championship caliber checkers program. Artif. Intell. 1992, 53, 273–289. [Google Scholar] [CrossRef]
- Brown, N.; Sandholm, T. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science 2018, 359, 418–424. [Google Scholar] [CrossRef] [PubMed]
- Moravcík, M.; Schmid, M.; Burch, N.; Lisý, V.; Morrill, D.; Bard, N.; Davis, T.; Waugh, K.; Johanson, M.; Bowling, M.H. DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker. CoRR 2017. [Google Scholar] [CrossRef] [PubMed]
- Peters, J.; Schaal, S. Reinforcement Learning of Motor Skills with Policy Gradients. Neural Netw. 2008, 21, 682–697. [Google Scholar] [CrossRef] [PubMed]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; Volume 80, pp. 1861–1870. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.K.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. CoRR 2020, arXiv:2002.00444. [Google Scholar]
- Wu, J.; Huang, Z.; Lv, C. Uncertainty-Aware Model-Based Reinforcement Learning with Application to Autonomous Driving. arXiv 2021, arXiv:2106.12194. [Google Scholar]
- Zhao, X.; Zhang, L.; Ding, Z.; Xia, L.; Tang, J.; Yin, D. Recommendations with Negative Feedback via Pairwise Deep Reinforcement Learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep Learning Based Recommender System. ACM Comput. Surv. 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Zhao, T.; Eskenazi, M. Towards End-to-End Learning for Dialog State Tracking and Management using Deep Reinforcement Learning. In Proceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue; Association for Computational Linguistics: Los Angeles, CA, USA, 2016; pp. 1–10. [Google Scholar] [CrossRef]
- Dhingra, B.; Li, L.; Li, X.; Gao, J.; Chen, Y.N.; Ahmed, F.; Deng, L. Towards End-to-End Reinforcement Learning of Dialogue Agents for Information Access. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, AB, Canada, 30 July–4 August 2017. [Google Scholar] [CrossRef]
- Shi, W.; Yu, Z. Sentiment Adaptive End-to-End Dialog Systems. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, QC, Australia, 15–20 July 2018. [Google Scholar] [CrossRef]
- Shah, P.; Hakkani-Tür, D.; Liu, B.; Tür, G. Bootstrapping a Neural Conversational Agent with Dialogue Self-Play, Crowdsourcing and On-Line Reinforcement Learning. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 3 (Industry Papers); Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 41–51. [Google Scholar] [CrossRef]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Maximum Entropy Inverse Reinforcement Learning; AAAI: Chicago, IL, USA, 2008; Volume 8, pp. 1433–1438. [Google Scholar]
- Russell, S. Learning agents for uncertain environments. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 101–103. [Google Scholar]
- Ng, A.; Russell, S. Algorithms for Inverse Reinforcement Learning. In Proceedings of the ICML’00 Seventeenth International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000. [Google Scholar]
- Ho, J.; Ermon, S. Generative Adversarial Imitation Learning. In Advances in Neural Information Processing Systems 29, International Barcelona Convention Center; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 4565–4573. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Fu, J.; Luo, K.; Levine, S. Learning Robust Rewards with Adverserial Inverse Reinforcement Learning. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Takanobu, R.; Zhu, H.; Huang, M. Guided Dialog Policy Learning: Reward Estimation for Multi-Domain Task-Oriented Dialog. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Association for Computational Linguistics: Hong Kong, China, 2019; pp. 100–110. [Google Scholar] [CrossRef]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the 37-th Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep Variational Information Bottleneck. arXiv 2016, arXiv:1612.00410. [Google Scholar]
- Peng, X.B.; Kanazawa, A.; Toyer, S.; Abbeel, P.; Levine, S. Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Williams, J.; Raux, A.; Henderson, M. The Dialog State Tracking Challenge Series: A Review. Dialogue Discourse 2016, 7, 4–33. [Google Scholar] [CrossRef]
- Zhang, Z.; Huang, M.; Zhao, Z.; Ji, F.; Chen, H.; Zhu, X. Memory-Augmented Dialogue Management for Task-Oriented Dialogue Systems. ACM Trans. Inf. Syst. 2019, 37. [Google Scholar] [CrossRef]
- Wu, C.S.; Madotto, A.; Hosseini-Asl, E.; Xiong, C.; Socher, R.; Fung, P. Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Schatzmann, J.; Thomson, B.; Weilhammer, K.; Ye, H.; Young, S. Agenda-Based User Simulation for Bootstrapping a POMDP Dialogue System. In Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion Volume, Short Papers; Association for Computational Linguistics: Rochester, NY, USA, 2007; pp. 149–152. [Google Scholar]
- Gür, I.; Hakkani-Tür, D.; Tür, G.; Shah, P. User modeling for task oriented dialogues. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 900–906. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the 32nd International Conference on Machine Learning; Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Finn, C.; Levine, S.; Abbeel, P. Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization. In Proceedings of the 33rd International Conference on International Conference on Machine Learning—Volume 48. JMLR.org, ICML’16, New York, NY, USA, 19–24 June 2016; pp. 49–58. [Google Scholar]
- Budzianowski, P.; Wen, T.H.; Tseng, B.H.; Casanueva, I.; Ultes, S.; Ramadan, O.; Gašić, M. MultiWOZ—A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 5016–5026. [Google Scholar] [CrossRef]
- Gašić, M.; Mrkšić, N.; Su, P.; Vandyke, D.; Wen, T.; Young, S. Policy committee for adaptation in multi-domain spoken dialogue systems. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 806–812. [Google Scholar]
- Wang, Z.; Bapst, V.; Heess, N.; Mnih, V.; Munos, R.; Kavukcuoglu, K.; de Freitas, N. Sample Efficient Actor-Critic with Experience Replay. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Liu, B.; Lane, I. Adversarial Learning of Task-Oriented Neural Dialog Models. In Proceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue; Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 350–359. [Google Scholar] [CrossRef]
- Tresp, V. A Bayesian Committee Machine. Neural Comput. 2000, 12, 2719–2741. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value |
|---|---|
| Lagrange multiplier | 0.001 |
| Upper bound | 0.5 |
| Learning rate of dialogue policy | 0.0001 |
| Learning rate of reward estimator | 0.0001 |
| Learning rate of user simulator | 0.001 |
| Clipping component for dialogue policy | 0.02 |
| GAE component for dialogue policy | 0.95 |
| Model | Agenda | |||
|---|---|---|---|---|
| Turns | Match | Inform | Success | |
| GP-MBCM [37] | 2.99 | 44.29 | 19.04 | 28.9 |
| ACER [38] | 10.49 | 62.83 | 77.98 | 50.8 |
| PPO [33] | 9.83 | 69.09 | 83.34 | 59.1 |
| ALDM [39] | 12.47 | 62.60 | 81.20 | 61.2 |
| GDPL [23] | 7.64 | 83.90 | 94.97 | 86.5 |
| VRB (Ours) | 7.59 | 90.87 | 90.97 | 90.4 |
| Human | 7.37 | 95.29 | 66.89 | 75.0 |
| Model | VHUS | |||
|---|---|---|---|---|
| Turns | Match | Inform | Success | |
| GP-MBCM [37] | - | - | - | - |
| ACER [38] | 22.35 | 33.08 | 55.13 | 18.6 |
| PPO [33] | 19.23 | 33.08 | 56.31 | 18.3 |
| ALDM [39] | 26.90 | 24.15 | 54.37 | 16.4 |
| GDPL [23] | 22.43 | 36.21 | 52.58 | 19.7 |
| VRB (Ours) | 20.96 | 44.93 | 56.93 | 20.1 |
| VRB | PPO | ||
|---|---|---|---|
| U: | {‘attraction-inform-area-1’: ’south’} | U: | {‘attraction-inform-area-1’: ‘south’} |
| S: | {‘attraction-inform-choice-1’: ‘8’, ‘attraction-request-type-?’: ‘?’} | S: | {‘attraction-inform-choice-1’: ‘8’, ‘attraction-request-type-?’: ‘?’} |
| U: | {‘attraction-request-post-?’: ‘?’, ‘attraction-request-phone-?’: ‘?’, ’attraction-request-addr-?’: ‘?’, ‘attraction-request-fee-?’: ‘?’, ‘attraction-request-type-?’: ‘?’} | U: | {‘attraction-request-post-?’: ‘?’, ‘attraction-request-phone-?’: ‘?’, ‘attraction-request-addr-?’: ‘?’, ‘attraction-request-fee-?’: ‘?’, ‘attraction-request-type-?’: ‘?’} |
| S: | {‘attraction-inform-name-1’: ‘the junction’, ‘attraction-recommend-name-1’: ‘the junction’, ‘attraction-recommend-addr-1’: ‘clifton way’} | S: | {‘attraction-inform-name-1’: ‘the junction’, ‘attraction-inform-fee-1’: ‘?’, ‘attraction-recommend-name-1’: ‘the junction’} |
| U: | {‘attraction-request-post-?’: ‘?’, ‘attraction-request-phone-?’: ‘?’, ‘attraction-request-fee-?’: ‘?’, ‘attraction-request-type-?’: ‘?’} | U: | {‘attraction-request-post-?’: ‘?’, ‘attraction-request-phone-?’: ‘?’, ‘attraction-request-addr-?’: ‘?’, ‘attraction-request-type-?’: ‘?’} |
| S: | {‘attraction-inform-fee-1’: ‘?’, ‘attraction-inform-phone-1’: ‘01223511511’, ‘attraction-inform-post-1’: ‘cb17gx’} | S: | {‘attraction-inform-name-1’: ‘the junction’, ‘attraction-inform-addr-1’: ‘clifton way’, ‘attraction-inform-phone-1’: ‘01223511511’, ‘attraction-inform-post-1’: ‘cb17gx’} |
| U: | {‘attraction-request-type-?’: ‘?’} | U: | {‘attraction-request-type-?’: ‘?’} |
| S: | {‘attraction-inform-type-1’: ‘museum’} | S: | {} |
| U: | {‘hotel-inform-price-1’: ‘cheap’, ‘hotel-inform-area-1’: ‘centre’} | U: | {‘attraction-request-type-?’: ‘?’} |
| S: | {‘hotel-inform-name-1’: ‘alexander bed and breakfast’} | S: | {} |
| U: | {‘hotel-request-post-?’: ‘?’, ‘hotel-request-phone-?’: ‘?’} | U: | {‘attraction-request-type-?’: ‘?’} |
| S: | {‘general-reqmore-none-none’: ‘none’, ‘hotel-inform-phone-1’: ‘01223525725’, ‘hotel-inform-post-1’: ‘cb12de’} | S: | {} |
| U: | {‘hotel-inform-stay-1’: ‘dont care’, ‘hotel-inform-day-1’: ‘dont care’, ‘hotel-inform-people-1’: ‘dont care’} | U: | {‘attraction-request-type-?’: ‘?’} |
| S: | {‘booking-book-ref-1’: ‘none’} | S: | {} |
| U: | {‘general-bye-none-none’: ‘none’} | U: | {‘attraction-request-type-?’: ‘?’} |
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘attraction-request-type-?’: ‘?’} | ||
| S: | {} | ||
| U: | {‘general-bye-none-none’: ‘none’} | ||
| turn: 8 match: 1.0 inform: (1.0, 1.0, 1.0) | turn: 22 match: 0.0 inform: (0, 0, 0) | ||
| Success | Failure | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Lee, C.; Park, C.; Kim, K.; Lim, H. Variational Reward Estimator Bottleneck: Towards Robust Reward Estimator for Multidomain Task-Oriented Dialogue. Appl. Sci. 2021, 11, 6624. https://doi.org/10.3390/app11146624
Park J, Lee C, Park C, Kim K, Lim H. Variational Reward Estimator Bottleneck: Towards Robust Reward Estimator for Multidomain Task-Oriented Dialogue. Applied Sciences. 2021; 11(14):6624. https://doi.org/10.3390/app11146624
Chicago/Turabian StylePark, Jeiyoon, Chanhee Lee, Chanjun Park, Kuekyeng Kim, and Heuiseok Lim. 2021. "Variational Reward Estimator Bottleneck: Towards Robust Reward Estimator for Multidomain Task-Oriented Dialogue" Applied Sciences 11, no. 14: 6624. https://doi.org/10.3390/app11146624
APA StylePark, J., Lee, C., Park, C., Kim, K., & Lim, H. (2021). Variational Reward Estimator Bottleneck: Towards Robust Reward Estimator for Multidomain Task-Oriented Dialogue. Applied Sciences, 11(14), 6624. https://doi.org/10.3390/app11146624